LSTM – сети долгой краткосрочной памяти
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-06-21 14:04
Рекуррентные нейронные сети
Люди не начинают думать с чистого листа каждую секунду. Читая этот пост, вы понимаете каждое слово, основываясь на понимании предыдущего слова. Мы не выбрасываем из головы все и не начинаем думать с нуля. Наши мысли обладают постоянством.
Традиционные нейронные сети не обладают этим свойством, и в этом их главный недостаток. Представим, например, что мы хотим классифицировать события, происходящие в фильме. Непонятно, как традиционная нейронная сеть могла бы использовать рассуждения о предыдущих событиях фильма, чтобы получить информацию о последующих.
Решить эту проблемы помогают рекуррентые нейронные сети (Recurrent Neural Networks, RNN). Это сети, содержащие обратные связи и позволяющие сохранять информацию.

На схеме выше фрагмент нейронной сети принимает входное значение и возвращает значение . Наличие обратной связи позволяет передавать информацию от одного шага сети к другому.
Обратные связи придают рекуррентным нейронным сетям некую загадочность. Тем не менее, если подумать, они не так уж сильно отличаются от обычных нейронных сетей. Рекуррентную сеть можно рассматривать, как несколько копий одной и той же сети, каждая из которых передает информацию последующей копии. Вот, что произойдет, если мы развернем обратную связь:
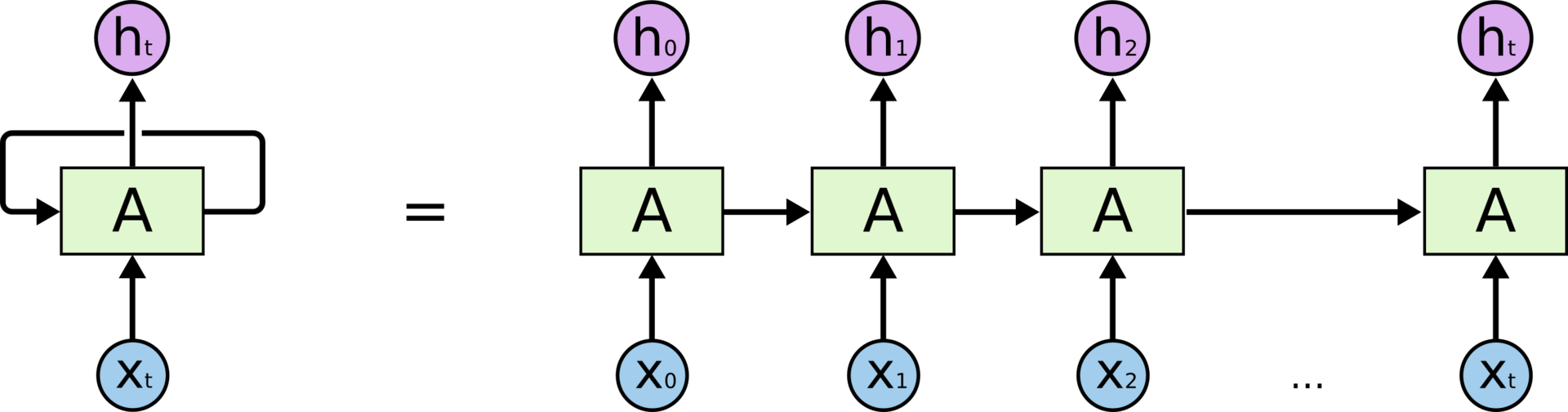 Рекуррентная нейронная сеть в развертке
Рекуррентная нейронная сеть в разверткеТо, что RNN напоминают цепочку, говорит о том, что они тесно связаны с последовательностями и списками. RNN – самая естественная архитектура нейронных сетей для работы с данными такого типа.
И конечно, их используют для подобных задач. За последние несколько лет RNN с невероятным успехом применили к целому ряду задач: распознавание речи, языковое моделирование, перевод, распознавание изображений… Список можно продолжать. О том, чего можно достичь с помощью RNN, рассказывает отличный блог-пост Андрея Карпатого (Andrej Karpathy) The Unreasonable Effectiveness of Recurrent Neural Networks.
Немалая роль в этих успехах принадлежит LSTM – необычной модификация рекуррентной нейронной сети, которая на многих задачах значительно превосходит стандартную версию. Почти все впечатляющие результаты RNN достигнуты именно с помощью LSTM. Им-то и посвящена наша статья.
Проблема долговременных зависимостей
Одна из привлекательных идей RNN состоит в том, что они потенциально умеют связывать предыдущую информацию с текущей задачей, так, например, знания о предыдущем кадре видео могут помочь в понимании текущего кадра. Если бы RNN обладали такой способностью, они были бы чрезвычайно полезны. Но действительно ли RNN предоставляют нам такую возможность? Это зависит от некоторых обстоятельств.
Иногда для выполнения текущей задачи нам необходима только недавняя информация. Рассмотрим, например, языковую модель, пытающуюся предсказать следующее слово на основании предыдущих. Если мы хотим предсказать последнее слово в предложении “облака плывут по небу”, нам не нужен более широкий контекст; в этом случае довольно очевидно, что последним словом будет “небу”. В этом случае, когда дистанция между актуальной информацией и местом, где она понадобилась, невелика, RNN могут обучиться использованию информации из прошлого.
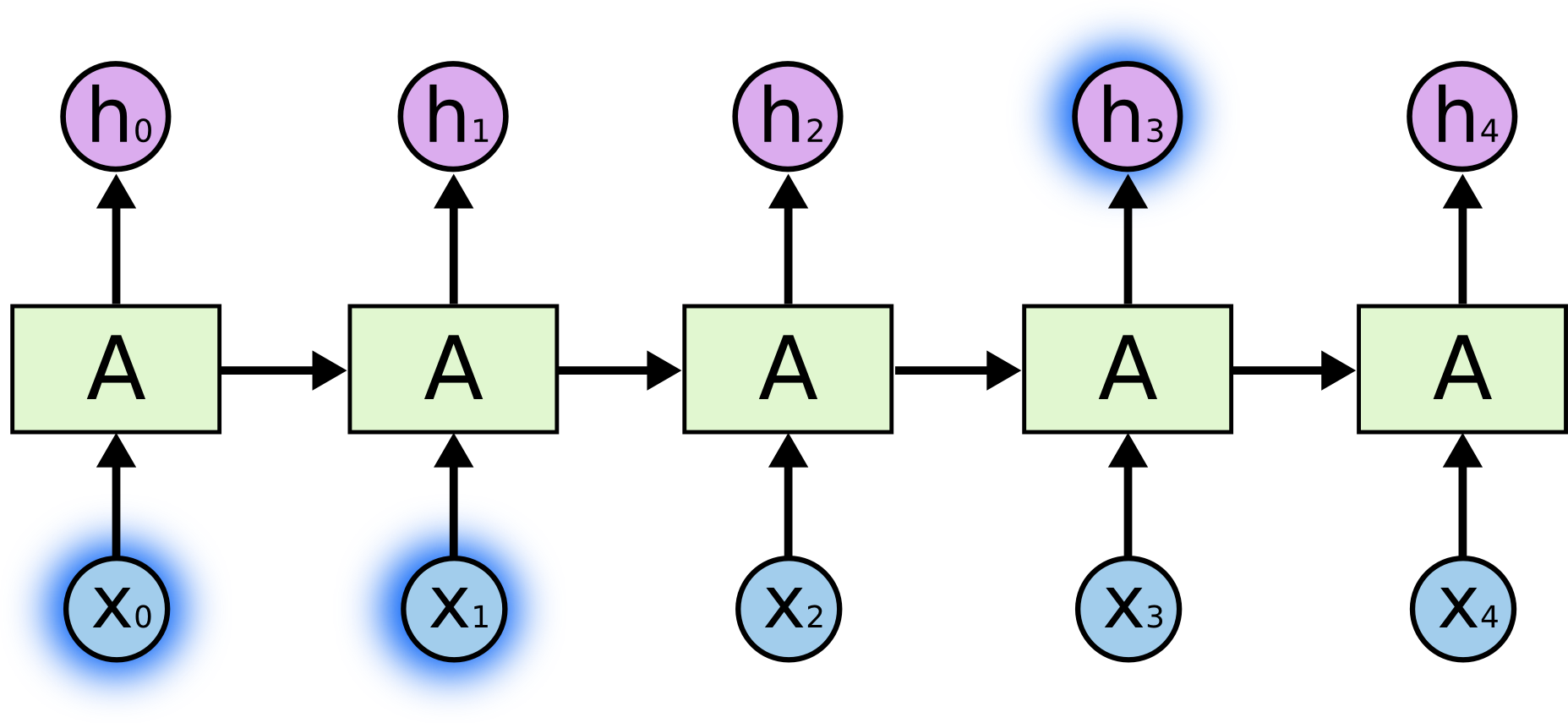 Но бывают случаи, когда нам необходимо больше контекста. Допустим, мы хотим предсказать последнее слово в тексте “Я вырос во Франции… Я бегло говорю по-французски”. Ближайший контекст предполагает, что последним словом будет называние языка, но чтобы установить, какого именно языка, нам нужен контекст Франции из более отдаленного прошлого. Таким образом, разрыв между актуальной информацией и точкой ее применения может стать очень большим.
Но бывают случаи, когда нам необходимо больше контекста. Допустим, мы хотим предсказать последнее слово в тексте “Я вырос во Франции… Я бегло говорю по-французски”. Ближайший контекст предполагает, что последним словом будет называние языка, но чтобы установить, какого именно языка, нам нужен контекст Франции из более отдаленного прошлого. Таким образом, разрыв между актуальной информацией и точкой ее применения может стать очень большим.К сожалению, по мере роста этого расстояния, RNN теряют способность связывать информацию.
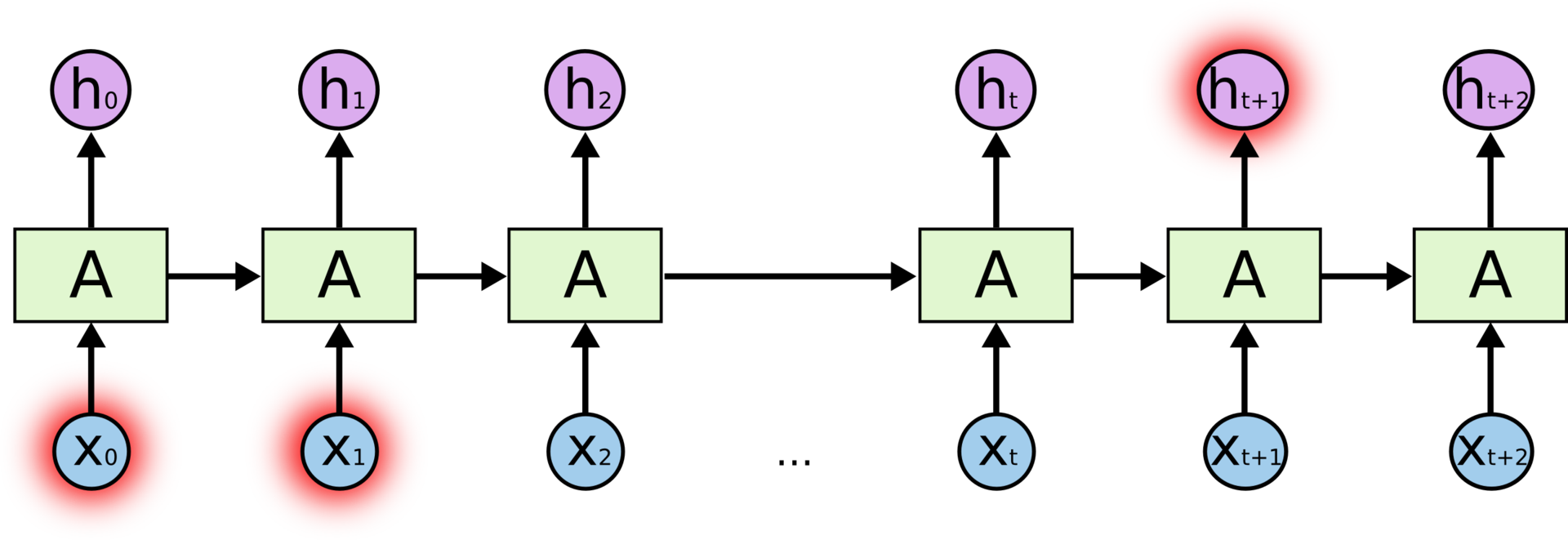 В теории проблемы с обработкой долговременных зависимостей у RNN быть не должно. Человек может аккуратно подбирать параметры сети для решения искусственные задачи такого типа. К сожалению, на практике обучить RNN этим параметрам кажется невозможным. Эту проблему подробно исследовали Зепп Хохрайтер (Sepp Hochreiter, 1991) и Иошуа Бенджио (Yoshua Bengio) с соавторами (1994); они нашли неоспоримые причины, по которым это может быть сложно.
В теории проблемы с обработкой долговременных зависимостей у RNN быть не должно. Человек может аккуратно подбирать параметры сети для решения искусственные задачи такого типа. К сожалению, на практике обучить RNN этим параметрам кажется невозможным. Эту проблему подробно исследовали Зепп Хохрайтер (Sepp Hochreiter, 1991) и Иошуа Бенджио (Yoshua Bengio) с соавторами (1994); они нашли неоспоримые причины, по которым это может быть сложно.К счастью, LSTM не знает таких проблем!
Сети LSTM
Долгая краткосрочная память (Long short-term memory; LSTM) – особая разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долговременным зависимостям. Они были представлены Зеппом Хохрайтер и Юргеном Шмидхубером (J?rgen Schmidhuber) в 1997 году, а затем усовершенствованы и популярно изложены в работах многих других исследователей. Они прекрасно решают целый ряд разнообразных задач и в настоящее время широко используются.
LSTM разработаны специально, чтобы избежать проблемы долговременной зависимости. Запоминание информации на долгие периоды времени – это их обычное поведение, а не что-то, чему они с трудом пытаются обучиться.
Любая рекуррентная нейронная сеть имеет форму цепочки повторяющихся модулей нейронной сети. В обычной RNN структура одного такого модуля очень проста, например, он может представлять собой один слой с функцией активации tanh (гиперболический тангенс).
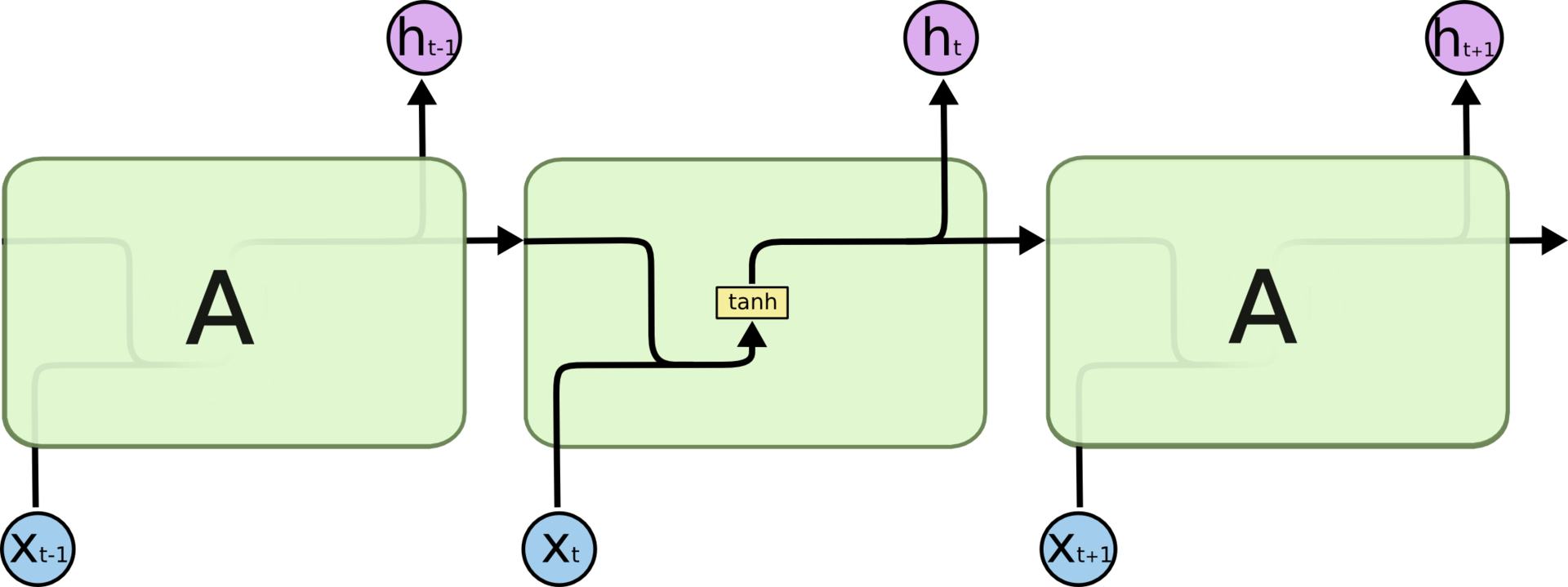 Повторяющийся модуль в стандартной RNN состоит из одного слоя.
Повторяющийся модуль в стандартной RNN состоит из одного слоя.Структура LSTM также напоминает цепочку, но модули выглядят иначе. Вместо одного слоя нейронной сети они содержат целых четыре, и эти слои взаимодействуют особенным образом.
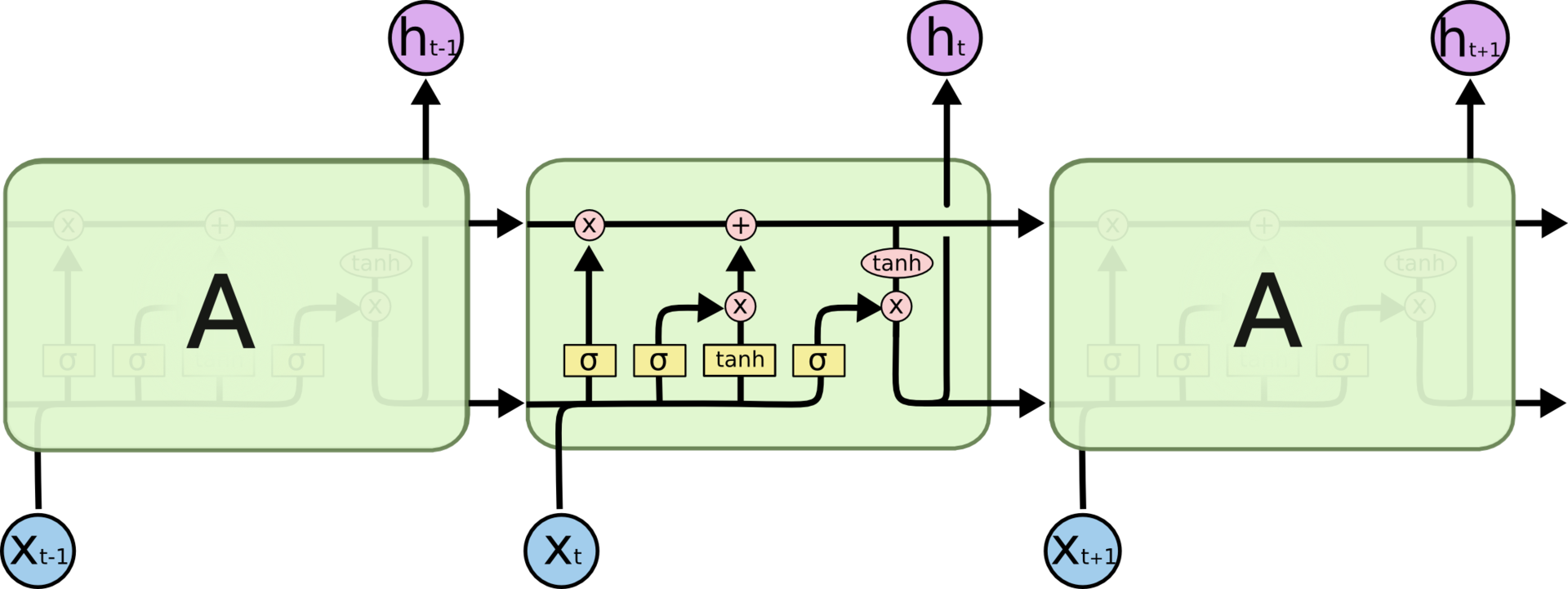 Повторяющийся модель в LSTM сети состоит из четырех взаимодействующих слоев.
Повторяющийся модель в LSTM сети состоит из четырех взаимодействующих слоев.Не будем пока озадачиваться подробностями. Рассмотрим каждый шаг схемы LSTM позже. Пока познакомимся со специальными обозначениями, которыми мы будем пользоваться.
 Слой нейронной сети; поточечная операция; векторный перенос; объединение; копирование.
Слой нейронной сети; поточечная операция; векторный перенос; объединение; копирование.На схеме выше каждая линия переносит целый вектор от выхода одного узла ко входу другого. Розовыми кружочками обозначены поточечные операции, такие, как сложение векторов, а желтые прямоугольники – это обученные слои нейронной сети. Сливающиеся линии означают объединение, а разветвляющиеся стрелки говорят о том, что данные копируются и копии уходят в разные компоненты сети.
Основная идея LSTM
Ключевой компонент LSTM – это состояние ячейки (cell state) – горизонтальная линия, проходящая по верхней части схемы.
Состояние ячейки напоминает конвейерную ленту. Она проходит напрямую через всю цепочку, участвуя лишь в нескольких линейных преобразованиях. Информация может легко течь по ней, не подвергаясь изменениям.
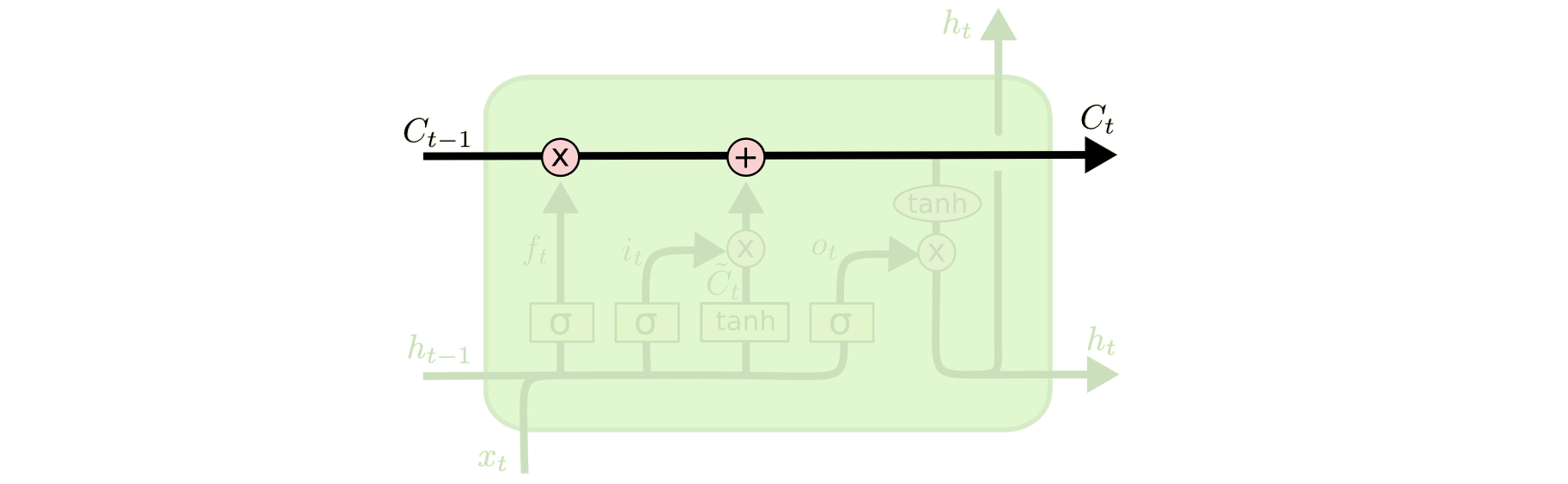 Тем не менее, LSTM может удалять информацию из состояния ячейки; этот процесс регулируется структурами, называемыми фильтрами (gates).
Тем не менее, LSTM может удалять информацию из состояния ячейки; этот процесс регулируется структурами, называемыми фильтрами (gates).Фильтры позволяют пропускать информацию на основании некоторых условий. Они состоят из слоя сигмоидальной нейронной сети и операции поточечного умножения.
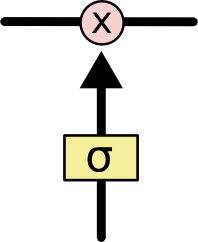 Сигмоидальный слой возвращает числа от нуля до единицы, которые обозначают, какую долю каждого блока информации следует пропустить дальше по сети. Ноль в данном случае означает “не пропускать ничего”, единица – “пропустить все”.
Сигмоидальный слой возвращает числа от нуля до единицы, которые обозначают, какую долю каждого блока информации следует пропустить дальше по сети. Ноль в данном случае означает “не пропускать ничего”, единица – “пропустить все”.В LSTM три таких фильтра, позволяющих защищать и контролировать состояние ячейки.
Пошаговый разбор LSTM
Первый шаг в LSTM – определить, какую информацию можно выбросить из состояния ячейки. Это решение принимает сигмоидальный слой, называемый “слоем фильтра забывания” (forget gate layer). Он смотрит на и и возвращает число от 0 до 1 для каждого числа из состояния ячейки . 1 означает “полностью сохранить”, а 0 – “полностью выбросить”.
Вернемся к нашему примеру – языковой модели, предсказывающей следующее слово на основании всех предыдущих. В этом случае состояние ячейки должно сохранить существительного, чтобы затем использовать местоимения соответствующего рода. Когда мы видим новое существительное, мы можем забыть род старого.
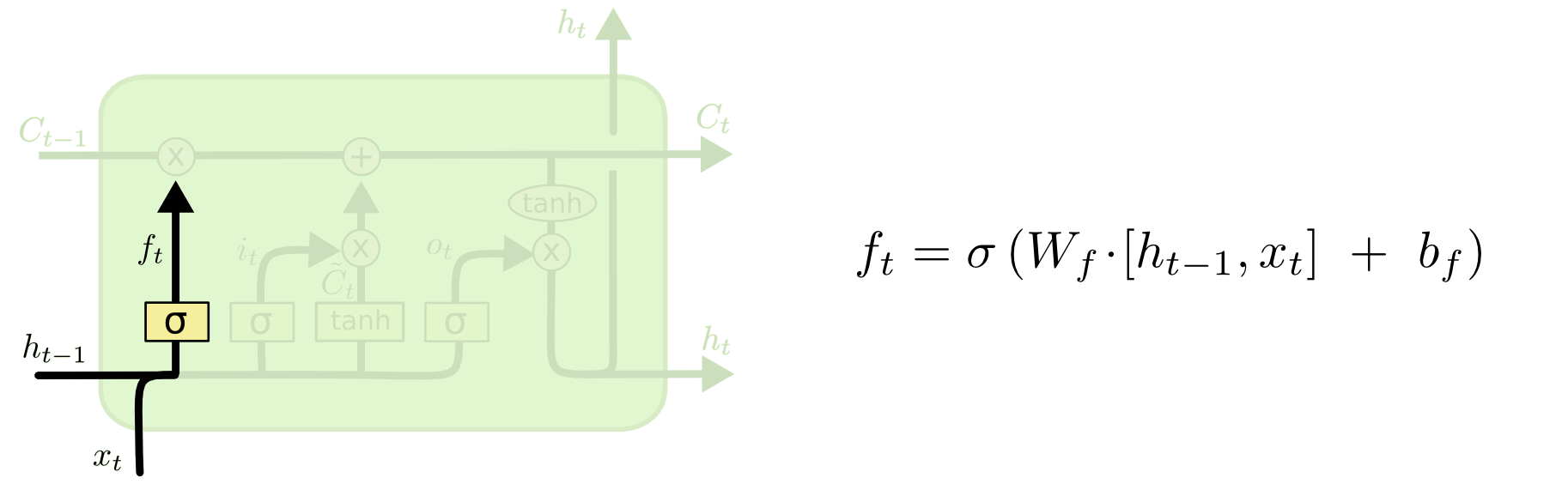 Следующий шаг – решить, какая новая информация будет храниться в состоянии ячейки. Этот этап состоит из двух частей. Сначала сигмоидальный слой под названием “слой входного фильтра” (input layer gate) определяет, какие значения следует обновить. Затем tanh-слой строит вектор новых значений-кандидатов , которые можно добавить в состояние ячейки.
Следующий шаг – решить, какая новая информация будет храниться в состоянии ячейки. Этот этап состоит из двух частей. Сначала сигмоидальный слой под названием “слой входного фильтра” (input layer gate) определяет, какие значения следует обновить. Затем tanh-слой строит вектор новых значений-кандидатов , которые можно добавить в состояние ячейки.В нашем примере с языковой моделью на этом шаге мы хотим добавить род нового существительного, заменив при этом старый.
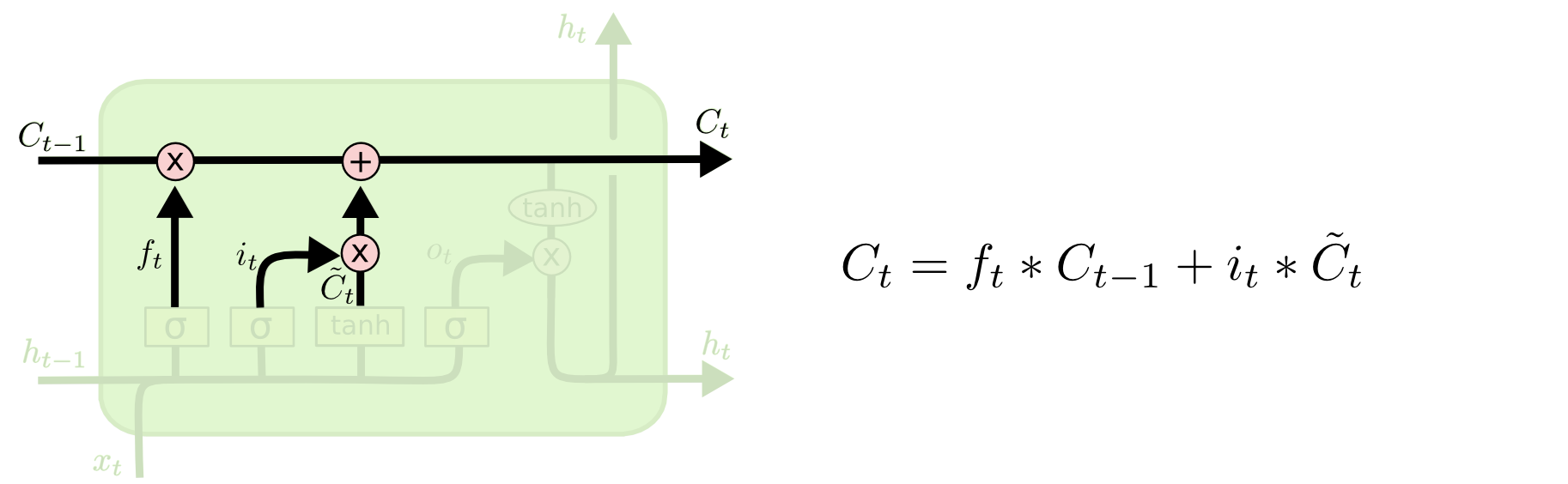
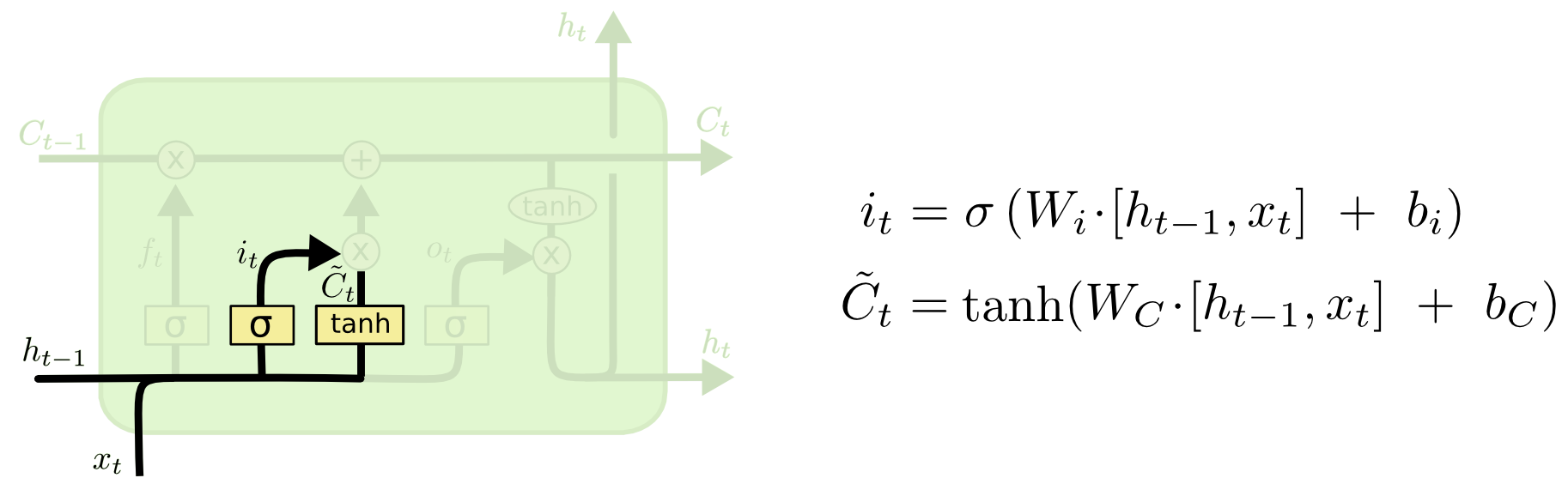 Настало время заменить старое состояние ячейки на новое состояние . Что нам нужно делать — мы уже решили на предыдущих шагах, остается только выполнить это.
Настало время заменить старое состояние ячейки на новое состояние . Что нам нужно делать — мы уже решили на предыдущих шагах, остается только выполнить это.Мы умножаем старое состояние на , забывая то, что мы решили забыть. Затем прибавляем . Это новые значения-кандидаты, умноженные на – на сколько мы хотим обновить каждое из значений состояния.
В случае нашей языковой модели это тот момент, когда мы выбрасываем информацию о роде старого существительного и добавляем новую информацию.
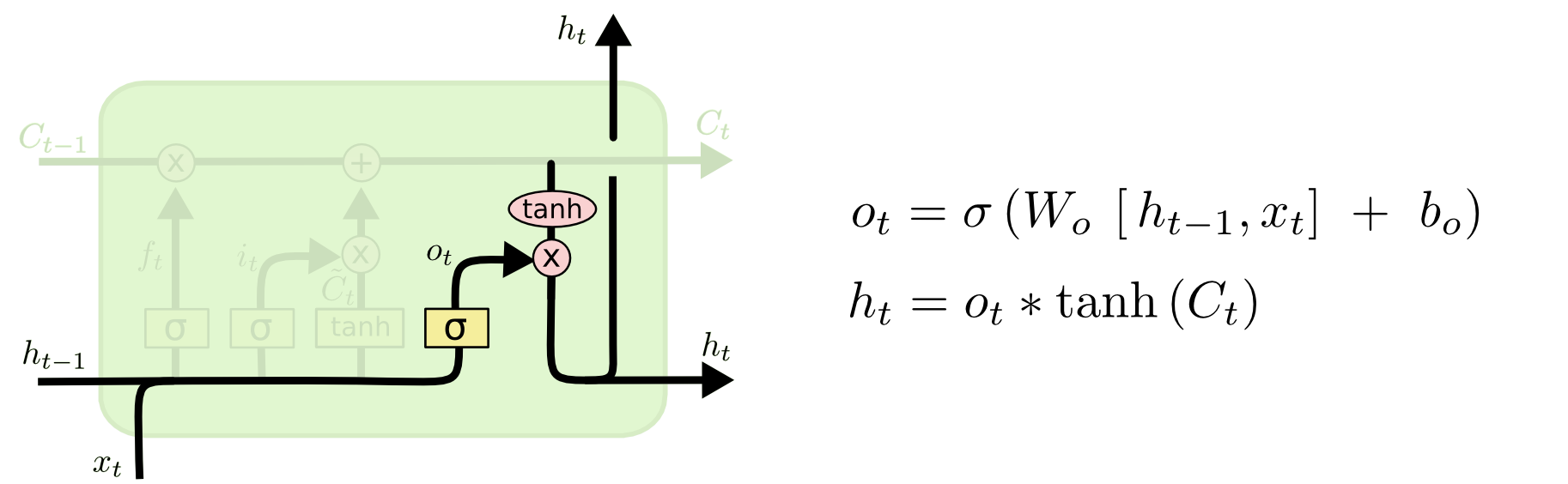
 Наконец, нужно решить, какую информацию мы хотим получать на выходе. Выходные данные будут основаны на нашем состоянии ячейки, к ним будут применены некоторые фильтры. Сначала мы применяем сигмоидальный слой, который решает, какую информацию из состояния ячейки мы будем выводить. Затем значения состояния ячейки проходят через tanh-слой, чтобы получить на выходе значения из диапазона от -1 до 1, и перемножаются с выходными значениями сигмоидального слоя, что позволяет выводить только требуемую информацию.
Наконец, нужно решить, какую информацию мы хотим получать на выходе. Выходные данные будут основаны на нашем состоянии ячейки, к ним будут применены некоторые фильтры. Сначала мы применяем сигмоидальный слой, который решает, какую информацию из состояния ячейки мы будем выводить. Затем значения состояния ячейки проходят через tanh-слой, чтобы получить на выходе значения из диапазона от -1 до 1, и перемножаются с выходными значениями сигмоидального слоя, что позволяет выводить только требуемую информацию.Мы, возможно, захотим, чтобы наша языковая модель, обнаружив существительное, выводила информацию, важную для идущего после него глагола. Например, она может выводить, находится существительное в единственном или множественном числе, чтобы правильно определить форму последующего глагола.
Вариации LSTM
Мы только что рассмотрели обычную LSTM; но не все LSTM одинаковы. Вообще, кажется, что в каждой новой работе, посвященной LSTM, используется своя версия LSTM. Отличия между ними незначительны, но о некоторых из них стоит упомянуть.
Одна из популярных вариаций LSTM, предложенная Герсом и Шмидхубером (Gers & Schmidhuber, 2000), характеризуется добавлением так называемых “смотровых глазков” (“peephole connections”). С их помощью слои фильтров могут видеть состояние ячейки.
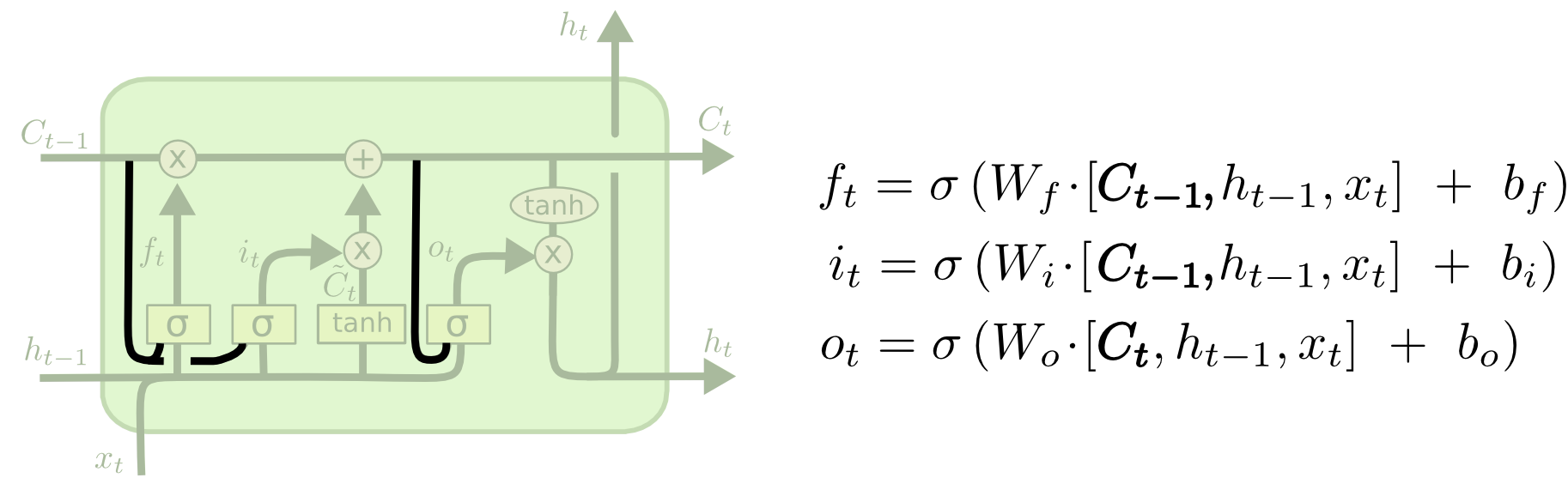 На схеме выше “глазки” есть у каждого слоя, но во многих работах они добавляются лишь к некоторым слоям.
На схеме выше “глазки” есть у каждого слоя, но во многих работах они добавляются лишь к некоторым слоям.Другие модификации включают объединенные фильтры “забывания” и входные фильтры. В этом случае решения, какую информацию следует забыть, а какую запомнить, принимаются не отдельно, а совместно. Мы забываем какую-либо информацию только тогда, когда необходимо записать что-то на ее место. Мы добавляем новую информацию с состояние ячейки только тогда, когда забываем старую.
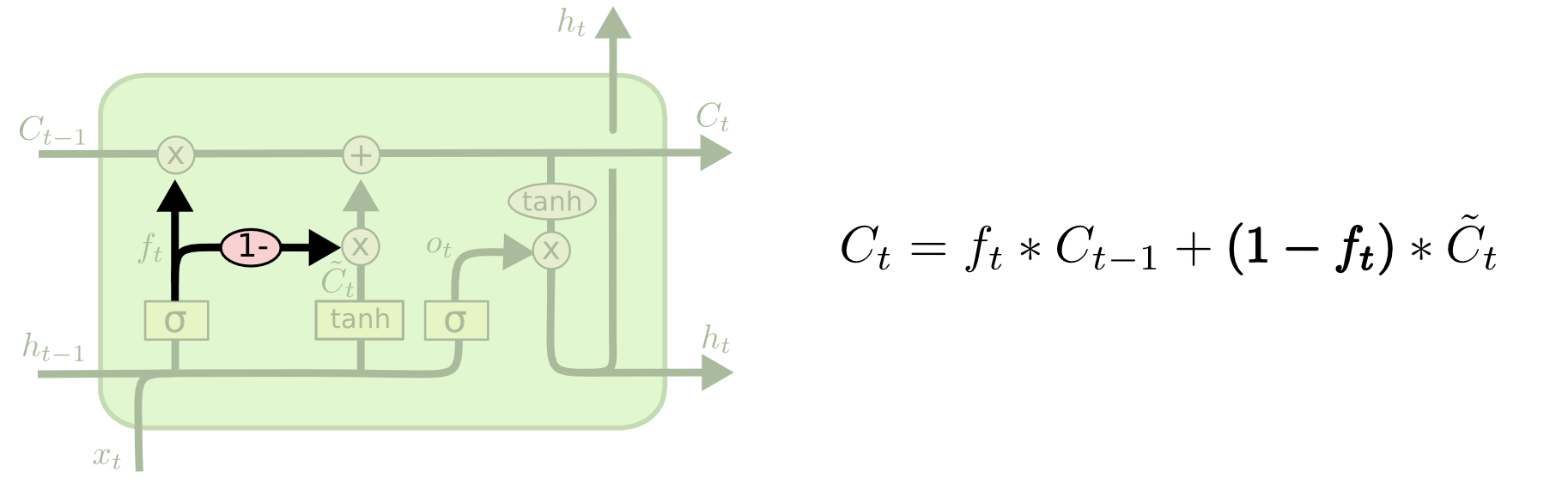 Немного больше отличаются от стандартных LSTM управляемые рекуррентные нейроны (Gated recurrent units, GRU), впервые описанные в работе Cho, et al (2012). В ней фильтры «забывания» и входа объединяют в один фильтр «обновления» (update gate). Кроме того, состояние ячейки объединяется со скрытым состоянием, есть и другие небольшие изменения. Построенная в результате модель проще, чем стандартная LSTM, и популярность ее неуклонно возрастает.
Немного больше отличаются от стандартных LSTM управляемые рекуррентные нейроны (Gated recurrent units, GRU), впервые описанные в работе Cho, et al (2012). В ней фильтры «забывания» и входа объединяют в один фильтр «обновления» (update gate). Кроме того, состояние ячейки объединяется со скрытым состоянием, есть и другие небольшие изменения. Построенная в результате модель проще, чем стандартная LSTM, и популярность ее неуклонно возрастает. Мы рассмотрели лишь несколько самых примечательных вариаций LSTM. Существует множество других модификаций, как, например, глубокие управляемые рекуррентные нейронные сети (Depth Gated RNNs), представленные в работе Yao, et al (2015). Есть и другие способы решения проблемы долговременных зависимостей, например, Clockwork RNN Яна Кутника (Koutnik, et al., 2014).
Мы рассмотрели лишь несколько самых примечательных вариаций LSTM. Существует множество других модификаций, как, например, глубокие управляемые рекуррентные нейронные сети (Depth Gated RNNs), представленные в работе Yao, et al (2015). Есть и другие способы решения проблемы долговременных зависимостей, например, Clockwork RNN Яна Кутника (Koutnik, et al., 2014).Какой же вариант лучший? Какую роль играют различия между ними? Клаус Грефф (Klaus Greff) и соавторы приводят хорошее сравнение самых популярных вариаций LSTM и в своей работе приходят к выводу, что они все приблизительно одинаковы. Рафал Йозефович (Rafal Jozefowicz, et al) в своей работе 2015 года протестировали более десяти тысяч архитектур RNN и нашли несколько решений, работающих на определенных задачах лучше, чем LSTM.
Заключение
Ранее мы упоминали о выдающихся результатах, которые можно достигнуть с использованием RNN. В сущности все эти результаты были получены на LSTM. На большинстве задач они действительно работают лучше.
LSTM, записанные в виде системы уравнений выглядят довольно устрашающе. Надеемся, что пошаговый разбор LSTM в этой статье сделал их более доступными.
LSTM – большой шаг в развитии RNN. При этом возникает естественный вопрос: каким будет следующий большой шаг? По общему мнению исследователей, следующий большой шаг – «внимание» (attention). Идея состоит в следующем: каждый шаг RNN берет данные из более крупного хранилища информации. Например, если мы используем RNN для генерации подписи к изображению, то такая RNN может рассматривать изображение по частям и на основании каждой части генерировать отдельные слова. Работа Келвина Ксу (Xu, et al., 2015), посвященная как раз такой задаче, может служить хорошей отправной точкой для тех, кто хочет изучить такой механизм, как «внимание». Исследователям уже удалось достичь впечатляющих результатов с использованием этого принципа, и, кажется, впереди еще много открытий…
Внимание — не единственная интересная область исследований в RNN. Например, Grid LSTM, описанные в работе Kalchbrenner, et al. (2015), кажутся весьма многообещающими. Исследования использования RNN в порождающих моделях (Gregor, et al. (2015), Chung, et al. (2015) или Bayer & Osendorfer (2015) также чрезвычайно интересны. Последние несколько лет — время расцвета рекуррентных нейронных сетей, и следующие годы обещают принести еще большие плоды.
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
Телеграм: t.me/ainewsline
Источник: habrahabr.ru