Открытый курс машинного обучения. Тема 1. Первичный анализ данных с Pandas
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-02-28 23:02

Старт открытого курса OpenDataScience
Привет всем, кто ждал запуска открытого курса по практическому анализу данных и машинному обучению!
Первая статья посвящена первичному анализу данных с Pandas.
Пока в серии планируется 7 статей, идущих вместе с тетрадками Jupyter (репозиторий mlcourse_open), соревнованиями и домашними заданиями.
Далее идет список будущих статей, описание курса и собственно, первая тема – введение в Pandas.
План серии статей
- Первичный анализ данных с Pandas
- Визуальный анализ данных в Python
- Классификация, деревья решений и метод ближайших соседей
- Линейные модели классификации и регрессии. Кросс-валидация и оценка модели
- Композиции: бэггинг, случайный лес. Кривые валидации и обучения
- Обучение без учителя: PCA, кластеризация, поиск аномалий
- Искусство построения и отбора признаков. Приложения в задачах обработки текста, изображений и гео-данных
План этой статьи:
- О курсе
- Домашние задания в курсе
- Демонстрация основных методов Pandas
- Первые попытки прогнозирования оттока
- Домашнее задание №1
- Обзор полезных ресурсов
1. О курсе
Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только. По этим темам мы готовим лекции и практические занятия, а для того, чтобы подготовить слушателей к ним, решили опубликовать серию вводных статей на Хабре.
Мы не ставим себе задачу разработать еще один исчерпывающий вводный курс по машинному обучению или анализу данных (т.е. это не замена специализации Яндекса и МФТИ, дополнительному образованию ВШЭ и прочим фундаментальным онлайн- и оффлайн-программам и книжкам). Цель этой серии статей — быстро освежить имеющиеся у вас знания или помочь найти темы для дальнейшего изучения. Подход примерно как у авторов книги Deep Learning, которая начинается с обзора математики и основ машинного обучения — краткого, максимально ёмкого и с обилием ссылок на источники.
Если ты планируешь пройти курс, то сразу предупреждаем: при подборе тем и создании материалов мы ориентируемся на то, что наши слушатели знают математику на уровне 2 курса технического вуза и хотя бы немного умеют программировать на Python. Это не жёсткие критерии отбора, а всего лишь рекомендации — ты можешь записаться на курс, не зная математики или Python (или даже обоих!), и параллельно навёрстывать:
- базовую математику (мат. анализ, линейную алгебру, оптимизацию, теорвер и статистику) можно повторить по этим конспектам Yandex & MIPT (делимся с разрешения). Кратко, на русском – то что надо. Если подробно, то матан – Кудрявцев, линал – Кострикин, оптимизация – Boyd (англ.), теорвер и статистика – Кибзун. Плюс отличные онлайн-курсы МФТИ и ВШЭ на Coursera;
- по Python хватит небольшого интерактивного туториала на Datacamp или этого репозитория по Python и базовым алгоритмам и структурам данных. Что-то более продвинутое – это, например, курс питерского Computer Science Center;
- что касается машинного обучения, то в 95% случаев вам в первую очередь посоветуют классический курс от Andrew Ng (Stanford, Coursera). На русском языке есть отличная специализация МФТИ и Яндекса «Машинное обучение и анализ данных». А также must-read: "The elements of statistical learning" (Hastie, Tibshirani), "Pattern recognition" (Bishop), "Machine Learning: A Probabilistic Perspective " (Murphy) и "Deep Learning" (Goodfellow, Bengio). Книга Bengio и Goodfellow начинается с понятного и интересного интро в машинное обучение и внутреннее устройство его алгоритмов.
Какое ПО нужно
Пока для воспроизведения описанного нужна только сборка Anaconda с Python 3.6. Чуть позже понадобятся и другие библиотеки, об этом будет сказано дополнительно.
Как подключиться к курсу
Подключиться можно в любой момент, но дедлайны по домашним заданиям жесткие.
Для участия:
- Заполните опрос, указав в нем реальное ФИО и желательно Google-почту (для ДЗ нужен гугл-аккаунт);
- Можете вступить в сообщество OpenDataScience, обсжудение курса ведется в канале #mlcourse_open.
2. Домашние задания в курсе
- Каждая статья сопровождается домашним заданием в виде тетрадки Jupyter, в которую надо дописать код, и на основе этого выбрать правильный ответ в форме Google (для этого нужен аккаунт Google);
- Максимум за задание – 10 баллов;
- На каждое задание дается 1 неделя, дедлайн жесткий;
- Решения домашних заданий выкладываются в репозиторий сразу после дедлайна;
- В конце серии статей будет подведен итог (рейтинг участников).
3. Демонстрация основных методов Pandas
Pandas — это библиотека Python, предоставляющая широкие возможности для анализа данных. Данные, с которыми работают датасаентисты, часто хранятся в форме табличек — например, в форматах .csv, .tsv или .xlsx. С помощью библиотеки Pandas такие табличные данные очень удобно загружать, обрабатывать и анализировать с помощью SQL-подобных запросов. А в связке с библиотеками Matplotlib и Seaborn Pandas предоставляет широкие возможности визуального анализа табличных данных.
Основными структурами данных в Pandas являются классы Series и DataFrame. Первый из них представляет собой одномерный индексированный массив данных некоторого фиксированного типа. Второй – это двухмерная структура данных, представляющая собой таблицу, каждый столбец которой содержит данные одного типа. Можно представлять её как словарь объектов типа Series. Структура DataFrame отлично подходит для представления реальных данных: строки соответствуют признаковым описаниям отдельных объектов, а столбцы соответствуют признакам.
# Обеспечим совместимость с Python 2 и 3 # pip install future from __future__ import (absolute_import, division, print_function, unicode_literals) # отключим предупреждения Anaconda import warnings warnings.simplefilter('ignore') # импортируем Pandas и Numpy import pandas as pd import numpy as npБудем показывать основные методы в деле, анализируя набор данных по оттоку клиентов телеком-оператора. Прочитаем данные (метод read_csv) и посмотрим на первые 5 строк с помощью метода head():
df = pd.read_csv('../../data/telecom_churn.csv')df.head()
В Jupyter-ноутбуках датафреймы Pandas выводятся в виде вот таких красивых табличек, и print(df.head()) выглядит хуже.
По умолчанию Pandas выводит всего 20 столбцов и 60 строк, поэтому если ваш датафрейм больше, воспользуйтесь функцией set_option:
pd.set_option('display.max_columns', 100) pd.set_option('display.max_rows', 100)Каждая строка представляет собой одного клиента – это объект исследования.
Столбцы – признаки объекта.
| Название | Описание | Тип |
|---|---|---|
| State | Буквенный код штата | номинальный |
| Account length | Как долго клиент обслуживается компанией | количественный |
| Area code | Префикс номера телефона | количественный |
| International plan | Международный роуминг (подключен/не подключен) | бинарный |
| Voice mail plan | Голосовая почта (подключена/не подключена) | бинарный |
| Number vmail messages | Количество голосовых сообщений | количественный |
| Total day minutes | Общая длительность разговоров днем | количественный |
| Total day calls | Общее количество звонков днем | количественный |
| Total day charge | Общая сумма оплаты за услуги днем | количественный |
| Total eve minutes | Общая длительность разговоров вечером | количественный |
| Total eve calls | Общее количество звонков вечером | количественный |
| Total eve charge | Общая сумма оплаты за услуги вечером | количественный |
| Total night minutes | Общая длительность разговоров ночью | количественный |
| Total night calls | Общее количество звонков ночью | количественный |
| Total night charge | Общая сумма оплаты за услуги ночью | количественный |
| Total intl minutes | Общая длительность международных разговоров | количественный |
| Total intl calls | Общее количество международных разговоров | количественный |
| Total intl charge | Общая сумма оплаты за международные разговоры | количественный |
| Customer service calls | Число обращений в сервисный центр | количественный |
Целевая переменная: Churn – Признак оттока, бинарный признак (1 – потеря клиента, то есть отток). Потом мы будем строить модели, прогнозирующие этот признак по остальным, поэтому мы и назвали его целевым.
Посмотрим на размер данных, названия признаков и их типы.
print(df.shape)(3333, 20)Видим, что в таблице 3333 строки и 20 столбцов. Выведем названия столбцов:
print(df.columns.index)Index(['State', 'Account length', 'Area code', 'International plan', 'Voice mail plan', 'Number vmail messages', 'Total day minutes', 'Total day calls', 'Total day charge', 'Total eve minutes', 'Total eve calls', 'Total eve charge', 'Total night minutes', 'Total night calls', 'Total night charge', 'Total intl minutes', 'Total intl calls', 'Total intl charge', 'Customer service calls', 'Churn'], dtype='object')Чтобы посмотреть общую информацию по датафрейму и всем признакам, воспользуемся методом info:
print(df.info())<class 'pandas.core.frame.DataFrame'> RangeIndex: 3333 entries, 0 to 3332 Data columns (total 20 columns): State 3333 non-null object Account length 3333 non-null int64 Area code 3333 non-null int64 International plan 3333 non-null object Voice mail plan 3333 non-null object Number vmail messages 3333 non-null int64 Total day minutes 3333 non-null float64 Total day calls 3333 non-null int64 Total day charge 3333 non-null float64 Total eve minutes 3333 non-null float64 Total eve calls 3333 non-null int64 Total eve charge 3333 non-null float64 Total night minutes 3333 non-null float64 Total night calls 3333 non-null int64 Total night charge 3333 non-null float64 Total intl minutes 3333 non-null float64 Total intl calls 3333 non-null int64 Total intl charge 3333 non-null float64 Customer service calls 3333 non-null int64 Churn 3333 non-null bool dtypes: bool(1), float64(8), int64(8), object(3) memory usage: 498.1+ KB Nonebool, int64, float64 и object — это типы признаков. Видим, что 1 признак — логический (bool), 3 признака имеют тип object и 16 признаков — числовые.
Изменить тип колонки можно с помощью метода astype. Применим этот метод к признаку Churn и переведём его в int64:
df['Churn'] = df['Churn'].astype('int64')Метод describe показывает основные статистические характеристики данных по каждому числовому признаку (типы int64 и float64): число непропущенных значений, среднее, стандартное отклонение, диапазон, медиану, 0.25 и 0.75 квартили.
df.describe()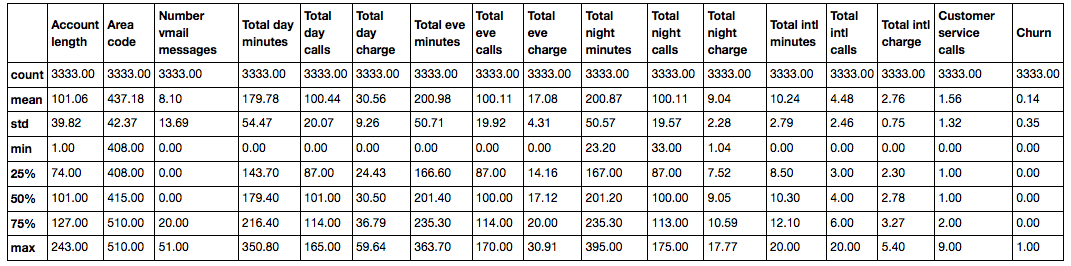
Чтобы посмотреть статистику по нечисловым признакам, нужно явно указать интересующие нас типы в параметре include.
df.describe(include=['object', 'bool'])| State | Area code | International plan | Voice mail plan | Churn | |
|---|---|---|---|---|---|
| count | 3333 | 3333 | 3333 | 3333 | 3333 |
| unique | 51 | 3 | 2 | 2 | 2 |
| top | WV | 415 | No | No | False |
| freq | 106 | 1655 | 3010 | 2411 | 2850 |
Для категориальных (тип object) и булевых (тип bool) признаков можно воспользоваться методом value_counts. Посмотрим на распределение данных по нашей целевой переменной — Churn:
df['Churn'].value_counts()0 2850 1 483 Name: Churn, dtype: int642850 пользователей из 3333 — лояльные, значение переменной Churn у них — 0.
Посмотрим на распределение пользователей по переменной Area code. Укажем значение параметра normalize=True, чтобы посмотреть не абсолютные частоты, а относительные.
df['Area code'].value_counts(normalize=True)415 0.496550 510 0.252025 408 0.251425 Name: Area code, dtype: float64Сортировка
DataFrame можно отсортировать по значению какого-нибудь из признаков. В нашем случае, например, по Total day charge (ascending=False для сортировки по убыванию):
df.sort(columns='Total day charge', ascending=False).head()
Сортировать можно и по группе столбцов:
df.sort(columns=['Churn', 'Total day charge'], ascending=[True, False]).head()
Индексация и извлечение данных
DataFrame можно индексировать по-разному. В связи с этим рассмотрим различные способы индексации и извлечения нужных нам данных из датафрейма на примере простых вопросов.
Для извлечения отдельного столбца можно использовать конструкцию вида DataFrame['Name']. Воспользуемся этим для ответа на вопрос: какова доля людей нелояльных пользователей в нашем датафрейме?
df['Churn'].mean()0.1449144914491449214,5% — довольно плохой показатель для компании, с таким процентом оттока можно и разориться.
Очень удобной является логическая индексация DataFrame по одному столбцу. Выглядит она следующим образом: df[ (df['Name'])], где — это некоторое логическое условие, проверяемое для каждого элемента столбца Name. Итогом такой индексации является DataFrame, состоящий только из строк, удовлетворяющих условию по столбцу Name.
Воспользуемся этим для ответа на вопрос: каковы средние значения числовых признаков среди нелояльных пользователей?
df[df['Churn'] == 1].mean()Account length 102.664596 Number vmail messages 5.115942 Total day minutes 206.914079 Total day calls 101.335404 Total day charge 35.175921 Total eve minutes 212.410145 Total eve calls 100.561077 Total eve charge 18.054969 Total night minutes 205.231677 Total night calls 100.399586 Total night charge 9.235528 Total intl minutes 10.700000 Total intl calls 4.163561 Total intl charge 2.889545 Customer service calls 2.229814 Churn 1.000000 dtype: float64Скомбинировав предыдущие два вида индексации, ответим на вопрос: сколько в среднем в течение дня разговаривают по телефону нелояльные пользователи?
df[df['Churn'] == 1]['Total day minutes'].mean()206.91407867494823Какова максимальная длина международных звонков среди лояльных пользователей (Churn == 0), не пользующихся услугой международного роуминга ('International plan' == 'No')?
df[(df['Churn'] == 0) & (df['International plan'] == 'No')]['Total intl minutes'].max()18.899999999999999Датафреймы можно индексировать как по названию столбца или строки, так и по порядковому номеру. Для индексации по названию используется метод loc, по номеру — iloc.
В первом случае мы говорим «передай нам значения первых пяти строк в столбцах от State до Area code», а во втором — «передай нам значения первых пяти строк в первых трёх столбцах».
df.loc[0:5, 'State':'Area code']| State | Account length | Area code | |
|---|---|---|---|
| 0 | KS | 128 | 415 |
| 1 | OH | 107 | 415 |
| 2 | NJ | 137 | 415 |
| 3 | OH | 84 | 408 |
| 4 | OK | 75 | 415 |
| 5 | AL | 118 | 510 |
df.iloc[0:5, 0:3]| State | Account length | Area code | |
|---|---|---|---|
| 0 | KS | 128 | 415 |
| 1 | OH | 107 | 415 |
| 2 | NJ | 137 | 415 |
| 3 | OH | 84 | 408 |
| 4 | OK | 75 | 415 |
Если нам нужна первая или последняя строчка датафрейма, пользуемся конструкцией df[:1] или df[-1:]:
df[-1:]
Применение функций к ячейкам, столбцам и строкам
Применение функции к каждому столбцу: apply
df.apply(np.max) State WY Account length 243 Area code 510 International plan Yes Voice mail plan Yes Number vmail messages 51 Total day minutes 350.8 Total day calls 165 Total day charge 59.64 Total eve minutes 363.7 Total eve calls 170 Total eve charge 30.91 Total night minutes 395 Total night calls 175 Total night charge 17.77 Total intl minutes 20 Total intl calls 20 Total intl charge 5.4 Customer service calls 9 Churn True dtype: objectМетод apply можно использовать и для того, чтобы применить функцию к каждой строке. Для этого нужно указать axis=1.
Применение функции к каждой ячейке столбца: map
Например, метод map можно использовать для замены значений в колонке, передав ему в качестве аргумента словарь вида {old_value: new_value}:
d = {'No' : False, 'Yes' : True} df['International plan'] = df['International plan'].map(d) df.head()
Аналогичную операцию можно провернуть с помощью метода replace:
df = df.replace({'Voice mail plan': d}) df.head()
Группировка данных
В общем случае группировка данных в Pandas выглядит следующим образом:
df.groupby(by=grouping_columns)[columns_to_show].function()- К датафрейму применяется метод
groupby, который разделяет данные поgrouping_columns– признаку или набору признаков. - Индексируем по нужным нам столбцам (
columns_to_show). - К полученным группам применяется функция или несколько функций.
Группирование данных в зависимости от значения признака Churn и вывод статистик по трём столбцам в каждой группе.
columns_to_show = ['Total day minutes', 'Total eve minutes', 'Total night minutes'] df.groupby(['Churn'])[columns_to_show].describe(percentiles=[])| Total day minutes | Total eve minutes | Total night minutes | ||
|---|---|---|---|---|
| Churn | ||||
| 0 | count | 2850.000000 | 2850.000000 | 2850.000000 |
| mean | 175.175754 | 199.043298 | 200.133193 | |
| std | 50.181655 | 50.292175 | 51.105032 | |
| min | 0.000000 | 0.000000 | 23.200000 | |
| 50% | 177.200000 | 199.600000 | 200.250000 | |
| max | 315.600000 | 361.800000 | 395.000000 | |
| 1 | count | 483.000000 | 483.000000 | 483.000000 |
| mean | 206.914079 | 212.410145 | 205.231677 | |
| std | 68.997792 | 51.728910 | 47.132825 | |
| min | 0.000000 | 70.900000 | 47.400000 | |
| 50% | 217.600000 | 211.300000 | 204.800000 | |
| max | 350.800000 | 363.700000 | 354.900000 |
Сделаем то же самое, но немного по-другому, передав в agg список функций:
columns_to_show = ['Total day minutes', 'Total eve minutes', 'Total night minutes'] df.groupby(['Churn'])[columns_to_show].agg([np.mean, np.std, np.min, np.max])| Total day minutes | Total eve minutes | Total night minutes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | amin | amax | mean | std | amin | amax | mean | std | amin | amax | |
| Churn | ||||||||||||
| 0 | 175.175754 | 50.181655 | 0.0 | 315.6 | 199.043298 | 50.292175 | 0.0 | 361.8 | 200.133193 | 51.105032 | 23.2 | 395.0 |
| 1 | 206.914079 | 68.997792 | 0.0 | 350.8 | 212.410145 | 51.728910 | 70.9 | 363.7 | 205.231677 | 47.132825 | 47.4 | 354.9 |
Сводные таблицы
Допустим, мы хотим посмотреть, как наблюдения в нашей выборке распределены в контексте двух признаков — Churn и Customer service calls. Для этого мы можем построить таблицу сопряженности, воспользовавшись методом crosstab:
pd.crosstab(df['Churn'], df['International plan'])| International plan | No | Yes |
|---|---|---|
| Churn | ||
| 0 | 2664 | 186 |
| 1 | 346 | 137 |
pd.crosstab(df['Churn'], df['Voice mail plan'], normalize=True)| Voice mail plan | No | Yes |
|---|---|---|
| Churn | ||
| 0 | 0.602460 | 0.252625 |
| 1 | 0.120912 | 0.024002 |
Мы видим, что большинство пользователей лояльны и при эттм пользуются дополнительными услугами (международного роуминга / голосовой почты).
Продвинутые пользователи Excel наверняка вспомнят о такой фиче, как сводные таблицы (pivot tables). В Pandas за сводные таблицы отвечает метод pivot_table, который принимает в качестве параметров:
values– список переменных, по которым требуется рассчитать нужные статистики,index– список переменных, по которым нужно сгруппировать данные,aggfunc— то, что нам, собственно, нужно посчитать по группам — сумму, среднее, максимум, минимум или что-то ещё.
Давайте посмотрим среднее число дневных, вечерних и ночных звонков для разных Area code:
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'], ['Area code'], aggfunc='mean').head(10)| Total day calls | Total eve calls | Total night calls | |
|---|---|---|---|
| Area code | |||
| 408 | 100.496420 | 99.788783 | 99.039379 |
| 415 | 100.576435 | 100.503927 | 100.398187 |
| 510 | 100.097619 | 99.671429 | 100.601190 |
Преобразование датафреймов
Как и многое другое в Pandas, добавление столбцов в DataFrame осуществимо несколькими способами.
Например, мы хотим посчитать общее количество звонков для всех пользователей. Создадим объект total_calls типа Series и вставим его в датафрейм:
total_calls = df['Total day calls'] + df['Total eve calls'] + df['Total night calls'] + df['Total intl calls'] df.insert(loc=len(df.columns), column='Total calls', value=total_calls) # loc - номер столбца, после которого нужно вставить данный Series # мы указали len(df.columns), чтобы вставить его в самом конце df.head()
Добавить столбец из имеющихся можно и проще, не создавая промежуточных Series:
df['Total charge'] = df['Total day charge'] + df['Total eve charge'] + df['Total night charge'] + df['Total intl charge'] df.head()
Чтобы удалить столбцы или строки, воспользуйтесь методом drop, передавая в качестве аргумента нужные индексы и требуемое значение параметра axis (1, если удаляете столбцы, и ничего или 0, если удаляете строки):
df = df.drop(['Total charge', 'Total calls'], axis=1) # избавляемся от созданных только что столбцов df.drop([1, 2]).head() # а вот так можно удалить строчки
4. Первые попытки прогнозирования оттока
Посмотрим, как отток связан с признаком "Подключение международного роуминга" (International plan). Сделаем это с помощью сводной таблички crosstab, а также путем иллюстрации с Seaborn (как именно строить такие картинки и анализировать с их помощью графики – материал следующей статьи.)
pd.crosstab(df['Churn'], df['International plan'], margins=True)| International plan | False | True | All |
|---|---|---|---|
| Churn | |||
| 0 | 2664 | 186 | 2850 |
| 1 | 346 | 137 | 483 |
| All | 3010 | 323 | 3333 |
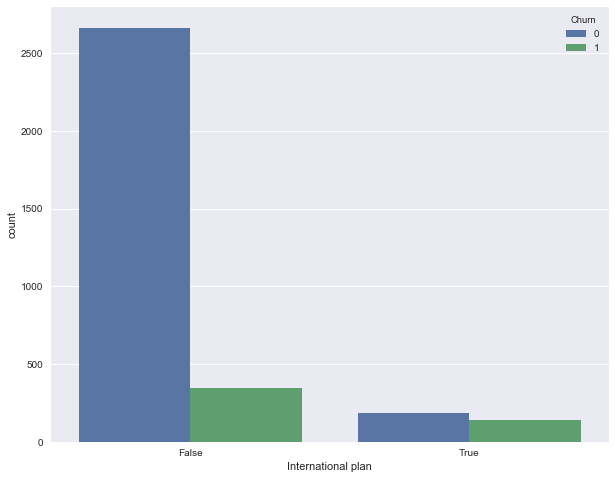
Видим, что когда роуминг подключен, доля оттока намного выше – интересное наблюдение! Возможно, большие и плохо контролируемые траты в роуминге очень конфликтогенны и приводят к недовольству клиентов телеком-оператора и, соответственно, к их оттоку.
Далее посмотрим на еще один важный признак – "Число обращений в сервисный центр" (Customer service calls). Также построим сводную таблицу и картинку.
pd.crosstab(df['Churn'], df['Customer service calls'], margins=True)| Customer service calls | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | All |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Churn | |||||||||||
| 0 | 605 | 1059 | 672 | 385 | 90 | 26 | 8 | 4 | 1 | 0 | 2850 |
| 1 | 92 | 122 | 87 | 44 | 76 | 40 | 14 | 5 | 1 | 2 | 483 |
| All | 697 | 1181 | 759 | 429 | 166 | 66 | 22 | 9 | 2 | 2 | 3333 |
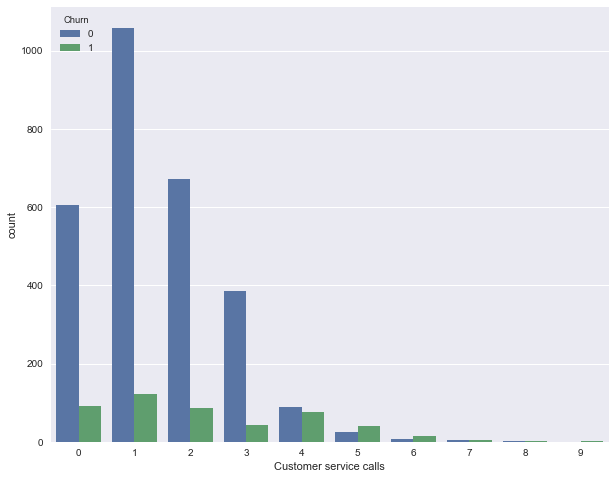
Может быть, по сводной табличке это не так хорошо видно (или скучно ползать взглядом по строчкам с цифрами), а вот картинка красноречиво свидетельствует о том, что доля оттока сильно возрастает начиная с 4 звонков в сервисный центр.
Добавим теперь в наш DataFrame бинарный признак — результат сравнения Customer service calls > 3. И еще раз посмотрим, как он связан с оттоком.
df['Many_service_calls'] = (df['Customer service calls'] > 3).astype('int') pd.crosstab(df['Many_service_calls'], df['Churn'], margins=True)| Churn | 0 | 1 | All |
|---|---|---|---|
| Many_service_calls | |||
| 0 | 2721 | 345 | 3066 |
| 1 | 129 | 138 | 267 |
| All | 2850 | 483 | 3333 |
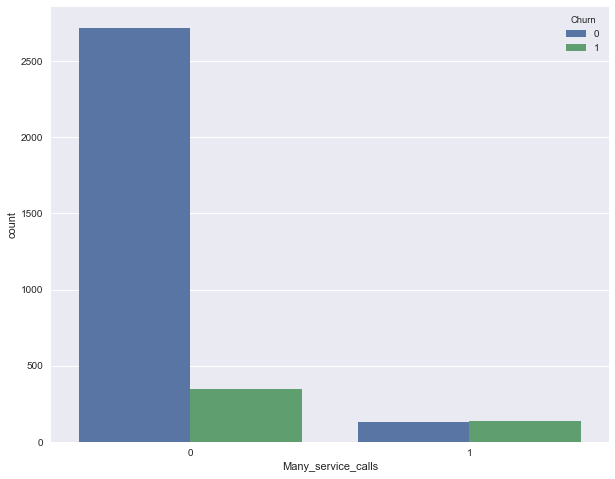
Объединим рассмотренные выше условия и построим сводную табличку для этого объединения и оттока.
pd.crosstab(df['Many_service_calls'] & df['International plan'] , df['Churn'])| Churn | 0 | 1 |
|---|---|---|
| row_0 | ||
| False | 2841 | 464 |
| True | 9 | 19 |
Значит, прогнозируя лояльность клиента в случае, когда число звонков в сервисный центр меньше 4 и не подключени роуминг (и отток – в противном случае), можно ожидать процент "угадывания лояльности клиента" около 85.8% (ошибаемся всего 464 + 9 раз). Эти 85.8%, которые мы получили с помощью очень простых рассуждений – это неплохая отправная точка (baseline) для дальнейших моделей машинного обучения, которые мы будем строить.
В целом до появления машинного обучения процесс анализа данных выглядел примерно так. Прорезюмируем:
- Доля лояльных клиентов в выборке – 85.5%. Самая наивная модель, ответ которой "Клиент всегда лоялен" на подобных данных будет угадывать примерно в 85.5% случаев. То есть доли правильных ответов (accuracy) последующих моделей должны быть как минимум не меньше, а лучше, значительно выше этой цифры;
- С помощью простого прогноза, который условно можно выразить такой формулой: "International plan = True & Customer Service calls < 4 => Churn = 0, else Churn = 1", можно ожидать долю угадываний 85.8%, что еще чуть выше 85.5%;
- Эти два бейзлайна мы получили без всякого машинного обучения, и они служат отправной точной для наших последующих моделей. Если окажется, что мы громадными усилиями увеличиваем долю правильных ответов всего, скажем, на 0.5%, то возможно, мы что-то делаем не так, и достаточно ограничиться простой моделью из двух условий;
- Перед обучением сложных моделей рекомендуется немного покрутить данные и проверить простые предположения. Более того, в бизнес-приложениях машинного обучения чаще всего начинают именно с простых решений, а потом экспериментируют с их усложнениями.
5. Домашнее задание №1
Первое домашнее задание посвящено анализу набора данных Adult репозитория UCI и представлено в этом Jupyter-ноутбуке. В датасете Adult собрана демографическая информация по жителям США.
Мы предлагаем выполнить это задание и затем ответить на 10 вопросов. Ссылка на форму для ответов (она же – в ноутбуке). Ответы в форме можно менять после отправки, но не после дедлайна (точнее, технически можно и после дедлайна, но это не будет зачтено).
Дедлайн: 6 марта 23:59 (жесткий).
6. Обзор полезных ресурсов
- В первую очередь, конечно же, официальная документация Pandas. В частности, рекомендуем короткое введение 10 minutes to pandas,
- PDF-шпаргалка по библиотеке,
- Отличная презентация Александра Дьяконова «Знакомство с Pandas»,
- На гитхабе есть подборка упражнений по Pandas и еще один полезный репозиторий (на английском языке),
- scipy-lectures.org — учебник по работе с pandas, numpy, matplotlib и scikit-learn.
Статья написана в соавторстве с yorko и при поддержке коммьюнити Open Data Science.
Источник: habrahabr.ru