Нейросетка играет в Доту
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-01-16 17:10
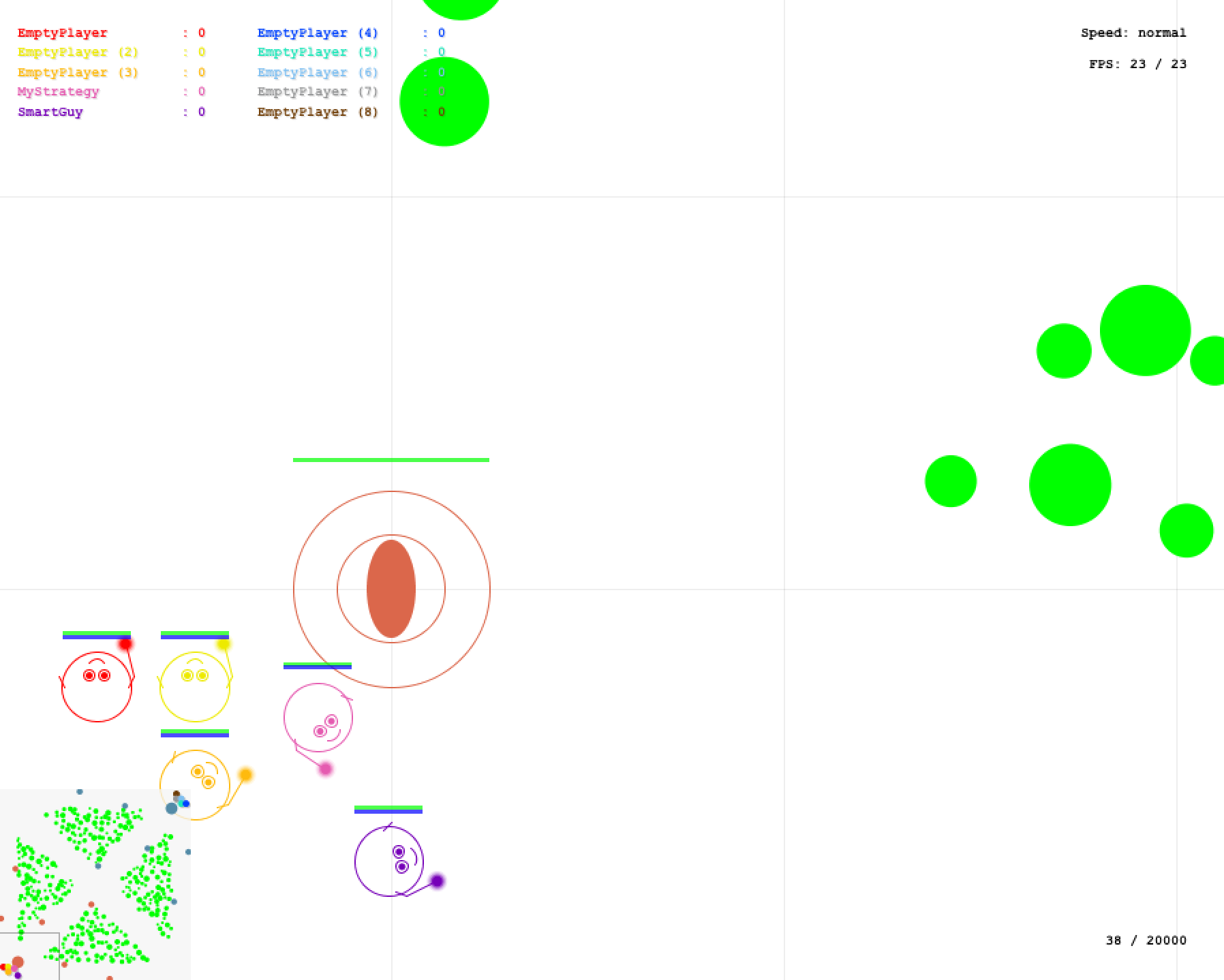 Всем привет! На самом деле нейросетка играет не в привычную Dota 2, а в RussianAICup 2016 CodeWizards. RussianAICup — это ежегодное открытое соревнование по программированию искусственного интеллекта. Участвовать в этом соревновании довольно интересно. В этом году темой была игра похожая на Доту. Так как я уже какое-то время занимаюсь обучением с подкреплением, то мне хотелось попробовать применить это в RussianAICup. Главной целью было научить нейронную сеть играть в эту игру, хотя занятие призового места — это, конечно, было бы приятно. В итоге нейросеть держится в районе 700 места. Что, я считаю, неплохо, ввиду ограничений соревнования. В этой статье речь пойдет скорее об обучении с подкреплением и алгоритмах DDPG и DQN, а не о самом соревновании.
Всем привет! На самом деле нейросетка играет не в привычную Dota 2, а в RussianAICup 2016 CodeWizards. RussianAICup — это ежегодное открытое соревнование по программированию искусственного интеллекта. Участвовать в этом соревновании довольно интересно. В этом году темой была игра похожая на Доту. Так как я уже какое-то время занимаюсь обучением с подкреплением, то мне хотелось попробовать применить это в RussianAICup. Главной целью было научить нейронную сеть играть в эту игру, хотя занятие призового места — это, конечно, было бы приятно. В итоге нейросеть держится в районе 700 места. Что, я считаю, неплохо, ввиду ограничений соревнования. В этой статье речь пойдет скорее об обучении с подкреплением и алгоритмах DDPG и DQN, а не о самом соревновании.В этой статье я не буду описывать базовую информацию о нейросетях, сейчас и так очень много информации о них на просторах интернета, а раздувать публикацию не хочется. Мне же хотелось бы сосредоточится на обучении с подкреплением с использованием нейросетей, то есть о том, как обучить искусственную нейронную сеть демонстрировать нужное поведение методом проб и ошибок. Я буду упрощенно описывать 2 алгоритма, база у них одна, а области применения немного отличаются.
Марковское состояние
На входе алгоритмы принимают текущее состояние агента S. Здесь важно чтобы состояние обладало свойством марковости, то есть по возможности включало в себя всю информацию, необходимую для предсказания следующих состояний системы. Например у нас есть камень, брошенный под углом к горизонту. Если мы в качестве состояния примем координаты камня, это не позволит нам предсказать его дальнейшее поведение, но если мы добавим к координатам вектор скорости камня, то такое состояние нам позволит предсказать всю дальнейшую траекторию движения камня, то есть будет марковским. На основе состояния алгоритм выдает информацию о действии A, которое необходимо сделать чтобы обеспечить оптимальное поведение, то есть такое поведение, которое ведет к максимизации суммы наград. Награда R — это вещественное число, которое мы используем для обучения алгоритма. Награда выдается в момент, когда агент, находясь в состоянии S, совершает действие А и переходит в состояние S'. Для обучения эти алгоритмы используют информацию о том, что они делали в прошлом и какой при этом был результат. Эти элементы опыта состоят из 4х компонентов (S, A, R, S'). Такие четверки мы складываем в массив опыта и далее используем для обучения. В статьях он имеет имя replay buffer.DQN
Или Deep Q-Networks — это тот самый алгоритм, который обучили играть в игры Atari. Этот алгоритм разработан для случаев, когда количество управляющих команд строго ограничено и в случае Atari равно количеству кнопок джойстика (18). Таким образом выход алгоритма представляет собой вектор оценок всех возможных действий Q. Индекс вектора указывает на конкретное действие, а значение указывает насколько хорошо это действие. То есть нам надо найти действие с максимальной оценкой. В этом алгоритме используется одна нейросеть, на вход которой мы подаем S, а индекс действия определяем как argmax(Q). Нейронную сеть мы обучаем с помощью уравнения Беллмана, которое и обеспечивает сходимость выхода нейросети к значениям, которые реализуют поведение максимизирующее сумму будущих наград. Для данного случая оно имеет вид: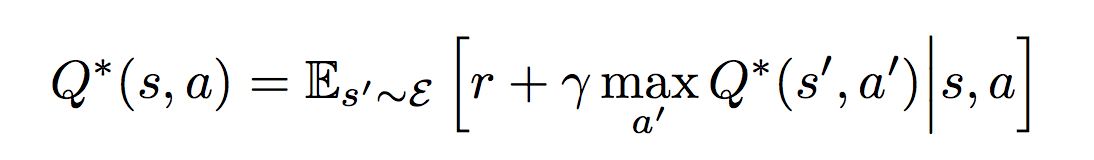
 Если это расшифровать получается следующее:
Если это расшифровать получается следующее:- Берем пачку (minibatch) из N элементов опыта (S, A, R, S'), например 128 элементов
- Для каждого элемента считаем
y = R + ? * maxпо всем A' (Qpast(S', A'))
? — это дискаунт фактор, число в интервале [0, 1], которое определяет насколько для нас важны будущие награды. Типичные значение обычно выбираются в интервале 0.9 — 0.99.
Qpast — это копия нашей же нейросети, но какое-то количество итераций обучения назад, например 100 или 1000. Веса этой нейросети мы просто периодически обновляем, не обучаем.
Qpast = (1 — ?) * Qpast + ? * Q
? — скорость обновления Qpast, типичное значение 0.01
Этот трюк обеспечивает лучшую сходимость алгоритма
- Далее считаем функцию потерь для нашего минибатча
L = ?по элементам минибатча (y — Q(S, A))2 / N
Используем среднюю квадратичную ошибку
- Применяем любимый алгоритм оптимизации, используя L
- Повторяем пока нейросеть достаточно не обучится
Если внимательно посмотреть на уравнение Беллмана, то можно заметить, что оно рекурсивно оценивает текущее действие взвешенной суммой наград от всех последующих действий, возможных после выполнения текущего действия.
DDPG
Или Deep Deterministic Policy Gradient — это алгоритм, созданный, для случая когда управляющие команды представляют собой значения из непрерывных пространств (continuous action spaces). Например, когда вы управляете автомобилем, вы поворачиваете руль на определенный угол или нажимаете педаль газа до определенной глубины. Возможных значений поворота руля и положений педали газа теоретически бесконечно много, поэтому мы хотим чтобы алгоритм выдавал нам эти самые конкретные значения, которые нам необходимо применить в текущей ситуации. Поэтому в данном подходе используются две нейросети: ? (S) — актор, который возвращает нам вектор A, компоненты которого являются значениями соответствующих управляющих сигналов. Например это может быть вектор из трех элементов (угол поворота руля, положение педали газа, положение педали тормоза) для автопилота машины. Вторая нейросеть Q(S, A) — критик, которая возвращает q — оценку действия A в состоянии S. Критик используется для обучения актора и обучается с помощью уравнения Беллмана: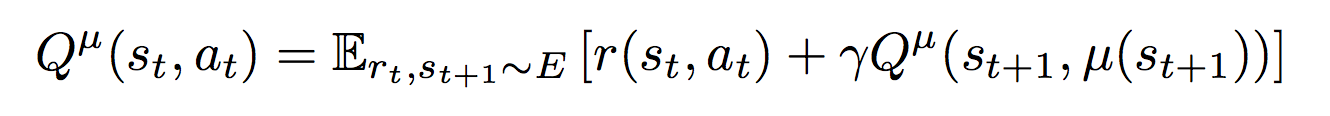
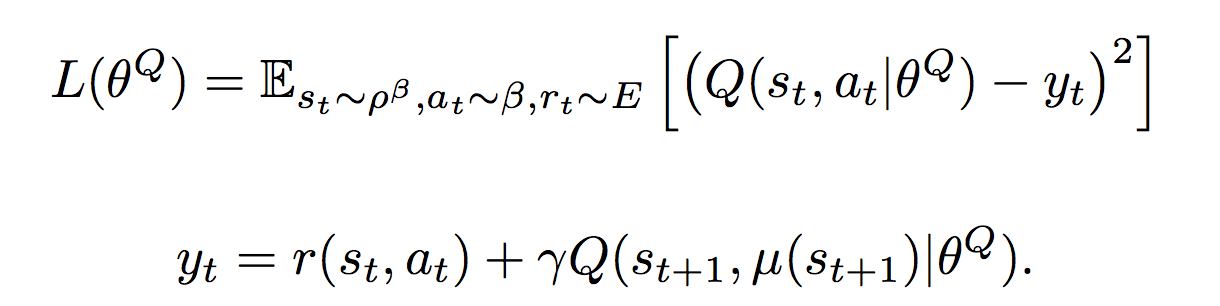 Критик обучается через градиент от оценки критика ?Q(S, ? (S)) по весам актора
Критик обучается через градиент от оценки критика ?Q(S, ? (S)) по весам актора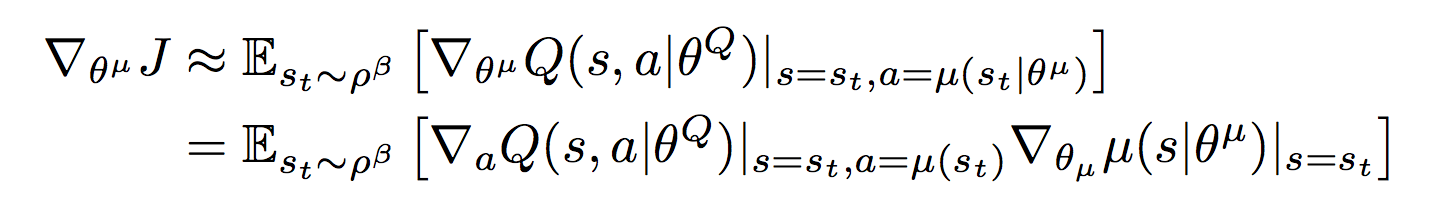 Если это расшифровать получается:
Если это расшифровать получается:- Берем минибатч из N элементов опыта (S, A, R, S')
- y = R + ? * Qpast (S', ?past (S'))
Qpast, ?past — это тот же трюк что и в случае DQN, только теперь это копии двух сетей
- Считаем функцию потерь
L = ?по минибатчу (y — Q (S, A))2
- Обучаем критика используя L
- Берем градиент по весам актора ?Q(S, ? (S)) любимым алгоритмом оптимизации и модифицируем актора, с помощью него
- Повторяем пока не достигнем желаемого
RussianAICup
Теперь я расскажу об агенте, которого я тренировал для соревнования. Подробные правила можете почитать по ссылке, если интересно. Также можете посмотреть видео и описание на главной странице. В соревновании есть 2 типа игр, первый — это когда твоя стратегия управляет одним из десяти волшебников. И второй, когда твоя стратегия управляет командой из 5 волшебников, противник при этом управляет противоположной командой из 5ти волшебников. Информация, которая доступна для стратегии включает все объекты, которые находятся в области видимости всех дружественных волшебников, все остальное пространство покрыто туманом войны:
- волшебники
- миньоны
- строения (башни и базы)
- деревья
- бонусы
- снаряды
Юнит может иметь следующую информацию о себе:
- координаты
- количество хитпоинтов
- количество маны
- время до следующего удара
- другие параметры, их много, в правилах есть полное описание
Есть локальный симулятор (он на КПДВ), в котором можно погонять свою стратегию против самой себя или 2х встроенных противников, достаточно простых стратегий. Для начала я решил попробовать решить задачу в лоб. Я использовал DDPG. Собрал все доступные параметры о мире, их получилось 1184 и подал на вход. Выходом у меня был вектор из 13 чисел, отвечающих за скорость перемещения прямо и вбок, поворот, разные типы атаки, а также параметры атаки, такие как дальность полета снаряда, в общем все параметры, которые существуют. С наградой для начала тоже решил не мудрить, игра выдает количество XP, поэтому я давал положительную награду за повышение XP и отрицательную за уменьшение хитпоинтов. Поэкспериментировав какое-то время я понял, что в таком виде очень трудно добиться от нейросети толка, так как зависимости, которые должна была выявить моя модель, по моим прикидкам, были довольно сложными. Поэтому я решил, что надо упростить задачу для нейросети.
Для начала я перестроил состояние, чтобы оно представляло не просто сборник всей входящей информации, а подавалось в виде кругового обзора от управляемого волшебника. Весь круговой обзор делился на 64 сегмента, в каждый сегмент могло попасть 4 ближайших объекта в этом сегменте. Таких круговых обзоров было 3, для дружественных, нейтральных и вражеских юнитов, а также для указания куда следовало двигаться. В итоге получилось еще больше параметров — 3144. Также я начал давать награду за движение в нужном направлении, то есть по дорожке к вражеской базе. Так как круговой обзор включает информацию о взаимном расположении объектов, я еще пробовал использовать сверточную сеть. Но ничего не получалось. Волшебники просто крутились на одном месте без малейшего проблеска интеллекта. И я оставил на какое-то время попытки, чтобы почитать информацию о тренировке нейросетей и вдохновиться.
Через какое-то время я вернулся к экспериментам уже вдохновившись, уменьшил скорость обучения с 1e-3 до 1e-5, очень сильно сократил количество входных параметров до 714, попутно отказавшись от некоторых данных, чтобы ускорить процесс обработки информации. Также я решил использовать нейросеть только для движения и поворота, а стрельбу оставил за вручную прописанной простой стратегией: если можем стрелять поворачиваемся в сторону слабейшего врага и стреляем. Таким образом я снял с нейросети достаточно сложную для обучения, но легкую для прописывания задачу по прицеливанию и выстрелу. И оставил достаточно сложно формализуемую задачу наступления и отступления. В итоге стали заметны проблески интеллекта на обычной полносвязной сети. Потренировав ее какое-то время (пару суток на GeForce GTX 1080 на эксперимент), добившись неплохого качества управления (сеть обыгрывала встроенного противника), я решил загрузить сеть в песочницу.
Веса сети я выгрузил из Tensorflow и захардкодил их в виде h файлов. В итоге получился архив в несколько десятков мегабайт и песочница отказалась его принять, сказав что максимальный файл для загрузки 1 Мб. Пришлось намного сильнее сократить нейросеть и потратить кучу времени (порядка недели или нескольких недель, я уже точно не помню) на ее обучение, подбор гиперпараметров и уложиться в размер архива 1 Мб. И вот когда я наконец снова попробовал загрузить, оно выдало, что ограничение на разархивированный архив 2 Мб, а у меня было 4Мб. Фейспалм. Поборов бурные чувства, я принялся еще больше ужимать нейросетку. В итоге ужал до следующей архитектуры:
394 x 192 x 128 x 128 x 128 x 128 x 6 394 — это входной слой, во всех слоях кроме последнего и предпоследнего используется relu, в предпоследнем tanh в качестве активационной функции, в последнем, как водится, активационной функции нет. В таком виде контроль был не таким хорошим, но проблеск интеллекта заметен был и я решил загрузить этот вариант в аккурат за несколько часов до начала финала. С небольшими улучшениями он до сих пор и играет russianaicup.ru/profile/Parilo2 в песочнице в районе 700 места в рейтинге. В целом я доволен результатом на данный момент. Ниже видео с примером матча 1х1, моя стратегия управляет всей командой из 5ти волшебников.
Предложения по улучшению конкурса
В конкурсе довольно интересно участвовать. Есть плюшки в виде локального симулятора. Я бы хотел предложить несколько изменить формат. То есть запускать на сервере только серверную часть и рейтинговую таблицу, а клиенты чтобы коннектились через интернет к серверу и участвовали в поединках. Таким образом можно снять нагрузку с сервера, а также убрать ограничения по ресурсам для стратегий. В общем, так как это сделано во многих онлайн играх типа Старкрафт 2 или той же Доты.Код
Код агента доступен на гитхабе. Используется С++ и для управления и для обучения. Обучение реализовано в виде отдельной программы WizardTrainer, которая зависит от TensorFlow, стратегия подключается по сети к тренеру, скидывает туда состояние среды и получает оттуда действия которые необходимо совершать. Также она туда отправляет весь получаемый опыт. Таким образом к одной нейросетке можно подключать несколько агентов и она будет управлять всеми одновременно. Собрать это все не так просто, если потребуется спросите меня как.Ресурсы
Более подробно об обучении с подкреплением, этих, а также других алгоритмах можно посмотреть в замечательном курсе David Silver из Google DeepMind. Слайды доступны здесь.Оригинальные статьи DDPG и DQN. Формулы я брал из них.
Спасибо, что дочитали до конца. Удачи вам на пути познания!
.S. Прошу извинить за размер формул, не хотел, чтобы они были маленькие, перестарался с принтскрином.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru