Машинное обучение для страховой компании: Исследуем алгоритмы
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-06-23 12:21
искусственный интеллект, алгоритмы машинного обучения, реализация нейронной сети
Предлагаю продолжить добрую традицию, которая началась в пятницу чуть больше месяца назад. Тогда я поделилась с вами вводной статьёй о том, для чего нужно машинное обучение в страховой компании и как проверялась реалистичность самой идеи. Сегодня будет её продолжение, в котором начинается самое интересное — тестирование алгоритмов.

2. Исследуем алгоритмы
3. Оптимизация модели
Простой пример: в первой статье в конечной оценке была ремарка о несбалансированной по классам тестовой выборке. Исправить ситуацию можно, введя в схему несложный скрипт, который отфильтрует лишние строки во всей выборке. В качестве демонстрации сделаем это следующим способом (возможны и другие).
 Модуль возвращает измененный массив данных, в котором (как будет видно позже) содержится равное для обоих классов количество записей.
Модуль возвращает измененный массив данных, в котором (как будет видно позже) содержится равное для обоих классов количество записей.
В прототипе, о котором шла речь в предыдущей статье, было использовано два типа данных: количество посещений пациентом врача за последние три месяца и последняя потраченная на этот визит сумма. Для начала добавим:
Однако так мы только увеличим количество признаков, никак их не обработав. Для этого используем MS Analysis Services, в котором для извлечения признаков применяется машинное обучение — в частности, упрощенный алгоритм Байеса.
 По результатам можно выбрать границы для бинарного представления входных данных. Например, «возраст младше 19» и «количество обращений к врачу меньше 5» свидетельствуют о большей вероятности отсутствия пика. В то время как «возраст старше 64» и «количество обращений больше 14» чреваты затратами в следующем месяце.
По результатам можно выбрать границы для бинарного представления входных данных. Например, «возраст младше 19» и «количество обращений к врачу меньше 5» свидетельствуют о большей вероятности отсутствия пика. В то время как «возраст старше 64» и «количество обращений больше 14» чреваты затратами в следующем месяце.
Можно получить список диагнозов, которые чаще других предшествуют большим тратам.
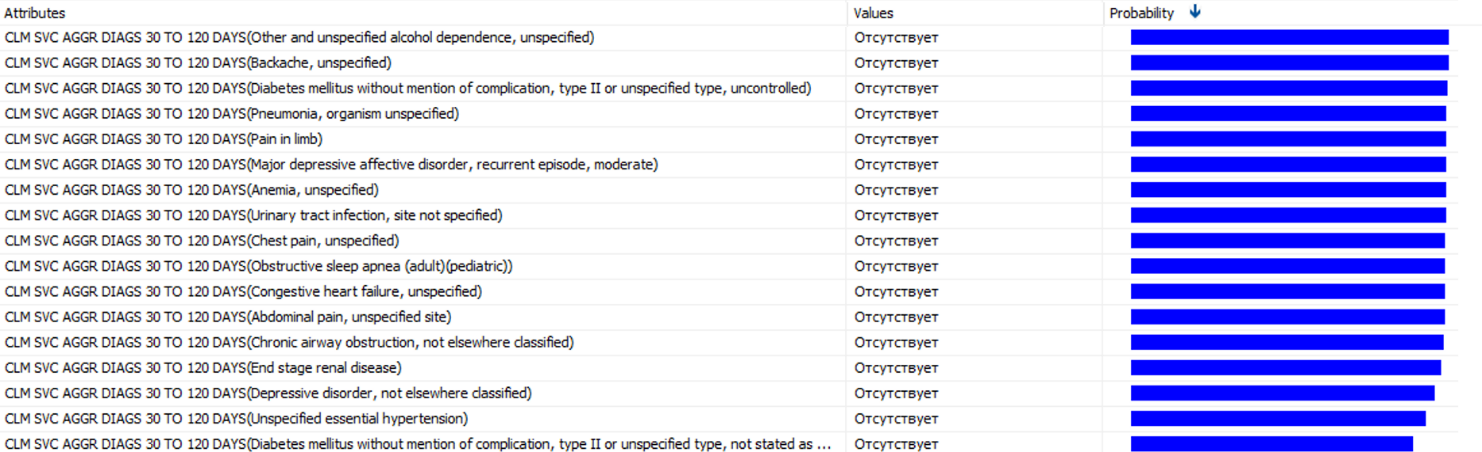 Это только часть выбранных диагнозов. В каждом из диагнозов, с вероятностью от 85% до 100%, последует пик затрат. Их наличие стоит вынести в отдельный признак. Не стоит упускать и наличие обычных диагнозов, которые не обойдутся компании дорого. Поэтому следует провести нормировку найденных вероятностей и ввести новый признак, который будет представлять собой взвешенную сумму количества диагнозов за последние 90 дней.
