Как научить свою нейросеть генерировать стихи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-07-25 09:10
лингвистика, реализация нейронной сети, компьютерная лингвистика
Умоляю перестань мне сниться
Я люблю тебя моя невеста
Белый иней на твоих ресницах
Поцелуй на теле бессловесном
Когда-то в школе мне казалось, что писать стихи просто: нужно всего лишь расставлять слова в нужном порядке и подбирать подходящую рифму. Следы этих галлюцинаций (или иллюзий, я их не различаю) встретили вас в эпиграфе. Только это стихотворение, конечно, не результат моего тогдашнего творчества, а продукт обученной по такому же принципу нейронной сети.
Вернее, нейронная сеть нужна лишь для первого этапа — расстановки слов в правильном порядке. С рифмовкой справляются правила, применяемые поверх предсказаний нейронной сети. Хотите узнать подробнее, как мы это реализовывали? Тогда добро пожаловать под кат.
Языковые модели определяют вероятность появления последовательности слов в данном языке:
в данном языке:  . Перейдём от этой страшной вероятности к произведению условных вероятностей слова от уже прочитанного контекста:
. Перейдём от этой страшной вероятности к произведению условных вероятностей слова от уже прочитанного контекста:
 .
.
В жизни эти условные вероятности показывают, какое слово мы ожидаем увидеть дальше. Посмотрим, например, на всем известные слова из Пушкина:
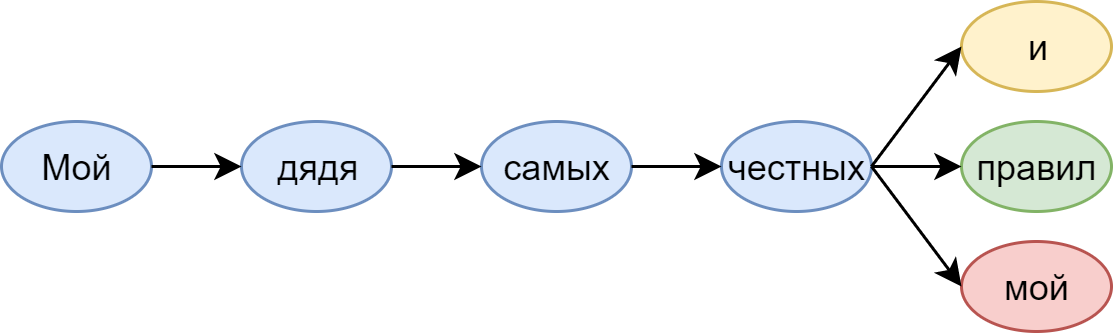
Языковая модель, которая сидит у нас (во всяком случае, у меня) в голове, подсказывает: после честных навряд ли снова пойдёт мой. А вот и, или, конечно, правил — очень даже.
 — отбрасывая слишком далекие слова, как не влияющие на вероятность появления данного.
— отбрасывая слишком далекие слова, как не влияющие на вероятность появления данного.
Такая модель легко реализуется с помощью Counter’ов на Python — и оказывается весьма тяжелой и при этом не слишком вариативной. Одна из самых заметных её проблем — недостаточность статистики: большая часть 5-грамм слов, в том числе и допустимых языком, просто не встретится в сколько-то ни было большом корпусе.
Для решения такой проблемы используют обычно сглаживание Kneser–Ney или Katz’s backing-off. За более подробной информацией про методы сглаживания N-грамм стоит обратиться к известной книге Кристофера Маннинга “Foundations of Statistical Natural Language Processing”.
Хочу заметить, что 5-граммы слов я назвал не просто так: именно их (со сглаживанием, конечно) Google демонстрирует в статье “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling” — и показывает результаты, весьма сопоставимые с результатами у рекуррентных нейронных сетей — о которых, собственно, и пойдет далее речь.
Нейросетевые языковые модели
Преимущество рекуррентных нейронных сетей — в возможности использовать неограниченно длинный контекст. Вместе с каждым словом, поступающим на вход рекуррентной ячейки, в неё приходит вектор, представляющий всю предыдущую историю — все обработанные к данному моменту слова (красная стрелка на картинке).
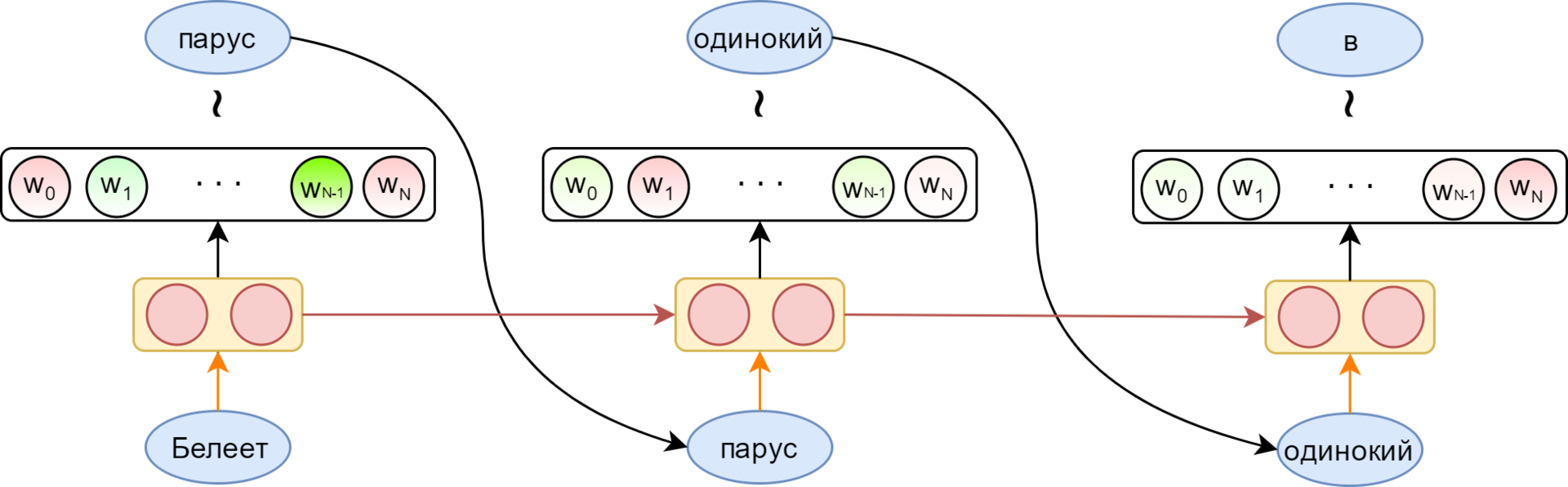
Возможность использования контекста неограниченной длины, конечно, только условная. На практике классические RNN страдают от затухания градиента — по сути, отсутствия возможности помнить контекст дальше, чем на несколько слов. Для борьбы с этим придуманы специальные ячейки с памятью. Самыми популярными являются LSTM и GRU. В дальнейшем, говоря о рекуррентном слое, я всегда буду подразумевать LSTM.
