Постановка задачи компьютерного зрения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-10-24 17:11

Последние лет восемь я активно занимаюсь задачами, связанными с распознаванием образов, компьютерным зрением, машинным обучением. Получилось накопить достаточно большой багаж опыта и проектов (что-то своё, что-то в ранге штатного программиста, что-то под заказ). К тому же, с тех пор, как я написал пару статей на Хабре, со мной часто связываются читатели, просят помочь с их задачей, посоветовать что-то. Так что достаточно часто натыкаюсь на совершенно непредсказуемые применения CV алгоритмов.
Но, чёрт подери, в 90% случаев я вижу одну и ту же системную ошибку. Раз за разом. За последние лет 5 я её объяснял уже десяткам людей. Да что там, периодически и сам её совершаю-
В 99% задач компьютерного зрения то представление о задаче, которое вы сформулировали у себя в голове, а тем более тот путь решения, который вы наметили, не имеет с реальностью ничего общего. Всегда будут возникать ситуации, про которые вы даже не могли подумать. Единственный способ сформулировать задачу - набрать базу примеров и работать с ней, учитывая как идеальные, так и самые плохие ситуации. Чем шире база-тем точнее поставлена задача. Без базы говорить о задаче нельзя.
Тривиальная мысль. Но все ошибаются. Абсолютно все. В статье я приведу несколько примеров таких ситуаций. Когда задача поставлена плохо, когда хорошо. И какие подводные камни вас ждут в формировании ТЗ для систем компьютерного зрения.
Первые примеры
Плохие
Одна из самых частых идей, про которую меня спрашивают (даже предлагали взяться) - это распознавание этикеток в магазинах: "Добрый день! Я придумал классный стартап: человек приходит в магазин, снимает ценник, мы находим товар, цену и смотрим в каком магазине товар самый дешевый! Я всё уже сделал, но остался только модуль распознавания!". За последние два года с аналогичными предложениями мне писали раз пять-
И действительно! В сознании человека, который редко сталкивается с задачами распознавания, есть чёткая картина: «Распознать строчку текста на этикетке - это расплюнуть!». Ведь есть ABBYY, которые распознают текст страницами, есть Smart Engines (1, 2), у которых и карточки с кучей цифр распознаются, и этикетки даже! Задача давно решена! Какая разница, Ikea или Ашан? Все этикетки похожи, единый модуль справится.
Обычно после такого хочется сказать человеку: "Сходите в три разных сети, сделайте десять кадров и посмотрите на них". На что обычно можно получить ответ: "Что я там не видел! Вчера был в Перекрёстке и смотрел на них!".
Посмотрим?








Это не самые плохие примеры (фотографии кликабельны). На всех примерах тут человек может прочитать/додумать информацию. А машина?
- Фотографии часто нерезкие, текст расплывается и сливается. Зачастую буквы написаны так близко друг к другу, что сегментация практически невозможна.
- По краям ценников очень много артефактов, часто буквы обрезаны, или по ним идёт полоса.
- Если съёмка со вспышкой - будут блики, часто полностью перекрывающие текст.
- На одном ценнике часто 2-3 цены, написанные разными шрифтами (а часто ценники могут стоять в упор друг к другу).
- Шрифт изменяется даже в пределах одной торговой сети.
- Формат ценников изменяется даже в пределах одной торговой сети.
Некоторые, особо упёртые продолжают настаивать: «Вы всё придумали! Вот есть пост у Smart Engines, где всё работает и ценники распознаются!»
И действительно! Замечательный пример корректно поставленной задачи: ищется прямоугольник заданного размера, на красном фоне, шрифт один и тот же. Определив границы прямоугольника можно примерно уже сегментировать код. Эвристика есть, но минимальная: связать три блока на картинке, расположенных в известном порядке.
Да: будут пересветы, будут блики, уголки могут быть загнуты, кто-то черканёт на ценнике свой автограф, а у кого-то камера всегда выдаёт нерезкие кадры. Но когда вы знаете положение каждой цифры, всё остальное уже не так важно. И в большинстве случаев всё будет работать замечательно.
N.B. Я не говорю, что задача распознавания ценников не решаема в общем случае. Решаема. И сегодняшний прогресс делает это решение всё ближе и ближе. Google уже распознаёт номера домов. А ABBYY настраивается под любой заранее заданный формат текста. Но решение такой задачи находится на границе современных технологий, решение будет неидеально, или будет требовать огромного времени и средств на разработку. Конечно, можно сделать распознавание цены на ценниках (без текста) и такая система будет неплохо работать на некоторых ценниках. А иногда можно прочитать штрих-код (из приведённых ценников открытым форматом штрих-код написан на одном). Часто есть способы срезать углы и упростить постановку задачи.
Отвлечёмся от этикеток
Вы скажете что это примеры из воздуха и что так не бывает?.. Приведу пример который даже публиковался на Хабре: habrahabr.ru/post/265209.
Прежде чем читать дальше, попробуйте понять, почему метод не будет работать.
- Для тех кому лень читать. Автор предлагает ставить клеймо на дерево из трёх точек. И считает, что пересечения прямых между точками с годичными кольцами позволят однозначно маркировать и классифицировать бревно с камеры.
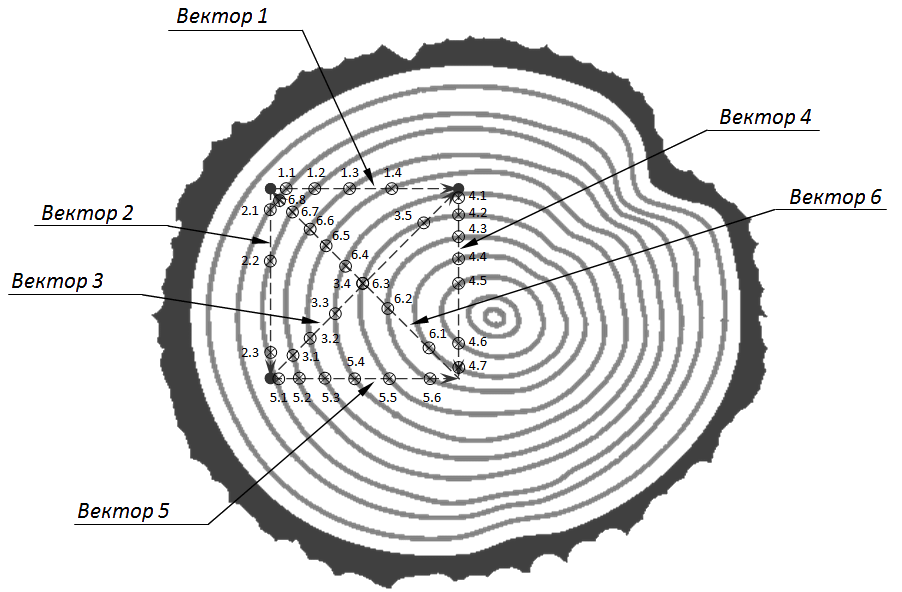
Вот такую красивую картинку он приводит. Метод сразу ясен и понятен. Неправда ли?
- Сам автор статьи обращался ко мне где-то за неделю до публикации с вопросом, будет ли это всё работать. Я сказал, что скорее всего не будет, привел несколько примеров, а так же сказал, как нужно модифицировать алгоритм, чтобы всё заработало. Но статью он написал в ключе, что это рабочий метод. И никто в десятке комментариев не возразил. Всего два дислайка- (Чорт, каюсь, один из них - я).
Попробуем разобраться. Во-первых, как выглядит «годичное кольцо»? Попросим Яндекс выдать нам бревно:

Идеальное. Красивые кольца! Прямо как на рисунке выше. Постойте- А что же это?

Тоже кольца- А что если у нас фотоаппарат чуть-чуть промазал с резкостью?

Блин. Половина колец пропало. А если у нас вечереет и поднялось ISO?

Опять-
Ну ладно, может не всё так плохо? Придумаем критерий, чтобы выбирать только достаточно большие годовые полосы, будем генерировать несколько вариантов для каждого дерева. Ок?


Нет, ещё есть трещины, которые могут поменять геометрию и ситуации когда полос вообще почти нет. И это первые 20 идеальных картинок из выдачи Яндекса. Вывод напрашивается за пять минут. Но ведь есть же классная идея! Зачем смотреть картинки из поиска?..
Сама по себе задача, на мой взгляд, скорее решаема. Если брать отметки как опорные точки и сравнивать теми же методами, которыми сравнивают глаза. Но, опять же, пока не протестируешь базу хотя бы на пару сотен примеров - никогда не узнаешь, можно ли работу успешно выполнить. Но почему-то такое предложение не понравилось автору статьи- Жаль!
Это два наиболее осмысленных и репрезентативных, на мой взгляд, примера. По ним можно понять, почему нужно абстрагироваться от идеи и смотреть реальные кадры.
Ещё несколько примеров, с которыми я встречался, но уже в двух словах. Во всех этих примерах у людей не было ни единой фотографии на момент, когда они начали спрашивать о реализуемости задачи:
1) Распознавание номеров у марафонцев на футболках по видеопотоку (картинка из Яндыкса)

Хы. Пока готовил статью натолкнулся на это. Очень хороший пример, на котором видны все потенциальные проблемы. Это и разные шрифты, это и нестабильный фон с тенями, это нерезкость и замятые углы. И самое главное. Заказчик предлагает идеализированную базу. Снятую на хороший фотоаппарат солнечным днём. Попробуйте посмотреть номера спортсменов на майках поискав поиском яндыкса.
Хы.Хы За пару часов до публикации автор заказа внезапно вышел на меня сам с предложением взяться за работу, от которого я отказался:) Всё же это карма, добавить это в статью.
2) Распознавание текста на фотографиях экранов телефонов
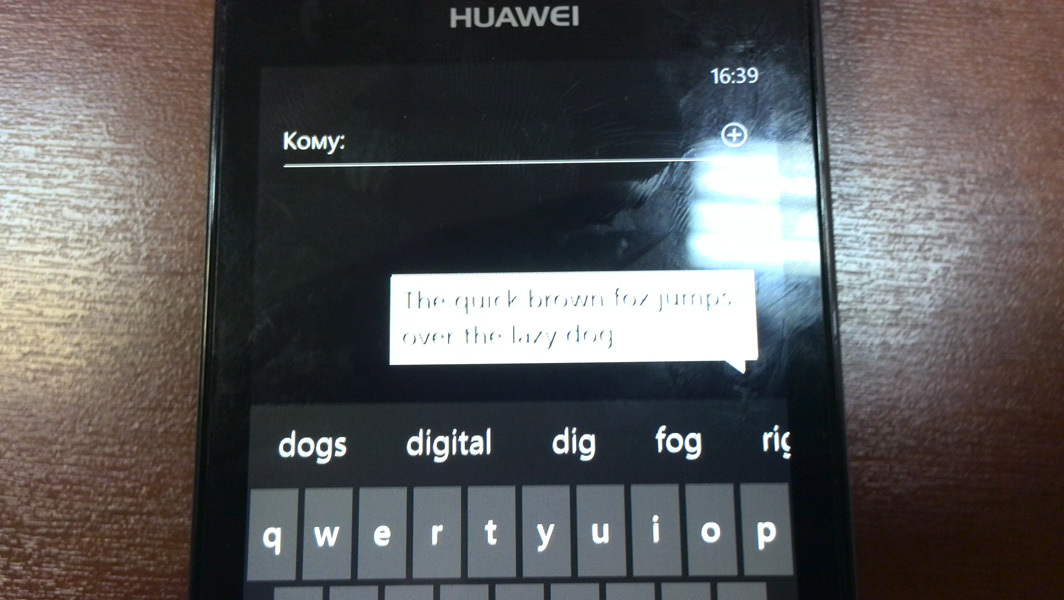
3) И, мой любимый пример. Письмо на почту:
" нужна программа в коммерческий сектор для распознания избражений.
Алгоритм работы такой. оператор программы задает изображения предмета(-ов) в нескольких ракурсах и т.п.
потом при появленини этого или максимально похожего изображения предмета, програма совершает требуемое/заданное действие.
деталей естественно не могу пока рассказать." (орфография, пунктуация сохранены)
Хорошие
Но не всё так плохо! Ситуация, когда задача ставится идеально, встречается часто. Моя любимая: «Нужно ПО для автоматического подсчета лосей на фото.
Пример фото с лосями высылаю.»


Оба фото кликабельны.
До сих пор жалею, что с этой задачей не срослось. Сначала кандидатскую защищал и был занят, а потом заказчик как-то энтузиазм потерял (или нашёл других исполнителей).
В постановке нет ни малейшей трактовки решения. Только две вещи: «что нужно сделать», «входные данные». Много входных данных. Всё.
Мысль - вывод
Единственный способ поставить задачу - набрать базу и определить методологию работы по этой базе. Что вы хотите получить? Какие границы применимости алгоритма? Без этого вы не только не сможете подойти к задаче, вы не сможете её сдать. Без базы данных заказчик всегда сможет сказать «У вас не работает такой-то случай. Но это же критичная ситуация! Без него я не приму работу».
Как сформировать базу
Наверное, всё это был приквел к статье. Настоящая статья начинается тут. Идея того, что в любой задаче CV и ML нужна база для тестирования - очевидна. Но как набрать такую базу? На моей памяти три-четыре раза первая набранная база спускалась в унитаз. Иногда и вторая. Потому что была нерепрезентативна. В чём сложность?
Нужно понимать, что «сбор базы» = «постановка задачи». Собранная база должна:
1. Отражать проблематику задачи;
2. Отражать условия, в которых будет решаться задача;
3. Формулировать задачу как таковую;
4. Приводить заказчика и исполнителя к консенсусу относительно того, что было сделано.
Время года
Пару лет назад мы с другом решили сделать систему, которая могла бы работать на мобильниках и распознавать автомобильные номера. Что-то даже получилось, и мы писали серию статей про это (http://habrahabr.ru/company/recognitor/ ). На тот момент мы были весьма умудрённые в CV системах. Знали, что нужно собирать такую базу, чтобы плохо было. Чтобы посмотрел на неё и сразу понял все проблемы. Мы собрали такую базу:




Сделали алгоритм, и он даже неплохо работал. Давал 80-85% распознавания выделенных номеров.
Ну да- Только летом, когда все номера стали чистые и хорошие точность системы просела процентов на 5-
Биометрия
Достаточно много в своей жизни мы работали с биометрией (1, 2, 3). И, кажется, наступили на все возможные грабли при сборе биометрических баз.
- База должна быть собрана в разных помещениях. Когда аппарат для сбора базы стоит только у разработчиков - рано или поздно выяснится, что он завязан на соседнюю лампу.
- В биометрических базах нужно иметь 5-10 снимков для каждого человека. И эти 5-10 снимков должны быть сделаны в разные дни, в разное время дня. Подходя к биометрическому сканеру несколько раз подряд, человек сканируется одним и тем же способом. Подходя в разные дни - по-разному. Некоторые биометрические характеристики могут немножко меняться в течении суток.
- База, собранная из разработчиков нерепрезентативна. Они подсознательно считываются так, чтобы всё сработало-
- У вас новая модель сканера? А вы уверены, что он работает со старой базой?
Вот глаза собранные с разных сканеров. Разные поля работы, разные блики, разные тени, разные пространственные разрешения, и.т.д.

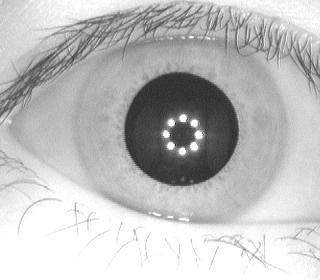
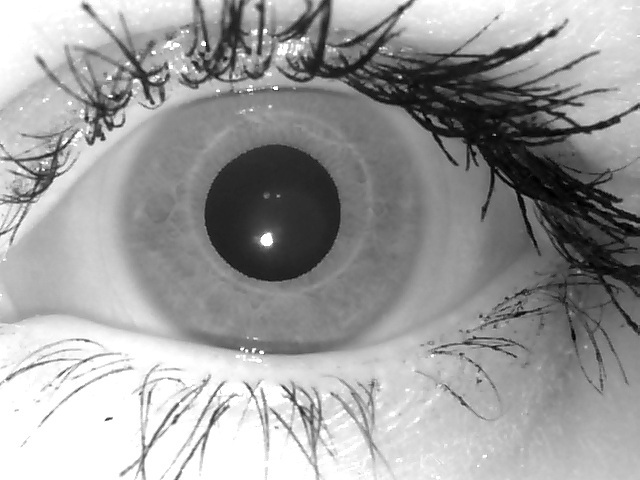
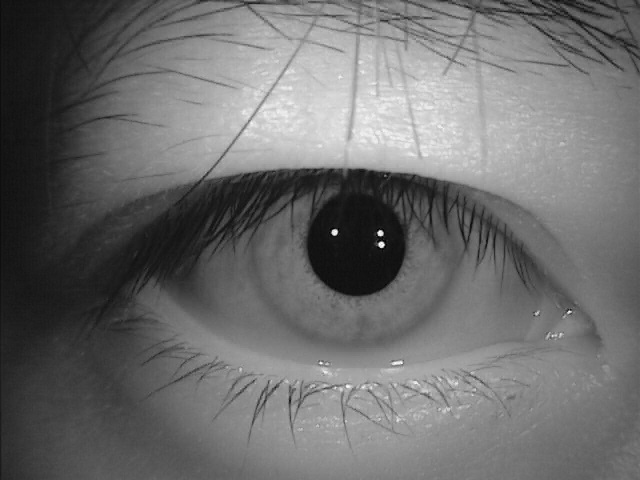
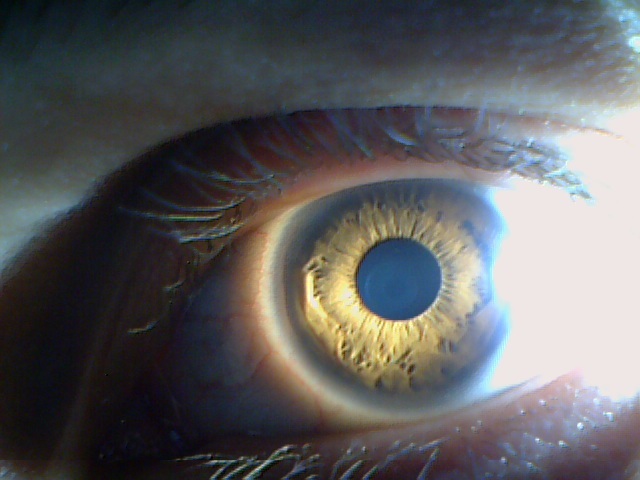
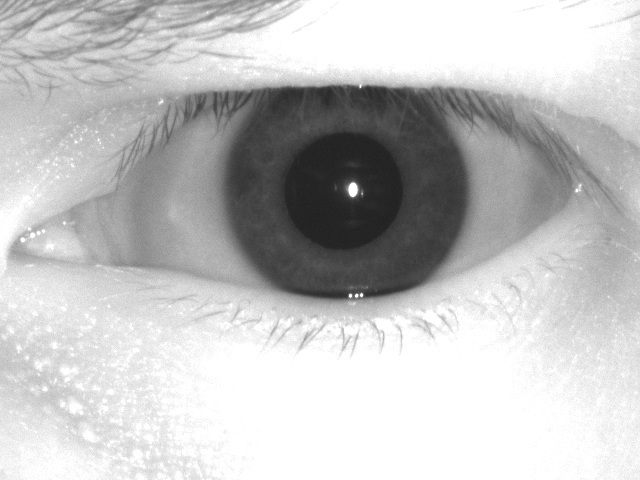
База для нейронных сетей и алгоритмов обучения
Если у вас в коде используется какой-то алгоритм обучения - пиши пропало. Вам нужно формировать базу для обучения с его учётом. Предположим, в вашей задаче распознавания имеется два сильно отличающихся шрифта. Первый встречается в 90% случаев, второй в 10%. Если вы нарежете эти два шрифта в данной пропорции и обучитесь по ним единым классификатором, то с высокой вероятностью буквы первого шрифта будут распознаваться, а буквы второго нет. Ибо нейронная сеть/SVM найдёт локальный минимум не там, где распознаётся 97% первого шрифта и 97% второго, а там где распознаётся 99% первого шрифта и 0% второго. В вашей базе должно быть достаточно примеров каждого шрифта, чтобы обучение не ушло в другой минимум.
Как сформировать базу при работе с реальным заказчиком
Одна из нетривиальных проблем при сборе базы - кто это должен делать. Заказчик или исполнитель. Сначала приведу несколько печальных примеров из жизни.
Я нанимаю вас, чтобы вы решили мне задачу!
Именно такую фразу я услышал однажды. И блин, не поспоришь. Но вот только базу нужно было бы собирать на заводе, куда бы нас никто не пустил. А уж тем более, не дал бы нам монтировать оборудование. Те данные, которые давал заказчик были бесполезны: объект размером в несколько пикселей, сильно зашумлённая камера с импульсными помехами, которая периодически дергается, от силы двадцать тестовых картинок. На предложения поставить более хорошую камеру, выбрать более хороший ракурс для съёмки, сделать базу хотя бы на пару сотен примеров, заказчик ответил фразой из заголовка.
У нас нет времени этим заниматься!
Однажды директор весьма крупной компании (человек 100 штата + офисы во многих странах мира) предложил пообщаться. В продукте, который выпускала эта компания часть функционала была реализована очень старыми и очень простыми алгоритмами. Директор рассказал нам, что давно грезит о модификации данного функционала в современные алгоритмы. Даже нанимал две разных команды разработчиков. Но не срослось. Одна команда по его словам слишком теоретизировала, а вторая никакой теории не знала и тривиальщину делала. Мы решили попробовать.
На следующий день нам выдали доступ к огромному массиву сырой информации. Сильно больше, чем я бы сумел просмотреть за год. Потратив на анализ информации пару дней мы насторожились спросили: «А что собственно вам нужно от новых алгоритмов?». Нам назвали десятка два ситуаций, когда текущие алгоритмы не работают. Но за пару дней я видел лишь одну-две указных ситуации. Просмотрев ещё пачку данных смог найти ещё одну. На вопрос: «какие ситуации беспокоят ваших клиентов в первую очередь?», - ни директор ни его главные инженеры не смогли дать ответа. У них не было такой статистики.
Мы исследовали вопрос и предложили алгоритм решения, который мог автоматически собрать все возможные ситуации. Но нам нужно было помочь с двумя вещами. Во-первых, развернуть обработку информации на серверах самой фирмы (у нас не было ни достаточной вычислительной мощности, ни достаточного канала к тому месту, где хранились сырые данные). На это бы ушла неделя работы администратора фирмы. А во-вторых, представитель фирмы должен был классифицировать собранную информацию по важности и по тому как её нужно обрабатывать (это ещё дня три). К этому моменту мы уже потратили две-три недели своего времени на анализ данных, изучение статей по тематике и написание программ для сбора информации (никакого договора подписано на этот момент не было, всё делали на добровольных началах).
На что нам было заявлено: «Мы не можем отвлекать на эту задачу никого. Разбирайтесь сами». На чём мы откланялись и удалились.
Заказчик даёт базу
Был и другой случай. На этот раз заказчик поменьше. А система, которой занимается заказчик разбросана по всей территории страны. Зато заказчик понимает, что мы базу не соберём. И из всех сил старается собрать базу. Собирает. Очень большую и разнообразную. И даже уверяет, что база репрезентативна. Начинаем работать. Почти доделываем алгоритм. Перед сдачей выясняется, что на собранной базе-то алгоритм работает. И условиям договора мы удовлетворяем. Но вот база-то была нерепрезентативной. В ней нет 2/3 ситуаций. А те ситуации, что есть - представлены непропорционально. И на реальных данных система работает сильно хуже.
Вот и получается. Мы старались. Всё что обещали - сделали, хотя задача оказалась сильно сложнее, чем планировали. Заказчик старался. Потратил много времени на сбор базы.
Но итоговый результат - хреновый. Пришлось что-то придумывать на ходу, хоть как-то затыкать дырки-
Так кто должен сформировать базу?
Проблема в том, что очень часто задачи компьютерного зрения возникают в сложных системах. Системах, которые делались десятки лет многими людьми. И разобраться в такой системе часто сильно дольше, чем решить саму задачу. А заказчик хочет чтобы разработка началась уже завтра. И естественно, предложение заплатить за подготовку ТЗ и базы сумму в 2 раза больше стоимости задачи, увеличить сроки в 3 раза, дать допуск к своим системам и алгоритмам, выделить сотрудника, который всё покажет и расскажет, вызывает у него недоумение.
На мой взгляд решение любой задачи компьютерного зрения требует постоянного диалога между заказчиком и исполнителем, а так же желания заказчика сформулировать задачу. Исполнитель не видит всех нюансов бизнеса заказчика, не знает систему изнутри. Я ни разу не видел чтобы подход: «вот вам деньги, завтра сделайте мне решение» сработал. Решение-то было. Но работало ли оно как нужно?
Сам я как огня пытаюсь шарахаться от таких контрактов. Работаю ли я сам, или в какой-то фирме, которая взяла заказ на разработку.
В целом ситуацию можно представить так: предположим, вы хотите устроить свою свадьбу. Вы можете:
- Продумать и организовать всё самому от начала до конца. По сути данный вариант - «решать задачу самому».
- Продумать всё от начала до конца. Написать все сценарии. И нанять исполнителей для каждой роли. Тамаду для того чтобы гости не скучали, ресторан, чтобы все приготовили и провели. Написать основную канву для тамады, меню для ресторана. Этот вариант - это диалог. Обеспечить данными исполнителя, расписать всё, что требуется.
- Можно продумать большими блоками, не вникая в детали. Нанять тамаду, пусть делает, что делает. Не согласовывать меню ресторана. Заказать модельеру подбор платья, причёски, имиджа. Головной боли минимум, но когда начнутся конкурсы на раздевание, то можно понять что что-то было сделано не так. Далеко не факт, что сформулировав задачу в стиле «распознайте мне символ» исполнитель и заказчик поймут одно и то же.
- А можно всё заказать свадебному агентству. Дорого, думать совсем не надо. Но вот, что получится - уже не знает никто. Вариант - «сделайте мне хорошо». Скорее всего, качество будет зависеть от стоимости. Но не обязательно
Есть ли задачи, где база не нужна
Есть. Во-первых, в задачах, где база - это слишком сложно. Например, разработка робота, который анализирует видео, и по нему принимает решения. Нужен какой-то тестовый стенд. Можно сделать базы на какие-то отдельные функции. Но сделать базу по полному циклу действий зачастую нельзя. Во-вторых, когда идёт исследовательская работа. Например, идёт разработка не только алгоритмов, но и устройства, которым будет набираться база. Каждый день новое устройство, новые параметры. Когда алгоритм меняется по три раза в день. В таких условиях база бесполезна. Можно создавать какие-то локальные базы, изменяющиеся каждый день. Но что-то глобальное неосмысленно.
В-третьих, это задачи, где можно сделать модель. Моделирование это вообще очень большая и сложная тема. Если возможно сделать хорошую модель задёшево, то конечно нужно её делать. Хотите распознать текст, где есть только один шрифт - проще всего создать алгоритм моделирования ( пример такой задачи ).
Научный подход
А как же учёные? Неужели под каждую работу они собирают отдельную базу?
Обычно нет. В интернете можно найти очень много открытых баз данных. Обычно универсальных, для каких-то классических примеров. Например есть несколько сайтов с базами для биометрии (самый известный). Есть сайты с базами для тестирования различных алгоритмов обучения (1 2 3).
Проблема всех этих баз зачастую в том, что они малоприменимы и нерепрезентативны. Взять например легендарный MNIST - базу изображений цифр с ручным написанием:

Все алгоритмы машинного распознавания тестируются на ней. Всё бы хорошо, но- Топовые алгоритмы давным давно имеют точности вида 99.5%, 99.6%, 99.6351%, и.т.д. Не распознаётся 30-40 картинок, которые всем хорошо известны. Половину из них даже человеку нереально распознать. Хитрыми настройками можно чуть-чуть поправить точность и сделать +0.1%. Но ведь понятно, что ни к реальным данным, а уж там более к качественной оценке алгоритма ничего этого отношения не имеет.
Зачастую получается, что написанный по таким базам алгоритм будет работать только в тех условиях и при тех параметрах при которых собрана вся база.
Приводите свои примеры!
На хабре есть множество людей, которые занимаются обработкой изображений и наверняка имеют большой опыт в этом (статьи некоторых из них я читал ещё будучи студентом): SmartEngines sergeypid BelBES mephistopheies rocknrollnerd YUVladimir Nordavind BigObfuscator Vasyutka
(Простите, если кого отметил не по делу, но большинство из отмеченных писали классные статьи по CV и ML). Наверняка у вас есть собственные мысли о том, как сделать постановку задачи идеальной и собрать классную базу. Поделитесь? А может закритикуете написанное, как ересь от начала до конца?:)
Телеграм: t.me/ainewsline
Источник: habrahabr.ru