По дороге с облаками. Реляционные базы данных в новом технологическом контексте
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-06-06 22:47

Привет, Хабр! Мы задумываемся об издании не совсем обычной книги, автор которой желает изложить очень интересную трактовку современного технологического ландшафта, охватывающего базы данных и технологии обработки Big Data. Автор полагает, что без активного использования облаков никуда не деться, и рассказывает об этом ландшафте именно в таком ракурсе.
Об авторе:
Александр Васильевич Сенько, кандидат физико-математических наук в области компьютерного моделирования и оптимизации мощных сверхвысокочастотных приборов.
Автор имеет сертификаты Microsoft в области создания приложений в среде Microsoft Azure: Microsoft Certified Professional и Microsoft Specialist: Developing Microsoft Azure Solutions. В 2008 году закончил Белорусский Государственный Университет Информатики и Радиоэлектроники (БГУИР) по специальности “Моделирование и компьютерное проектирование радиоэлектронных средств”. С 2007 по 2012-й годы автор работает в научно-исследовательском институте ядерных проблем БГУ на должностях техника, лаборанта, инженера. С 2013 года по настоящее время автор работает в компании ISSoft Solutions на должности разработчика ПО и DevOps с специализацией в области создания облачных приложений на базе стека Microsoft
Под катом вы сможете оценить идеи и стиль автора. Не стесняйтесь голосовать и комментировать — и добро пожаловать под кат!
Введение или почему эту статью следовало написать.
В настоящее время облачные сервисы позволяют разработчикам и системным администраторам очень быстро создавать инфраструктуру приложения и так же быстро от нее избавляться, когда в этом отпадает необходимость. Плата взимается за время использования ресурсов облака и за их уровень производительности, именуемый еще «ценовой уровень» – pricing tier. Можно очень быстро создать ресурсы, «поиграться» с ними, «пощупать», освоить их, и при этом совершенно не нужно заботиться о покупке/администрировании серверов, чтении документации об инсталляции требуемого софта и пр. В облачных средах все типовые задачи администрирования и мониторинга сведены в удобные API или пользовательский интерфейс веб-портала управления. Но тут появляется одна сложность – если человек не разбирается или не до конца понимает, как работают облачные среды, задача «что мне надо сделать, чтобы получить базу данных и подключиться к ней из моего приложения» на первых порах озадачивает. Обилие облачных сервисов и различных «ценовых уровней» для каждого сервиса еще больше осложняет задачу выбора. Эта статья представляет краткий обзор одного из самых популярных облачных сервисов – сервисов реляционных баз данных.
Реляционные базы данных являются традиционным хранилищем данных. Информацию в них можно представить в виде набора таблиц, состоящих из строк. Эти таблицы связаны друг с другом с помощью «ключей» — специальных ограничений целостности, ставивящих строкам одной таблицы в соответствие строки другой. «Большие данные» зачастую удобнее хранить и быстрее обрабатывать в нереляционном виде (например, в базах данных типа ключ/значение), но данные, хранящиеся в виде взаимосвязанных таблиц, допускают эффективный анализ в любом измерении – по строкам связанных таблиц и по всей таблице, что для случая NoSQL баз данных сопряжено с большими трудностями. Кроме того, для реляционных баз данных имеется очень эффективный язык запросов – SQL. В облачных средах реляционные базы данных представлены в двух видах – SQL as a Service и в виде готовых образов для виртуальных машин. Базы данных, размещаемые на виртуальных машинах, по сути, мало отличаются от серверов баз данных, размещенных на традиционных виртуальных и физических хостах. При этом выбор типа виртуальной машины, виртуальных дисков, облачного хранилища для их размещения и сетевых интерфейсов существенно влияют на ее производительнсть, но это тема отдельной главы, а возможно и книги. У серверов баз данных, размещенных на виртуальных машинах в облаках, есть существенные ограничения, связанные с масштабированием, доступностью и отказоустойчивостью. Например, виртуальные машины Azure имеют SLA (service level agreement – соглашение об уровне доступности) на уровне 99,95% только в случае использовании кластера минимум из двух машин, размещенных в одной общей группе доступности (Availability Set), при этом у них будут физически разделены сетевые интерфейсы и источники питания. Для того, чтобы достичь уровня 99,99 необходимо конфигурировать кластер из нескольких виртуальных машин Always On.
В то же время SQL обладает SLA на уровне 99.99 без дополнительных трудностей, связанных с конфигурированием кластеров. С другой стороны, требованиям стандартов HIPPA соответствуют SQL-сервера, размещенные на виртуальных машинах, но не сервис Azure SQL. В остальном же облачный сервиc SQL имеет непревзойденные возможности в плане масштабирования, доступности и простоте администрирования (репликация, резервное копирование, экспорт, анализ производительности выполняемых запросов). Кроме того, SQL as a Service в ряде случаев существенно дешевле аналогичного по производительности сервера, размещаемого на виртуальной машине (автор сознает, что это очень спорное утверждение, особенно учитывая особенности использования ресурсов в SQL as a Service и SQL на виртуальных машинах). SQL as a Service, не поддерживает всех возможностей традиционных серверов баз данных. Например, выполнение запросов из таблиц в одной базе данных внутри другой в случае SQL сервиса сопряжено с рядом трудностей и ограничений. Рассмотрим примеры реализации SQL as a Service в разных облачных средах.
Служба реляционной базы данных Azure SQL от Microsoft.
Реализация SQL-As-A-Service от Microsoft представляет собой облачную службу реляционной базы данных на основе движка Microsoft SQL Server и называется Azure SQL. В языке запросов Azure SQL реализовано подмножество функций T-SQL. Экземпляры сервисов Azure SQL, являющиеся прямыми аналогами баз данных MS-SQL, логически группируются в «серверы» Azure SQL Server. Каждый сервер Azure SQL должен иметь уникальный URL, учетные данные (имя пользователя и пароль), а также набор допустимых IP адресов, которые могут иметь доступ к нему (этот список формируется в firewall сервера и регулирует правила доступа к нему).
Физически Azure SQL Server размещается в ЦОД–е, расположенном в определенном географическом регионе. В этом же регионе размещаются все экземпляры баз данных Azure SQL. Возможна также географическая репликация баз данных в несколько регионов по схеме Primary-Secondary или Primary-ReadOnly Replica (первичный сервер – реплика, доступная только для чтения). Благодаря широкой поддержке T-SQL в Azure SQL имеется возможность прямой миграции баз данных из Microsoft SQL Server в Azure SQL. Конечно, прямая миграция из одного типа базы данных в другую – далеко не простая и не быстрая задача, но в данном случае это принципиально возможно и напрямую поддерживается с помощью специальных программ от Microsoft, Red Gate и пр. Однако следует иметь в виду, что это программное обеспечение в ряде случаев просто «вырезает» несовместимые объекты базы данных, не пытаясь их адаптировать. И может получиться, что после такой миграции база данных «поднялась», но счастливые разработчики могут «внезапно» недосчитаться ряда объектов базы данных в Azure SQL. Каждый экземпляр баз данных имеет определенный «ценовой уровень» — pricing tier — который характеризуется своей производительностью, ограничениями по размеру, количеству точек восстановления и возможностями репликации. Все возможные ценовые уровни разделены на следующие уровни: базовые (“Basic”), стандартные (“Standard”) и премиум (“Premium”). Самое главное различие ценовых уровней проявляется в разном значении DTU – обобщенного параметра, характеризующего производительность базы данных. Что же это за параметр? DTU (eDTU) это обобщенная характеристика производительности базы данных, включающая в себя показатели производительности центрального процессора, памяти, устройств ввода-вывода и сетевого интерфейса. Этот показатель определяет своего рода «объем», который может «занимать» производительность Azure SQL. Если в данный момент в базе выполняется запрос, то этот запрос потребляет определенное количество ресурсов, которые занимают часть этого разрешенного объема (см рисунок 1). При этом следует иметь в виду, что ограничивается не только объем, но и конкретные значения каждого из показателей (т.е. не получится «обменять» крайне малое использование CPU на крайне большое значение памяти). Это проявляется в частности в том, что один «кривой» запрос может вызвать переиспользование одного из ресурсов и в итоге одвесить всю базу данных (экземпляр сервиса Azure SQL Database но не Azure SQL Server) и точно такой же запрос будет нормально отрабатывать в традиционной базе данных Microsoft SQL Server. Это происходит потому, то в Azure SQL срабатывает механизм защиты ресурсов базы от чрезмерного использования, который вынуждает процесс, вызвавший запрос, отключиться по таймауту, освободив тем самым ресурсы базы данных.
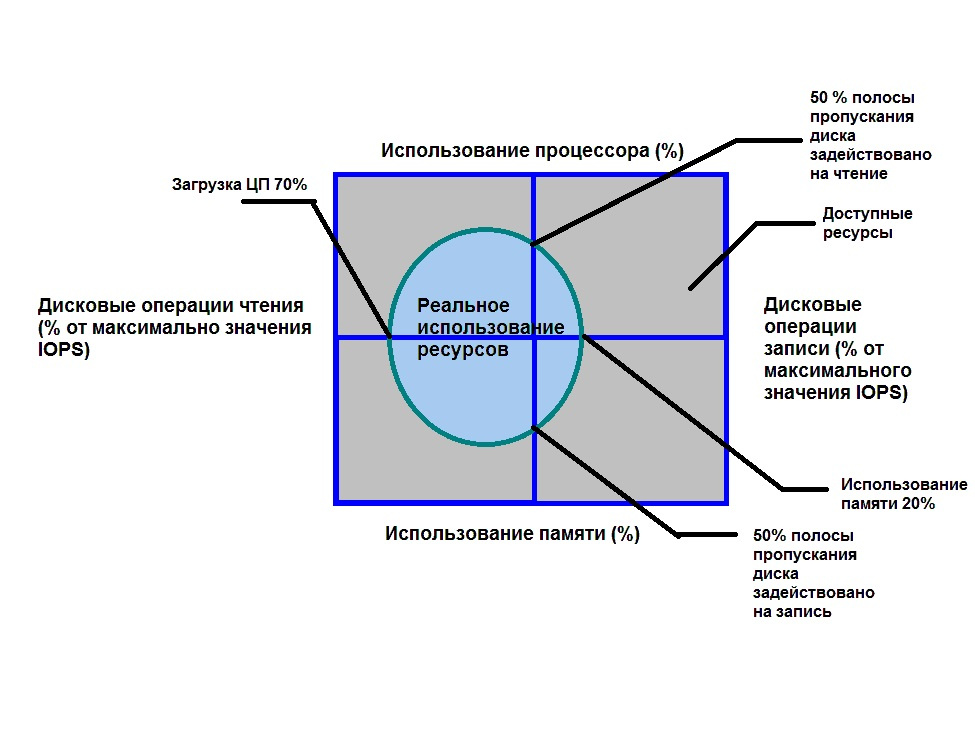
Итак, Azure SQL состоят из экземпляров Azure SQL Database, являющихся собственно реляционными хранилищами информации с определенными значениями размера и максимального DTU; экземпляра Azure SQL Server, который группирует базы Azure SQL Database, обеспечивая им общую строку соединения (connection string), правила доступа, прописанные в firewall и в ряде случаев предоставляя общий эластичный пул ресурсов (Elastic Database Pool, о котором– ниже).
Теперь познакомимся с Elastic Database Pool. Этот сервис встроен в состав Azure SQL Server и служит для объединения баз данных в один пул и назначения всем им общих разделяемых ресурсов. Зачем это нужно? Рассмотрим пример SaaS приложения, созданного для оказания неких услуг зарегистрированным в нем пользователям (например, это «облачная» CRM система). Каждому зарегистрированному пользователю такой системы выделяется своя база данных определенного уровня производительности, выражающегося конкретным значением DTU. Каждый уровень производительности имеет определенную месячную стоимость, которая в конечном итоге скажется на прибыли владельца SaaS – она будет равна суммарной месячной плате всех пользователей за вычетом расходов на облачные сервисы, лежащие в основе архитектуры системы. Теперь предположим, что активность пользователей, выражающаяся в использовании DTU каждой базы, носит некореллированный характер, т.е. они нагружают свои базы в различные случайные временные промежутки. Это приводит к тому, что появляются моменты времени, когда использование DTU базы конкретного пользователя очень мало, и моменты, когда оно велико. Таким образом, в момент малого использования DTU базы «простаивают» — но за них взимается плата со стороны Azure. А что если взять несколько таких баз данных, что интервалы активности каждой совпадают с интервалами недогруженности других, и объединить их в общий пул баз данных и распределить общие ресурсы DTU между базами таким образом, чтобы суммарная нагрузка была равномерна во времени; плата за ценовой уровень при этом будет существенно меньше, чем суммарная плата за все базы данных. Именна такая идея лежит в основе сервиса Azure Elastic Database Pool. Кроме того, ElasticDatabasePool позволяет реализовывать сценарии разделения одной большой базы данных на меньшие, но выполнять запросы в этой разделенной на «фрагменты» (shard) БД так, как будто это одна монолитная база данных.
Рассмотрим теперь случай, когда все же необходимо выполнить запрос к данным, расположенным в разных базах данных. Если имеется просто набор баз данных без фрагментирования, необходимо выбрать одну головную базу данных и создать в ней внешние источники данных и внешние таблицы (reference table), являющиеся «отражениями» реальных таблиц, размещенных в других базах данных. Можно также не использовать специализированную головную базу данных, а создавать таблицы в каждом экземпляре Azure SQL Database. Недостаток такого подхода в том, что при смене схем таблиц в базах данных, необходимо синхронно менять схемы во внешних таблицах (если отсутствует головная база данных, то необходимо проделать очень большую работу по смене схемы во всех внешних таблицах во всех базах, где они присутствуют). Кроме того, у реализации T-SQL в Azure SQL есть ограничения на типы данных для внешних таблиц (например, они не поддерживают Foreign Key и тип nvatrchar(max)) и в настоящее время присутствует целый ряд ограничений на выполнение подобных запросов и базы данных, где эти запросы будут выполняться – например невозможно выполнить экспорт базы данных в BACPAC файл в случае наличия в ней ссылок на внешние таблицы. Ну и не следует забывать и об снижении производительности для таких запросов. А как же это все выглядит?
Давайте для определенности предположим, что у нас две базы данных – база First и база Second. Теперь допустим, что из базы Second нам нужно выполнить запрос к базе First. Для этого в базе Second должны быть созданы учетные данные (credentials), которые будут служить для доступа к базе данных First:
Затем в базе данных Second создадим внешний источник данных, который будет использоваться для связи с таблицами внешней базы данных:
После этого в базе Second надо создать «внешнюю таблицу» (External Table) – таблицу, являющуюся «отражением» аналогичной таблицы, размещенной в базе First:
И все! Теперь мы можем в базе данных Second делать запросы к таблице из базы First как к обычной таблице, размещенной в базе Second. Стоит иметь в виду, что эти таблицы связаны только по данным – любые изменения схемы в одной базе данных никак не отразятся на схеме таблицы в другой.
Другой возможный случай выполнения запросов к различным базам данных – это использование Elastic Database jobs. Суть этой технологии в том, что группа баз данных объединяется и управляется централизованно из общего специализированного головного сервера ВМ. Взаимодействуя с этим сервером программно или через Azure Portal, можно управлять всеми подключенными базами данных с помощью создания заданий (jobs). Эти задания могут быть следующего характера:
Сервис Elastic Database jobs содержит следующие компоненты (рисунок 2):

Настройка, использование и администрирование всей этой системы – довольно сложная тема и подробно рассматриваться не будет. Интересующиеся могут ознакомиться с темой здесь.
Помимо одиночных баз данных, сервис AzureSQL позволяет создавать более сложные реляционные хранилища – фрагментированные базы данных – Sharded Databases и реляционные хранилища с широкой поддержкой массивно-параллельного выполнения запросов – Azure SQL DWH.