Это только часть выбранных диагнозов. В каждом из диагнозов, с вероятностью от 85% до 100%, последует пик затрат. Их наличие стоит вынести в отдельный признак. Не стоит упускать и наличие обычных диагнозов, которые не обойдутся компании дорого. Поэтому следует провести нормировку найденных вероятностей и ввести новый признак, который будет представлять собой взвешенную сумму количества диагнозов за последние 90 дней.
В результате получено семь параметров в векторе входных признаков. Сравним их с тем, что было получено в прошлый раз с использованием разных алгоритмов.
Поскольку была проведена фильтрация данных для получения сбалансированной выборки, граничное значение для присвоения классов пока менять не будем. К этому вопросу мы вернемся в следующей статье.
На начальном этапе он позволяет получить исходное значение в промежутке от минус до плюс бесконечности. Далее осуществим преобразование, используя сигмоидальную функцию вида 1/(1+e^(-score) ),, где score — это полученное ранее значение, осуществляем преобразование. Результатом будет число в пределах от -1 до +1. Решение о принадлежности к классу принимается на основании выбранного порогового значения.
 Параметры:
Параметры:

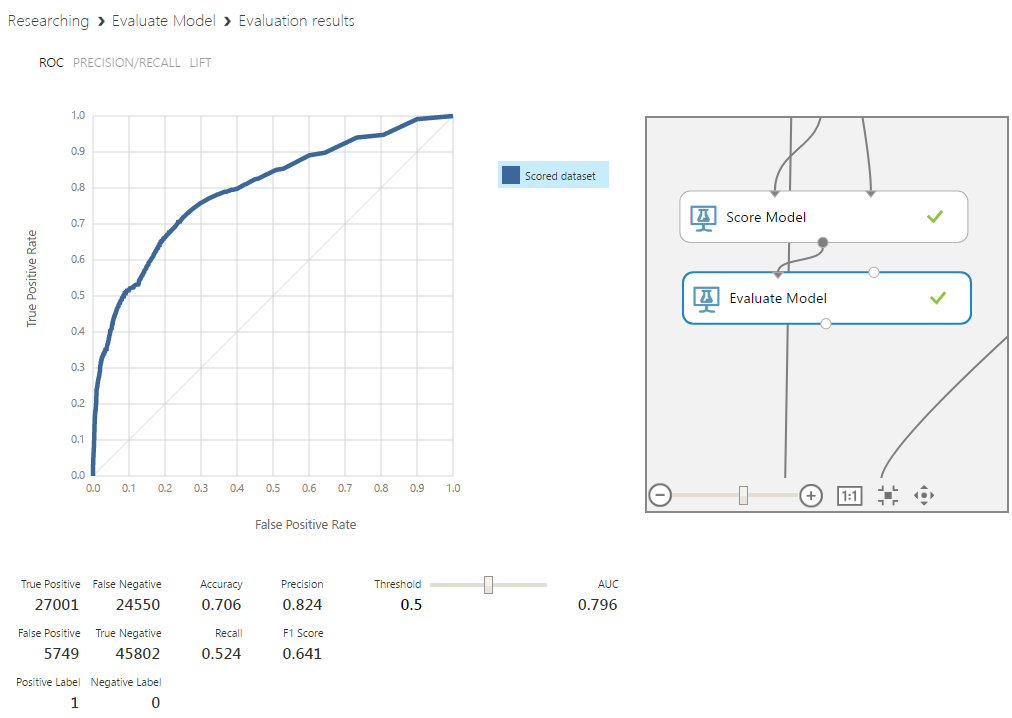
Этот алгоритм был использован в прототипе модели, поэтому сравнение будет наиболее показательно. Даже без настройки границы определения классов и с небольшими добавками в вектор входных признаков, процент верно предсказанных пиков увеличился на 5%, а их отсутствия — на 15%. Такой важный показатель, как площадь под кривой этого графика, тоже существенно вырос. Этот параметр отражает, насколько хорошо при разных граничных значениях соотносятся друг с другом значения классов. Чем дальше кривая находится от диагонали — тем лучше.
 Параметры:
Параметры:

По графику видно, что это не самый удачный алгоритм для данной задачи. Точность и площадь под кривой низкие. К тому же, сама кривая имеет нестабильный характер, что могло бы быть допустимо для прототипа, но не для модели с обработанными данными.
 Параметры:
Параметры:
Байесовский классификатор показал результаты, очень похожие на результаты логистической регрессии. Поскольку регрессия более простая, между ними остановимся на ней.
В каждом дереве используется случайное подмножество признаков размера m (m — настраиваемый параметр, однако часто предлагается использовать значение, близкое к корню из размера исходного вектора признаков). Классификация проходит через голосование. Класс, получивший наибольшее количество голосов, побеждает.
 Параметры:
Параметры:
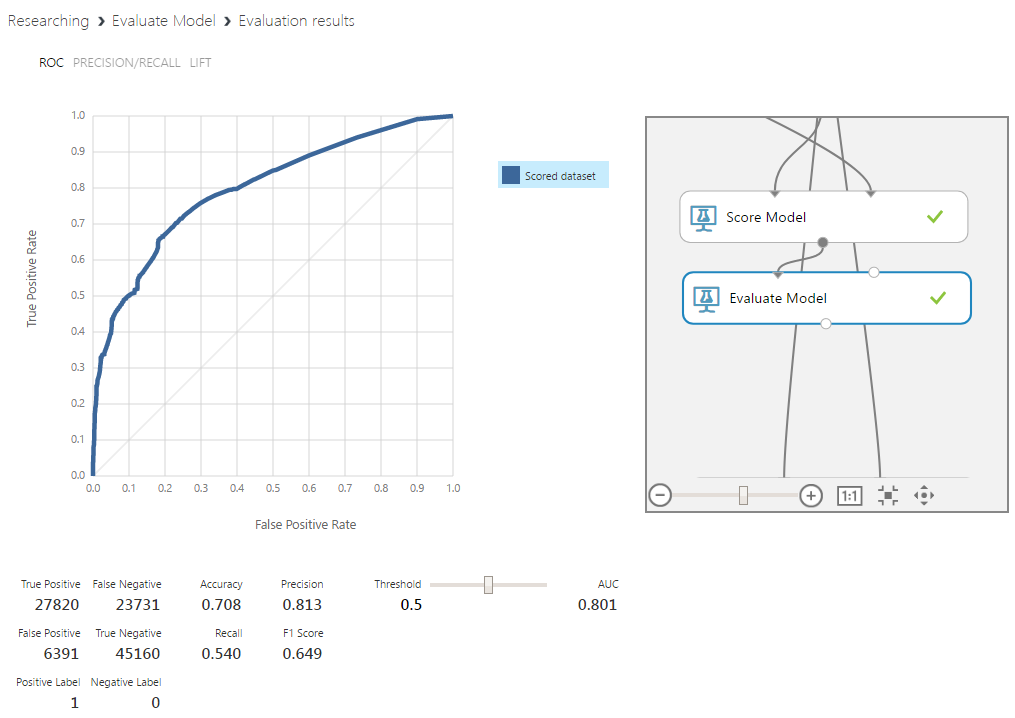
Random forest оказался наиболее результативным алгоритмом, дав прирост к определению пиков на 8% и их отсутствия на 13%. Немаловажным в контексте задачи является и лучшая интерпретируемость причин определения данных к какому-либо из классов. Конечно, этот алгоритм в целом является черным ящиком, однако для него есть относительно несложные способы извлечения необходимой информации.
Во всех описанных выше алгоритмах, кроме байесовских сетей, есть параметр “create trainer mode”. Выставив его на Parameter Range, можно включить режим, в котором алгоритм обучится на различных вариантах комбинаций параметров в пределах заданных диапазонов, и выдаст лучший вариант. Эту особенность осветим позже.
Возьмем алгоритм, показавший лучшие результаты среди остальных — Random Forest.
 По всем выборкам результат устойчивый и достаточно высокий. Модель имеет хорошую способность к обобщению, а на обучение подается достаточное количество данных.
По всем выборкам результат устойчивый и достаточно высокий. Модель имеет хорошую способность к обобщению, а на обучение подается достаточное количество данных.
Полученные результаты говорят о явном улучшении точности и стабильности модели. В заключительной статье мы затронем вопросы переобучения, статистических выбросов и комитетов.
Цикл статей «Машинное обучение для страховой компании»
1. Реалистичность идеи2. Исследуем алгоритмы
3. Оптимизация модели
Использование возможности встраивания скриптов Python в Azure для предобработки данных
В первой статье мы говорили о том, что Azure поддерживает использование Python-скриптов. Необходимый для этого модуль может принимать на вход два массива данных и zip-архив с дополнительными материалами (например, другими скриптами, библиотеками и пр).Простой пример: в первой статье в конечной оценке была ремарка о несбалансированной по классам тестовой выборке. Исправить ситуацию можно, введя в схему несложный скрипт, который отфильтрует лишние строки во всей выборке. В качестве демонстрации сделаем это следующим способом (возможны и другие).
Модуль возвращает измененный массив данных, в котором (как будет видно позже) содержится равное для обоих классов количество записей.Анализ используемых данных. Использование MS Analysis Service
Практически в любой задаче машинного обучения необработанные данные не дают удовлетворительного результата. Для выделения наиболее информативных для модели признаков потребуется data mining.В прототипе, о котором шла речь в предыдущей статье, было использовано два типа данных: количество посещений пациентом врача за последние три месяца и последняя потраченная на этот визит сумма. Для начала добавим:
- возраст;
- id диагнозов;
- количество пиков затрат за последние 3 месяца.
Однако так мы только увеличим количество признаков, никак их не обработав. Для этого используем MS Analysis Services, в котором для извлечения признаков применяется машинное обучение — в частности, упрощенный алгоритм Байеса.
По результатам можно выбрать границы для бинарного представления входных данных. Например, «возраст младше 19» и «количество обращений к врачу меньше 5» свидетельствуют о большей вероятности отсутствия пика. В то время как «возраст старше 64» и «количество обращений больше 14» чреваты затратами в следующем месяце. Можно получить список диагнозов, которые чаще других предшествуют большим тратам.
Это только часть выбранных диагнозов. В каждом из диагнозов, с вероятностью от 85% до 100%, последует пик затрат. Их наличие стоит вынести в отдельный признак. Не стоит упускать и наличие обычных диагнозов, которые не обойдутся компании дорого. Поэтому следует провести нормировку найденных вероятностей и ввести новый признак, который будет представлять собой взвешенную сумму количества диагнозов за последние 90 дней.В результате получено семь параметров в векторе входных признаков. Сравним их с тем, что было получено в прошлый раз с использованием разных алгоритмов.
Тестирование различных алгоритмов и выставление их параметров
Мы определись с параметрами, которые будут использованы для обучения. Рассмотрим несколько разных алгоритмов классификации: logistic regression, support vector machine, decision jungle/random forest, Bayesian network. Очевидным вариантом также являются нейронные сети, но это отдельная сложная тема и в данном случае этот алгоритм будет излишним.Поскольку была проведена фильтрация данных для получения сбалансированной выборки, граничное значение для присвоения классов пока менять не будем. К этому вопросу мы вернемся в следующей статье.
Logistic regression
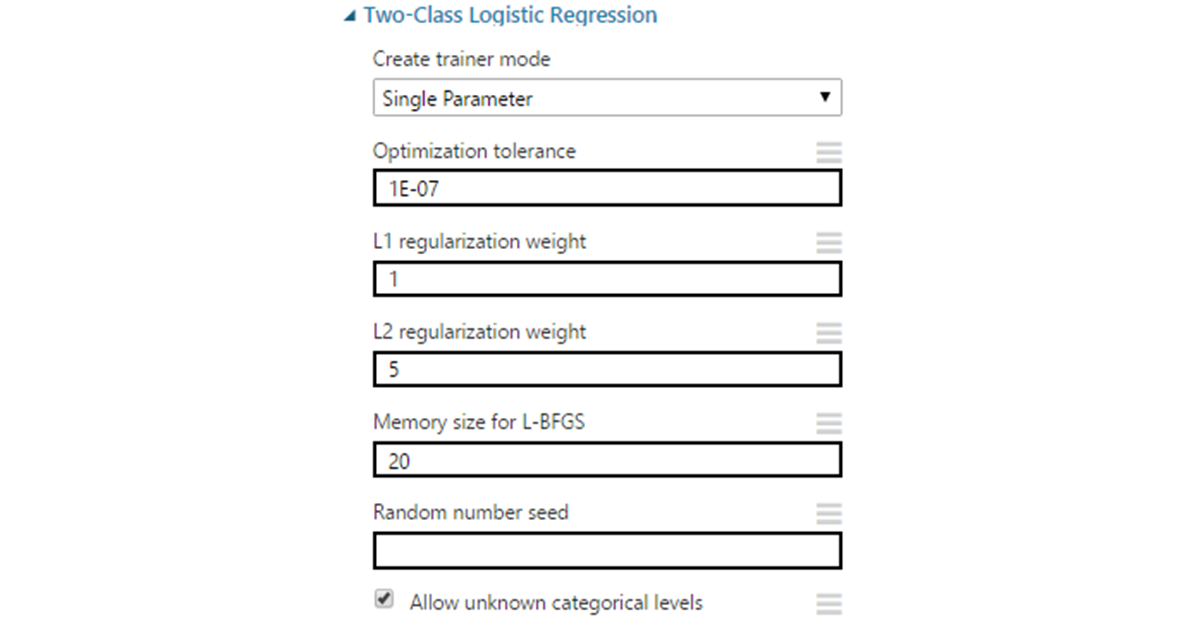
Это частный случай линейного регрессора, приспособленного к задачам классификации. Алгоритм уже упоминался в первой статье, где он использовался для построения простейшей модели в качестве прототипа.На начальном этапе он позволяет получить исходное значение в промежутке от минус до плюс бесконечности. Далее осуществим преобразование, используя сигмоидальную функцию вида 1/(1+e^(-score) ),, где score — это полученное ранее значение, осуществляем преобразование. Результатом будет число в пределах от -1 до +1. Решение о принадлежности к классу принимается на основании выбранного порогового значения.
Параметры:- Optimization tolerance — граница для минимального изменения точности. Если разница между итерациями становится меньше указанного значения, обучение останавливается. В большинстве случаев можно оставить значение по умолчанию равное 1Е-7.
- L1 & L2 regularization — регуляризация по нормам 1 и 2 порядка. L1 используется для уменьшения размерности входных данных через удаление признаков, наименее влияющих на результат. L2 «штрафует» признаки c большими коэффициентами, сводя эти коэффициенты к нулю на бесконечности. Указанные значения являются коэффициентами для норм и для начала могут по умолчанию оставаться равными 1.
- L-BFGS — метод оптимизации для нахождения локального максимума (минимума) нелинейного функционала без ограничений с ограниченной памятью. Это квазиньютоновский метод (основанный на накоплении информации о кривизне целевой функции по изменению ее градиента), используемый для взвешивания параметров модели. Тут выбор зависит от предпочтений: выставляемое значение влияет на количество данных, используемых для инверсии гессиана функции. По сути, берется указанное количество последних векторов. Увеличение этого значения улучшает точность. Улучшает до определенных пределов (не следует также забывать про переобучение). При этом может сильно увеличить время выполнения, поэтому часто выставляется в окрестности 10.
- Random seed можно выставить в случае необходимости получения одинаковых результатов на разных запусках алгоритма.
Этот алгоритм был использован в прототипе модели, поэтому сравнение будет наиболее показательно. Даже без настройки границы определения классов и с небольшими добавками в вектор входных признаков, процент верно предсказанных пиков увеличился на 5%, а их отсутствия — на 15%. Такой важный показатель, как площадь под кривой этого графика, тоже существенно вырос. Этот параметр отражает, насколько хорошо при разных граничных значениях соотносятся друг с другом значения классов. Чем дальше кривая находится от диагонали — тем лучше.
Support Vector Machine
Метод опорных векторов входит в группу линейных классификаторов, хотя некоторые модификации в основную часть алгоритма позволяют строить и нелинейные классификаторы. Суть заключается в переводе исходных данных в более высокую размерность и построении разделяющей гиперплоскости. Увеличение размерности необходимо, так как исходные вектора часто линейно неразделимы. После перевода гиперплоскость ищется с условием максимального зазора до гиперплоскостей, обозначающих границу классов. Параметры:- Number of iterations — количество итераций обучения алгоритма. Представляет собой параметр для размена точности и скорости алгоритма. Для начала можно поставить значение в диапазоне от 1 до 10.
- Lambda — аналог веса для L1 в логистической регрессии
- Normalize features — нормализация данных перед обучением. В связи со спецификой метода в большинстве случаев следует оставить параметр включенным по умолчанию.
- Project to unit sphere — нормализация коэффициентов. Этот параметр опционален и чаще всего его использование не понадобится.
- Allow unknown category — по умолчанию включенный параметр, который позволяет обработку неизвестных модели параметров. Он ухудшает работу модели с теми данными, которые известны классификатору, при этом улучшает точность для неизвестных.
- Random seed — аналогично с логистической регрессией.
По графику видно, что это не самый удачный алгоритм для данной задачи. Точность и площадь под кривой низкие. К тому же, сама кривая имеет нестабильный характер, что могло бы быть допустимо для прототипа, но не для модели с обработанными данными.
Bayesian network
Байесовские сети — это вероятностная модель данных, представленная в виде ациклического направленного графа. Вершинами графа являются переменные, отражающие истинность некоего суждения, а ребра — степень зависимости между ними. Настройка модели заключается в подборе этих переменных и взаимосвязи между ними. В нашем случае, конечным оцениваемым суждением, на котором сходится граф, будет наличие пика затрат. Параметры:- Number of training iterations — аналогично параметру в SVM.
- Include bias — введение постоянной величины во входные параметры модели. Это необходимо, когда ее нет в исходном векторе.
- Allow unknown values — аналогично параметру в SVM.
Байесовский классификатор показал результаты, очень похожие на результаты логистической регрессии. Поскольку регрессия более простая, между ними остановимся на ней.
Random Forest
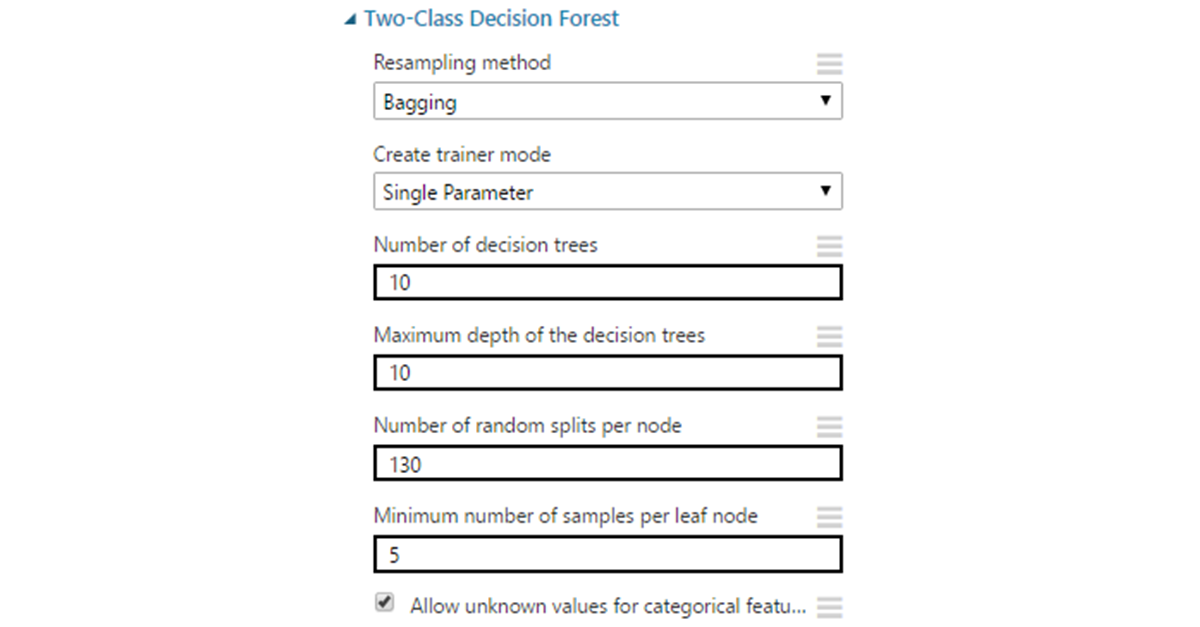
Этот метод представляет собой комитет классических деревьев решений. В данном алгоритме деревья не подвергаются прунингу (прунинг — метод снижения сложности модели через урезание ветвей дерева после того, как оно полностью построено). Тем не менее, условия ранней остановки остаются. Разнообразие достигается за счет выбора случайных подмножеств исходных данных. Размер остается тем же, но в этих подмножествах допускаются повторные использования одних и тех же данных.В каждом дереве используется случайное подмножество признаков размера m (m — настраиваемый параметр, однако часто предлагается использовать значение, близкое к корню из размера исходного вектора признаков). Классификация проходит через голосование. Класс, получивший наибольшее количество голосов, побеждает.
Параметры:- Resampling method по умолчанию выставлен на bagging, что дает для каждого дерева уникальную выборку данных описанным выше способом. Можно также выставить replicate, если есть необходимость обучать все деревья на одинаковых данных.
- Number of decision trees. Увеличение количества деревьев может дать большее покрытие выборки, но не всегда, и ценой увеличения времени обучения.
- Maximum depth — максимальная глубина дерева. Значение по умолчанию — 32 — достаточно большое и во многих ситуациях приведет к переобучению. Чаще всего нет необходимости делать глубину больше десяти.
- Number of random splits per node — определяет количество случайных разделений признаков при построении вершин. Слишком большое количество может привести к переобучению, поэтому стоит для начала ограничиться значением в пределах от 10 до 30.
- Minimum number of samples per leaf node — минимальное количество записей для образования «листа» (вершины которая уже не подлежит разделению на ветви). Практически никогда нет смысла оставлять в этом месте 1, поскольку подобные листья избыточны и часто приводят модель к переобучению.
- Allow unknown values — аналогично с SVM.
Random forest оказался наиболее результативным алгоритмом, дав прирост к определению пиков на 8% и их отсутствия на 13%. Немаловажным в контексте задачи является и лучшая интерпретируемость причин определения данных к какому-либо из классов. Конечно, этот алгоритм в целом является черным ящиком, однако для него есть относительно несложные способы извлечения необходимой информации.
Во всех описанных выше алгоритмах, кроме байесовских сетей, есть параметр “create trainer mode”. Выставив его на Parameter Range, можно включить режим, в котором алгоритм обучится на различных вариантах комбинаций параметров в пределах заданных диапазонов, и выдаст лучший вариант. Эту особенность осветим позже.
Использование cross-validation для проверки variance
Кросс-валидационная оценка может использоваться для решения различных задач. Например, ее используют для борьбы с переобучением в условиях малого количества данных для выделения отдельной валидационной выборки. Сейчас она потребуется в качестве инструмента для проверки способности текущей модели к обобщению. Для этого разделим данные на десять частей и рассмотрим каждую из них как тестовую. Далее необходимо будет обучить модель на каждом варианте разделения.Возьмем алгоритм, показавший лучшие результаты среди остальных — Random Forest.
По всем выборкам результат устойчивый и достаточно высокий. Модель имеет хорошую способность к обобщению, а на обучение подается достаточное количество данных.Итог
Во этой части из цикла статей о машинном обучении мы рассмотрели:- Встраивание Python-скриптов в общую схему проекта на примере получения уравновешенной по классам выборки данных.
- Использование MS Analysis Services для извлечения новых признаков из сырых данных.
- Кросс-валидацию модели для оценки стабильности результата и полноты данных в обучающей выборке.
Полученные результаты говорят о явном улучшении точности и стабильности модели. В заключительной статье мы затронем вопросы переобучения, статистических выбросов и комитетов.
Об авторах
Команда WaveAccess создаёт технически сложное, высоконагруженное и отказоустойчивое программное обеспечение для компаний из разных стран. Комментарий Александра Азарова, руководителя направления machine learning в WaveAccess:Машинное обучение позволяет автоматизировать области, где на текущий момент доминируют экспертные мнения. Это дает возможность снизить влияние человеческого фактора и повысить масштабируемость бизнеса.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru