Похоже, с помощью нейронных сетей появился шанс слабый ИИ сделать сильным
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-04-06 00:00
искусственный интеллект, ИИ проекты, новости нейронных сетей
 Рост интереса к разработкам в сфере искусственного интеллекта связан не только с увеличением производительности компьютеров, но и с рядом качественных прорывов в машинном обучении. И хотя все планомерно идет к тому, что успех более чем вероятен, и в возможности создания в обозримом будущем сильного ИИ уже мало кто сомневается, одной важной стороне этого процесса уделяется незаслуженно мало внимания.
Рост интереса к разработкам в сфере искусственного интеллекта связан не только с увеличением производительности компьютеров, но и с рядом качественных прорывов в машинном обучении. И хотя все планомерно идет к тому, что успех более чем вероятен, и в возможности создания в обозримом будущем сильного ИИ уже мало кто сомневается, одной важной стороне этого процесса уделяется незаслуженно мало внимания.К построению искусственного интеллекта есть два принципиально разных подхода, назовем их условно алгоритмический и с помощью самообучения. В первом случае надо вручную прописать все правила, по которым действует интеллект, а во втором нужно создать алгоритм, который сам обучится на некотором большом объеме данных, и выделит эти правила самостоятельно. Как мы уже знаем, алгоритмический путь потерпел катастрофическое фиаско. И это печально, потому что этот путь более «правильный». Хотя в нем есть свои недостатки, вроде взрывающихся роботов от логического парадокса (шутка. хотя нет, правда), но зато такой робот никогда не сделает того, на что он не запрограммирован.
Но важно даже не это, а то что это академическая задача. Разобраться, как работает сознание, интеллект, разум. Поражение в этой области это как пощечина нашему собственном интеллекту. Почему же ничего не получилось? В основном, это проблема комбинаторного взрыва. Разум нашего уровня оперирует слишком уж большим количеством понятий и их отношениями. В развитом языке порядка 500 тысяч слов, и еще наверно столько же, а может и больше, чувственных образов, которым пока не дали словесного определения. Итого, интеллект человеческого уровня должен оперировать не менее чем миллионом понятий и их взаимоотношениями. Пусть вас не смущает, что на практике людьми используется порядка 2000-30000 тысяч слов (2000 — это необходимый минимум для свободного общения в другой стране, см. Simplified English, а писатели вроде Шекспира, используют порядка 30 тысяч слов). Просто это обобщенные и наиболее часто используемые слова в тех рутинных вещах и ситуациях, которые мы называем жизнью. А на самом деле развитый мозг оперирует намного большим числом «внутренних» понятий, которые он при желании облекает в эти общие слова. Хотя и 30 тысяч это большое число. Представьте, что ваша собака могла бы различать 30 тысяч слов. Понимать, что обозначает каждое из этих слов и реагировать на каждое по-разному. Определенно, она была бы гораздо умнее. И даже наверняка с ней можно было бы поддерживать беседу.
«Алгоритмический» путь
Известен древний компьютерный эксперимент, когда попытались описать вручную созданными правилами взаимоотношение простых геометрических фигур в виртуальной сцене. «Шар круглый», «куб может сдвинуть другой куб», «шар может катиться», «пирамида может лежать на кубе», и так далее. Оказалось, что при числе объектов в сцене более пяти, вручную описать все их возможные физические взаимодействия очень сложно. А при числе более десяти, уже не представляется возможным. А нам нужно сделать такое ручное описание не менее, чем для миллиона понятий! Комбинаторный взрыв.Именно он стал причиной провала экспертных систем. Разумеется, первым делом мы попытались найти общие правила, которые упростили бы количество требуемых описаний для понятий. Ведь очевидно, что ходить может только то, у чего есть ноги. Поэтому мы можем написать одно правило, описывающее ходьбу, для всех ходячих объектов. И все равно количество понятий, для которых надо вручную писать правила, а главное — количество их возможных взаимодействий друг с другом, невероятно велико. И по факту мы имеем, что мы не смогли это сделать. Даже с применением всех доступных тогда методов машинного обучения, которые позволяли в частично автоматическом режиме строить такие правила (см. например алгоритм построения деревьев решений, которые по сути и представляют собой логику работы робота с «алгоритмическим» искусственным интеллектом).
Еще один наглядный пример — провал автоматических алгоритмических переводчиков. Построить общие правила, полностью описывающие два разных языка, это по сути создать правила, по которым действует разум, который оперирует этими языками. Один человек может знать два языка, поэтому описать общую структуру двух языков (чтобы их можно было конвертировать один в другой), это не то же самое, что описать правила синтаксиса для одного отдельного языка. Создать правила одновременно для двух языков это значит описать их общую структуру, а значит и общую структуру того человека, который ими пользуется. Те, кто занимался созданием баз знаний для таких алгоритмических переводчиков, могут более подробно рассказать, с какими трудностями они столкнулись. Но в целом, трудности сводятся к комбинаторному взрыву, и к тому, что реально используемых в мышлении понятий больше, чем слов. Более того, буквально за год-два язык меняется, некоторые правила устаревают и перевод с их помощью будет восприниматься комично. Опять получится "-Как ты это делаешь? -Всегда правой!" ("-How do you? -All right!"). Последний случай такой попытки создать вручную базу знаний для автоматического переводчика, который приходит на память, это ABBYY Compreno. Прекрасное начинание, много труда, но похоже завершившееся как и предыдущие попытки.
Самообучение
А что касается подхода с самообучением, то с ним все просто. Нужен алгоритм и нужны данные для обучения. Со вторым до недавнего времен, как минимум, до развитого интернета с большим количеством контента, было туго. Но собрав всю свою волю и самообладание в кулак, необходимо признать, что и с алгоритмами машинного обучения ситуация, до сих пор, была так себе… Уже давно существовали библиотеки книг, содержащие достаточно материала, чтобы на их базе создать искусственный интелелект. Почему же мы опять облажались? В первый раз с ручным построением правил, а теперь и с машинным обучением по книгам. Если бы на это существовал простой ответ, то мы бы уже все сделали. Но, кажется, с последними достижениями в сфере слабого ИИ, разгадка и ответ на этот вопрос стали ближе.Здесь совпали сразу несколько факторов:
1. Рост вычислительной мощности. В основном, параллельные вычисления на GPU, что дало возможность даже простым людям с легкостью повторять результаты самых последних научных работ (что ранее было недоступно, по крайней мере, если у вас не было личного суперкомпьютера). Да-да, вы правильно поняли. Для таких замечательных фреймворков, вроде связки TensorFlow + Keras, созданы копии самых современнейших архитектур нейросетей. Все, о чем вы слышали в новостях о нейросетях и их достижениях за последние несколько лет, вы можете повторить на домашнем компьютере. Буквально в течении нескольких минут, необходимых для скачивания этих библиотек. Конечно, гиганты вроде Google могут себе позволить запускать расчет на 1000 компьютерах с GPU с 12 Gb видеопамяти на борту в течении пары недель. Но и обычный настольный игровой компьютер тоже дает сейчас большой простор для маневра.
2. Увеличение данных для обучения. База картинок ImageNet содержит порядка 10 млн. фотографий, вручную маркированных на более чем 1000 категорий. Впечатляющий результат, учитывая что первые попытки распознавания образов предпринимались с базами в несколько сотен образцов.
3. Но, главное, появились новые эффективные методы обучения. Так как старыми алгоритмами мы до сих пор не можем добиться ничего вразумительного, даже от новых увеличенных объемов данных. И это говорит само за себя (хоть это и печально, повторюсь).
Если не получается найти выход, выходите через вход
Разумеется, возможны и разные комбинированные методы. Где-то используем самообучение, где-то вручную пишем правила. Именно так и происходит сейчас. Google Assistant, Siri, IBM Watson — все они используют для распознавания речи и картинок машинное обучение (как правило, нейросети), а для общей работы вручную написанные правила. Watson вообще, судя по всему, представляет собой жуткую смесь древних экспертных систем и современных узкоспециализированных модулей по распознаванию. Более того, такой подход сейчас кажется наиболее перспективным. Только с обратным порядком — не мы пишем правила для примитивных распознавалок, а надо создать ИИ нашего уровня, и дать ему доступ ко всей алгоритмической мощи современных компьютеров. И такие ранние попытки уже предпринимаются, например Нейронная машина Тьюринга, где пытаются научить нейросеть пользоваться жестким диском для хранения структурированных данных. С рядом ограничений, но суть именно такова.Хочется верить, что мы все же осилим эту задачу, и с помощью машинных методов создадим ИИ автоматически, а потом с помощью этих же машинных методов упростим полученный набор правил до минимально возможного. И получим тот самый алгоритмический сильный ИИ. Это было бы здорово. Святой грааль робототехников. Да и в целом, нашего разума по изучению самого себя.
Так что именно изменилось? Откуда такой хайп по поводу ИИ в последнее время?
Нейронные сети
Не секрет, что после долгой зимы в сфере ИИ, наступившая весна обязана своим появлением современному развитию глубоких нейронных сетей. Дело в том, что существовавшие до этого нейросети были качественно ограничены только двумя слоями. После двух первых (а точнее, последних) слоев градиент, по которому происходит обучение методом обратного распространения ошибки, из-за математических особенностей быстро становится все меньше и меньше. Веса между нейронами остальных слоев перестают оказывать влияние на результат, и получается что фактически работают только два последних слоя нейросети, а остальные оказываются пустым балластом. Конечно, архитектур нейронных сетей еще в давние времена было придумано множество, с разными способами обучения, но так как они себя не оправдали (по крайней мере, пока), то далее будем вести речь только о самой успешной модели искусственной нейронной сети — перцептронах и их ближайших родственниках.Решение по эффективному обучению многослойных нейросетей оказалось на удивление простым: что если взять один входной слой, добавить к нему только один промежуточный слой, а третьим слоем (выходным) сделать точную копию первого входного. И заставить нейронную сеть научиться на выходе делать копию первого (т. е. входного) слоя. Если во внутреннем слое количество нейронов будет меньше, чем во входном, то у нейронной сети не будет выбора, кроме каким-то образом сжать информацию. А это и есть извлечение неких общих признаков. Такая штука называется автоэнкодером и прекрасно обучается стандартным методом обратного распространения ошибки, так как представляет собой обычный однослойный перцептрон.

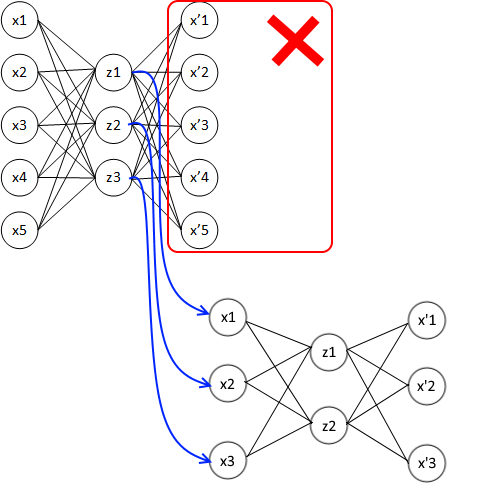
Какой в этом физический смысл, помимо решения проблемы исчезающего градиента? Дело в том, что в первом слое (в первом автоэнкодере) будут выделяться какие-то простые признаки. Скажем, вертикальные и горизонтальные линии, если идет речь о распознавании изображений. Второй слой (второй автоэнкодер) на своем входе будет получать уже не исходные пиксели картинки, а только вертикальные и горизонтальные линии. И уже из этих линий выделять признаки более высокого абстрактного уровня: квадраты, круги, многоугольники. Третий слой получит на свой вход эти абстрактные простые фигуры и будет оперировать только ими, выделив из них, скажем, схематичную фигурку человека («палка, палка, огуречик — вот и вышел человечек!»). Все что нам не хватает для полного счастья, это на выходе из такой многослойной-многоэнкодерной сети добавить один-два слоя обычного перцептрона, чтобы классифицировать результат самого последнего автоэнкодера. Разбить человечков по классам или вывести в удобном виде (x,y) координаты фигуры на картинке.
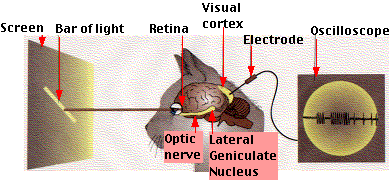
Хорошая новость в том, что наш собственный мозг (по крайней мере, зрение) работает именно таким способом. На самых первых нейронах, связанных с сетчаткой глаза, распознаются только простые линии и градиенты яркости. Примерно такие:

На следующем слое нейроны активируются как реакция на более сложные фигуры, на следующем на еще более сложные, и так далее. В какой-то момент, примерно на десятом слое и спустя примерно 100 мс от момента попадания фотонов на сетчатку глаза (обработка на каждом слое занимает 10-20 мс, поэтому наш мозг, упрощенно говоря, представляет собой десятислойную нейронную сеть), нарастающая сложность распознанных образов достигает такого уровня, что мы определяем, что перед нами стоит красивая девушка, и нервный импульс с выхода десятого слоя начинает бежать к мышцам лица, чтобы мы начали улыбаться. Крайне эффективное применение нейронной сети, выработанное эволюцией для продолжения рода.
Более того, все это подтверждено экспериментально на томографах и прямым подключением электродов к разным группам нейронов в мозгу. Тренироваться, согласно славной старой традиции (или не славной в данном случае, учитывая инвазивность метода) начали на кошках. Подробнее в замечательной статье про работу зрения и наиболее близкие к нему по принципу действия сверточные нейронные сети: Обзор топологий глубоких сверточных нейронных сетей.
Не смотря на свою простоту, идея такого послойного обучения нейросети получила практическую реализацию только в середине 2000-х годов (хотя и до этого пытались предобучать начальные слои в многослойном перцептроне методами без учителя, но не так успешно). Надо понимать, что такой метод обучения глубоких нейронных сетей (и даже не совсем такой, т.к. все начиналось с ограниченных машин Больцмана, но суть та же) это была первая ласточка, известившая о новой нейросетевой революции. С того момента прогресс ушел далеко вперед, сейчас автоэнкодеры и их аналоги в чистом виде практически не используются (их заменили новые методы регуляризации и слои вроде сверточных или реккурентных), а зоопарк архитектур нейросетей разросся до неприличных размеров. Краткую памятку о различных типах современных нейронных сетей можно наглядно посмотреть здесь: Зоопарк архитектур нейронных сетей. Часть 1 и Часть 2. Из двух частей. Краткую. Ага.
Оказалось, что в энкодере внутрениий слой можно делать не меньше, а больше входного. А чтобы сигнал не проходил насквозь без изменений (нам ведь нужно реализовать что-то вроде сжатия, чтобы вычленить признаки), давайте случайно отключать входные нейроны или подмешивать к ним случайные величины, эмулируя случайный шум. Это оказалось даже полезнее, чем чистый автоэнкодер, так как позволяет распознавать зашумленные данные. Вообще, идея случайным образом выключать часть нейронов во время обучения, т.н. dropout (иногда до 50% всей нейросети!) оказалась очень полезной. В некотором роде это приближение к биологическому образцу, так как в живом мозге активность нейронов тоже носит отчасти случайный характер. За подробностями отправлю к замечательной и крайне рекомендуемой к прочтению статье о современных типах нейронных сетей и как мы дошли до такой жизни Как обучается ИИ.
Строго говоря, обучать нейронную сеть вовсе необязательно методом обратного распространения ошибки. Существуют варианты вероятностного обучения, есть что-то вроде отжига, когда материал постепенно остывает, понижая свою температуру сходным образом с природным процессом (только в роли чисел-показаний температуры, у нас числа в весах между нейронами). Существуют эмуляции активации биологических нейронов, когда связь усиливается при частой активации, в том числе с эмуляцией тормозных нейронов. Есть даже обучение весов нейросети с помощью генетического алгоритма или методом муравьиной колонии. Ведь в конце концов нам надо всего лишь подобрать числа в весах нейронов, чтобы сигнал от входа максимально хорошо и правильно дошел до нужного выхода. А метод подбора этих чисел не так уж важен, лишь бы он выполнял свою функцию. Просто градиентный спуск методом обратного распространения ошибки один из самых быстрых, а с современными его модификациями вроде adam (сравнение современных способов обучения нейросетей: Методы оптимизации нейронных сетей), он почти не застревает в локальных экстремумах.
Чтобы не увеличивать размер и так непомерно раздувшейся статьи, краткое описание наиболее интересных и перспективных для сильного ИИ архитектур современных нейросетей убраны под спойлеры.
Сверточные нейронные сети
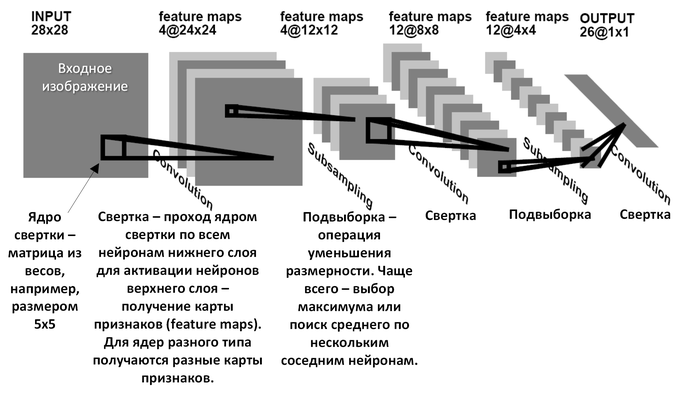 На самом деле сверточные сети работают так. Сначала мы решаем, сколько признаков хотим выделить из картинки. Это будет количество плоскостей (второй большой квадрат на картинке, обозначенный feature maps). Например, если мы хотим найти вертикальные линии, горизонтальные и диагональные, нам достаточно 4 плоскостей (т.к. диагональные могут быть двух видов: / и ). После этого решаем, какого размера должен быть фильтр, которым будем проходить по картинке. Это размер маленького черного квадратика, допустим, 3х3 пикселя. И заполняем его какими-нибудь числами, графически кодирующими примитив, который хотим найти. К пример, заполняем четверками по диагонали, чтобы искать наклонную линию . А потом проходим им как скользящим окном по всей исходной картинке, и перемножаем пиксели на картинке на пиксели в нашем маленьком квадратике-фильтре, и суммируем результат. Получаем одно единственное число, характеризующее насколько картинка под скользящим окном похожа на картинку в фильтре. И записываем это число в плоскость, соответствующую этому фильтру. Картинка ниже лучше объясняет принцип.
На самом деле сверточные сети работают так. Сначала мы решаем, сколько признаков хотим выделить из картинки. Это будет количество плоскостей (второй большой квадрат на картинке, обозначенный feature maps). Например, если мы хотим найти вертикальные линии, горизонтальные и диагональные, нам достаточно 4 плоскостей (т.к. диагональные могут быть двух видов: / и ). После этого решаем, какого размера должен быть фильтр, которым будем проходить по картинке. Это размер маленького черного квадратика, допустим, 3х3 пикселя. И заполняем его какими-нибудь числами, графически кодирующими примитив, который хотим найти. К пример, заполняем четверками по диагонали, чтобы искать наклонную линию . А потом проходим им как скользящим окном по всей исходной картинке, и перемножаем пиксели на картинке на пиксели в нашем маленьком квадратике-фильтре, и суммируем результат. Получаем одно единственное число, характеризующее насколько картинка под скользящим окном похожа на картинку в фильтре. И записываем это число в плоскость, соответствующую этому фильтру. Картинка ниже лучше объясняет принцип.
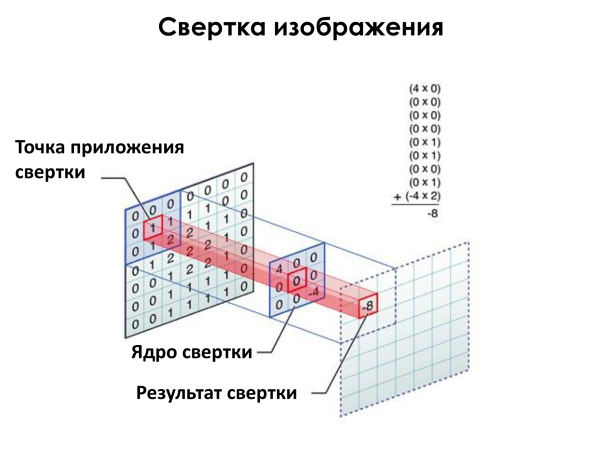 Иллюстрация с лекции Яндекса
Иллюстрация с лекции Яндекса
Здесь маленький синий квадратик между плоскостями почти что кодирует диагональную линию из левого верхнего угла в правый нижний, если бы у него по диагонали были все четверки (к сожалению, иллюстрация нашлась только такая, с нулем в центре и -4 в нижнем правом углу). Область на исходной картинке немного похожа на такую диагональную линию, так как там есть 1 и 2, которые умножались бы на 4, соответствующие положениям этих 1 и 2. И общая степень похожести была бы 0*4+1*4+2*4=12 (вместо -8 на картинке). А вот если бы на исходной картинке по диагонали тоже были бы четверки, а еще лучше десятки! («летят n самолетов, нет, n мало, пусть будет k. и оба реактивные»). Тогда степень похожести была бы 10*4+10*4+10*4=120. Чем больше число, тем лучше.
На самом деле, мы не знаем какие именно графические примитивы мы хотим искать, а главное, какие из них окажутся важными для распознавания, например, морды лица кота на фото. Поэтому мы просто создадим заведомо избыточное количество плоскостей. Каждая из плоскостей составляет как бы карту, на которой отмечены места, где на картинке встречаются наиболее похожие на ее фильтр участки. Как на символ в примере выше. Как правило, в сверточных сетях в первом слое используется 100-200 плоскостей, чтобы перекрыть все возможные типы простых примитивов. Еще зависит от размера фильтра, чем он больше по размеру, тем большее разнообразие примитивов может вместить, и тем больше нам надо плоскостей-карт для них. И инициализируем веса принадлежащих им окошек-фильтров случайными числами. Нейросеть сама разберется, какие придать им значения в процессе обучения. Что удивительно, обученные на реальных фотографиях сверточные нейросети в первом слое создают именно такие же примитивы, вроде наклонных линий и пятен разной яркости (см. выше картинку), на которые реагируют нейроны первого слоя у живой кошки. И, надо полагать, у человека тоже.
Какие во всем этом плюсы?
Во-первых, уменьшается число нейронов по сравнению с полносвязным перцептроном, а это экономия памяти и ускорение расчета.
Во-вторых, выходные плоскости-карты признаков используются дальше как входные картинки для следующих сверточных слоев. Что позволяет строить глубокие многослойные сети, в которых каждый слой все так же прекрасно обучается. По сути, тот же принцип, что у автоэнкодеров выше, которые предвестили новый рывок нейросетей. Следующий слой работает уже не с пикселями исходной картинки, а с линиями как абстрактными объектами. И генерирует на выходе квадраты, круги, треугольники. Которые используются как входы для следующего слоя, который из этих фигур распознает фигуру человека.
В-третьих, сверточные сети позволяют определять не только факт наличия признака на картинке, но и его положение. В каком-то слое лицо человека будет распознано не просто по наличию где-то на фотографии глаз и рта, а по тому, что левый глаз расположен именно выше и левее, правый выше и правее, а рот ниже их обоих и по центру. Тут можно провести аналогию с каскадами Хаара, которые использовались раньше для распознавания лиц в методе Виолы-Джонса. Только сверточные нейронные сети могут распознавать не только графические примитивы вроде горизонтальных/вертикальных полос, но и такие сложные абстрактные понятия как «попугай». Если «попугай» расположен на правом плече абстрактного объекта «человек с деревянной ногой», то с большой вероятностью этот объект «пират». В этом сила сверточных (и других многослойных) нейронных сетей.
В-четвертых, сверточные нейронные сети в целом повторяют устройство нашего зрения (как сигналы от сетчатки проходят первичную обработку и попадают в мозг), поэтому работает схожим образом. И хотя повторяют те же ошибки в оптическом распознавании, что и мы, но и делают точно такие же эффективные акценты в тех местах на фото, где делаем мы.
Все это сделало сверточные сети такими эффективными в задачах распознавания.
Сверточные нейронные сети
Отдельно стоит отметить сверточные нейронные сети. Вот стандартная картинка из википедии, служащая для иллюстрации ее принципа работы. Не знаю как вам, а мне она была долгое время непонятна, хотя написанием собственных реализаций нейронных сетей (не сверточных) и их ансаблей я занимался еще лет 20 назад, когда готовых библиотек для этого дела в интернете просто не было. Потом, как и многие в то время, столкнулся с типичными проблемами вроде исчезающего градиента и недостатка вычислительной мощности, и все забросил. Хорошо, что брошенное знамя подобрали другие. На самом деле сверточные сети работают так. Сначала мы решаем, сколько признаков хотим выделить из картинки. Это будет количество плоскостей (второй большой квадрат на картинке, обозначенный feature maps). Например, если мы хотим найти вертикальные линии, горизонтальные и диагональные, нам достаточно 4 плоскостей (т.к. диагональные могут быть двух видов: / и ). После этого решаем, какого размера должен быть фильтр, которым будем проходить по картинке. Это размер маленького черного квадратика, допустим, 3х3 пикселя. И заполняем его какими-нибудь числами, графически кодирующими примитив, который хотим найти. К пример, заполняем четверками по диагонали, чтобы искать наклонную линию . А потом проходим им как скользящим окном по всей исходной картинке, и перемножаем пиксели на картинке на пиксели в нашем маленьком квадратике-фильтре, и суммируем результат. Получаем одно единственное число, характеризующее насколько картинка под скользящим окном похожа на картинку в фильтре. И записываем это число в плоскость, соответствующую этому фильтру. Картинка ниже лучше объясняет принцип. Иллюстрация с лекции ЯндексаЗдесь маленький синий квадратик между плоскостями почти что кодирует диагональную линию из левого верхнего угла в правый нижний, если бы у него по диагонали были все четверки (к сожалению, иллюстрация нашлась только такая, с нулем в центре и -4 в нижнем правом углу). Область на исходной картинке немного похожа на такую диагональную линию, так как там есть 1 и 2, которые умножались бы на 4, соответствующие положениям этих 1 и 2. И общая степень похожести была бы 0*4+1*4+2*4=12 (вместо -8 на картинке). А вот если бы на исходной картинке по диагонали тоже были бы четверки, а еще лучше десятки! («летят n самолетов, нет, n мало, пусть будет k. и оба реактивные»). Тогда степень похожести была бы 10*4+10*4+10*4=120. Чем больше число, тем лучше.
На самом деле, мы не знаем какие именно графические примитивы мы хотим искать, а главное, какие из них окажутся важными для распознавания, например, морды лица кота на фото. Поэтому мы просто создадим заведомо избыточное количество плоскостей. Каждая из плоскостей составляет как бы карту, на которой отмечены места, где на картинке встречаются наиболее похожие на ее фильтр участки. Как на символ в примере выше. Как правило, в сверточных сетях в первом слое используется 100-200 плоскостей, чтобы перекрыть все возможные типы простых примитивов. Еще зависит от размера фильтра, чем он больше по размеру, тем большее разнообразие примитивов может вместить, и тем больше нам надо плоскостей-карт для них. И инициализируем веса принадлежащих им окошек-фильтров случайными числами. Нейросеть сама разберется, какие придать им значения в процессе обучения. Что удивительно, обученные на реальных фотографиях сверточные нейросети в первом слое создают именно такие же примитивы, вроде наклонных линий и пятен разной яркости (см. выше картинку), на которые реагируют нейроны первого слоя у живой кошки. И, надо полагать, у человека тоже.
Какие во всем этом плюсы?
Во-первых, уменьшается число нейронов по сравнению с полносвязным перцептроном, а это экономия памяти и ускорение расчета.
Во-вторых, выходные плоскости-карты признаков используются дальше как входные картинки для следующих сверточных слоев. Что позволяет строить глубокие многослойные сети, в которых каждый слой все так же прекрасно обучается. По сути, тот же принцип, что у автоэнкодеров выше, которые предвестили новый рывок нейросетей. Следующий слой работает уже не с пикселями исходной картинки, а с линиями как абстрактными объектами. И генерирует на выходе квадраты, круги, треугольники. Которые используются как входы для следующего слоя, который из этих фигур распознает фигуру человека.
В-третьих, сверточные сети позволяют определять не только факт наличия признака на картинке, но и его положение. В каком-то слое лицо человека будет распознано не просто по наличию где-то на фотографии глаз и рта, а по тому, что левый глаз расположен именно выше и левее, правый выше и правее, а рот ниже их обоих и по центру. Тут можно провести аналогию с каскадами Хаара, которые использовались раньше для распознавания лиц в методе Виолы-Джонса. Только сверточные нейронные сети могут распознавать не только графические примитивы вроде горизонтальных/вертикальных полос, но и такие сложные абстрактные понятия как «попугай». Если «попугай» расположен на правом плече абстрактного объекта «человек с деревянной ногой», то с большой вероятностью этот объект «пират». В этом сила сверточных (и других многослойных) нейронных сетей.
В-четвертых, сверточные нейронные сети в целом повторяют устройство нашего зрения (как сигналы от сетчатки проходят первичную обработку и попадают в мозг), поэтому работает схожим образом. И хотя повторяют те же ошибки в оптическом распознавании, что и мы, но и делают точно такие же эффективные акценты в тех местах на фото, где делаем мы.
Все это сделало сверточные сети такими эффективными в задачах распознавания.
Рекуррентные сети
Использовать несколько обычных нейросетей, каждую для своего отдельного момента времени неудобно, так как длительность входного сигнала может быть разной, а зачастую сигнал вообще полностью непрерывный. То есть бесконечной длины. Поэтому в рекуррентные нейросети встроены запоминающие элементы, которые помнят что было в предыдущие моменты времени, и подмешивают тот старый сигнал к текущему. Здесь возникает сложный вопрос, что именно запоминать (критерии могут быть разными, например, по необычности сигнала. Или по частоте повторяемости), а также как быстро забывать старые моменты времени, чтобы этот подмешиваемый сигнал не вырос до бесконечности. В целом, этот вопрос пока до конца не решен, хотя существующие реализации рекуррентных нейросетей вроде LSTM и GRU показывают неплохие результаты. И, несомненно, за рекуррентными сетями большое будущее, так как большинство процессов в физическом мире требуют анализа в реальном времени.
Рекуррентные сети
Благодаря обнаруженному десять лет назад способу эффективно обучать многослойные сети, а также успехам сверточных сетей, другие типы нейронных сетей тоже получили мощный импульс для развития. Хочется отметить прежде всего рекуррентные нейросети, в частности LSTM и ее более позднего родственника GRU (хотя LSTM появилась даже раньше применения автоэнкодеров в глубоком обучении). По сути, любая рекуррентная нейросеть аналогична поставленным в ряд нескольким обычным, где каждой из них на вход подается вектор данных, соответствующий ее моменту времени. Так как время реакции человеческих нейронов порядка 10 мс, то обычно это число и используется для дискретизации входного потока. Будь то звук для распознавания речи, или видео, или еще какой процесс, который нам кажется непрерывным.Использовать несколько обычных нейросетей, каждую для своего отдельного момента времени неудобно, так как длительность входного сигнала может быть разной, а зачастую сигнал вообще полностью непрерывный. То есть бесконечной длины. Поэтому в рекуррентные нейросети встроены запоминающие элементы, которые помнят что было в предыдущие моменты времени, и подмешивают тот старый сигнал к текущему. Здесь возникает сложный вопрос, что именно запоминать (критерии могут быть разными, например, по необычности сигнала. Или по частоте повторяемости), а также как быстро забывать старые моменты времени, чтобы этот подмешиваемый сигнал не вырос до бесконечности. В целом, этот вопрос пока до конца не решен, хотя существующие реализации рекуррентных нейросетей вроде LSTM и GRU показывают неплохие результаты. И, несомненно, за рекуррентными сетями большое будущее, так как большинство процессов в физическом мире требуют анализа в реальном времени.
Состязательные GAN сети
Теперь изменим как-нибудь веса в первой генерирующей нейросети, чтобы она сгенерировала такую картинку, которую вторая нейронная сеть не сможет отличить от настоящей фотографии. Градиентным методом обратного распространения ошибки, или любым другим способом обучения. Но в это же время второй нейросети опять говорим, какая фотография настоящая, а какая фейковая (мы-то знаем это наверняка, так как контролируем процесс). И снова научим ее отличать настоящую от фейковой еще лучше, чем раньше. И будем так повторять снова и снова. Первая нейросеть все время будет учиться генерировать картинки, чтобы вторая не смогла их отличить от настоящих (пользуясь оценкой, которую дает вторая нейросеть ее творчеству, в пределах 0..1, и стремясь, чтобы та дала ей 1, т.е. не отличила от настоящей). Но вторая нейросеть тоже будет постоянно учиться отличать все лучше и лучше фейковые картинки от настоящих. С помощью нашей читерской подсказки, какая из них какой является на самом деле.
Такой подход дает впечатляющие результаты по «творчеству» нейросетей. Это так же используется, чтобы генерировать похожие на настоящие наборы данных, если настоящих данных у нас по каким-то причинам мало. На этом видео можно посмотреть, как GAN учится генерировать кошачьи морды, похожие на настоящие: https://www.youtube.com/watch?v=JRBscukr7ew.
 Или человеческие лица
Или человеческие лица
 Да, кривовато, но это были первые успешные опыта такого рода, сейчас уже есть примеры получше. И надо учитывать еще тот факт, что мы, люди, слишком хорошо распознаем несовершенства на человеческих лицах. В этом была эволюционная необходимость, чтобы распознавать болезни. Кто плохо умел распознавать болезненные лица, тот оставлял меньше потомства, поэтому их конкурентов в процентном отношении оказывались больше. Со времененем конкуренты окончательно подавили их количественно, поэтому к нашим дням остались потомки только тех, кто хорошо распознавал лица. Вы прослушали краткий курс как работает естественный отбор, все встают, аплодисменты, расходимся.
Да, кривовато, но это были первые успешные опыта такого рода, сейчас уже есть примеры получше. И надо учитывать еще тот факт, что мы, люди, слишком хорошо распознаем несовершенства на человеческих лицах. В этом была эволюционная необходимость, чтобы распознавать болезни. Кто плохо умел распознавать болезненные лица, тот оставлял меньше потомства, поэтому их конкурентов в процентном отношении оказывались больше. Со времененем конкуренты окончательно подавили их количественно, поэтому к нашим дням остались потомки только тех, кто хорошо распознавал лица. Вы прослушали краткий курс как работает естественный отбор, все встают, аплодисменты, расходимся.
А вот спальни генерируются куда как лучше (вероятно потому, что мы хуже распознаем несовершенные детали на них):
 Но самая потрясающая часть нейросетей типа GAN, это способность манипулировать тем, что будет нарисовано. Так как генерирующую нейросеть мы инициировали случайным набором чисел на входе, то она построила картинку, соответствующую этому набору. Сделала классификацию наоборот, так сказать. Поэтому мы можем взять два входных вектора от разных сгенерированных картинок и манипулировать ими как обычными числами: складывать, вычитать, умножать.
Но самая потрясающая часть нейросетей типа GAN, это способность манипулировать тем, что будет нарисовано. Так как генерирующую нейросеть мы инициировали случайным набором чисел на входе, то она построила картинку, соответствующую этому набору. Сделала классификацию наоборот, так сказать. Поэтому мы можем взять два входных вектора от разных сгенерированных картинок и манипулировать ими как обычными числами: складывать, вычитать, умножать.
К примеру, один случайный набор чисел (входной вектор) сгенерировал мужчину в очках. А другой случайный набор дает мужчину без очков. И третий дает женщину. Мы можем из первого вектора вычесть второй и в разнице получим те числа, которые определяют очки. А потом сложить с третьим набором, который определяет, что будет нарисована женщина. И подадим результат как вектор чисел на вход генерирующей нейросети. И она, тарам-папам!, сгенерирует женщину в очках!и с бородой Это удивительная магия, если не знать что за ней стоит.
 Аналогично можно работать с любыми признаками, которые мы видим на сгенерированных картинках. Но сначала надо нагенерировать множество фото на случайных векторах, конечно. К примеру, таким способом можно состарить или омолодить человека на фото, если у нас где-нибудь найдется сгенерированная фотография пожилого/молодого человека. Качество следующей иллюстрации показывает, насколько быстро идет прогресс в этой области.
Аналогично можно работать с любыми признаками, которые мы видим на сгенерированных картинках. Но сначала надо нагенерировать множество фото на случайных векторах, конечно. К примеру, таким способом можно состарить или омолодить человека на фото, если у нас где-нибудь найдется сгенерированная фотография пожилого/молодого человека. Качество следующей иллюстрации показывает, насколько быстро идет прогресс в этой области.
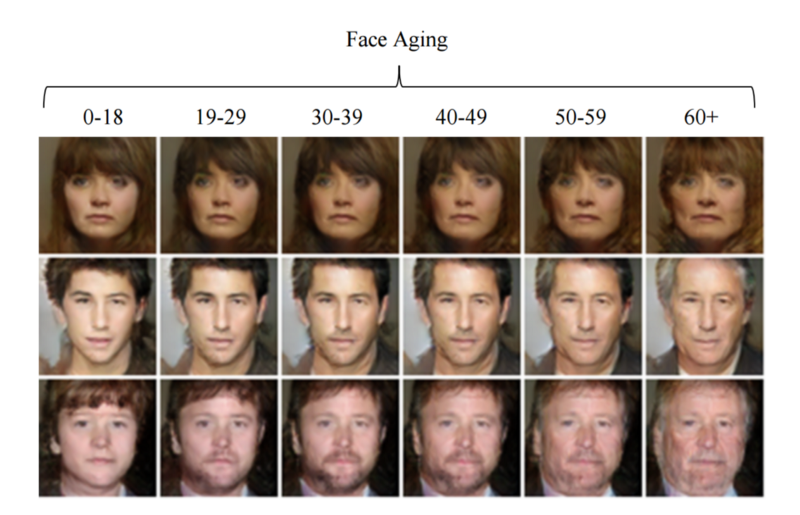 Иллюстрация из работы https://arxiv.org/abs/1702.01983v1
Иллюстрация из работы https://arxiv.org/abs/1702.01983v1
Еще один пример применения GAN: Нейросеть предсказывает 1 секунду будущего по фотографии.
В этой работе на вход нейросети подается кадр из видео с разрешением 64х64 пикселя, а нейросеть пытается предсказать, что произойдет в следующих 32 кадрах (через 1 сек). Согласитесь, это уже похоже на сильный ИИ, ведь многие абстрактные вещи на самом деле являются предсказанием. Например, начинаем убирать со стола одну из трех палочек. Допустим, нейросеть делает предсказание: через 1 секунду останется две палочки. А ведь это процесс вычитания, примерно так дети и учатся арифметике.
Технически предсказание заключается в том, что нейросеть выдает ряд измененных картинок, то есть генерирует эти картинки. Поэтому обучение сделано через GAN подход: одна сеть пытается генерировать реалистичные картинки, а другая пытается их отличить от настоящих. Только из-за недостатка вычислительной мощности разрешение 64х64 пикселя и анализ единственного кадра это слишком мало. Представьте что будет, когда нейросети смогут анализировать картинку хотя бы 640х480, и не один кадр, а хотя бы последние несколько секунд? Если при этом будут выдавать реалистичные предсказания, то это будет большой шаг в сторону ИИ.
К сожалению, GAN нейросети очень сложно обучать. Так как обе нейросети, и генерирующая, и оценивающая, должны развиваться примерно на равном уровне. Если генерирующая научится обманывать оценивающую раньше, что та никогда не сможет отличить ее творчество от настоящих фотографий, то процесс обучения потеряет смысл, застопорится. Аналогично, генерирующая никогда не сможет научиться делать реалистичные картинки, если оценивающая всегда будет ставить ей 0, т.е. что распознала фейковость. А значит не будет никакого градиента, по которому можно обучаться. Псеводослучайные алгоритмы обучения, вроде метода Монте-Карло, и даже их разновидности с накоплением положительных изменений, такие как генетический алгоритм, работают слишком медленно для практического применения.
Подробнее про генеративные нейронные сети (к которым относится GAN) можно почитать тут: Generative Models.
Состязательные GAN сети
Другим крайне интересным типом нейросетей являются конкурирующие нейронные сети GAN. Принцип очень простой — пусть одна нейросеть инициируется на входе случайными числами и случайными весами и, соответственно, выдаст на выходе случайный результат. Например, массив цветов пикселей для картинки. А другой нейросети мы на вход подаем две картинки — одну сгенерированную первой нейросетью (сейчас она случайная), а вторую настоящую. Какую-нибудь фотографию природы, например. Так как мы знаем какая картинка настоящая, а какая сгенерирована первой нейросетью, то мы можем указать это второй. И научить ее, чтобы для фэйковой картинки она поставила число 0, а для настоящей 1.Теперь изменим как-нибудь веса в первой генерирующей нейросети, чтобы она сгенерировала такую картинку, которую вторая нейронная сеть не сможет отличить от настоящей фотографии. Градиентным методом обратного распространения ошибки, или любым другим способом обучения. Но в это же время второй нейросети опять говорим, какая фотография настоящая, а какая фейковая (мы-то знаем это наверняка, так как контролируем процесс). И снова научим ее отличать настоящую от фейковой еще лучше, чем раньше. И будем так повторять снова и снова. Первая нейросеть все время будет учиться генерировать картинки, чтобы вторая не смогла их отличить от настоящих (пользуясь оценкой, которую дает вторая нейросеть ее творчеству, в пределах 0..1, и стремясь, чтобы та дала ей 1, т.е. не отличила от настоящей). Но вторая нейросеть тоже будет постоянно учиться отличать все лучше и лучше фейковые картинки от настоящих. С помощью нашей читерской подсказки, какая из них какой является на самом деле.
Такой подход дает впечатляющие результаты по «творчеству» нейросетей. Это так же используется, чтобы генерировать похожие на настоящие наборы данных, если настоящих данных у нас по каким-то причинам мало. На этом видео можно посмотреть, как GAN учится генерировать кошачьи морды, похожие на настоящие: https://www.youtube.com/watch?v=JRBscukr7ew.
Или человеческие лица Да, кривовато, но это были первые успешные опыта такого рода, сейчас уже есть примеры получше. И надо учитывать еще тот факт, что мы, люди, слишком хорошо распознаем несовершенства на человеческих лицах. В этом была эволюционная необходимость, чтобы распознавать болезни. Кто плохо умел распознавать болезненные лица, тот оставлял меньше потомства, поэтому их конкурентов в процентном отношении оказывались больше. Со времененем конкуренты окончательно подавили их количественно, поэтому к нашим дням остались потомки только тех, кто хорошо распознавал лица. Вы прослушали краткий курс как работает естественный отбор, все встают, аплодисменты, расходимся.А вот спальни генерируются куда как лучше (вероятно потому, что мы хуже распознаем несовершенные детали на них):
Но самая потрясающая часть нейросетей типа GAN, это способность манипулировать тем, что будет нарисовано. Так как генерирующую нейросеть мы инициировали случайным набором чисел на входе, то она построила картинку, соответствующую этому набору. Сделала классификацию наоборот, так сказать. Поэтому мы можем взять два входных вектора от разных сгенерированных картинок и манипулировать ими как обычными числами: складывать, вычитать, умножать.К примеру, один случайный набор чисел (входной вектор) сгенерировал мужчину в очках. А другой случайный набор дает мужчину без очков. И третий дает женщину. Мы можем из первого вектора вычесть второй и в разнице получим те числа, которые определяют очки. А потом сложить с третьим набором, который определяет, что будет нарисована женщина. И подадим результат как вектор чисел на вход генерирующей нейросети. И она, тарам-папам!, сгенерирует женщину в очках!
Аналогично можно работать с любыми признаками, которые мы видим на сгенерированных картинках. Но сначала надо нагенерировать множество фото на случайных векторах, конечно. К примеру, таким способом можно состарить или омолодить человека на фото, если у нас где-нибудь найдется сгенерированная фотография пожилого/молодого человека. Качество следующей иллюстрации показывает, насколько быстро идет прогресс в этой области. Иллюстрация из работы https://arxiv.org/abs/1702.01983v1Еще один пример применения GAN: Нейросеть предсказывает 1 секунду будущего по фотографии.
В этой работе на вход нейросети подается кадр из видео с разрешением 64х64 пикселя, а нейросеть пытается предсказать, что произойдет в следующих 32 кадрах (через 1 сек). Согласитесь, это уже похоже на сильный ИИ, ведь многие абстрактные вещи на самом деле являются предсказанием. Например, начинаем убирать со стола одну из трех палочек. Допустим, нейросеть делает предсказание: через 1 секунду останется две палочки. А ведь это процесс вычитания, примерно так дети и учатся арифметике.
Технически предсказание заключается в том, что нейросеть выдает ряд измененных картинок, то есть генерирует эти картинки. Поэтому обучение сделано через GAN подход: одна сеть пытается генерировать реалистичные картинки, а другая пытается их отличить от настоящих. Только из-за недостатка вычислительной мощности разрешение 64х64 пикселя и анализ единственного кадра это слишком мало. Представьте что будет, когда нейросети смогут анализировать картинку хотя бы 640х480, и не один кадр, а хотя бы последние несколько секунд? Если при этом будут выдавать реалистичные предсказания, то это будет большой шаг в сторону ИИ.
К сожалению, GAN нейросети очень сложно обучать. Так как обе нейросети, и генерирующая, и оценивающая, должны развиваться примерно на равном уровне. Если генерирующая научится обманывать оценивающую раньше, что та никогда не сможет отличить ее творчество от настоящих фотографий, то процесс обучения потеряет смысл, застопорится. Аналогично, генерирующая никогда не сможет научиться делать реалистичные картинки, если оценивающая всегда будет ставить ей 0, т.е. что распознала фейковость. А значит не будет никакого градиента, по которому можно обучаться. Псеводослучайные алгоритмы обучения, вроде метода Монте-Карло, и даже их разновидности с накоплением положительных изменений, такие как генетический алгоритм, работают слишком медленно для практического применения.
Подробнее про генеративные нейронные сети (к которым относится GAN) можно почитать тут: Generative Models.
Обучение с подкреплением
Обучение с подкреплением чем-то похоже на то, как учатся живые люди. Поэтому это тоже очень перспективное направление, хотя и находящееся пока на самом начальном уровне. К сожалению, математический аппарат построения функции полезности действий (штука, которая управляет текущими действиями нейросети, чтобы получить награду в будущем) довольно сложно объяснить на пальцах, поэтому заинтересовавшимся лучше поискать материал самостоятельно.
Обучение с подкреплением
Еще одна быстро развивающаяся область, это обучение с подкреплением. Суть ее сводится к тому, что нейронная сеть обучается по параметру, который оценивает ее работу не прямо сейчас, а через некоторое время. Скажем, нужно выиграть в компьютерную игру, набрав максимум очков. Но очки даются не в тот момент, когда нейросеть нажимает на клавишу движения или поворота, а через некоторое время. Это может быть, например, какой-то бонус на уровне, до которого еще нужно добраться.Обучение с подкреплением чем-то похоже на то, как учатся живые люди. Поэтому это тоже очень перспективное направление, хотя и находящееся пока на самом начальном уровне. К сожалению, математический аппарат построения функции полезности действий (штука, которая управляет текущими действиями нейросети, чтобы получить награду в будущем) довольно сложно объяснить на пальцах, поэтому заинтересовавшимся лучше поискать материал самостоятельно.
Во всем этом главное понять
По сути, известная теорема о том, что однослойный перцептрон может аппроксимировать любую функцию, означает всего лишь, что мы можем использовать нейронную сеть как справочную таблицу. Действительно, если каждый входной нейрон соединен с каждым нейроном среднего скрытого слоя, то мы можем для нужных весов поставить 1, а для всех остальных 0. И по этой связи со значением 1, сигнал напрямую пойдет к выходу, как ссылка в таблице. Однако размер этой таблицы (число нейронов в скрытом слое) должно быть, если не ошибаюсь, 2^n от числа понятий-записей в таблице.
Но заметьте, эта теорема означает только то, что мы можем обучить однослойную нейронную сеть на обучающей выборке и использовать ее как справочную таблицу. Но это вовсе не значит, что на новых данных она будет так же хорошо работать! Если новых данных нет в нашей супер-таблице, то все пропало, шеф. Поэтому многослойные сети работают несколько хитрее в плане интерполяции и смешивания сигнала, чем однослойные.
Поэтому те же сверточные нейросети, помимо того что имеют сходство со зрительной системой человека, на самом деле тоже служат в том числе для уменьшения количества нейронов в сети по сравнению с ближайшими аналогами. Впрочем, в обоих случаях может лежать одинаковый принцип уменьшения числа необходимых для работы нейронов. Известно, что наши глаза по количеству воспринимающих свет колбочек и палочек соответствуют картинке примерно в 120 мегапикселей (для каждого глаза), но нервный канал, соединяющий глаз с мозгом, физически не способен провести такое количество информации через себя. Количество нервных волокон в зрительном нерве составляет примерно 1.2 млн, что соответствует картинке чуть более одного мегапикселя для каждого глаза. То есть уже в нервных клетках, непосредственно связанных с глазами, еще до обработки сигнала мозгом, происходит сжатие видеоряда в 100 раз.
С этим, кстати, связаны различные глюки нашего зрительного восприятия. Зрительные иллюзии, вот это все. Более того, аналогичные иллюзии возникают и в других областях нашего мышления, в психологии, в инстинктах, в речи (Вики: Иллюзия). Везде, где происходит аналогичное по принципу сжатие сигнала с помощью нейронов. То есть везде.

Благодаря тому, что глубокие многослойные нейросети позволяют меньшим числом нейронов достичь большей сложности, и получены все вдохновляющие результаты последних лет. Глубокие нейронные сети уже сейчас в отдельных областях превзошли человека: в распознавании дорожных знаков, определении классов при большом числе категорий (ResNet, ошибка определения одной из тысячи категории для 10 млн картинок 3.57%, а у человека среднее 5%, но не качественно, увы, и к этому мы позже вернемся. Внезапный диван леопардовой расцветки), в распознавании речи, чтении по губам. И очевидно, что в ближайшие годы мы услышим еще о многих подобных примерах.
Вступление закончено, пора вносить торт
Итак, мы научились правильно обучать многослойные нейронные сети. А также знаем, что наш собственный мозг представляет собой примерно десятислойную нейронную сеть (для первичного распознавания объектов высшего уровня абстракции, а далее непрерывно работает как рекуррентная сеть). И, технически, мы теперь можем сделать некий аналог человеческого мозга. Так почему сильный ИИ до сих пор не создан, что пошло не так?Для начала необходимо заметить, что научного определения для сознания, разума и интеллекта в интересующем нас контексте не существует. Это философские понятия. Слово есть, а
Можно посмотреть на это иначе — если бы определение искусственного интеллекта существовало, то он был бы уже создан. Определение чего либо (если оно не философское и не иное ненаучное) можно рассматривать как прямое ТЗ для программиста.
Единственная форма разумной жизни, которая нам известна — это мы сами. Поэтому то интуитивное понимание интеллекта (разума, сознания), которое есть у нас всех, и которое так глупо и безуспешно философы пытаются облечь в слова, на самом деле, простая степень похожести на нас самих. Что-то вроде расширенного теста Тьюринга. Если мы будем слышать рассказ о том, как некто что-то делает в некоторых ситуациях, как он поступает и какие решения принимает, и не сможем отличить его от человека (при достаточном количестве информации, позволяющей делать обоснованные выводы), то это и будет критерием разумен он или нет. Даже если в реальности это окажется двуногий робот-гуманоид или написанная чат-программа. Других способов определить интеллект пока не существует. И даже этот метод несовершенен, так как нет критерия когда объем информации станет достаточным для выводов.
Кратко это можно описать так: от искусственного интеллекта мы ожидаем то же, что от разумного нормального человека. В разговоре, в действиях, в его решениях. Только с поправкой на отсутствие полового влечения, например. Или имеющего расширенную память, включающую весь интернет и мгновенный доступ к ней. Или имеющий быстродействие (скорость мышления) в тысячи раз быстрее биологического образца. Но это остается «все тот же человек».
Поэтому задача создания искусственного интеллекта сводится к тому, чтобы он был максимально похож на нас. Другие возможные формы искусственного интеллекта, например, действующие по каким-то другим, отличным от наших, правилам, являются очень интересной темой для рассуждений. Но, к сожалению, на данный момент такие рассуждения возможны только как философские. То есть не имеющие адекватного научного определения под собой.
Как же нам добиться создания сильного ИИ хотя бы нашего уровня? Да в принципе, ничего особо делать не надо. Так как в некоторых когнитивных областях, которые компьютеру ранее казались в принципе недоступными, вроде качественного распознавания речи и образов, нейронные сети сравнялись и обошли человека. Поэтому есть обоснованная надежда, что из таких простых строительных блоков со временем возникнет что-то более сложное. Грубо говоря, выход с ResNet надо отправить на другую не менее сложную нейросеть (которая еще не создана), результат ее работы отправить на модуль генерации неотличимого от человеческого голоса, и так далее. Вполне возможно, что из этого и правда вырастет сильный ИИ. Это кажется тем более реальным, как только представишь, что нейронная сеть научится хорошо восстанавливать 3d сцену по обычному видео с youtube. И по роликам научится понимать куда и как люди движутся, что делают и т.д… Почему именно по видео это может дать результат, а по книгам (описывающим в текстовом виде все те же действия) не дало? Об этом ниже.
И такие попытки уже делаются! Нейронные сети уже довольно неплохо определяют нормали по фото и поле глубины, а от этого один шаг до полноценной реконструкции 3d сцены.
 Иллюстрация с лекции Нейронные сети: практическое применение
Иллюстрация с лекции Нейронные сети: практическое применениеТут еще нужно заметить, что вычислительная мощность для применений в нейронных сетях все еще смехотворно мала. Например, у обычной мухи дрозофилы порядка 150 тысяч нейронов. А когда мы перевалили за первую тысячу нейронов в искусственных нейросетях? Совсем недавно. Правда, наши сети намного эффективнее для узких задач. Даже самые мощные суперкомпьютеры по производительности вычислений на ватт энергии, пока примерно равны мозгу мыши. Есть надежда, что в ближайшие 10-20 лет будет создан компьютер, обладающий такими же параллельными вычислительными возможностями, как человеческий мозг, и потребляющий всего 10 кВт. И это лучшее, на что можно надеяться. По сравнению с 20 Вт у человеческого мозга. Шутка. Надеяться всегда можно на лучшее. Представляется что-то вроде SD карты на сотни гигабайт, в которой ячейки смогут параллельно производить простые математические операции (сумматора будет вполне достаточно). С учетом частоты в гигагерцы (и, в перспективе, в терагерцы) по сравнению с 100 Гц биологического нейрона, это моментально превысит вычислительные возможности нашего мозга.
Недостаток текущей вычислительной мощности для нейросетевого применения тем более удручает, что существует масса других более формальных методов машинного обучения, выполняющих ту же задачу, что и нейронные сети (например, для задач классификации метод опорных векторов или случайный лес деревьев решений), но менее требовательных к ресурсам. К сожалению, в тех задачах, где сейчас сильны нейросети, они им сильно уступают. Правда, здесь можно сослаться на интересную статью, в которой показывается, что большую роль играют данные для обучения и знания о том, какие результаты можно получить с такой-то архитектурой, а также вера исследователя в успех. Грубо говоря, еще 20 лет назад можно было достичь тех же результатов, что и сейчас. Набери тогда исследователи достаточную обучающую выборку и запусти расчет на большее время (пропорционально росту производительности компьютеров с тех пор). Но для этого они должны были знать, что могут получить, и верить в свой успех. Так или иначе, а история не знает сослагательных наклонений.
Но вполне возможно, что успехи нейронных сетей вызваны просто общим интересом к ним, а значит и количеством задействованных ресурсов. Но не будем обманывать себя и питать ложные надежды =). У нейронные сетей, как метода машинного обучения, действительно есть свои интересные особенности, доказательством чему служит вал научных работ последних лет. В основном, посвященных многослойности и вытекающих из этого следствий. Так что, похоже, нейросети с нами всерьез и надолго.
Другая проблема в данных для обучения. На самом деле, их нет. ImageNet с 10 млн маркированных картинок это большой успех, но возьмите любую задачу, к которой вы могли бы применить самые новейшие нейронные сети, и окажется, что данных для обучения нет. Это прекрасная возможность и стимул разрабатывать методы обучения нейросетей, не требующих больших объемов обучающей выборки. В идеале, они должны работать даже на единичных примерах. Как наш мозг.
Ну когда же конец
И все же, почему сильный ИИ до сих пор не создан? И даже нет намеков, а вернее, четко обозначенных путей, по которым к нему можно прийти в ближайшее время?И здесь наступает грустный момент нашей повести. В точности с концепцией героя с тысячью лицами, после начальных вдохновляющих успехов, главный герой попадает в сюжетную яму. Из которой он потом будет долго и мучительно выбираться.
Дело в том, что многие качества разумного мышления, которые мы считаем само собой разумеющимися, на самом деле не являются таковыми. Не хочется показаться голословным, а тем более исказить детали и выступить в роли испорченного телефона, но то, о чем дальше пойдет речь, является компиляцией из разных источников (научные статьи, новости, телевизионные документальные фильмы и т.д.), поэтому быстрое гугление первоисточников не принесло особого результата. Если кто-то поделится ссылками на что-нибудь из перечисленного ниже или похожего, буду благодарен.
Известны примеры, когда в сохранившихся первобытных племенах имеются радикальные отличия в мышлении. Где-то катастрофически малое количество слов в языке. Где-то имеются один-два названия для синего цвета, но зато десятки для оттенков зеленого. Где-то было видео (за указание на первоисточник спасибо tin04ka в комментарии: документальный фильм BBC Horizon:Do You See What I See, есть на youtube), кадр из которого показан ниже. На нем туземец не может отличить синий квадратик от зеленых. При этом он здоров и не дальтоник, просто такова особенность их языка (отсутствие слов для синих цветов) и связанного с этим обучения в детстве. Можете себе представить, что на этой картинке вы не сможете отличить синий квадрат от зеленых?
 Представитель народа Химби из Намибии, если интернет не врет
Представитель народа Химби из Намибии, если интернет не вретТакже недавно была новость, что в каком-то племени туземцы не могут считать до чисел больше четырех. У них есть понятия, грубо говоря, «один», «два» и «много». Других нет. И если положить перед таким туземцем кучки из 4 и 5 палочек, он не видит между ними разницы. Так же, как мы не видим разницы между кучками из 1000 и 1001 палочек. И там, и там примерно одинаковые кучки из «много».
Другой известный пример, уже наших исследователей середины прошлого века (за ссылку на источник спасибо GreatNonentity). Которые изучали особенности мышления изолированных народов, заставших начало коллективизации и поэтому подвергшихся в короткий срок значительным изменениям в образовании. Среди испытуемых были как неграмотные люди, никогда не посещавшие школу, так и имевшие образование разных степеней (от кратких курсов, до нескольких классов). Выяснилось, что у получавших традиционное школьное образование и не получавших, имеются существенные отличия в способах логического мышления. Например, исследователь задавал такой детский вопрос-загадку: «Белые медведи живут там, где снег. На севере снег. Какого цвета там медведи?» Не имевшие школьного образования не могли провести такие логические параллели. Все их ответы сводились к вариантам вроде: «Если кто-то поедет на север и посмотрит, то он сможет сказать какого цвета там медведи, а иначе никаких способов узнать это нет». Добиться другого от них не удалось. А имевшие классическое образование без труда справлялись с такими вопросами, так как рассуждали уже другими категориями, полученными в процессе обучения. Эти исследования сильно пошатнули царившие в то время представления о разуме, так как подобные построения, которые с легкостью разгадывают наши дети, до этого считались само собой разумеющимся свойством разума.
А сколько еще может вскрыться подобных нюансов об интеллекте, которые мы не видим, так как не знаем другой разумной жизни, кроме самих себя?
Похоже, что значительная часть того, что мы считаем разумом и интеллектом, на самом деле является результатом обучения в раннем детстве. В пользу этой теории говорят случаи обнаружения детей-маугли, выросших в лесу без общения с людьми. Большинство из которых, не смотря на развитый и физиологически идентичный нашему мозг (т.к. это современные люди, просто оказавшиеся в младенчестве в лесу), так и не сумели адаптироваться к жизни в обществе. Особенно много таких случаев почему-то в Индии, вероятно благодаря большой численности населения, нищете, и теплому климату. Некоторых не удалось научить не то что говорить, но и просто приучить пользоваться одеждой или столовой ложкой.
А значит надо обратить более пристальное внимание на то, как обучаются младенцы. И мы увидим, что они познают мир через физическое взаимодействие с ним. Потрогать, покрутить предметы в руках, и тому подобное. Даже обычный осмотр помещения, это в некотором роде анализ трехмерной обстановки, благодаря встроенному и сразу работающему бинокулярному зрению.
Более того, практически все наши знания, в том числе такая абстрактная наука как математика (являющаяся царицей наук, как известно), на самом деле сильно привязана к трехмерному представлению. Ведь как ребенок научился считать? Перед ним на столе лежали две палочки. А потом мама (или учитель) добавил к ним еще одну. И ребенок научился складывать числа.
Если хорошо подумать, то почти все наши внутренние понятия, так или иначе привязаны к окружающему трехмерному (объемному) миру. Какие-то самые сложные концепции из высшей математики конечно визуально представить нельзя или очень сложно, но зато вы видите значки, которые их обозначают. Вы знаете, что эти значки нарисованы на бумаге учебника, который можно взять в руки. Со всеми следствиями, которые их этого вытекают в физическом мире. Например, что этот учебник можно положить на полку. Или бросить об стену. Знакомое желание для многих студентов на уроках математического анализа, не так ли? Впрочем, один профессор на вопросы студентов, где это им пригодится в жизни, всегда отвечал: «Смотря что вы считаете жизнью». Ну а более простые вещи из математики легко представляются в уме, теорема Пифагора и тому подобное. Некоторые даже могут сделать это для четырехмерного куба.
И, что важнее всего, такой подход через обучение в привязке к трехмерной форме объектов устранит главную проблему сегодняшних нейросетей — непонимание контекста. Нейронная сеть, обученная воспринимать 3d мир и распознавать картинки не просто разбив их на классы, а в привязке к трехмерной форме распознаваемых объектов, никогда не спутает леопарда с диваном с леопардовой расцветкой. Потому что мы сами их отличаем именно по 3d форме, которую реконструируем из изображения. Диван имеет форму дивана, а леопард форму леопарда, какими бы цветами они ни были раскрашены. Другое дело, что сверточная нейросеть тоже могла бы отличать диван от леопарда по форме (см. выше принцип действия сверточных нейросетей). И она технически может это сделать, дайте ей для обучения 10 млн леопардов и 10 млн диванов. Ну а так ей оказалось проще ориентироваться только на пятна. Потому что распознаваемые классы не привязаны к 3d форме объектов. И это кажется ключевым моментом.
Да-да, я все понял, развяжите меня пожалуйста
Таким образом, похоже что наиболее реалистичный путь создать сильный ИИ — это дать ему возможность пройти путь младенца. Возможность манипулировать и изучать трехмерные объемные тела. Конечно, никто не будет в теченииНо если серьезно, есть отличная возможность провести такое же обучение, но быстрее, и не в ущерб нервным клеткам
Но тут возникает проблема. Человек — это существо с тонко преднастроенной нейронной сетью. Вот пример. Создали мы младенца в виртуальной реальности. И добавили ему таймер, чтобы по истечении некоторого времени он становился голодным. А что делает младенец, когда он голоден? Правильно, он кричит. Хорошо, нет проблем. Пусть над головой младенца в симуляторе появляются буквы «Аааа», обозначающие крик, как в компьютерной игре. Но сколько времени их держать над головой, как часто их показывать, и когда вообще прекратить плакать? У настоящего ребенка есть тонкая преднастройка. Он покричит и устанет. Да и сам крик не постоянный, а с перерывами. И таких нюансов очень много. Именно поэтому жестко прописанные боты в играх для нас выглядят явно неразумными, хотя по формальным признакам их зачастую можно отнести к разумным существам. Мол, собирают информацию, используют ее для достижения своих целей и так далее. Но об определении интеллекта, а точнее, об отсутствии такого определения, мы уже говорили выше. А по факту, боты в игре нам кажутся неразумными, потому что они не очень похожи на нас. А конкретно — на нашу преднастройку в нейронной сети мозга. Компьютерный персонаж непрерывно бьется об стену при сбое алгоритма навигации? Неразумный. А вот человек ударился бы пару раз (например, натолкнувшись в темноте на стену, что как бы аналог сбоя системы навигации у бота), и прекратил бы. Человек — разумный. Улавливаете разницу, да? Похоже, что разумность (т.е. похожесть в поведении на нас) во многом определяется преднастройкой нейронной сети. Хотя в обоих случаях в основе их действий — стуканий об стену, лежат примерно одинаковые ошибки расчеты поиска пути.
Конечно, это сильно упрощенный пример, потому что у человека в расчете пути принимает участие на много порядков больше понятий, чем у компьютерного бота. Человек понимает, что перед ним трехмерная стена и биться об нее головой больше двух раз (ну хорошо, уговорили, трех) нет смысла. Что опять же возвращает нас к необходимости обучать нейронную сеть ИИ в трехмерном окружении, имитирующем реальный физический мир.
Как же нам дать ИИ боту преднастройку, похожую на нашу? Можно попробовать алгоритмически описать основные инстинкты и физиологию человека. Но скорее всего мы опять столкнемся с комбинаторным взрывом, как это было при попытке вручную написать все правила для ИИ. Можно попробовать взять знания об устройстве организма на молекулярном уровне из медицины. Хотя сама медицина нуждается в сильном ИИ, который систематизировал в ней все накопленные знания.
Остается еще вариант самообучения по видеороликам. И вот тут очень пригодятся все эти достижения нейронных сетей последних лет по распознаванию изображений и звука. Преобразовать реальный мир в 3d сцену можно было уже давно, от стереокамер и аналогов камер глубины вроде kinect, и заканчивая анализом монопотока вроде LSD-SLAM (еще на первых марсоходах, кстати, использовались SLAM алгоритмы). Но для обработки имеющегося в интернете видео контента нужны нейронные сети. И тем более, для анализа что на видео происходит. А судя по последним нейросетевым достижениям, появляется робкая надежда, что это будет им по плечу. Отсюда и оптимизм в плане шансов на создание сильного ИИ в обозримом будущем.
Но неизвестно, к чему такое обучение по видероликам приведет. Делать похожее поведение может и получится. Но такой ИИ перенимет все наши слабые стороны. Потому что здравомыслящий человек имеет жесткую предустановку: «Что бы в жизни ни случилось, главное не попасть на youtube!». А иметь ИИ, обученный вести себя по роликами с ютюба, мы точно не захотим.

 Пока это робкие и смешные попытки, но несложно представить, что через несколько лет это перерастет в полноценный симулятор физического окружения.
Пока это робкие и смешные попытки, но несложно представить, что через несколько лет это перерастет в полноценный симулятор физического окружения.А потом виртуальному младенцу добавят игрушек для игры. Потом положат перед ним две палочки, а потом добавят еще одну. И он научится считать.
Зачем козе баян
А стоит ли вообще все это таких усилий? Мы уже убедились, что вряд ли сможем создать ИИ с отличным от нашего способа мышления, со всеми его недостатками вроде иллюзий разного рода. Собственно, как уже говорилось выше, сама идея «чистого» абстрактного ИИ, хоть и очень заманчива, но весьма спекулятивна. Подтверждением тому служит хотя бы то, что попытки сделать сильный ИИ на базе книг провалились. На базе текстовых данных всего интернета — тоже (см. IBM Watson, хоторый хоть и содержит на своих дисках «весь интернет», на деле не умнее анкеты с поисковой строкой). Остался неисследованным вопрос создания ИИ на базе физического окружения, будь то в виртуальном симуляторе или в реальности. Но этот способ, скорее всего, в лучшем случае приведет к ИИ на уровне человеческого.А нужен ли нам ИИ уровня человека? Не, не нужен. Но как уже отмечалось, имея искусственную форму разума, можно дать ей большие возможности, чем имеем мы сами в силу ограничений физиологии. Для примера, сейчас в интернете выложено более 100 млн научных работ. Из них около 30 млн по медицине. Ни одному живому человеку не под силу прочитать такой объем. А тем более, охватить все междисциплинарные знания. Даже узкие специалисты, уверен, не все работы из своей области отслеживают. А ведь в таком объеме информации наверяка скрыто множество взаимосвязей, из которых можно было бы сделать полезные выводы. Традиционные методы машинного обучения фактически потерпели фиско на этом поприще. Теперь вся надежда на сильный ИИ, который сможет освоить все эти накопленные знания человечества. Если говорим об ИИ на базе нейросети, который будет примерно равен по интеллекту человеку, то для этого он потенциально может пользоваться расширенной по сравнению с людьми памятью и более высокой тактовой частотой.
Впрочем, локомотив прогресса так и так не остановить, это лишь вопрос времени.
 Об ошибках, как орфографических, так и фактических, просьба сообщать в личку или в комментариях.
Об ошибках, как орфографических, так и фактических, просьба сообщать в личку или в комментариях.Телеграм: t.me/ainewsline
Источник: geektimes.ru