Рассмотрим сперва фрагментированные базы данных. Нужда во фрагментации базы данных появляется в случае, когда ее размер становится чрезмерно большим для размещения на одном экземпляре Azure SQL (в настоящее время это более 1 ТБ для Premium pricing tier). Конечно, можно разбить большую базу данных на меньшие базы логически, проведя анализ ее структуры (схемы). Как уже указывалось ранее, Azure SQL Server это логическая группировка экземпляров Azure SQL Database, а не физическое объединение на одном сервере. И прямые запросы к объектам базы данных из другой базы данных возможны только если эти объекты являются External table или эти базы объединены в Elastic Database Pool, и используются запросы Elastic Database Query или транзакции Elastic Transactions. В этом случае необходимо применить фрагментацию (sharding) базы данных. Фрагментация базы данных — это по сути горизонтальное масштабирование, отличное от вертикального масштабирования – увеличения «размера» базы данных в масштабе CPU, оперативной памяти, IOPs и пр. Разделение одного большого хранилища на несколько хранилищ меньшего масштаба и параллельная обработка в их всех с последующим сложением результатов обработки – ключевая концепция всех технологий обработки больших данных, с которой мы будем далее не раз встречаться.
Об авторе:
Александр Васильевич Сенько, кандидат физико-математических наук в области компьютерного моделирования и оптимизации мощных сверхвысокочастотных приборов.
Автор имеет сертификаты Microsoft в области создания приложений в среде Microsoft Azure: Microsoft Certified Professional и Microsoft Specialist: Developing Microsoft Azure Solutions. В 2008 году закончил Белорусский Государственный Университет Информатики и Радиоэлектроники (БГУИР) по специальности “Моделирование и компьютерное проектирование радиоэлектронных средств”. С 2007 по 2012-й годы автор работает в научно-исследовательском институте ядерных проблем БГУ на должностях техника, лаборанта, инженера. С 2013 года по настоящее время автор работает в компании ISSoft Solutions на должности разработчика ПО и DevOps с специализацией в области создания облачных приложений на базе стека Microsoft
Под катом вы сможете оценить идеи и стиль автора. Не стесняйтесь голосовать и комментировать — и добро пожаловать под кат!
Введение или почему эту статью следовало написать.
В настоящее время облачные сервисы позволяют разработчикам и системным администраторам очень быстро создавать инфраструктуру приложения и так же быстро от нее избавляться, когда в этом отпадает необходимость. Плата взимается за время использования ресурсов облака и за их уровень производительности, именуемый еще «ценовой уровень» – pricing tier. Можно очень быстро создать ресурсы, «поиграться» с ними, «пощупать», освоить их, и при этом совершенно не нужно заботиться о покупке/администрировании серверов, чтении документации об инсталляции требуемого софта и пр. В облачных средах все типовые задачи администрирования и мониторинга сведены в удобные API или пользовательский интерфейс веб-портала управления. Но тут появляется одна сложность – если человек не разбирается или не до конца понимает, как работают облачные среды, задача «что мне надо сделать, чтобы получить базу данных и подключиться к ней из моего приложения» на первых порах озадачивает. Обилие облачных сервисов и различных «ценовых уровней» для каждого сервиса еще больше осложняет задачу выбора. Эта статья представляет краткий обзор одного из самых популярных облачных сервисов – сервисов реляционных баз данных.
Реляционные базы данных являются традиционным хранилищем данных. Информацию в них можно представить в виде набора таблиц, состоящих из строк. Эти таблицы связаны друг с другом с помощью «ключей» — специальных ограничений целостности, ставивящих строкам одной таблицы в соответствие строки другой. «Большие данные» зачастую удобнее хранить и быстрее обрабатывать в нереляционном виде (например, в базах данных типа ключ/значение), но данные, хранящиеся в виде взаимосвязанных таблиц, допускают эффективный анализ в любом измерении – по строкам связанных таблиц и по всей таблице, что для случая NoSQL баз данных сопряжено с большими трудностями. Кроме того, для реляционных баз данных имеется очень эффективный язык запросов – SQL. В облачных средах реляционные базы данных представлены в двух видах – SQL as a Service и в виде готовых образов для виртуальных машин. Базы данных, размещаемые на виртуальных машинах, по сути, мало отличаются от серверов баз данных, размещенных на традиционных виртуальных и физических хостах. При этом выбор типа виртуальной машины, виртуальных дисков, облачного хранилища для их размещения и сетевых интерфейсов существенно влияют на ее производительнсть, но это тема отдельной главы, а возможно и книги. У серверов баз данных, размещенных на виртуальных машинах в облаках, есть существенные ограничения, связанные с масштабированием, доступностью и отказоустойчивостью. Например, виртуальные машины Azure имеют SLA (service level agreement – соглашение об уровне доступности) на уровне 99,95% только в случае использовании кластера минимум из двух машин, размещенных в одной общей группе доступности (Availability Set), при этом у них будут физически разделены сетевые интерфейсы и источники питания. Для того, чтобы достичь уровня 99,99 необходимо конфигурировать кластер из нескольких виртуальных машин Always On.
В то же время SQL обладает SLA на уровне 99.99 без дополнительных трудностей, связанных с конфигурированием кластеров. С другой стороны, требованиям стандартов HIPPA соответствуют SQL-сервера, размещенные на виртуальных машинах, но не сервис Azure SQL. В остальном же облачный сервиc SQL имеет непревзойденные возможности в плане масштабирования, доступности и простоте администрирования (репликация, резервное копирование, экспорт, анализ производительности выполняемых запросов). Кроме того, SQL as a Service в ряде случаев существенно дешевле аналогичного по производительности сервера, размещаемого на виртуальной машине (автор сознает, что это очень спорное утверждение, особенно учитывая особенности использования ресурсов в SQL as a Service и SQL на виртуальных машинах). SQL as a Service, не поддерживает всех возможностей традиционных серверов баз данных. Например, выполнение запросов из таблиц в одной базе данных внутри другой в случае SQL сервиса сопряжено с рядом трудностей и ограничений. Рассмотрим примеры реализации SQL as a Service в разных облачных средах.
Служба реляционной базы данных Azure SQL от Microsoft.
Реализация SQL-As-A-Service от Microsoft представляет собой облачную службу реляционной базы данных на основе движка Microsoft SQL Server и называется Azure SQL. В языке запросов Azure SQL реализовано подмножество функций T-SQL. Экземпляры сервисов Azure SQL, являющиеся прямыми аналогами баз данных MS-SQL, логически группируются в «серверы» Azure SQL Server. Каждый сервер Azure SQL должен иметь уникальный URL, учетные данные (имя пользователя и пароль), а также набор допустимых IP адресов, которые могут иметь доступ к нему (этот список формируется в firewall сервера и регулирует правила доступа к нему).
Физически Azure SQL Server размещается в ЦОД–е, расположенном в определенном географическом регионе. В этом же регионе размещаются все экземпляры баз данных Azure SQL. Возможна также географическая репликация баз данных в несколько регионов по схеме Primary-Secondary или Primary-ReadOnly Replica (первичный сервер – реплика, доступная только для чтения). Благодаря широкой поддержке T-SQL в Azure SQL имеется возможность прямой миграции баз данных из Microsoft SQL Server в Azure SQL. Конечно, прямая миграция из одного типа базы данных в другую – далеко не простая и не быстрая задача, но в данном случае это принципиально возможно и напрямую поддерживается с помощью специальных программ от Microsoft, Red Gate и пр. Однако следует иметь в виду, что это программное обеспечение в ряде случаев просто «вырезает» несовместимые объекты базы данных, не пытаясь их адаптировать. И может получиться, что после такой миграции база данных «поднялась», но счастливые разработчики могут «внезапно» недосчитаться ряда объектов базы данных в Azure SQL. Каждый экземпляр баз данных имеет определенный «ценовой уровень» — pricing tier — который характеризуется своей производительностью, ограничениями по размеру, количеству точек восстановления и возможностями репликации. Все возможные ценовые уровни разделены на следующие уровни: базовые (“Basic”), стандартные (“Standard”) и премиум (“Premium”). Самое главное различие ценовых уровней проявляется в разном значении DTU – обобщенного параметра, характеризующего производительность базы данных. Что же это за параметр? DTU (eDTU) это обобщенная характеристика производительности базы данных, включающая в себя показатели производительности центрального процессора, памяти, устройств ввода-вывода и сетевого интерфейса. Этот показатель определяет своего рода «объем», который может «занимать» производительность Azure SQL. Если в данный момент в базе выполняется запрос, то этот запрос потребляет определенное количество ресурсов, которые занимают часть этого разрешенного объема (см рисунок 1). При этом следует иметь в виду, что ограничивается не только объем, но и конкретные значения каждого из показателей (т.е. не получится «обменять» крайне малое использование CPU на крайне большое значение памяти). Это проявляется в частности в том, что один «кривой» запрос может вызвать переиспользование одного из ресурсов и в итоге одвесить всю базу данных (экземпляр сервиса Azure SQL Database но не Azure SQL Server) и точно такой же запрос будет нормально отрабатывать в традиционной базе данных Microsoft SQL Server. Это происходит потому, то в Azure SQL срабатывает механизм защиты ресурсов базы от чрезмерного использования, который вынуждает процесс, вызвавший запрос, отключиться по таймауту, освободив тем самым ресурсы базы данных.
Итак, Azure SQL состоят из экземпляров Azure SQL Database, являющихся собственно реляционными хранилищами информации с определенными значениями размера и максимального DTU; экземпляра Azure SQL Server, который группирует базы Azure SQL Database, обеспечивая им общую строку соединения (connection string), правила доступа, прописанные в firewall и в ряде случаев предоставляя общий эластичный пул ресурсов (Elastic Database Pool, о котором– ниже).
Теперь познакомимся с Elastic Database Pool. Этот сервис встроен в состав Azure SQL Server и служит для объединения баз данных в один пул и назначения всем им общих разделяемых ресурсов. Зачем это нужно? Рассмотрим пример SaaS приложения, созданного для оказания неких услуг зарегистрированным в нем пользователям (например, это «облачная» CRM система). Каждому зарегистрированному пользователю такой системы выделяется своя база данных определенного уровня производительности, выражающегося конкретным значением DTU. Каждый уровень производительности имеет определенную месячную стоимость, которая в конечном итоге скажется на прибыли владельца SaaS – она будет равна суммарной месячной плате всех пользователей за вычетом расходов на облачные сервисы, лежащие в основе архитектуры системы. Теперь предположим, что активность пользователей, выражающаяся в использовании DTU каждой базы, носит некореллированный характер, т.е. они нагружают свои базы в различные случайные временные промежутки. Это приводит к тому, что появляются моменты времени, когда использование DTU базы конкретного пользователя очень мало, и моменты, когда оно велико. Таким образом, в момент малого использования DTU базы «простаивают» — но за них взимается плата со стороны Azure. А что если взять несколько таких баз данных, что интервалы активности каждой совпадают с интервалами недогруженности других, и объединить их в общий пул баз данных и распределить общие ресурсы DTU между базами таким образом, чтобы суммарная нагрузка была равномерна во времени; плата за ценовой уровень при этом будет существенно меньше, чем суммарная плата за все базы данных. Именна такая идея лежит в основе сервиса Azure Elastic Database Pool. Кроме того, ElasticDatabasePool позволяет реализовывать сценарии разделения одной большой базы данных на меньшие, но выполнять запросы в этой разделенной на «фрагменты» (shard) БД так, как будто это одна монолитная база данных.
Рассмотрим теперь случай, когда все же необходимо выполнить запрос к данным, расположенным в разных базах данных. Если имеется просто набор баз данных без фрагментирования, необходимо выбрать одну головную базу данных и создать в ней внешние источники данных и внешние таблицы (reference table), являющиеся «отражениями» реальных таблиц, размещенных в других базах данных. Можно также не использовать специализированную головную базу данных, а создавать таблицы в каждом экземпляре Azure SQL Database. Недостаток такого подхода в том, что при смене схем таблиц в базах данных, необходимо синхронно менять схемы во внешних таблицах (если отсутствует головная база данных, то необходимо проделать очень большую работу по смене схемы во всех внешних таблицах во всех базах, где они присутствуют). Кроме того, у реализации T-SQL в Azure SQL есть ограничения на типы данных для внешних таблиц (например, они не поддерживают Foreign Key и тип nvatrchar(max)) и в настоящее время присутствует целый ряд ограничений на выполнение подобных запросов и базы данных, где эти запросы будут выполняться – например невозможно выполнить экспорт базы данных в BACPAC файл в случае наличия в ней ссылок на внешние таблицы. Ну и не следует забывать и об снижении производительности для таких запросов. А как же это все выглядит?
Давайте для определенности предположим, что у нас две базы данных – база First и база Second. Теперь допустим, что из базы Second нам нужно выполнить запрос к базе First. Для этого в базе Second должны быть созданы учетные данные (credentials), которые будут служить для доступа к базе данных First:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<пар0ль>'; CREATE DATABASE SCOPED CREDENTIAL FirstDBQueryCred -- Это имя учетной записи WITH IDENTITY = '<ИмяПользователя>', SECRET = '<пар0ль>'; Затем в базе данных Second создадим внешний источник данных, который будет использоваться для связи с таблицами внешней базы данных:
CREATE EXTERNAL DATA SOURCE FirstDatabaseDataSource WITH ( TYPE = RDBMS, LOCATION = '<logical_server_name>.database.windows.net', DATABASE_NAME = 'First', CREDENTIAL = FirstDBQueryCred ) После этого в базе Second надо создать «внешнюю таблицу» (External Table) – таблицу, являющуюся «отражением» аналогичной таблицы, размещенной в базе First:
CREATE EXTERNAL TABLE [dbo].[TableFromFirstDatabase] ( [KeyFieldID] [int] NOT NULL, [DataField] [varchar](50) NOT NULL ) WITH ( DATA_SOURCE = FirstDatabaseDataSource)И все! Теперь мы можем в базе данных Second делать запросы к таблице из базы First как к обычной таблице, размещенной в базе Second. Стоит иметь в виду, что эти таблицы связаны только по данным – любые изменения схемы в одной базе данных никак не отразятся на схеме таблицы в другой.
Другой возможный случай выполнения запросов к различным базам данных – это использование Elastic Database jobs. Суть этой технологии в том, что группа баз данных объединяется и управляется централизованно из общего специализированного головного сервера ВМ. Взаимодействуя с этим сервером программно или через Azure Portal, можно управлять всеми подключенными базами данных с помощью создания заданий (jobs). Эти задания могут быть следующего характера:
- административные (согласованное изменение схемы, выполнение перекомпиляции индексов);
- периодическое обновление данных или сбор данных для систем BI, в т.ч. для выполнения анализа большого количеств данных.
Сервис Elastic Database jobs содержит следующие компоненты (рисунок 2):
- головной сервер, размещаемый на экземпляре Azure Cloud Service Worker Role. По сути, это специализированное ПО, размещаемое (по состоянию на настоящее время) на виртуальной маший Azure Cloud Service. Для обеспечения высокой доступности, рекомендуется создавать минимум 2 экземпляра ВМ;
- управляющая база данных. Это экземпляр Azure SQL, служащий для хранения метаданных всех подключенных баз данных;
- экземпляр службы Azure Service Bus, служащий для объединения и синхронизации всех компонентов;
- экземпляр облачного хранилища Azure Storage Account, служащий для хранения журналов всей системы.
Настройка, использование и администрирование всей этой системы – довольно сложная тема и подробно рассматриваться не будет. Интересующиеся могут ознакомиться с темой здесь.
Помимо одиночных баз данных, сервис AzureSQL позволяет создавать более сложные реляционные хранилища – фрагментированные базы данных – Sharded Databases и реляционные хранилища с широкой поддержкой массивно-параллельного выполнения запросов – Azure SQL DWH.
Рассмотрим сперва фрагментированные базы данных. Нужда во фрагментации базы данных появляется в случае, когда ее размер становится чрезмерно большим для размещения на одном экземпляре Azure SQL (в настоящее время это более 1 ТБ для Premium pricing tier). Конечно, можно разбить большую базу данных на меньшие базы логически, проведя анализ ее структуры (схемы). Как уже указывалось ранее, Azure SQL Server это логическая группировка экземпляров Azure SQL Database, а не физическое объединение на одном сервере. И прямые запросы к объектам базы данных из другой базы данных возможны только если эти объекты являются External table или эти базы объединены в Elastic Database Pool, и используются запросы Elastic Database Query или транзакции Elastic Transactions. В этом случае необходимо применить фрагментацию (sharding) базы данных. Фрагментация базы данных — это по сути горизонтальное масштабирование, отличное от вертикального масштабирования – увеличения «размера» базы данных в масштабе CPU, оперативной памяти, IOPs и пр. Разделение одного большого хранилища на несколько хранилищ меньшего масштаба и параллельная обработка в их всех с последующим сложением результатов обработки – ключевая концепция всех технологий обработки больших данных, с которой мы будем далее не раз встречаться.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru