Как нам помогают нейронные сети в технической поддержке
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-06-22 11:00

Несмотря на всеобщий хайп вокруг машинного обучения и нейронных сетей, несомненно, сейчас на них действительно стоит обратить особое внимание. Почему? Вот ключевые причины:
- Железо стало гораздо быстрее и можно легко обсчитывать модели на GPU
- Появилась куча неплохих бесплатных фреймворков для нейросетей
- Одурманенные предыдущим хайпом, компании стали собирать бигдату — теперь есть на чем тренироваться!
- Нейронки в некоторых областях приблизились к человеку, а в некоторых — уже превзошли в решении ряда задач (где тут лопаты продают, надо срочно бункер рыть)
Но управлять этим, по прежнему, сложно: много математики, высшей и беспощадной. И либо ты из физмата, либо сиди и решай 2-3 тысячи задачек в течении двух-трех лет, чтобы понимать, о чем идет речь. Разобраться по дороге на собеседование в электричке, полистав книжку «Программирование на PHP/JavaScript за 3 дня» — не получится, ну никак, и списать никто не даст (даже за ящик водки).

Вам не дадут «списать» модель нейросети даже за ящик водки. Часто именно на Ваших данных публично доступная модель работает внезапно плохо и придется разбираться в тервере и матане
Но зато, ууУУ, овладев основами, можно строить разные предсказательные модели, реализующие интересные и мощные алгоритмы. И вот тут язык начинает заворачиваться и выпадать изо рта, цепляя левый глаз…
Красота теории и практика
Даже в такой, казалось бы, интуитивно понятной и прикладной до уровня «АК-47» области, как обработка реляционных данных, крупная и очень известная компания IBM в свое время замучилась и, по сути, «выдавила» старика Кодда, знаменитого создателя «языка для базок», для прогулок на все четыре стороны. Что же произошло? Кодд утверждал, что SQL, распространяемый IBM — это зло, он не строг и не полон и не соответствует строгой и красивой теории :-) Тем не менее, мы же все пользуемся SQL до сих пор и… ничего, живые.
Примерно то же происходит сейчас и с машинным обучением. С одной стороны еженедельно или, даже, чаще, выходят окрыляющие научные публикации на тему внезапной победы ГироДраконов (имеющих в физиологических шариках — гироскопы) над ГиперКашалотами в Тьюринг-пространствах в созвездии Маленького Принца, массово появляются бесплатные прототипы на github и в дистрибутивах нейронных фреймворков, которые понимают смысл вопроса на 5% лучше предыдущих прототипов — но, по сути, продолжая ни черта не понимать суть. Одновременно с этим, путем сильнейшего группового насилия над нейросетью и самой идеей обучения с подкреплением в пространствах огромной размерности — она вдруг начинает обыигрывать Atari в двумерные игры и про победу нейросетей над чемпионами в Go, наверно, все давно знают уже. А с другой, бизнес начинает осознавать, что область еще очень сырая, находится в фазе бурного роста и прикладных, эффективно решающих задачи людей кейсов еще очень мало — хотя они, безусловно, есть и просто поражают. К сожалению, гораздо больше академических игрушек: нейронки старят лица, генерят порно (не гуглите, потеряете потенцию на сутки) и создают глючную верстку по дизайну веб-страниц.

А может взять и пригласить эту созданную нейронной сетью девушку на свидание? Потрясающий опыт, запомнится на всю жизнь.
А реальный, потрясающий успех в некоторых сферах, таких как, например, распознавание образов, достигнут ценой обучения огромных сверточных сетей из сотен слоев — что могут себе позволить, пожалуй, только гиганты индустрии: Google, Microsoft… Аналогично дело обстоит и с машинным переводом: вам нужны большие, очень большие, объемы данных и большие вычислительные мощности.
Похожая ситуация и с рекуррентными нейронными сетями. Несмотря на их «невиданную мощь» и способность предсказывать цепочки событий, генерить похожие на бред писателя под действием тяжелых наркотиков тексты и прочие фокусы — они обучаются очень и очень медленно и вам снова требуются несоразмерные вычислительные ресурсы.
Языковые нейронные модели сейчас, как никогда, очень интересны, но многие требуют значительных корпусов текстов и, опять таки, вычислительных ресурсов, что особенно пока затруднительно для русского языка. И хотя дело сдвинулось с мертвой точки и уже можно найти эмбеддинги и не только для русского, эффективно их использовать в составе сложных языковых моделей в production, не тащя 1000 килограмм питонячих потрохов и стадо хрюкающих слонов — неясно как.

Вы думаете, что развернуть Hadoop без помощи понимающих системных администраторов — просто? Пойдите лучше и похрюкайте вместе с этим стадом :)
Большую, действительно большую, надежду подают появившиеся пару лет назад генеративные состязательные сети (GAN). Несмотря на их потрясающие возможности: восстановление утраченной части изображения, повышение разрешения, изменение возраста лица, создание интерьера, применение в биоинформатике и вообще, проникновение в суть данных и генерация их по определенному условию (например: хочу увидеть много молодых девушек с красивыми попами): это, скорее, пока удел серьезных ученых-исследователей.
Поэтому рассчитывать на то, что вы займетесь deeplearning «на коленке» и что-то из этого полезного получится и быстро — не стоит (ударение на букву «о»). Нужно и знать немало и работать в «поте лица своего».
Бизнес-кейсы алгоритмов ML — в сухом остатке
Откинув громоздкую теорию и хорошенько протрезвев, можно увидеть, что остается небольшая пригоршня теоретически полезных в электронной коммерции и CRM алгоритмов, с которыми можно и нужно начинать работать и решать текущие бизнес-задачи:
- Классификация чего угодно на несколько классов (спам/не спам, купит/не купит, уволится/не уволится)
- Персонализация: какой товар/услугу человек купит, уже купив другие?
- Регрессия чего угодно в циферку: определяем цену квартиры по ее параметрам, цену автомобиля, потенциальный доход клиента по его характеристикам
- Кластеризация чего угодно в несколько групп
- Обогащение бизнесовых датасетов или предобучение с помощью GAN
- Перевод одной последовательности в другую: Next Best Offer, циклы лояльности клиента и др.

Говорят, что в голове «блондинки» (это собирательный образ, девушкам не обижаться, бывают мужчины как «блондинки») мозга нет, а два уха напрямую соединяются тонкой ниточкой. Если ниточку перерезать — уши отвалятся и упадут на пол
Бизнес-менеджерам, тем временем, ничего не остается делать, как с утра до вечера кидать в разработчиков учебниками математики со словами: «ну найдите же прикладное применение этим алгоритмам, for-fan — не предлагать!» и нанимать экспертов, понимающих научные публикации и способные, хотя бы на python, писать адекватный код.
Как мы используем нейросети в техподдержке и почему?
Мы отталкивались от того, что с одной стороны у нас уже есть собранная «бигдата», достаточная для обучения нейросети (десятки тысяч примеров), а с другой — есть бизнес-задача постоянно и ежедневно классифицировать поток входящих обращений клиентов с вопросами и предложениями на заранее определенный список тем (десятки) для последующей маршрутизации на ответственных сотрудников.
Выбор алгоритма, почему нейронки
Мы рассматривали классические и хорошо известные алгоритмы для, простите за тавтологию, классификации текстов: байесовский классификатор, логистическая регрессия, машина опорных векторов, но выбрали нейросети и вот почему:
- За счет факторизации слоев и нелинейности, они способны аппроксимировать гораздо более сложные паттерны меньшим числом слоев, чем плоско-широкие модели
- Нейросети, при достаточном числе обучающих примеров, лучше работают с новыми данными «by design» (генерализация лучше)
- Нейросети могут работать лучше классических моделей и даже лучше моделей, которые предварительно парсят тексты и вычленяют из них смысловые отношения между словами и предложениями.
- Если использовать регуляризацию, похожую на действие алкоголя в мозге человека (dropout), то нейросети адекватно сходятся и не сильно страдают от переобучения
В результате мы пришли к такой, довольно простой, но, как оказалось, очень эффективной на практике архитектуре:
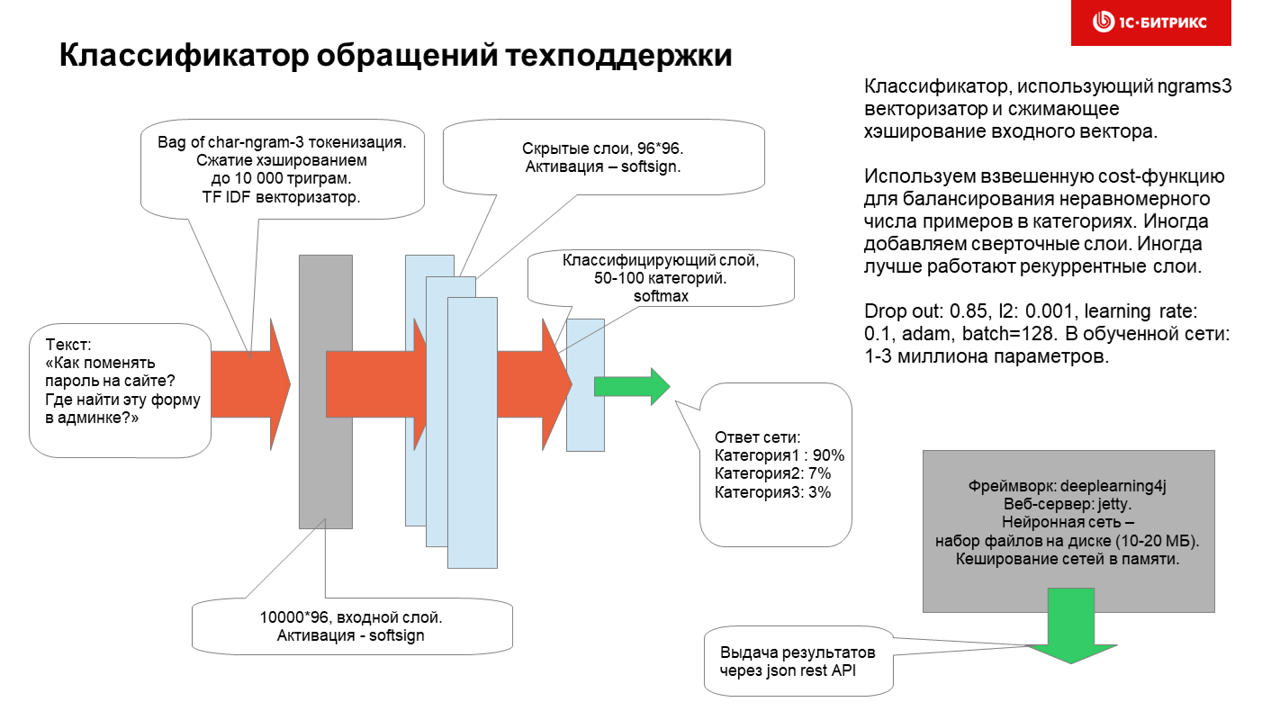
Обучается нейросеть часа полтора (без GPU, а на нем гораздо быстрее) и использует для обучения датасет ~ 100к привязок вопросов к категориям.
Категории распределены очень неравномерно, но эксперименты с назначением весов обучающим примерам с плохо представленными категориями (десятки-сотни примеров для рубрики) — особо не улучшили работу нейросети.
Напомню, что на вход сети подаются обращения граждан на куче языков, которые могут содержать:
- код на PHP
- верстку
- мат-перемат-сленг
- описание проблемы, задачи, идеи
- ссылки на файлы внутри продукта
Оказалось, что нейросеть работает лучше, если данные предварительно не обрабатывать и делать из них char3 ngrams как есть. В этом случае и устойчивость к опечаткам прекрасно работает, и можно ввести небольшой кусок пути к файлу или фрагмент кода или одно-два слова текста на любом языке и рубрика определиться весьма адекватно.
Вот как это работает изнутри:
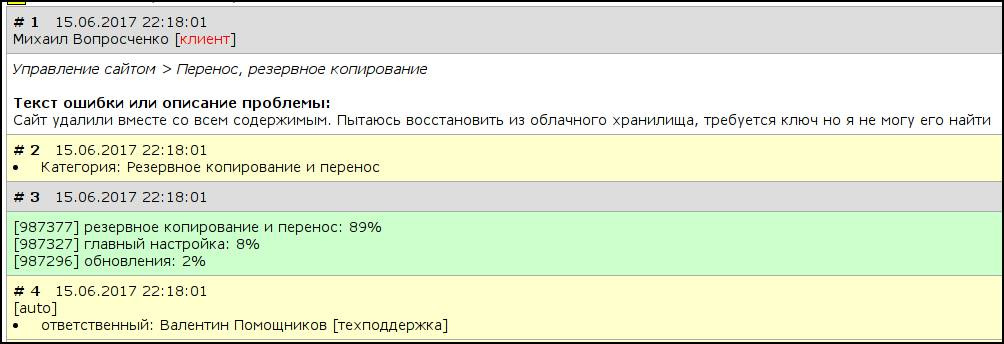
Если при классификации нейросеть не уверена или ошибается — ее страхует человек и обращение переназначается вручную. Точность классификации пока 85% и ее, конечно можно и нужно увеличивать — но, даже текущее решение сократило немало человеко-часов, помогает увеличить качество обслуживания клиентов и является примером, что нейросети это никакие не игрушки по генерации порно — а способны работать рядом с людьми и быть очень полезными.

В голове у этого астродроида не очень мощная нейросеть — но он, тем не менее, иногда ошибаясь, приносит много пользы на протяжении 6 частей (или уже 7) киносаги
Планы на будущее
Сейчас мы экспериментируем на Keras с другими архитектурами текстовых классификаторов:
— на базе рекуррентной сети
— на базе сверточной сети
— на базе bag-of-words
Лучше всего работает многослойный классификатор, на вход которого подаются one-hot вектора символов (из небольшого словаря символов корпуса), затем проходит несколько слоев 1D-свертки c global-max/average pooling и на выходе стоит обычная feed-forward слой с softmax. Подобный классификатор обучить сквозным способом так и не получилось, и даже batch normalization не помог (надо было меньше на девушек заглядываться и слушать преподавателя) — но удалось таки хорошенько ее обучить путем последовательного обучения слоя за слоем. Видимо, когда мы придумаем, как вместо тензоров на java эффективно использовать тензоры на Keras/python/Tensorflow на production — мы обязательно выкатим эту архитектуру на бой и еще больше обрадуем наших менеджеров и клиентов.
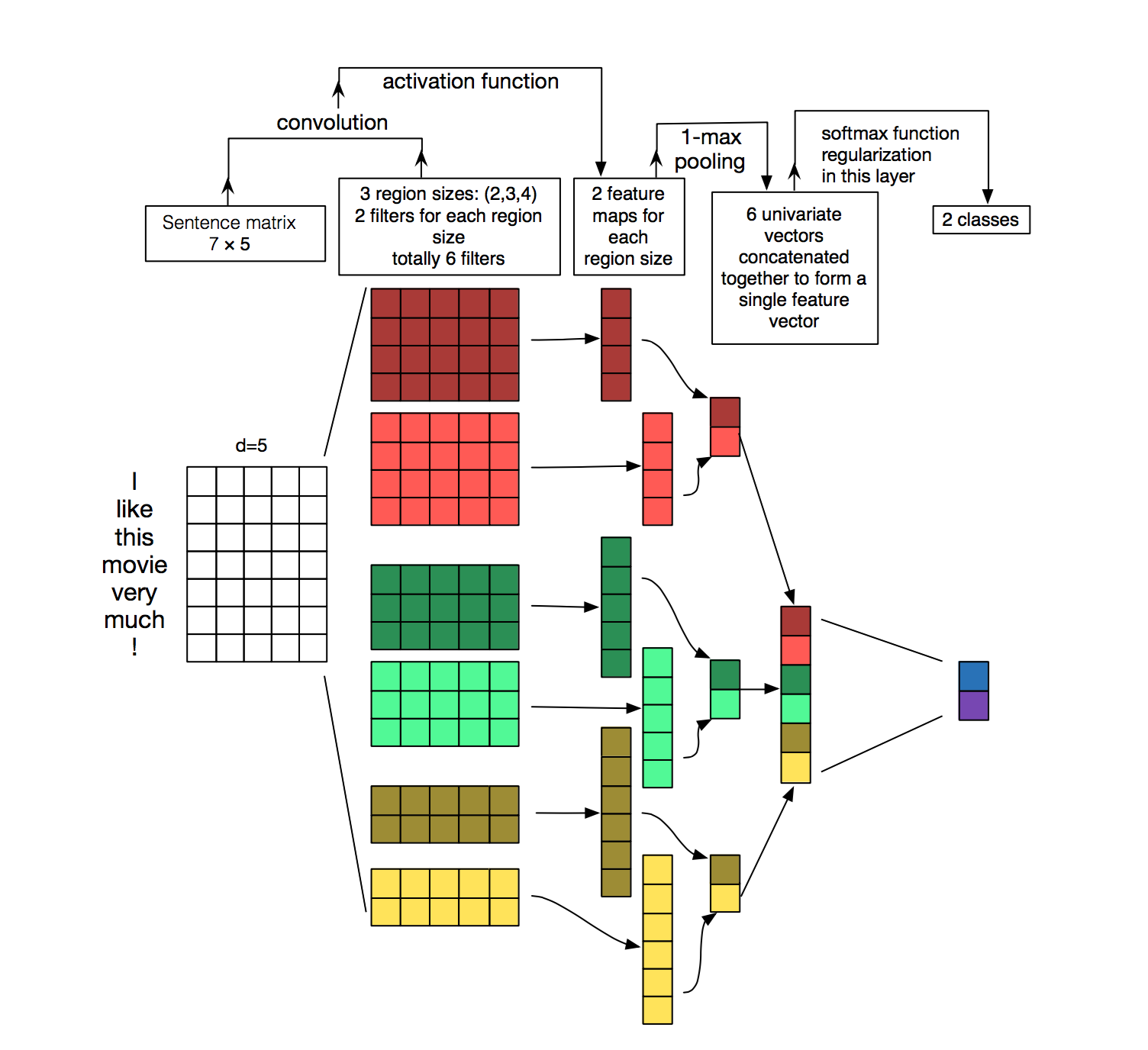
Так работает не всем понятная 1D-свертка. Можно сказать, что создаются kernels (сверточные ядра), определяющие 1-2-3-n цепочки символов, «аля» мульти-nrgams модель. В нашем случае лучше всего работает 1D-свертка с окном 9.
В завершении поста, дорогие друзья, желаю вам не тушевать перед ML и нейронками, смело брать их и использовать, строить и обучать модели и уверен, вы сами увидите, как AI эффективно работает, как помогает снять с людей рутину и увеличить качество ваших сервисов. Всем удачи и хорошего и, главное, быстрого схождения нейросетей! Целую нежно.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru