Открытый курс машинного обучения. Тема 6. Построение и отбор признаков
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-04-03 18:10
машинное обучение python, алгоритмы кластеризации, архитектура нейронных сетей, анализ больших данных

Сообщество Open Data Science приветствует участников курса!
В рамках курса мы уже познакомились с несколькими ключевыми алгоритмами машинного обучения. Однако перед тем как переходить к более навороченным алгоритмам и подходам, хочется сделать шаг в сторону и поговорить о подготовке данных для обучения модели. Известный принцип garbage in – garbage out на 100% применим к любой задаче машинного обучения; любой опытный аналитик может вспомнить примеры из практики, когда простая модель, обученная на качественно подготовленных данных, показала себя лучше хитроумного ансамбля, построенного на недостаточно чистых данных.

- Первичный анализ данных с Pandas
- Визуальный анализ данных c Python
- Классификация, деревья решений и метод ближайших соседей
- Линейные модели классификации и регрессии
- Композиции: бэггинг, случайный лес
- Построение и отбор признаков. Приложения в задачах обработки текста, изображений и геоданных
- Обучение без учителя: PCA, кластеризация, поиск аномалий
В рамках сегодняшней статьи хочется обзорно описать три похожих, но разных задачи:
- feature extraction and feature engineering – превращение данных, специфических для предметной области, в понятные для модели векторы;
- feature transformation – трансформация данных для повышения точности алгоритма;
- feature selection – отсечение ненужных признаков.
Отдельно отмечу, что в этой статье почти не будет формул, зато будет относительно много кода.
В некоторых примерах будет использоваться датасет от компании Renthop, используемого в соревновании Two Sigma Connect: Rental Listing Inquires на Kaggle. В этой задаче нужно предсказать популярность объявления об аренде недвижимости, т.е. решить задачу классификации на три класса ['low', 'medium', 'high']. Для оценки решения используется метрика log loss (чем меньше — тем лучше). Тем, у кого еще нет аккаунта на Kaggle, придется зарегистрироваться; также для скачивания данных нужно принять правила соревнования.
# перед началом работы не забудьте скачать файл train.json.zip с Kaggle и разархивировать его import json import pandas as pd # сразу загрузим датасет от Renthop with open('train.json', 'r') as raw_data: data = json.load(raw_data) df = pd.DataFrame(data)
- Извлечение признаков (Feature Extraction)
- Преобразования признаков (Feature transformations)
- Выбор признаков (Feature selection)
- Домашнее задание
Извлечение признаков (Feature Extraction)
В жизни редко данные приходят в виде готовых матриц, потому любая задача начинается с извлечения признаков. Иногда, конечно, достаточно прочитать csv файл и сконвертировать его в numpy.array, но это счастливые исключения. Давайте посмотрим на некоторые популярные типы данных, из которых нужно извлекать признаки.
Тексты
Текст – самый очевидный пример данных в свободном формате; методов работы с текстом достаточно, чтобы они не уместились в одну статью. Тем не менее, обзорно пройдем по самым популярным.
Перед тем как работать с текстом, его необходимо токенизировать. Токенизация предполагает разбиение текста на токены – в самом простом случае это просто слова. Но, делая это слишком простой регуляркой ("в лоб"), мы можем потерять часть смысла: "Нижний Новгород" это не два токена, а один. Зато призыв "воруй-убивай!" можно напрасно разделить на два токена. Существуют готовые токенайзеры, которые учитывают особенности языка, но и они могут ошибаться, особенно если вы работаете со специфическими текстами (профессиональная лексика, жаргонизмы, опечатки).
После токенизации в большинстве случаев нужно задуматься о приведении к нормальной форме. Речь идет о стемминге и/или лемматизации – это схожие процессы, используемые для обработки словоформ. О разнице между ними можно прочитать здесь.
Итак, мы превратили документ в последовательность слов, можно начинать превращать их в вектора. Самый простой подход называется Bag of Words: создаем вектор длиной в словарь, для каждого слова считаем количество вхождений в текст и подставляем это число на соответствующую позицию в векторе. В коде это выглядит даже проще, чем на словах:
from functools import reduce import numpy as np texts = [['i', 'have', 'a', 'cat'], ['he', 'have', 'a', 'dog'], ['he', 'and', 'i', 'have', 'a', 'cat', 'and', 'a', 'dog']] dictionary = list(enumerate(set(list(reduce(lambda x, y: x + y, texts))))) def vectorize(text): vector = np.zeros(len(dictionary)) for i, word in dictionary: num = 0 for w in text: if w == word: num += 1 if num: vector[i] = num return vector for t in texts: print(vectorize(t))Также идея хорошо иллюстрируется картинкой:

Это предельно наивная реализация. В реальной жизни нужно позаботиться о стоп-словах, максимальном размере словаря, эффективной структуре данных (обычно текстовые данные превращают в разреженные вектора)…
Используя алгоритмы вроде Вag of Words, мы теряем порядок слов в тексте, а значит, тексты "i have no cows" и "no, i have cows" будут идентичными после векторизации, хотя и противоположными семантически. Чтобы избежать этой проблемы, можно сделать шаг назад и изменить подход к токенизации: например, использовать N-граммы (комбинации из N последовательных терминов).
In : from sklearn.feature_extraction.text import CountVectorizer In : vect = CountVectorizer(ngram_range=(1,1)) In : vect.fit_transform(['no i have cows', 'i have no cows']).toarray() Out: array([[1, 1, 1], [1, 1, 1]], dtype=int64) In : vect.vocabulary_ Out: {'cows': 0, 'have': 1, 'no': 2} In : vect = CountVectorizer(ngram_range=(1,2)) In : vect.fit_transform(['no i have cows', 'i have no cows']).toarray() Out: array([[1, 1, 1, 0, 1, 0, 1], [1, 1, 0, 1, 1, 1, 0]], dtype=int64) In : vect.vocabulary_ Out: {'cows': 0, 'have': 1, 'have cows': 2, 'have no': 3, 'no': 4, 'no cows': 5, 'no have': 6}Также отмечу, что необязательно оперировать именно словами: в некоторых случаях можно генерировать N-граммы из букв (например, такой алгоритм учтет сходство родственных слов или опечаток).
In : vect = CountVectorizer(ngram_range=(3,3), analyzer='char_wb') In : n1, n2, n3, n4 = vect.fit_transform(['иванов', 'петров', 'петренко', 'смит']).toarray() In : euclidean(n1, n2) Out: 3.1622776601683795 In : euclidean(n2, n3) Out: 2.8284271247461903 In : euclidean(n3, n4) Out: 3.4641016151377544Развитие идеи Bag of Words: слова, которые редко встречаются в корпусе (во всех рассматриваемых документах этого набора данных), но присутствуют в этом конкретном документе, могут оказаться более важными. Тогда имеет смысл повысить вес более узкотематическим словам, чтобы отделить их от общетематических. Этот подход называется TF-IDF, его уже не напишешь в десять строк, потому желающие могут ознакомиться с деталями во внешних источниках вроде wiki. Вариант по умолчанию выглядит так:
Аналоги Bag of words могут встречаться и за пределами текстовых задач: например, bag of sites в соревновании, которые мы проводим – Catch Me If You Can. Можно поискать и другие примеры – bag of apps, bag of events.

Используя такие алгоритмы, можно получить вполне рабочее решение несложной проблемы, эдакий baseline. Впрочем, для нелюбителей классики есть и более новые подходы. Самый распиаренный метод новой волны – Word2Vec, но есть и альтернативы (Glove, Fasttext…).
Word2Vec является частным случаем алгоритмов Word Embedding. Используя Word2Vec и подобные модели, мы можем не только векторизовать слова в пространство большой размерности (обычно несколько сотен), но и сравнивать их семантическую близость. Классический пример операций над векторизированными представлениями: king – man + woman = queen.

Стоит понимать, что эта модель, конечно же, не обладает пониманием слов, а просто пытается разместить вектора таким образом, чтобы слова, употребляемые в общем контексте, размещались недалеко друг от друга. Если это не учитывать, то можно придумать много курьезов: например, найти противоположность Гитлеру путем умножения соответствующего вектора на -1.
Такие модели должны обучаться на очень больших наборах данных, чтобы координаты векторов действительно отражали семантику слов. Для решения своих задач можно скачать предобученную модель, например, здесь.
Похожие методы, кстати, применяются и других областях (например, в биоинформатике). Из совсем неожиданных применений – food2vec.
Изображения
В работе с изображениями все и проще, и сложнее одновременно. Проще, потому что часто можно вообще не думать и пользоваться одной из популярных предобученных сетей; сложнее, потому что если нужно все-таки детально разобраться, то эта кроличья нора окажется чертовски глубокой. Впрочем, обо всем по порядку.
Во времена, когда GPU были слабее, а "ренессанс нейросетей" еще не случился, генерация фичей из картинок была отдельной сложной областью. Для работы с картинками нужно было работать на низком уровне, определяя, например, углы, границы областей и так далее. Опытные специалисты в компьютерном зрении могли бы провести много параллелей между более старыми подходами и нейросетевым хипстерством: в частности, сверточные слои в современных сетях очень похожи на каскады Хаара. Не будучи опытным в этом вопросе, не стану даже пытаться передать знание из публичных источников, оставлю пару ссылок на библиотеки skimage и SimpleCV и перейду сразу к нашим дням.
Часто для задач, связанных с картинками, используется какая-нибудь сверточная сеть. Можно не придумывать архитектуру и не обучать сеть с нуля, а взять предобученную state of the art сеть, веса которой можно скачать из открытых источников. Чтобы адаптировать ее под свою задачу, дата сайнтисты практикуют т.н. fine tuning: последние полносвязные слои сети "отрываются", вместо них добавляются новые, подобранные под конкретную задачу, и сеть дообучается на новых данных. Но если вы хотите просто векторизовать изображение для каких-то своих целей (например, использовать какой-то несетевой классификатор) – просто оторвите последние слои и используйте выход предыдущих слоев:
from keras.applications.resnet50 import ResNet50 from keras.preprocessing import image from scipy.misc import face import numpy as np resnet_settings = {'include_top': False, 'weights': 'imagenet'} resnet = ResNet50(**resnet_settings) img = image.array_to_img(face()) # какой милый енот! img = img.resize((224, 224)) # в реальной жизни может понадобиться внимательнее относиться к ресайзу x = image.img_to_array(img) x = np.expand_dims(x, axis=0) # нужно дополнительное измерение, т.к. модель рассчитана на работу с массивом изображений features = resnet.predict(x)
Тем не менее, не стоит зацикливаться на нейросетевых методах. Некоторые признаки, сгенерированные руками, могут оказаться полезными и в наши дни: например, предсказывая популярность объявлений об аренде квартиры, можно предположить, что светлые квартиры больше привлекают внимание, и сделать признак "среднее значение пикселя". Вдохновиться примерами можно в документации соответствующих библиотек.
Если на картинке ожидается текст, его также можно прочитать и не разворачивая своими руками сложную нейросеть: например, при помощи pytesseract.
In : import pytesseract In : from PIL import Image In : import requests In : from io import BytesIO In : img = 'http://ohscurrent.org/wp-content/uploads/2015/09/domus-01-google.jpg' # просто случайная картинка из поиска In : img = requests.get(img) ...: img = Image.open(BytesIO(img.content)) ...: text = pytesseract.image_to_string(img) ...: In : text Out: 'Google'Надо понимать, что pytesseract – далеко не панацея:
# на этот раз возьмем картинку от Renthop In : img = requests.get('https://photos.renthop.com/2/8393298_6acaf11f030217d05f3a5604b9a2f70f.jpg') ...: img = Image.open(BytesIO(img.content)) ...: pytesseract.image_to_string(img) ...: Out: 'Cunveztible to 4}»'Еще один случай, когда нейросети не помогут – извлечение признаков из метаинфорации. А ведь в EXIF может храниться много полезного: производитель и модель камеры, разрешение, использование вспышки, геокоординаты съемки, использованный для обработки софт и многое другое.
Геоданные
Географические данные не так часто попадаются в задачах, но освоить базовые приемы для работы с ними также полезно, тем более, что в этой сфере тоже хватает готовых решений.
Геоданные чаще всего представлены в виде адресов или пар "широта + долгота", т.е. точек. В зависимости от задачи могут понадобиться две обратные друг другу операции: геокодинг (восстановление точки из адреса) и обратный геокодинг (наоборот). И то, и другое осуществимо при помощи внешних API вроде Google Maps или OpenStreetMap. У разных геокодеров есть свои особенности, качество разнится от региона к региону. К счастью, есть универсальные библиотеки вроде geopy, которые выступают в роли оберток над множеством внешних сервисов.
Если данных много, легко упереться в лимиты внешних API. Да и получать информацию по HTTP – далеко не всегда оптимальное по скорости решение. Поэтому стоит иметь в виду возможность использования локальной версии OpenStreetMap.
Если данных немного, времени хватает, а желания извлекать наворченные признаки нет, то можно не заморачиваться с OpenStreetMap и воспользоваться reverse_geocoder:
In : import reverse_geocoder as revgc In : revgc.search((df.latitude, df.longitude)) Loading formatted geocoded file... Out: [OrderedDict([('lat', '40.74482'), ('lon', '-73.94875'), ('name', 'Long Island City'), ('admin1', 'New York'), ('admin2', 'Queens County'), ('cc', 'US')])]Работая с геокодингом, нельзя забывать о том, что адреса могут содержать опечатки, соответственно, стоит потратить время на очистку. В координатах опечаток обычно меньше, но и с ними не все хорошо: GPS по природе данных может "шуметь", а в некоторых местах (туннели, кварталы небоскребов...) – довольно сильно. Если источник данных – мобильное устройство, стоит учесть, что в некоторых случаях геолокация определяется не по GPS, а по WiFi сетям в округе, что ведет к дырам в пространстве и телепортации: среди набора точек, описывающих путешествие по Манхеттену может внезапно оказаться одна из Чикаго.
WiFi location tracking основан на комбинации SSID и MAC-адреса, которые могут совпадать у совсем разных точек (например, федеральный провайдер стандартизировал прошивку роутеров с точностью до MAC-адреса и размещает их в разных городах). Есть и более банальные причины вроде переезда компании со своими роутерами в другой офис.
Точка обычно находится не в чистом поле, а среди инфраструктуры – здесь можно дать волю фантазии и начать придумывать признаки, применяя жизненный опыт и знание доменной области. Близость точки к метро, этажность застройки, расстояние до ближайшего магазина, количество банкоматов в радиусе – в рамках одной задачи можно придумывать десятки признаков и добывать их из разных внешних источников. Для задач вне городской инфраструктуры могут пригодиться признаки из более специфических источников: например, высота над уровнем моря.
Если две или более точек взаимосвязаны, возможно, стоит извлекать признаки из маршрута между ними. Здесь пригодятся и дистанции (стоит смотреть и на great circle distance, и на "честное" расстояние, посчитанное по дорожному графу), и количество поворотов вместе с соотношением левых и правых, и количество светофоров, развязок, мостов. Например, в одной из моих задач неплохо себя проявил признак, который я назвал "сложность дороги" – расстояние, посчитанное по графу и деленное на GCD.
Дата и время
Казалось бы, работа с датой и временем должна быть стандартизирована из-за распространенности соответствующих признаков, но подводные камни остаются.
Начнем с дней недели – их легко превратить в 7 dummy переменных при помощи one-hot кодирования. Кроме этого, полезно выделить отдельный признак для выходных.
df['dow'] = df['created'].apply(lambda x: x.date().weekday()) df['is_weekend'] = df['created'].apply(lambda x: 1 if x.date().weekday() in (5, 6) else 0)В некоторых задачах могут понадобиться дополнительные календарные признаки: например, снятие наличных денег может быть привязано к дню выдачи зарплат, а покупка проездного – к началу месяца. А по-хорошему, работая с временными данными, надо иметь под рукой календарь с государственными праздниками, аномальными погодными условиями и другими важными событиями.
- Что общего между китайским новым годом, нью-йорским марафоном, гей-парадом и инаугурацией Трампа?
- Их все нужно внести в календарь потенциальных аномалий.
А вот с часом (минутой, днем месяца...) все не так радужно. Если использовать час как вещественную переменную, мы немного противоречим природе данных: 0 < 23, хотя 02.01 0:00:00 > 01.01 23:00:00. Для некоторых задач это может оказаться критично. Если же кодировать их как категориальные переменные, можно наплодить кучу признаков и потерять информацию о близости: разница между 22 и 23 будет такой же, как и между 22 и 7.
Есть и более эзотерические подходы к таким данным. Например, проекция на окружность с последующим использованием двух координат.
def make_harmonic_features(value, period=24): value *= 2 * np.pi / period return np.cos(value), np.sin(value)Такое преобразование сохраняет дистанцию между точками, что важно для некоторых алгоритмов, основанных на расстоянии (kNN, SVM, k-means...)
In : from scipy.spatial import distance In : euclidean(make_harmonic_features(23), make_harmonic_features(1)) Out: 0.5176380902050424 In : euclidean(make_harmonic_features(9), make_harmonic_features(11)) Out: 0.5176380902050414 In : euclidean(make_harmonic_features(9), make_harmonic_features(21)) Out: 2.0Впрочем, разницу между такими способами кодирования обычно можно уловить только в третьем знаке после запятой в метрике, не раньше.
Временные ряды, веб и прочее
Мне не довелось вдоволь поработать с временными рядами, потому я оставлю ссылку на библиотеку для автоматической генерации признаков из временных рядов и пойду дальше.
Если вы работаете с вебом, то у вас обычно есть информация про User Agent пользователя. Это кладезь информации.
Во-первых, оттуда в первую очередь нужно извлечь операционную систему. Во-вторых, сделать признак is_mobile. В-третьих, посмотреть на браузер.
In : ua = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/ ...: 56.0.2924.76 Safari/537.36' In : import user_agents In : ua = user_agents.parse(ua) In : ua.is_bot Out: False In : ua.is_mobile Out: False In : ua.is_pc Out: True In : ua.os.family Out: 'Ubuntu' In : ua.os.version Out: () In : ua.browser.family Out: 'Chromium' In : ua.os.version Out: () In : ua.browser.version Out: (56, 0, 2924)Как и в других доменных областях, можно придумывать свои признаки, основываясь на догадках о природе данных. На момент написания статьи Chromium 56 был новым, а через какое-то время такая версия браузера сможет сохраниться только у тех, кто очень давно не перезагружал этот самый браузер. Почему бы в таком случае не ввести признак "отставание от свежей версии браузера"?
Кроме ОС и браузера, можно посмотреть на реферер (доступен не всегда), http_accept_language и другую метаинформацию.
Следующая по полезности информация – IP-адрес, из которого можно извлечь как минимум страну, а желательно еще город, провайдера, тип подключения (мобильное / стационарное). Нужно понимать, что бывают разнообразные прокси и устаревшие базы, так что признак может содержать шум. Гуру сетевого администрирования могут попробовать извлекать и гораздо более навороченные признаки: например, строить предположения об использовании VPN. Кстати, данные из IP-адреса неплохо комбинировать с http_accept_language: если пользователь сидит за чилийским прокси, а локаль браузера – ru_RU, что-то здесь нечисто и достойно единицы в соответствующей колонке в таблице (is_traveler_or_proxy_user).
Вообще, доменной специфики в той или иной области настолько много, что в одной голове ей не уместиться. Потому я призываю уважаемых читателей поделиться опытом и рассказать в комментариях об извлечении и генерации признаков в своей работе.
Преобразования признаков (Feature transformations)
Нормализация и изменение распределения
Монотонное преобразование признаков критично для одних алгоритмов и не оказывает влияния на другие. Кстати, это одна из причин популярности деревьев решений и всех производных алгоритмов (случайный лес, градиентный бустинг) – не все умеют/хотят возиться с преобразованиями, а эти алгоритмы устойчивы к необычным распределениям.
Бывают и сугубо инженерные причины: np.log как способ борьбы со слишком большими числами, не помещающимися в np.float64. Но это скорее исключение, чем правило; чаще все-таки вызвано желанием адаптировать датасет под требования алгоритма. Параметрические методы обычно требуют как минимум симметричного и унимодального распределения данных, что не всегда обеспечивается реальным миром. Могут быть и более строгие требования (уместно вспомнить урок про линейные модели).
Впрочем, требования к данным предъявляют не только параметрические методы: тот же метод ближайших соседей предскажет полную чушь, если признаки ненормированы: одно распределение расположено в районе нуля и не выходит за пределы (-1, 1), а другой признак – это сотни и тысячи.
Простой пример: предположим, что стоит задача предсказать стоимость квартиры по двум признакам – удаленности от центра и количеству комнат. Количество комнат редко превосходит 5, а расстояние от центра в больших городах легко может измеряться в десятках тысяч метров.
Самая простая трансформация – это Standart Scaling (она же Z-score normalization).
StandartScaling хоть и не делает распределение нормальным в строгом смысле слова...
In : from sklearn.preprocessing import StandardScaler In : from scipy.stats import beta In : from scipy.stats import shapiro In : data = beta(1, 10).rvs(1000).reshape(-1, 1) In : shapiro(data) Out: (0.8783774375915527, 3.0409122263582326e-27) # значение статистики, p-value In : shapiro(StandardScaler().fit_transform(data)) Out: (0.8783774375915527, 3.0409122263582326e-27) # с таким p-value придется отклонять нулевую гипотезу о нормальности данных… но в какой-то мере защищает от выбросов
In : data = np.array([1, 1, 0, -1, 2, 1, 2, 3, -2, 4, 100]).reshape(-1, 1).astype(np.float64) In : StandardScaler().fit_transform(data) Out: array([[-0.31922662], [-0.31922662], [-0.35434155], [-0.38945648], [-0.28411169], [-0.31922662], [-0.28411169], [-0.24899676], [-0.42457141], [-0.21388184], [ 3.15715128]]) In : (data – data.mean()) / data.std() Out: array([[-0.31922662], [-0.31922662], [-0.35434155], [-0.38945648], [-0.28411169], [-0.31922662], [-0.28411169], [-0.24899676], [-0.42457141], [-0.21388184], [ 3.15715128]])Другой достаточно популярный вариант – MinMax Scaling, который переносит все точки на заданный отрезок (обычно (0, 1)).
In : from sklearn.preprocessing import MinMaxScaler In : MinMaxScaler().fit_transform(data) Out: array([[ 0.02941176], [ 0.02941176], [ 0.01960784], [ 0.00980392], [ 0.03921569], [ 0.02941176], [ 0.03921569], [ 0.04901961], [ 0. ], [ 0.05882353], [ 1. ]]) In : (data – data.min()) / (data.max() – data.min()) Out: array([[ 0.02941176], [ 0.02941176], [ 0.01960784], [ 0.00980392], [ 0.03921569], [ 0.02941176], [ 0.03921569], [ 0.04901961], [ 0. ], [ 0.05882353], [ 1. ]])StandartScaling и MinMax Scaling имеют похожие области применимости и часто сколько-нибудь взаимозаменимы. Впрочем, если алгоритм предполагает вычисление расстояний между точками или векторами, выбор по умолчанию – StandartScaling. Зато MinMax Scaling полезен для визуализации, чтобы перенести признаки на отрезок (0, 255).
Если мы предполагаем, что некоторые данные не распределены нормально, зато описываются логнормальным распределением, их можно легко привести к честному нормальному распределению:
In : from scipy.stats import lognorm In : shapiro(data) Out: (0.05714237689971924, 0.0) In : shapiro(np.log(data)) Out: (0.9980740547180176, 0.3150389492511749)Логнормальное распределение подходит для описания зарплат, стоимости ценных бумаг, населения городов, количества комментариев к статьям в интернете и т.п. Впрочем, для применения такого приема распределение не обязательно должно быть именно логнормальным – все распределения с тяжелым правым хвостом можно пробовать подвергнуть такому преобразованию. Кроме того, можно пробовать применять и другие похожие преобразования, ориентируясь на собственные гипотезы о том, как приблизить имеющееся распределение к нормальному. Примерами таких трансформаций являются преобразование Бокса-Кокса (логарифмирование – это частный случай трансформации Бокса-Кокса) или преобразование Йео-Джонсона, расширяющее область применимости на отрицательные числа; кроме того, можно пробовать просто добавлять константу к признаку – np.log(x + const).
В примерах выше мы работали с синтетическими данными и строго проверяли нормальность при помощи критерия Шапиро-Уилка. Давайте попробуем посмотреть на реальные данные, а для проверки на нормальность будем использовать менее формальный метод – Q-Q график. Для нормального распределения он будет выглядеть как ровная диагональная линия, и визуальные отклонения интуитивно понятны.
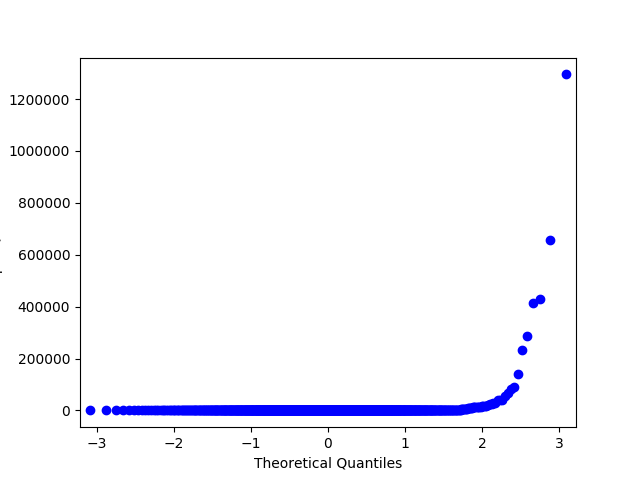

In : import statsmodels.api as sm # возьмем признак price из датасета Renthop и пофильтруем руками совсем экстремальные значения для наглядности In : price = df.price[(df.price <= 20000) & (df.price > 500)] In : price_log = np.log(price) In : price_mm = MinMaxScaler().fit_transform(price.values.reshape(-1, 1).astype(np.float64)).flatten() # много телодвижений, чтобы sklearn не сыпал warning-ами In : price_z = StandardScaler().fit_transform(price.values.reshape(-1, 1).astype(np.float64)).flatten() In : sm.qqplot(price_log, loc=price_log.mean(), scale=price_log.std()).savefig('qq_price_log.png') In : sm.qqplot(price_mm, loc=price_mm.mean(), scale=price_mm.std()).savefig('qq_price_mm.png') In : sm.qqplot(price_z, loc=price_z.mean(), scale=price_z.std()).savefig('qq_price_z.png')
Q-Q график исходного признака

Q-Q график признака после StandartScaler. Форма не меняется
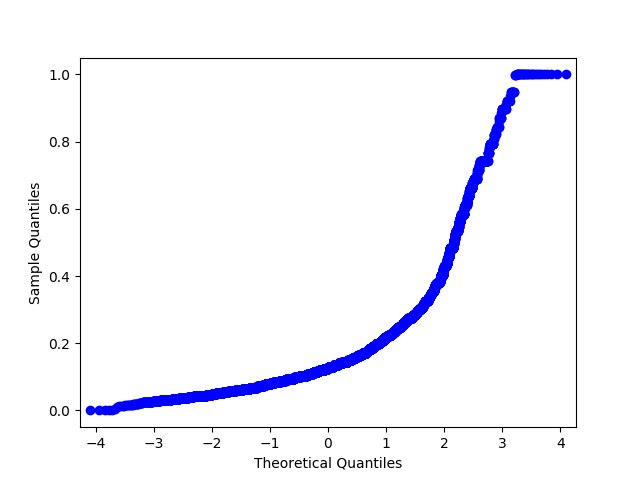
Q-Q график признака после MinMaxScaler. Форма не меняется

Q-Q график признака после логарифмирования. Дела пошли на поправку!
Давайте посмотрим, могут ли преобразования как-то помочь реальной модели. Я сделал небольшой скрипт, который читает данные соревнования Renthop, выбирает некоторые признаки (остальные по-диктаторски выброшены для простоты), и возвращает нам более или менее готовые данные для демонстрации.
In : from demo import get_data In : x_data, y_data = get_data() In : x_data.head(5) Out: bathrooms bedrooms price dishwasher doorman pets 10 1.5 3 8.006368 0 0 0 10000 1.0 2 8.606119 0 1 1 100004 1.0 1 7.955074 1 0 1 100007 1.0 1 8.094073 0 0 0 100013 1.0 4 8.116716 0 0 0 air_conditioning parking balcony bike ... stainless 10 0 0 0 0 ... 0 10000 0 0 0 0 ... 0 100004 0 0 0 0 ... 0 100007 0 0 0 0 ... 0 100013 0 0 0 0 ... 0 simplex public num_photos num_features listing_age room_dif 10 0 0 5 0 278 1.5 10000 0 0 11 57 290 1.0 100004 0 0 8 72 346 0.0 100007 0 0 3 22 345 0.0 100013 0 0 3 7 335 3.0 room_sum price_per_room bedrooms_share 10 4.5 666.666667 0.666667 10000 3.0 1821.666667 0.666667 100004 2.0 1425.000000 0.500000 100007 2.0 1637.500000 0.500000 100013 5.0 670.000000 0.800000 [5 rows x 46 columns] In : x_data = x_data.values In : from sklearn.linear_model import LogisticRegression In : from sklearn.ensemble import RandomForestClassifier In : from sklearn.model_selection import cross_val_score In : from sklearn.feature_selection import SelectFromModel In : cross_val_score(LogisticRegression(), x_data, y_data, scoring='neg_log_loss').mean() /home/arseny/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sklearn/linear_model/base.py:352: RuntimeWarning: overflow encountered in exp np.exp(prob, prob) # кажется, что-то пошло не так! вообще-то стоит разобраться, в чем проблема Out: -0.68715971821885724 In : from sklearn.preprocessing import StandardScaler In : cross_val_score(LogisticRegression(), StandardScaler().fit_transform(x_data), y_data, scoring='neg_log_loss').mean() /home/arseny/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sklearn/linear_model/base.py:352: RuntimeWarning: overflow encountered in exp np.exp(prob, prob) Out: -0.66985167834479187 # ого! действительно помогает! In : from sklearn.preprocessing import MinMaxScaler In : cross_val_score(LogisticRegression(), MinMaxScaler().fit_transform(x_data), y_data, scoring='neg_log_loss').mean() ...: Out: -0.68522489913898188 # a на этот раз – нет :( Взаимодействия (Interactions)
Если предыдущие преобразования диктовались скорее математикой, то этот пункт снова обоснован природой данных; его можно отнести как к трансформациям, так и к созданию новых признаков.
Снова обратимся к задаче Two Sigma Connect: Rental Listing Inquires. Среди признаков в этой задаче есть количество комнат и стоимость аренды. Житейская логика подсказывает, что стоимость в пересчете на одну комнату более показательна, чем общая стоимость – значит, можно попробовать выделить такой признак.
rooms = df["bedrooms"].apply(lambda x: max(x, .5)) # избегаем деления на ноль; .5 выбран более или менее произвольно df["price_per_bedroom"] = df["price"] / roomsНеобязательно руководствоваться жизненной логикой. Если признаков не очень много, вполне можно сгенерировать все возможные взаимодействия и потом отсеять лишние, используя одну из техник, описанных в следующем разделе. Кроме того, не все взаимодействия между признаками должны иметь хоть какой-то физический смысл: например, (часто используемые для линейных моделей)[https://habrahabr.ru/company/ods/blog/322076/] полиномиальные признаки (см. sklearn.preprocessing.PolynomialFeatures) трактовать практически невозможно.
Заполнение пропусков
Не многие алгоритмы умеют работать с пропущенными значениями "из коробки", а реальный мир часто поставляет данные с пропусками. К счастью, это одна из тех задач, для решения которых не нужно никакого творчества. Обе ключевые для анализа данных python библиотеки предоставляют простые как валенок решения: pandas.DataFrame.fillna и sklearn.preprocessing.Imputer.
Готовые библиотечные решения не прячут никакой магии за фасадом. Подходы к обработке отсутствующих значений напрашиваются на уровне здравого смысла:
- закодировать отдельным пустым значением типа
"n/a"(для категориальных переменных); - использовать наиболее вероятное значение признака (среднее или медиану для вещественных переменных, самое частое для категориальных);
- наоборот, закодировать каким-то невероятным значением (хорошо заходит для моделей, основанных на деревьях решений, т.к. позволяет сделать разделение на пропущенные и непропущенные значения);
- для упорядоченных данных (например, временных рядов) можно брать соседнее значение – следующее или предыдущее.

Удобство использования библиотечных решений иногда подсказывает воткнуть что-то вроде df = df.fillna(0) и не париться о пропусках. Но это не самое разумное решение: большая часть времени обычно уходит не на построение модели, а на подготовку данных; бездумное неявное заполнение пропусков может спрятать баг в обработке и испортить модель.
Выбор признаков (Feature selection)
Зачем вообще может понадобиться выбирать фичи? Кому-то эта идея может показаться контринтуитивной, но на самом деле есть минимум две важные причины избавляться от неважных признаков. Первая понятна всякому инженеру: чем больше данных, тем выше вычислительная сложность. Пока мы балуемся с игрушечными датасетами, размер данных – это не проблема, а для реального нагруженного продакшена лишние сотни признаков могут быть ощутимы. Другая причина – некоторые алгоритмы принимают шум (неинформативные признаки) за сигнал, переобучаясь.
Статистические подходы
Самый очевидный кандидат на отстрел – признак, у которого значение неизменно, т.е. не содержит вообще никакой информации. Если немного отойти от этого вырожденного случая, резонно предположить, что низковариативные признаки скорее хуже, чем высоковариативные. Так можно придти к идее отсекать признаки, дисперсия которых ниже определенной границы.
In : from sklearn.feature_selection import VarianceThreshold In : from sklearn.datasets import make_classification In : x_data_generated, y_data_generated = make_classification() In : x_data_generated.shape Out: (100, 20) In : VarianceThreshold(.7).fit_transform(x_data_generated).shape Out: (100, 19) In : VarianceThreshold(.8).fit_transform(x_data_generated).shape Out: (100, 18) In : VarianceThreshold(.9).fit_transform(x_data_generated).shape Out: (100, 15)Есть и другие способы, также основанные на классической статистике.
In : from sklearn.feature_selection import SelectKBest, f_classif In : x_data_kbest = SelectKBest(f_classif, k=5).fit_transform(x_data_generated, y_data_generated) In : x_data_varth = VarianceThreshold(.9).fit_transform(x_data_generated) In : from sklearn.linear_model import LogisticRegression In : from sklearn.model_selection import cross_val_score In : cross_val_score(LogisticRegression(), x_data_generated, y_data_generated, scoring='neg_log_loss').mean() Out: -0.45367136377981693 In : cross_val_score(LogisticRegression(), x_data_kbest, y_data_generated, scoring='neg_log_loss').mean() Out: -0.35775228616521798 In : cross_val_score(LogisticRegression(), x_data_varth, y_data_generated, scoring='neg_log_loss').mean() Out: -0.44033042718359772Видно, что отобранные фичи повысили качество классификатора. Понятно, что этот пример сугубо искусственный, тем не менее, прием достоин проверки и в реальных задачах.
Отбор с использованием моделей
Другой подход: использовать какую-то baseline модель для оценки признаков, при этом модель должна явно показывать важность использованных признаков. Обычно используются два типа моделей: какая-нибудь "деревянная" композиция (например, Random Forest) или линейная модель с Lasso регуляризацией, склонной обнулять веса слабых признаков. Логика интутивно понятна: если признаки явно бесполезны в простой модели, то не надо тянуть их и в более сложную.
from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectFromModel from sklearn.model_selection import cross_val_score from sklearn.pipeline import make_pipeline x_data_generated, y_data_generated = make_classification() pipe = make_pipeline(SelectFromModel(estimator=RandomForestClassifier()), LogisticRegression()) lr = LogisticRegression() rf = RandomForestClassifier() print(cross_val_score(lr, x_data_generated, y_data_generated, scoring='neg_log_loss').mean()) print(cross_val_score(rf, x_data_generated, y_data_generated, scoring='neg_log_loss').mean()) print(cross_val_score(pipe, x_data_generated, y_data_generated, scoring='neg_log_loss').mean()) -0.184853179322 -0.235652626736 -0.158372952933Нельзя забывать, что это тоже не серебряная пуля — может получиться даже хуже.
x_data, y_data = get_data() x_data = x_data.values pipe1 = make_pipeline(StandardScaler(), SelectFromModel(estimator=RandomForestClassifier()), LogisticRegression()) pipe2 = make_pipeline(StandardScaler(), LogisticRegression()) rf = RandomForestClassifier() print('LR + selection: ', cross_val_score(pipe1, x_data, y_data, scoring='neg_log_loss').mean()) print('LR: ', cross_val_score(pipe2, x_data, y_data, scoring='neg_log_loss').mean()) print('RF: ', cross_val_score(rf, x_data, y_data, scoring='neg_log_loss').mean()) LR + selection: -0.714208124619 LR: -0.669572736183 # стало только хуже! RF: -2.13486716798 Перебор
Наконец, самый надежный, но и самый вычислительно сложный способ основан на банальном переборе: обучаем модель на подмножестве "фичей", запоминаем результат, повторяем для разных подмножеств, сравниваем качество моделей. Такой подход называется Exhaustive Feature Selection.
Перебирать все комбинации – обычно слишком долго, так что можно пробовать уменьшить пространство перебора. Фиксируем небольшое число N, перебираем все комбинации по N признаков, выбираем лучшую комбинацию, потом перебираем комбинации из N+1 признаков так, что предыдущая лучшая комбинация признаков зафиксирована, а перебирается только новый признак. Таким образом можно перебирать, пока не упремся в максимально допустимое число признаков или пока качество модели не перестанет значимо расти. Этот алгоритм называется Sequential Feature Selection.
Этот же алгоритм можно развернуть: начинать с полного пространства признаков и выкидывать признаки по одному, пока это не портит качество модели или пока не достигнуто желаемое число признаков.
In : selector = SequentialFeatureSelector(LogisticRegression(), scoring='neg_log_loss', verbose=2, k_features=3, forward=False, n_jobs=-1) In : selector.fit(x_data_scaled, y_data) In : selector.fit(x_data_scaled, y_data) [2017-03-30 01:42:24] Features: 45/3 -- score: -0.682830838803 [2017-03-30 01:44:40] Features: 44/3 -- score: -0.682779463265 [2017-03-30 01:46:47] Features: 43/3 -- score: -0.682727480522 [2017-03-30 01:48:54] Features: 42/3 -- score: -0.682680521828 [2017-03-30 01:50:52] Features: 41/3 -- score: -0.68264297879 [2017-03-30 01:52:46] Features: 40/3 -- score: -0.682607753617 [2017-03-30 01:54:37] Features: 39/3 -- score: -0.682570678346 [2017-03-30 01:56:21] Features: 38/3 -- score: -0.682536314625 [2017-03-30 01:58:02] Features: 37/3 -- score: -0.682520258804 [2017-03-30 01:59:39] Features: 36/3 -- score: -0.68250862986 [2017-03-30 02:01:17] Features: 35/3 -- score: -0.682498213174 # "Вечерело. А старушки все падали и падали..." ... [2017-03-30 02:21:09] Features: 10/3 -- score: -0.68657335969 [2017-03-30 02:21:18] Features: 9/3 -- score: -0.688405548594 [2017-03-30 02:21:26] Features: 8/3 -- score: -0.690213724719 [2017-03-30 02:21:32] Features: 7/3 -- score: -0.692383588303 [2017-03-30 02:21:36] Features: 6/3 -- score: -0.695321584506 [2017-03-30 02:21:40] Features: 5/3 -- score: -0.698519960477 [2017-03-30 02:21:42] Features: 4/3 -- score: -0.704095390444 [2017-03-30 02:21:44] Features: 3/3 -- score: -0.713788301404 # но улучшение не могло продолжаться вечноДомашнее задание
В рамках самостоятельной работы предлагается ответить на несколько несложных вопросов: Jupyter-заготовка, веб-форма для ответов. Как обычно, на работу выделена одна неделя, т.е. ответы принимаются до 10 апреля 23:59 UTC+3. В случае возникновения каких-то сложностей с ответами на вопросы, пишите в Slack-чат Open Data Science (канал #mlcourse_open, для оперативного ответа может быть полезно обратиться к @arsenyinfo).
Open Data Science желает удачи в выполнении домашней работы, а также чистых данных и полезных признаков в реальной работе!
Телеграм: t.me/ainewsline
Источник: habrahabr.ru