Механизм подсчета нейронной сети в PL/SQL для распознавания рукописных цифр
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-05-17 20:55

Дорогие коллеги, спешим порадовать всех, кто неравнодушен к наукоемким задачам. Сегодня мы приготовили для вас перевод любопытной публикации от экспертов по базам данных из CERN, посвященный обучению и эксплуатации нейронных сетей с помощью Python и инструментария на базе Oracle PL/SQL.
 В этой статье вы найдете пример построения и развертывания базового механизма подсчета искусственной нейронной сети с использованием PL/SQL. Статья предназначена для учебных целей, в частности для практиков Oracle, которые хотят на конкретном примере познакомиться с нейронными сетями.
В этой статье вы найдете пример построения и развертывания базового механизма подсчета искусственной нейронной сети с использованием PL/SQL. Статья предназначена для учебных целей, в частности для практиков Oracle, которые хотят на конкретном примере познакомиться с нейронными сетями.
В настоящее время машинное обучение и нейронные сети являются актуальными темами в обработке данных. Для работы и экспериментов с нейронными сетями и глубинного обучения (deep learning) сейчас доступны многие инструменты и платформы (см. ссылки в конце этой статьи). Распознавание рукописных цифр, в частности, с использованием базы данных MNIST, Яна Лекуна и др., сейчас является вводным примером для ознакомления с нейронными сетями.
В этой статье вы увидите, как построить и развернуть простой механизм подсчета нейронных сетей, чтобы распознавать рукописные цифры, используя Oracle и PL/SQL. Конечным результатом является небольшой пакет PL/SQL с точностью около 98%. Нейронная сеть создается и обучается с помощью TensorFlow, а затем передается в Oracle для ее обслуживания.
Одна из идей, которые эта статья призвана проиллюстрировать, заключается в том, что подсчет нейронных сетей намного проще, чем их обучение: операции, необходимые для обслуживания обученной сети, могут быть реализованы относительно легко на многих языках/средах программирования. Обсуждения по этим темам обычно сосредоточены вокруг платформ для «Big data» (например, Spark и MLlib). Интересно, что нейронные сети также могут быть с успехом применены в мире РСУБД. Это может быть полезно, поскольку большое количество ценных данных в настоящее время хранится в реляционных базах данных. В случае Oracle реализация механизма подсчета также упрощается благодаря наличию зрелой среды PL/SQL с пакетом для линейной алгебры: UTL_NLA.
Давайте начнем с конца: как развернуть пакет PL/SQL MNIST и распознать рукописные цифры в Oracle
Один короткий пакет PL/SQL и две таблицы — это всё, что вам нужно для воспроизведения следующего примера (вы можете найти подробный код на Github). Таблицы:
Механизм для подсчета нейронной сети из примера находится в пакете под названием MNIST. В нём есть процедура INIT, которая загружает компоненты нейронной сети из таблицы tensors_array в переменные PL/SQL и функцию SCORE, которая принимает изображение в качестве входных данных и возвращает число — прогнозируемое значение цифры.
Вот пример его использования, где первая картинка в таблице testdata_array проверяется и правильно распознается как изображение числа 7 (метка изображения согласуется с предсказанием MNIST.SCORE):

Рисунок 1: Это растровое отображение тестовой картинки, используемой в примере. Оно подтверждает, что прогноз MNIST.SCORE корректен и действительно картинка представляет собой изображение числа 7, написанного от руки и закодированного в сетке 28x28 gray-scale пикселей.
Обработка всех тестовых изображений также выполняется простой командой SQL. В примере на рис. 2 для обработки 10000 тестовых изображений требуется 2 минуты, то есть в среднем около 12 мс на изображение. Точность функции оценки составляет около 98%. Она рассчитывается следующим образом: согласно меткам данных, 9787 из 10000 изображений оцениваются правильно. Отметим также, что набор тестовых изображений не пересекается с изображениями, используемыми для обучения нейронной сети. Поэтому мы можем ожидать, что пакет MNIST имеет точность распознавания цифр около 98% в том числе и при использовании на общем вводе.
Полный код PL/SQL и dump-файл datapump с соответствующими таблицами можно найти на Github. В следующих абзацах я расскажу, как построить и обучить нейронную сеть.
 Рисунок 2: Точность функции оценки PL/SQL MNIST.SCORE на тестовом наборе из 10K изображений составляет около 98%. Обработка занимает около 12 мс на изображение.
Рисунок 2: Точность функции оценки PL/SQL MNIST.SCORE на тестовом наборе из 10K изображений составляет около 98%. Обработка занимает около 12 мс на изображение.
Нейронная сеть
Нейронная сеть, используемая в этой статье, состоит из трех слоев (см. Рис. 3): один слой ввода, один скрытый слой и один слой вывода. Если эта тема для вас нова, я рекомендую почитать дополнительную литературу (см. Ссылки) и, в частности, книгу «Neural Networks and Deep Learning» Майкла Нильсена, которая обеспечит отличное введение в тему и серию пошаговых примеров, касающихся проблемы распознавания рукописных цифр.
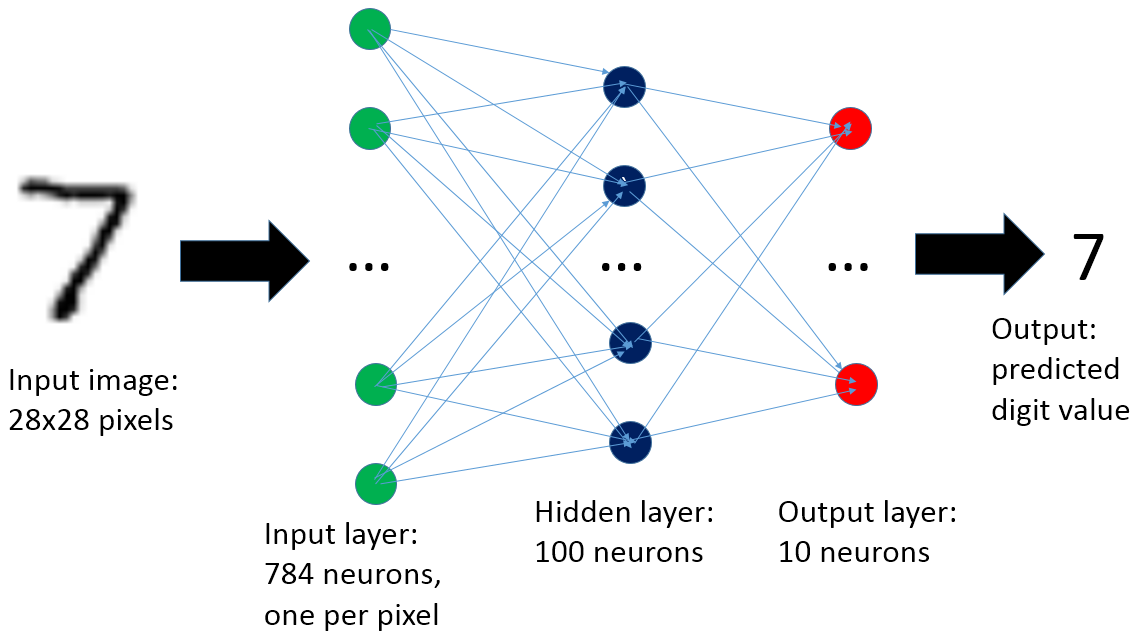 Рисунок 3: Искусственная нейронная сеть, используемая в этой статье, состоит из трех слоев. Слой ввода содержит 784 нейрона, по одному на пиксель входящего изображения. Чтобы повысить точность, добавлен скрытый слой из 100 нейронов. Слой вывода имеет 10 нейронов, по одному на каждое возможное выходное значение (то есть, цифры от 0 до 9).
Рисунок 3: Искусственная нейронная сеть, используемая в этой статье, состоит из трех слоев. Слой ввода содержит 784 нейрона, по одному на пиксель входящего изображения. Чтобы повысить точность, добавлен скрытый слой из 100 нейронов. Слой вывода имеет 10 нейронов, по одному на каждое возможное выходное значение (то есть, цифры от 0 до 9).
Получите учебные и тестовые данные, постройте и обучите нейронную сеть
Ещё одним важным шагом для развертывания нейронных сетей является обучение. Для этого вам нужны данные, по возможности много. Вам также нужен движок для выполнения необходимых вычислений. К счастью, существует множество доступных платформ для работы с нейронными сетями, которые являются бесплатными и относительно используемыми для развертывания (см. Ссылки). В этой статье вы увидите, как использовать TensorFlow от Google и среду Python. TensorFlow поставляется с инструкцией для распознавания рукописных цифр в базе данных MNIST. В инструкцию включены учебные и тестовые данные с метками, а также примеры кода.
Вы можете найти код, который я использовал для обучения нейронной сети, на Github. Некоторые основные моменты и фрагменты кода обсуждаются ниже.
Импорт данных: Пример набора данных, который поставляется с TensorFlow, включает 55000 изображений для обучения и 10000 изображений для тестирования. Они изначально исходят из работы Яна Лекуна и коллег. Наличие большого количества высококачественных данных очень важно для успеха процесса. Кроме того, на изображениях имеются ярлыки: на них указывается, какое число изображено на картинке, и эта информация очень важна, поскольку упражнение заключается в осуществлении контролируемого обучения.
Определение нейронной сети: в сети есть четыре тензора (в данном случае — вектор и матрицы): W0, W1, b0 и b1. Они определены в следующем фрагменте кода. Чтобы лучше понять их роль, а также значение перекрестной энтропии и оптимизатора градиентного спуска для обучения нейронной сети, см. ссылки, а именно «Neural Networks and Deep Learning» и инструкцию TensorFlow.
 Обучение нейронной сети: обучение проходит с несколькими этапами оптимизации. Оно проводится с использованием 55000 изображений с метками. Выполняется более 30000 итераций, с использованием «мини-порций» размером 100 изображений. На каждом шаге алгоритм градиентного спуска (gradient descent) вычисляет обновление весов и смещений (W0, W1, bo и b1) с целью минимизации функции потерь (cross_entropy). Соответствующий фрагмент кода:
Обучение нейронной сети: обучение проходит с несколькими этапами оптимизации. Оно проводится с использованием 55000 изображений с метками. Выполняется более 30000 итераций, с использованием «мини-порций» размером 100 изображений. На каждом шаге алгоритм градиентного спуска (gradient descent) вычисляет обновление весов и смещений (W0, W1, bo и b1) с целью минимизации функции потерь (cross_entropy). Соответствующий фрагмент кода:
 Результат: в результате обученная сеть имеет точность около 98% в прогнозировании изображений в тестовом наборе. Обратите внимание, что тестовый набор состоит из 10000 изображений и не совпадает с набором изображений, используемых для обучения (учебный набор содержит 55000 изображений).
Результат: в результате обученная сеть имеет точность около 98% в прогнозировании изображений в тестовом наборе. Обратите внимание, что тестовый набор состоит из 10000 изображений и не совпадает с набором изображений, используемых для обучения (учебный набор содержит 55000 изображений).
Можно получить более высокую точность при более сложных конфигурациях нейронной сети (подробности см. в Ссылках), но это выходит за рамки данной статьи.
Ручной подсчет нейронной сети, пример на языке Python
Основной результат обучающих операций состоит в том, что тензоры (в данном случае матрицы и векторы), которые составляют нейронную сеть, теперь заполнены полезными значениями. Я считаю, что хороший способ понять, как все это работает, — «запустить сеть вручную», то есть запустить в качестве примера переход от изображения рукописной цифры к предсказанию ее значения обученной нейронной сетью. В качестве первого шага мы извлекаем значения обученных тензоров из нашей модели в массивы numpy для последующей обработки:
 Пример «ручного» управления сетью в Python выглядит следующим образом:
Пример «ручного» управления сетью в Python выглядит следующим образом:
 W0_matrix, b0_array, W1_matrix и b1_array являются тензорами, которые составляют нейронную сеть после обучения, testimage — слой ввода, sigmoid() используется как функция активации, hidden_layer представляет скрытый слой сети, predicted — это слой вывода, а softmax() — это функция, используемая для нормализации вывода как распределения вероятностей. В конце вычисления массив predicted[n] содержит предсказание, что входное изображение представляет цифру «n». Функция argmax() находит значение «n», для которого predicted[n] максимально.
W0_matrix, b0_array, W1_matrix и b1_array являются тензорами, которые составляют нейронную сеть после обучения, testimage — слой ввода, sigmoid() используется как функция активации, hidden_layer представляет скрытый слой сети, predicted — это слой вывода, а softmax() — это функция, используемая для нормализации вывода как распределения вероятностей. В конце вычисления массив predicted[n] содержит предсказание, что входное изображение представляет цифру «n». Функция argmax() находит значение «n», для которого predicted[n] максимально.
Код, показанный выше, прогнозирует значение 7 для тестового изображения. Прогноз подтверждается как правильный значением метки, а также может быть визуально подтвержден растровым отображением тестового изображения (см. Рис. 1).
Перенос тестовых данных и сети в Oracle
Пример из предыдущего параграфа о том, как вручную запустить механизм подсчета, показывает, что обслуживание нейронной сети может быть прямолинейным, в некоторых случаях это просто вопрос выполнения некоторых базовых вычислений с матрицами. Это контрастирует со сложностью обучения нейросетевых моделей, где часто требуется специализированный движок, высокое качество обучающих данных, а в более сложных случаях еще и специализированное оборудование, такое как GPU карты.
Тема предыдущего параграфа также подготовила почву для следующей разработки: это перемещение тензоров нейронной сети и тестовых данных в Oracle и внедрение обслуживающего механизма там.
Существует множество способов экспорта numpy массивов Python. Один из них — сохранить массивы в текстовом формате. Здесь же вы увидите метод, предназначенный для прямого экспорта в Oracle с помощью cx_Oracle, библиотеки Python для взаимодействия с Oracle. Для получения дополнительных примеров и ссылок о том, как использовать cx_Oracle советую ознакомиться с заметками «Oracle и Python и cx_Oracle».
Код можно найти на Github, вот некоторые релевантные фрагменты:
— Создайте таблицы для размещения определений тензоров и тестовых данных:
— Из Python откройте соединение с Oracle:
— Пример того, как перенести матрицу W0 в таблицу Oracle tensors:
Наконец, вы можете экспортировать таблицы testdata и tensors для последующего использования. В репозитории Github вы можете найти dump-файл, полученный с помощью следующей команды (запустить как Oracle):
Оптимизации Oracle для линейной алгебры
Из документации Oracle: «Пакет UTL_NLA предоставляет подмножество операций BLAS и LAPACK (версия 3.0) для векторов и матриц, представленных как VARRAYS». Это очень полезно для выполнения вычислений, необходимых для обслуживания нейронной сети из этой статьи.
Ниже приведен фрагмент кода MNIST, чтобы понять, как это работает на практике. Код выполняет вычисление v_Y0 = v_Y0 + g_W0_matrix * p_testimage_array, где g_W0_matrix — матрица 784x100, p_testimage_array — вектор из 784 элементов (кодирует изображения 28x28), а v_Y0 — вектор из 100 элементов.
Чтобы использовать UTL_NLA, тензоры, которые делают нейронную сеть и тестовые изображения, должны храниться в varrays из binary_float или, скорее, быть объявлены типом данных UTL_NLA_ARRAY.
По этой причине также удобно проводить пост-обработку таблиц tensors и testdata следующим образом:
Последний шаг, возвращающий вас к обсуждению в разделе «Давайте начнем с конца: как развернуть пакет PL/SQL MNIST и распознать рукописные цифры в Oracle», — это создать пакет PL/ SQL MNIST, который загружает тензоры и выполняет операции, необходимые для подсчета нейронной сети, подробный код можно посмотреть на Github.
Заключение и комментарии
Эта статья описывает пример внедрения механизма подсчета для искусственной нейронной сети с использованием реляционной СУБД Oracle и PL/SQL. Речь идет о простой реализации примера для ознакомления с нейронными сетями: распознавание рукописных цифр в базе данных MNIST. Сеть обучается с помощью TensorFlow, а затем экспортируется в Oracle. Конечным результатом является небольшой пакет PL/SQL, который обеспечивает распознавание цифр с точностью около 98%.
В ближайшем будущем мы можем ожидать рост развертывания нейронных сетей вблизи источников и хранилищ данных. Пример в этой статье того, как реализовать механизм обслуживания нейронной сети в базе данных Oracle, показывает, что это не только возможно, но и легко реализовать.
Обслуживание нейронных сетей намного проще их обучения. Хотя для обучения требуется специализированное программное обеспечение/платформы, знание предметной области и большое количество учебных данных, обученные сети можно импортировать и запускать в целевых системах, что во многих случаях требует низкого использования вычислительных ресурсов.
Эта статья была задумана как учебный материал: вместо более производительной сверточной сети используется простая нейронная сеть прямого распространения (см. Ссылки). Более того, перемещение данных из TensorFlow в Oracle и реализация обслуживающего движка в PL/SQL — это своего рода “костыль” в текущем состоянии, и он не предназначен для использования в production.
Код, сопровождающий эту статью, доступен на Github.
Примечания о том, как создать тестовую среду
Основными компонентами и инструментами для тестирования скриптов в этой статье являются:
среда Python (на Linux с CentOS 7), установленная с помощью Anaconda 4.1: Python 2.7, Jupyter Ipython notebook.
TensorFlow, версия 0.9 (последняя на момент написания статьи), установленная в соответствии с инструкциями https://www.tensorflow.org/versions/r0.9/get_started/os_setup.html
Реляционная СУБД Oracle, работающая на Linux. Скрипты Oracle были протестированы на Oracle 11.2.0.4 и 12.1.0.2
Ссылки и благодарности
Отличным введением в нейронные сети и вдохновением для этой статьи послужила книга Майкла Нильсена (Michael Nielsen) «Neural Networks and Deep Learning».
Код для обучения нейронной сети, используемый в этой статье, является расширением инструкции TensorFlow MNIST от Google.
Также рекомендую: учебник по TensorFlow Нартина Гордона (Nartin Gorner),
«Базовые техники для TensorFlow» Аарона Шумахера (Aaron Schumacher),
«Базы данных MNIST» Яна Лекуна (Yann LeCun),
«Визуализация MNIST» Кристофера Олаха (Christopher Olah),
«Машинное обучение Python» Себастиана Ращка (Sebastian Raschka).
Другие популярные фреймворки для работы с нейронными сетями и глубокого обучения, помимо TensorFlow, включают Theano и Torch среди многих прочих, смотрите также эту страницу на Википедии.
 Всех любителей наукоемких задач и computer science приглашаем летом посетить одноименную секцию базы данных и computer science на PG Day'17 Russia. Будем обсуждать блокчейны, моделирование и визуализацию данных, теорию профилирования СУБД, data mining и еще несколько интересных тем )
Всех любителей наукоемких задач и computer science приглашаем летом посетить одноименную секцию базы данных и computer science на PG Day'17 Russia. Будем обсуждать блокчейны, моделирование и визуализацию данных, теорию профилирования СУБД, data mining и еще несколько интересных тем )
Ну и не забывайте, что в этом году в рамках PG Day состоится секция для специалистов, работающих с Oracle и другими коммерческими базами данных. Ожидаются первоклассные доклады от экспертов из крупнейших технологических компаний и полноценный мастер-класс, посвященный диагностике производительности Oracle Database.
В этой статье вы найдете пример построения и развертывания базового механизма подсчета искусственной нейронной сети с использованием PL/SQL. Статья предназначена для учебных целей, в частности для практиков Oracle, которые хотят на конкретном примере познакомиться с нейронными сетями.В настоящее время машинное обучение и нейронные сети являются актуальными темами в обработке данных. Для работы и экспериментов с нейронными сетями и глубинного обучения (deep learning) сейчас доступны многие инструменты и платформы (см. ссылки в конце этой статьи). Распознавание рукописных цифр, в частности, с использованием базы данных MNIST, Яна Лекуна и др., сейчас является вводным примером для ознакомления с нейронными сетями.
В этой статье вы увидите, как построить и развернуть простой механизм подсчета нейронных сетей, чтобы распознавать рукописные цифры, используя Oracle и PL/SQL. Конечным результатом является небольшой пакет PL/SQL с точностью около 98%. Нейронная сеть создается и обучается с помощью TensorFlow, а затем передается в Oracle для ее обслуживания.
Одна из идей, которые эта статья призвана проиллюстрировать, заключается в том, что подсчет нейронных сетей намного проще, чем их обучение: операции, необходимые для обслуживания обученной сети, могут быть реализованы относительно легко на многих языках/средах программирования. Обсуждения по этим темам обычно сосредоточены вокруг платформ для «Big data» (например, Spark и MLlib). Интересно, что нейронные сети также могут быть с успехом применены в мире РСУБД. Это может быть полезно, поскольку большое количество ценных данных в настоящее время хранится в реляционных базах данных. В случае Oracle реализация механизма подсчета также упрощается благодаря наличию зрелой среды PL/SQL с пакетом для линейной алгебры: UTL_NLA.
Давайте начнем с конца: как развернуть пакет PL/SQL MNIST и распознать рукописные цифры в Oracle
Один короткий пакет PL/SQL и две таблицы — это всё, что вам нужно для воспроизведения следующего примера (вы можете найти подробный код на Github). Таблицы:
- TENSORS_ARRAY: эта таблица содержит числовые значения для векторов и матриц (тензоров), которые составляют нейронную сеть. Существует всего 79510 чисел с плавающей запятой, закодированных в четырех тензорах с использованием типа данных UTL_NLA_ARRAY_FLT.
- TESTDATA_ARRAY: эта таблица содержит тестовые изображения. Есть 10K изображений, каждое из которых состоит из 28 * 28 = 784 пикселей. Изображения также кодируются с использованием типа данных UTL_NLA_ARRAY_FLT.
Механизм для подсчета нейронной сети из примера находится в пакете под названием MNIST. В нём есть процедура INIT, которая загружает компоненты нейронной сети из таблицы tensors_array в переменные PL/SQL и функцию SCORE, которая принимает изображение в качестве входных данных и возвращает число — прогнозируемое значение цифры.
Вот пример его использования, где первая картинка в таблице testdata_array проверяется и правильно распознается как изображение числа 7 (метка изображения согласуется с предсказанием MNIST.SCORE):
SQL> exec mnist.init PL/SQL procedure successfully completed. SQL> select mnist.score(image_array), label from testdata_array where rownum=1; MNIST.SCORE(IMAGE_ARRAY) LABEL ------------------------ ---------- 7 7Рисунок 1: Это растровое отображение тестовой картинки, используемой в примере. Оно подтверждает, что прогноз MNIST.SCORE корректен и действительно картинка представляет собой изображение числа 7, написанного от руки и закодированного в сетке 28x28 gray-scale пикселей.
Обработка всех тестовых изображений также выполняется простой командой SQL. В примере на рис. 2 для обработки 10000 тестовых изображений требуется 2 минуты, то есть в среднем около 12 мс на изображение. Точность функции оценки составляет около 98%. Она рассчитывается следующим образом: согласно меткам данных, 9787 из 10000 изображений оцениваются правильно. Отметим также, что набор тестовых изображений не пересекается с изображениями, используемыми для обучения нейронной сети. Поэтому мы можем ожидать, что пакет MNIST имеет точность распознавания цифр около 98% в том числе и при использовании на общем вводе.
Полный код PL/SQL и dump-файл datapump с соответствующими таблицами можно найти на Github. В следующих абзацах я расскажу, как построить и обучить нейронную сеть.
Рисунок 2: Точность функции оценки PL/SQL MNIST.SCORE на тестовом наборе из 10K изображений составляет около 98%. Обработка занимает около 12 мс на изображение. Нейронная сеть
Нейронная сеть, используемая в этой статье, состоит из трех слоев (см. Рис. 3): один слой ввода, один скрытый слой и один слой вывода. Если эта тема для вас нова, я рекомендую почитать дополнительную литературу (см. Ссылки) и, в частности, книгу «Neural Networks and Deep Learning» Майкла Нильсена, которая обеспечит отличное введение в тему и серию пошаговых примеров, касающихся проблемы распознавания рукописных цифр.
Рисунок 3: Искусственная нейронная сеть, используемая в этой статье, состоит из трех слоев. Слой ввода содержит 784 нейрона, по одному на пиксель входящего изображения. Чтобы повысить точность, добавлен скрытый слой из 100 нейронов. Слой вывода имеет 10 нейронов, по одному на каждое возможное выходное значение (то есть, цифры от 0 до 9).Получите учебные и тестовые данные, постройте и обучите нейронную сеть
Ещё одним важным шагом для развертывания нейронных сетей является обучение. Для этого вам нужны данные, по возможности много. Вам также нужен движок для выполнения необходимых вычислений. К счастью, существует множество доступных платформ для работы с нейронными сетями, которые являются бесплатными и относительно используемыми для развертывания (см. Ссылки). В этой статье вы увидите, как использовать TensorFlow от Google и среду Python. TensorFlow поставляется с инструкцией для распознавания рукописных цифр в базе данных MNIST. В инструкцию включены учебные и тестовые данные с метками, а также примеры кода.
Вы можете найти код, который я использовал для обучения нейронной сети, на Github. Некоторые основные моменты и фрагменты кода обсуждаются ниже.
Импорт данных: Пример набора данных, который поставляется с TensorFlow, включает 55000 изображений для обучения и 10000 изображений для тестирования. Они изначально исходят из работы Яна Лекуна и коллег. Наличие большого количества высококачественных данных очень важно для успеха процесса. Кроме того, на изображениях имеются ярлыки: на них указывается, какое число изображено на картинке, и эта информация очень важна, поскольку упражнение заключается в осуществлении контролируемого обучения.
Определение нейронной сети: в сети есть четыре тензора (в данном случае — вектор и матрицы): W0, W1, b0 и b1. Они определены в следующем фрагменте кода. Чтобы лучше понять их роль, а также значение перекрестной энтропии и оптимизатора градиентного спуска для обучения нейронной сети, см. ссылки, а именно «Neural Networks and Deep Learning» и инструкцию TensorFlow.
Обучение нейронной сети: обучение проходит с несколькими этапами оптимизации. Оно проводится с использованием 55000 изображений с метками. Выполняется более 30000 итераций, с использованием «мини-порций» размером 100 изображений. На каждом шаге алгоритм градиентного спуска (gradient descent) вычисляет обновление весов и смещений (W0, W1, bo и b1) с целью минимизации функции потерь (cross_entropy). Соответствующий фрагмент кода: Результат: в результате обученная сеть имеет точность около 98% в прогнозировании изображений в тестовом наборе. Обратите внимание, что тестовый набор состоит из 10000 изображений и не совпадает с набором изображений, используемых для обучения (учебный набор содержит 55000 изображений).Можно получить более высокую точность при более сложных конфигурациях нейронной сети (подробности см. в Ссылках), но это выходит за рамки данной статьи.
Ручной подсчет нейронной сети, пример на языке Python
Основной результат обучающих операций состоит в том, что тензоры (в данном случае матрицы и векторы), которые составляют нейронную сеть, теперь заполнены полезными значениями. Я считаю, что хороший способ понять, как все это работает, — «запустить сеть вручную», то есть запустить в качестве примера переход от изображения рукописной цифры к предсказанию ее значения обученной нейронной сетью. В качестве первого шага мы извлекаем значения обученных тензоров из нашей модели в массивы numpy для последующей обработки:
Пример «ручного» управления сетью в Python выглядит следующим образом: W0_matrix, b0_array, W1_matrix и b1_array являются тензорами, которые составляют нейронную сеть после обучения, testimage — слой ввода, sigmoid() используется как функция активации, hidden_layer представляет скрытый слой сети, predicted — это слой вывода, а softmax() — это функция, используемая для нормализации вывода как распределения вероятностей. В конце вычисления массив predicted[n] содержит предсказание, что входное изображение представляет цифру «n». Функция argmax() находит значение «n», для которого predicted[n] максимально.Код, показанный выше, прогнозирует значение 7 для тестового изображения. Прогноз подтверждается как правильный значением метки, а также может быть визуально подтвержден растровым отображением тестового изображения (см. Рис. 1).
Перенос тестовых данных и сети в Oracle
Пример из предыдущего параграфа о том, как вручную запустить механизм подсчета, показывает, что обслуживание нейронной сети может быть прямолинейным, в некоторых случаях это просто вопрос выполнения некоторых базовых вычислений с матрицами. Это контрастирует со сложностью обучения нейросетевых моделей, где часто требуется специализированный движок, высокое качество обучающих данных, а в более сложных случаях еще и специализированное оборудование, такое как GPU карты.
Тема предыдущего параграфа также подготовила почву для следующей разработки: это перемещение тензоров нейронной сети и тестовых данных в Oracle и внедрение обслуживающего механизма там.
Существует множество способов экспорта numpy массивов Python. Один из них — сохранить массивы в текстовом формате. Здесь же вы увидите метод, предназначенный для прямого экспорта в Oracle с помощью cx_Oracle, библиотеки Python для взаимодействия с Oracle. Для получения дополнительных примеров и ссылок о том, как использовать cx_Oracle советую ознакомиться с заметками «Oracle и Python и cx_Oracle».
Код можно найти на Github, вот некоторые релевантные фрагменты:
— Создайте таблицы для размещения определений тензоров и тестовых данных:
SQL> create table tensors (name varchar2(20), val_id number, val binary_float, primary key(name, val_id)); SQL> create table testdata (image_id number, label number, val_id number, val binary_float, primary key(image_id, val_id)); — Из Python откройте соединение с Oracle:
import cx_Oracle ora_conn = cx_Oracle.connect('mnist/<a href="mnist@ORCL">mnist@ORCL</a>') cursor = ora_conn.cursor() — Пример того, как перенести матрицу W0 в таблицу Oracle tensors:
i=0 sql="insert into tensors values ('W0', :val_id, :val)" for column in W0_matrix: array_values = [] for element in column: array_values.append((i, float(element))) i += 1 cursor.executemany(sql, array_values) ora_conn.commit() Наконец, вы можете экспортировать таблицы testdata и tensors для последующего использования. В репозитории Github вы можете найти dump-файл, полученный с помощью следующей команды (запустить как Oracle):
$ expdp mnist/mnist tables=testdata,tensors directory=DATA_PUMP_DIR dumpfile=MNIST_tables.dmp Оптимизации Oracle для линейной алгебры
Из документации Oracle: «Пакет UTL_NLA предоставляет подмножество операций BLAS и LAPACK (версия 3.0) для векторов и матриц, представленных как VARRAYS». Это очень полезно для выполнения вычислений, необходимых для обслуживания нейронной сети из этой статьи.
Ниже приведен фрагмент кода MNIST, чтобы понять, как это работает на практике. Код выполняет вычисление v_Y0 = v_Y0 + g_W0_matrix * p_testimage_array, где g_W0_matrix — матрица 784x100, p_testimage_array — вектор из 784 элементов (кодирует изображения 28x28), а v_Y0 — вектор из 100 элементов.
utl_nla.blas_gemv( trans => 'N', m => 100, n => 784, alpha => 1.0, a => g_W0_matrix, lda => 100, x => p_testimage_array, incx => 1, beta => 1.0, y => v_Y0, incy => 1, pack => 'C' ); Чтобы использовать UTL_NLA, тензоры, которые делают нейронную сеть и тестовые изображения, должны храниться в varrays из binary_float или, скорее, быть объявлены типом данных UTL_NLA_ARRAY.
По этой причине также удобно проводить пост-обработку таблиц tensors и testdata следующим образом:
SQL> create table testdata_array as select a.image_id, a.label, cast(multiset(select val from testdata where image_id=a.image_id order by val_id) as utl_nla_array_flt) image_array from (select distinct image_id, label from testdata) a order by image_id; SQL> create table tensors_array as select a.name, cast(multiset(select val from tensors where name=a.name order by val_id) as utl_nla_array_flt) tensor_vals from (select distinct name from tensors) a; Последний шаг, возвращающий вас к обсуждению в разделе «Давайте начнем с конца: как развернуть пакет PL/SQL MNIST и распознать рукописные цифры в Oracle», — это создать пакет PL/ SQL MNIST, который загружает тензоры и выполняет операции, необходимые для подсчета нейронной сети, подробный код можно посмотреть на Github.
Заключение и комментарии
Эта статья описывает пример внедрения механизма подсчета для искусственной нейронной сети с использованием реляционной СУБД Oracle и PL/SQL. Речь идет о простой реализации примера для ознакомления с нейронными сетями: распознавание рукописных цифр в базе данных MNIST. Сеть обучается с помощью TensorFlow, а затем экспортируется в Oracle. Конечным результатом является небольшой пакет PL/SQL, который обеспечивает распознавание цифр с точностью около 98%.
В ближайшем будущем мы можем ожидать рост развертывания нейронных сетей вблизи источников и хранилищ данных. Пример в этой статье того, как реализовать механизм обслуживания нейронной сети в базе данных Oracle, показывает, что это не только возможно, но и легко реализовать.
Обслуживание нейронных сетей намного проще их обучения. Хотя для обучения требуется специализированное программное обеспечение/платформы, знание предметной области и большое количество учебных данных, обученные сети можно импортировать и запускать в целевых системах, что во многих случаях требует низкого использования вычислительных ресурсов.
Эта статья была задумана как учебный материал: вместо более производительной сверточной сети используется простая нейронная сеть прямого распространения (см. Ссылки). Более того, перемещение данных из TensorFlow в Oracle и реализация обслуживающего движка в PL/SQL — это своего рода “костыль” в текущем состоянии, и он не предназначен для использования в production.
Код, сопровождающий эту статью, доступен на Github.
Примечания о том, как создать тестовую среду
Основными компонентами и инструментами для тестирования скриптов в этой статье являются:
среда Python (на Linux с CentOS 7), установленная с помощью Anaconda 4.1: Python 2.7, Jupyter Ipython notebook.
TensorFlow, версия 0.9 (последняя на момент написания статьи), установленная в соответствии с инструкциями https://www.tensorflow.org/versions/r0.9/get_started/os_setup.html
Реляционная СУБД Oracle, работающая на Linux. Скрипты Oracle были протестированы на Oracle 11.2.0.4 и 12.1.0.2
Ссылки и благодарности
Отличным введением в нейронные сети и вдохновением для этой статьи послужила книга Майкла Нильсена (Michael Nielsen) «Neural Networks and Deep Learning».
Код для обучения нейронной сети, используемый в этой статье, является расширением инструкции TensorFlow MNIST от Google.
Также рекомендую: учебник по TensorFlow Нартина Гордона (Nartin Gorner),
«Базовые техники для TensorFlow» Аарона Шумахера (Aaron Schumacher),
«Базы данных MNIST» Яна Лекуна (Yann LeCun),
«Визуализация MNIST» Кристофера Олаха (Christopher Olah),
«Машинное обучение Python» Себастиана Ращка (Sebastian Raschka).
Другие популярные фреймворки для работы с нейронными сетями и глубокого обучения, помимо TensorFlow, включают Theano и Torch среди многих прочих, смотрите также эту страницу на Википедии.
Ну и не забывайте, что в этом году в рамках PG Day состоится секция для специалистов, работающих с Oracle и другими коммерческими базами данных. Ожидаются первоклассные доклады от экспертов из крупнейших технологических компаний и полноценный мастер-класс, посвященный диагностике производительности Oracle Database.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru