Artisto: опыт запуска нейросетей в production
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-07-31 17:01
нейросети новости, техническое зрение, машинное обучение python, архитектура нейронных сетей

Эдуард Тянтов (Mail.ru Group)
Меня зовут Эдуард Тянтов, я занимаюсь машинным обучением в компании Mail.ru Group. Я расскажу про приложение стилизации видео с помощью нейронных сетей Artisto, про технологию, которая лежит в основе этого приложения.Давайте я дам пару фактов о нашем приложении:
- 1-е мобильное приложение стилизации видео в мире;
- Уникальная технология стабилизации видео;
- Приложение с технологией разработаны за 1 месяц.
Во-первых, это самое первое в мире приложение для стилизации видео в мире. До этого были только стартапы вроде deepart.io – компания по сей день существует и предлагает, например, сконвертировать 10 сек. видео за 100 евро. А мы всем пользователям предлагаем сделать это абсолютно бесплатно в онлайне в отличие от deepart.io, которые делают это в оффлайне.
Во-вторых, у нас уникальная технология стабилизации видео. Мы очень долго над этим работали, потому что если взять технологию для фото и попробовать применить ее для видео, возникают различные проблемы, которые сильно ухудшают качество видео. Я об этом подробно расскажу.
И третье – мы всего лишь за один месяц, с того момента как мы сели за разработку технологии и до того момента, когда приложение вышло в store‘ы. Прошел всего один месяц, что достаточно оперативно.

Поднимите руки, кто из вас в курсе сверточных нейронных сетей? Достаточно много людей, но все-таки половина, поэтому я на этом достаточно подробно остановлюсь, чтобы все могли понять, что происходит.
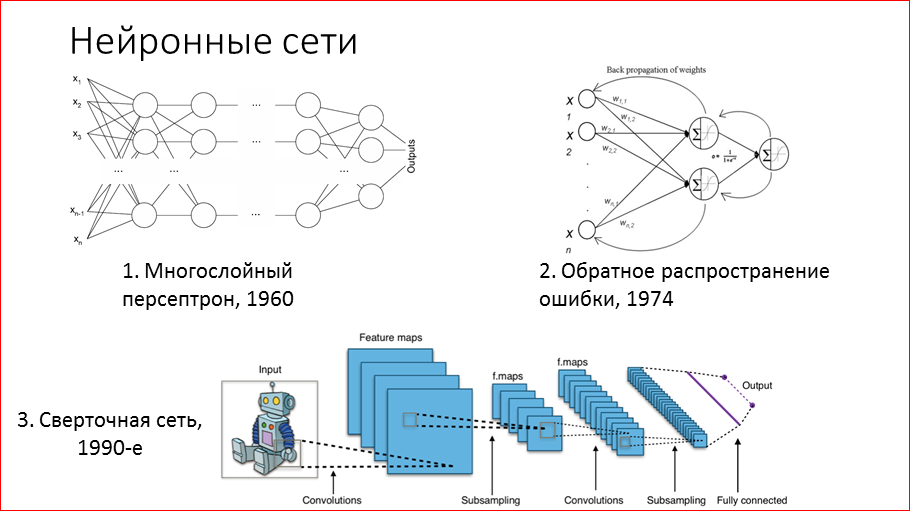
Немного истории. Ученые достаточно давно пытаются понять, как устроен наш мозг, и в 60-х годах предложили математическую модель под названием «многослойный персептрон», где нейроны объединены в слои и все нейроны связаны с соседними слоями связью «каждый с каждым». Технически обучение такой сети означает определение этих весов, и такая сеть может воспроизводить любые зависимости между данными.
В 74-ом году научились их более или менее эффективно обучать методом обратного распространения ошибки. Этот метод используется и по сей день, естественно, с некоторыми улучшениями. Его суть заключается в том, что мы берем на выходе то, что выдает наша сеть, сравниваем с тем, что должно быть, с истинным значением на выборке, и на основе этой разницы, ошибки, мы изменяем веса в последнем слое. И дальше эту процедуру мы повторяем слой за слоем, как бы распространяя ошибку из конца сети в начало. Так эти сети обучаются.
В 90-х годах Ян Ли Кун (он сейчас руководитель исследовательской лаборатории Facebook FAIR) активно работал над созданием сверточных сетей. В 98-м году он выпустил работу, где рассказал подробно, как с помощью таких сетей можно распознавать рукописные цифры на чеках, и некоторые банки в США применяли эту технологию на практике. Но тогда эта технология сверточных сетей особой популяризации не получила из-за того, что нужно было достаточно долго и трудно их обучать, и нужно было много вычислений. Прорыв случился много позже, и об этом я расскажу.
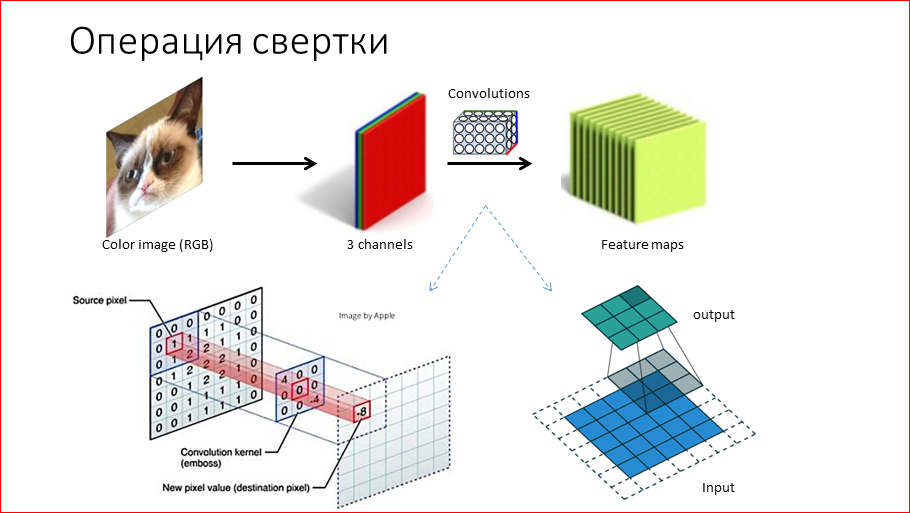
Давайте подробно обсудим, что такое сверточная сеть. Она получила свое название за счет операции свертки, как ни странно. Ее смысл заключается в следующем – мы берем изображение RGB (или можно grey scale), это 3 канала, 3 матрицы. Мы эти матрицы прогоняем через свертку. Свертка, как показано внизу на слайде – это матрица 3 х 3 в данном случае, которую мы двигаем по изображению и поэлементно умножаем веса на этой свертке на числа соответствующие и складываем, получаем соответствующие позиции, некие числа. Получается, что мы входную матрицу преобразовали в выходную. Эта выходная матрица называется feature maps. И, если рассказать, что графически кодирует свертка, она кодирует какие-то признаки на изображении. Это могут быть, например, наклонные линии. Тогда в feature map мы будем иметь информацию, где, в каких местах эта наклонная линия имеется на изображении. Естественно, в сверточных нейронных сетях этих сверток очень-очень много, тысячи, и они кодируют различные признаки. Что самое замечательно в этом всем – нам абсолютно не нужно задавать их, т.е. они в процессе обучения выучиваются сами.

Второй важный блок – это pooling или операция subsampling. Она признана сократить размерность входной матрицы, входного слоя. Как показано на рисунке, мы берем матрицу 4 х 4 и по 4 элемента берем максимальные, т.е. получаем матрицу 2 х 2. Т.о. мы существенно сокращаем, а именно в 4 раза, все последующие вычисления. Это нам также, как бонус, дает некую устойчивость к перемещению поворотов объектов на картинке, потому что в сверточных нейросетях много операций pooling. В результате к концу сети немного теряются пространственные координаты, и получается некая независимость от положения.
Если мы посмотрим, что сверточная сеть выучивает, то получится достаточно интересно. Данная сеть училась на лицах:
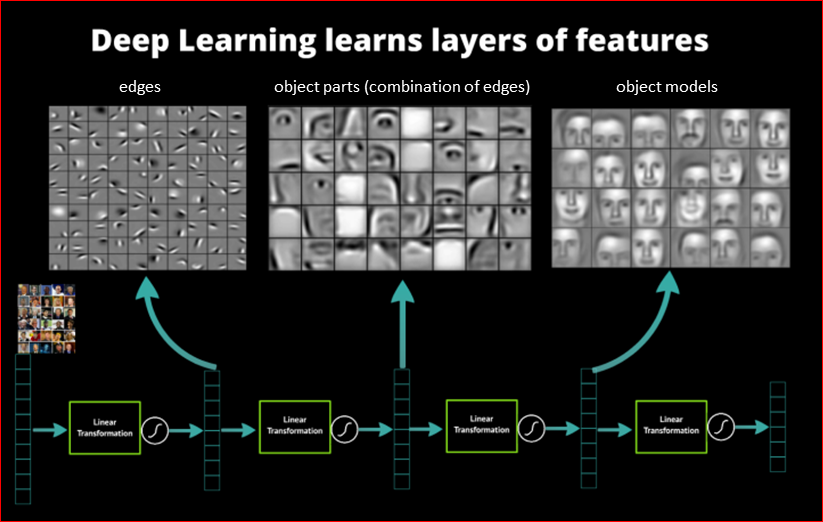
И мы можем видеть, что на первом сверточном слое нейросеть выучивает простейшие примитивы – различные градиенты, линии, часто цвета, т.е. базовые примитивы. Мы точно знаем на сегодняшний момент, что наша визуальная кора мозга – visual cortex – работает точно так же, соответственно, сеть эмулирует наш мозг.
Далее. У нас, получается, по мере движения по сети все усложняются и усложняются те признаки, которые выделяет сеть. На основе первого слоя второй слой уже распознает некие части лица – глаза, уши и т.д. И уже последний слой строит целые модели лиц. У нас получается иерархичность признаков – чем ближе к концу сети, тем сложнее объекты мы можем детектировать на основе более простых вначале.

Основной прогресс в компьютерном зрении происходил в рамках ImageNet Challenge. ImageNet – это такая база фотографий, размеченная руками, там их примерно 10 млн. Она была специально создана для того, чтобы исследователи со всего мира соревновались и прогрессировали в этом computer vision’е.
Есть популярный challenge – с 2010-го года проходят ежегодно соревнования, там много разных категорий и самая популярная – это классификация на 1000 классов изображения. Среди классов много животных, разных пород собак и т.д. В 2012-ом году впервые на этом соревновании победила сверточная сеть, ее автор Крижевский (Krizhevsky A.) смог поместить все вычисления на GPU, их достаточно много и благодаря этому, он смог обучить 5-слойную сеть. На тот момент это было существенным прорывом, как для сверточных сетей, как и для computer vision, потому что существенно сократило ошибку.
Ошибка там измеряется топ 5, т.е. сеть выдает 5 возможных категорий, что изображено на картинке, и если хоть одна совпадает, то считается успехом. Что очень интересно – ученые замерили, сколько люди ошибаются на этом challenge. Посадили людей, дали им точно так же размечать данные и выяснилось, что ошибка порядка 5%. А современные сверточные сети имеют ошибку порядка 3.5%. Это не совсем значит, что нейросети работают лучше, чем наш мозг, потому что они были заточены именно под эти тысячи классов, а люди не всегда различают породы собак, и если человека посадить и его учить этим классам, то, естественно, будет лучше, но, тем не менее, уже алгоритм очень и очень близко.

Рассмотрим популярную архитектуру. В данном случае это VGG. Это один из победителей 2014 года. Она очень популярна, а популярна потому, что последователи обученную ее выложили в сеть, и все ей могли пользоваться. Она выглядит, вроде, сложно, но на самом деле она просто блочная, каждый блок сверточный. Это несколько слоев сверток и потом операция pooling’а, т.е. уменьшения изображения. И так у нас 5 раз повторяется, у нас происходит 5 pooling’ов. В конце у нас свертки уже видят изображение 14 х 14, и количество фильтров ближе к концу возрастает. Т.е. если мы вначале имеем 32 фильтра, которые распознают примитивы, то в конце сети у нас уже есть 512 фильтров, которые распознают какие-то сложные объекты, может быть, стулья, столы, животные и т.д. Дальше в этой сети идут полносвязные блоки, которые выполняют уже на основе этих признаков чисто классификацию на эти 1000 классов.
Эту сеть предобученную используют во многих задачах, потому что эти признаки, которые выделяет сеть, можно использовать во многих задачах в computer vision‘е, в том числе для стилизации фото.
Давайте и перейдем к этой теме. Как перенести стиль на фото?

Во-первых, что мы хотим, чтобы быть предельно понятным? Мы хотим взять фотографию, в данном случае это город, и взять какой-то стиль, например, «De sterrennacht» Ван Гога и попытаться перерисовать исходную контентную картинку в этом стиле. И получить такое piece of art, как говорится. Кажется невероятным, но в современном мире это возможно. Т.е. нам не нужен уже никакой художник для этого, можно это сделать.

Немножко истории. В сентябре 2015 года Леон Гатис выпустил статью, в которой он рассказал, как это можно сделать, придумал. Единственным его недостатком было то, что этот алгоритм был достаточно медленным, и из-за этого широкого практического применения для конечного пользователя на тот момент не получил.
В марте 2016-го года выходят две статьи с идеей, как ускорить всю эту обработку, и первым из них был наш соотечественник из Сколтеха – Дмитрий Ульянов предложил, как это можно делать, первым.
И дальше через пару месяцев выходит приложение Prisma, получает оглушительный успех, и через полтора месяца запускается Vinci от Вконтакте для стилизации фото, и от нас – Artisto для стилизации исключительно видео на тот момент.
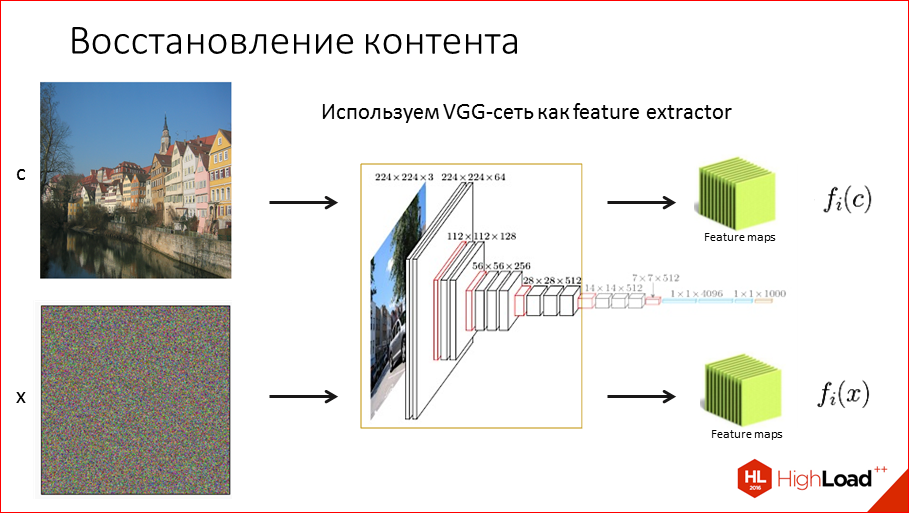
Как же все это можно провернуть? Начнем с первой статьи Artistic Style. Как нам восстановить контент? Т.е. нам надо смешать контентную картинку и стилевую каким-то образом. Для начала нам надо попробовать восстановить контент. Что мы для этого будем делать? Мы возьмем нашу VGG сеть, о которой я упоминал ранее, и будем использовать ее как feature extractor, т.е. будем рассматривать ее как способ извлечения признаков из изображения. Мы прогоняем картинку через эту сеть и получаем на выходе иерархическую информацию в этих feature maps, которая нам говорит, что расположено на этом изображении. Соответственно, можем прогнать любую другую картинку, например, шум, получить какие-то числа, эти feature maps и между собой уже их можем сравнивать, т.е. теперь мы можем численно сравнивать картинки.
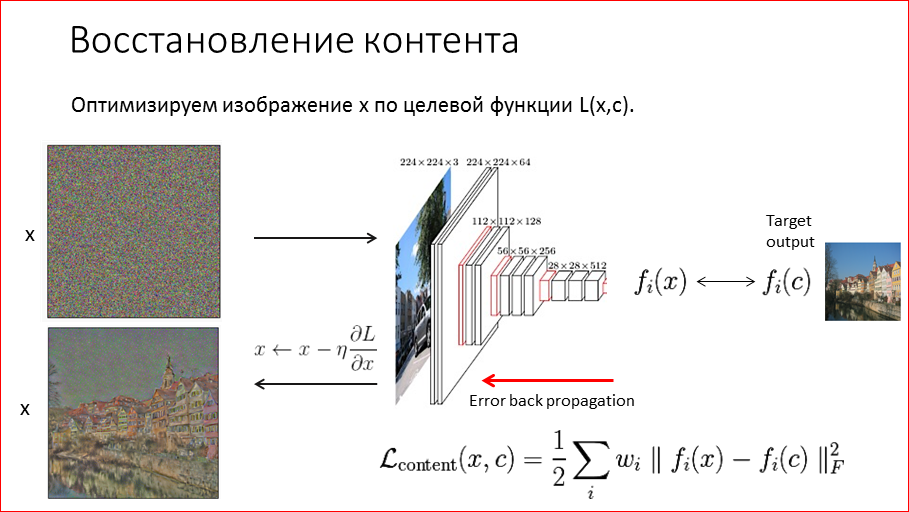
Какой алгоритм предложил Гатис. Он предложил такой оптимизационный алгоритм – мы начинаем с шума, это наш холст, на который мы пробуем нарисовать картинку, которая будет похожа на контентную. Прогоняем ее через сеть, получаем признаки и сравниваем, насколько они похожи с контентными признаками нашего целевого изображения. Замеряем ошибку. Естественно, вначале она огромная, потому что на шуме там ничего не сработало, нет никаких объектов. И эту ошибку обратным распространением ошибки – back propagation алгоритмом гоним по сети. Но сеть мы сами никак не изменяем, т.е. она у нас фиксированная, а ошибка к нам приходит в начало, в изображение. И мы заменяем на основе ошибки на выходе само изображение, т.е. перерисовываем. Так мы повторяем n итераций.

И если посмотреть спустя 1000 итераций, как происходит восстановление, то мы видим, что достаточно неплохо мы смогли с помощью этого алгоритма восстановить исходное контентное изображение. Видим, конечно, что потерялись цвета.
Если посмотреть на последние картинки, это как раз последние слои, до этого здесь был взят слой 4.2, это один из последних слоев. Если посмотреть поближе, приблизить картинку, то видно, что помимо цветов, еще и потерялись немного пространственные координаты, т.е. поплыли границы изображения.

Это произошло по понятным причинам, потому что у нас в сети идет pooling, мы изображение сжимаем-сжимаем и в конце мы знаем, что, например, там расположен дом, но мы только приблизительно понимаем, где он расположен на картинке. Если по этим слоям пытаться восстановить, то получится так неточно.
Если же, наоборот, воспользоваться ранними слоями, то уже там уже информация практически никакая не потеряна, и восстанавливается все очень хорошо. Здесь можно сообразить, что для того, чтобы смешать стиль с контентом, нам лучше пользоваться последними слоями, которые не так точно восстанавливают, потому что нам и не нужно точно восстановить картинку, нам нужно в стиле перерисовать.
Переходим к самому интересному, как же все-таки перенести стиль? И что вообще такое стиль?
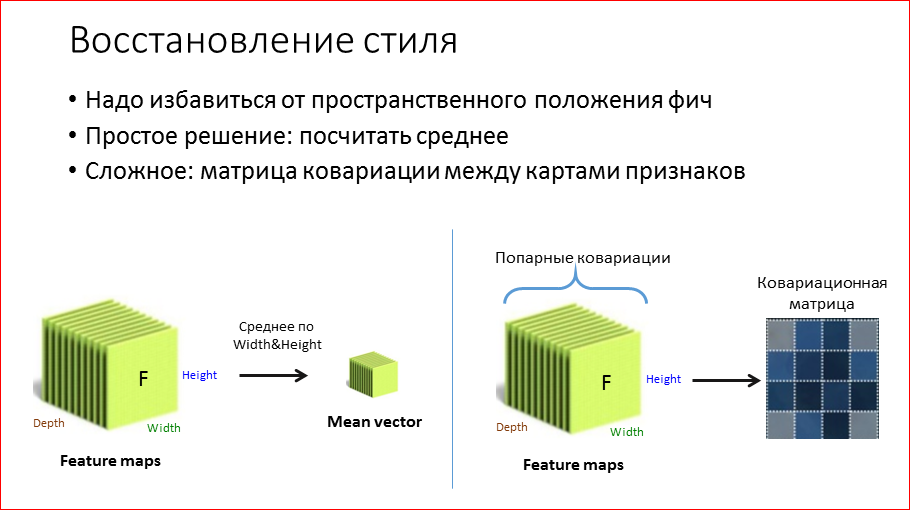
Кажется, что стиль – это такие мазки, цвета. Именно это хочется перенести. Если мы возьмем точно такой же алгоритм и попытаемся восстановить стиль, то у нас объекты, которые были на стилевом изображении, будут на тех же местах. Соответственно, первое, что нам нужно сделать и, по сути, единственное – это избавиться от пространственных координат. Естественно, если мы избавимся от координат, то мы уже как-то сможем передавать стиль.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Тут есть два варианта, как это делать. Точнее, их несколько, я расскажу простой, для понимания, и сложный.
Можно просто взять feature map. Мы зафиксировали какой-то слой, по которому мы хотим восстанавливать стиль, допустим, какое-то раннее из 2-го блока. Берем и по пространственным координатам усредняем. Т.е. получили такой вектор средних. Как это можно понять? Т.е. это реально будет восстанавливать стиль, мы сейчас это увидим. Почему это будет восстанавливать? Можно, например, предположить, что какая-то из сверток, например, кодирует признак наличия звезды, на изображении. На «De sterrennacht» у нас n звезд, допустим, 10. Если у нас в процессе оптимизации наш алгоритм нарисовал всего 2 звезды, а их там 10, то сравнение этих средних нам поможет понять, что надо дорисовать еще звезду, сделать небо более звездным.
Более сложный способ – это взять и попарно перемножить все эти feature maps между собой и получить т.н. матрицу ковариации. Это такое обобщение дисперсии на многомерный случай, т.е. в первом случае у нас было среднее, а это, можно считать, что дисперсия. И т.к. в дисперсии содержится информация о взаимосвязях между фильтрами, то чисто экспериментально оно работает лучше.

И наш алгоритм не сильно меняется, т.е. мы также фиксируем какой-то слой, с которого мы хотим восстанавливать стиль, или слои. Прогоняем нашу стилевую картинку через сеть. Получаем какой-то feature map, из него мы получаем ковариационную матрицу и то же самое проделываем с нашим холстом, с шумом и сравниваем уже не feature map, а именно эти матрицы. И точно так же прогоняем ошибку обратно. И получается неплохо.

Что мы здесь видим? Это шум в стиле Ван Гога. Цвета, мазки – все передалось.
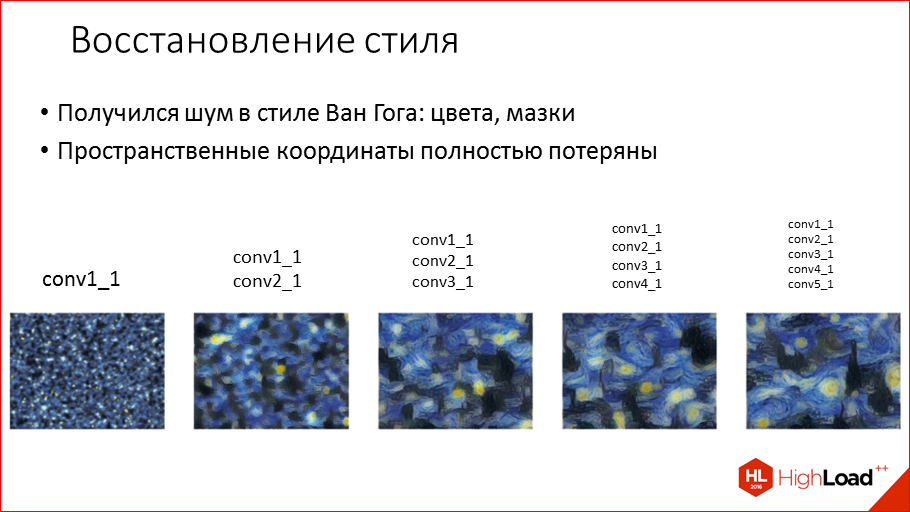
Если мы поиграемся с различными слоями, то мы увидим, что например, на 1-ом слое там еще недостаточно информации о стиле, там только цвета: желтый, синий, черный. И чем дальше мы будем добавлять слои, например, если 2-й и 3-й добавим, то там уже, в принципе, очень хорошо передается стиль. Если же мы добавим из последних слоев, которые распознают объекты, то у нас уже начнут вылезать всякие башни, изображения, но они полностью теряют координаты, конечно. Но, тем не менее, очевидно, что предпочтительно брать из первых слоев, которые передают именно сам стиль.
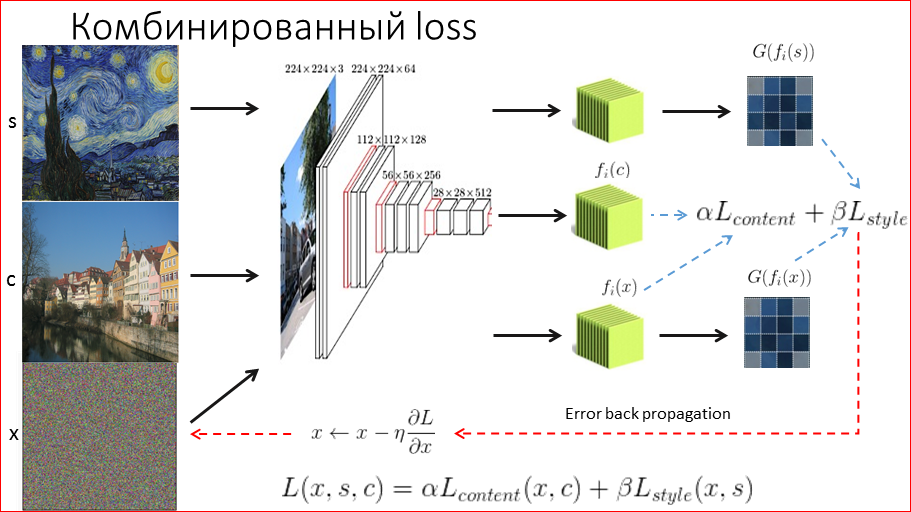
Теперь, когда мы имеем 2 технологии восстановления стиля и контента, нам бы их как-нибудь смешать, чтобы лучше смиксовать 2 этих изображения. Как мы это делаем? Опять же, фиксируем стиль, получаем из него ковариационную матрицу, запомнили, да? Берем контентное изображение, извлекаем из него feature map, фиксируем.
И теперь наш шум прогоняем, получаем и то, и другое. И в некоей пропорции мы сравниваем. Т.е. мы сравнили 2 ковариационные матрицы, 2 feature map, у нас получилась какая-то ошибка, мы ее взвешиваем с какими-то весами, допустим, мы говорим, что стиль в 10 раз важнее, чем контент, и будем надеяться, что объекты останутся на своих местах, но перерисуются в нужном нам стиле.

И, о чудо, это действительно происходит, эта картинка из статьи взбудоражила всю общественность в deep learning’е. Это был прорыв. И уже позволяет без художника стилизовать любое изображение.

Итак, если резюмировать, то нам этот алгоритм позволяет смешивать любые 2 картинки, неважно какие. Хоть 2 фотографии. Не требует никакого обучения, здесь только оптимизация, поэтому можно достаточно быстро экспериментировать, подбирать нужные параметры и, в общем, очень быстро получать какой-то результат. Код на всех популярных библиотеках для deep learning’а есть, можно выбрать любую наиболее подходящую. Но самый большой жирный минус в том, что все это очень долго вычисляется для онлайн, т.е. если на CPU это 5 минут, если на GPU современном, то это порядка 10-15 сек. Еще фото можно постараться засунуть как-то в онлайн, для видео – нет.
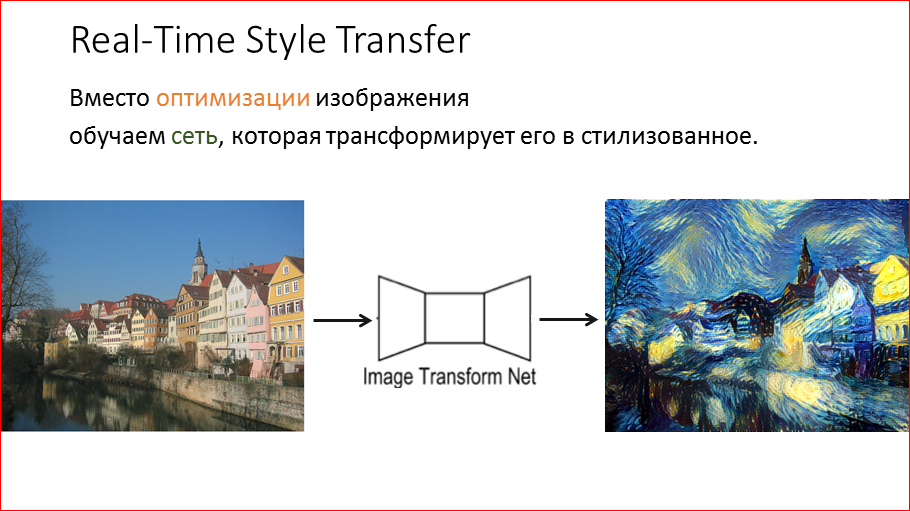
И Дмитрий Ульянов чуть позже предлагает, как можно это все сильно ускорить. Идея достаточно проста и элегантна – просто взять и научить сеть стилизовать любое изображение. Не заниматься никакой оптимизацией, а просто подал любую картинку, сеть ее как-то переваривает и выдает стилизованное изображение.
Звучит просто. Как это мы делаем?
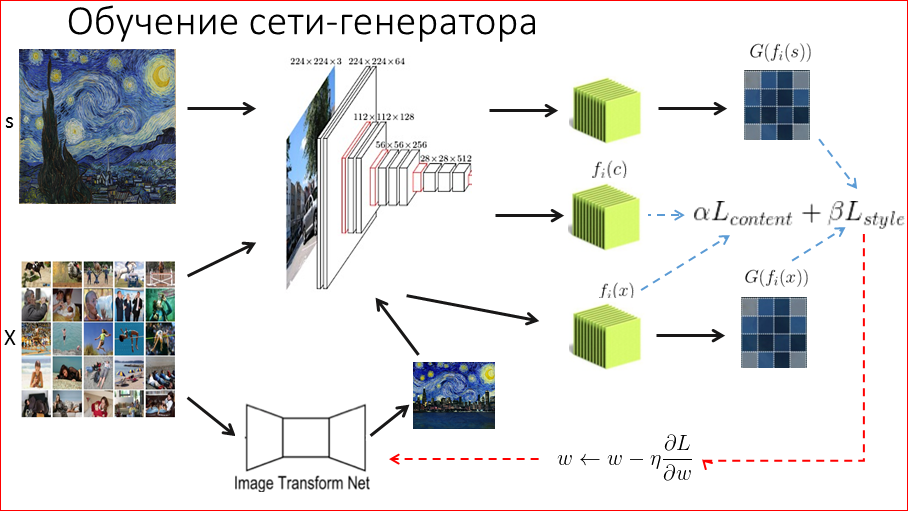
Опять же, фиксируем стилевое изображение, матрицу ковариации из него, контентное изображение и его признаки, и теперь у нас здесь отличие. Нам надо стилизовать любое изображение. Соответственно, мы берем некий dataset, мы будем обучать сеть. Мы берем dataset какой-то фотографии. Желательно для нашего приложения брать фотографии, которые реально будут загружать пользователи, а не какие-то абстрактные. Например, фотографии людей – пользователи очень любят фотографировать людей, себя, там они должны обязательно быть, чтобы сеть уметь на них конкретно отрисовывать. После этого мы берем какое-то изображение из этого dataset, прогоняем через нашу новую сеть-генератор, или трансформационную сеть, которая нам должна отстилизовать изображение. Вначале, когда мы ее инициализируем она выдает какой-то шум, но со временем она будет обучаться и выдавать какое-то стилизованное изображение. Т.к. нам надо сеть обучать, мы должны понять, насколько хорошо она стилизует. Делаем мы это точно так же – мы прогоняем это стилизованное изображения через сеть, получаем необходимые нам данные и сравниваем с тем контентом и стилем, которые мы хотим. Опять же, некоторые пропорции. И эту ошибку прогоняем обратно и уже не оптимизируем изображение, а именно обучаем саму сеть. И так мы ходим по этому dataset, и спустя десятки тысяч итераций сеть учится стилизовать изображение.

Это пример из статьи Ульянова его сети-генератора. Здесь, что интересно, на вход сети подается изображение в нескольких разрешениях, дальше прогоняется через набор сверток, и у нас получается, что сеть усредняет стилизации на разных разрешениях. Такая интересная у него идея.

И если резюмировать, то огромный плюс – это то, что требуется всего 1 прогон по обученной сети. На GPU это достаточно быстро, в десятках мсек это измеряется, в зависимости от самой сети или входного разрешения картинки. Это, естественно, не бесплатно. Мы за это платим, потому что нам под каждый стиль нужно обучать отдельную сеть, обучаются сети достаточно долго, но в данной задаче это еще приемлемо – несколько часов, потому что обычно сети, та же VGG, обучаются, например, неделю. Здесь нам для экспериментов, а их нужно будет проводить очень много, нам нужно несколько часов на современных картах. И на момент того, как мы разрабатывали, код был только от Ульянова, он был на Torch, это библиотека Facebook, она на Lua, что для специалистов по машинному обучению несколько непривычно, потому что все привыкли к Python, в основном. И тут требуется некий входной порог.
Теорию мы рассмотрели, все вроде бы здорово. Все должно получаться. В статьях отличные результаты. Давайте посмотрим, как оно работает на практике.

Но прежде чем перейти к экспериментам, я должен познакомить вас с этой девушкой, которая участвовала во всех наших экспериментах и наши нейронные сети сильно коверкали ее прекрасное лицо. Специально для этой конференции, я ее «выдернул» просто из выдачи Google по запросу «девушка». Это оказывается жена футболиста, ее зовут Хофи и она у нас натерпелась. Общая рекомендация – не использовать фотографии себя или своих близких для тестирования, потому что дальше они будут попадать в презентации, и про вас будут рассказывать на HighLoad.

Если мы возьмем этот медленный алгоритм Гатиса (т.е. мы в фазе ресерча пробовали все) и применим некоторые стили, то мы получим что-то вполне адекватное достаточно быстро.

Т.е. в принципе, отлично стилизуется, получаются какие-то красивые изображения, здорово предаются все мазки, цвета. Отлично передаются картины, ну, типа Ван Гога. Но если мы будем пытаться добиться чистых изображений, мы об этом чуть позже подробно поговорим, чтобы лицо девушки было достаточно чистое, а не все в мазках кисти, то этого уже очень тяжело добиться.
Мы очень долго пытались оптимизировать скорость работы этой сети. Нам удалось даже достичь 100 мсек на стиль, т.е. мы в процессе оптимизации как начальное приближение используем некую деградированную картинку девушки, и так получается быстрее. Для каждого стиля это надо подбирать и очень тяжело, и 100 мсек по-прежнему неприемлемо для видео. Итог: нам этот алгоритм никак не подходит.

Дальше мы возлагаем надежды на творение Ульянова – на нейросеть, которая сразу стилизует. Что мы хотим взять? Взять фотографию девушки, взять красивый мозаичный стиль и получить отличную стилизацию. Это наши ожидания. Но они разбиваются о суровую реальность.

Мы видим, что как мы ни крутим параметры, как ни стараемся, девушку либо всю мостит текстурой, либо ей подбивает глаз, либо, вообще, какие-то трещины и морщины на лице. Сколько мы ни крутили, это еще самые лучшие результаты, были и намного хуже, поверьте.

Из коробки оно не работает, т.е. не выдает красивого ничего, по-прежнему, из-за того что обучение идет несколько часов, очень трудно экспериментировать. Мы на это потратили достаточно много времени. А хороший результат получается только тогда, когда взять сеть из второй статьи – Джастина Джонсона из Стенфорда – и применить модель генератора оттуда. Она, оказывается, работает уже неплохо. Она имеет примерно такую структуру, похожа на инкодер/декодер, который применяется, в частности, для сегментации. Мы в первой половине сети так же, как VGG, у нас свертки, пулинги, и в конце мы получаем какое-то представление о том, что нарисовано на картинке, у нас достаточное, в несколько раз меньшее разрешение, а потом мы начинаем делать обратные операции, повышая разрешение, уменьшая количество фильтров, перерисовывая изображение. И на выходе мы получаем картинку.

И, оказывается, что в целом это достаточно неплохо работает, плюс пару патчей и танцев с бубнами, и получается неплохо. Такой стиль типа огненного уже сразу можно в продакшн, тут ничего не нужно, он трешовый, и все отлично.
Во-первых, нам этот алгоритм уже подходит, он выдает какие-то приемлемые результаты, он достаточно быстрый – это 1 прогон сети и, если мы хотим стилизовать видео, то мы бьем видео на кадры, их отдельно стилизуем и опять склеиваем – получаем видео. Но для видео есть некоторые аспекты, которые на фото не очень заметны, но для видео уже существенны.

Первое – это только не на лицо. У нас может быть стиль, который отлично стилизует фотографию Кремля, любые пейзажи, но фотографию человека – там опять получаются какие-то артефакты. Можно представить, как если эту девушку на видео снять, и как у нее по лицу будут «гулять» эти морщины, трещины – будет ужас. А пользователи очень любят себя фотографировать – посмотрите в Инстаграм. Соответственно, как бы ваш фильтр отлично не стилизовал пейзажи, любые фотографии, самое важное, чтобы он работал на людях. Иначе пользователи просто не будут этим пользоваться.

Вторая проблем – это рябь. Здесь я привожу видео, которое я взял у Марка Цукерберга, они сейчас тоже с этим экспериментируют, и вы можете видеть, что там достаточно сильно рябит на пустых областях – на стене, на потолке. Связано это с тем, что алгоритму, оказывается, очень выгодно в эти пустые области накладывать текстуру. И текстуру он от кадра к кадру накладывает немного по-разному, и все рябит. Выгодно ему это делать, потому что, напомню, у нас контент loss, т.е. мы контент – сравниваем последние слои, где у нас объекты. На стене объектов никаких нет. А стилевое – это ранние слои, где какая-то текстура. И нейросеть, удовлетворяя стилевой loss, лепит туда текстуры, не создавая особо никаких объектов. Поздние слои контента ничего этого не видят и, соответственно, сеть безнаказанно все мостит текстурой. Это сильно ухудшает видео. Мы с этим много боролись, с этими двумя проблемами.

Первая из наших наработок – это т.н. heatmap loss. Мы берем какой-то контентный layer, и у нас получились какие-то признаки. Мы детектим какие-то объекты. Значит, если мы возьмем все эти 512, например, фильтров просуммируем, то мы получим оценку, насколько в той или иной части картины много объектов. Если мы видим стену, она плоская, там ничего нет интересного, синий цвет, там нет никаких объектов, мы их не видим. И если мы возьмем лицо девушки, особенно ее волосы, там уже много интересных фич, последние слои много чего интересного видят. Если мы возьмем плохую стилизацию, как снизу, и она начнет лепить нам текстуру, куда нам не нужно, получается совершенно другой heatmap. Мы можем сравнивать эти тепловые карты между собой, добавить еще один loss и штрафовать сеть, чтобы она не могла эту текстуру мостить там, где нам не нужно. Мы управляем обучением сети.

Второе. Как выяснилось, разработчик машинного обучения может пару дней потратить на то, чтобы этот стиль, который нам нужен, довести до идеала, а можно взять дизайнера, взять фотошоп и начать управлять стилем путем изменения самой стилевой картинки. Т.е. мы будем менять, по сути, эти карты слоев. Здесь в данном случае, видим красивую текстуру кубов, если попробовать стилизовать, то получится очень мелкая текстура, много маленьких кубов, на видео это очень сильно моргает, и мы просто дорисовываем большие кубы, чтобы алгоритму было проще рисовать сплошные пустые области.
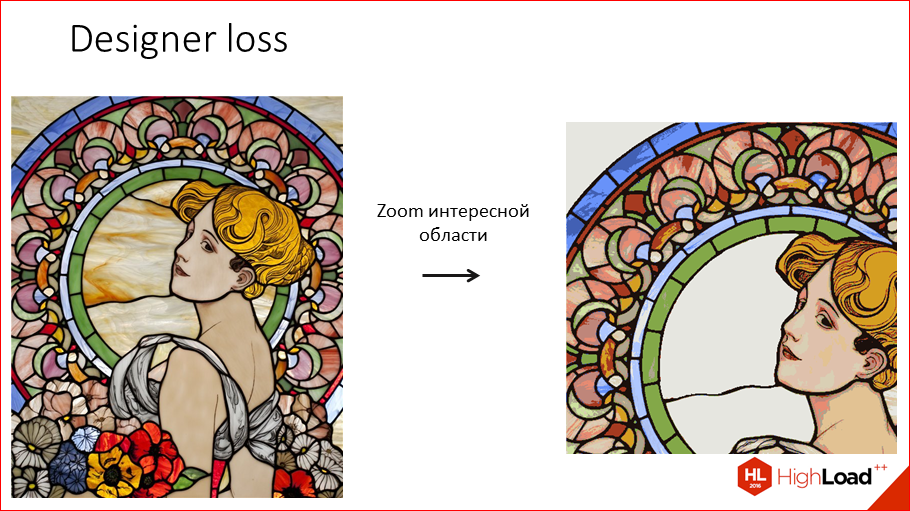
Второй вариант. У нас есть стилевое изображение, оно нам очень нравится, мы хотим стилизовать им, но там есть внизу всякие цветы, которые нам не интересны, нам интересна мозаика или сама девушка. Мы ее вырезаем, деградируем всякие ненужные нам текстуры, чтобы у нас никаких артефактов не возникало, просто однотонные цвета. Это отлично справляется со всякой рябью.

Третье – достаточно стандартный подход в машинном обучении, к нам эта идея почему-то пришла в самом конце – это при обучении менять входные данные так, чтобы сеть была устойчива к каким-то изменениям. Например, если у нас сеть распознает объекты, и у нас на картинке собака, если мы ее перевернем на 90 градусов, положим, то она все еще собака, и сети необходимо быть устойчивой к таким вещам, а в обучающем множестве просто лежачих собак может не быть, и алгоритм может ошибаться. Поэтому мы в процессе обучения переворачиваем собаку так-сяк, и она у нас выучивает, как бы, инварианты к ее положению, получается. В случае стилизации, напомню, что у нас пользователи берут свой телефон идут с ним, снимают, и у нас возникает много шума, меняется освещение. И чтобы сеть в разных освещениях не рисовала совершенно разную стилизацию и тогда картинка, чтобы не тряслась, мы в процессе обучения добавляем к обучаемым картинкам шум и требуем, чтобы она рисовала так же хорошо, как будто шума не было. Т.о. мы получаем некую устойчивость. Это отлично работает и достаточно бесплатно.

Четвертая вещь, что можно делать – это т.н. super-resolution. Такая задача в машинном обучении – повышение разрешения картинки. Она отлично подходит для того, чтобы убирать всякий мелкий шум и – здорово – есть всякие уже предобученные сети, например, waifu2x. Ее обучали для улучшения качества анимэ-картинок, но она отлично подходит и для обычных объектов. Но большой жирный минус, в том, что это еще одна нейронная сеть, она достаточно тяжелая и, по сути, это минимум в 2 раза уменьшение скорости.

Результаты, тем не менее, для super-resolution, для этой waifu, очень интересны. У нас картинка, которую мы стилизовали, получилась немного расфокусированная, мы прогоняем ее через waifu и получаем – у нас блюр убрался и, что интересно, перерисовалась шапка, перерисовались зрачки – такой вот эффект, т.е. мы можем улучшить картинку. Но для видео увеличение в 2 раза – это слишком жестко по нагрузке, для фото это, в принципе, реально.

Мы вот это не применяли. И мы взяли 3 из 4-х концепций — тепловые карты, дизайнеров и фрагментацию, т.е. добавление шума, чтобы сделать наш продукт лучше. Сейчас я вам покажу кусок видео, который мы сделали для руфера из Нью-Йорка. Вперед. (демонстрирует видео).

Как вы могли убедиться, видео достаточно стабильное, все объекты на задних фонах, вся текстура не мельтешит, все достаточно стабильно, всякие интересные объекты, типа татуировки у парня, перерисовываются в мозаичном стиле, при этом его кожа абсолютно одноцветная без всяких артефактов. Такой отличный результат у нас получился.
Теперь у нас есть технология, мы умеем ее готовить, пришло время поставить генерацию стилей на поток.
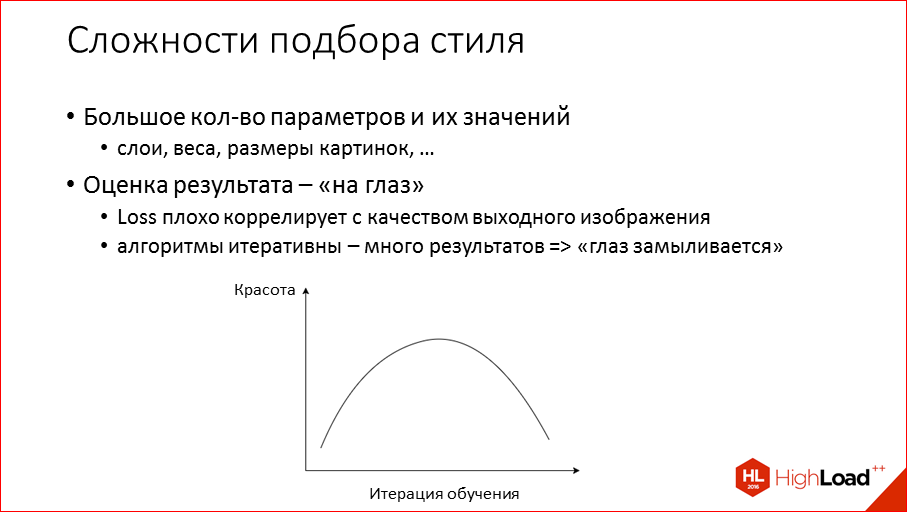
Тут есть парочка аспектов: во-первых, параметров много, их реально много. На следующем слайде я покажу, насколько. И вторая проблема, что результат стилизации нужно оценивать исключительно на глаз, причем не любой глаз, а человека, у которого есть стиль, чувство вкуса некое. Потому что пользователю то, что понравится диплёнеру, совершенно может не коррелировать никак. Может нравится, когда происходит отличная трансформация, все преколбашивает, все цвета, все по-другому, а пользователям нужно не это. Соответственно, что было замечено – по мере обучения наши стилевые контентные loss’ы не очень хорошо коррелируют с красотой изображения. С какого-то момента эти loss’ы падают, сеть обучается лучше и лучше, а красота начинает резко ухудшаться. Поэтому надо в какие-то моменты останавливаться, т.е. надо отсмотреть много результатов.
Плюс ещe, когда вы смотрите сотни картинок, глаз очень быстро замыливается, и у нас были случаи, когда мы боролись со всякими артефактами на картинке, вот ты все их убрал, показываешь: «Смотрите, какой отличный результат», и тебе говорят: «Парень, это исходная практически картинка, только отблюрена, у тебя там нет артефактов, но ничего не изменилось». Т.е. уже кажется, что без стилизации просто лучше.

Тут кусок интерфейса. Вглядываться в эти параметры не нужно, просто для того, из скольких всяких разных параметров мы сделали интерфейс. Я вначале использовал коробочное решение FGLab на node.js, но оно у меня почему-то глючило, теряло некие эксперименты. Мы написали быстренько свое, несложный интерфейс.
Что мы выяснили? Что нет смысла брать какой-то стиль, который нам кажется, что будет здоровский, и пытаться с ним стилизовать долго и мучительно. Потому что нет никакой гарантии, что с какой-то картинкой вообще что-то выйдет. Тут у нас ничего не гарантировано. Поэтому проще взять несколько наборов гипер-параметров, которые у нас работали, и к ним подбирать уже стилевую картинку. И потом, когда что-то адекватное из этого получается, можно уже руками менять какие-то параметры и уже дотюнивать хорошего кандидата.

Тут мы иллюстрируем, что на каждую сотую-двухсотую итерацию сохраняется несколько изображений, надо отсматривать много картинок – сотни на каждое обучение.

Какой рецепт успешной штамповки стилей? Мы берем много стилевых изображений, все которые нам нравятся, надергиваем из Сети. Берем рабочие сеты гипер-параметров, которые у нас на каких-то стилях работали хорошо и давали результат. Дальше нам нужны вычислительные мощности, т.е. нам нужно много GPU. Мы использовали где-то 20 штук для обучения, но т.к. это требует вмешательства человека, то у нас занято было штук 5. Т.е. только в какие-то моменты мы использовали все. Необходимым элементом является Redbull – без него невозможно отсмотреть такое количество фотографий и не сойти с ума. И после просмотра мы получаем кучу стилей.
Немного о результатах нашего приложения. Выпустились мы в конце июля, в начале октября наше приложение завоевывает топы USA, т.е. в App Store и Play Market мы занимаем 2-ое место, в «десятке» мы висим порядка 2-х недель.

Это отличный результат, достаточно тяжело туда пробиться. В Apple Store 1-ое место мы уступили iTunes U – это приложение, которое Apple «прибил гвоздями» на несколько месяцев на первое место, и только недавно его оттуда вытеснили. Поэтому проиграли только им. Но на этапе лонча через неделю-две в России мы тоже занимали 1-ое место. По ходу жизни нашего приложения, особенно вирусного эффекта в США, у нас во многих разных странах, во всяких Гавайях и т.д. тоже были хорошие позиции и много 1-ых мест.

Второй интересный для нас результат – PR-эффект – то, что мы специально для nvidia разработали с помощью нашего приложения life-стриминг, и они на своей конференции GPU Technology демонстрируют возможности новых видеокарт для обработки видео. На картинке не видно, но президент презентует работу нашего приложения, отличный для нас PR.

Немного о user experience, о наших пользователях. Во-первых, пользователям легче работать с фото, чем с видео. Т.е. мы через какое-то время, где-то через месяц после запуска добавили обработку фото, потому что пользователи банально их чаще делают. Потом им не нравятся всякие трэшовые трансформации, как я уже говорил, когда ваше лицо перерисовывается цветными макаронами, пользователь от этого не становится счастливее. Ему нравятся очень простые эффекты – замена цветов, немного границы, в общем, ничего такого особенного, это заходит отлично.
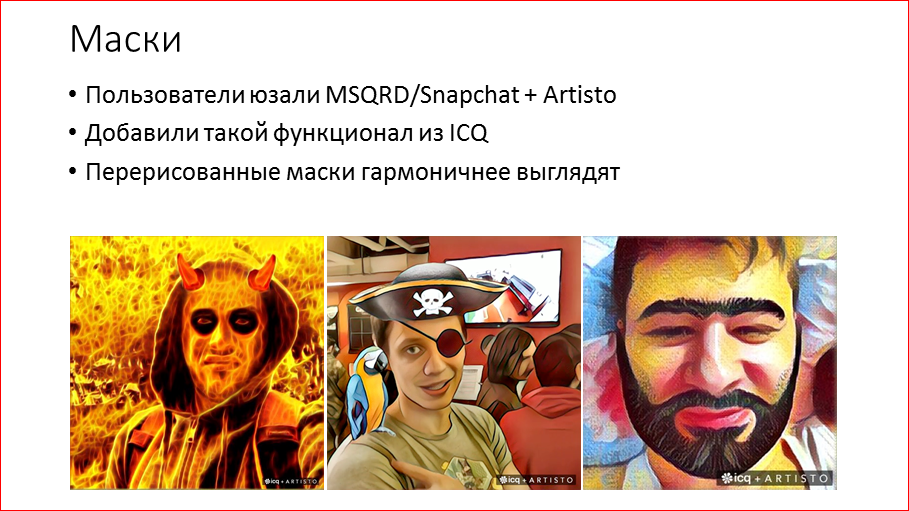
Потом мы заметили, что пользователи наши начали использовать MSQRD и Snapchat для наложения масок и потом прогонять через Artisto, чтобы получить стилизованное фото или видео. У нас есть ICQ, у Mail.ru Group, и есть такая технология. Мы у них ее позаимствовали и впилили в наше приложение. И теперь пользователи могут одновременно делать обе вещи. Мы видим, что даже когда мы маску накладываем просто на фотографию, видно, что она наложена, если мы перерисовываем каким-то стилем, то уже это практически незаметно и получается очень интересные карды. Вы можете видеть меня на одной из этих картинок.
И в заключение скажу, что сейчас мы живем в такое время, когда нам вычислительные мощности алгоритма позволяют анализировать данные, обучать сложные сети – это все больше и больше проникает в нашу жизнь. В deep learning’е сейчас бум, это реально новое открытие, очень много сейчас внедрения этих технологий в сферу развлечений, таких как Artisto и прочих. Но уже очень скоро это будет непосредственно в нашей жизни в виде пилотируемых автомобилей. Я очень жду медицину, когда, например, те архитектуры сетей, которые мы сегодня рассматривали, можно использовать as is для анализа МРТ, для анализа УЗИ, они там тоже отлично работают. Поэтому, думаю, в ближайшие лет 5, уже можно будет заменять дорогостоящих специалистов, которых дорого и долго учить, и они еще ошибаются часто. Такая технология сможет заменить.
Если вас заинтересовали сверточные сети, то есть очень хороший курс Стенфорда на эту тему, который можно прочитать, там все коротко и ясно написано. Значит, если вы хотите поэкспериментировать со стилизацией, то можно вбить «Style Transfer» в Google – там будут все статьи, весь код, который можно установить и попробовать, как оно работает. Уверен, что в результате моего доклада теперь вы точно знаете, что за этими технологиями сверточных сетей, в частности стилизации, стоят достаточно простые и понятные концепции, ничего космического, магического там нет. Всеми этими технологиями, связанными с нейросетями, очень интересно заниматься, увлекательно и, как вы видели по ходу моей презентации, очень даже весело.
Спасибо большое!
Контакты
» Блог компании Mail.Ru GroupЭтот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++.
Сейчас мы уже вовсю готовим конференцию 2017-года — самый большой HighLoad++
в истории. Если вам интересно и важна стоимость билетов — покупайте сейчас, пока цена ещё не высока!
Кстати, в этом году мы также будем проводить AI-секцию, посвящённую машинному обучению и нейронным сетям.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru