YT: зачем Яндексу своя MapReduce-система и как она устроена
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-10-03 17:56
большие данные big data, алгоритмы машинного обучения, кластеризация данных

В течение последних шести лет в Яндексе идет работа над системой под кодовым называнием YT (по-русски мы называем её «Ыть»). Это основная платформа для хранения и обработки больших объемов данных - мы уже о ней рассказывали на YaC 2013. С тех пор она продолжала развиваться. Сегодня я расскажу о том, с чего началась разработка YT, что нового в ней появилось и что ещё мы планируем сделать в ближайшее время.
Кстати, 15 октября в офисе Яндекса мы расскажем не только о YT, но и о других наших инфраструктурных технологиях: Media Storage, Yandex Query Language и ClickHouse. На встрече мы раскроем тайну - расскажем, сколько же в Яндексе MapReduce-систем.
Какую задачу мы решаем?
По роду своей деятельности Яндекс постоянно сталкивается с необходимостью хранить и обрабатывать данные таких объемов, с которыми обычному пользователю никогда не приходится иметь дело. Поисковые логи и индексы, пользовательские данные, картографическая информация, промежуточные данные и результаты алгоритмов машинного обучения - все это может занимать сотни петабайт дискового пространства. Для эффективной обработки подобных объемов традиционно используется парадигма MapReduce, позволяющая достичь хорошего баланса между эффективностью вычислений и простотой пользовательского кода.
В том или ином виде MapReduce-подобные вычисления используются во всех крупнейших компаниях, занимающихся Big Data: Google, Microsoft, Facebook, Yahoo и других. Кроме того, де-факто MapReduce давно стал стандартном при работе с данными гораздо более скромного размера - не в последнюю очередь благодаря удачной open source-реализации во фреймворке Hadoop MapReduce и наличию развитой экосистемы, которая предоставляет удобные аналитические средства поверх MapReduce.
Конечно, далеко не все задачи удачно ложатся на модель MapReduce. Основное ограничение состоит в том, что она предполагает пакетное (batch) выполнение, при котором значительные объемы данных целиком проходят цепочку трансформаций. Эти трансформации занимают минуты, часы, а иногда и многие сутки. Такой способ работы непригоден для интерактивных ответов пользователям, поэтому помимо MapReduce-вычислений традиционно используют системы типа KV-хранилища (key-value storage), позволяющие выполнять чтение и запись данных (а также, возможно, некоторые вычисления над ними) с низкой латентностью. В мире существует много десятков таких систем: начиная с классических RDBMS (Oracle, Microsoft SQL Server, MySQL, PostgreSQL), подходящих для хранения десятков и сотен терабайт данных, и заканчивая NoSQL-системами (HBase, Cassandra), способными работать со многими петабайтами.
В случае с MapReduce наличие нескольких различных и параллельно используемых систем не имеет большого смысла. Дело в том, что все они, по сути, будут решать одну и ту же задачу. Однако для KV-хранилищ степень разнообразия решаемых задач и общий уровень специфики намного выше. В Яндексе мы используем сразу несколько таких систем. Часть данных хранится в MySQL, хорошо зарекомендовавшем себя с точки зрения надежности и разнобразия функций. Там, где объем данных велик и важна скорость их обработки, мы используем ClickHouse - собственную поколоночную DBMS Яндекса. Наконец, последние три года мы активно работали над задачей создания KV-хранилища в рамках YT. Его мы применяем в случае, когда необходима высокая надежность хранения, поддержка транзакционности, а также интеграция с MapReduce-вычислениями.
Почему бы не использовать стек Hadoop?
Для значительной части нашей собственной Big Data-инфраструктуры существуют общедоступные продукты, решающие похожие задачи. В первую очередь, конечно, речь идет об экосистеме Hadoop, на основе которой - в теории - можно построить весь стек вычислений: начиная с распределенной файловой системы (HDFS) и MapReduce-фреймворка и заканчивая KV-хранилищами (HBase, Cassandra), инструментами для аналитики (Hive, Impala) и системами обработки потоков данных (Spark).
Для компаний малого и среднего размера, работающих с Big Data, Hadoop часто является безальтернативным выбором. Крупные игроки, в свою очередь, либо активно используют и развивают Hadoop (так поступили, например, Yahoo и Facebook), либо создают собственную инфраструктуру (Google, Microsoft).
Выбирая между этими двумя возможностями, Яндекс пошёл по второму пути. Решение это далось непросто, и, безусловно, его нельзя расценивать как единственно верное. В расчет было принято множество факторов. Постараемся кратко резюмировать наиболее значимые:
- Так сложилось исторически, что в Яндексе наибольший объем вычислительного кода пишется на C++; при этом Hadoop существенно ориентирован на Java-платформу. Само по себе это не фатально - всегда можно написать адаптеры поддержки старого кода для С++, а новый развивать на Java. Однако стоит признать, что в компании за годы развития накопился немалый опыт именно в работе с С++, а Java-разработка представлена намного скромнее.
- Примеры успешного использования Hadoop в компаниях типа Yahoo и Facebook показывают, что для эффективного использования Hadoop обычно не берется его ванильная версия, а выполняется форк с последующей глубокой доработкой. Для его создания крайне желательно, а то и необходимо наличие в компании core-разработчиков Hadoop. Эти специалисты крайне редки даже по меркам американского IT-рынка, так что для Яндекса их найм в достаточном количестве - очень сложная задача.
- Возможно, указанный выше форк платформы никогда и не будет влит в основную ветку разработки и перестанет быть совместимым с этой веткой. Тогда преимущество от использования готовых решений экосистемы будет ограничено двумя наборами инструментов: которые получится «забрать с собой» в момент отделения и которые удастся перенести поверх форка.
- Но зачем вообще делать форк Hadoop? Почему бы не использовать публично доступные и развиваемые версии, по возможности участвуя в их разработке? Дело в том, что, хотя Hadoop сам по себе весьма неплох, он далеко не идеален. За время работы над собственной инфраструктурой в Яндексе мы неоднократно сталкивались с задачами, решить которые получалось лишь ценой весьма радикальных изменений наших систем. Поскольку мы не обладаем достаточной компетенцией в Hadoop-разработке, то не можем внести такие обширные изменения в публичные ветки. Подобные радикальные патчи практически наверняка не смогут пройти code review за разумное время.
- Ещё можно было бы предположить, что для полноценной интеграции Hadoop в рамках компании необязательно иметь в штате высококвалифицированных специалистов по этой платформе - достаточно ограничиться услугами крупных интеграторов Hadoop-решений, например Cloudera. Однако здравый смысл и опыт близких нам по роду деятельности компаний показывает: хоть такая помощь и может быть полезной на первом этапе внедрения, сложные задачи, требующие значительных доработок кодовой базы Hadoop, все равно пришлось бы решать самостоятельно (см., например, опыт Mail.Ru).
Конечно, отказавшись от переиспользования готовых Hadoop-инструментов, мы сильно усложили себе задачу, поскольку нет никакой возможности соревноваться с Hadoop-сообществом, насчитывающим многие сотни и тысячи разработчиков по всему миру. С другой стороны, как указано выше, фактическая невозможность получить по разумной цене критически важные для Яндекса изменения в экосистеме, а также опыт использующих Hadoop компаний перевесили все плюсы.
С учетом сделанного выбора мы вынуждены активно работать над наиболее актуальными для нас частями инфраструктуры, вкладывая основные силы в улучшение небольшого числа ключевых систем: самой платформы YT, а также создаваемых поверх нее инструментов.
Что мы сейчас умеем?
Из написанного выше вытекает, что YT как минимум представляет собой MapReduce-систему. Это правда, представляет, но далеко не вся. С самого рождения YT проектировалась с прицелом на то, чтобы стать основой для решения широкого спектра вычислительных задач в области Big Data.
За те три года, что прошли со дня доклада про YT на YaC, система претерпела значительное развитие. Многие из упомянутых тогда проблем успешно решены. Впрочем, нам не доводится скучать, поскольку компания (а вместе с ней и инфраструктура) активно развивается. Так что новые задачи прибывают с каждым днем.
Опишем кратко текущую архитектуру YT.
Кластер
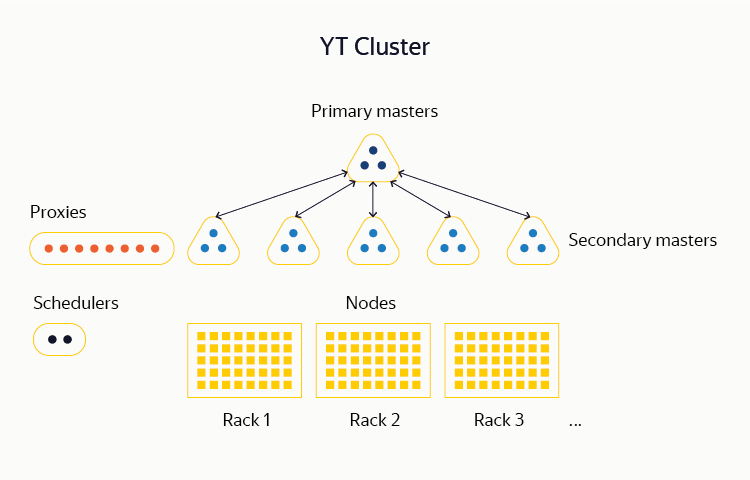
YT - многокомпонентная система, единицей развертывания которой является кластер. Сейчас мы поддерживаем кластеры с общим числом серверов (нодов) до 10 000. На таком количестве машин мы можем хранить сотни петабайт данных, а также планировать и производить вычисления на сотнях тысяч CPU-ядер.
Большинство наших YT-кластеров целиком располагаются внутри одного дата-центра. Сделано это потому, что в процессе MapReduce-вычислений важно иметь гомогенную сеть между машинами, чего в наших масштабах практически невозможно достичь, если они разделены географически. Из этого правила есть исключения: некоторые кластеры YT, в которых внутренние потоки данных невелики, все же распределены между несколькими ДЦ. Так что полный выход из строя одного или нескольких из них не оказывает влияние на работу системы.
DFS
Самый нижний слой YT образует распределенная файловая система (DFS). Ранние реализации DFS были похожи на ставшими классическими HDFS или GFS. Данные хранятся на дисках нод кластера в виде небольших (обычно до 1 ГБ) фрагментов, называемых чанками. Информация обо всех имеющихся в системе чанках, а также о том, какие файлы и таблицы присутствуют в DFS и из каких чанков они состоят, располагается в памяти мастер-серверов.
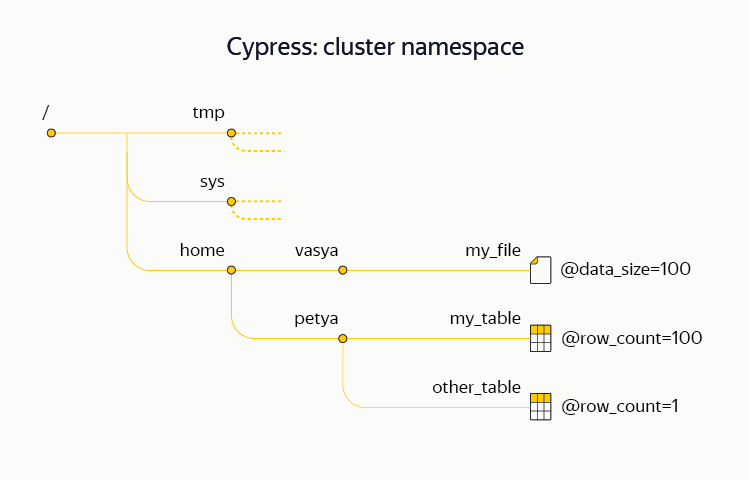
Пространство имен (структура каталогов, имена файлов и таблиц в них, метаатрибуты, права доступа и т. д.) нашей DFS носит название Кипарис. В отличие от большинства традиционных файловых систем, Кипарис поддерживает транзакционность, то есть позволяет атомарно выполнять сложные операции со своей структурой и данными. К примеру, в рамках транзакции Кипариса есть возможность атомарно залить в систему несколько файлов, а также отметить в метаатрибутах факт поступления новой порции данных. Также Кипарис поддерживает систему блокировок на узлах. Эту возможность мы активно используем на практике: один из кластеров YT распределен между дата-центрами и практически не хранит чанков, но его Кипарис используется различными инфраструктурными процессами в качестве высокодоступного хранилища метаданнных и сервиса координации (аналогичного Chubby, Zookeeper или etcd).
С учетом количества машин, из которых состоят кластеры, отказы оборудования происходят каждый день и не представляют из себя уникальное явление. Система проектируется так, чтобы переживать большинство видов типичных отказов в автоматическим режиме, без участия человека. В частности, в системе отсутствуют так называемые единственные точки отказа (SPoF, single point of failure), то есть ее работу невозможно нарушить поломкой одного сервера. Более того, с практической точки зрения важно, чтобы система продолжала работать в ситуации, когда одновременно вышли из строя бёльшие по размеру случайные подмножества (например два случайно выбранных сервера в кластере) или даже целые структурные группы машин (скажем стойки).
Для распределенной DFS мастер-сервер, если он один, образует собой естественную SPoF, так как при его отключении система перестает быть способна принимать и отдавать данные. Поэтому с самого начала мастер-сервера были реплицированы. В простейшем случае можно считать, что вместо одного мастер-сервера мы имеем три, состояние которых поддерживается идентичным. Система способна продолжить работать при выходе из строя любого из трех мастер-серверов. Подобные переключения происходят полностью автоматически и не вызывают даунтайма. Синхронизация между набором мастер-серверов обеспечивается с помощью одной из разновидностей алгоритма консенсуса. В нашем случае мы используем библиотеку собственной разработки - она называется Hydra. Ближайшим open source-аналогом Hydra служит алгоритм Raft. Близкие идеи (алгоритм ZAB) используются в системе Apache Zookeeper.

Описанная схема с тремя реплицированными мастер-серверами хороша с точки зрения отказоустойчивости, но не позволяет масштабировать кластер до нужных нам объемов. Дело в том, что в плане объема метаданных мы остаемся ограничены памятью отдельного мастер-сервера. Поэтому примерно год назад мы реализовали прозрачную для пользователя систему шардирования метаданных чанков, которую мы называем multicell. При ее использовании метаданные разделяются (как говорят, шардируются) между различными триплетами мастер-серверов. Внутри каждого триплета по-прежнему работает Hydra, обеспечивая отказоустойчивость.
Отметим, что шардирование метаданных чанков в рамках HDFS сейчас не предусмотрено. Вместо него предлагается использовать менее удобную HDFS-федерацию - проект сомнительной полезности, т. к. для малых объемов данных он не имеет смысла, а опыт его применения в крупных компаниях, по имеющимся данным, не всегда положителен.
Отказоустойчивость, конечно, важна не только на уровне метаданных, но и на уровне данных, хранящихся в чанках. Для достижения этой цели мы используем два метода. Первый - репликация, то есть хранение каждого чанка в нескольких (обычно трех) копиях на различных серверах. Второй - erasure-кодирование, то есть разбиение каждого чанка на небольшое число частей, вычисление дополнительных частей с контрольными суммами и хранение всех этих частей на различных серверах.

Последний метод особенно интересен. Если при использовании обычной тройной репликации для хранения объема X необходимо потратить еще 2X под дополнительные реплики, то при использовании подходящих erasure-кодов этот оверхед снижается до X/2. С учетом тех объемов, с которыми приходится иметь дело нам (это десятки и сотни петабайт) выигрыш оказывается колоссальным. В рамках имеющихся у нас систем erasure-кодирование доступно уже порядка четырех лет. Отметим, что аналогичная поддержка в Hadoop (т. н. EC-HDFS) стала доступна лишь менее года назад.
Таблицы
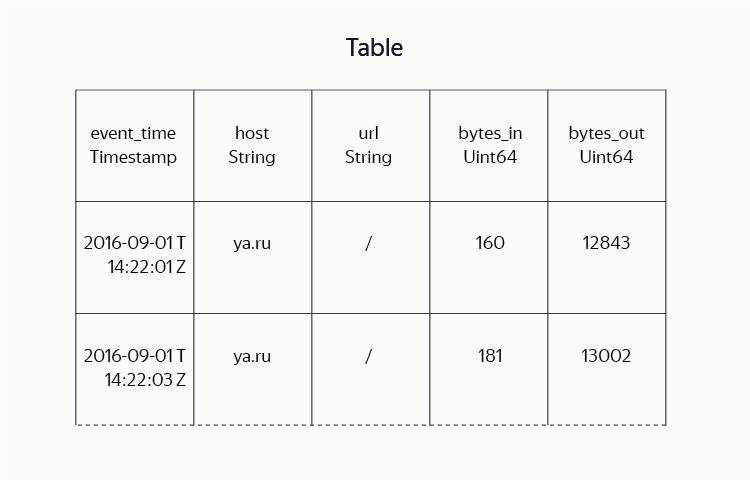
В отличие от связки HDFS с Hadoop Mapreduce, где основной видимой пользователю единицей хранения является файл, в YT DFS файлы хотя и присутствуют, но используются не так активно. Вместо этого данные в основном хранятся в таблицах - наборах строк, состоящих из колонок с данными. За время разработки системы мы потратили немало сил на то, чтобы добиться эффективного и компактного хранения данных в таблицах. Мы сочетаем идеи поколоночных форматов хранения (Hadoop ORC, Parquet) с разнообразием блочных алгоритмов компрессии (lz4, gzip, brotli и др.).
Для пользователя подобные детали реализации прозрачны: он просто задает схему таблицы (указывает имена и типы колонок), желаемый алгоритм сжатия, метод репликации и т. д. Там, где в Hadoop пользователи вынуждены представлять таблицы в виде набора файлов, содержащих данные в определенном формате, пользователи YT оперируют терминами таблиц в целом и их частей: выполняют сортировки, map-, reduce- и join-операции, читают таблицы по диапазонам строк и т. д.
MapReduce-планировщик
Бёльшая часть вычислений над хранящимися у нас данными выполняется в модели MapReduce. Как уже было указано, общий пул вычислительных мощностей кластера составляет сотни тысяч ядер. Их использование контролируется центральным планировщиком. Он разбивает большие вычисления (называемые операциями) вроде map, sort, reduce и т. д. на отдельные локальные части (джобы), распределяет ресурсы между ними, контролирует их выполнение и обеспечивает отказоустойчивость путем перезапуска части вычислений при сбоях.
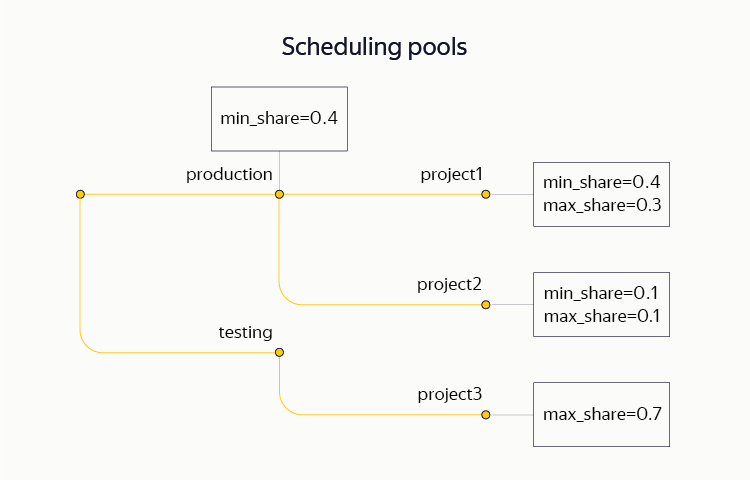
Мы выделяем два основных ресурса для планирования: СPU и память. Для разделения ресурсов между операциями мы применяем весьма гибкую схему, Hierarchical Dominant Resource Fair Share, позволяющую группировать вычисления в древовидную структуру и задавать ограничения (нижние и верхние) на отдельных поддеревьях. В частности, в рамках единого кластера различные проекты одновременно держат как production-, так и testing-контуры. На том же кластере часть ресурсов выделяется для ad hoc-аналитики.
За сутки на типичном большом кластере YT выполняется более 250 тыс. операций, суммарно состоящих из 100 млн джобов.
В данный момент активный планировщик в кластере всегда один, но для отказоустойчивости в системе всегда есть пассивные standby-реплики. При выходе из строя основного планировщика за время порядка десятка секунд происходит переключение на другую его реплику. Последняя восстанавливает состояние вычислительных операций и продолжает их выполнение.
Сейчас планировщик - это единственная наиболее критично нагруженная машина всего кластера. Код планировщика многократно оптимизировался с учетом количества джобов (сотни тысяч) и операций (тысячи), которыми приходится одновременно управлять. Нам удалось добиться высокой степени его параллельности, так что сейчас мы фактически полностью используем ресурсы одной машины. Впрочем, для дальнейшего роста размеров кластера такой подход кажется тупиковым, поэтому мы активно работаем над созданием нового распределенного планировщика.
В настоящий момент MapReduce-слой YT ежедневно используется многими сотнями разработчиков, аналитиков и менеджеров Яндекса для выполнения аналитических вычислений над данными. Также им пользуются десятки разнообразных проектов, которые в автоматическом режиме готовят данные для наших основных сервисов.
KV-хранилище
Как уже было сказано несколько раз, MapReduce-вычисления не покрывают весь спектр стоящих перед нами задач. Классические MapReduce-таблицы (мы называем их статическими) отлично подходят для эффективного хранения больших объемов данных и их обработки в MapReduce-операциях. С другой стороны - они не способы заменить собой KV-хранилище. Действительно, типичное время чтения строки из статической таблицы измеряется сотнями миллисекунд. Запись в такую таблицу занимает не меньше, да и вовсе возможна только в конец, так что ни о каком использовании подобных таблиц для создания интерактивных сервисов говорить не приходится.
Примерно три года назад мы в рамках YT начали работать над созданием новых динамических таблиц, подобных тем, что можно найти в системах вроде HBase и Cassandra. Для этого нам потребовалось провести множество доработок базовых слоев (Hydra, DFS). В результате мы действительно имеем возможность в рамках общего с MapReduce пространства имен создавать для пользователя динамические таблицы. Они поддерживают эффективные операции чтения и записи строк и их диапазонов по первичному ключу. Нашу систему отличает транзакционность и строгая консистентность (т. н. уровень изоляции snapshot), а также поддержка распределенных транзакций - то есть возможность в одной транзакции атомарно изменить несколько строк одной таблицы или даже нескольких различных таблиц.
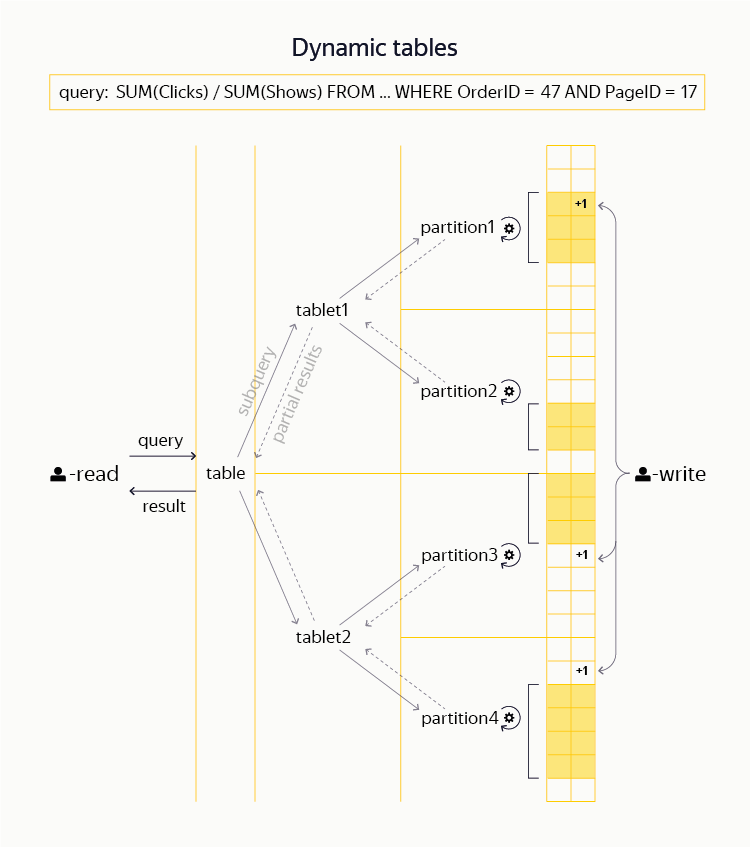
С точки зрения ближайших аналогов наши динамические таблицы близки к классическим идеям BigTable и HBase, но адаптированы для поддержки более сильной модели транзакционности. При этом, несмотря на похожие базовые принципы, нам не кажется реалистичной возможность добавить подобную функциональность в имеющиеся open source-системы, скажем в HBase, путем коммита патчей. (Например, см. тикет, в котором обсуждается портирование части кода из проекта HydraBase, развиваемого в Facebook, в HBase. Пример особенно показателен тем, что функциональность HydraBase, повышающая доступность системы за счет горячей репликации регион-серверов, чрезвычайно важна для наших приложений, и мы поддерживаем ее внутри YT.)
Поверх данных таблиц мы также имеем возможность распределенно выполнять интерактивные запросы, в том числе фильтрацию, агрегацию и простейшие виды джойнов. (Среди общедоступных систем подобные возможности предоставляет, например, Impala или Presto.) В Яндексе крупнейшим пользователем динамических таблиц является Баннерная система, хранящая там информацию о кликах и показах рекламных объявлений и обеспечивающая рекламодателям возможность проводить аналитику своих кампаний. Как и любое приличное распределенное KV-хранилище, YT способен обслуживать многие миллионы операций чтения и записи в секунду.
Каковы наши планы?
Даже из описания выше легко понять, что система активно развивается. Действительно, с учетом масштаба и амбициозности стоящих перед нами задач сложно придумать хоть один аспект системы, который нельзя было бы улучшить, получив на выходе ясную и хорошо измеримую пользу.
В заключительной части стоит выделить еще ряд долгосрочных проектов развития, которыми мы занимаемся в рамках YT.
Кросс-датацентровая репликация
Компании масштаба Яндекса не могут себе позволить быть зависимыми от единственного дата-центра, и фактически кластера YT развернуты сразу в нескольких. Задача синхронизации данных между ними - одновременно сложная и важная, т. к. позволяет переложить часть забот об отказоустойчивости с высокоуровневых сервисов на основную инфраструктуру.
В случае, когда хранимые объемы данных малы, мы традиционно разворачиваем кросс-датацентровые инсталляции YT, способные переживать выпадения дата-центров целиком. С другой стороны, у этого подхода есть ряд недостатков. В частности, развитие и обновление подобных кросс-датацентровых инсталляций - весьма нетривиальное занятие. Дело в том, что требуется по возможности обеспечить близкий к 100% uptime.
Система из набора полунезависимых кластеров, по одному в каждом дата-центре, смотрится более удобной с эксплуатационной точки зрения. Поэтому мы часто используем отдельные кластеры с настроенными автоматическими процессами репликации данных между статическими таблицами в них.
Мы также учимся реплицировать динамические таблицы - это позволяет реализовывать различные режимы репликации (синхронную, асинхронную) и кворумную запись в набор дата-центров.
Дальнейшее масштабирование мастер-серверов
Итак, в YT мы научились шардировать часть метаданных мастер-сервера, относящуюся к чанкам. Но пользователи в большинстве случаев работают не с чанками напрямую, а деревом файлов, таблиц и каталогов - то есть с Кипарисом. Это дерево мы по-прежнему храним в памяти одного мастер-сервера (трех с учетом репликации), что естественным образом ограничивает количество узлов в нем на уровне порядка 100 млн. По мере роста числа пользователей и расширения кластеров нам, вероятно, придется решать задачу шардирования этой части метаданных.
Интеграция статических и динамических таблиц
Несмотря на то, что изначально динамические таблицы создавались «в стороне» от MapReduce-модели и статических таблиц, довольно быстро стала понятна польза от возможности сочетать эти инструменты в рамках одного вычисления.
К примеру, можно построить длинной цепочкой MapReduce-вычислений статическую таблицу с индексом для какого-либо сервиса, а затем легким движением руки превратить её в динамическую, загрузить в память и дать фронтенду сервиса возможность забирать интересующие его данные с латентностью, измеряемой миллисекундами.
Или, скажем, есть возможность в процессе выполнения сложного MapReduce-вычисления обращаться за справочными данными к динамической таблице, выполняя так называемый map-side join.
Интеграция динамики и статики в рамках YT - это большой и сложный проект, который сейчас еще далек от завершения, однако он позволяет радикально упростить и оптимизировать решение ряда задач, по традиции считающихся сложными.
Облачные мощности
Не секрет, что значительную часть парка серверов Яндекса составляют так называемые поисковые кластеры, состоящие из машин, непосредственно хранящих данные поискового индекса и отвечающих на запросы пользователей. Профиль нагрузки таких машин весьма характерен. Если в случае c основными MapReduce-кластерами YT узким местом почти всегда является CPU (который показывает практически 100-процентную загрузку 24/7), то на поисковом кластере CPU-нагрузка заметно меняется - например, в зависимости от времени дня.
Это открывает возможность использовать высвобождающиеся мощности для выполнения MapReduce-вычислений. Они тем самым частично оказываются перенесены в поисковое облако динамически меняющихся размеров. Эффективное использование таких дополнительных мощностей - еще один приоритетный для нас проект. Для его успеха необходимо развивать систему управления кластерами, контейнеризизации и разделения общих между проектами ресурсов (к ним относятся память, CPU, сеть и диск).
Телеграм: t.me/ainewsline
Источник: habrahabr.ru