Нейросеть научили предсказывать наводнения по Flickr
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-03-11 23:48

Британские ученые показали, что семантический анализ пользовательского контента в социальных сетях позволяет предсказывать стихийные бедствия. Статья опубликована в журнале PLOS ONE.
Современные системы предупреждения об опасности стихийных бедствий во многом основаны на работе специализированного оборудования и профессиональных аналитиков. В то же время существуют сервисы, с помощью которых все желающие в реальном времени могут сообщить властям об изменении некоторых климатических показателей, например количества осадков или уровня водоемов. Кроме того, ранее Геологическая служба США (USGS) признала, что анализ пользовательского контента и геопозиционирования постов в Twitter может быть хорошим дополнением к высокотехнологичным методам, выступая в роли «социального барометра».
Прошлые исследования показали, что схожим образом может использоваться сервис для обмена фотографиями Flickr. Так, динамика публикаций, а также характер их описания и тегов коррелировали с колебаниями атмосферного давления в штате Нью-Джерси накануне и во время урагана «Сэнди» в 2012 году, что теоретически позволяло прогнозировать изменения погоды в пострадавших районах. Тем не менее, существующие методы анализа контента в соцсетях часто зависят от ключевых слов и фраз, соответствующих конкретному типу или названию стихийного бедствия («наводнение», «Катрина»). По мнению авторов новой работы, такой подход может быть эффективен при решении оперативных задач, но его возможности сильно ограничены.
Чтобы восполнить пробел, ученые из Уорикского университета разработали алгоритм для семантического анализа тегов, который тренировали с помощью метода матрицы корреляции деконструированных каскадов (Deconstructed Cascade Correlation Matrix). Этот метод позволяет обучать искусственную нейросеть анализу целевой проблемы, «замораживая» весовые коэффициенты скрытых блоков на входе, — в результате оценка остается относительно стабильной несмотря на изменчивость параметров. Кроме того, DCCM предусматривает возможность вертикальной и горизонтальной деконструкции переменных и работу онлайн. Метод является междисциплинарным и применяется, в том числе, для прогнозирования погоды.
Команда обучала новый алгоритм на фотографиях и видеороликах из пакета Yahoo Flickr Creative Commons 100M (YFCC100M), которые были опубликованы в период с апреля 2004 по август 2014 года. На входе компьютер анализировал материалы по четырем общим («природа», «пейзаж», «река», «вода») и двум сводным («RW» — от «река» и «вода», и «NL» — от «природа» и «пейзаж») тегам, каждый из которых на выходе был связан с специфическими («потоп», «наводнение», «пойма») тегами без указания атрибутов веса. Сопоставление тегов с риском стихийного бедствия проводилось на основании трех параметров: масштаба события, количества публикаций за пять суток до пика наводнения и спустя пять суток, а также шаблона поведения в пиковый период наводнения.
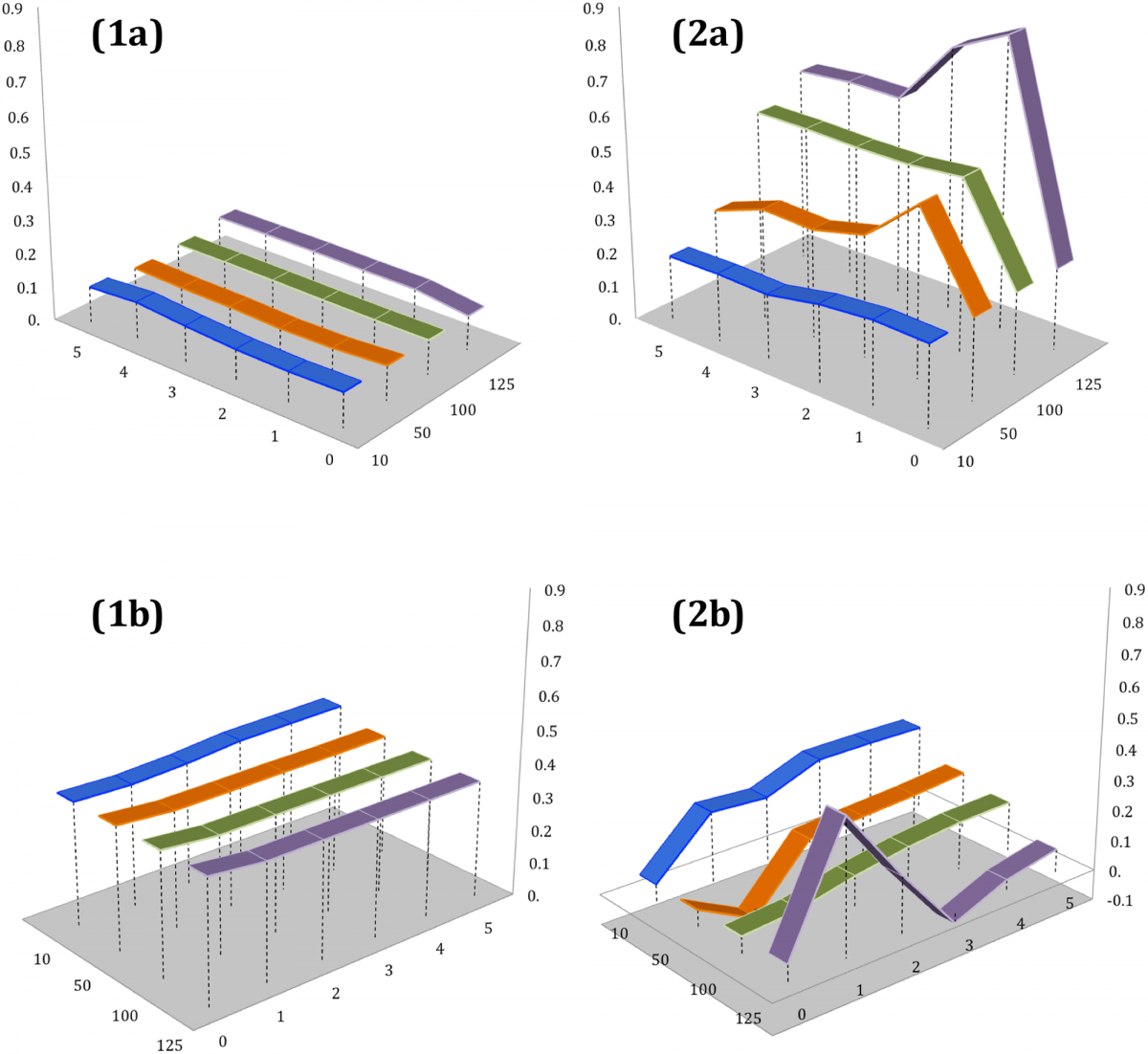
Результаты показали, что появление во Flickr тегов, связанных с наводнениями, статистически значимо коррелирует с показателем встречаемости специфических («вода», «река») и сводных («RW») тегов. В то же время угроза стихийного бедствия оказалась почти не связана с ростом числа таких тегов, как «пейзаж» и «природа». Примечательно, что теги «вода» и «река» заняли промежуточное положение между маркерами бедствия и тематикой природы и примерно одинаково коррелировали с остальными тегами. Сводные теги чаще встречались за один день до пикового периода наводнения, при этом по мере приближения к пику тег «RW» использовался все чаще, а тег «NL», напротив, резко терял популярность.
Кроме того, ученые ретроспективно проверили способность модели предсказывать наводнение по числу публикаций в день за пять суток до события. Наиболее сильной корреляция оказалась для тегов «RW» и «вода». Так, на угрозу бедствия указывал рост числа загрузок с тегом «RW» до 100 и более за пять дней до наводнения с последующим плавным падением показателя. При увеличении количества публикаций с тегом «RW» до 125 и более в день корреляция увеличивалась; схожая динамика оказалась характерна для роста загрузок с тегом «вода» до 125 и более в день с пиком за три дня до наводнения и последующим снижением показателя.
По мнению авторов, их исследование указывает на то, что социальные сети являются ресурсом, который может использоваться в сочетании с профессиональными источниками метеорологичесикх данных. В будущем такие системы предупреждения, основанные на анализе пользовательского контента, могли бы обладать беспрецедентными точностью и эффективностью, считают ученые.
Поведение пользователей социальных сетей становится объектом изучения не впервые. Ранее психологи связали активность на таких площадках с чувством социальной изоляции, а физики сравнили распространение мемов в социальных сетях со статистическими моделями, которые описывают эпидемии и финансовые рынки.
Телеграм: t.me/ainewsline
Источник: naked-science.ru