Глубинное обучение по особенностям заголовка и содержимого статьи для преодоления кликбейта
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-03-27 22:03
Когда-то в прошлом я написал статью о выявлении кликбейта. Та статья получила хорошие отклики, а также много критики. Некоторые сказали, что нужно учитывать содержимое сайта, другие просили больше примеров из разных источников, а некоторые предложили попробовать методы глубинного обучения.
В этой статье я постараюсь решить эти вопросы и вывести выявление кликбейта на новый уровень.
Не бывает бесплатной еды информации
Просматривая собственную ленту Facebook, я обнаружил, что кликбейт нельзя классифицировать просто по заголовку. Он зависит ещё от контента. Если контент сайта хорошо соответствует заголовку, его не следует классифицировать как кликбейт. Однако очень сложно определить, что такое настоящий кликбейт.
Посмотрим некоторые реальные примеры на Facebook.
| 1. |  |
| 2. |  |
| 3. |  |
| 4. |  |
Что вы думаете теперь? Какие из них вы бы классифицировали как кликбейт, а какие нет? Стало сложнее после удаления информации об источнике?
Мои предыдущие модели на базе TF-IDF и Word2Vec классифицируют первые три как кликбейт, а может и четвёртую тоже. Однако среди этих примеров только два кликбейта: второй и третий. Первый пример — это статья, которую распространяет CNN, а четвёртая из The New York Times. Это два авторитетных источника новостей, независимо от того, что говорит Трамп! :)
Если Facebook/Google будут учитывать только заголовки, то они заблокируют все вышеперечисленные примеры в ленте новостей или результатах поиска.
Так что я решил классифицировать не только по заголовку, но ещё и по содержимому сайта, который открывается по ссылке, и по некоторым основным особенностям, заметным на этом сайте.
Начнём со сбора данных.
Сбор данных
В этот раз я извлекал данные из публично доступных страниц Facebook. Макс Вульф написал отличную статью, как это делается. Питоновские скрипты доступны здесь. Этот скрапер позволяет извлекать данные с публичных страниц Facebook, которые доступны для просмотра без авторизации на сайте.Я извлёк данные со следующих страниц:
- Buzzfeed
- CNN
- The New York Times
- Clickhole
- StopClickBaitOfficial
- Upworthy
- Wikinews
Посмотрим, какие данные скрапер Макса Вульфа извлёк со страницы Clickhole.
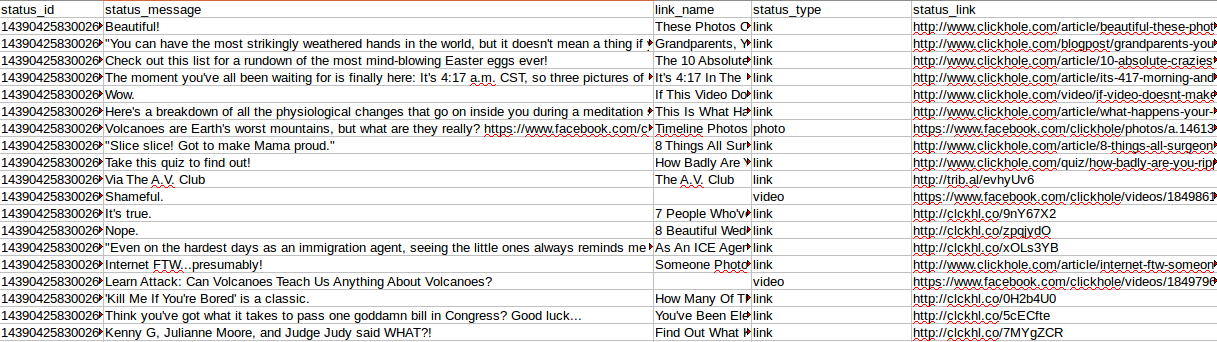
Здесь интересны следующие поля:
- link_name (заголовок опубликованного URL)
- status_type (есть ли ссылка, фотография или видео)
- status_link (реальный URL)
Я отфильтровал статусы status_type==link, потому что интересуют только опубликованные URL, где есть какой-то текстовый контент.
Затем объединил собранные данные в два файла CSV: Buzzfeed, Clickhole, Upworthy и Stopclickbaitofficial попали в clickbaits.csv, а остальное — в non_clickbaits.csv.
Обработка данных и генерация признаков
Когда данные собраны и сохранены в два разных файла, пришло время сбора документов html по всем ссылкам и сохранения всех данных как файлов pickle. Для этого я создал очень простой скрипт Python: Я очень строго подошёл к извлечению html, и в случае любого сбоя возвращался ответ “no html”. Для экономии своего времени и ускорения сбора данных использовал Parallel в Joblib. Обратите внимание, что нужно включить поддержку куков для краулинга сайтов вроде The New York Times.
Я очень строго подошёл к извлечению html, и в случае любого сбоя возвращался ответ “no html”. Для экономии своего времени и ускорения сбора данных использовал Parallel в Joblib. Обратите внимание, что нужно включить поддержку куков для краулинга сайтов вроде The New York Times.Поскольку на моём компьютере 64 ГБ ОЗУ, я делал всё в памяти. Вы можете легко модифицировать код, чтобы сохранять результаты построчно в CSV и освободить много памяти.
Следующим шагом было сгенерировать признаки из этих данных HTML.
Для генерации признаков использовал BeautifulSoup4 и goose-extractor.
Сгенерированные признаки включали в себя:
- Размер HTML (в байтах)
- Длина HTML
- Общее количество ссылок
- Общее количество кнопок
- Общее количество полей ввода (inputs)
- Общее количество ненумерованных списков
- Общее количество нумерованных списков
- Общее число тегов H1
- Общее число тегов H2
- Длина текста во всех найденных тегах H1
- Длина текста во всех найденных тегах H2
- Общее количество изображений
- Общее количество тегов html
- Количество уникальных тегов html
Посмотрим на некоторые из этих признаков:
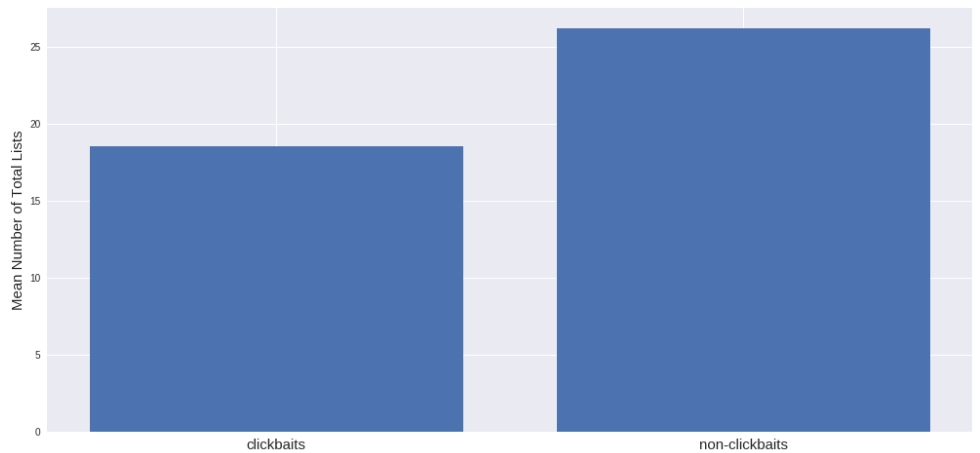
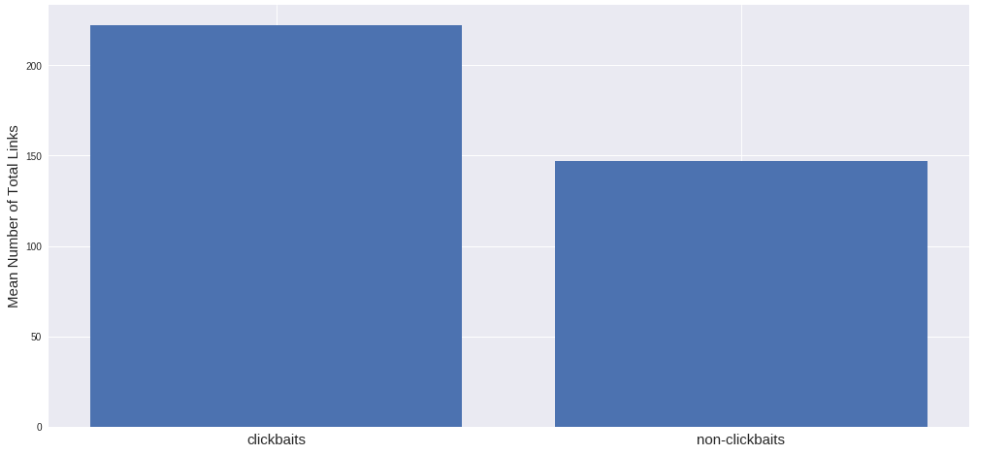
Похоже, что среднее количество списков больше на сайтах без кликбейта, чем на сайтах с кликбейтом. Я думал, что будет наоборот, но данные убеждают в обратном. Ещё выходит, что на сайтах с кликбейтом больше ссылок:
Поначалу я предположил, что на сайтах с кликбейтом будет больше изображений. И да, я был прав:
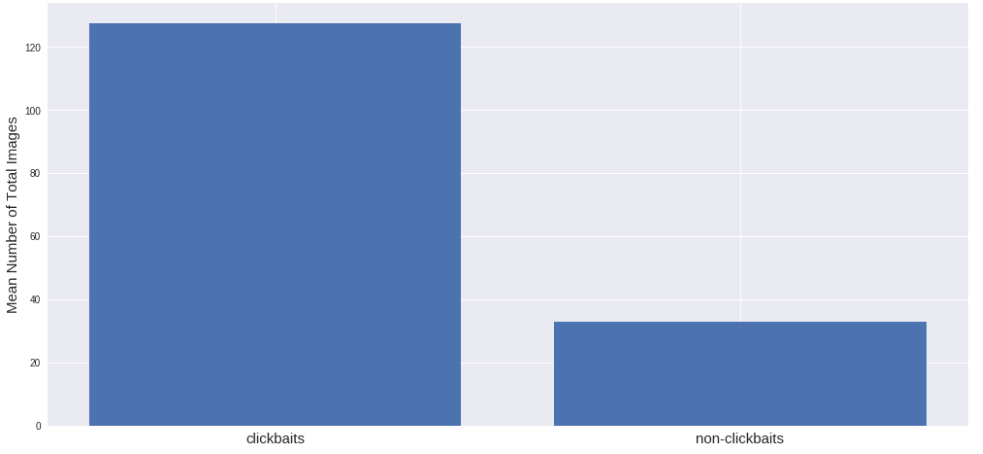
Вот как они привлекают людей. Картинки в статьях — это как червяки для рыб :)
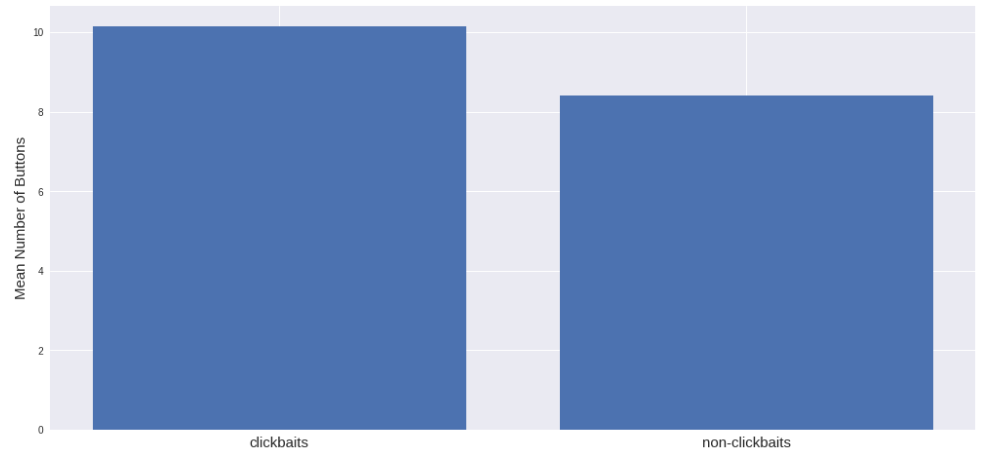
Количество интерактивных элементов, например, кнопок, почти не отличается:
При работе с текстовыми данными принято составлять облака слов :), так что вот они.
| Облако слов заголовков для кликбейта |  |
 |
В конце концов, текстовые признаки включают в себя:
- Весь текст H1
- Весь текст H2
- Мета-описание
Конечно, вы можете извлечь с веб-страниц больше текстовых и нетекстовых признаков, но я ограничил себя вышеприведённым списком. На этом этапе извлечения текстовых данных с веб-страниц я также удалил доменные имена из текстовых данных соответствующих веб-страниц, чтобы избежать какого-либо переобучения.
Я заметил, что текст с Buzzfeed часто содержит слова «Сообщите о проблеме спасибо», так что удалил их тоже. Также создал специальный список стоп-слов для веб-страниц:

В опрелелённый момент данные стали меня удовлетворять и появилась уверенность, что модель не переобучится на этих данных. Тогда я начал конструктировать некоторые крутые модели глубинного обучения. Но сначала посмотрим на окончательные данные:

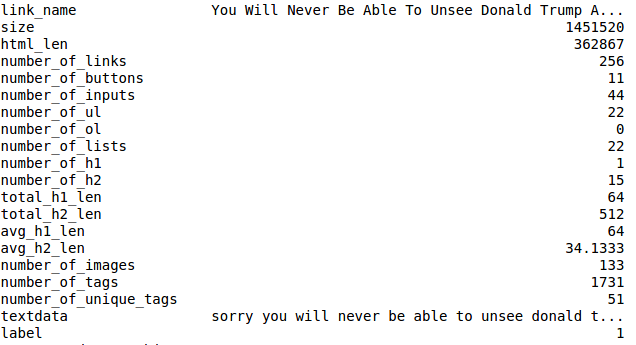
В итоге я закончил примерно с 50 000 образцами. Примерно 25 000 для кликбейтерских сайтов, примерно столько же для остальных.
Начнём строить модели!
Модели глубинного обучения
Перед началом построения моделей глубинного обучения я разделил данные на две части, используя расслоение по метке (1=кликбейт, 0=не_кликбейт). Назовём это тестовыми данными, они состоят примерно из 2500 примеров из каждой выборки. Тестовые данные были оставлены в неприкосновенности, их использовали только для оценки модели. Настоящая модель была построена и проверена на остальных 90% данных — данных для обучения.
Сначала я попробовал простую модель LSTM с встроенным слоем, который преобразует положительные индексы в векторы плотности фиксированного размера. За ним следовали два плотных слоя (Dense) с отсевом (Dropout) и пакетной нормализацией (Batch Normalization):

Простая сеть показывает точность 0,904 на наборе валидации после нескольких периодов, а также точность 0,884 на тестовом наборе. Я расценил это как бенчмарк и постарался улучшить показатели. У нас всё ещё есть признаки контента, которые можно добавить! Возможно, это улучшит точность и на наборе валидации, и на тестовом наборе.
В следующей модели без изменения плотных слоёв, за которыми следуют слои LSTM, я добавил признаки текстового контента и осуществил их слияние перед проходом через плотные слои:
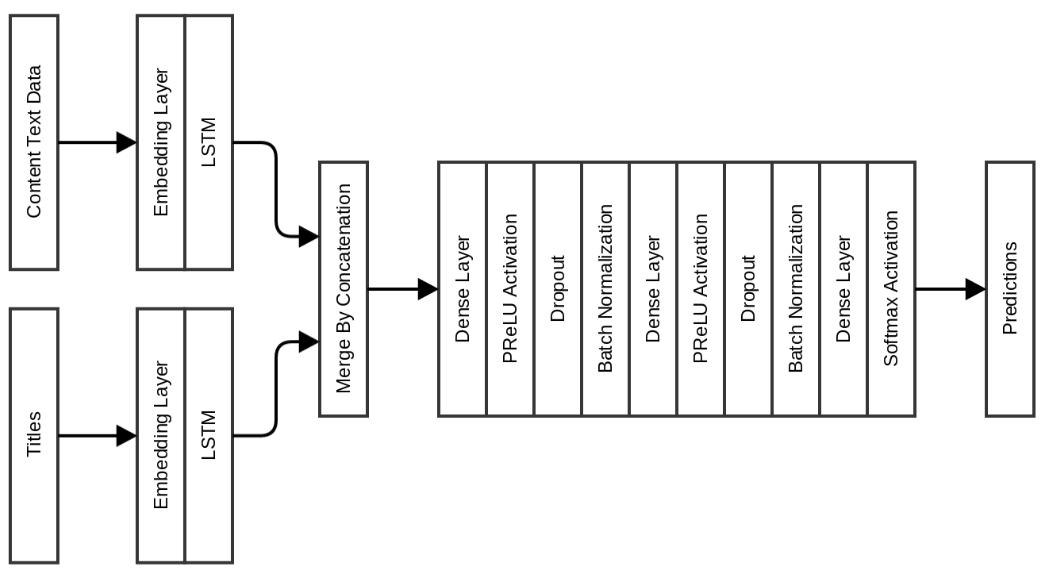
Такая модель сразу же улучшила показатели на 7% по бенчмаркам! Точность валидации выросла до 0,975, а точность на тестовом наборе — до 0,963. Недостаток этих моделей в том, что требуется много времени для обучения, поскольку необходимо усвоить встраивание. Чтобы преодолеть это, следующие модели я делал со встраиванием GloVe как инициализацией для встроенных слоёв. Было использовано 840 млрд 300-мерных вставок GloVe, обученных на данных Common Crawl. Эти вставки можно скачать здесь.
Предыдущие модели с распределённой плотностью по времени (time distributed dense), как рассказывалось в моей статье о дублирующихся постах в Quora. Вставки были инициализированы GloVe:
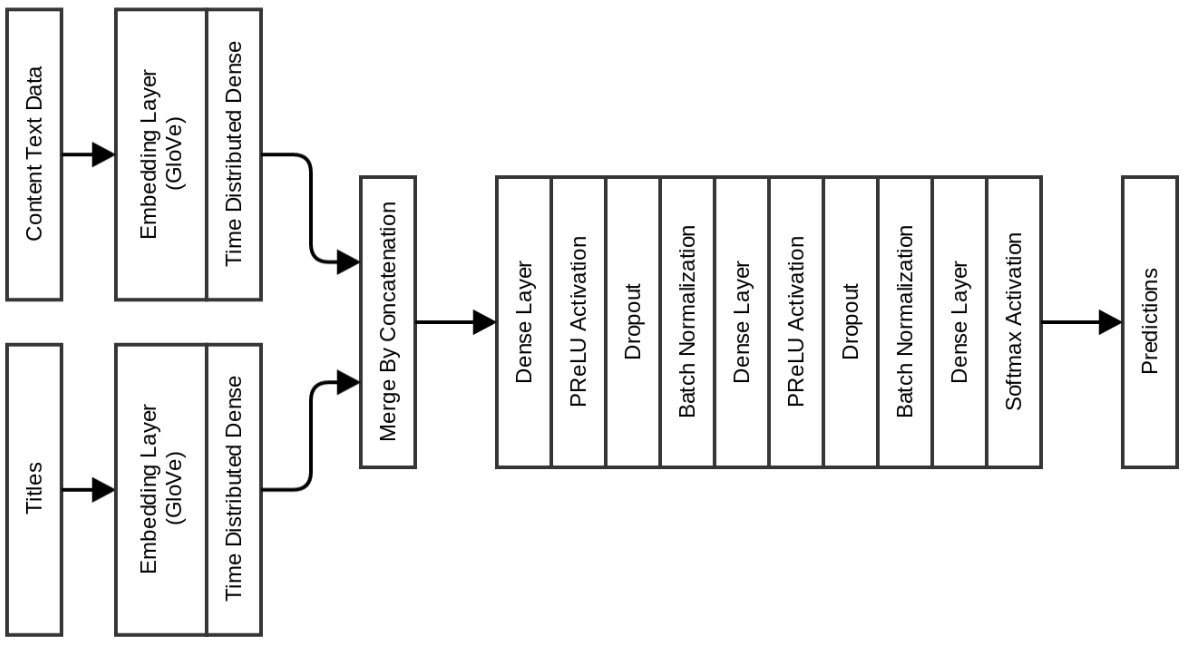
Модель показывает точность валидации 0,977, а точность на тестовом наборе — 0,971. Преимущество использования этой модели в том, что время обучения на период выходит менее 10 секунд, в то время как предыдущей модели требовалось 120-150 секунд на период.
Так что если вам нужна модель быстрой обучаемой нейросети для определения кликбейта, выбирайте одну из вышеупомянутых. Если нужна более точная модель, см. ниже :)
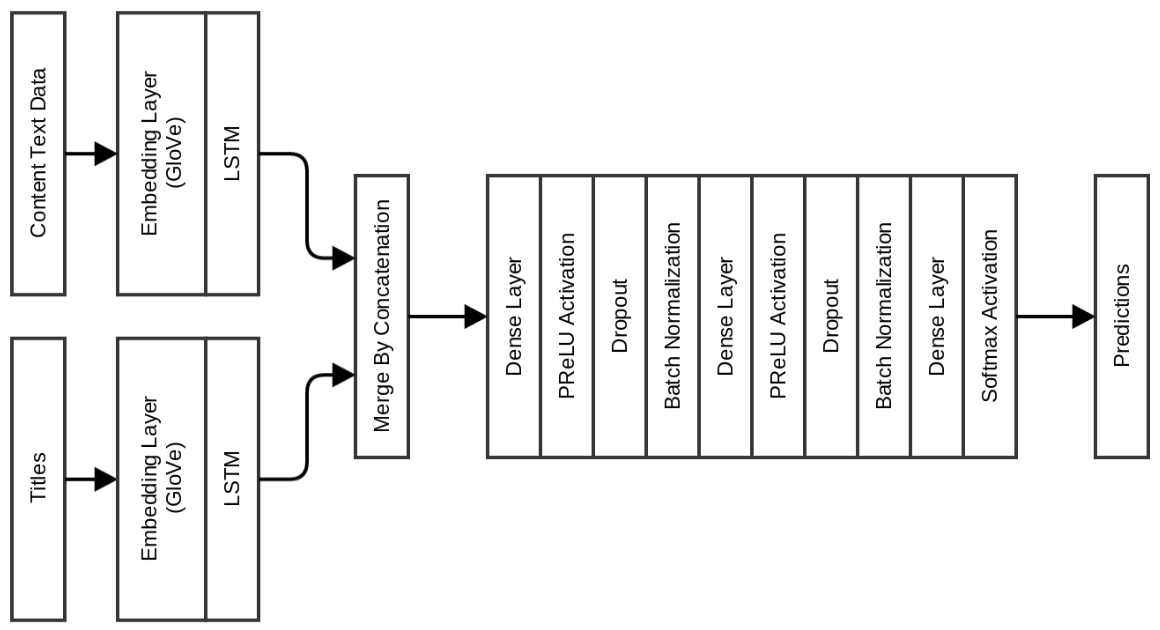
Эта сеть даёт хорошую прибавку к точности валидации: 0,983, но тестовая точность увеличилась очень незначительно до 0,975.
Если помните, я создал также некоторые численные признаки на основе того, что мы не видим, когда переходим по URL. Моя следующая и окончательная модель включает в себя и эти признаки тоже, вместе с LSTM для данных заголовка и текста контента:
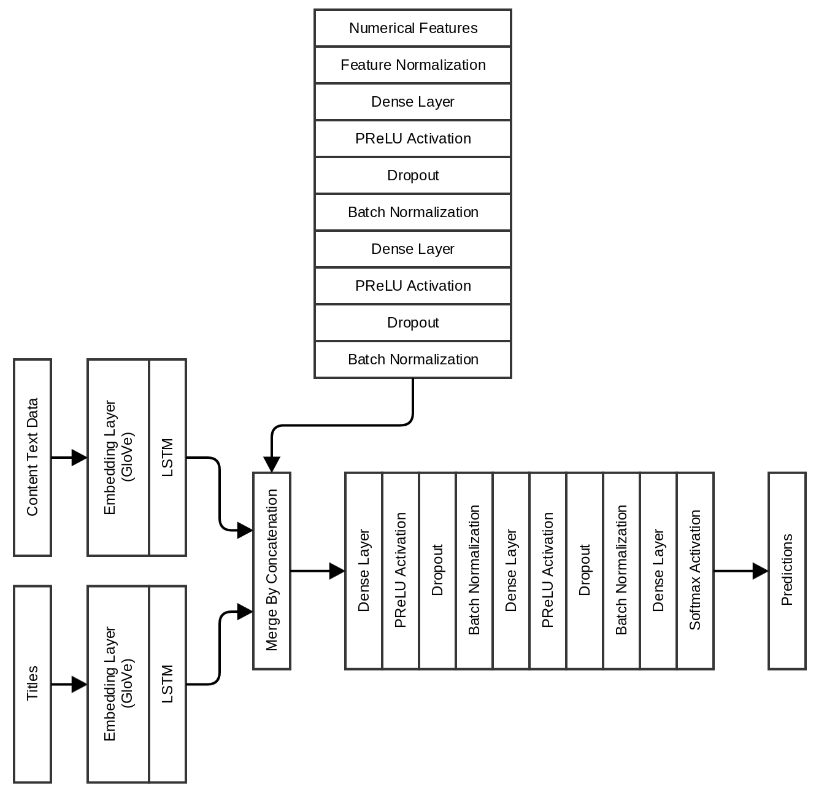
Как оказалось, это лучшая модель с точностью валидации 0,996 и 0,991 на тестовом наборе. Каждый период занимает примерно 60 секунд на этой конкретной модели.
В таблице сведены воедино показатели точности, полученные разными моделями:

Подводя итоги, я смог построить модель для определения кликбейта, которая учитывает заголовок, текстовое содержимое и некоторые функции веб-сайта и демонстрирует точность выше 99% как во время валидации, так и на тестовом наборе.
Код всего, о чём я говорил, доступен на GitHub.
Все модели обучались на NVIDIA TitanX, система Ubuntu 16.04 c 64 ГБ памяти.
Объединим усилия и остановим кликбейт #StopClickBaits!
Не стесняйтесь комментировать или писать по электронной почте на abhishek4 [at] gmail [dot] com, если у вас есть какие-то вопросы.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru