Синтезатор речи воспроизведёт сказанное человеком по одним лишь движениям губ
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-12-01 15:35

Учёные из Гренобльского университета представили технологию, которая поможет общаться людям с нарушениями речи – афазией или параличом, например. От человека требуются лишь двигать мышцами рта, а всё остальное сделает специально разработанный вокодер (устройство синтеза речи).
Технологию невозможно было бы создать без использования нейрокомпьютерных интерфейсов, говорят специалисты. Концепция следующая: вокодер должен воспроизводить голосовой сигнал по минимальному набору параметров, опираясь только на информацию о движениях органов речи, причём в режиме реального времени.
Команда из Гренобля использовала в разработке простой вокодер, а также искусственную нейросеть с тремя скрытыми слоями. Алгоритм обучали с помощью специальной базы данных, которая включала в себя информацию о звуках и движениях рта, которые им соответствуют.
В разработке вокодера принял участие доброволец, который произносил текст, в то время как к его губам, языку, мягкому нёбу и челюсти были присоединены девять датчиков.
В итоге специалисты получили базу из 19 тысяч звуков, в которую вошли 712 речевых элементов разной длины (начиная с отдельных гласных и согласных и заканчивая целыми предложениями) и соответствующие им движения органов речи. Общая продолжительность аудиозаписи составила 45 минут.
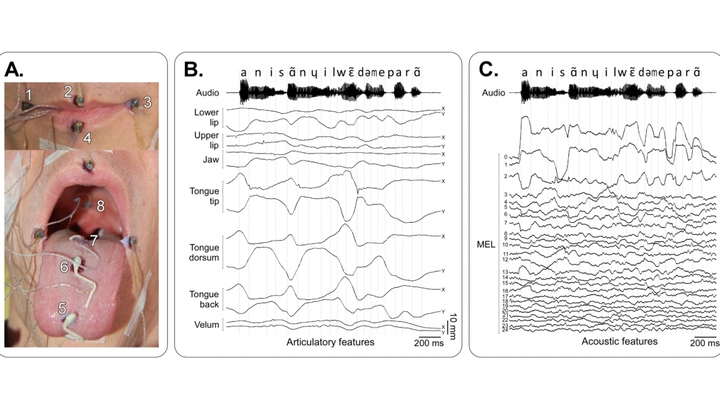
Затем систему протестировали на четырёх других добровольцах – их попросили беззвучно произнести семь гласных и несколько последовательностей по схеме "гласная-согласная-гласная". Вторая группа участников должна была по восстановленному компьютером сигналу определить, какой именно звук произносили испытуемые.
Результат оказался многообещающим: алгоритм помог распознать отдельные гласные звуки в 86%, а согласные – в 49% случаев. Последовательности звуков система распознавала в 48-52% случаев.
Авторы работы признаются, что речь, воспроизведенная компьютером, пока что мало напоминает естественное звучание человеческого голоса, однако в ближайшее время команда планирует улучшить эту функцию вокодера.
К слову, сегодня существует специальное приложение, которое позволяет использовать голос одного человека для создания искусственного голоса тем, кто испытывает трудности с устной речью.
В будущем устройство может быть использовано не только для помощи людям с проблемами речевого аппарата. Разработка станет полезна исследователям, которые создают нейрокомпьютерные интерфейсы, способные воспроизводить речь человека только на основе сигналов его мозга.
Научная статья, рассказывающая про разработку подробнее, опубликована в издании PLOS Computational Biology.
Добавим, что ранее мы рассказывали о роботизированной перчатке, которая подарила голос людям с нарушениями речи. Тем временем генетики удивили научное сообщество заявлением, что человеческая речь может быть следствием возникновения генетической мутации.
Телеграм: t.me/ainewsline
Источник: www.vesti.ru