Машинное обучение для страховой компании: Реалистичность идеи
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-05-19 19:55

Пятница — отличный день, чтобы что-то начать, например, новый цикл статей по машинному обучению. В первой части команда WaveAccess рассказывает для чего нужно машинное обучение в страховой компании и как они проверяли реалистичность идеи предсказания пиков затрат.

Большое количество успешных проектов с применением машинного обучения реализовано в США, и в основном это решения из области интеллектуальных приложений. Разработавшие их компании изменили рынок и правила игры в своей индустрии. К примеру, Amazon ввёл рекомендательную систему покупок на своем сайте — и это предопределило сегодняшний вид онлайн-магазинов. Google через алгоритмы машинного обучения разработал систему целевой рекламы, предлагающей пользователю индивидуально подобранные товары на основе известной о нем информации. Netflix, Pandora (интернет-радио), Uber стали ключевыми фигурами на своих рынках и задали им дальнейший вектор развития, а в основе решений лежало машинное обучение.
Поскольку сокращение затрат критически важно для этого бизнеса, компании используют большое количество проверенных методов, но всегда находятся в поиске новых возможностей.
Для медицинской страховой компании (нашего клиента) прогнозирование затрат на лечение застрахованных лиц — хороший способ сокращения издержек. Если известно, что в ближайший месяц или два на лечение клиента потребуется достаточно серьезная сумма, нужно присмотреться к нему повнимательнее: например, передать его более квалифицированным врачам-кураторам, предложить пройти диагностические обследования заранее, отслеживать выполнение рекомендаций врачей и так далее, чтобы тем самым снизить в ряде случаев стоимость будущего лечения.
Но как прогнозировать затраты на лечение каждого клиента, когда их больше миллиона?
Одним из вариантов может быть индивидуальный анализ известной о пациенте информации. Так можно предсказать, к примеру, резкое повышение (если рассматривать относительные значения) или просто пик (абсолютные величины) затрат. Данные в этой задаче содержат много шума, поэтому здесь нельзя рассчитывать на результат, близкий к 100% верных предсказаний. Однако, поскольку речь идет о несбалансированной по классам статистике, даже 50% предсказанных пиков при 80-90% предсказанных отсутствий повышения затрат могут дать важную информацию для компании. Подобная задача может быть эффективно решена только средствами машинного обучения. Конечно, можно подобрать вручную набор правил по уже существующим данным, который будет очень грубым и неэффективным в долгосрочной перспективе в сравнении с алгоритмами машинного обучения, поскольку вручную подобрать оптимальные граничные значения и коэффициенты практически невозможно.
Так как Amazon ML поддерживает работу только 1 алгоритма — линейную регрессию (и его адаптацию для задач классификации — логистическую). Это ограничивает возможности реализуемых решений.
Microsoft Azure ML представляет собой более гибкий сервис:
Поскольку для решения поставленных на проекте задач требовалась сложная композиция алгоритмов, выбрали Azure. Однако, так как рассказать о преимуществах комплексного подхода к решению задач машинного обучения невозможно без сравнения, в данной статье мы ограничимся простыми алгоритмами, а более сложные вариации рассмотрим в следующих статьях.
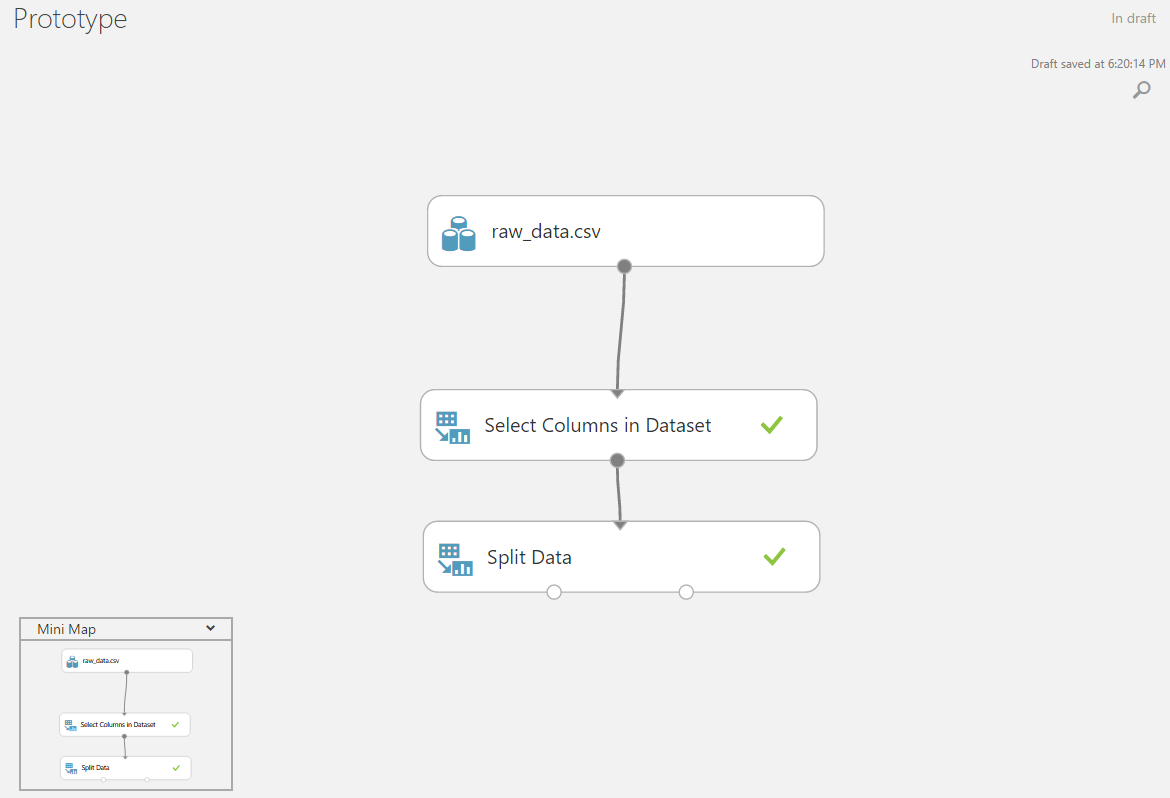 Если в загруженных данных находится больше столбцов, чем нужно, или наоборот, некоторые данные находятся в другом источнике — их можно легко объединить или убрать из матрицы входных данных.
Если в загруженных данных находится больше столбцов, чем нужно, или наоборот, некоторые данные находятся в другом источнике — их можно легко объединить или убрать из матрицы входных данных.
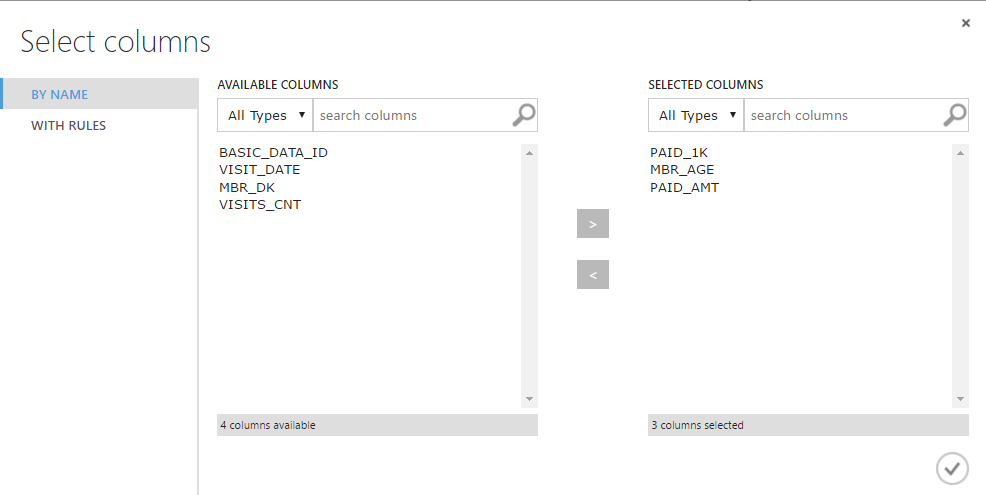 Выберем (для обучения) простейший вариант алгоритма — логистическую регрессию. Этот консервативный метод часто применяют первым, чтобы получить точку для дальнейшего сравнения; в определенных задачах он может оказаться наиболее подходящим и показать лучший результат.
Выберем (для обучения) простейший вариант алгоритма — логистическую регрессию. Этот консервативный метод часто применяют первым, чтобы получить точку для дальнейшего сравнения; в определенных задачах он может оказаться наиболее подходящим и показать лучший результат.
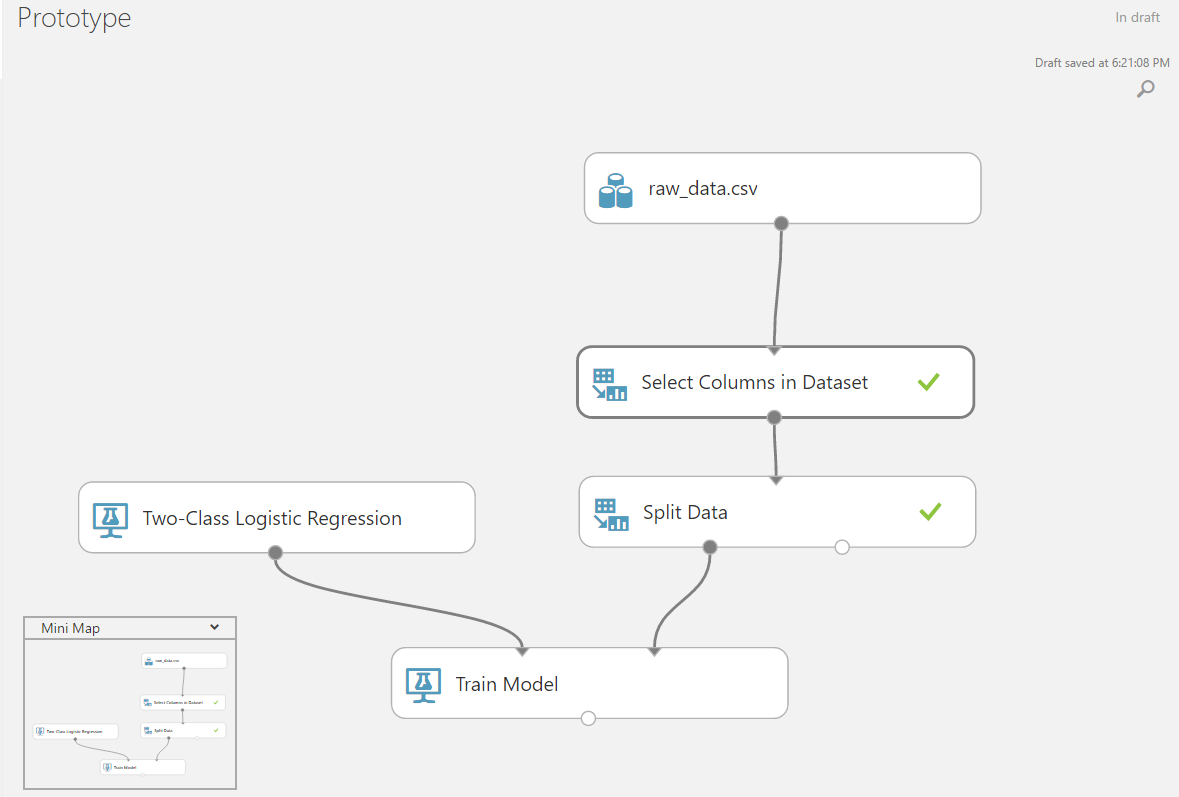 Добавим блоки обучения и тестирования алгоритма и свяжем с ними исходные данные.
Добавим блоки обучения и тестирования алгоритма и свяжем с ними исходные данные.
 Для удобства проверки результатов можно добавить блок оценки результатов работы алгоритма, где можно поэкспериментировать с границей разделения классов.
Для удобства проверки результатов можно добавить блок оценки результатов работы алгоритма, где можно поэкспериментировать с границей разделения классов.
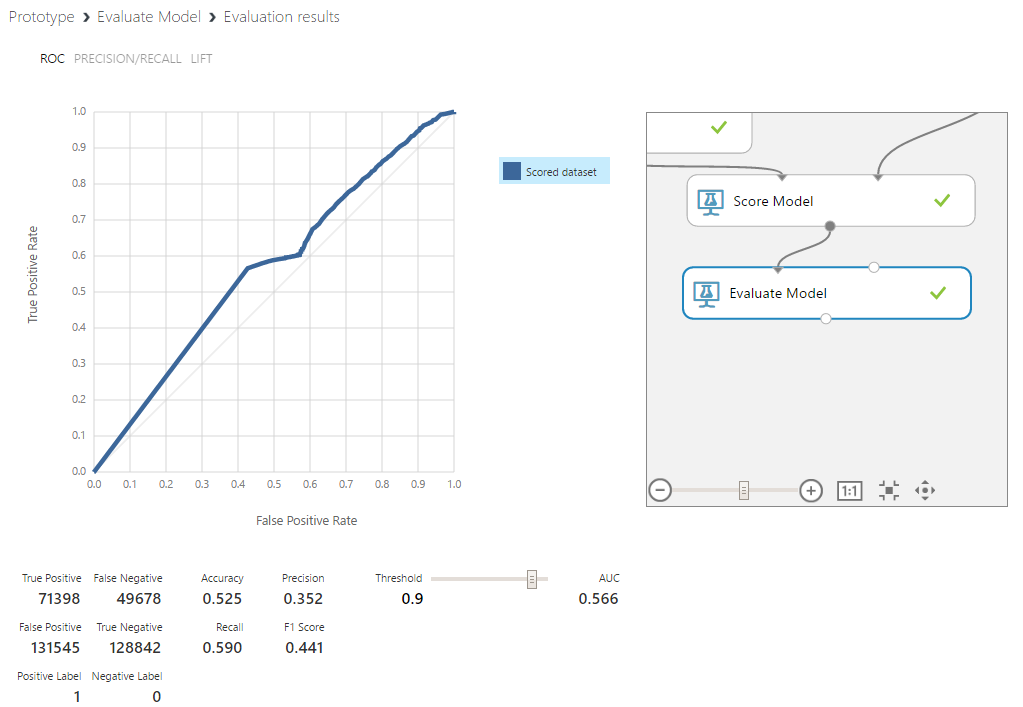 В нашем эксперименте базовый алгоритм на необработанных данных при границе разделения классов, установленной на 0.9, предсказал около 60% пиков и 49% их отсутствия. Это свидетельствует о том, что концепцию стоит развивать на более сложных схемах, что и будет сделано в дальнейшем.
В нашем эксперименте базовый алгоритм на необработанных данных при границе разделения классов, установленной на 0.9, предсказал около 60% пиков и 49% их отсутствия. Это свидетельствует о том, что концепцию стоит развивать на более сложных схемах, что и будет сделано в дальнейшем.
В следующих статьях мы рассмотрим на примере анализ данных, работу других алгоритмов и их комбинаций, борьбу с переобучением и некорректными данными.
Цикл статей «Машинное обучение для страховой компании»
- Реалистичность идеи.
- Обработке данных и исследование алгоритмов.
- Оптимизация алгоритмов.
Введение
Сегодня машинное обучение эффективно используют для автоматизации задач, выполнение которых требует большого количества рутинного ручного труда и которые тяжело запрограммировать традиционным способом. Например, это задачи с большим количеством влияющих переменных: идентификация спам-писем, поиск информации в тексте и так далее. В таких ситуациях применение машинного обучения становится особенно востребованным.Большое количество успешных проектов с применением машинного обучения реализовано в США, и в основном это решения из области интеллектуальных приложений. Разработавшие их компании изменили рынок и правила игры в своей индустрии. К примеру, Amazon ввёл рекомендательную систему покупок на своем сайте — и это предопределило сегодняшний вид онлайн-магазинов. Google через алгоритмы машинного обучения разработал систему целевой рекламы, предлагающей пользователю индивидуально подобранные товары на основе известной о нем информации. Netflix, Pandora (интернет-радио), Uber стали ключевыми фигурами на своих рынках и задали им дальнейший вектор развития, а в основе решений лежало машинное обучение.
Зачем страховой компании машинное обучение?
Важным финансовым показателем для страховой компании является разница между стоимостью проданных страховок и затратами на возмещение по страховым случаям.Поскольку сокращение затрат критически важно для этого бизнеса, компании используют большое количество проверенных методов, но всегда находятся в поиске новых возможностей.
Для медицинской страховой компании (нашего клиента) прогнозирование затрат на лечение застрахованных лиц — хороший способ сокращения издержек. Если известно, что в ближайший месяц или два на лечение клиента потребуется достаточно серьезная сумма, нужно присмотреться к нему повнимательнее: например, передать его более квалифицированным врачам-кураторам, предложить пройти диагностические обследования заранее, отслеживать выполнение рекомендаций врачей и так далее, чтобы тем самым снизить в ряде случаев стоимость будущего лечения.
Но как прогнозировать затраты на лечение каждого клиента, когда их больше миллиона?
Одним из вариантов может быть индивидуальный анализ известной о пациенте информации. Так можно предсказать, к примеру, резкое повышение (если рассматривать относительные значения) или просто пик (абсолютные величины) затрат. Данные в этой задаче содержат много шума, поэтому здесь нельзя рассчитывать на результат, близкий к 100% верных предсказаний. Однако, поскольку речь идет о несбалансированной по классам статистике, даже 50% предсказанных пиков при 80-90% предсказанных отсутствий повышения затрат могут дать важную информацию для компании. Подобная задача может быть эффективно решена только средствами машинного обучения. Конечно, можно подобрать вручную набор правил по уже существующим данным, который будет очень грубым и неэффективным в долгосрочной перспективе в сравнении с алгоритмами машинного обучения, поскольку вручную подобрать оптимальные граничные значения и коэффициенты практически невозможно.
Реализация машинного обучения
В подобных проектах часто актуальна реализация программного комплекса в виде веб-сервиса. Для реализации машинного обучения клиент рассматривал 2 наиболее известных решения в этой области: MS Azure ML и Amazon ML.Так как Amazon ML поддерживает работу только 1 алгоритма — линейную регрессию (и его адаптацию для задач классификации — логистическую). Это ограничивает возможности реализуемых решений.
Microsoft Azure ML представляет собой более гибкий сервис:
- большое количество встроенных алгоритмов + поддержка встраивания своего кода на R и Python;
- во встроенных инструментах есть все необходимое для базовой работы в областях классификации, кластеризации, регрессии, компьютерного зрения, работы с текстом и др.;
- есть функционал для предобработки, манипуляции и организации данных;
- модули в Azure ML организованы как блок-схемы, что делает порог вхождения низким, а работу интуитивной — поэтому Azure ML стал удобным средством прототипирования, позволяющим быстро реализовать базовые решения для проверки жизнеспособности гипотез, идей и проектов.
Поскольку для решения поставленных на проекте задач требовалась сложная композиция алгоритмов, выбрали Azure. Однако, так как рассказать о преимуществах комплексного подхода к решению задач машинного обучения невозможно без сравнения, в данной статье мы ограничимся простыми алгоритмами, а более сложные вариации рассмотрим в следующих статьях.
Прототипирование
Проверим реалистичность идеи предсказания пиков затрат. В качестве исходных данных, для получения базовой отметки, возьмем необработанные данные: возраст пациента, количество приемов врача, количество потраченных на клиента денег за несколько последних месяцев. Границу для пика затрат на следующий месяц выберем как $1000. Выгрузим данные в Azure и разделим их на тренировочную и тестовую выборки в соотношении 4 к 1 (валидацию на этом этапе проводить не будем, поэтому выборка для нее в данной ситуации не предусмотрена). Если в загруженных данных находится больше столбцов, чем нужно, или наоборот, некоторые данные находятся в другом источнике — их можно легко объединить или убрать из матрицы входных данных. Выберем (для обучения) простейший вариант алгоритма — логистическую регрессию. Этот консервативный метод часто применяют первым, чтобы получить точку для дальнейшего сравнения; в определенных задачах он может оказаться наиболее подходящим и показать лучший результат. Добавим блоки обучения и тестирования алгоритма и свяжем с ними исходные данные. Для удобства проверки результатов можно добавить блок оценки результатов работы алгоритма, где можно поэкспериментировать с границей разделения классов. В нашем эксперименте базовый алгоритм на необработанных данных при границе разделения классов, установленной на 0.9, предсказал около 60% пиков и 49% их отсутствия. Это свидетельствует о том, что концепцию стоит развивать на более сложных схемах, что и будет сделано в дальнейшем.В следующих статьях мы рассмотрим на примере анализ данных, работу других алгоритмов и их комбинаций, борьбу с переобучением и некорректными данными.
Об авторах
Команда WaveAccess создаёт технически сложное, высоконагруженное и отказоустойчивое программное обеспечение для компаний из разных стран. Комментарий Александра Азарова, руководителя направления machine learning в WaveAccess:Машинное обучение позволяет автоматизировать области, где на текущий момент доминируют экспертные мнения. Это дает возможность снизить влияние человеческого фактора и повысить масштабируемость бизнеса.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru