Искусственный интеллект в поиске. Как Яндекс научился применять нейронные сети, чтобы искать по смыслу, а не по словам
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-11-03 09:07
искусственный интеллект, новости нейронных сетей, реализация нейронной сети, поисковые системы

Сегодня мы анонсировали новый поисковый алгоритм «Палех». Он включает в себя все те улучшения, над которыми мы работали последнее время.
Например, поиск теперь впервые использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.
Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
В этом посте я постараюсь немного рассказать о том, как у нас это получилось и почему это не просто ещё один алгоритм машинного обучения, а важный шаг в будущее.
Искусственный интеллект или машинное обучение?
Почти все знают, что современные поисковые системы работают с помощью машинного обучения. Почему об использовании нейронных сетей для его задач надо говорить отдельно? И почему только сейчас, ведь хайп вокруг этой темы не стихает уже несколько лет? Попробую рассказать об истории вопроса.
Поиск в интернете - сложная система, которая появилась очень давно. Сначала это был просто поиск страничек, потом он превратился в решателя задач, и сейчас становится полноценным помощником. Чем больше интернет, и чем больше в нём людей, тем выше их требования, тем сложнее приходится становиться поиску.
Эпоха наивного поиска
Сначала был просто поиск слов - инвертированный индекс. Потом страниц стало слишком много, их стало нужно ранжировать. Начали учитываться разные усложнения - частота слов, tf-idf.
Эпоха ссылок
Потом страниц стало слишком много на любую тему, произошёл важный прорыв - начали учитывать ссылки, появился PageRank.
Эпоха машинного обучения
Интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. Произошёл второй важный прорыв - поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие - нет.
Где-то на этом этапе человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Произошёл следующий переход - поисковики стали активно использовать машинное обучение.
Один из лучших алгоритмов машинного обучения изобрели в Яндексе - Матрикснет. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования пишет машина (получалось около 300 мегабайт).
Но у «классического» машинного обучения есть предел: оно работает только там, где очень много данных. Небольшой пример. Миллионы пользователей вводят запрос [вконтакте], чтобы найти один и тот же сайт. В данном случае их поведение является настолько сильным сигналом, что поиск не заставляет людей смотреть на выдачу, а подсказывает адрес сразу при вводе запроса.
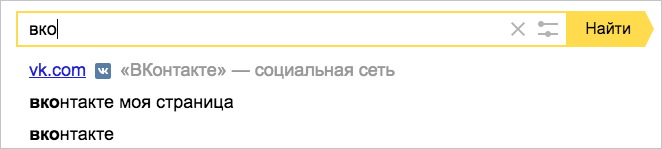
Но люди сложнее, и хотят от поиска всё больше. Сейчас уже до 40% всех запросов уникальны, то есть не повторяются хотя бы дважды в течение всего периода наблюдений. Это значит, что у поиска нет данных о поведении пользователей в достаточном количестве, и Матрикснет лишается ценных факторов. Такие запросы в Яндексе называют «длинным хвостом», поскольку все вместе они составляют существенную долю обращений к нашему поиску.
Эпоха искусственного интеллекта
И тут время рассказать о последнем прорыве: несколько лет назад компьютеры становятся достаточно быстрыми, а данных становится достаточно много, чтобы использовать нейронные сети. Основанные на них технологии ещё называют машинным интеллектом или искусственным интеллектом - потому что нейронные сети построены по образу нейронов в нашем мозге и пытаются эмулировать работу некоторых его частей.
Машинный интеллект гораздо лучше старых методов справляется с задачами, которые могут делать люди: например, распознаванием речи или образов на изображениях. Но как это поможет поиску?
Как правило, низкочастотные и уникальные запросы довольно сложны для поиска - найти хороший ответ по ним заметно труднее. Как это сделать? У нас нет подсказок от пользователей (какой документ лучше, а какой - хуже), поэтому для решения поисковой задачи нужно научиться лучше понимать смысловое соответствие между двумя текстами: запросом и документом.
Легко сказать
Строго говоря, искусственные нейросети - это один из методов машинного обучения. Совсем недавно им была посвящена лекция в рамках Малого ШАДа. Нейронные сети показывают впечатляющие результаты в области анализа естественной информации - звука и образов. Это происходит уже несколько лет. Но почему их до сих пор не так активно применяли в поиске?
Простой ответ - потому что говорить о смысле намного сложнее, чем об образе на картинке, или о том, как превратить звуки в расшифрованные слова. Тем не менее, в поиске смыслов искусственный интеллект действительно стал приходить из той области, где он уже давно король, - поиска по картинкам.
Несколько слов о том, как это работает в поиске по картинкам. Вы берёте изображение и с помощью нейронных сетей преобразуете его в вектор в N-мерном пространстве. Берете запрос (который может быть как в текстовом виде, так и в виде другой картинки) и делаете с ним то же самое. А потом сравниваете эти вектора. Чем ближе они друг к другу, тем больше картинка соответствует запросу.
Ок, если это работает в картинках, почему бы не применить эту же логику в web-поиске?
Дьявол в технологиях
Сформулируем задачу следующим образом. У нас на входе есть запрос пользователя и заголовок страницы. Нужно понять, насколько они соответствует друг другу по смыслу. Для этого необходимо представить текст запроса и текст заголовка в виде таких векторов, скалярное умножение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы хотим обучить нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие векторы, а для семантически несвязанных запросов и заголовков вектора должны различаться.
Сложность этой задачи заключается в подборе правильной архитектуры и метода обучения нейронной сети. Из научных публикаций известно довольно много подходов к решению проблемы. Вероятно, самым простым методом здесь является представление текстов в виде векторов с помощью алгоритма word2vec (к сожалению, практический опыт говорит о том, что для рассматриваемой задачи это довольно неудачное решение).
Дальше - о том, что мы пробовали, как добились успеха и как смогли обучить то, что получилось.
DSSM
В 2013 году исследователи из Microsoft Research описали свой подход, который получил название Deep Structured Semantic Model.
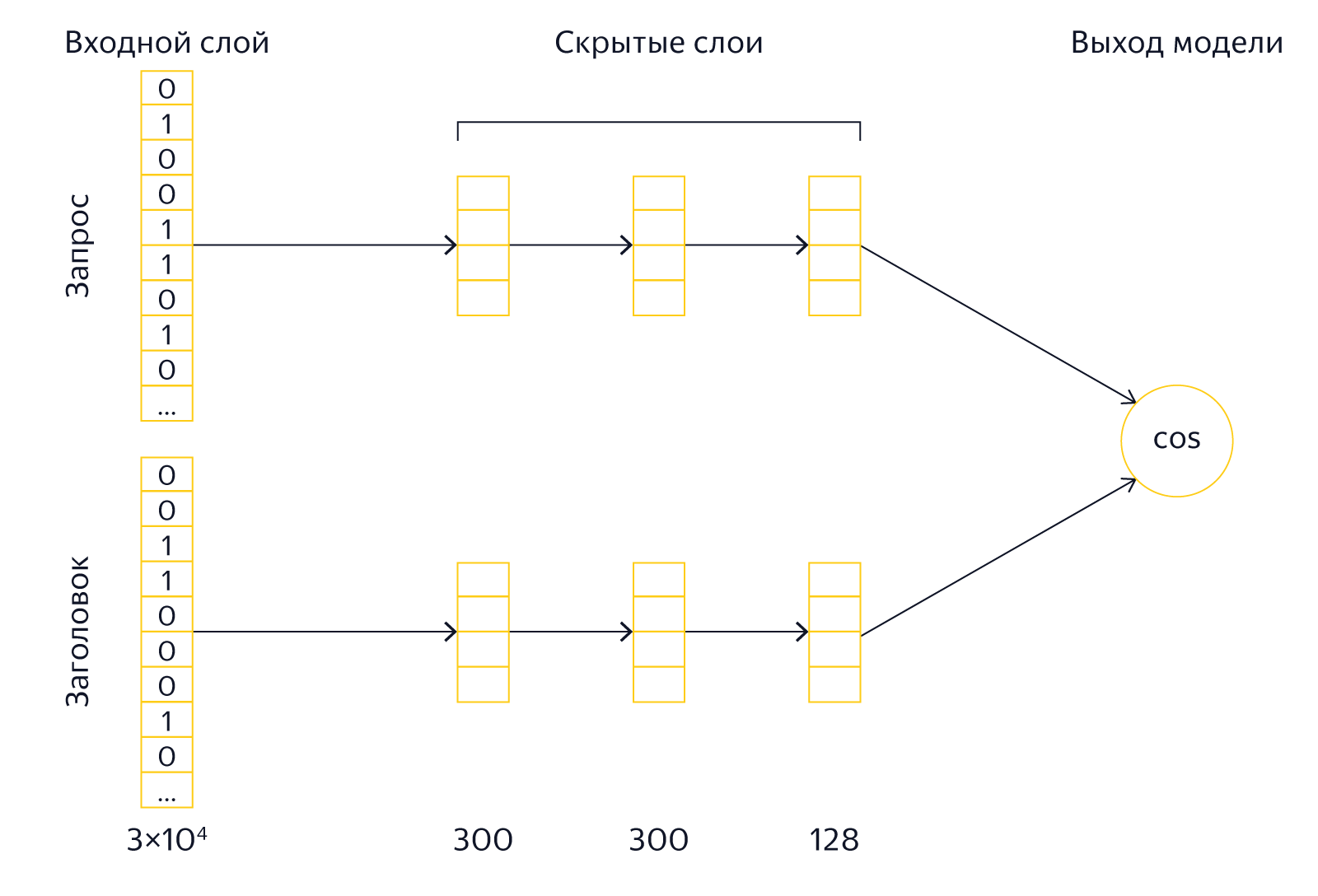
На вход модели подаются тексты запросов и заголовков. Для уменьшения размеров модели, над ними производится операция, которую авторы называют word hashing. К тексту добавляются маркеры начала и конца, после чего он разбивается на буквенные триграммы. Например, для запроса [палех] мы получим триграммы [па, але, лех, ех]. Поскольку количество разных триграмм ограничено, то мы можем представить текст запроса в виде вектора размером в несколько десятков тысяч элементов (размер нашего алфавита в 3 степени). Соответствующие триграммам запроса элементы вектора будут равны 1, остальные - 0. По сути, мы отмечаем таким образом вхождение триграмм из текста в словарь, состоящий из всех известных триграмм. Если сравнить такие вектора, то можно узнать только о наличии одинаковых триграмм в запросе и заголовке, что не представляет особого интереса. Поэтому теперь их надо преобразовать в другие вектора, которые уже будут иметь нужные нам свойства семантической близости.
После входного слоя, как и полагается в глубоких архитектурах, расположено несколько скрытых слоёв как для запроса, так и для заголовка. Последний слой размером в 128 элементов и служит вектором, который используется для сравнения. Выходом модели является результат скалярного умножения последних векторов заголовка и запроса (если быть совсем точным, то вычисляется косинус угла между векторами). Модель обучается таким образом, чтобы для положительны обучающих примеров выходное значение было большим, а для отрицательных - маленьким. Иначе говоря, сравнивая векторы последнего слоя, мы можем вычислить ошибку предсказания и модифицировать модель таким образом, чтобы ошибка уменьшилась.
Мы в Яндексе также активно исследуем модели на основе искусственных нейронных сетей, поэтому заинтересовались моделью DSSM. Дальше мы расскажем о своих экспериментах в этой области.
Теория и практика
Характерное свойство алгоритмов, описываемых в научной литературе, состоит в том, что они не всегда работают «из коробки». Дело в том, что «академический» исследователь и исследователь из индустрии находятся в существенно разных условиях. В качестве отправной точки (baseline), с которой автор научной публикации сравнивает своё решение, должен выступать какой-то общеизвестный алгоритм - так обеспечивается воспроизводимость результатов. Исследователи берут результаты ранее опубликованного подхода, и показывают, как их можно превзойти. Например, авторы оригинального DSSM сравнивают свою модель по метрике NDCG с алгоритмами BM25 и LSA. В случае же с прикладным исследователем, который занимается качеством поиска в реальной поисковой машине, отправной точкой служит не один конкретный алгоритм, а всё ранжирование в целом. Цель разработчика Яндекса состоит не в том, чтобы обогнать BM25, а в том, чтобы добиться улучшения на фоне всего множества ранее внедренных факторов и моделей. Таким образом, baseline для исследователя в Яндексе чрезвычайно высок, и многие алгоритмы, обладающие научной новизной и показывающие хорошие результаты при «академическом» подходе, оказываются бесполезны на практике, поскольку не позволяют реально улучшить качество поиска.
В случае с DSSM мы столкнулись с этой же проблемой. Как это часто бывает, в «боевых» условиях точная реализация модели из статьи показала довольно скромные результаты. Потребовался ряд существенных «доработок напильником», прежде чем мы смогли получить результаты, интересные с практической точки зрения. Здесь мы расскажем об основных модификациях оригинальной модели, которые позволили нам сделать её более мощной.
Большой входной слой
В оригинальной модели DSSM входной слой представляет собой множество буквенных триграмм. Его размер равен 30 000. У подхода на основе триграмм есть несколько преимуществ. Во-первых, их относительно мало, поэтому работа с ними не требует больших ресурсов. Во-вторых, их применение упрощает выявление опечаток и ошибок в словах. Однако, наши эксперименты показали, что представление текстов в виде «мешка» триграмм заметно снижает выразительную силу сети. Поэтому мы радикально увеличили размер входного слоя, включив в него, помимо буквенных триграмм, ещё около 2 миллионов слов и словосочетаний. Таким образом, мы представляем тексты запроса и заголовка в виде совместного «мешка» слов, словесных биграмм и буквенных триграмм.
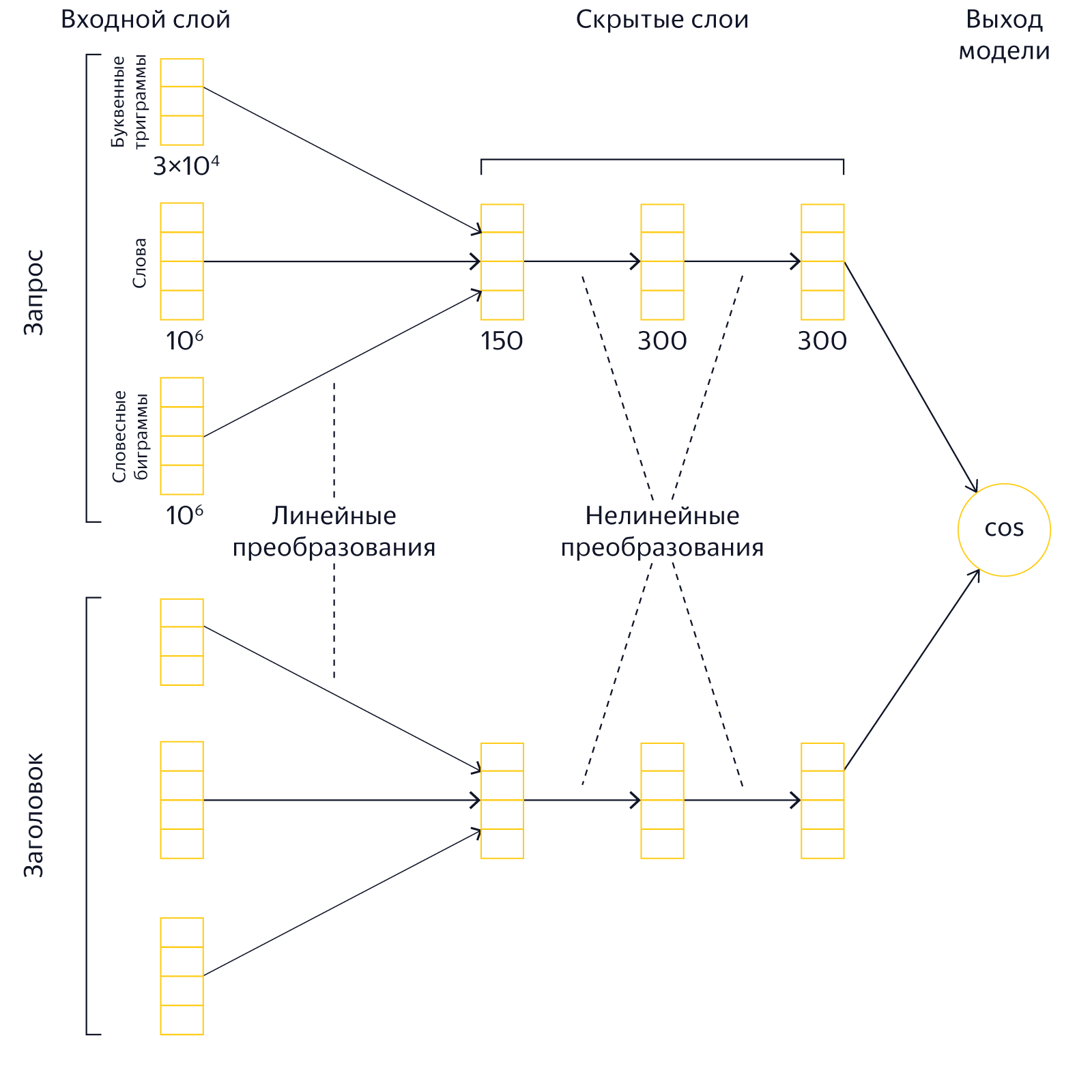
Использование большого входного слоя приводит к увеличению размеров модели, длительности обучения и требует существенно больших вычислительных ресурсов.
Тяжело в обучении: как нейронная сеть боролась сама с собой и научилась на своих ошибках
Обучение исходного DSSM состоит в демонстрации сети большого количества положительных и отрицательных примеров. Эти примеры берутся из поисковой выдачи (судя по всему, для этого использовался поисковик Bing). Положительными примерами служат заголовки кликнутых документов выдачи, отрицательными - заголовки документов, по которым не было клика. У этого подхода есть определённые недостатки. Дело в том, что отсутствие клика далеко не всегда свидетельствует о том, что документ нерелевантен. Справедливо и обратное утверждение - наличие клика не гарантирует релевантности документа. По сути, обучаясь описанным в исходной статье образом, мы стремимся предсказывать аттрактивность заголовков при условии того, что они будут присутствовать в выдаче. Это, конечно, тоже неплохо, но имеет достаточно косвенное отношение к нашей главной цели - научиться понимать семантическую близость.
Во время своих экспериментов мы обнаружили, что результат можно заметно улучшить, если использовать другую стратегию выбора отрицательных примеров. Для достижения нашей цели хорошими отрицательными примерами являются такие документы, которые гарантированно нерелевантны запросу, но при этом помогают нейронной сети лучше понимать смыслы слов. Откуда их взять?
Первая попытка
Сначала в качестве отрицательного примера просто возьмём заголовок случайного документа. Например, для запроса [палехская роспись] случайным заголовком может быть «Правила дорожного движения 2016 РФ». Разумеется, полностью исключить то, что случайно выбранный из миллиардов документ будет релевантен запросу, нельзя, но вероятность этого настолько мала, что ей можно пренебречь. Таким образом мы можем очень легко получать большое количество отрицательных примеров. Казалось бы, теперь мы можем научить нашу сеть именно тому, чему хочется - отличать хорошие документы, которые интересуют пользователей, от документов, не имеющих к запросу никакого отношения. К сожалению, обученная на таких примерах модель оказалась довольно слабой. Нейронная сеть - штука умная, и всегда найдет способ упростить себе работу. В данном случае, она просто начала выискивать одинаковые слова в запросах и заголовках: есть - хорошая пара, нет - плохая. Но это мы и сами умеем делать. Для нас важно, чтобы сеть научилась различать неочевидные закономерности.
Ещё одна попытка
Следующий эксперимент состоял в том, чтобы добавлять в заголовки отрицательных примеров слова из запроса. Например, для запроса [палехская роспись] случайный заголовок выглядел как [Правила дорожного движения 2016 РФ роспись]. Нейронной сети пришлось чуть сложнее, но, тем не менее, она довольно быстро научилась хорошо отличать естественные пары от составленных вручную. Стало понятно, что такими методами мы успеха не добьемся.
Успех
Многие очевидные решения становятся очевидны только после их обнаружения. Так получилось и на этот раз: спустя некоторое время обнаружилось, что лучший способ генерации отрицательных примеров - это заставить сеть «воевать» против самой себя, учиться на собственных ошибках. Среди сотен случайных заголовков мы выбирали такой, который текущая нейросеть считала наилучшим. Но, так как этот заголовок всё равно случайный, с высокой вероятностью он не соответствует запросу. И именно такие заголовки мы стали использовать в качестве отрицательных примеров. Другими словами, можно показать сети лучшие из случайных заголовков, обучить её, найти новые лучшие случайные заголовки, снова показать сети и так далее. Раз за разом повторяя данную процедуру, мы видели, как заметно улучшается качество модели, и всё чаще лучшие из случайных пар становились похожи на настоящие положительные примеры. Проблема была решена.
Подобная схема обучения в научной литературе обычно называется hard negative mining. Также нельзя не отметить, что схожие по идее решения получили широкое распространение в научном сообществе для генерации реалистично выглядящих изображений, подобный класс моделей получил название Generative Adversarial Networks.
Разные цели
В качестве положительных примеров исследователи из Microsoft Research использовались клики по документам. Однако, как уже было сказано, это достаточно ненадежный сигнал о смысловом соответствии заголовка запросу. В конце концов, наша задача состоит не в том, чтобы поднять в поисковой выдаче самые посещаемые сайты, а в том, чтобы найти действительно полезную информацию. Поэтому мы пробовали в качестве цели обучения использовать другие характеристики поведения пользователя. Например, одна из моделей предсказывала, останется ли пользователь на сайте или уйдет. Другая - насколько долго он задержится на сайте. Как оказалось, можно заметно улучшить результаты, если оптимизировать такую целевую метрику, которая свидетельствует о том, что пользователь нашёл то, что ему было нужно.
Профит
Ок, что это нам дает на практике? Давайте сравним поведение нашей нейронной модели и простого текстового фактора, основанного на соответствии слов запроса и текста - BM25. Он пришёл к нам из тех времён, когда ранжирование было простым, и сейчас его удобно использовать за базовый уровень.
В качестве примера возьмем запрос [келлская книга] и посмотрим, какое значение принимают факторы на разных заголовках. Для контроля добавим в список заголовков явно нерелевантный результат.
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0.91 | 0.92 |
| ученые исследуют келлскую книгу вокруг света | 0.88 | 0.85 |
| book of kells wikipedia | 0 | 0.81 |
| ирландские иллюстрированные евангелия vii viii вв | 0 | 0.58 |
| икеа гипермаркеты товаров для дома и офиса ikea | 0 | 0.09 |
Все факторы в Яндексе нормируются в интервал [0;1]. Вполне ожидаемо, что BM25 имеет высокие значения для заголовков, которые содержат слова запроса. И вполне предсказуемо, что этот фактор получает нулевое значение на заголовках, не имеющих общих слов с запросом. Теперь обратите внимание на то, как ведет себя нейронная модель. Она одинаково хорошо распознаёт связь запроса как с русскоязычным заголовком релевантной страницы из Википедии, так и с заголовком статьи на английском языке! Кроме того, кажется, что модель «увидела» связь запроса с заголовком, в котором не упоминается келлская книга, но есть близкое по смыслу словосочетание («ирландские евангелия»). Значение же модели для нерелевантного заголовка существенно ниже.
Теперь давайте посмотрим, как будут себя вести наши факторы, если мы переформулируем запрос, не меняя его смысла: [евангелие из келлса].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0 | 0.85 |
| ученые исследуют келлскую книгу вокруг света | 0 | 0.78 |
| book of kells wikipedia | 0 | 0.71 |
| ирландские иллюстрированные евангелия vii viii вв | 0.33 | 0.84 |
| икеа гипермаркеты товаров для дома и офиса ikea | 0 | 0.10 |
Для BM25 переформулировка запроса превратилась в настоящую катастрофу - фактор стал нулевым на релевантных заголовках. А наша модель демонстрирует отличную устойчивость к переформулировке: релевантные заголовки по-прежнему имеют высокое значение фактора, а нерелевантный заголовок - низкое. Кажется, что именно такое поведение мы и ожидали от штуки, которая претендует на способность «понимать» семантику текста.
Ещё пример. Запрос [рассказ в котором раздавили бабочку].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| фильм в котором раздавили бабочку | 0.79 | 0.82 |
| и грянул гром википедия | 0 | 0.43 |
| брэдбери рэй википедия | 0 | 0.27 |
| машина времени роман википедия | 0 | 0.24 |
| домашнее малиновое варенье рецепт заготовки на зиму | 0 | 0.06 |
Как видим, нейронная модель оказалась способна высоко оценить заголовок с правильным ответом, несмотря на полное отсутствие общих слов с запросом. Более того, хорошо видно, что заголовки, не отвечающие на запрос, но всё же связанные с ним по смыслу, получают достаточно высокое значение фактора. Как будто наша модель «прочитала» рассказ Брэдбери и «знает», что это именно о нём идёт речь в запросе!
А что дальше?
Мы находимся в самом начале большого и очень интересного пути. Судя по всему, нейронные сети имеют отличный потенциал для улучшения ранжирования. Уже понятны основные направления, которые нуждаются в активном развитии.
Например, очевидно, что заголовок содержит неполную информацию о документе, и хорошо бы научиться строить модель по полному тексту (как оказалось, это не совсем тривиальная задача). Далее, можно представить себе модели, имеющие существенно более сложную архитектуру, нежели DSSM - есть основания предполагать, что таким образом мы сможем лучше обрабатывать некоторые конструкции естественных языков. Свою долгосрочную цель мы видим в создании моделей, способных «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека. На пути к этой цели будет много сложностей - тем интереснее будет его пройти. Мы обещаем рассказывать о своей работе в этой области. Cледите за следующими публикациями.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru