Объяснение нейронных машин Тьюринга
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-04-29 18:20

Я обнаружил, что подавляющее большинство онлайновой информации об исследованиях в области искусственного интеллекта делится на две категории: первая рассказывает о достижениях непрофессиональной аудитории, а вторая — другим исследователям. Я не нашёл хорошего ресурса для людей с техническим образованием, которые не знакомы с более продвинутыми концепциями и ищут информацию для восполнения пробелов. Это моя попытка заполнить данную пустоту, предоставив доступные, но в то же время (относительно) подробные объяснения. Здесь я объясню научную статью Грейвса, Уэйна и Данихейки (2014) о нейронных машинах Тьюринга (NTM).
Изначально я не собирался рассказывать об этой статье, но я никак не мог понять другую интересную статью, о которой собирался рассказать. В ней как раз шла речь о модификации NTM, так что я решил убедиться, что полностью понимаю NTM, прежде чем двигаться дальше. Убедившись в этом, у меня появилось ощущение, что та вторая статья не слишком подходит для объяснения, а вот оригинальная работа по NTM очень хорошо написана, и я настоятельно рекомендую её прочитать.
Мотивация
В течение первых тридцати лет исследований искусственного интеллекта нейронные сети считались, в основном, бесперспективным направлением. С 1950-х до конца 1980-х в ИИ доминировал символьный подход. Он предполагал, что работу систем обработки информации вроде человеческого мозга можно понять благодаря манипуляциям с символами, структурами и правилами обработки этих символов и структур. Только в 1986 году появилась серьёзная альтернатива символьному ИИ; её авторы использовали термин «параллельная распределённая обработка» (Parallel Distributed Processing), но сегодня чаще используется термин «коннекционизм». Вы могли не слышать о таком подходе, но наверняка слышали об одной из самых знаменитых техник моделирования коннекционизма — искусственных нейронных сетях.
Критики выдвинули два аргумента против того, что нейронные сети помогут нам лучше понять интеллект. Во-первых, нейронные сети с фиксированным размером входных данных, по-видимому, не способны решать проблемы с входными данными переменного размера. Во-вторых, нейронные сети вроде бы не способны привязывать значения к конкретному местонахождению в структурах данных. Способность записи и чтения из памяти является критически важной в обеих системах обработки информации, которые доступны для изучения: в мозге и компьютерах. В таком случае что можно ответить на эти два аргумента?
Первый аргумент был опровергнут с созданием рекуррентных нейронных сетей (RNN). Они могут обрабатывать входные данные переменного размера без необходимости модификации или добавления компонента времени в процедуру обработки — при переводе предложения или распознавании рукописного текста RNN неоднократно получают входные данные фиксированного размера столько раз, сколько требуется. В своей научной статье Грейвс с соавторами пытается опровергнуть второй аргумент, предоставляя нейронной сети доступ к внешней памяти и способность обучаться, как её использовать. Они назвали свою систему нейронной машиной Тьюринга (NTM).
Предпосылки
Для специалистов в области теории вычислительных машин очевидна необходимость наличия системы памяти. Компьютеры чрезвычайно усовершенствовались за последние полстолетия, но они по-прежнему состоят из трёх компонентов: памяти, управляющей логики и арифметических/логический операций. Есть и биологические свидетельства, указывающие на пользу системы памяти для быстрого сохранения и извлечения информации. Такая система памяти называется рабочей памятью, а статья по NTM ссылается на несколько более ранних работ, которые изучали рабочую память с точки зрения вычислительной нейробиологии.
Интуиция
Принципиальная схема NTM включает нейронную сеть, которая называется контроллер, 2D-матрицу (банк памяти) и матрицу памяти или обыкновенную память. На каждом шаге времени нейронная сеть получает некоторые данные из внешнего мира и отправляет некоторые выходные данные во внешний мир. Однако нейросеть также имеет возможность считывать информацию из отдельных ячеек памяти и возможность записывать в отдельные ячейки памяти. Грейвс с соавторами черпал вдохновение из традиционной машины Тьюринга и использовал термин «головка» при описании операций с ячейками памяти. На схеме внизу пунктирная линия ограничивает части архитектуры, которые находятся «внутри» системы, по отношению к внешнему миру.
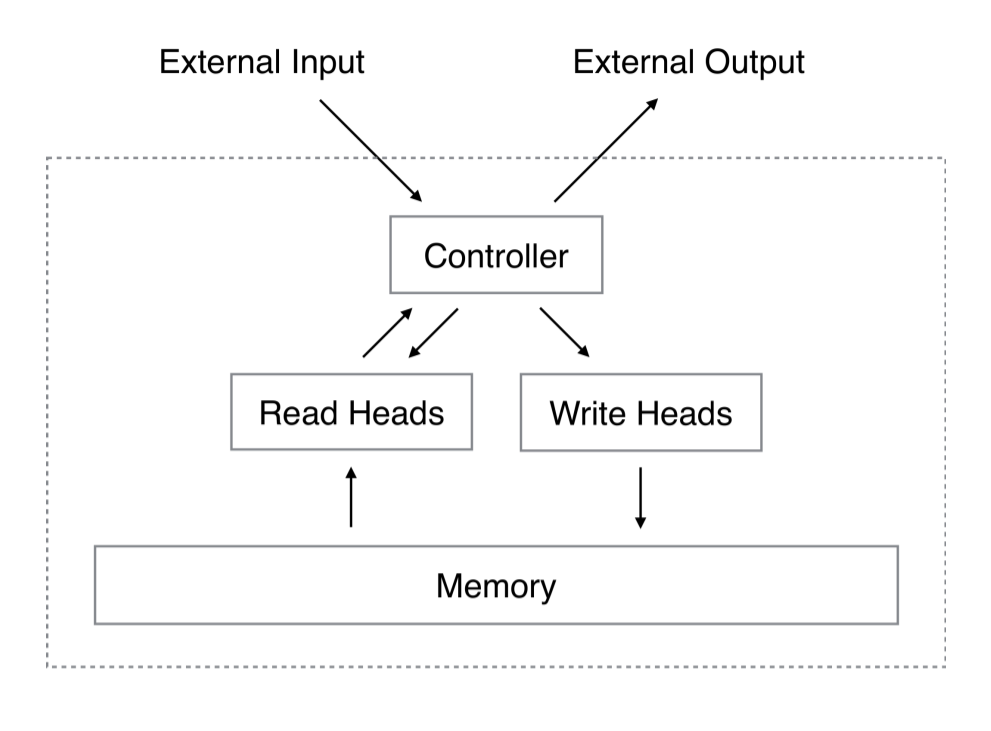
Но есть подвох. Предположим, что мы индексируем память  , указав строку и колонку, как в обычной матрице. Мы бы хотели обучить нашу нейросеть с помощью метода обратного распространения ошибки и нашего любимого метода оптимизации (например, методом стохастического градиента), но как получить градиент определённого индекса? Не получится. Вместо этого контроллер осуществляет операции чтения и записи в рамках «размытых» операций, которые взаимодействуют со всеми элементами в памяти в той или иной степени. Контроллер рассчитает веса для ячеек памяти, которые позволят ему определить ячейки памяти дифференцируемым образом. Далее я объясню, как генерируются эти весовые векторы, а затем — как они используются (так легче понять систему).
, указав строку и колонку, как в обычной матрице. Мы бы хотели обучить нашу нейросеть с помощью метода обратного распространения ошибки и нашего любимого метода оптимизации (например, методом стохастического градиента), но как получить градиент определённого индекса? Не получится. Вместо этого контроллер осуществляет операции чтения и записи в рамках «размытых» операций, которые взаимодействуют со всеми элементами в памяти в той или иной степени. Контроллер рассчитает веса для ячеек памяти, которые позволят ему определить ячейки памяти дифференцируемым образом. Далее я объясню, как генерируются эти весовые векторы, а затем — как они используются (так легче понять систему).
Математика
Чтение
Возьмём матрицу памяти с  строк и
строк и  элементов в строке, с временем
элементов в строке, с временем  как
как  . Чтобы осуществить чтение (и запись), требуется некий механизм внимания, который определяет, откуда головка должна считать данные. Механизм внимания будет нормированным по длине (length-) весовым вектором
. Чтобы осуществить чтение (и запись), требуется некий механизм внимания, который определяет, откуда головка должна считать данные. Механизм внимания будет нормированным по длине (length-) весовым вектором  . Мы будем говорить об отдельных элементах весового вектора как о
. Мы будем говорить об отдельных элементах весового вектора как о  . Под «нормированием» авторы подразумевают соблюдение двух следующих ограничений:
. Под «нормированием» авторы подразумевают соблюдение двух следующих ограничений:

Головка чтения вернёт нормированный по длине (length- ) вектор
) вектор  , который представляет собой линейную комбинацию строк памяти
, который представляет собой линейную комбинацию строк памяти  , масштабированных весовым вектором:
, масштабированных весовым вектором:

Запись
Запись немного сложнее, чем чтение, поскольку включает в себя два отдельных шага: стирание, затем добавление. Чтобы стереть старые данные, записывающей головке нужен новый вектор, это length- стирающий вектор  , вдобавок к нашему length- нормированному весовому вектору . Стирающий вектор используется в конъюнкции с весовым вектором для определения, какие элементы в строке следует удалить, оставить неизменными или нечто среднее. Если весовой вектор указывает на строку, а стирающий вектор указывает стереть элемент, то элемент в этой строке будет стёрт.
, вдобавок к нашему length- нормированному весовому вектору . Стирающий вектор используется в конъюнкции с весовым вектором для определения, какие элементы в строке следует удалить, оставить неизменными или нечто среднее. Если весовой вектор указывает на строку, а стирающий вектор указывает стереть элемент, то элемент в этой строке будет стёрт.

После преобразования  в
в  записывающая головка использует length- добавляющий вектор
записывающая головка использует length- добавляющий вектор  для завершения операции записи.
для завершения операции записи.

Адресация
Создание таких весовых векторов для определения мест, где следует считывать и записывать данные — непростое дело, я бы представил этот процесс в виде четырёх стадий. На каждой стадии генерируется промежуточный весовой вектор, который передаётся на следующую стадию. Цель первой стадии — сгенерировать весовой вектор на основании того, насколько близка каждая строка в памяти к length- вектору  , выпущенному контроллером. Будем называть этот промежуточный весовой вектор
, выпущенному контроллером. Будем называть этот промежуточный весовой вектор  весовым вектором контента. Другой параметр
весовым вектором контента. Другой параметр  сейчас объясню.
сейчас объясню.
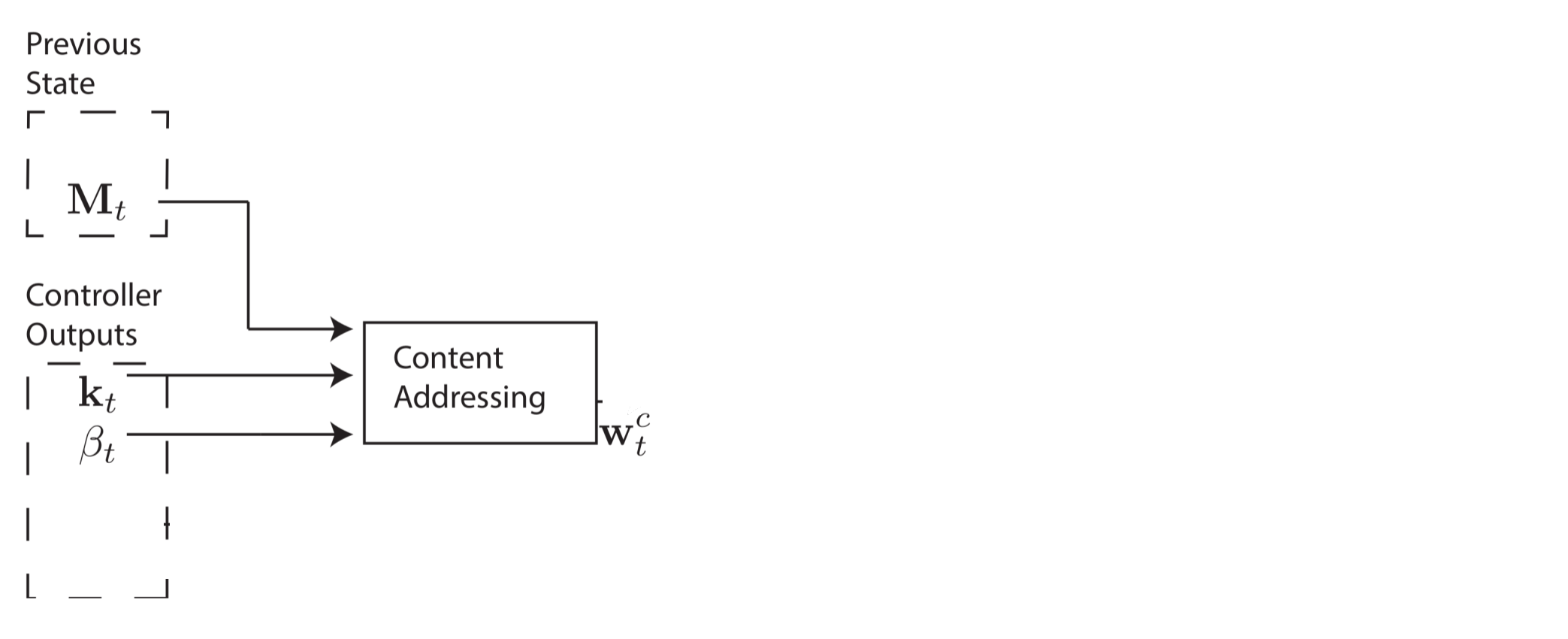 Весовой вектор контента позволяет контроллеру выбирать значения, похожие на уже знакомые значения, что называется адресацией по контенту. Для каждой головки контроллер производит ключевой вектор , который сравнивается с каждой строкой , используя меру сходства. В этой работе авторы используют косинус меру сходства, которая определяется следующим образом:
Весовой вектор контента позволяет контроллеру выбирать значения, похожие на уже знакомые значения, что называется адресацией по контенту. Для каждой головки контроллер производит ключевой вектор , который сравнивается с каждой строкой , используя меру сходства. В этой работе авторы используют косинус меру сходства, которая определяется следующим образом:

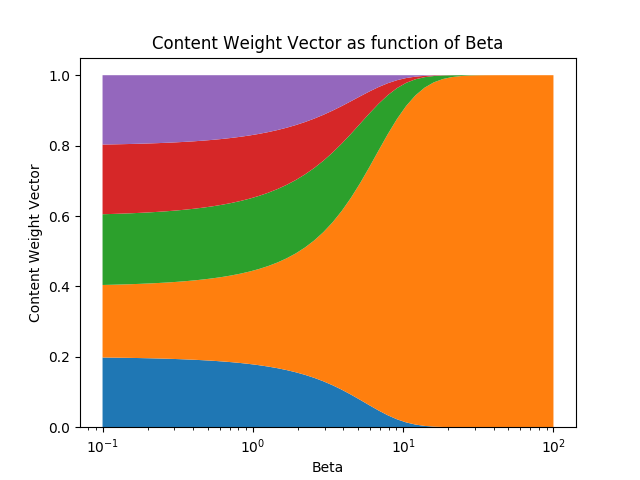
Положительный скалярный параметр  , который называется прочностью ключа, используется для определения, насколько сконцентрирован должен быть весовой вектор контента. При малых значениях беты весовой вектор будет размытым, а при больших значениях беты весовой вектор будет сконцентрирован на наиболее похожей строке в памяти. Для визуализации, если ключ и матрица памяти производят вектор подобия
, который называется прочностью ключа, используется для определения, насколько сконцентрирован должен быть весовой вектор контента. При малых значениях беты весовой вектор будет размытым, а при больших значениях беты весовой вектор будет сконцентрирован на наиболее похожей строке в памяти. Для визуализации, если ключ и матрица памяти производят вектор подобия [0.1, 0.5, 0.25, 0.1, 0.05], вот как изменяется весовой вектор контента в зависимости от беты.
Весовой вектор контента можно вычислить следующим образом:

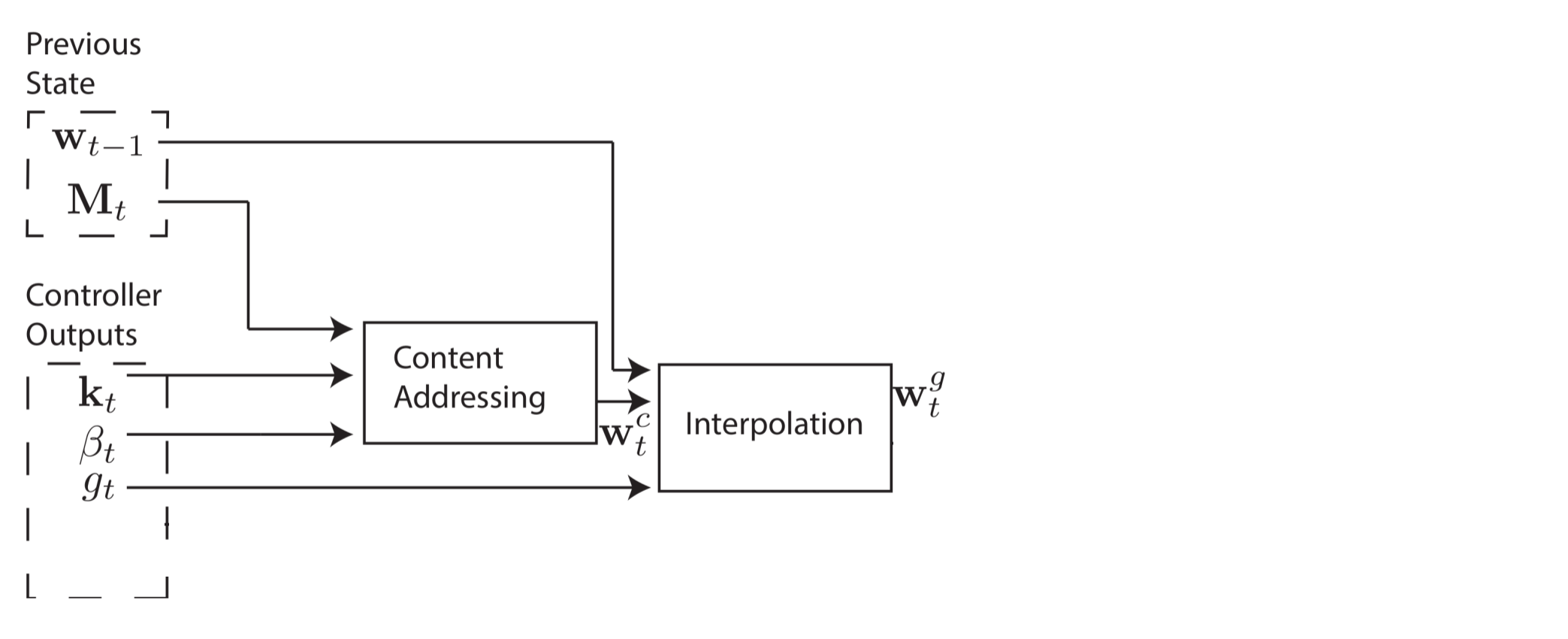
Однако в некоторых случаях мы можем захотеть прочитать из конкретных ячеек памяти, а не прочитать конкретные значения в памяти. Например, авторы показывают функцию  . В этом случае нас не волнуют конкретные значения x и y, только то, что они постоянно считывают из одних и тех же ячеек в памяти. Это называется адресация по ячейкам, и для её реализации нам нужны ещё три этапа. На втором этапе скалярный параметр
. В этом случае нас не волнуют конкретные значения x и y, только то, что они постоянно считывают из одних и тех же ячеек в памяти. Это называется адресация по ячейкам, и для её реализации нам нужны ещё три этапа. На втором этапе скалярный параметр  , который называется вентилем интерполяции (interpolation gate), смешивает весовой вектор контента с весовым вектором предыдущего шага времени
, который называется вентилем интерполяции (interpolation gate), смешивает весовой вектор контента с весовым вектором предыдущего шага времени  для производства вентильного весового вектора
для производства вентильного весового вектора  . Это позволяет системе понять, когда использовать (или игнорировать) адресацию по контенту.
. Это позволяет системе понять, когда использовать (или игнорировать) адресацию по контенту.

Мы бы хотели, чтобы контроллер мог смещать фокус на другие строки. Предположим, что одним из системных параметров ограничен диапазон допустимых смещений. Например, внимание головки может сместиться вперёд на одну строку (+1), остаться без изменений (0) или сместиться на строку назад (-1). Произведём сдвиги по модулю , так что сдвиг вперёд с нижнего ряда памяти перемещает внимание головки на верхнюю строчку, также как сдвиг назад с верхней строчки перемещает внимание головки на нижнюю строчку. После интерполяции каждая головка выдаёт нормированное взвешивание сдвига  и происходит следующее свёрточное перемещение для расчёта веса сдвига
и происходит следующее свёрточное перемещение для расчёта веса сдвига  .
.

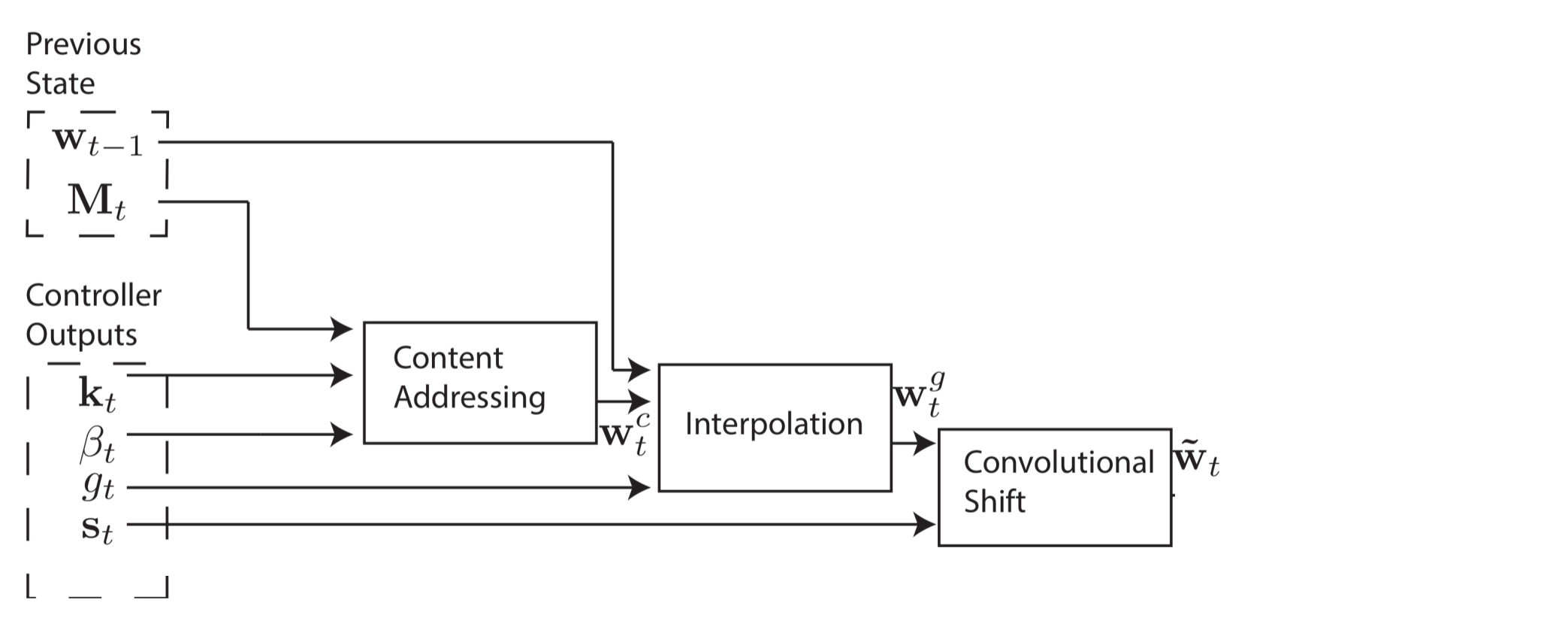
Четвёртая и окончательная стадия, уточнение (sharpening), используется чтобы предотвратить размывание веса сдвига . Для этого требуется скаляр  .
.

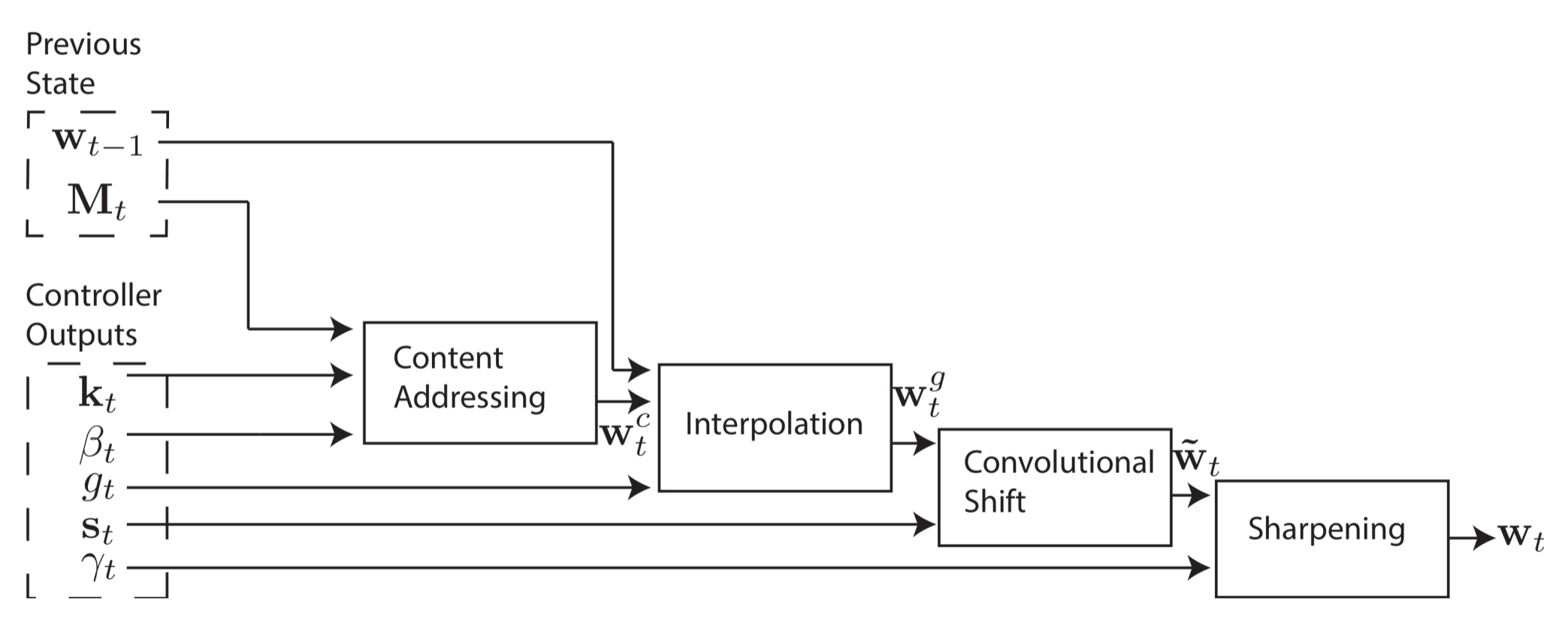 Теперь готово! Можно вычислить весовой вектор, который определяет адреса для чтения и записи. Что ещё лучше, система полностью дифференцируема и поэтому обладает сквозной обучаемостью end-to-end.
Теперь готово! Можно вычислить весовой вектор, который определяет адреса для чтения и записи. Что ещё лучше, система полностью дифференцируема и поэтому обладает сквозной обучаемостью end-to-end.
Эксперименты и результаты
Копирование
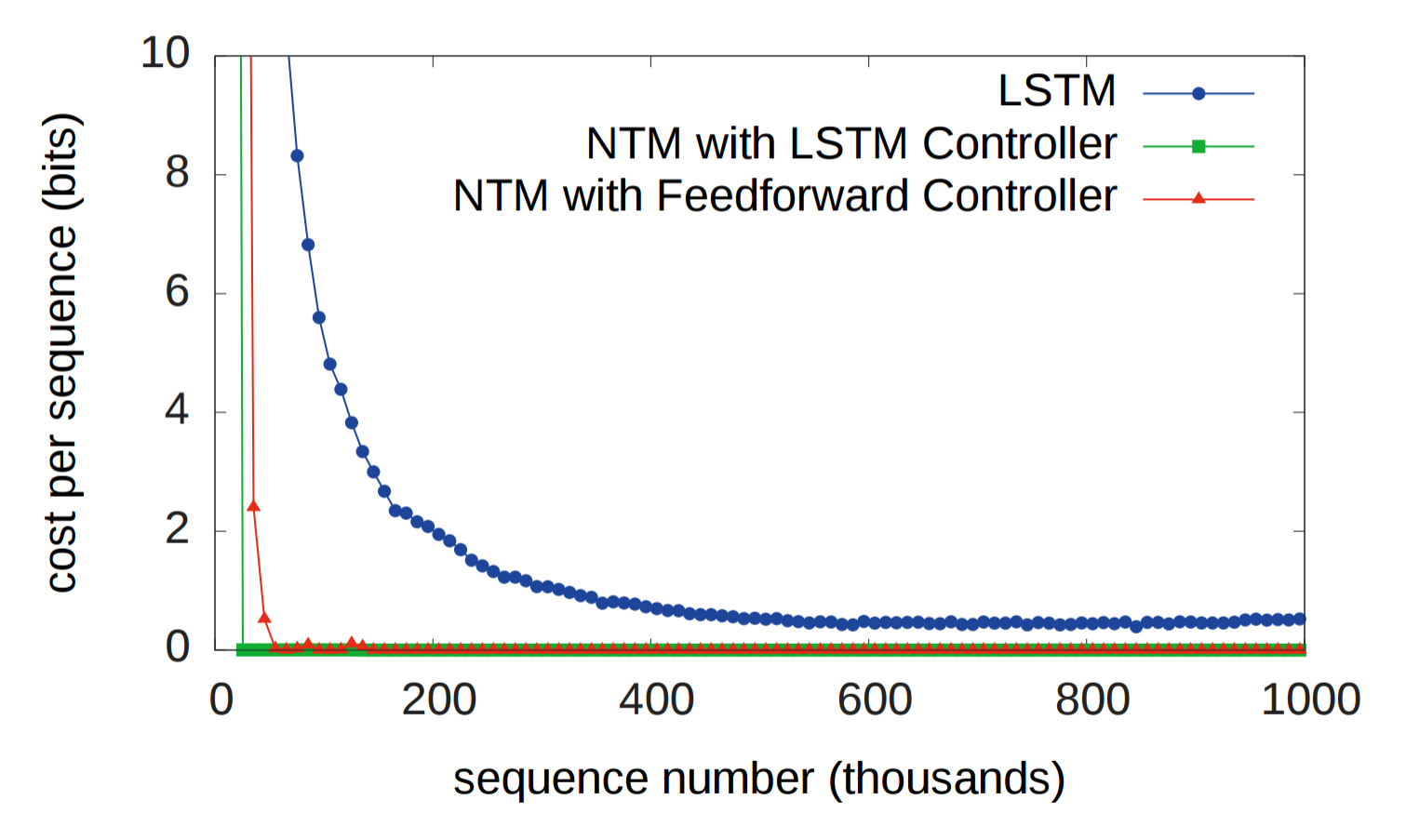
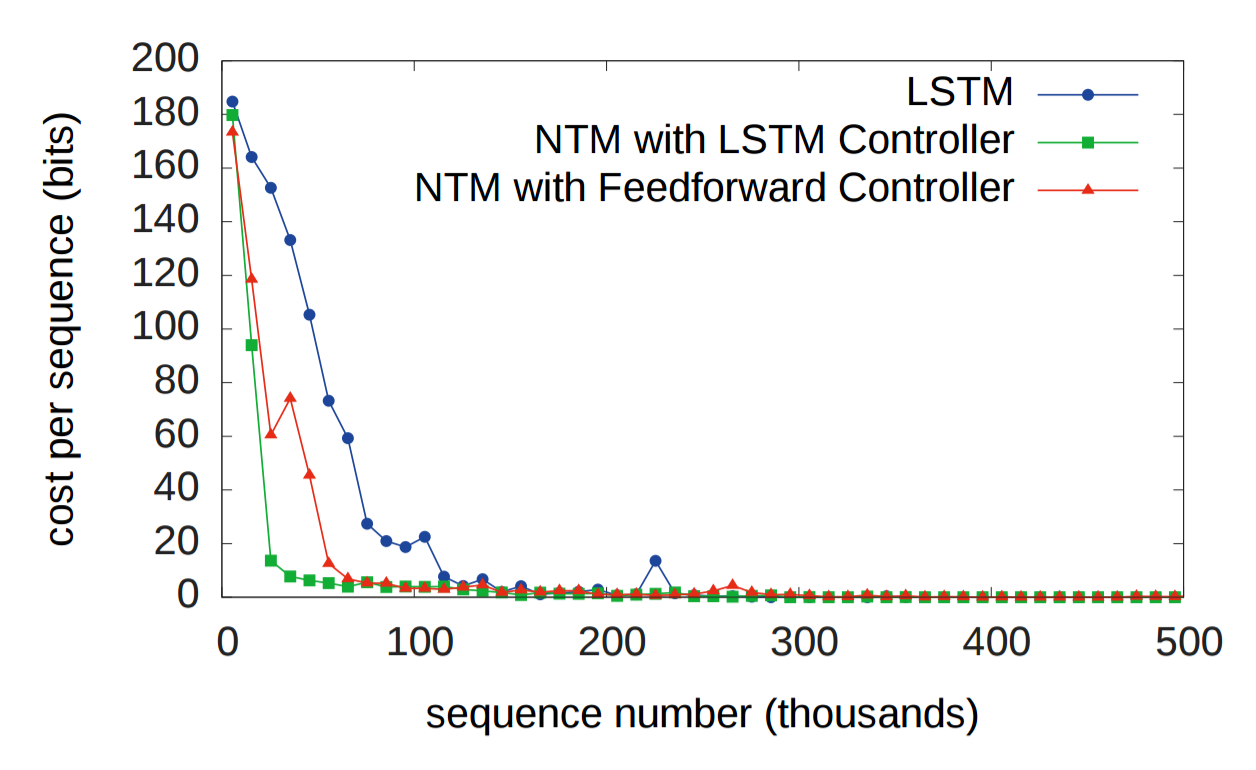
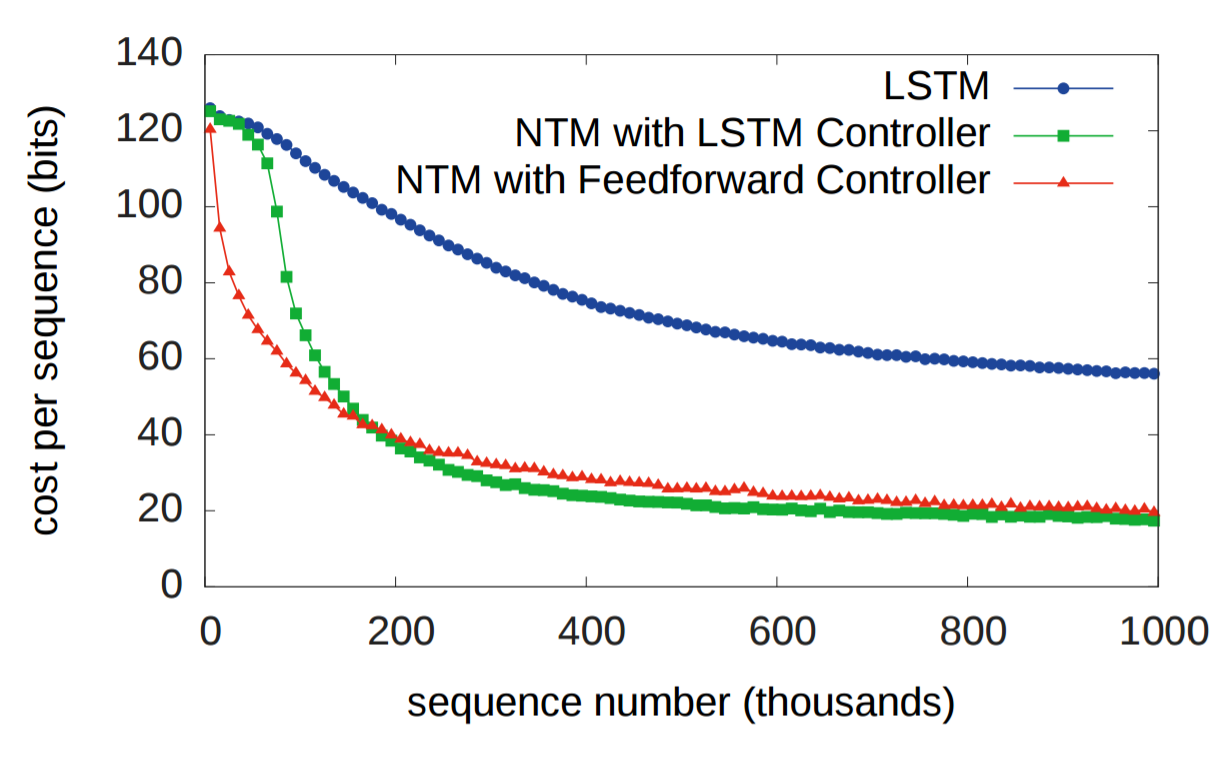
Исторически RNN страдали от неспособности надолго запоминать информацию. Первый эксперимент призван проверить, улучшит ли ситуацию наличие внешней системы памяти. В эксперименте трём системам дана последовательность случайных восьмибитных векторов, за которым следует флаг разделителя данных, а затем их просят повторить последовательность входных данных. LSTM сравнивается с двумя NTM, одна из которых использует контроллер LSTM, а другая — упреждающий контроллер (feedforward controller). На графике внизу «стоимость каждой последовательности» означает количество бит, которые система неправильно воспроизвела во всей последовательности. Как видите, обе архитектуры NTM значительно превосходят LSTM.
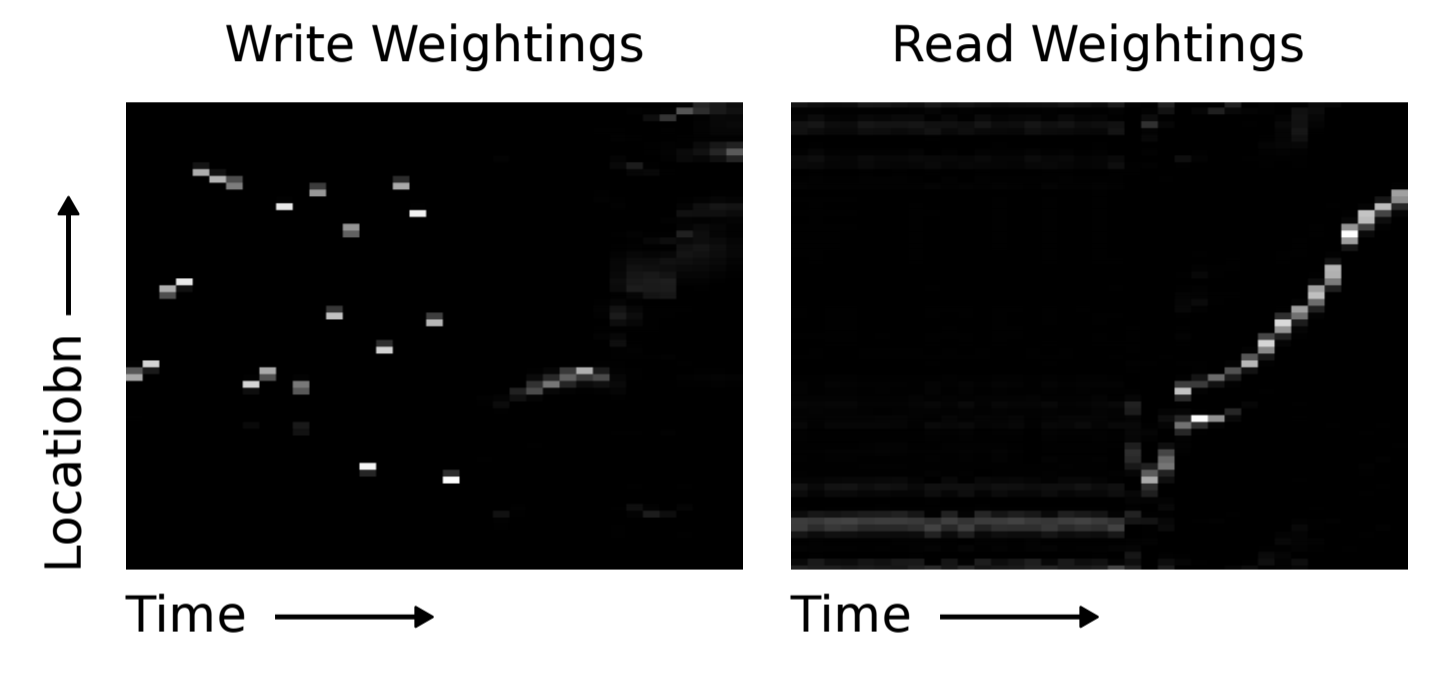
Очевидно, и LSTM и NTM обучились некоему рудиментарному алгоритму копирования. Исследователи представили в графическом виде схему, как NTM выполняет чтение и запись (показана внизу). Белый цвет соответствует весу 1, а чёрный — весу 0. Иллюстрация явно показывает, что веса для ячеек памяти были чётко сфокусированы.

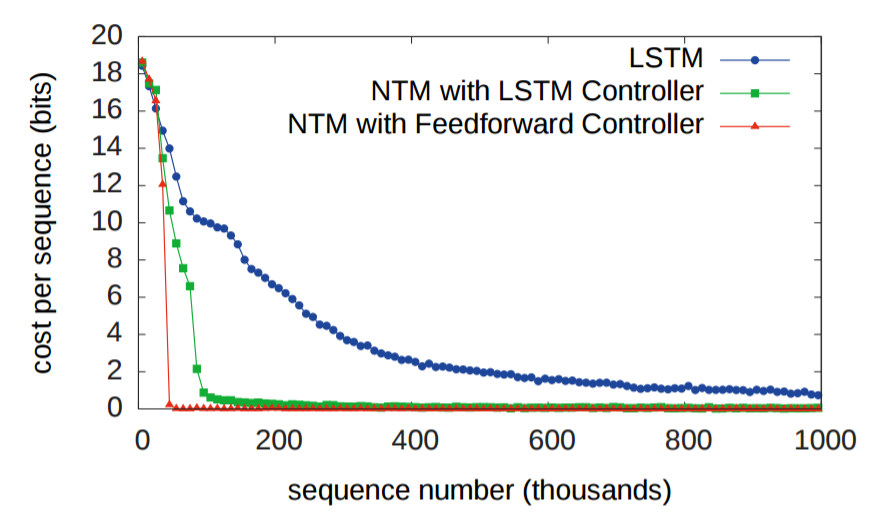
Далее исследователи хотели узнать, насколько хорошо алгоритмы LSTM и NTM могут масштабироваться для более длинных последовательностей, чем все входные данные, на которых они обучались. Обучение происходило на последовательностях от 1 до 20 случайных векторов, так что LSTM и NTM сравнили на последовательностях длиной 10, 20, 30, 50 и 120 векторов. Следующие две иллюстрации нуждаются в некоторым пояснении. Там по восемь блоков. Четыре верхних блока соответствуют последовательностям 10, 20, 30 и 50. В каждом блоке колонка из восьми красных и синих квадратиков используется для визуализации значений 1 и 0. Яркие цветные квадратики соответствуют значениям между 0.0 и 1.0.
Производительность копирования LSTM на последовательностях длиной 10, 20, 30, 40
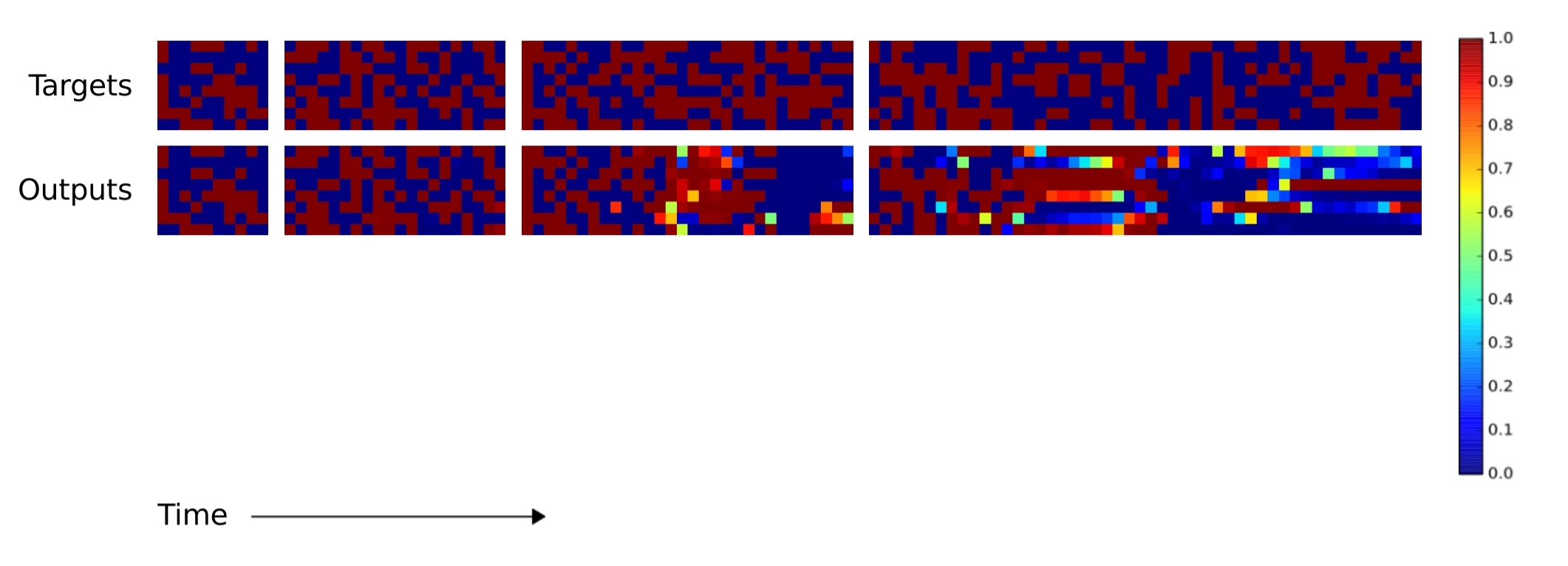
Производительность копирования NTM на последовательностях длиной 10, 20, 30, 40

Как можете заметить, NTM выдаёт гораздо меньше ошибок на длинных последовательностях. Я не смог найти в научной работе, какая именно NTM (контроллер RNN или упреждающий контроллер) использовался при генерации этого изображения вверху. Разница между NTM и LSTM становится ещё более выраженной при увеличении последовательности до 120 векторов, как показано ниже.
Производительность копирования LSTM на последовательности длиной 120
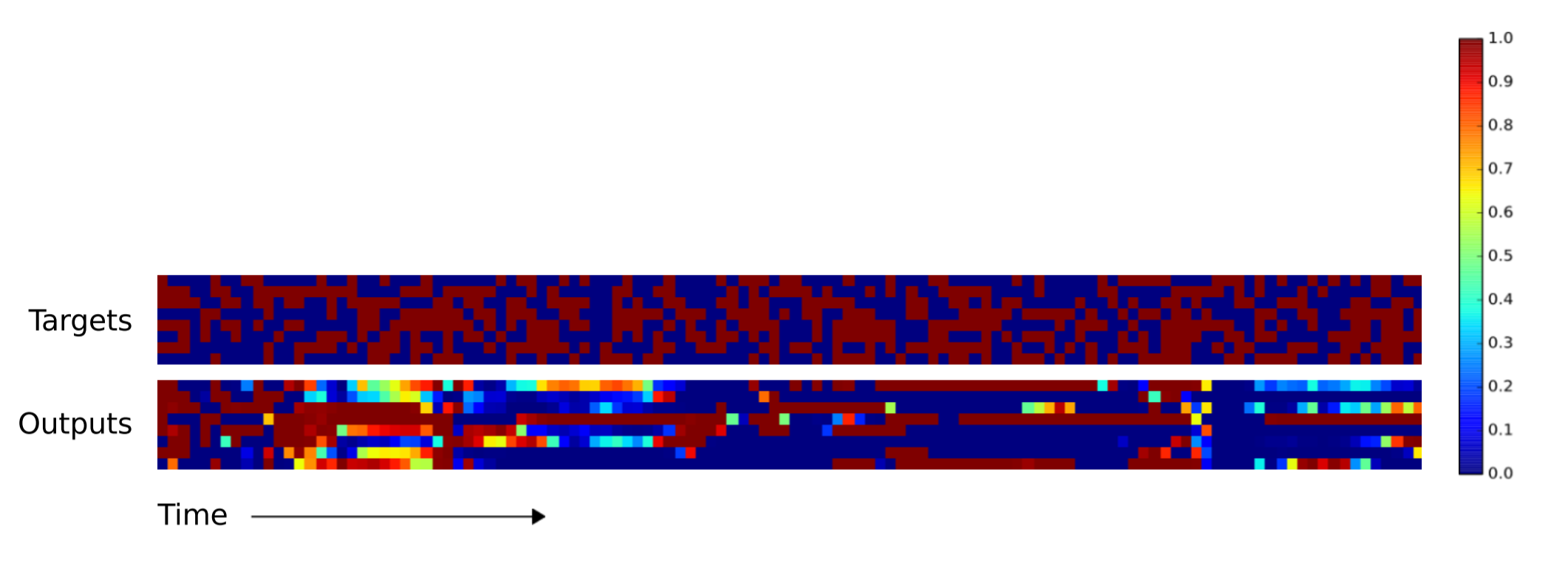
Производительность копирования NTM на последовательности длиной 120
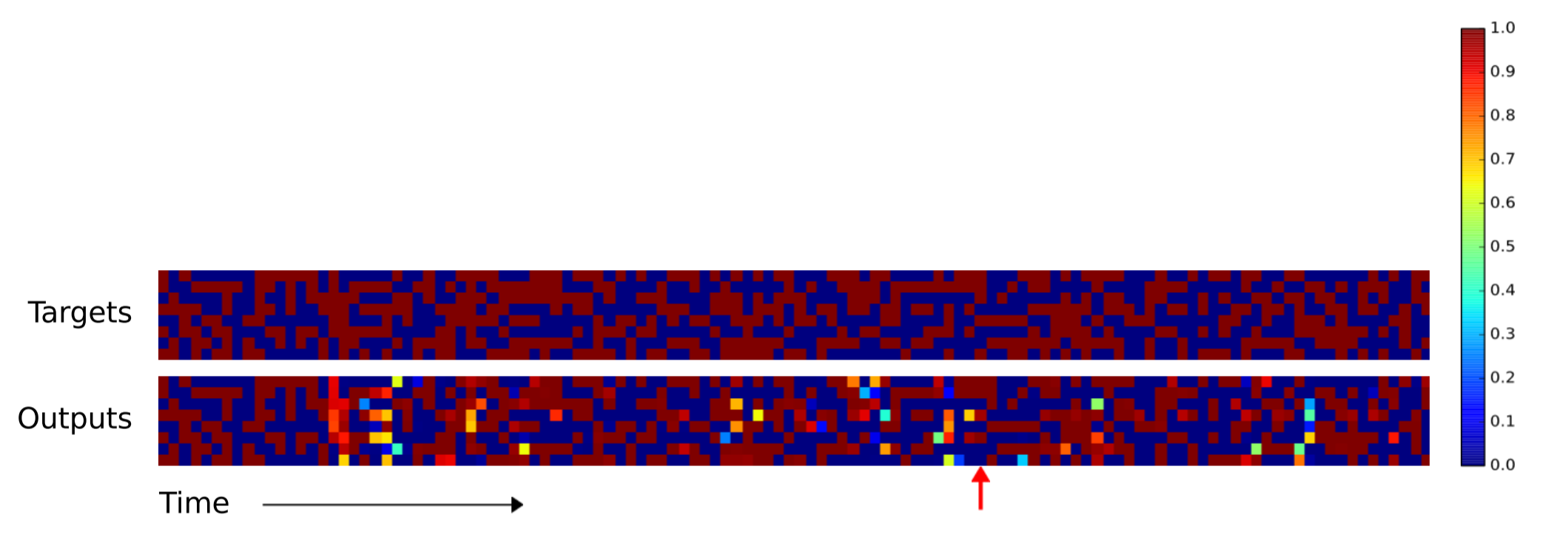
Повторное копирование
Второй эксперимент должен был определить, сможет ли NTM обучиться вложенной функции (в данном случае, вложенному циклу). Кроме последовательности, в NTM передавали также скалярное значение, соответствующее количеству раз, которое NTM должна выдать скопированную входную последовательность. Ожидаемо обе NTM превзошли LSTM.
Как и раньше, LSTM затруднилась обобщить алгоритм повторения копирования, а NTM — нет.

Ассоциативное восстановление данных
Третий эксперимент должен был определить, способна ли NTM обучиться косвенному обращению, то есть когда один элемент данных указывает на другой. Авторы подали в качестве входных данных список элементов, а затем запрашивали один элемент из списка, ожидая возвращения следующего элемента из списка. Авторы отмечают, что превосходство NTM с упреждающим контроллером над NTM с LSTM-контроллером указывает на то, что память NTM — лучшая система хранения данных, чем внутреннее состояние LSTM.
И снова NTM превзошли LSTM при обобщении большого количества элементов в списке.
Динамические N-граммы
Четвёртая задача была разработана для определения, может ли NTM обучиться апостериорным прогнозируемым распределениям. Исследователи создали N-граммы (последовательности из N элементов), которые при получении предыдущих элементов последовательности вычисляют некое распределение вероятностей для следующего элемента последовательности. В данном случае исследователи использовали бинарные 6-граммы. Оптимальным решением для способности агента предсказывать следующий бит будет решение в аналитическом виде, и обе NTM превзошли LSTM, приблизившись к оптимальной оценке.

Приоритетная сортировка
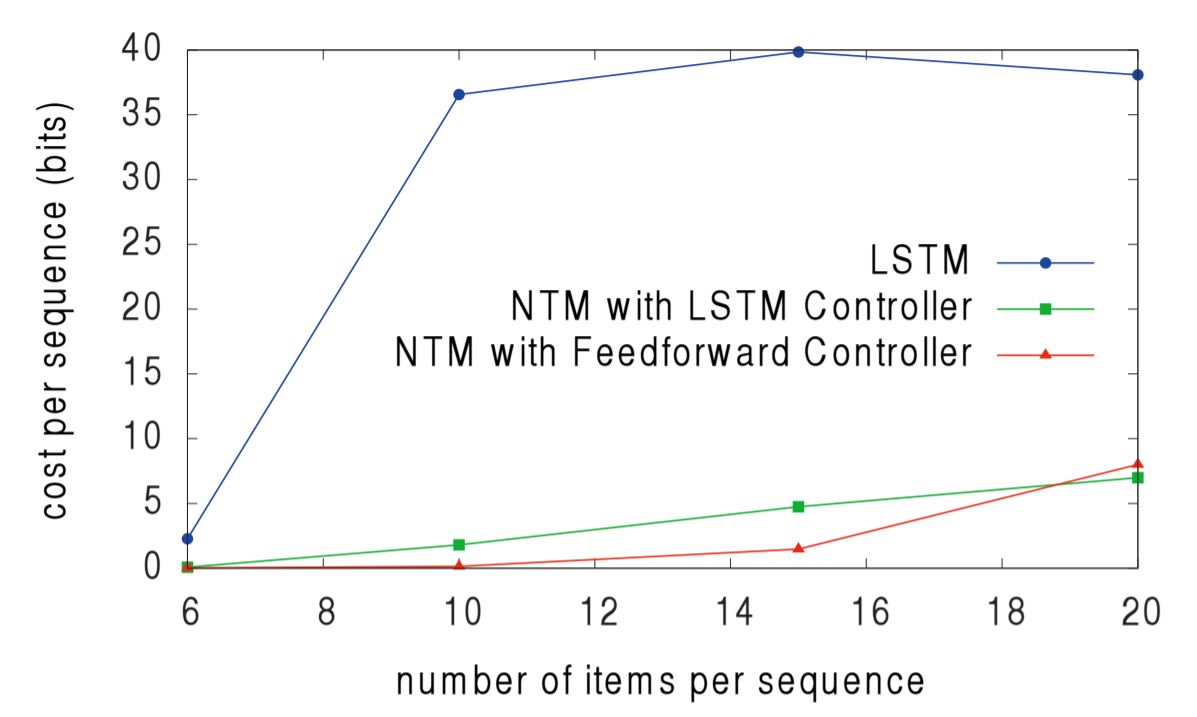
Пятый и последний эксперимент проверял, может ли NTM обучиться сортировать данные. Двадцати бинарным векторам были присвоены скалярные «рейтинги приоритета», равномерно выбранные из диапазона [-1, 1], а задачей каждой системы было вернуть 16 векторов с наивысшим приоритетом из входных данных. Изучив операции записи и чтения в памяти NTM, учёные обнаружили, что NTM с помощью приоритетов приблизительно оценивает, в каком порядке должны храниться вектора. Затем для выдачи 16 векторов с наивысшим приоритетом ячейки памяти считываются последовательно. Это видно по последовательности операций запими и чтения из памяти.
И ещё раз NTM превзошли LSTM.
Резюме
- Нейробиологические модели рабочей памяти мозга и цифровая компьютерная архитектура предполагают, что функциональность системы может зависеть от наличия внешней памяти.
- Нейронные сети, дополненные внешней памятью, предлагают возможный ответ на ключевой критический аргумент в сторону коннекционизма, что нейронные сети не способны привязывать значения к конкретному местонахождению в структурах данных (связывание переменных).
- Размытые операции чтения и записи являются дифференцируемыми. Это критически важно для того, чтобы контролллер обучился, как использовать память.
- Результаты пяти тестов показали, что NTM могут превзойти LSTM и обучиться более обобщённым алгоритмам, чем LSTM.
Примечания
Буду благодарен за любые отзывы. Если я где-то допустил ошибку или у вас имеется предложение, пишите мне или комментируйте на Reddit и HackerNews. В ближайшем будущем я собираюсь создать список почтовой рассылки (спасибо, Бен) и интегрировать RSS (спасибо, Юрий).
Телеграм: t.me/ainewsline
Источник: habrahabr.ru