Рыжей стрелкой на картинке показано отображение слова в его эмбеддинг (embedding). Выходной слой (в простейшем случае) — полносвязный слой с размером, соответствующим размеру словаря, имеющий softmax активацию — для получения распределения вероятностей для слов словаря. Из этого распределения можно сэмплировать следующее слово (или просто брать максимально вероятное).
Уже по картинке виден минус такого слоя: его размер. При словаре в несколько сотен тысяч слов его он легко может перестать влезать на видеокарту, а для его обучения требуются огромные корпуса текстов. Это очень наглядно демонстрирует картинка из блога torch:
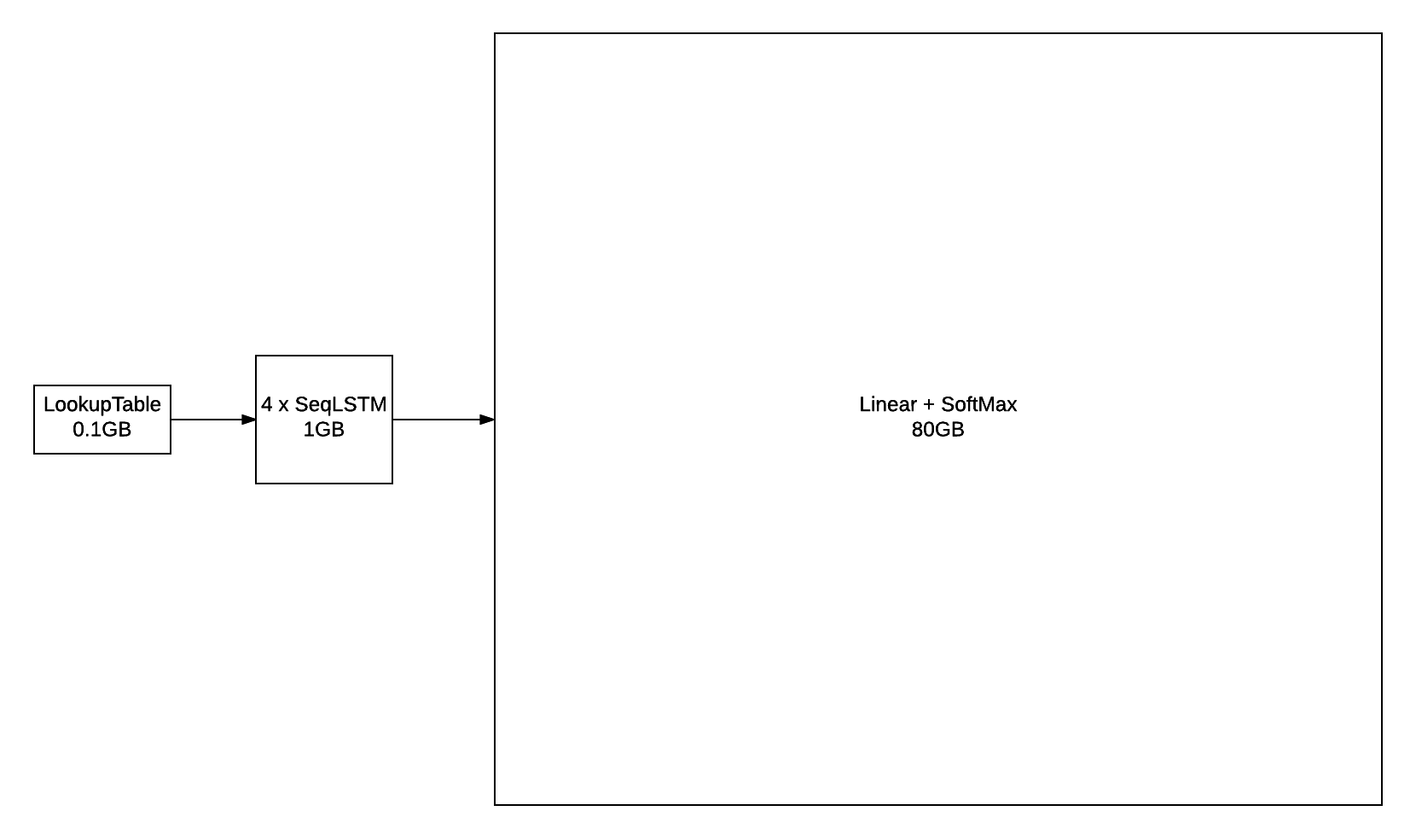
Для борьбы с этим было придумано весьма большое количество различных приемов. Наиболее популярными можно назвать иерархический softmax и noise contrastive estimation. Подробно про эти и другие методы стоит почитать в отличной статье Sebastian Ruder.
 и предсказанным вектором
и предсказанным вектором  записывается как
записывается как  . Она показывает близость распределений, задаваемый и .
. Она показывает близость распределений, задаваемый и .
При вычислении кросс-энтропии для многоклассовой классификации — это вероятность
— это вероятность  -ого класса, а — вектор, полученный с one-hot-encoding (т.е. битовый вектор, в котором единственная единица стоит в позиции, соответствующей номеру класса). Тогда
-ого класса, а — вектор, полученный с one-hot-encoding (т.е. битовый вектор, в котором единственная единица стоит в позиции, соответствующей номеру класса). Тогда  при некотором
при некотором  .
.
Кросс-энтропийные потери целого предложения получаются усреднением значений по всем словам. Их можно записать так:
получаются усреднением значений по всем словам. Их можно записать так:  . Видно, что это выражение соответствует тому, чего мы и хотим достичь: вероятность реального предложения из языка должна быть как можно выше.
. Видно, что это выражение соответствует тому, чего мы и хотим достичь: вероятность реального предложения из языка должна быть как можно выше.
Кроме этого, уже специфичной для языкового моделирования метрикой является перплексия (perplexity):
 .
.
Чтобы понять её смысл, посмотрим на модель, предсказывающую слова из словаря равновероятно вне зависимости от контекста. Для неё , где N — размер словаря, а перплексия будет равна размеру словаря — N. Конечно, это совершенно глупая модель, но оглядываясь на неё, можно трактовать перплексию реальных моделей как уровень неоднозначности генерации слова.
, где N — размер словаря, а перплексия будет равна размеру словаря — N. Конечно, это совершенно глупая модель, но оглядываясь на неё, можно трактовать перплексию реальных моделей как уровень неоднозначности генерации слова.
Скажем, в модели с перплексией 100 выбор следующего слова также неоднозначен, как выбор из равномерного распределения среди 100 слов. И если такой перплексии удалось достичь на словаре в 100 000, получается, что удалось сократить эту неоднозначность на три порядка по сравнению с “глупой” моделью.
Исходя из этих предпосылок, мы начали с относительно простой модели, в общих чертах повторяющей ту, что изображена на картинке выше. В роли желтого прямоугольника с неё выступали два слоя LSTM и следующий за ними полносвязный слой.
Решение ограничить размер выходного слоя кажется вполне рабочим. Естественно, словарь надо ограничивать по частотности — скажем, взятием пятидесяти тысяч самых частотных слов. Но тут возникает ещё вопрос: какую архитектуру рекуррентной сети лучше выбрать.
Очевидных варианта тут два: использовать many-to-many вариант (для каждого слова пытаться предсказать следующее) или же many-to-one (предсказывать слово по последовательности предшествующих слов).
Чтобы лучше понимать суть проблемы, посмотрим на картинку:
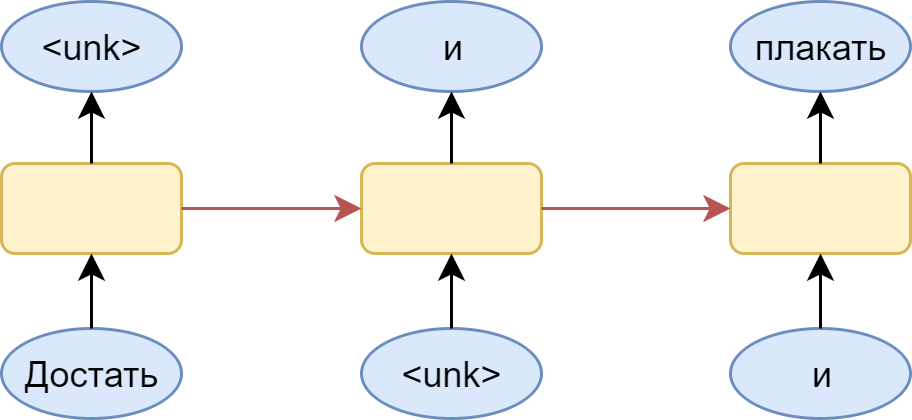
Здесь изображен many-to-many вариант со словарем, в котором не нашлось места слову “чернил”. Логичным шагом является подстановка вместо него специального токена <unk> — незнакомое слово. Проблема в том, что модель радостно выучивает, что вслед за любым словом может идти незнакомое слово. В итоге, выдаваемое ею распределение оказывается смещено в сторону именно этого незнакомого слова. Конечно, это легко решается: нужно всего лишь сэмплировать из распределение без этого токена, но всё равно остается ощущение, что полученная модель несколько кривовата.
Альтернативным вариантом является использование many-to-one архитектуры:
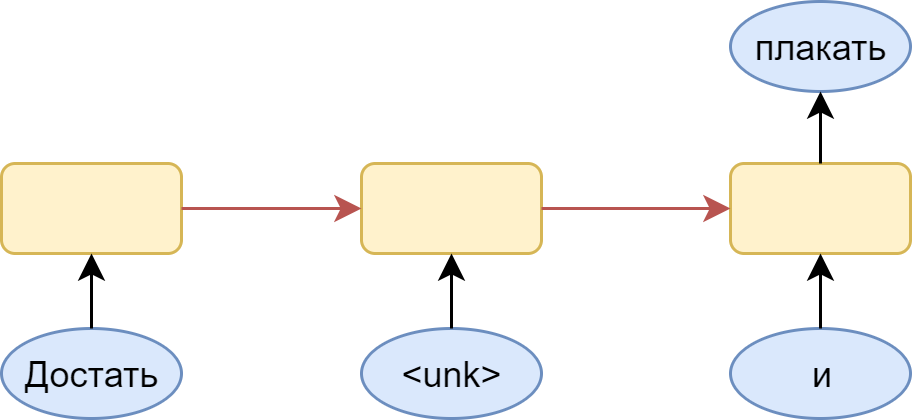
При этом приходится нарезать всевозможные цепочки слов из обучающей выборки — что приведет к заметному её разбуханию. Зато все цепочки, для которых следующее слов — неизвестное, мы сможем просто пропускать, полностью решая проблему с частым предсказанием <unk> токена.
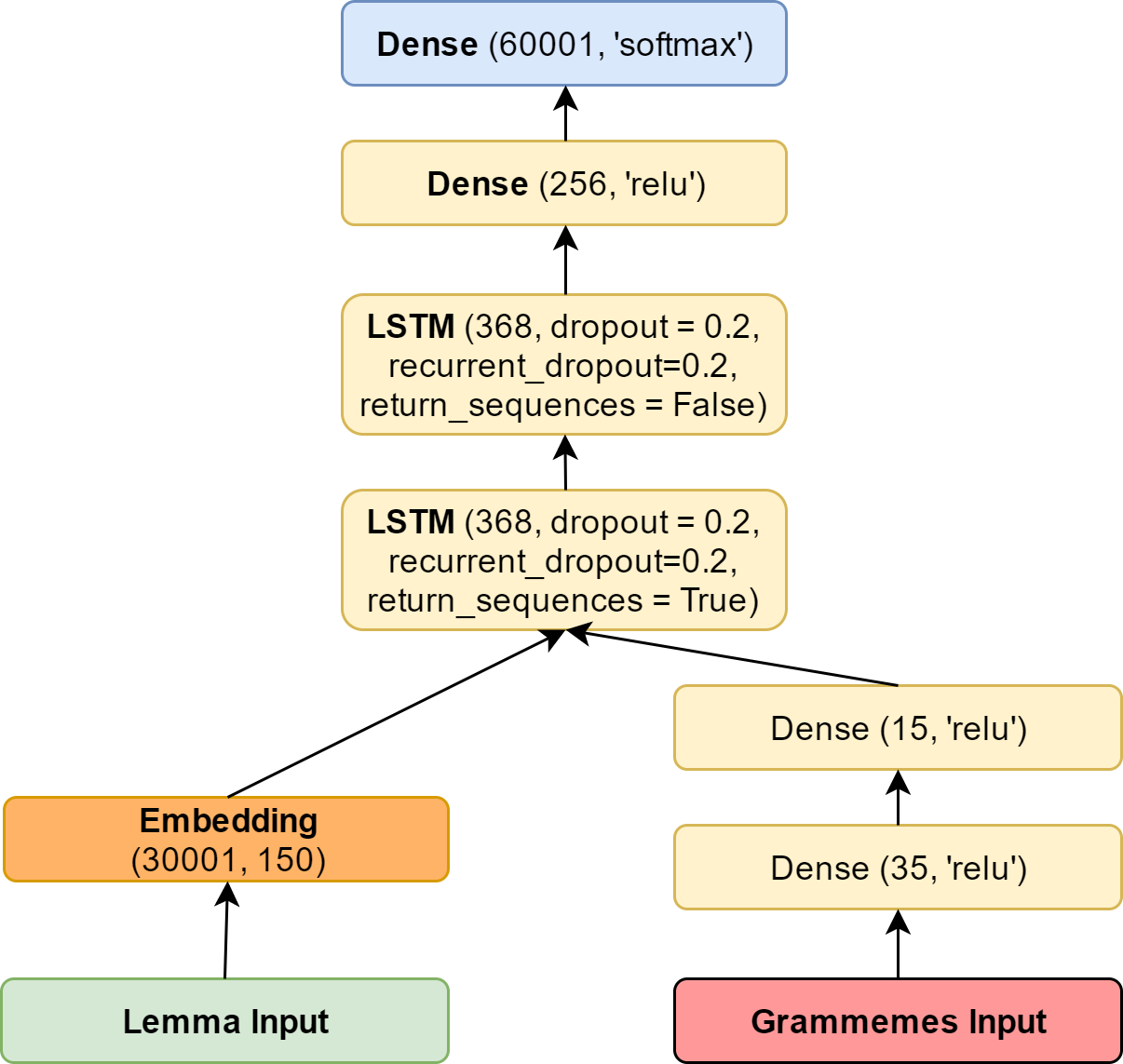
Такая модель имела у нас следующие параметры (в терминах библиотеки keras):

Как видно, в неё включено 60000 + 1 слово: плюс первый токен это тот самый <unk>.
Проще всего повторить её можно небольшой модификацией примера. Основное её отличие в том, что пример демонстрирует посимвольную генерацию текста, а вышеописанный вариант строится на пословной генерации.
Полученная модель действительно что-то генерирует, но даже грамматическая согласованность получающихся предложений зачастую не впечатляет (про смысловую нагрузку и говорить нечего). Логичным следующим шагом является использование предобученных эмбеддингов для слов. Их добавление упрощает обучение модели, да и связи между словами, выученные на большом корпусе, могут придать осмысленность генерируемому тексту.
Основная проблема: для русского (в отличие от, например, английского) сложно найти хорошие словоформенных эмбеддингов. С имеющимися результат стал даже хуже.
Попробуем пошаманить немного с моделью. Недостаток сети, судя по всему — в слишком большом количестве параметров. Сеть просто-напросто не дообучается. Чтобы исправить это, следует поработать с входным и выходным слоями — самыми тяжелыми элементами модели.
Вместо того, чтобы представлять слово одним индексом в высокоразмерном пространстве, добавим морфологическую разметку:
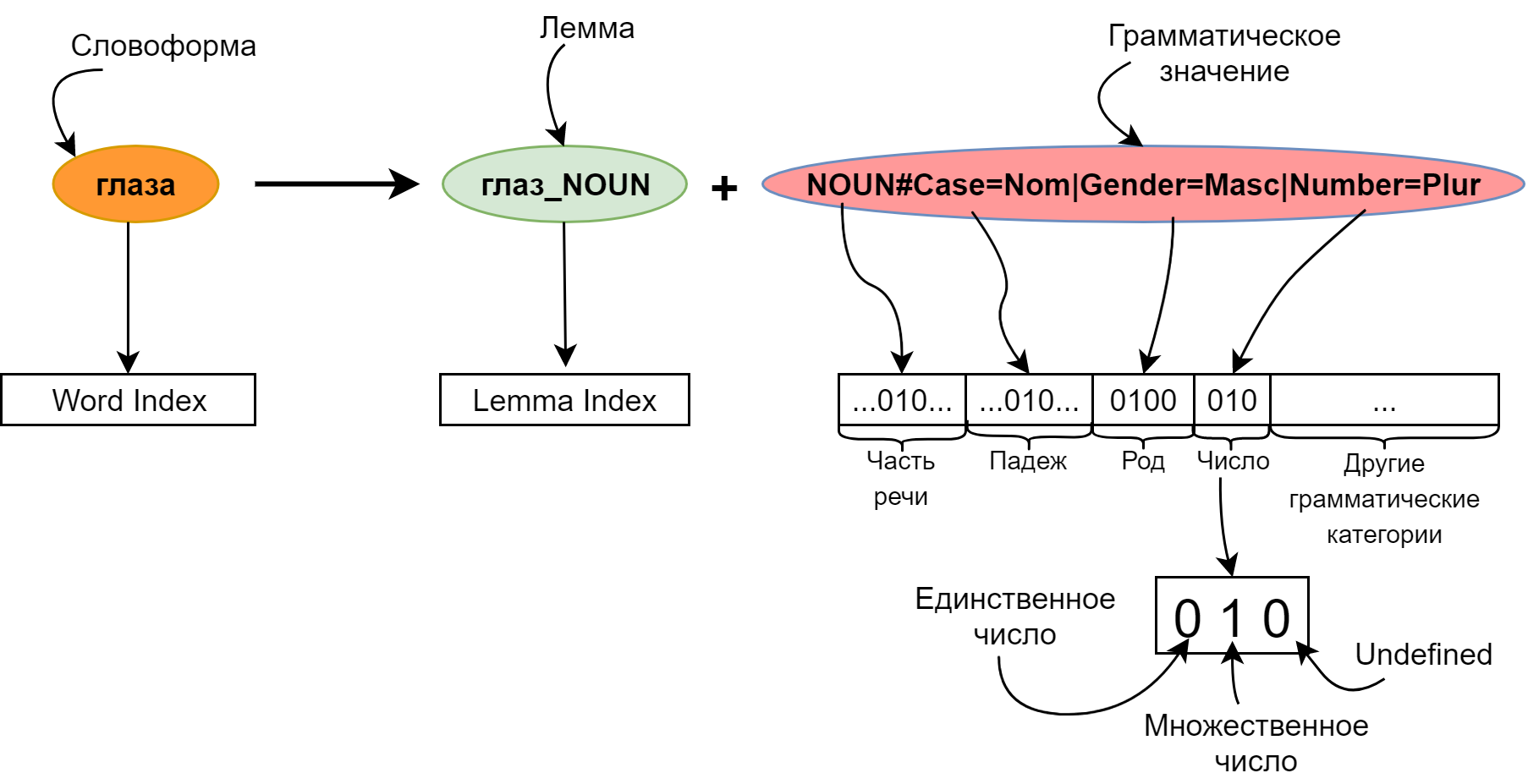
Каждое слово будем описывать парой: его лемма и грамматическое значение. Использование лемм вместо словоформ позволяет очень сильно сократить размер эмбеддингов: первым тридцати тысячам лемм соответствует несколько сотен тысяч различных слов. Таким образом, серьёзно уменьшив входной слой, мы ещё и увеличили словарный запас нашей модели.
Как видно из рисунка, лемма имеет приписанную к ней часть речи. Это сделано для того, чтобы можно было использовать уже предобученные эмбеддинги для лемм (например, от RusVectores). С другой стороны, эмбеддинги для тридцати тысяч лемм вполне можно обучить и с нуля, инициализируя их случайно.
Грамматическое значение мы представляли в формате Universal Dependencies, благо у меня как раз была под рукой модель, обученная для Диалога-2017.
При подаче грамматического значения на вход модели оно переводится в битовую маску: для каждой грамматической категории выделяются позиции по числу граммем в этой категории — плюс одна позиция для отсутствия данной категории в грамматическом значении (Undefined). Битовые вектора для всех категорий склеиваются в один большой вектор.
Вообще говоря, грамматическое значение можно было бы, так же как лемму, представлять индексом и обучать для него эмбеддинг. Но битовой маской сеть показала более высокое качество.
Этот битовый вектор можно, конечно, подавать в LSTM непосредственно, но лучше пропускать его предварительно через один или два полносвязных слоя для сокращения размерности и, одновременно — обнаружения связей между комбинациями граммем.
Эта проблема легко исправляется двумя способами. Честный путь — сэмплировать именно слово из действительно реализуемых пар лемма + грамматическое значение (вероятностью этого слова, конечно, будет произведение вероятностей леммы и грамматического значения). Более быстрый альтернативный способ — это выбирать наиболее вероятное грамматическое значение среди возможных для сэмплированной леммы.
Кроме того, softmax-слой можно было заменить иерархическим softmax’ом или вообще утащить реализацию noise contrastive estimation из tensorflow. Но нам, с нашим размером словаря, оказалось достаточно и обыкновенного softmax. По крайней мере, вышеперечисленные ухищрения не принесли значительного прироста качества модели.
Каждая строка рассматривалась как самостоятельная — таким образом мы боролись с тем, что соседние строки зачастую слабо связаны по смыслу (особенно на stihi.ru). Конечно, можно обучаться сразу на полном стихотворении, и это могло дать улучшение качества модели. Но мы решили, что перед нами стоит задача построить сеть, которая умеет писать грамматически связный текст, а для такой цели обучаться лишь на строках вполне достаточно.
При обучении ко всем строкам добавлялся завершающий символ , а порядок слов в строках инвертировался. Разворачивать предложения нужно для упрощения рифмовки слов при генерации. Завершающий же символ нужен, чтобы именно с него начинать генерацию предложения.
Кроме всего прочего, для простоты мы выбрасывали все знаки препинания из текстов. Это было сделано потому, что сеть заметно переобучалась под запятые и прочие многоточия: в выборке они ставились буквально после каждого слова. Конечно, это сильное упущение нашей модели и есть надежда исправить это в следующей версии.
Схематично предобработка текстов может быть изображена так:
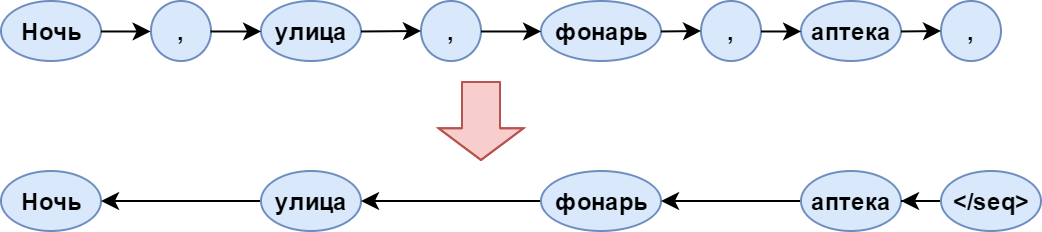
Стрелки означают направление, в котором модель читает предложение.
Метрические правила определяют последовательность ударных и безударных слогов в строке. Записываются они обычно в виде шаблона из плюсов и минусов: плюс означает ударный слог, а минусу соответствует безударный. Например, рассмотрим метрический шаблон + — + — + — + — (в котором можно заподозрить четырёхстопный хорей):
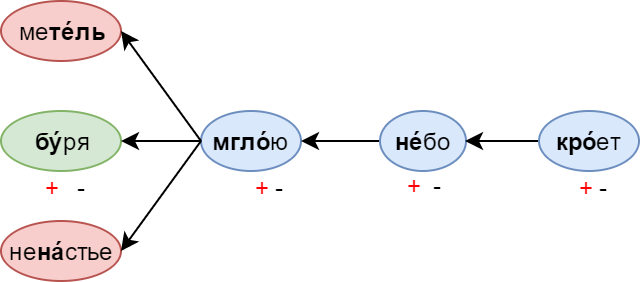
Генерация, как уже упоминалось, идёт справа налево — в направлении стрелок на картинке. Таким образом, после мглою фильтры запретят генерацию таких слов как метель (не там ударение) или ненастье (лишний слог). Если же в слове больше 2 слогов, оно проходит фильтр только тогда, когда ударный слог не попадает на “минус” в метрическом шаблоне.
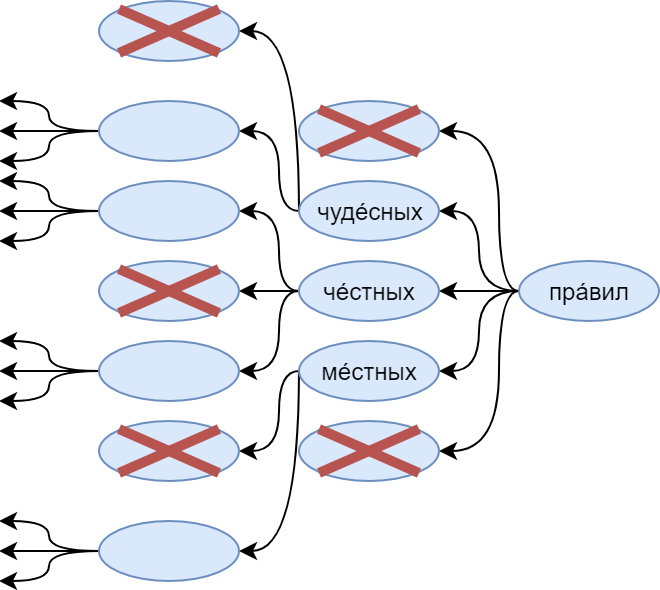
Второй же тип правил — ограничения по рифме. Именно ради них мы генерируем стихотворения задом наперед. Фильтр применяется при генерации самого первого слова в строке (которое окажется последним после разворота). Если уже была сгенерирована строка, с которой должна рифмоваться данная, этот фильтр сразу отсечёт все нерифмующиеся слова.

Также применялось дополнительное правило, запрещающее считать рифмами словоформы с одинаковой леммой.
У вас мог возникнуть вопрос: а откуда мы взяли ударения слов, и как мы определили какие слова рифмуются с какими? Для работы с ударениями мы взяли большой словарь и обучили на этом словаре классификатор, чтобы предсказывать ударения незнакомых слов (история, заслуживающая отдельной статьи). Рифмовка же определяется несложной эвристикой на основе расположения ударного слога и его буквенного состава.
Итого, входные параметры генератора — языковая модель, метрический шаблон, шаблон рифмы, N в лучевом поиске, параметры эвристики рифмовки. На выходе же имеем готовое стихотворение. В качестве языковой модели в этом же генераторе можно использовать и N-граммную модель. Система фильтров легко кастомизируется и дополняется.
Что будет это прожито
Не суждено кружить в пути
Почувствовав боль бомжика
Затерялся где то на аллее
Где же ты мое воспоминанье
Я люблю тебя мои родные
Сколько лжи предательства и лести
Ничего другого и не надо
За грехи свои голосовые
Скучаю за твоим окном
И нежными эфирами
Люблю тебя своим теплом
Тебя стенографируя
Пост был написан совместно с Гусевым Ильёй. В проекте также принимали участие Ивашковская Елена, Карацапова Надежда и Матавина Полина.
Работа над генератором была проделана в рамках курса “Интеллектуальные системы” кафедры Компьютерной лингвистики ФИВТ МФТИ. Хотелось бы поблагодарить автора курса, Константина Анисимовича, за советы, которые он давал в процессе.
Большое спасибо atwice за помощь в вычитке статьи.
Я люблю тебя моя невеста
Белый иней на твоих ресницах
Поцелуй на теле бессловесном
Когда-то в школе мне казалось, что писать стихи просто: нужно всего лишь расставлять слова в нужном порядке и подбирать подходящую рифму. Следы этих галлюцинаций (или иллюзий, я их не различаю) встретили вас в эпиграфе. Только это стихотворение, конечно, не результат моего тогдашнего творчества, а продукт обученной по такому же принципу нейронной сети.
Вернее, нейронная сеть нужна лишь для первого этапа — расстановки слов в правильном порядке. С рифмовкой справляются правила, применяемые поверх предсказаний нейронной сети. Хотите узнать подробнее, как мы это реализовывали? Тогда добро пожаловать под кат.
Языковые модели
Определение
Начнем с языковой модели. На Хабре я встречал не слишком-то много статей про них — не лишним будет напомнить, что это за зверь.Языковые модели определяют вероятность появления последовательности слов
в данном языке: . Перейдём от этой страшной вероятности к произведению условных вероятностей слова от уже прочитанного контекста:.В жизни эти условные вероятности показывают, какое слово мы ожидаем увидеть дальше. Посмотрим, например, на всем известные слова из Пушкина:
N-граммные языковые модели
Кажется, самым простым способом построить такую модель является использование N-граммной статистики. В этом случае мы делаем аппроксимацию вероятности — отбрасывая слишком далекие слова, как не влияющие на вероятность появления данного.Такая модель легко реализуется с помощью Counter’ов на Python — и оказывается весьма тяжелой и при этом не слишком вариативной. Одна из самых заметных её проблем — недостаточность статистики: большая часть 5-грамм слов, в том числе и допустимых языком, просто не встретится в сколько-то ни было большом корпусе.
Для решения такой проблемы используют обычно сглаживание Kneser–Ney или Katz’s backing-off. За более подробной информацией про методы сглаживания N-грамм стоит обратиться к известной книге Кристофера Маннинга “Foundations of Statistical Natural Language Processing”.
Хочу заметить, что 5-граммы слов я назвал не просто так: именно их (со сглаживанием, конечно) Google демонстрирует в статье “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling” — и показывает результаты, весьма сопоставимые с результатами у рекуррентных нейронных сетей — о которых, собственно, и пойдет далее речь.
Нейросетевые языковые модели
Преимущество рекуррентных нейронных сетей — в возможности использовать неограниченно длинный контекст. Вместе с каждым словом, поступающим на вход рекуррентной ячейки, в неё приходит вектор, представляющий всю предыдущую историю — все обработанные к данному моменту слова (красная стрелка на картинке).
Рыжей стрелкой на картинке показано отображение слова в его эмбеддинг (embedding). Выходной слой (в простейшем случае) — полносвязный слой с размером, соответствующим размеру словаря, имеющий softmax активацию — для получения распределения вероятностей для слов словаря. Из этого распределения можно сэмплировать следующее слово (или просто брать максимально вероятное).
Уже по картинке виден минус такого слоя: его размер. При словаре в несколько сотен тысяч слов его он легко может перестать влезать на видеокарту, а для его обучения требуются огромные корпуса текстов. Это очень наглядно демонстрирует картинка из блога torch:
Оценивание языковой модели
Более-менее стандартной функцией потерь, оптимизируемой при многоклассовой классификации, является кросс-энтропийная (cross entropy) функция потерь. Вообще, кросс-энтропия между вектором и предсказанным вектором записывается как . Она показывает близость распределений, задаваемый и .При вычислении кросс-энтропии для многоклассовой классификации
— это вероятность -ого класса, а — вектор, полученный с one-hot-encoding (т.е. битовый вектор, в котором единственная единица стоит в позиции, соответствующей номеру класса). Тогда при некотором .Кросс-энтропийные потери целого предложения
получаются усреднением значений по всем словам. Их можно записать так: . Видно, что это выражение соответствует тому, чего мы и хотим достичь: вероятность реального предложения из языка должна быть как можно выше.Кроме этого, уже специфичной для языкового моделирования метрикой является перплексия (perplexity):
.Чтобы понять её смысл, посмотрим на модель, предсказывающую слова из словаря равновероятно вне зависимости от контекста. Для неё
, где N — размер словаря, а перплексия будет равна размеру словаря — N. Конечно, это совершенно глупая модель, но оглядываясь на неё, можно трактовать перплексию реальных моделей как уровень неоднозначности генерации слова.Скажем, в модели с перплексией 100 выбор следующего слова также неоднозначен, как выбор из равномерного распределения среди 100 слов. И если такой перплексии удалось достичь на словаре в 100 000, получается, что удалось сократить эту неоднозначность на три порядка по сравнению с “глупой” моделью.
Реализация языковой модели для генерации стихов
Построение архитектуры сети
Вспомним теперь, что для нашей задачи языковая модель нужна для выбора наиболее подходящего следующего слова по уже сгенерированной последовательности. А из этого следует, что при предсказании никогда не встретится незнакомых слов (ну откуда им взяться). Поэтому число слов в словаре остается целиком в нашей власти, что позволяет регулировать размер получающейся модели. Таким образом, пришлось забыть о таких достижениях человечества, как символьные эмбеддинги для представления слов (почитать про них можно, например, здесь).Исходя из этих предпосылок, мы начали с относительно простой модели, в общих чертах повторяющей ту, что изображена на картинке выше. В роли желтого прямоугольника с неё выступали два слоя LSTM и следующий за ними полносвязный слой.
Решение ограничить размер выходного слоя кажется вполне рабочим. Естественно, словарь надо ограничивать по частотности — скажем, взятием пятидесяти тысяч самых частотных слов. Но тут возникает ещё вопрос: какую архитектуру рекуррентной сети лучше выбрать.
Очевидных варианта тут два: использовать many-to-many вариант (для каждого слова пытаться предсказать следующее) или же many-to-one (предсказывать слово по последовательности предшествующих слов).
Чтобы лучше понимать суть проблемы, посмотрим на картинку:
Альтернативным вариантом является использование many-to-one архитектуры:
Такая модель имела у нас следующие параметры (в терминах библиотеки keras):
Проще всего повторить её можно небольшой модификацией примера. Основное её отличие в том, что пример демонстрирует посимвольную генерацию текста, а вышеописанный вариант строится на пословной генерации.
Полученная модель действительно что-то генерирует, но даже грамматическая согласованность получающихся предложений зачастую не впечатляет (про смысловую нагрузку и говорить нечего). Логичным следующим шагом является использование предобученных эмбеддингов для слов. Их добавление упрощает обучение модели, да и связи между словами, выученные на большом корпусе, могут придать осмысленность генерируемому тексту.
Основная проблема: для русского (в отличие от, например, английского) сложно найти хорошие словоформенных эмбеддингов. С имеющимися результат стал даже хуже.
Попробуем пошаманить немного с моделью. Недостаток сети, судя по всему — в слишком большом количестве параметров. Сеть просто-напросто не дообучается. Чтобы исправить это, следует поработать с входным и выходным слоями — самыми тяжелыми элементами модели.
Доработка входного слоя
Очевидно, имеет смысл сократить размерность входного слоя. Этого можно добиться, просто уменьшив размерность словоформенных эмебедингов — но интереснее пойти другим путём.Вместо того, чтобы представлять слово одним индексом в высокоразмерном пространстве, добавим морфологическую разметку:
Как видно из рисунка, лемма имеет приписанную к ней часть речи. Это сделано для того, чтобы можно было использовать уже предобученные эмбеддинги для лемм (например, от RusVectores). С другой стороны, эмбеддинги для тридцати тысяч лемм вполне можно обучить и с нуля, инициализируя их случайно.
Грамматическое значение мы представляли в формате Universal Dependencies, благо у меня как раз была под рукой модель, обученная для Диалога-2017.
При подаче грамматического значения на вход модели оно переводится в битовую маску: для каждой грамматической категории выделяются позиции по числу граммем в этой категории — плюс одна позиция для отсутствия данной категории в грамматическом значении (Undefined). Битовые вектора для всех категорий склеиваются в один большой вектор.
Вообще говоря, грамматическое значение можно было бы, так же как лемму, представлять индексом и обучать для него эмбеддинг. Но битовой маской сеть показала более высокое качество.
Этот битовый вектор можно, конечно, подавать в LSTM непосредственно, но лучше пропускать его предварительно через один или два полносвязных слоя для сокращения размерности и, одновременно — обнаружения связей между комбинациями граммем.
Доработка выходного слоя
Вместо индекса слова можно предсказывать всё те же лемму и грамматическое значение по отдельности. После этого можно сэмплировать лемму из полученного распределения и ставить её в форму с наиболее вероятным грамматическим значением. Небольшой минус такого подхода в том, что невозможно гарантировать наличие такого грамматического значения у данной леммы.Эта проблема легко исправляется двумя способами. Честный путь — сэмплировать именно слово из действительно реализуемых пар лемма + грамматическое значение (вероятностью этого слова, конечно, будет произведение вероятностей леммы и грамматического значения). Более быстрый альтернативный способ — это выбирать наиболее вероятное грамматическое значение среди возможных для сэмплированной леммы.
Кроме того, softmax-слой можно было заменить иерархическим softmax’ом или вообще утащить реализацию noise contrastive estimation из tensorflow. Но нам, с нашим размером словаря, оказалось достаточно и обыкновенного softmax. По крайней мере, вышеперечисленные ухищрения не принесли значительного прироста качества модели.
Итоговая модель
В итоге у нас получилась следующая модель: Обучающие данные
До сих пор мы никак не обсудили важный вопрос — на чём учимся. Для обучения мы взяли большой кусок stihi.ru и добавили к нему морфологическую разметку. После этого отобрали длинные строки (не меньше пяти слов) и обучались на них.Каждая строка рассматривалась как самостоятельная — таким образом мы боролись с тем, что соседние строки зачастую слабо связаны по смыслу (особенно на stihi.ru). Конечно, можно обучаться сразу на полном стихотворении, и это могло дать улучшение качества модели. Но мы решили, что перед нами стоит задача построить сеть, которая умеет писать грамматически связный текст, а для такой цели обучаться лишь на строках вполне достаточно.
При обучении ко всем строкам добавлялся завершающий символ , а порядок слов в строках инвертировался. Разворачивать предложения нужно для упрощения рифмовки слов при генерации. Завершающий же символ нужен, чтобы именно с него начинать генерацию предложения.
Кроме всего прочего, для простоты мы выбрасывали все знаки препинания из текстов. Это было сделано потому, что сеть заметно переобучалась под запятые и прочие многоточия: в выборке они ставились буквально после каждого слова. Конечно, это сильное упущение нашей модели и есть надежда исправить это в следующей версии.
Схематично предобработка текстов может быть изображена так:
Реализация генератора
Правила-фильтры
Перейдём, наконец-то, к генератору поэзии. Мы начали с того, что языковая модель нужна только для построения гипотез о следующем слове. Для генератора необходимы правила, по которым из последовательности слов будут строиться стихотворения. Такие правила работают как фильтры языковой модели: из всех возможных вариантов следующего слова остаются только те, которые подходят — в нашем случае по метру и рифмовке.Метрические правила определяют последовательность ударных и безударных слогов в строке. Записываются они обычно в виде шаблона из плюсов и минусов: плюс означает ударный слог, а минусу соответствует безударный. Например, рассмотрим метрический шаблон + — + — + — + — (в котором можно заподозрить четырёхстопный хорей):
Второй же тип правил — ограничения по рифме. Именно ради них мы генерируем стихотворения задом наперед. Фильтр применяется при генерации самого первого слова в строке (которое окажется последним после разворота). Если уже была сгенерирована строка, с которой должна рифмоваться данная, этот фильтр сразу отсечёт все нерифмующиеся слова.
У вас мог возникнуть вопрос: а откуда мы взяли ударения слов, и как мы определили какие слова рифмуются с какими? Для работы с ударениями мы взяли большой словарь и обучили на этом словаре классификатор, чтобы предсказывать ударения незнакомых слов (история, заслуживающая отдельной статьи). Рифмовка же определяется несложной эвристикой на основе расположения ударного слога и его буквенного состава.
Лучевой поиск
В результате работы фильтров вполне могло не остаться ни одного слова. Для решения этой проблемы мы делаем лучевой поиск (beam search), выбирая на каждом шаге вместо одного сразу N путей с наивысшими вероятностями. Примеры стихов
Так толку мне теперь груститьЧто будет это прожито
Не суждено кружить в пути
Почувствовав боль бомжика
Затерялся где то на аллее
Где же ты мое воспоминанье
Я люблю тебя мои родные
Сколько лжи предательства и лести
Ничего другого и не надо
За грехи свои голосовые
Скучаю за твоим окном
И нежными эфирами
Люблю тебя своим теплом
Тебя стенографируя
Ссылки
- Репозиторий
- Пакет в pypi
- Паблик в VK со стихами
- Модель и словари, необходимые для её работы
- Оксфордский курс NLP, подготовленный при участии DeepMind
- One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
- Exploring the Limits of Language Modeling
- Character-Aware Neural Language Models
Пост был написан совместно с Гусевым Ильёй. В проекте также принимали участие Ивашковская Елена, Карацапова Надежда и Матавина Полина.
Работа над генератором была проделана в рамках курса “Интеллектуальные системы” кафедры Компьютерной лингвистики ФИВТ МФТИ. Хотелось бы поблагодарить автора курса, Константина Анисимовича, за советы, которые он давал в процессе.
Большое спасибо atwice за помощь в вычитке статьи.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru