Нейронные сети в детектировании номеров
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-05-29 02:38
 Распознавание автомобильных номеров до сих пор является самым продаваемым решением на основе компьютерного зрения. Сотни, если не тысячи продуктов конкурируют на этом рынке уже на протяжении 20-25 лет. Отчасти поэтому сверточные нейронные сети (CNN) не бьют прежние алгоритмические подходы на рынке.
Распознавание автомобильных номеров до сих пор является самым продаваемым решением на основе компьютерного зрения. Сотни, если не тысячи продуктов конкурируют на этом рынке уже на протяжении 20-25 лет. Отчасти поэтому сверточные нейронные сети (CNN) не бьют прежние алгоритмические подходы на рынке.Но опыт последних лет говорит, что алгоритмы CNN позволяют делать надежные и гибкие для применения решения. Есть и еще одно удобство: при таком подходе всегда можно улучшить надежность решения на порядок после реального внедрения за счет переобучения. Кроме того, такие алгоритмы отлично реализуются на GPU (графических модулях), которые значительно эффективней с точки зрения потребления электроэнергии, чем обычные процессоры. А платформа Jetson TX от NVidia так просто потребляет очень мало по меркам современных вычислителей. Наглядное «энергетическое превосходство»:
 Конечно, такое превосходство Jetson TX1 над Intel Core i7 преувеличено, т.к. всегда существуют побочные задачи: захват изображения с камеры, работа с памятью, не все вычисления целесообразно переносить на GPU. И все-таки, выглядит заманчиво.
Конечно, такое превосходство Jetson TX1 над Intel Core i7 преувеличено, т.к. всегда существуют побочные задачи: захват изображения с камеры, работа с памятью, не все вычисления целесообразно переносить на GPU. И все-таки, выглядит заманчиво.Несложно оценить бюджет потребления для системы в сборе:
 А значит, даже для автономного решения, запитываемого от солнца и ветра, можно установить 3-4 камеры с источниками ИК и 2 Jetson-а.
А значит, даже для автономного решения, запитываемого от солнца и ветра, можно установить 3-4 камеры с источниками ИК и 2 Jetson-а.Стало еще привлекательней! Значит, нужно сделать распознавание на Jetson TX1, и сделать хорошо.
Сразу скажем спасибо коллективу NVidia в России. Благодаря их помощи все получилось. Мужики подарили нам Jetson TX1 на опыты и обещали дать затестить TX2.
Алгоритм поиска номера
Поиск границ и углов автомобильных номеров на снимках состоял из трех стадий, реализованных разными обученными CNN-ями.Определение позиции автомобильного номера (центра):
 Выходной слой сверточной сети — поле вероятностей нахождения центра номера в данной точке. На выходе получаются вот такие красивые “Гауссы”. Конечно, тут возможны ложные срабатывания. Более того, пороги так и выбираются, чтобы минимизировать вероятность пропуска номера (увеличив “ложняки”).
Выходной слой сверточной сети — поле вероятностей нахождения центра номера в данной точке. На выходе получаются вот такие красивые “Гауссы”. Конечно, тут возможны ложные срабатывания. Более того, пороги так и выбираются, чтобы минимизировать вероятность пропуска номера (увеличив “ложняки”). За последние пару лет на наш свободно-доступный сервер пришли десятки тысяч разнообразных номеров. С такой базой удалось обучить значительно более надежный детектор, чем используемый ранее Haar.
Оценка масштаба автомобильного номера:
 Тут попутно отсеиваем часть ложных срабатываний.
Тут попутно отсеиваем часть ложных срабатываний. Поиск лучшего преобразования “гомографии”, приводящей автомобильный номер в привычный вид:
Здесь поработали еще 2 сверточные нейронные сети: детектирование границ номера, определение максимально правдоподобной гипотезы.
Результат работы первой:
А вторая выбирает наилучшую гомографию: В результате получается нормализованное изображение автомобильного номера, которое дальше необходимо распознать. Ниже несколько примеров таких нормализованных табличек (некоторые из них не читаемы даже глазом):
В результате получается нормализованное изображение автомобильного номера, которое дальше необходимо распознать. Ниже несколько примеров таких нормализованных табличек (некоторые из них не читаемы даже глазом): Такой многоуровневый подход показал себя весьма надежным. На каждой стадии вероятность пропуска минимизируется, а сверточная нейронная сеть на каждом следующем уровне обучается не только выполнять свою основную функцию, но и убирать ложные срабатывания. Таким образом, неточность каждой CNN компенсируется на следующем этапе.
Такой многоуровневый подход показал себя весьма надежным. На каждой стадии вероятность пропуска минимизируется, а сверточная нейронная сеть на каждом следующем уровне обучается не только выполнять свою основную функцию, но и убирать ложные срабатывания. Таким образом, неточность каждой CNN компенсируется на следующем этапе.Для того, чтобы заставить все это работать, мы использовали 2 типа сверточных сетей:
1) Стандартный классификационный вариант, подобный VGG:

2) Архитектуру, предназначенную для сегментации, подробнее описанную в одной из предыдущих статей: habrahabr.ru/company/recognitor/blog/277781
 Конечно, эти архитектуры пришлось немного облегчать для работы на Jetson TX1. Кроме того, несколько ухищрений с функциями потерь и выходными слоями помогли улучшить обобщение при тренировке на не такой уж и огромной базе, которая имелась в распоряжении.
Конечно, эти архитектуры пришлось немного облегчать для работы на Jetson TX1. Кроме того, несколько ухищрений с функциями потерь и выходными слоями помогли улучшить обобщение при тренировке на не такой уж и огромной базе, которая имелась в распоряжении.Алгоритм распознавания текста на номере
Честно говоря, казалось, что проблемы с распознаванием текста уже несколько лет основательны решены современными Deep Learning алгоритмами. Но почему-то нет.Вот относительно свежий обзор существующих проблем и методов решения: handong1587.github.io/deep_learning/2015/10/09/ocr.html
На Хабре недавно была статья про использование LSTM и CNN для распознавания текста в паспорте: habrahabr.ru/company/smartengines/blog/328000
Но описанный подход требует ручной разметки всей базы (границы между знаками). А у нас была серьезного размера база с разметкой другого плана (изображение + текст):
 Ведь был же алгоритм предыдущего поколения, который часто довольно удачно распознавал автомобильный номер (порою допуская ошибки). А значит, нужно было придумать подход, который позволил бы обучить нейронную сеть без привлечения информации о позиции каждого символа. Такой подход еще более ценен из-за того, что так значительно проще автоматически наращивать обучающую выборку. В системе, в которой глазами проверяют и исправляют ошибки (например, для отправки штрафа) автоматически формируется расширение обучающей выборки. Да даже если коррекция не проводится, переобучение поможет после накопления распознанных номеров.
Ведь был же алгоритм предыдущего поколения, который часто довольно удачно распознавал автомобильный номер (порою допуская ошибки). А значит, нужно было придумать подход, который позволил бы обучить нейронную сеть без привлечения информации о позиции каждого символа. Такой подход еще более ценен из-за того, что так значительно проще автоматически наращивать обучающую выборку. В системе, в которой глазами проверяют и исправляют ошибки (например, для отправки штрафа) автоматически формируется расширение обучающей выборки. Да даже если коррекция не проводится, переобучение поможет после накопления распознанных номеров.Любая сверточная сеть имеет заранее запрограммированную структуру, в которой заложено, что одни и те же ядра (свертки) применяются к разным позициям изображения. За счет этого достигается значительное сокращение количества весов.
Можно взглянуть на это свойство сверточных сетей и с другой стороны, как предлагает AlexeyR (https://habrahabr.ru/post/320866/). Если коротко, то задача обобщения неразрывно связана с задачей преобразования входной информации в контекст, в котором она чаще встречается или лучше описывается. Вооружившись этой концепцией (или вдохновившись) попробуем решить эту, кажется простую, задачу распознавания текста на изображении с имеющейся у нас разметкой (нет позиции знаков, есть лишь их перечень).
Соорудим маленькую контекстно-зависимую область из 36 миниколонок (https://habrahabr.ru/post/317712/):
 На картинке изображены только 10 преобразований. Вот как должны выглядеть отклики на каждый из контекстов в приведенной выше картинке
На картинке изображены только 10 преобразований. Вот как должны выглядеть отклики на каждый из контекстов в приведенной выше картинке Тут нужно отметить, что использовалось далеко не самое эффективное кодирование внутри миниколонок, но при имеющихся 22 понятиях, это не большая проблема.
Тут нужно отметить, что использовалось далеко не самое эффективное кодирование внутри миниколонок, но при имеющихся 22 понятиях, это не большая проблема.Сверточные сети задуманы так удачно, что эти контекстные преобразования автоматически получаются на выходе любого сверточного слоя, а значит нет смысла смещать входные изображения, достаточно взять выход любого сверточного слоя, совершить несколько преобразований, уже реализованных слоями в Caffe, да запустить обучение SGD.
И в результате обучения получим “срез” для 36 миниколонок:
 Выделим локальные максимумы и сообщим на выход сочетания: что узнали и в каком контексте. А затем соберем все по порядку слева-направо: A902YT190
Выделим локальные максимумы и сообщим на выход сочетания: что узнали и в каком контексте. А затем соберем все по порядку слева-направо: A902YT190Эту задачу удалось решить с помощью CAFFE и архитектуры сверточной сети. Но если бы пришлось рассматривать более сложные и неочевидные преобразования (масштаб, повороты в пространстве, перспективу), то пришлось бы задействовать больше вычислительных ресурсов и создавать куда более серьезные алгоритмы.
Кроме того, пришлось довольно сильно попотеть над регионами, качество которых оставляет желать лучшего. Но это настолько большая история, что не хочется ее включать в эту и так длинную статью.
При этом, стоит отдельно отметить. Если регионов нет, то любые номера с монотонным шрифтом распознаются одной и той же сеткой. Просто достаточно предоставить достаточно большую базу примеров.
Применения
Конечно, самое очевидное — контроль ПДД. Но есть еще несколько применений, которые нам встречались. Нам хотелось сделать достаточно универсальный алгоритм. Поэтому пришлось подумать о том, какие же варианты использования бывают:1) Контроль ПДД (применение 1)
 Высокое разрешение камер: 3-8MP
Высокое разрешение камер: 3-8MPИК осветитель
Предсказуемая ориентация и масштаб
Возможная ручная настройка после монтажа
До 10-20 номеров в кадре
2) Контроль проезда на КПП (применение 2)
 Камеры низкого разрешения (0.3MP — 1MP)
Камеры низкого разрешения (0.3MP — 1MP)ИК осветитель
Предсказуемый размер и область номера
Возможная ручная настройка после монтажа
Только один номер за раз в кадре
3) Фотографии “с рук” (применение 3)
 Камера высокого разрешения
Камера высокого разрешения Нет ИК подсветки
Непредсказуемый размер номера и область его расположения
Оказалось, что последнее применение наиболее затратно по вычислительным ресурсам. В основном из-за того, что масштаб номера плохо предсказуем.
Наиболее простое применение — второе. В кадре не больше одного номера. Масштаб номера варьируется в небольших пределах.
Первое применение тоже достаточно удачное и находится по вычислительным потребностям посередине.
Но со всеми этими ситуациями Jetson TX1 успешно справляется. Только последнее не укладывается в масштаб реального времени, а требует около 1 секунды на расчет в неоптимизированном коде.
Бюджет времени расчета кадра на Jetson TX1
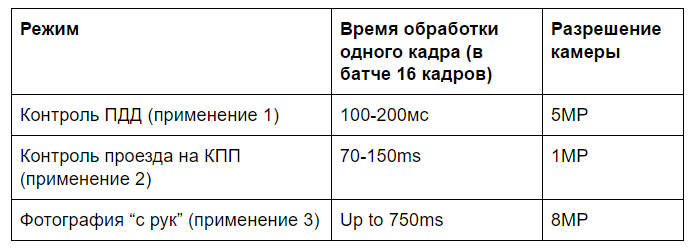
Тесты производительности предварительны, все еще возможна оптимизация, особенно под специфичное применение.
И, естественно, при выполнении того же самого алгоритма на видеокартах уровня 1080/Titan можно получить практически десятикратное увеличение скорости работы. Для третьего применения это уже ~100мс на изображение.
Telegram Bot
Плоха та статья на хабре, которая не заканчивается рассказом о написании Telegram бота! Поэтому, конечно, мы сделали одного такого на Jetson TX1, чтобы Вы могли пофотографировать и протестировать алгоритм. Бота зовут RecognitorРаботает сейчас этот бот на демонстрационной плате Jetson TX1:
 Jetson TX1 распознает изображения в домашних условиях (обратите внимание на вентилятор — он включается каждый раз, когда приходит новое изображение).
Jetson TX1 распознает изображения в домашних условиях (обратите внимание на вентилятор — он включается каждый раз, когда приходит новое изображение).
Оказалось, что Telegram Bot — великолепный вспомогательный инструмент при работе с программами компьютерного зрения. Так, например, можно организовать ручную проверку результатов распознавания с его помощью. Telegram API предоставляет отличный набор функций для этого. ZlodeiBaal здесь уже использовал телеграм бота (https://habrahabr.ru/post/322520/).
Все просто: прикладываете изображение в сообщение (одно! Кажется telegram позволяет отправить несколько, но проанализировано будет только последнее). Возвращается изображение с отмеченными рамками и несколько строк со всеми вероятно-найденными номерами. В каждой строке также указан процент — это условная вероятность того, что номер действительно распознан. Меньше 50% — что-то с номером не то (часть не влезла в кадр или это вовсе не номер).
Если же хотите оставить нам комментарий по конкретной фотографии, то просто напишите его текстом, не прикладывая картинку. Он обязательно сохранится в файле log.txt, который очень вероятно мы прочитаем.
Не забывайте, что сейчас алгоритм запущен в тестовом режиме и ожидаются лишь стандартные рос.гос.номера или желтые номера такси ( без транзитов, прицепы и.т.д.).
Обучающая выборка
У нас в распоряжении было около 25000 изображений. Большая часть базы — снимки с телефона со случайным положением и масштабом номера: Несколько тысяч снимков были получены с контрольно-пропускных пунктов:
Несколько тысяч снимков были получены с контрольно-пропускных пунктов: Около тысячи снимков — стандартный ракурс для камер регистрации нарушений ПДД.
Около тысячи снимков — стандартный ракурс для камер регистрации нарушений ПДД.  Большая часть базы была основана на той выборке, которую мы выкладывали в открытый доступ давным давно —
Большая часть базы была основана на той выборке, которую мы выкладывали в открытый доступ давным давно — yadi.sk/d/EAfnQ947criHW
yadi.sk/d/0H2AipxrcrXqy
yadi.sk/d/U41QZ8v7cpJ6R
В итоге
Собрали весь стек алгоритмов распознавания автомобильных номеров, основанный на сверточных нейронных сетях, для Jetson TX1 с достаточным быстродействием, чтобы работать с видео в реальном времени.Надежность распознавания значительно улучшилась относительно предыдущего алгоритма (https://habrahabr.ru/company/recognitor/blog/225913/ ). Конкретные цифры приводить тяжело, т.к. они сильно разнятся в зависимости от условий применения. Но разница неплохо видна невооруженным глазом — Recognitor
Благодаря тому, что все алгоритмы переобучаемы, можно легко расширить применимость решения. Вплоть до изменения объектов распознавания.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru