Можно ли уехать из Клинцов? (data mining of blablacar.ru)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-07-17 10:20

Парсинг сайта blablacar.ru и анализ пассажиропотока из г. Клинцы Брянской области с помощью языка программирования R.

Предыстория
По воле разных обстоятельств дауншифтнулся в небольшой город Брянской области (г. Клинцы). Живу, работаю, интересуюсь культурным отдыхом. «Куда здесь можно сходить?» — спрашиваю у местных. «Лучше всего сходить на вокзал за билетами», — доброжелательно советуют клинчане.
Идея понравилась, и в качестве отдохновения от забот решил заняться одно-двухдневными путешествиями, выбрав для этой цели Блаблакар (экономичнее, по идее, время поездок проще подобрать, с водителем можно пообщаться, выбор маршрутов больше).
Чтобы лучше представлять: куда, когда, как и за сколько из Клинцов можно уехать, — провёл небольшое исследование. Результатами, алгоритмом, скриптами и данными делюсь в этой статье.
Библиотеки R
Для проведения исследования использованы следующие библиотеки R:
- rvest, Rselenium — парсинг данных;
- dplyr, tidyr — манипуляция с данными;
- ggplot2, ggmap, grid, gridExtra — визуализация;
- forecast, zoo — работа с временными рядами;
- сaret, xgboost, mlr — машинное обучение.
Получение данных
Собрать данные с сайта стандартными средствами R (библиотека rvest) с ходу не удалось. Блаблакар работает на JS, который формирует динамические страницы в зависимости от запроса пользователя, а функции rvest их не поддерживают.
Так как с веб-технологиями я знаком постольку-поскольку, то не стал разбираться, где и что лежит на сервере и как именно подтягивается, а выбрал более простое, как мне показалось, решение.
Установил на машине сервер Rselenium, через него запускал Google Chrome, который формировал нужную страницу и сохранял выдачу. Далее страница без проблем парсилась R.
Блаблакар предоставляет данные всего лишь за два месяца (713 поездок), поэтому эта схема отлично сработала (раза с третьего, весело поскрипывая костылями, сервер запустился). Однако не уверен, что алгоритм подойдёт для парсинга большего количества страниц — слишком много времени и ресурсов уходит, много узких мест.
Скрипт парсера
#### ГЕНЕРАЦИЯ ССЫЛОК #### # Месяцы mnth <- 5:7 # Дни days <- seq(1, 31, 1) # Цикл генерации url.t <- c() urls <- c() for(i in mnth){ for(j in days){ url <- paste0("https://www.blablacar.ru/poisk-poputchikov/klintcy/#?db=", j, "/", i, "/2017&fn=%D0%9A%D0%BB%D0%B8%D0%BD%D1%86%D1%8B,+%D0%91%D1%80%D1%8F%D0%BD%D1%81%D0%BA%D0%B0%D1%8F+%D0%BE%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C&fc=52.756616%7C32.256669&fcc=RU&fp=0&tn=&sort=trip_date&order=asc&radius=15&limit=100") url.t <- c(url.t, url) } urls <- c(urls, url.t) url.t <- c() } # Удаление лишних ссылок urls <- urls[11:74] urls <- urls[-52] # удаление 31 июня #### ПАРСИНГ #### # Создание датасета для хранение полученных данных blblcars <- data.frame(Name = character(), Age = character(), Date = character(), Time = character(), City = character(), Price = character(), stringsAsFactors = FALSE) # Запуск сервера RSelenium rD <- rsDriver( browser = c("chrome")) remDr <- rD$client for (j in urls) { # Переход на страницу remDr$navigate(j) # Перерыв на 3 секунды, иначе браузер не успевает сформировать страницу Sys.sleep(3) # Получение данных со страницы html <- remDr$getPageSource() html <- read_html(html[[1]]) # Имена names <- html_nodes(html, ".ProfileCard-info--name") names.i <- c() if (length(names) == 0) { names.i <- NA } else { for (i in 1:length(names)) { names.i[i] <- gsub(".* | .*", "", names[[i]]) } } # Возраст age <- html_nodes(html, ".u-truncate+ .ProfileCard-info") age.i <- c() if (length(age) == 0) { age.i <- NA } else { for (i in 1:length(age)) { age.i[i] <- gsub(".*возраст: |<br/>.*", "", age[[i]]) } } # Дата date <- html_nodes(html, ".time") date.i <- c() if (length(date) == 0) { date.i <- NA } else { for (i in 1:length(date)) { date.i[i] <- gsub(".*content="|">.*", "", date[[i]]) } } # Время time <- html_nodes(html, ".time") time.i <- c() if (length(time) == 0) { time.i <- NA } else { for (i in 1:length(time)) { time.i[i] <- gsub(".* - | .*", "", time[[i]]) } } # Цена price <- html_nodes(html, ".price") price.i <- c() if (length(price) == 0) { price.i <- NA } else { for (i in 1:length(price)) { price.i[i] <- gsub(".*<span class=""> | .*", "", price[[i]]) } } # Пункт назначения city <- html_nodes(html, ".trip-roads-stop~ .trip-roads-stop") city.i <- c() if (length(city) == 0) { city.i <- NA } else { for (i in 1:length(city)) { city.i[i] <- gsub("<span class="trip-roads-stop">|</span>", "", city[[i]]) } } # Сохранение в датасет blblcars.t <- data.frame(Name = names.i, Age = age.i, Date = date.i, Time = time.i, City = city.i, Price = price.i, stringsAsFactors = FALSE) # Добавление данных в итоговый датасет blblcars <- rbind(blblcars, blblcars.t) } # Закрытие сервера RSelenium remDr$close() # Сохранение данных save(blblcars, file = "data/blblcars")Динамика и предсказание трафика
Скрипт предварительной обработки данных
#### ОБРАБОТКА ДАННЫХ #### # Загрузка данных load("data/blblcars") # Преобразование типов данных blblcars$Age <- as.integer(blblcars$Age) blblcars$Price <- as.integer(gsub("[^0-9]", "", blblcars$Price)) blblcars$hours <- as.integer(gsub(":..", "", blblcars$Time)) blblcars$days <- weekdays(as.Date(blblcars$Date))В среднем из Клинцов выезжает 10 машин в день, максимум — 35. Трафик растущий. Что влияет на положительную динамику — сезон отпусков, более благоприятная дорожная обстановка летом, долгосрочный рост аудитории сервиса — сложно точно сказать. Нужны данные хотя бы за пару лет.
Скрипт графика
#### Динамика трафика #### # row.names(blblcars)[is.na(blblcars$Price)] 2017-06-03 - не было поездок blblcars$Date[214] <- "2017-06-03" # Добавление дня, в который не было поездок # Формирование временного ряда bl.date <- blblcars %>% count(Date) bl.date$n[bl.date$Date == "2017-06-03"] <- 0 bl.date$Date <- as.Date(bl.date$Date) bl.date <- bl.date %>% filter(Date != "2017-07-12") # Min. 1st Qu. Median Mean 3rd Qu. Max. # 0.00 8.00 10.00 11.48 13.00 35.00 summary(bl.date$n) #### График "Количество поездок растёт в сезон отпусков" #### ggplot(bl.date, aes(x = Date, y = n))+ geom_line()+ geom_smooth()+ labs(title = "Пассажиропоток растёт", subtitle = "динамика количества поездок из г. Клинцы на blablacar.ru с 11 мая по 11 июля 2017 г.", caption = "Источник: blablacar.ru silentio.su", x = "Дата", y = "количество поездок")+ theme(legend.position = "none", axis.text.x = element_text(size = 14), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))
Предсказать трафик на ближайшую неделю или месяц тоже проблематично. Протестировал несколько моделей, но точность предсказаний оставляет желать лучшего.
Скрипт модели
#### Предсказание трафика #### bl.arima <- zoo(bl.date$n, bl.date$Date) model.arima <- auto.arima(bl.arima) predic.ar <- forecast(model.arima, h = 14) plot(predic.ar, type = "line", main = " ") title(main = "Динамика и предсказание трафика из Клинцов", xlab = "ARIMA(2,1,1), прогноз на 12-25 июля 2017 г.", ylab = "Количество поездок") grid.text("Источник: blablacar.ru silentio.su", x = 0.98, y = 0.02, just = c("right", "bottom"), gp = gpar(fontsize = 14, col = "dimgrey"))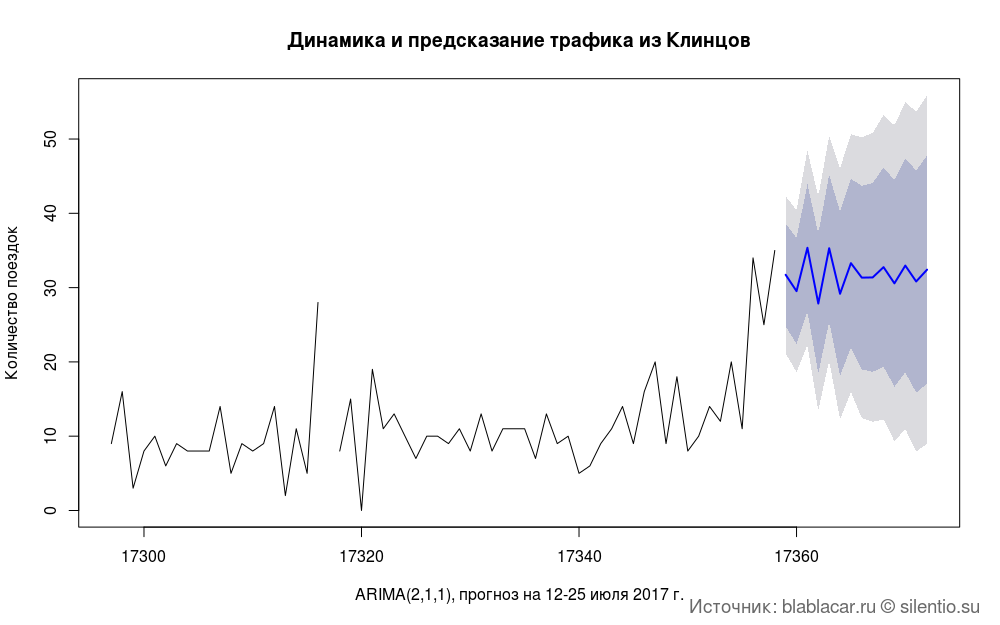
Самые популярные направления
За два месяца машины из Клинцов отправлялись в 59 разных городов. Однако основных направлений немного: Брянск (40% всех поездок), Москва (18%), города Брянской области, Гомель (приграничный город в Белоруссии, областной центр), Орёл, Смоленск — 88% от всех поездок.
Скрипт графика
#### Самые популярные направления #### bl.city <- blblcars %>% count(City) bl.city$percents <- round(bl.city$n/sum(bl.city$n)*100, digits = 2) bl.city <- bl.city %>% arrange(desc(n)) # 59 городов length(unique(bl.city$City)) #### График "Топ-10 маршрутов из г. Клинцы на blablacar.ru" #### ggplot(bl.city[1:10,], aes(x = reorder(City, n), y = percents, fill = percents))+ geom_bar(stat = "identity")+ coord_flip()+ geom_label(aes(label = paste0(percents, "%")), size = 5, colour = "white", hjust = 1)+ labs(title = "Чаще всего клинчане ездят в Брянск и Москву", subtitle = "Топ-10 маршрутов из г. Клинцы на blablacar.ru", caption = "Источник: blablacar.ru silentio.su", x = "Города", y = "% от всех поездок")+ theme(legend.position = "none", axis.text.x = element_text(size = 14), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))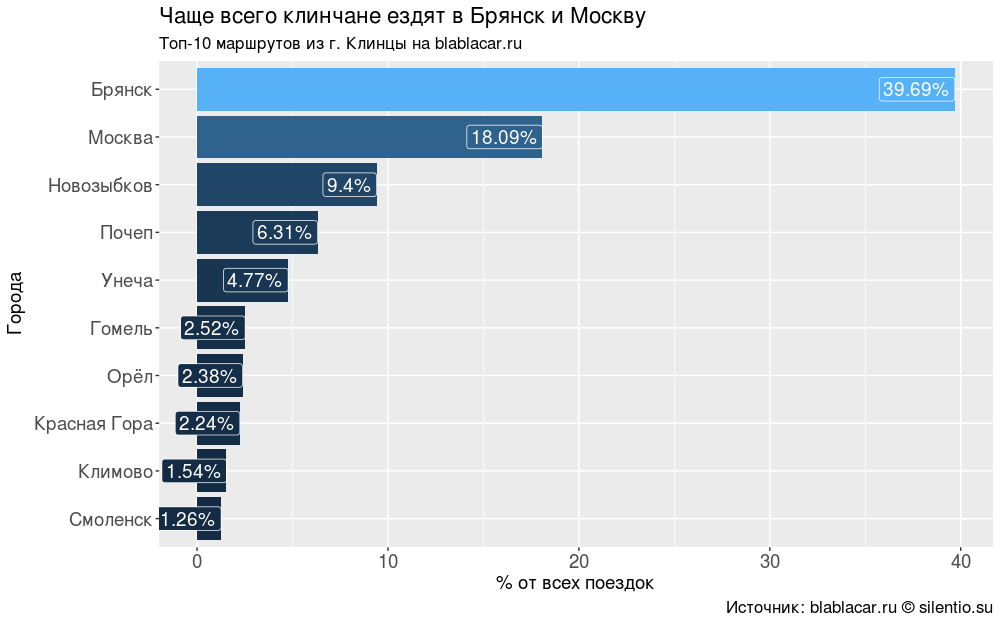
Если нанести пункты назначения на карту, то получится почти идеальная окружность с центром в Клинцах и радиусом 1000-1200 км, плотная в центре и разряженная ближе к периферии. Также хорошо видна дуга «Клинцы-Брянск-Калуга-Москва».
Скрипт карты
#### Карта маршрутов из г. Клинцы на blablacar.ru #### # Геолокация bl.city <- na.omit(bl.city) geo <- geocode(bl.city$City) bl.city <- cbind(bl.city, as.data.frame(geo)) map <- get_map(location = "Klintsy", maptype = "terrain", zoom = 4) ggmap(map)+ geom_point(data = bl.city, aes(x = lon, y = lat, size = percents), alpha = 1, colour = "red")+ labs(title = "Карта маршрутов из г. Клинцы на blablacar.ru", caption = "Источник: blablacar.ru silentio.su", x = " ", y = " ", size = "% поездок:")+ theme(legend.position = "left", legend.text = element_text(size = 12), axis.text.x = element_text(size = 8), axis.title.x = element_text(size = 8), axis.text.y = element_text(size = 8), axis.title.y = element_text(size = 8), title = element_text(size = 14))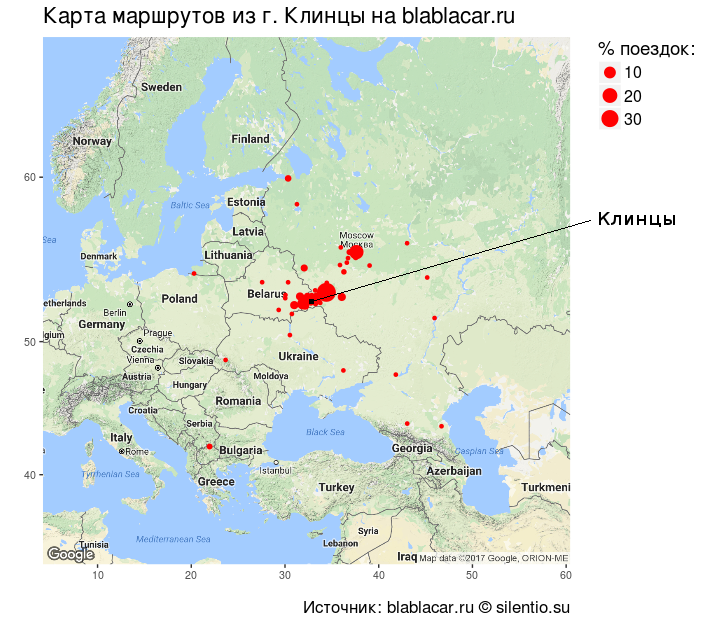
То есть в основном клинчане путешествуют по месту, регулярно ездят в близлежащие областные центры и в МСК.
Стоимость проезда
Стоимость проезда у всех водителей, сгруппированных по направлениям, примерно одинаковая: около 100 р. — по области, в среднем 280 р. — Брянск, 900 р. — Москва. Это где-то на 25% дешевле, чем у регулярных перевозчиков.
Самый большой разброс цен — на билеты в Орёл (от 350 до 600 р.) и Смоленск (от 450 до 650 рублей).
Скрипт графика
#### Средняя цена по Топ-10 направлений #### bl.price.top <- blblcars %>% filter(City %in% unique(bl.city$City[1:10])) %>% select(City, Price) bl.price.top <- full_join(bl.price.top, bl.price.top %>% group_by(City) %>% summarise(mean = mean(Price)) ) bl.price.top$mean <- round(bl.price.top$mean, digits = 0) bl.price.top$mean <- paste0(bl.price.top$mean, " р.") bl.price.top <- bl.price.top %>% unite(City, c(City, mean), sep = ", ") #### График "Самый большой разброс цен на билеты в Орёл и Смоленск" #### ggplot(bl.price.top, aes(x = reorder(City, Price), y = Price))+ stat_summary(geom = "line", group = 1, fun.data = "mean_cl_boot", size = 1, colour = "blue")+ stat_summary(fun.data = "mean_cl_boot", colour = "red", size = 1)+ labs(title = "Самый большой разброс цен - на билеты в Орёл и Смоленск", subtitle = "Средняя цена поездки из г. Клинцы на blablacar.ru (Топ-10 направлений)", caption = "Источник: blablacar.ru silentio.su", x = "Направления и средняя цена", y = "Цена поездки, руб.")+ theme(legend.position = "none", legend.text = element_text(size = 14), axis.text.x = element_text(size = 14, angle = 90), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))
Как ни странно, цена поездки не всегда зависит от расстояния. Дороже всего съездить из Клинцов на Юг и Кавказ — 1500-2300 р. За аналогичные расстояния в направлении Европы просят раза в два меньше.
Скрипт графика
#### Самые дорогие направления #### bl.price <- blblcars %>% select(City, Price) %>% group_by(City) %>% summarise(price = mean(Price)) bl.price$price <- round(bl.price$price, digits = 0) bl.price <- bl.price %>% arrange(desc(price)) #### График "Топ-10 самых дорогих маршрутов из г. Клинцы на blablacar.ru" #### ggplot(bl.price[1:10,], aes(x = reorder(City, price), y = price, fill = price))+ geom_bar(stat = "identity")+ coord_flip()+ geom_label(aes(label = paste0(price, " р.")), size = 5, colour = "white", hjust = 1)+ labs(title = "Дороже всего съездить из Клинцов на Юг и Кавказ", subtitle = "Топ-10 самых дорогих маршрутов из г. Клинцы на blablacar.ru", caption = "Источник: blablacar.ru silentio.su", x = "Направления", y = "Средняя цена поездки, руб.")+ theme(legend.position = "none", axis.text.x = element_text(size = 14), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))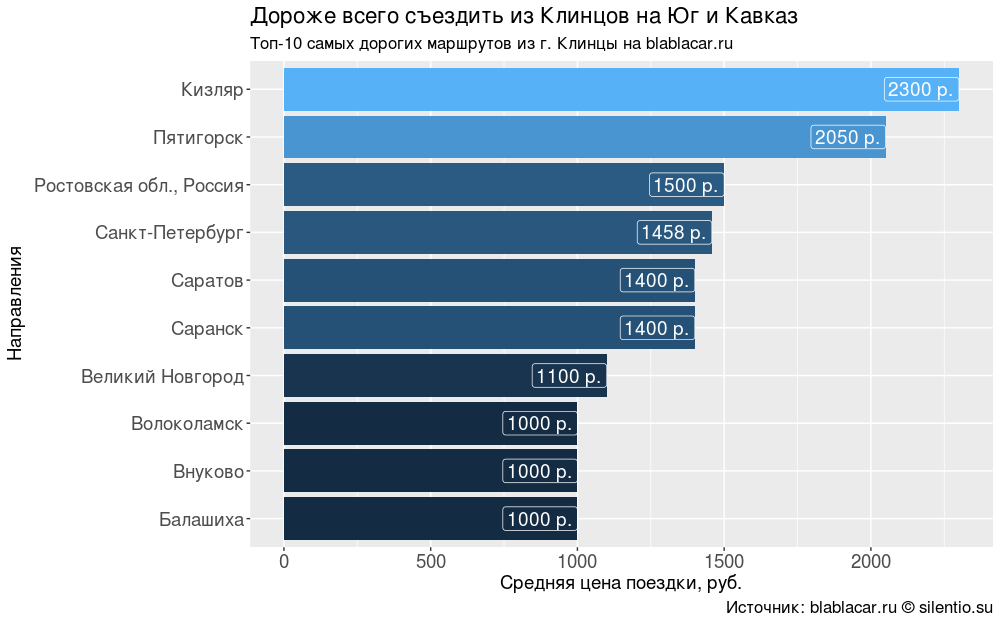
Анализ водителей
Меня заинтересовала мотивация водителей. Почему они берут пассажиров? Есть ли среди них те, кто пользуется сервисом для получения коммерческой выгоды?
54% водителей за два месяца только 1 раз воспользовались сервисом. Остальные ездят с частотой от 1 раза в месяц до 1 раза в неделю, вероятно, по рабочим делам — пассажиров берут в целях снижения дорожных расходов.
Я нашёл только одного человека, который, скорее всего (но это неточно), занимается коммерческим извозом (маршрутное такси, маршрут «Новозыбков — Клинцы — Москва», каждые три дня).
Скрипт графика
#### Самые популярные водители #### drivers <- blblcars %>% select(Name, Age) drivers$Age <- paste0("возраст: ", drivers$Age) drivers <- drivers %>% unite(Name, c(Name, Age), sep = ", ") drivers <- drivers %>% count(Name) drivers$percents <- round(drivers$n/sum(drivers$n)*100, digits = 2) drivers <- arrange(drivers, desc(n)) drivers$per.month <- round(drivers$n/2, digits = 0) summary(as.factor(drivers$n))/sum(drivers$n)*100 #### График "Большинство водителей подвозят людей эпизодически" #### ggplot(drivers[1:10,], aes(x = reorder(Name, n), y = percents, fill = percents))+ geom_bar(stat = "identity")+ coord_flip()+ geom_label(aes(label = paste0(per.month, " поезд./месяц")), size = 5, colour = "white", hjust = 1)+ labs(title = "Большинство водителей подвозят людей эпизодически", subtitle = "Топ-10 водителей по количеству поездок из г. Клинцы на blablacar.ru", caption = "Источник: blablacar.ru silentio.su", x = "Водители", y = "Количество поездок в месяц")+ theme(legend.position = "none", axis.text.x = element_text(size = 14), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))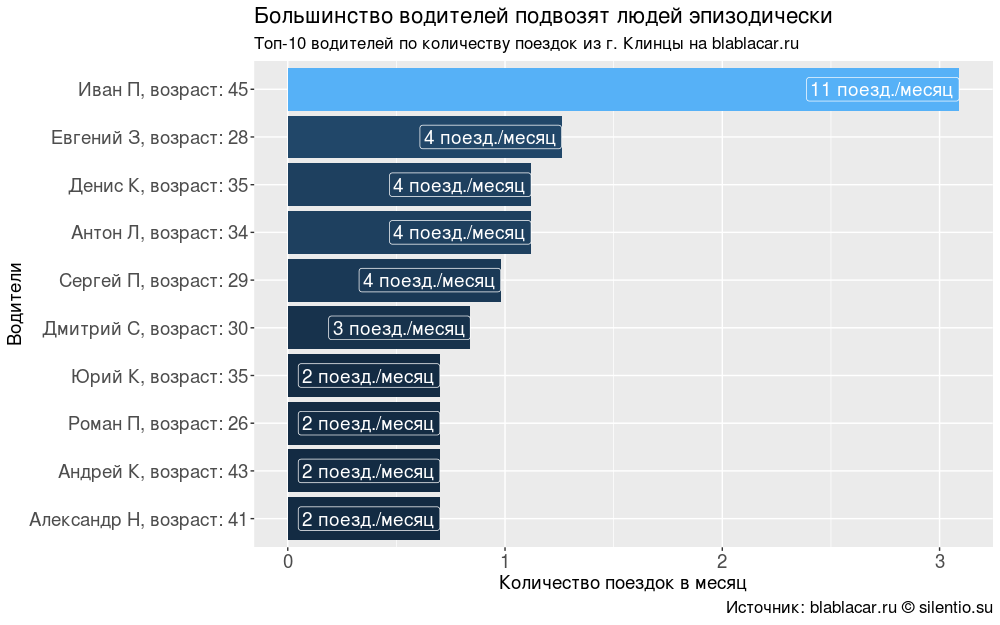
Время отправления
Легче всего уехать из Клинцов с 16:00 до 19:00. Автомобили до Москвы отправляются в ночь, часов в девять вечера.
Скрипт графика
#### Самые популярные часы отправления для Топ-10 #### bl.hours <- blblcars %>% group_by(City) %>% count(hours) bl.hours <- ungroup(bl.hours) # Добавление нулевых значений for (i in unique(bl.hours$City)) { for (j in seq(0, 23, 1)) { if (!j %in% bl.hours$hours[bl.hours$City == i]) { bl.hours <- rbind(bl.hours, data.frame(City = i, hours = j, n = 0)) } } } # Отбор Топ-10 bl.hours <- bl.hours %>% filter(City %in% bl.city$City[1:10]) bl.hours$percents <- round(bl.hours$n/sum(bl.hours$n)*100, digits = 2) #### График "Распределение поездок из г. Клинцы на blablacar.ru по времени суток" #### ggplot(bl.hours, aes(x = hours, y = percents, fill = City))+ geom_bar(stat = "identity")+ labs(title = "Легче всего уехать из Клинцов с 16:00 до 19:00", subtitle = "Распределение поездок из г. Клинцы на blablacar.ru по времени суток", caption = "Источник: blablacar.ru silentio.su", x = "Часы (время суток)", y = "% от всех поездок (по Топ-10)", fill = "Направления:")+ theme(legend.position = "right", legend.text = element_text(size = 12), axis.text.x = element_text(size = 14), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))
Чаще всего люди уезжают из города во вторник, пятницу и воскресенье.
Скрипт графика
#### Самые популярные дни отправления для Топ-10 #### bl.days <- blblcars %>% group_by(City) %>% count(days) bl.days <- ungroup(bl.days) # Добавление нулевых значений for (i in unique(bl.days$City)) { for (j in unique(bl.days$days)) { if (!j %in% bl.days$days[bl.days$City == i]) { bl.days <- rbind(bl.days, data.frame(City = i, days = j, n = 0)) } } } # Отбор Топ-10 bl.days <- bl.days %>% filter(City %in% bl.city$City[1:10]) bl.days$percents <- round(bl.days$n/sum(bl.days$n)*100, digits = 2) # Сортировка по дням недели bl.days$days <- as.factor(bl.days$days) bl.days$days <- factor(bl.days$days, levels = c("Понедельник", "Вторник", "Среда", "Четверг", "Пятница", "Суббота", "Воскресенье")) #### График "Распределение поездок из г. Клинцы на blablacar.ru по дням недели" #### ggplot(bl.days, aes(x = days, y = percents, fill = City))+ geom_bar(stat = "identity")+ labs(title = "Легче всего уехать из Клинцов во вторник, пятницу и воскресенье", subtitle = "Распределение поездок из г. Клинцы на blablacar.ru по дням недели", caption = "Источник: blablacar.ru silentio.su", x = "Дни недели", y = "% от всех поездок (по Топ-10)", fill = "Направления:")+ theme(legend.position = "right", legend.text = element_text(size = 12), axis.text.x = element_text(size = 14), axis.title.x = element_text(size = 14), axis.text.y = element_text(size = 14), axis.title.y = element_text(size = 14), title = element_text(size = 14))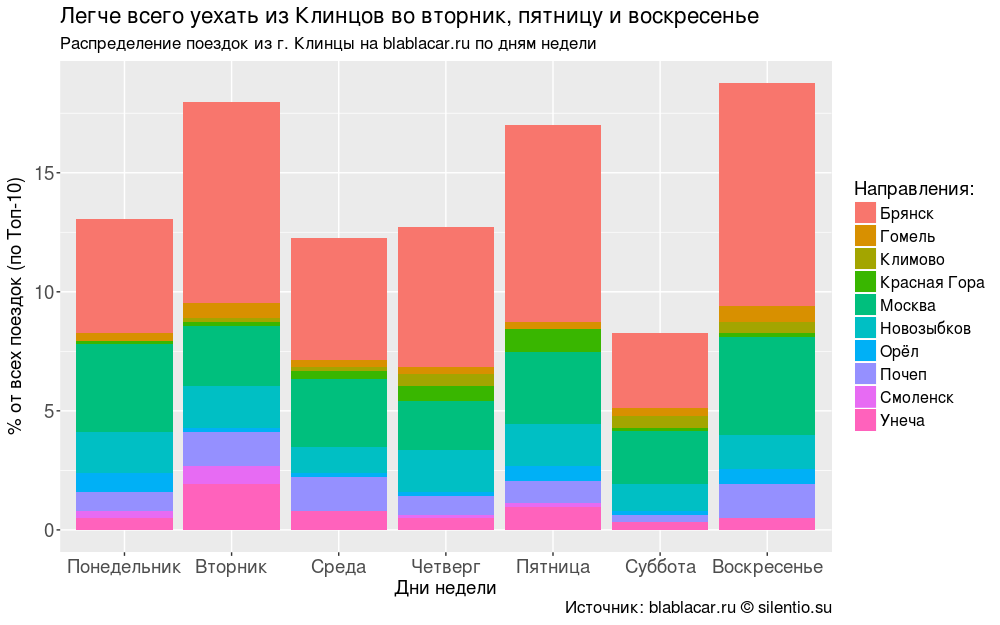
Заключение
По результатам исследования я составил расписание, которое поясняет, куда, когда и за сколько с наибольшей вероятностью можно уехать, если появится такое желание.
Скрипт расписания
#### РАСПИСАНИЕ #### tbls <- blblcars %>% filter(City %in% bl.city$City[1:10]) %>% group_by(City) %>% select(City, days, Time, Price) # Добавление средней цены tbls <- full_join(tbls, tbls %>% summarise(mean.price = round(mean(Price), digits = 0)), by = "City" ) tbls <- tbls %>% select(-Price) # Добавление наиболее вероятного дня недели tbls <- full_join(tbls, tbls %>% count(days) %>% top_n(1, n), by = "City") for (i in unique(tbls$City)) { tbls$days.y[tbls$City == i] <- paste0(unique(tbls$days.y[tbls$City == i]), collapse = ", ") } tbls <- tbls %>% select(-c(days.x, n)) # Добавление наиболее вероятного времени tbls <- full_join(tbls, tbls %>% count(Time) %>% top_n(1, n), by = "City") for (i in unique(tbls$City)) { tbls$Time.y[tbls$City == i] <- paste0(unique(tbls$Time.y[tbls$City == i]), collapse = ", ") } tbls <- tbls %>% select(-c(Time.x, n)) tbls <- ungroup(tbls) tbls <- unique(tbls) tbls <- tbls[c("City", "days.y", "Time.y", "mean.price")] colnames(tbls) <- c("Пункт назначения", "Дни недели", "Время отправления", "Средняя цена поездки") tbls <- tbls %>% arrange(`Пункт назначения`) write.csv(tbls, file = "data/tbls.csv", row.names = F)
Также я обучил алгоритм xgboost, который на основании дня недели и времени отправления предсказывает наиболее вероятный маршрут.
Самым информативным признаком оказался час отправления. Глубокой ночью модель стабильно советует ехать в Новозыбков, днём — в Брянск, вечером — в Москву. Поездки в другие города xgboost находит маловероятными.
Модель xgboost
#### МОДЕЛЬ XGBOOST #### # Подготовка данных df <- read.csv("data/Поездки из Клинцов - Блаблакар.csv", stringsAsFactors = F) df <- df %>% select(c(City, Time, days)) df <- df %>% separate(Time, c("hours", "minutes"), sep = ":") df$days <- as.factor(df$days) levels(df$days) <- c("7", "2", "1", "5", "3", "6", "4") df[,2:4] <- apply(df[,2:4], 2, function(x) as.numeric(x)) top10 <- df %>% count(City) %>% arrange(desc(n)) top10 <- top10$City[1:10] df <- df %>% filter(City %in% top10) df <- na.omit(df) # Кодировка маршрутов df$class <- as.numeric(as.factor(df$City))-1 City.class <- df %>% select(City, class) City.class <- unique(City.class) df <- df[,-1] # Разделение данные на train и test # Выборка 1/3 indexes <- createDataPartition(df$class, times = 1, p = 0.7, list = F) train <- df[indexes,] test <- df[-indexes,] # Сохранение маршрутов y.train <- train$class # Создание матрицы train.m <- data.matrix(train[,-4]) train.m <- xgb.DMatrix(train.m, label = y.train) # Stopping. Best iteration: # [15] train-merror:0.425361+0.010171 # test-merror:0.504626+0.035449 model <- xgb.cv(data = train.m, nfold = 4, eta = 0.03, nrounds = 2000, num_class = 10, objective = "multi:softmax", early_stopping_round = 200) # Подбор параметров модели # Постановка задачи train$class <- as.factor(train$class) traintask <- makeClassifTask(data = train, target = "class") lrn <- makeLearner("classif.xgboost", predict.type = "response") lrn$par.vals <- list(objective = "multi:softmax", eval_metric = "merror", nrounds = 15, eta = 0.03) params <- makeParamSet(makeDiscreteParam("booster", values = c("gbtree", "gblinear")), makeIntegerParam("max_depth", lower = 1, upper = 10), makeNumericParam("min_child_weight", lower = 1, upper = 10), makeNumericParam("subsample", lower = 0.5, upper = 1), makeNumericParam("colsample_bytree", lower = 0.5, upper = 1)) rdesc <- makeResampleDesc("CV", iters = 4) # Стратегия поиска ctrl <- makeTuneControlRandom(maxit = 10) # Подбор параметров mytune <- tuneParams(learner = lrn, task = traintask, resampling = rdesc, par.set = params, control = ctrl, show.info = T) # [Tune-y] 10: mmce.test.mean=0.525; time: 0.0 min # [Tune] Result: booster=gbtree; max_depth=10; min_child_weight=5; # subsample=0.99; colsample_bytree=0.907 : mmce.test.mean=0.516 # Xgboost-model # Параметры модели param <- list( "num_class" = 10, "objective" = "multi:softmax", "eval_metric" = "merror", "eta" = 0.03, "max_depth" = 10, "min_child_weight" = 5, "subsample" = 0.99, "colsample_bytree" = 0.907) # Расчёт количества итераций model <- xgb.cv(data = train.m, params = param, nfold = 4, nrounds = 20000, early_stopping_round = 100) # Stopping. Best iteration: # [84] train-merror:0.462308+0.015107 test-merror:0.509050+0.028020 # Xgboost-модель model <- xgboost(data = train.m, params = param, nrounds = 84, scale_pos_weight = 5) # Создание test-matrix y.test <- test$class test <- data.matrix(test[,-4]) # График информативности признаков mat <- xgb.importance(feature_names = colnames(train.m), model = model) xgb.plot.importance(importance_matrix = mat, main = "Информативность признаков:") # Предсказание y.predict <- predict(model, test, nrounds = 84, scale_pos_weight = 5) # Замена классов на города replace.class <- function(x){ for (i in unique(x)) { x[x == i] <- City.class$City[City.class$class == i] } return(x) } # Проверка точности confusionMatrix(replace.class(y.predict), replace.class(y.test)) # Тестирование модели # Генерация случайного датасета df_test <- data.frame(hours = as.numeric(sample(x = c(0:23), size = 10, replace = T)), minutes = as.numeric(sample(x = c(0:59), size = 10, replace = T)), days = as.numeric(sample(x = c(1:7), size = 10, replace = T))) # Предсказание df_test$City <- replace.class(predict(model, data.matrix(df_test), nrounds = 84, scale_pos_weight = 5)) # Отрисовка таблицы df_test <- df_test[c("City", "days", "hours", "minutes")] colnames(df_test) <- c("Пункт назначения", "День недели", "Час отправления", "Минуты оправления") df_test <- df_test %>% arrange(`Час отправления`) grid.text("Предсказание маршрута с помощью модели xgboost", x = 0.5, y = 0.93, just = c("centre", "bottom"), gp = gpar(fontsize = 16)) grid.table(df_test) grid.text("Источник: blablacar.ru", x = 0.02, y = 0.01, just = c("left", "bottom"), gp = gpar(fontsize = 11)) grid.text(" silentio.su", x = 0.98, y = 0.01, just = c("right", "bottom"), gp = gpar(fontsize = 11))
Если ответить на вопрос, вынесенный в заголовок, то ответ: «Да, из Клинцов можно уехать. только недалеко Это ж не Омск».
Телеграм: t.me/ainewsline
Источник: habrahabr.ru