Рекурентная нейронная сеть в 10 строчек кода оценила отзывы зрителей нового эпизода “Звездных войн”
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-12-24 13:44

Hello, Habr! Недавно мы получили от “Известий” заказ на проведение исследования общественного мнения по поводу фильма «Зве?здные вои?ны: Пробуждение Силы», премьера которого состоялась 17 декабря. Для этого мы решили провести анализ тональности российского сегмента Twitter по нескольким релевантным хэштегам. Результата от нас ждали всего через 3 дня (и это в самом конце года!), поэтому нам нужен был очень быстрый способ. В интернете мы нашли несколько подобных онлайн-сервисов (среди которых sentiment140 и tweet_viz), но оказалось, что они не работают с русским языком и по каким-то причинам анализируют только маленький процент твитов. Нам помог бы сервис AlchemyAPI, но ограничение в 1000 запросов в сутки нас также не устраивало. Тогда мы решили сделать свой анализатор тональности с блэк-джеком и всем остальным, создав простенькую рекурентную нейронную сеть с памятью. Результаты нашего исследования были использованы в статье “Известий”, опубликованной 3 января.
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
 Такая архитектура нейронной сети позволяет решать такие задачи, как, предсказание последнего слова в предложении, например слово «солнце» в фразе «в ясном небе светит солнце».
Такая архитектура нейронной сети позволяет решать такие задачи, как, предсказание последнего слова в предложении, например слово «солнце» в фразе «в ясном небе светит солнце».
Моделирование памяти в нейронной сети подобным образом вводит новое измерение в описание процесса её работы — время. Пусть нейронная сеть получает на вход последовательность данных, например, текст пословно или слово побуквенно. Тогда каждый следующий элемент этой последовательности поступает на нейрон в новый условный момент времени. К этому моменту в нейроне уже есть накопленный с начала поступления информации опыт. В примере с солнцем в качестве x0 выступит вектор, характеризующий предлог «в», в качестве x1 — слово «небе» и так далее. В итоге в качестве ht должен быть вектор, близкий к слову «солнце».
Основное отличие разных типов рекурентных нейронов друг от друга кроется в том, как обрабатывается ячейка памяти внутри них. Традиционный подход подразумевает сложение двух векторов (сигнала и памяти) с последующим вычислением активации от суммы, например, гиперболическим тангенсом. Получается обычная сетка с одним скрытым слоем. Подобную схему рисуют следующим образом:
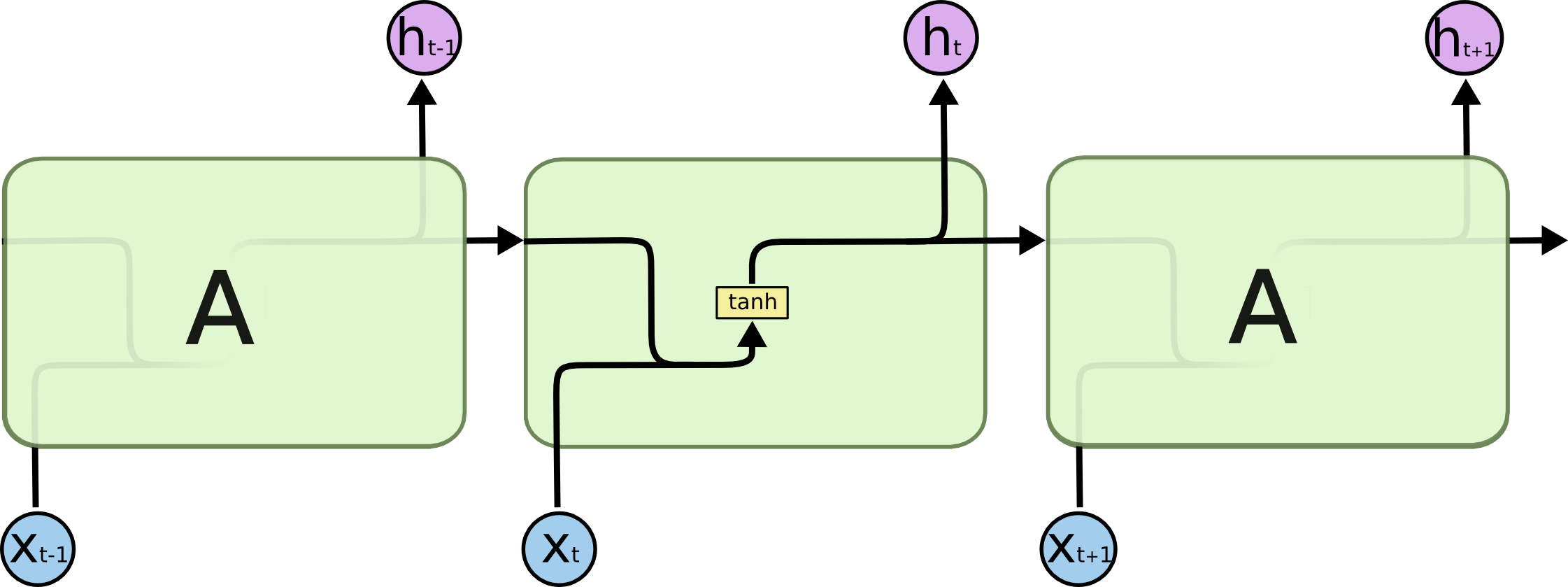
Но память, реализованная подобным образом, получается весьма короткой. Поскольку каждый раз информация в памяти смешивается с информацией в новом сигнале, спустя 5-7 итераций информация уже полностью перезаписывается. Возвращаясь к задаче предсказывания последнего слова в предложении, нужно отметить, что в пределах одного предложения такая сеть будет работать неплохо, но если речь заходит о более длинном тексте, то закономерности в его начале уже не будут вносить какой либо вклад в решения сети ближе к концу текста, также как ошибка на первых элементах последовательностей в процессе обучения перестаёт вносить вклад в общую ошибку сети. Это очень условное описание данного явления, на самом деле это фундаментальная проблема нейронных сетей, которая называется проблема исчезающего градиента, и из-за неё ни много ни мало началась третья «зима» глубокого обучения в конце XX-го века, когда нейронные сети на полтора десятилетия уступили лидерство машинам опорных векторов и алгоритмам бустинга.
Чтобы побороть этот недостаток, была придумана LSTM-RNN сеть (Long Short-Term Memory Recurent Neural Network), в которой были добавлены дополнительные внутренние преобразования, которые оперируют с памятью более осторожно. Вот её схема:
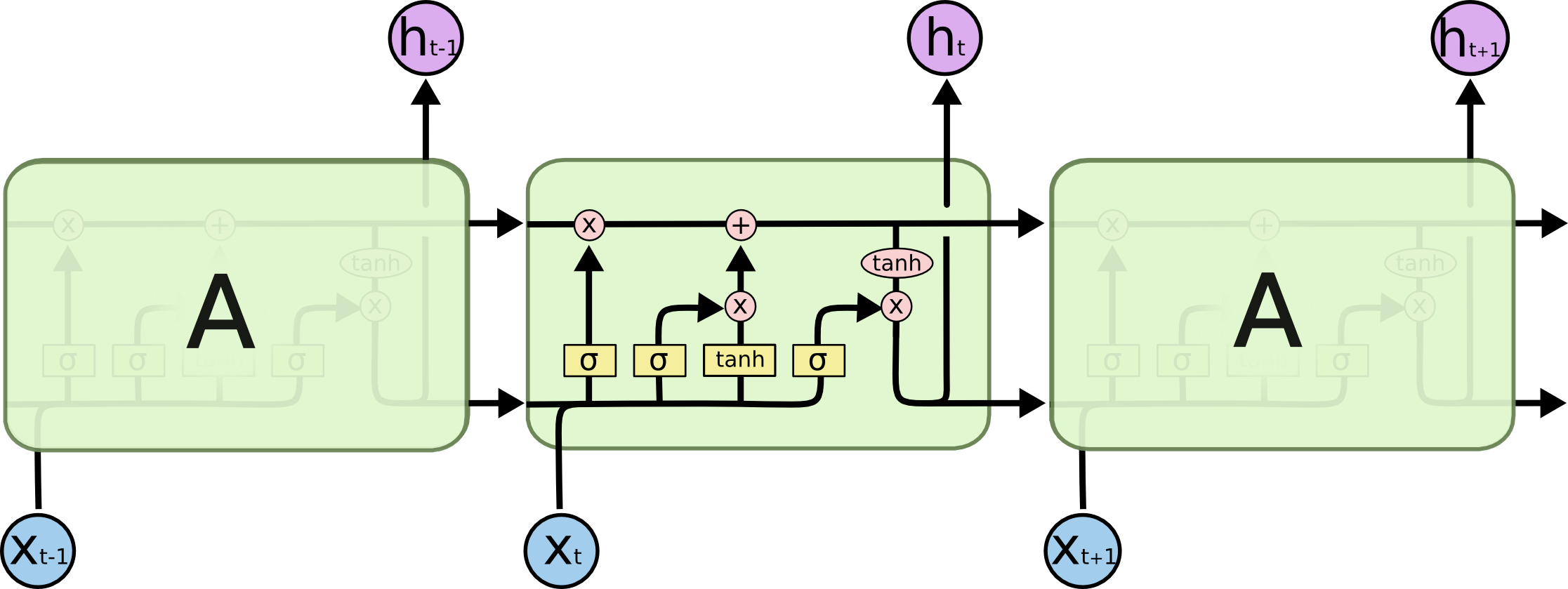
Пройдёмся подробнее по каждому из слоев:
Первый слой вычисляет, насколько на данном шаге ему нужно забыть предыдущую информацию — по сути множители к компонентам вектора памяти.

Второй слой вычисляет, насколько ему интересна новая информация, пришедшая с сигналом — такой же множитель, но уже для наблюдения.
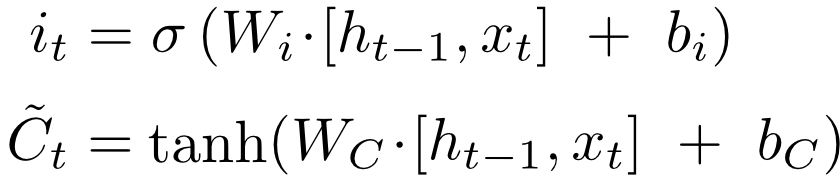
На третьем слое вычисляется линейная комбинация памяти и наблюдения с только вычисленными весами для каждой из компонент. Так получается новое состояние памяти, которое в таком же виде передаётся далее.
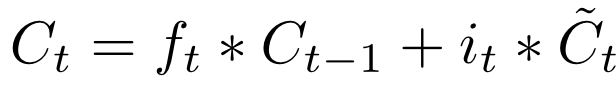
Осталось вычислить output. Но поскольку часть входного сигнала уже в памяти, не нужно считать активацию по всему сигналу. Сначала сигнал проходит через сигмоиду, которая решает, какая его часть важна для дальнейших решений, затем гиперболический тангенс «размазывает» вектор памяти на отрезок от -1 до 1, и в конце эти два вектора перемножаются.

Полученные таким образом ht и Ct передаются далее по цепочке. Безусловно, существует множество вариаций того, какие именно функции активации используются каждым слоем, немного модифицируют сами схемы и прочее, но суть остаётся прежней — сначала забывают часть памяти, затем запоминают часть нового сигнала, а уже потом на основе этих данных вычисляется результат. Картинки я взял отсюда, там также можно посмотреть несколько примеров более сложных схем LSTM.
Не буду здесь подробно рассказывать про то, как такие сети обучаются, скажу только, что используется алгоритм BPTT (Backpropagation Through Time), который является обобщением стандартного алгоритма на случай, когда в сети есть время. Почитать про этот алгоритм можно здесь или здесь.
Есть также успешные примеры использования LSTM-сеток в качестве одного из слоёв в гибридных системах. Вот пример гибридной сети, которая отвечает на вопросы по картинке из серии «сколько изображено книжек?»:

Здесь LSTM-сеть работает в связке с модулем распознавания образов на картинках. Вот здесь доступно сравнение разных гибридных архитектур для решения этой задачи.
Звучит здорово, если бы не тот факт, что Theano сам генерирует и компилирует код на C++. Может это мой предрассудок, но я с большим недоверием отношусь к подобного рода системам, поскольку, как правило, они наполнены невероятном числом багов, которые очень сложно находить, возможно из-за этого я долгое время не уделял должного внимания этой библиотеке. Но Theano был разработан в канадском институте MILA под руководством Yoshua Bengio, одного из самых знаменитых специалистов в области глубокого обучения нашего времени, и за свой пока что недолгий опыт работы с ней, никаких ошибок я, разумеется, не обнаружил.
Тем не менее, Theano это только библиотека для эффективных расчётов, на ней нужно самостоятельно реализовывать backpropagation, нейроны и всё остальное. Например, вот код с использованием только Theano той же сети LSTM, о которой я рассказывал выше, и в нём около 650 строк, что совсем не отвечает заголовку этой статьи. Но может быть я бы никогда и не попробовал поработать с Theano, если бы не удивительная библиотека keras. Являясь по сути только сахаром для интерфейса Theano, она как раз и решает задачу, заявленную в заголовке.
В основе любого кода с использованием keras лежит объект model, который описывает то, в каком порядке и какие именно слои содержит ваша нейросеть. Например, модель, которую мы использовали для оценки тональности твитов про Звёздные войны, принимала на вход последовательность слов, поэтому её тип был
После объявления типа модели, к ней последовательно добавляются слои, например, добавить LSTM-слой можно такой командой:
После того, как все слои добавлены, модель нужно скомпилировать, при желании указав тип функции потерь, алгоритм оптимизации и ещё несколько настроек:
Компиляция занимает пару минут, после этого у модели доступны всем понятные методы fit(), predict(), predict_proba() и evaluate(). Вот так просто, по-моему это идеальный вариант для того, чтобы начать погружаться в глубины deep learning. Когда возможностей keras будет не хватать и захочется, например, использовать собственные функции потерь, можно опуститься на уровень ниже и часть кода написать на Theano. Кстати, если кого-то тоже пугают программы, которые сами генерируют другие программы, в качестве бэкенда к keras можно подключить и свеженький TensorFlow от Google, но работает он пока что заметно медленнее.
Пока они выкачивались, я занялся поиском обучающей выборки. На английском языке в свободном доступе находятся несколько размеченных корпусов твитов, самый крупный из них — стэнфордская обучающая выборка упомянутого в самом начале sentiment140, также есть список небольших датасетов. Но все они на английском языке, а задача ставилась именно для русского. В этой связи хочу высказать отдельную благодарность аспирантке (наверное уже бывшей?) Института систем информатики им. А.П.Ершова СО РАН Юлии Рубцовой, которая выложила в открытый доступ корпус из почти 230 000 размеченных (с точностью более 82%) твитов. Побольше бы нашей стране таких людей, которые на безвозмездной основе поддерживают коммьюнити. В общем, с этим датасетом и работали, почитать о нём и скачать можно по ссылке.
Я очистил все твиты от лишнего, оставив только непрерывные последовательности кириллических символов и чисел, которые прогнал через PyStemmer. Затем заменил одинаковые слова на одинаковые числовые коды, в итоге получив словарь из примерно 100000 слов, а твиты представились в виде последовательностей чисел, они готовы к классификации. Чистить от низкочастотного мусора я не стал, потому что сетка умная и сама догадается, что там лишнее.
Вот наш код нейросети на keras:
За исключением импортов и объявлений переменных вышло ровно 10 строк, а можно было бы и в одну написать. Пробежимся по коду. В сети 6 слоёв:
Для того, чтобы обучение происходило на GPU при выполнении этого кода нужно выставить соответствующий флаг, например так:
На GPU эта самая модель у нас обучалась почти в 20 раз быстрее, чем на CPU — порядка 500 секунд на датасете из 160 000 твитов (треть твитов пошли на валидацию).
Для подобных задач нет каких-то чётких правил формирования топологии сети. Мы честно потратили полдня на эксперименты с различными конфигурациями, и данная показала лучшую точность — 75%. Результат предсказания сетки мы сравнивали с обыкновенной логистической регрессией, которая показывала 71% точности на том же датасете при векторизации текста методом tf-idf и примерно те же самые 75%, но при использовании tf-idf для биграмм. Причина того, что нейросеть почти не обогнала логистическую регрессию скорее всего в том, что обучающая выборка была всё-таки маловата (по-честному для такой сети нужно не меньше 1 млн твитов обучающей выборки) и зашумлена. Обучение проходило всего за 1 эпоху, так как далее мы фиксировали сильное переобучение.
Модель предсказывала вероятность того, что твит позитивный; мы считали положительным отзыв с этой вероятностью от 0.65, отрицательным — до 0.45, а промежуток между ними — нейтральным. В разбивке по дням динамика выглядит следующим образом:
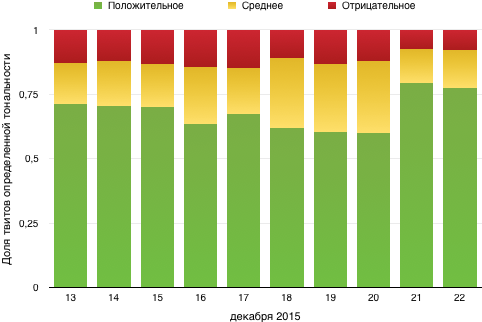
В целом видно, что людям фильм скорее понравился. Хотя лично мне не очень :)
0,9171:
0,8428:
0,8013:
0,7515:
0,6473:
0,6420:
0,6389:
0,5947:
0,1187:
0,1056:
0,0939:
0,0410:
.S. Уже после того, как исследование было проведено, наткнулись на статью, в которой хвалят сверточные сети для решения этой задачи. В следующий раз попробуем их, в keras они также поддерживаются. Если кто-то из читателей решит проверить сам, пишите в комментарии о результатах, очень интересно. Да пребудет с вами Сила больших данных!
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
Что такое RNN?
Основное отличие рекурентных сетей (Recurrent Neural Network, RNN) от традиционных заключается в логике работы сети, при которой каждый нейрон взаимодействует сам с собой. На вход таким сетям как правило передаётся сигнал, являющийся некоторой последовательностью. Каждый элемент такой последовательности поочерёдно передаётся одним и тем же нейронам, которые своё же предсказание возвращают себе вместе со следующим её элементом, до тех пор пока последовательность не закончится. Такие сети, как правило, используются при работе с последовательной информацией — в основном с текстами и аудио/видео-сигналами. Элементы рекурентной сети изображают как обычные нейроны с дополнительной циклической стрелкой, которая демонстрирует то, что кроме входного сигнала нейрон использует также своё дополнительное скрытое состояние. Если «развернуть» такое изображение, получится целая цепочка одинаковых нейронов, каждый из которых получает на вход свой элемент последовательности, выдаёт предсказание и передаёт его дальше по цепочке как своего рода ячейку памяти. Нужно понимать, что это абстракция, поскольку это один и тот же нейрон, который отрабатывает несколько раз подряд. Такая архитектура нейронной сети позволяет решать такие задачи, как, предсказание последнего слова в предложении, например слово «солнце» в фразе «в ясном небе светит солнце». Моделирование памяти в нейронной сети подобным образом вводит новое измерение в описание процесса её работы — время. Пусть нейронная сеть получает на вход последовательность данных, например, текст пословно или слово побуквенно. Тогда каждый следующий элемент этой последовательности поступает на нейрон в новый условный момент времени. К этому моменту в нейроне уже есть накопленный с начала поступления информации опыт. В примере с солнцем в качестве x0 выступит вектор, характеризующий предлог «в», в качестве x1 — слово «небе» и так далее. В итоге в качестве ht должен быть вектор, близкий к слову «солнце».
Основное отличие разных типов рекурентных нейронов друг от друга кроется в том, как обрабатывается ячейка памяти внутри них. Традиционный подход подразумевает сложение двух векторов (сигнала и памяти) с последующим вычислением активации от суммы, например, гиперболическим тангенсом. Получается обычная сетка с одним скрытым слоем. Подобную схему рисуют следующим образом:
Чтобы побороть этот недостаток, была придумана LSTM-RNN сеть (Long Short-Term Memory Recurent Neural Network), в которой были добавлены дополнительные внутренние преобразования, которые оперируют с памятью более осторожно. Вот её схема:
Первый слой вычисляет, насколько на данном шаге ему нужно забыть предыдущую информацию — по сути множители к компонентам вектора памяти.
Не буду здесь подробно рассказывать про то, как такие сети обучаются, скажу только, что используется алгоритм BPTT (Backpropagation Through Time), который является обобщением стандартного алгоритма на случай, когда в сети есть время. Почитать про этот алгоритм можно здесь или здесь.
Использование LSTM-RNN
Рекурентные нейронные сети, построенные на подобных принципах очень популярны, вот несколько примеров подобных проектов:Есть также успешные примеры использования LSTM-сеток в качестве одного из слоёв в гибридных системах. Вот пример гибридной сети, которая отвечает на вопросы по картинке из серии «сколько изображено книжек?»:
Здесь LSTM-сеть работает в связке с модулем распознавания образов на картинках. Вот здесь доступно сравнение разных гибридных архитектур для решения этой задачи.
Theano и keras
Для языка Python существует много очень мощных библиотек для создания нейронных сетей. Не задаваясь целью привести хоть сколько-нибудь полный обзор этих библиотек, хочу познакомить вас с библиотекой Theano. Вообще говоря, из коробки это очень эффективный инструментарий по работе с многомерными тензорами и графами. Доступны реализации большинства алгебраических операций над ними, в том числе поиск экстремумов тензорных функций, вычисление производных и прочее. И всё это можно эффективно параллелить и запускать вычисления с использованием технологий CUDA на видеокарточках.Звучит здорово, если бы не тот факт, что Theano сам генерирует и компилирует код на C++. Может это мой предрассудок, но я с большим недоверием отношусь к подобного рода системам, поскольку, как правило, они наполнены невероятном числом багов, которые очень сложно находить, возможно из-за этого я долгое время не уделял должного внимания этой библиотеке. Но Theano был разработан в канадском институте MILA под руководством Yoshua Bengio, одного из самых знаменитых специалистов в области глубокого обучения нашего времени, и за свой пока что недолгий опыт работы с ней, никаких ошибок я, разумеется, не обнаружил.
Тем не менее, Theano это только библиотека для эффективных расчётов, на ней нужно самостоятельно реализовывать backpropagation, нейроны и всё остальное. Например, вот код с использованием только Theano той же сети LSTM, о которой я рассказывал выше, и в нём около 650 строк, что совсем не отвечает заголовку этой статьи. Но может быть я бы никогда и не попробовал поработать с Theano, если бы не удивительная библиотека keras. Являясь по сути только сахаром для интерфейса Theano, она как раз и решает задачу, заявленную в заголовке.
В основе любого кода с использованием keras лежит объект model, который описывает то, в каком порядке и какие именно слои содержит ваша нейросеть. Например, модель, которую мы использовали для оценки тональности твитов про Звёздные войны, принимала на вход последовательность слов, поэтому её тип был
model = Sequential() После объявления типа модели, к ней последовательно добавляются слои, например, добавить LSTM-слой можно такой командой:
model.add(LSTM(64)) После того, как все слои добавлены, модель нужно скомпилировать, при желании указав тип функции потерь, алгоритм оптимизации и ещё несколько настроек:
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary") Компиляция занимает пару минут, после этого у модели доступны всем понятные методы fit(), predict(), predict_proba() и evaluate(). Вот так просто, по-моему это идеальный вариант для того, чтобы начать погружаться в глубины deep learning. Когда возможностей keras будет не хватать и захочется, например, использовать собственные функции потерь, можно опуститься на уровень ниже и часть кода написать на Theano. Кстати, если кого-то тоже пугают программы, которые сами генерируют другие программы, в качестве бэкенда к keras можно подключить и свеженький TensorFlow от Google, но работает он пока что заметно медленнее.
Анализ тональности твитов
Вернёмся к нашей первоначальной задаче — определить, понравились Звёздные войны российскому зрителю, или нет. Я использовал простенькую библиотеку TwitterSearch, как удобный инструмент для того, чтобы итерироваться по результатам поиска от Twitter. Как и у всех открытых API крупных систем, Twitter имеет определённые ограничения. Библиотека позволяет вызывать callback после каждого запроса, так что очень удобно расставлять паузы. Таким образом выкачалось около 50 000 твитов на русском языке по следующим хештегам:- #starwars
- #звездныевойны
- #star #wars
- #звездные #войны
- #ПробуждениеСилы
- #TheForceAwakens
- #пробуждение #силы
Пока они выкачивались, я занялся поиском обучающей выборки. На английском языке в свободном доступе находятся несколько размеченных корпусов твитов, самый крупный из них — стэнфордская обучающая выборка упомянутого в самом начале sentiment140, также есть список небольших датасетов. Но все они на английском языке, а задача ставилась именно для русского. В этой связи хочу высказать отдельную благодарность аспирантке (наверное уже бывшей?) Института систем информатики им. А.П.Ершова СО РАН Юлии Рубцовой, которая выложила в открытый доступ корпус из почти 230 000 размеченных (с точностью более 82%) твитов. Побольше бы нашей стране таких людей, которые на безвозмездной основе поддерживают коммьюнити. В общем, с этим датасетом и работали, почитать о нём и скачать можно по ссылке.
Я очистил все твиты от лишнего, оставив только непрерывные последовательности кириллических символов и чисел, которые прогнал через PyStemmer. Затем заменил одинаковые слова на одинаковые числовые коды, в итоге получив словарь из примерно 100000 слов, а твиты представились в виде последовательностей чисел, они готовы к классификации. Чистить от низкочастотного мусора я не стал, потому что сетка умная и сама догадается, что там лишнее.
Вот наш код нейросети на keras:
from keras.preprocessing import sequence from keras.utils import np_utils from keras.models import Sequential from keras.layers.core import Dense, Dropout, Activation from keras.layers.embeddings import Embedding from keras.layers.recurrent import LSTM max_features = 100000 maxlen = 100 batch_size = 32 model = Sequential() model.add(Embedding(max_features, 128, input_length=maxlen)) model.add(LSTM(64, return_sequences=True)) model.add(LSTM(64)) model.add(Dropout(0.5)) model.add(Dense(1)) model.add(Activation('sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary") model.fit( X_train, y_train, batch_size=batch_size, nb_epoch=1, show_accuracy=True ) result = model.predict_proba(X) За исключением импортов и объявлений переменных вышло ровно 10 строк, а можно было бы и в одну написать. Пробежимся по коду. В сети 6 слоёв:
- Слой Embedding, который занимается подготовкой фичей, настройки говорят о том, что в словаре 100 000 разных фичей, а сетке ждать последовательности из не более, чем 100 слов.
- Далее два слоя LSTM, каждый из которых отдаёт на выход тензор размерность batch_size / length of a sequence / units in LSTM, а второй отдаёт матрицу batch_size / units in LSTM. Чтобы второй понимал первого, выставлен флаг return_sequences=True
- Слой Dropout отвечает за переобучение. Он обнуляет случайную половину фичей и мешает коадаптации весов в слоях (верим на слово канадцам).
- Dense-слой это обычный линейный юнит, который взвешенно суммирует компоненты входного вектора.
- Последний слой активации загоняет это значение в интервал от 0 до 1, чтобы она стала вероятностью. По сути Dense и Activation в таком порядке это логистическая регрессия.
Для того, чтобы обучение происходило на GPU при выполнении этого кода нужно выставить соответствующий флаг, например так:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python myscript.py На GPU эта самая модель у нас обучалась почти в 20 раз быстрее, чем на CPU — порядка 500 секунд на датасете из 160 000 твитов (треть твитов пошли на валидацию).
Для подобных задач нет каких-то чётких правил формирования топологии сети. Мы честно потратили полдня на эксперименты с различными конфигурациями, и данная показала лучшую точность — 75%. Результат предсказания сетки мы сравнивали с обыкновенной логистической регрессией, которая показывала 71% точности на том же датасете при векторизации текста методом tf-idf и примерно те же самые 75%, но при использовании tf-idf для биграмм. Причина того, что нейросеть почти не обогнала логистическую регрессию скорее всего в том, что обучающая выборка была всё-таки маловата (по-честному для такой сети нужно не меньше 1 млн твитов обучающей выборки) и зашумлена. Обучение проходило всего за 1 эпоху, так как далее мы фиксировали сильное переобучение.
Модель предсказывала вероятность того, что твит позитивный; мы считали положительным отзыв с этой вероятностью от 0.65, отрицательным — до 0.45, а промежуток между ними — нейтральным. В разбивке по дням динамика выглядит следующим образом:
Примеры работы сети
Я выбрал по 5 примеров твитов из каждой группы (указанное число — вероятность того, что отзыв положительный):Позитивная тональность
0,9945:Можно выдыхать спокойно, новые Star Wars олдскульно отличные. Абрамс — крутой, как и всегда. Сценарий, музыка, актёры и съемка — идеально.— snowdenny (@maximlupashko) December 17, 2015
0,9171:
Всем советую сходить на звездные войны супер фильм— николай (@shans9494) December 22, 2015
0,8428:
СИЛА ПРОБУДИЛАСЬ! ДА ПРИБУДЕТ С ВАМИ СИЛА СЕГОДНЯ НА ПРЕМЬЕРЕ ЧУДА, КОТОРОЕ ВЫ ЖДАЛИ 10 ЛЕТ! #TheForceAwakens #StarWars— Vladislav Ivanov (@Mrrrrrr_J) December 16, 2015
0,8013:
Хоть и не являюсь поклонницей #StarWars, но это исполнение чудесно! #StarWarsForceAwakens https://t.co/1hHKdy0WhB— Oksana Storozhuk (@atn_Oksanasova) December 16, 2015
0,7515:
Кто сегодня посмотрел звездные войны? я я я :))— Anastasiya Ananich (@NastyaAnanich) December 19, 2015
Смешанная тональность
0,6476:Новые Звездные войны лучше первого эпизода, но хуже всех остальных— Igor Larionov (@Larionovll1013) December 19, 2015
0,6473:
сюжетный спойлер
Хан Соло умрёт. Приятного просмотра. #звездныевойны— Nick Silicone (@nicksilicone) December 16, 2015
0,6420:
У всех вокруг Звездные войны. Я одна что ли не в теме? :/— Olga (@dlfkjskdhn) December 19, 2015
0,6389:
Идти или не идти на Звездные Войны, вот в чем вопрос — annet_p (@anitamaksova) December 17, 2015
0,5947:
Звездные войны оставили двоякие впечатления. И хорошо и не очень. Местами не чувствовалось что это те самые… что-то чужое проскальзывало— Колот Евгений (@KOLOT1991) December 21, 2015
Негативная тональность
0,3408:Вокруг столько разговоров, неужели только я не фанатею по Звёздным войнам? #StarWars #StarWarsTheForceAwakens— modern mind (@modernmind3) December 17, 2015
0,1187:
они вырвали мое бедное сердце из грудной клетки и разбили его на миллионы и миллионы осколков #StarWars— Remi Evans (@Remi_Evans) December 22, 2015
0,1056:
ненавижу дноклов, проспойлерили мне звездные войны— пижамка найла (@harryteaxxx) December 17, 2015
0,0939:
Проснулась и поняла, что новый Star Wars разочаровал.— Tim Frost (@Tim_Fowl) December 20, 2015
0,0410:
Я разочарован #пробуждениесилы— Eugenjkee; Star Wars (@eugenjkeee) December 20, 2015
.S. Уже после того, как исследование было проведено, наткнулись на статью, в которой хвалят сверточные сети для решения этой задачи. В следующий раз попробуем их, в keras они также поддерживаются. Если кто-то из читателей решит проверить сам, пишите в комментарии о результатах, очень интересно. Да пребудет с вами Сила больших данных!
Телеграм: t.me/ainewsline
Источник: habrahabr.ru