Особенности использования машинного обучения при защите от DDoS-атак
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-09-18 21:07


Этот пост подготовлен по материалам выступления Константина Игнатова, Qrator Labs, на партнёрской конференции «1С-Битрикс».
Допустим, на ваш сайт началась DDoS-атака. Как вы об этом узнаете? Как ваша система безопасности определяет, что вы подверглись нападению? Каковы способы защиты? Какая последовательность действий и событий должна произойти в случае атаки?
Как правило, владелец ресурса узнает об атаке только в тот момент, когда ему начинают звонить недовольные пользователи. Эту ситуацию большинство компаний встречают неподготовленными. В момент пожара разрабатывать план спасения поздно, и все бросаются на поиски универсального средства, которое окажется под рукой. Но «волшебной пилюли» против DDoS, которая мгновенно бы устранила проблему, нет. Готовиться необходимо заранее.
Защита от DDoS - это процесс. Начинать его необходимо не тогда, когда случилась атака, а сильно заранее. Очевидно, что этот процесс относится к сфере информационной безопасности.
Что означает термин «информационная безопасность»?
В данном контексте мы говорим о противодействии двух сторон. Злоумышленники (конкуренты, вымогатели, недовольные пользователи) хотят, чтобы ваш сайт хотя бы на время перестал работать (ушёл в даунтайм). Владелец ресурса хочет стопроцентной доступности без перерыва.
Есть два основных принципа информационной безопасности:
- Стараться мыслить, как преступник, то есть мысленно пытаться встать на сторону тех людей, которые хотят отправить сайт в даунтайм. Нужно понять, как они это будут делать, какие данные им могут понадобиться, какие шаги они предпримут.
- Как можно чаще задавать себе вопрос: что может пойти не так в той или иной ситуации; что может сломаться, если мы сделаем так или иначе; к каким проблемам приведёт подключение того или иного компонента; какие минусы есть у используемых решений.
Процесс защиты от DDoS
DDoS-атака направлена на исчерпание ограниченных ресурсов. Это могут быть любые ресурсы:
- Количество SMS, которые может принять ваш телефон.
- Размер оперативной памяти.
- Канальная ёмкость.
- Всё, что угодно.
Полностью переложить проблему противодействия DDoS на поставщика соответствующей услуги не получится. Необходимо задуматься об этом еще на стадии проектирования системы. Над проблемой защиты должна работать большая команда людей:
- Сетевые инженеры должны предусмотреть, чтобы канальной ёмкости хватало хотя бы на легитимный трафик, и чтобы при этом оставался запас.
- Разработчики веб-приложений должны сделать так, чтобы один запрос не привел к исчерпанию всей оперативной памяти. Криво написанный софт может сыграть плохую службу и привести к выходу из строя сайта, даже если вы используете самую современную систему противодействия DDoS.
- Специалисты по информационной безопасности должны защищать (делать скрытым, следить, чтобы нигде не «светился») IP-адрес, на котором находится ваш сервер.
Рассмотрим, как работают системы противодействия DDoS-атакам на примере Qrator Labs - компании-партнёра «1С-Битрикс», предоставляющей сервис фильтрации трафика. Узнать её защищенный IP-адрес можно в личном кабинете в «1С-Битрикс». После чего можно перевести на этот адрес свой DNS. Старый IP-адрес продолжит работать. Одна из задач внешнего сервиса защиты состоит в том, чтобы никто не знал этот старый IP-адрес. Потому что как только он начинает «светиться», злоумышленники могут атаковать интернет-ресурс в обход защиты Qrator. Для таких случаев тоже есть решения, но их стоимость выше.
Помимо того, что защита от нападений должна быть разработана заблаговременно, сам процесс защиты целесообразно автоматизировать. Злоумышленники, как правило, редко сфокусированы на конкретном сайте. У них всё поставлено на поток, написаны универсальные скрипты. Они автоматически просканировали множество сайтов, обнаружили какую-то уязвимость на вашем и решили атаковать. Запустили скрипт, ушли спать - атака не представляет никакой сложности. А вот на разработку тактики защиты может уйти несколько часов, даже если у вас очень сильная команда специалистов. Вы вносите изменения в свой сайт, атака отражена. Злоумышленник просыпается через несколько часов, меняет пару строчек в своем скрипте, и вам наверняка придётся снова придумывать, как защититься. И так по кругу. Вряд ли ваши спецы выдержат больше 48 часов в таком режиме. После этого приходится прибегать к дорогим средствам защиты, потому что подключение под атакой всегда стоит больше. Нейтрализовать атаку, когда она уже в разгаре, вполне возможно, но это гораздо сложнее, и даунтайма уже не избежать. Внешние поставщики таких услуг, как правило, используют автоматизацию, т.к. «ручные» средства практически никогда не спасают.
Машинное обучение для автоматизации
Когда мы говорим об автоматизации в современных системах противодействия DDoS-атакам, практически всегда подразумевается использование технологий машинного обучения. Применение machine learning необходимо для нейтрализации атак уровня приложений (L7). Большинство других типов атак можно нейтрализовать методом «грубой силы». Во время атаки типа Amplification в канал поступает много одинаковых пакетов. Не нужно применять искусственный интеллект, чтобы понять, где пакет от легитимного пользователя, а где мусор. Достаточно иметь большую канальную емкость, чтобы пропустить и отфильтровать весь плохой трафик. Если емкости не хватает, может пригодиться сторонняя геораспределенная сеть, такая как Qrator, которая примет на себя излишний трафик, отфильтрует мусор и отдаст «чистые» пакеты от легитимных пользователей.
Атака на приложения происходит по другой схеме. В приложение может поступать множество самых разных запросов с большим количеством параметров. Если их достаточно много, этот поток выводит из строя базу данных. Чтобы решить проблему, необходимо уметь распознавать, где запросы от реальных пользователей, а где от ботов. Эта задача неординарная, потому что на первый взгляд они неразличимы. В её решении наиболее эффективно использовать машинное обучение.
Что такое машинное обучение?
В первую очередь, это просто набор алгоритмов, который имеет две фазы:
- Первая фаза - обучение, когда мы рассказываем нашим алгоритмам, что они должны делать.
- Вторая фаза - применение «знаний» на практике.
Алгоритмы бывают трёх типов:
- С обратной связью от человека (обучение с учителем) - мы рассказываем нашим алгоритмам, что нужно делать, а они потом учатся. Используются для задач классификации и регрессии.
- С обратной связью от данных (обучение без учителя) - мы просто показываем алгоритму данные, а он, например, находит в них аномалии, или группирует те или иные объекты по своему усмотрению. Применяются для решения задач кластеризации и поиска аномалий.
- С обратной связью от среды (теория управления). Например, когда выбираете степень масштабирования ресурсов исходя из количества ссылок на сайт в Twitter сегодня. То есть поддерживаете некий постоянный уровень нагрузки на один сервер в среднем.
В качестве примера задачи для машинного обучения я взял статистику по уровню входного трафика одного из наших клиентов (верхний график). А на нижнем графике представлен прогноз, построенный на основании тестовых данных (выделенный синим участок в начале кривой).
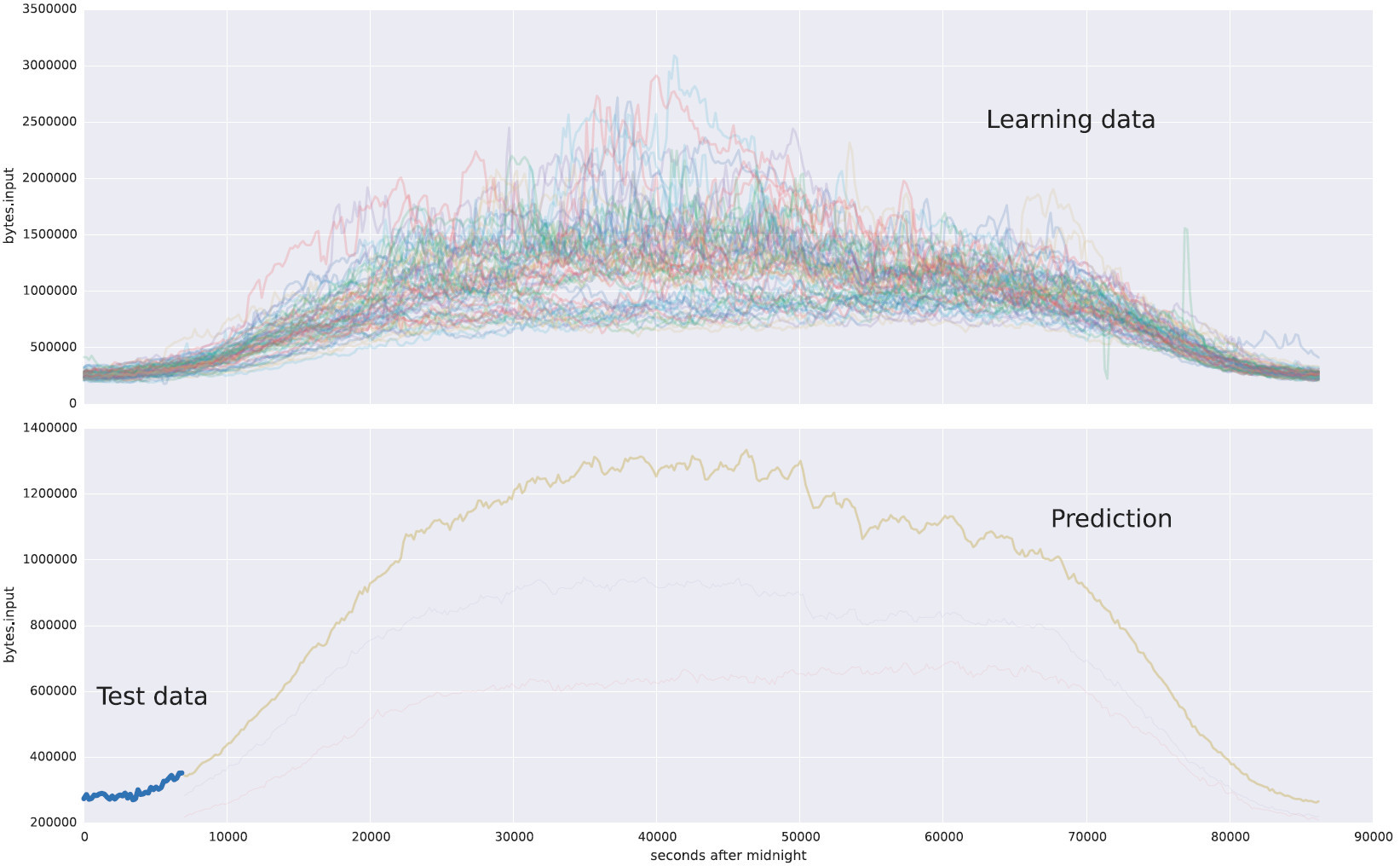
Сверху приведены суточные изменения объемов трафика На второй картинке смотрим график начала нагрузки, алгоритм предсказывает каким будет дальше трафик. Это пример регрессии.
Влияние злоумышленников на процесс обучения
При помощи алгоритмов машинного обучения рассчитывается оценка математического ожидания, дисперсии или других числовых характеристик распределения той или иной случайной величины.
Чтобы соответствовать принципам информационной безопасности, алгоритм должен работать в соответствии с двумя основными требованиями:
- На первом этапе алгоритм должен уметь игнорировать аномалии, которые могут оказаться в исходных данных.
- На втором этапе, когда алгоритм уже работает по нашей задаче, мы хотим понимать, почему он принял то или иное решение. Например, почему он отнес запрос к категории легитимных.
В нашем случае данные для обучения - это информация об активности пользователей. Это значит, что злоумышленники могут оказать влияние как минимум на часть данных, на которых мы собираемся учиться. А что если им придёт в голову отличная идея: так повлиять на общую статистику, чтобы наши алгоритмы научились именно тому, что хотят злоумышленники? Это вполне может произойти, а значит необходимо заранее предотвратить такую возможность.
Вот пример из нашего внутреннего отчёта о странной активности у одного из наших клиентов.
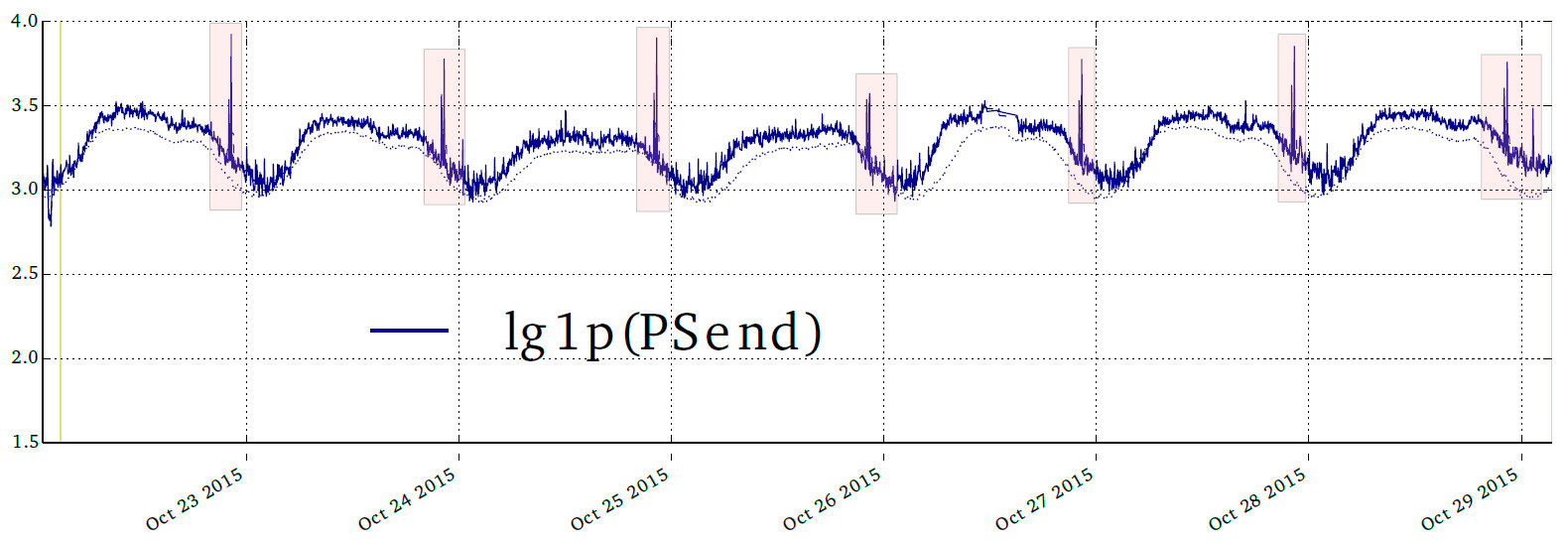
Каждый вечер, в одно и то же время количество пакетов увеличивалось. Не смертельно, сайт продолжал открываться, нагрузка была на грани допустимого (на графике логарифмический масштаб). Причиной этого могло быть всё, что угодно: cкорее всего, сисадмин что-то напутал, записал в cron операцию ежедневного сохранения бэкапов на определенное время. Но может быть кто-то пытается научить наши алгоритмы пропускать нелигитимный трафик.
Уметь так делать и уметь защищаться от этого - непростые задачи, над их решением трудятся лучшие умы, в Сети есть уже немало научных статей на эту тему. Наши алгоритмы пока никто не смог научить «плохому» и мы готову к тому, что кто-то попытается. Сейчас расскажу, почему у злоумышленников ничего не выйдет.
Как с этим бороться?
На первом этапе (обучение) важными становятся такие понятия, как робастность и breaking point.
Робастность - мера того, насколько легко можно повлиять на прогнозируемую оценку.
Breaking point - количество образцов в обучающей выборке, достаточное для искажения оценки.
Хотя оба термина очень близки друг к другу, нам ближе второй из них. Он означает количество искаженных, неправильных элементов в обучающей выборке - тех исходных данных, на которых мы учимся,- позволяющее повлиять на результаты прогнозирования.
Если breaking point равен нулю, то алгоритм может сломаться сам по себе. Если breaking point равен единице, то достаточно вбросить один-единственный неправильный запрос, и система будет предсказывать не то, что должна.
Чем выше значение breaking point, тем сложнее - а значит дороже для злоумышленника - повлиять на обучение алгоритмов. Если мы так обучили нашу систему, что breaking point высокий, вопрос противодействия перемещается в экономическую плоскость. Выигрывает тот, кто потратил меньше денег.
В идеале защита должна стоить очень мало, а ее преодоление - очень много.
На втором этапе (отработка алгоритма) нужно помнить о том, что всё может пойти не так, как планировалось. Иногда приходится анализировать постфактум, а что же всё-таки произошло. Поэтому неплохо бы иметь возможность заставить алгоритмы «рассказать», как они отработали и почему. Объяснимость действий алгоритма помогает «приглядывать» за автоматизированным процессом, а также облегчает задачи тестирования, отладки и расследования инцидентов.
Сбор данных
Алгоритмам машинного обучения нужны данные. Где их взять? В принципе, здесь у нас всё под рукой-
Какие именно данные нужно собирать?
В первую очередь, необходимо наблюдать за всеми исчерпаемыми ресурсами:
- количество соединений;
- объём трафика;
- свободная память;
- загрузка ЦПУ;
- прочие исчерпаемые ресурсы.
Собирать и хранить такие данные легко - существует множество инструментов для этого. Объём таких данных предсказуем. Если вы каждую минуту записывали один мегабайт данных телеметрии, то даже после начала DDoS-атаки вы всё равно будете записывать один мегабайт. Если вы ещё этого не делаете, то самое время начать.
Второй тип данных для анализа - поведение пользователей, которое отражено в логах (в основном это access.log иили лог, хранящий запросы к базе данных). Они должны быть в удобном для машины формате.
В отличие от телеметрии, объем логов растёт как минимум линейно с количеством запросов. Особенно чувствительно это может быть во время DDoS-атаки, когда ресурсов катастрофически не хватает. У вас ЦПУ загружен на 100%, а тут еще система пытается сохранить 2Гб логов. Нужно сделать так, чтобы эта задача в критических ситуациях либо не запускалась, либо прерывалась. Но неплохо всё-таки, чтобы хотя бы какие-то логи сохранялись даже под атакой.
Можно хранить не все логи, а только часть. Но нужно подойти к этому с умом. Не имеет смысла записывать каждый десятый запрос, нужно сохранять сессиями. Например, вы можете вычислять некриптографический хэш от IP-адреса и сохранять только определённый диапазон этих хэшей: пусть некриптографический хэш принимает значения в диапазоне от 1 до 100. Начинаем с сохранения всех запросов. Если не успеваем, сохраняем запросы только от тех IP-адресов, хэш которых находится в диапазоне 1-90. Уменьшаем интервал, пока не сможем справиться с потоком.
Также всегда нужен хотя бы небольшой образец логов «чистого поведения» системы (то есть не под атакой). Даже если вы их не храните, периодически можно записывать небольшой дамп, чтобы иметь представление о том, как себя ведут пользователи, когда на вас нет DDoS-атаки.
Что полезного мы можем извлечь из сохраненной телеметрии и логов?
На основе телеметрии мы можем научить алгоритмы определять, когда ресурсы сервера близки к исчерпанию. Если есть логи, можем проанализировать, чем отличается поведение злоумышленников от обычных пользователей. Можем группировать пользователей по разным признакам, например, выбирать тех, кто оказывает большую нагрузку, но при этом не приносит дохода. Зачем это может понадобиться? Если сервер совсем не справляется с нормальной нагрузкой (когда нет атаки), то, к сожалению, придётся банить кого-то из легитимных пользователей. Кого? Явно не тех, кто сейчас нажимает «купить».
Примеры задач
На практике обычно алгоритмы не используются по отдельности, а складываются в цепочку задач (pipeline): то, что получается на выходе из одного алгоритма, используется как входные данные для другого. Или результаты работы одного алгоритма используются, как параметры для настройки другого.
Рассмотрим примеры задач, которые раскладываются на цепочки.
Задача -1. Оценить будущую плановую нагрузку на сайт
Задача раскладывается на следующие шаги:
- Понять, какая нагрузка бывает и как она меняется в зависимости от времени, дня недели. В результате мы должны получить несколько типов нагрузки. Например, нагрузка по рабочим дням, по выходным, во время и сразу после презентации нового IPhone.
- Оценить, к какому типу относится текущий уровень нагрузки (считаем, что в данный момент атаки нет)
- Предсказать плановое значение на основе имеющихся данных по текущей нагрузке и её типу.
Задача -2. Принять решение, нужно ли кого-нибудь банить, если мы видим признаки атаки
На текущий момент мы точно знаем, что есть атака. Возможно, следует заблокировать часть IP-адресов, которые участвуют в нападении. Но агрессивная блокировка приводит к тому, что будет забанена и часть легитимных пользователей. Эта ситуация называется False Positive, и нужно стремиться, чтобы таких случаев было как можно меньше (алгоритм ошибочно - False - относит пользователя к группе тех, кто причиняет вред - Positive). Если сервер способен «переварить» атаку (то есть обработать все запросы) без последствий для пользователей, то и делать ничего не надо. Следовательно, необходимо оценить способность сервера выдержать атаку без даунтайма. Задача раскладывается на следующие шаги:
- Определить зависимость количества ошибоксбоев от количества запросов.
- Определить, сколько запросов необходимо отфильтровать.
Очевидно, что данная задача - это часть цепочки, которая ведёт к достижению главной цели - доступности сервера. На следующем этапе, например, необходимо решить, какие именно запросы нужно блокировать.
Задача -3. Запросы от каких реальных пользователей можно отфильтровать с меньшими потерями для бизнеса, если сервер не справляется с легитимной нагрузкой
В этой задаче мы рассматриваем ситуацию, когда легитимная нагрузка на сервер больше, чем он способен выдержать (даже без учета зловредного трафика). Такие ситуации, к сожалению, случаются. Чтобы решить эту задачу, нужно пройти два первых шага из Задачи -2. То есть данная задача - это тоже часть некоторой цепочки.
Затем идём по следующим шагам:
- Выделяем признаки сессий. Например: заходил ли посетитель на страницу оформления заказа, пришёл ли он по ссылке из рекламной кампании, авторизован ли пользователь на сайте. Составляем таблицу всех сессий и их признаков за длительный промежуток времени.
- Маркируем сессии по важности.
В идеале хорошо бы рассчитать вероятную прибыль от каждой сессии из текущих, чтобы банить только тех, кто наименее важен. Но на практике обычно применяют эвристики и упрощают задачу - блокируют тех пользователей, чьи сессии имеют признаки менее важных.
Остановимся подробнее на Задаче -1
Помните график, на котором отображена входная нагрузка на одного нашего клиента? На самом деле, ради красоты он очищен. Реальный график выглядит так:

Видим много огромных всплесков, на несколько порядков превышающих обычный уровень нагрузки. Также видно, что нагрузка непостоянна, дни бывают очень разные. То есть задача построения робастной модели на основе таких данных нетривиальна.
На эту тему написаны горы статей и проведено множество исследований. Но общепринятого идеального решения здесь нет.
Могут использоваться следующие подходы:
- Использование абсолютных отклонений.
- Робастная нормализация.
- Нелинейные обратимые преобразования (sigmoid).
- «Тяжёлые хвосты», когда нужно предположение о распределении.
- Сэмплирование ради уменьшения вероятности попадания «плохих» образцов в обучающую выборку.
Как правило можно принять, что
- в алгоритмах, основанных на деревьях breaking point < минимального размера листка;
- при кластеризации breaking point < минимального размера кластера.
Например, если применить робастную нормализацию и нелинейные обратимые преобразования, то получится так:

Сверху - исходные данные. Второй график - результат робастной нормализации с её помощью мы уменьшаем влияние аномалий. Последний график - результат нелинейного обратимого преобразования. То, что у нас есть аномалия, мы поняли уже на втором графике, после этого ее абсолютная величина нас уже не очень интересует. Мы её «обрезаем» при помощи нелинейного преобразования. Получаем данные, с которыми гораздо проще работать.
Этот же самый график можно визуализировать в виде цветной картинки.
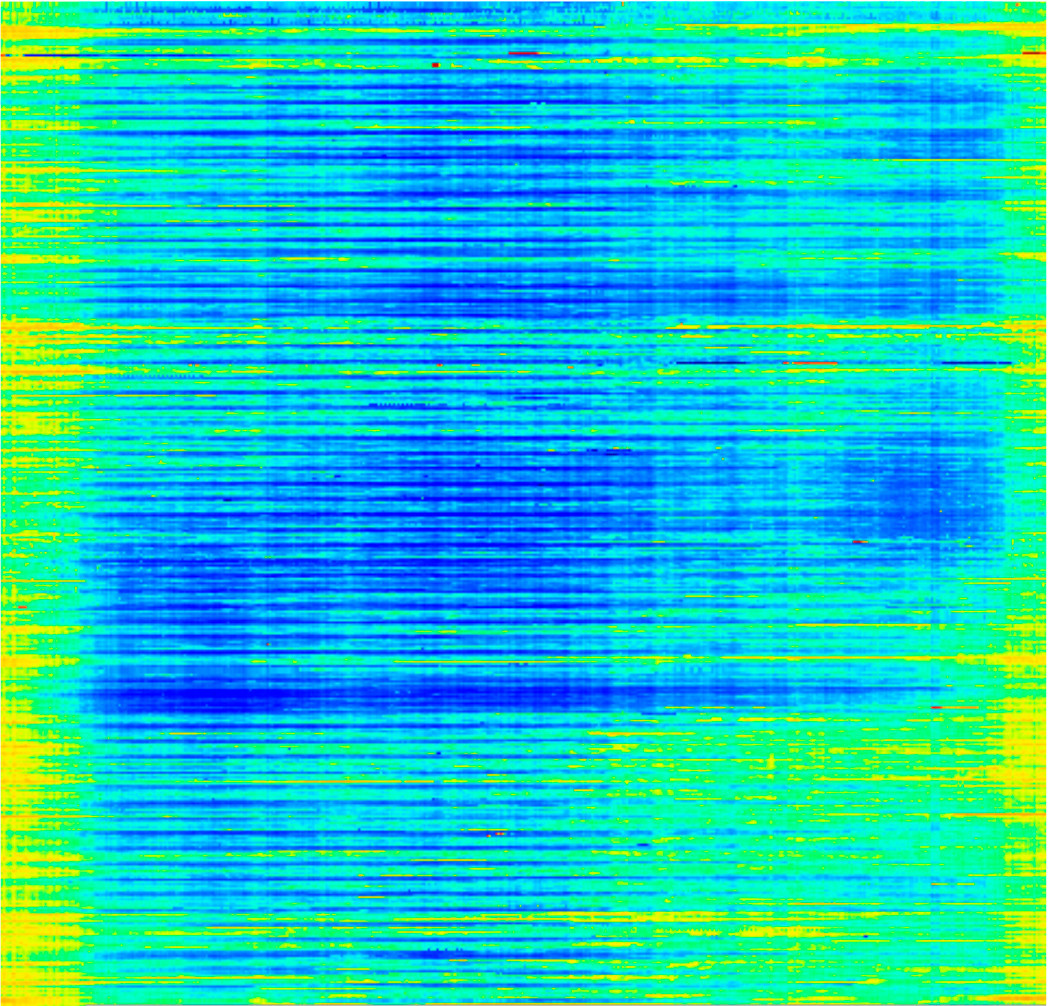
Читается эта картинка построчно слева направо, сверху вниз. По горизонтали - секунды с начала дня, по вертикали - даты. Желтый и красный (например, в правом верхнем углу) показывают высокую нагрузку.
После применения вышеописанных подходов, мы можем сгруппировать разные дни по уровню нагрузки и кластеризовать их.
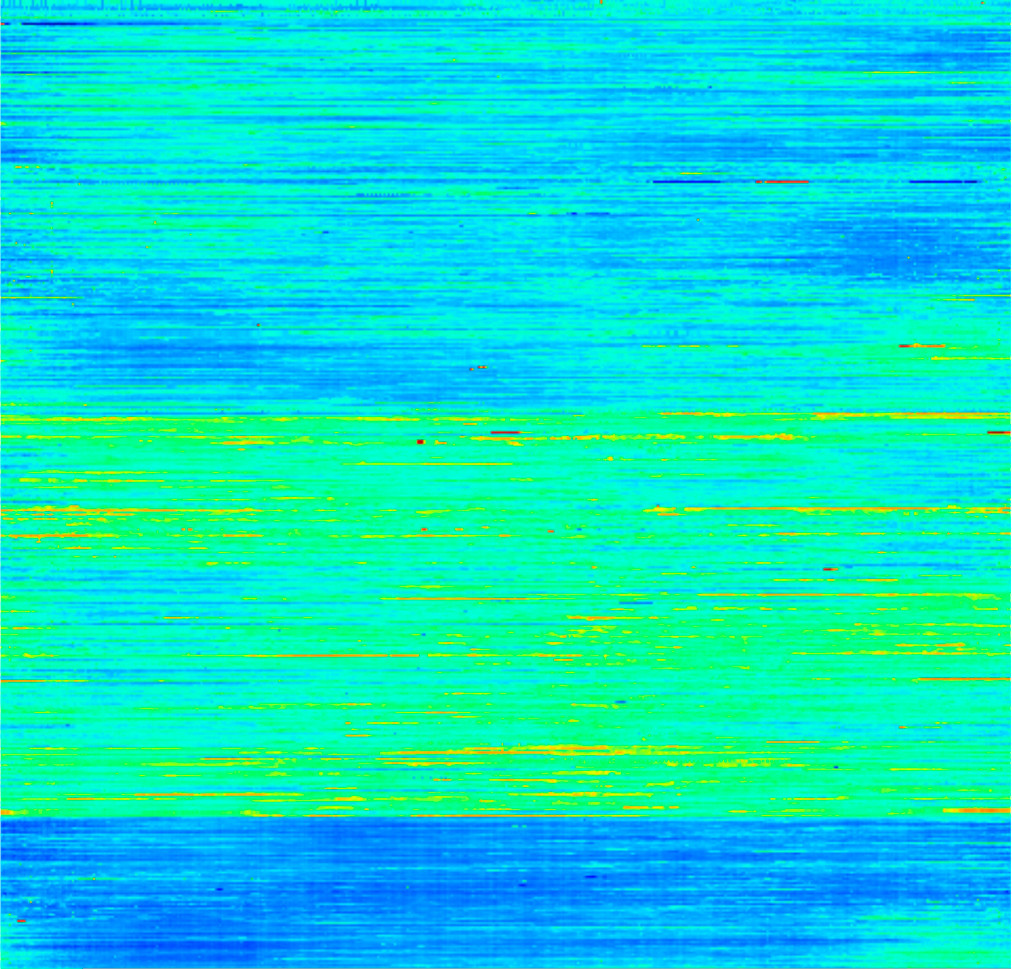
Мы можем увидеть три разных типа нагрузки, которые более явно отражены на следующих иллюстрациях.
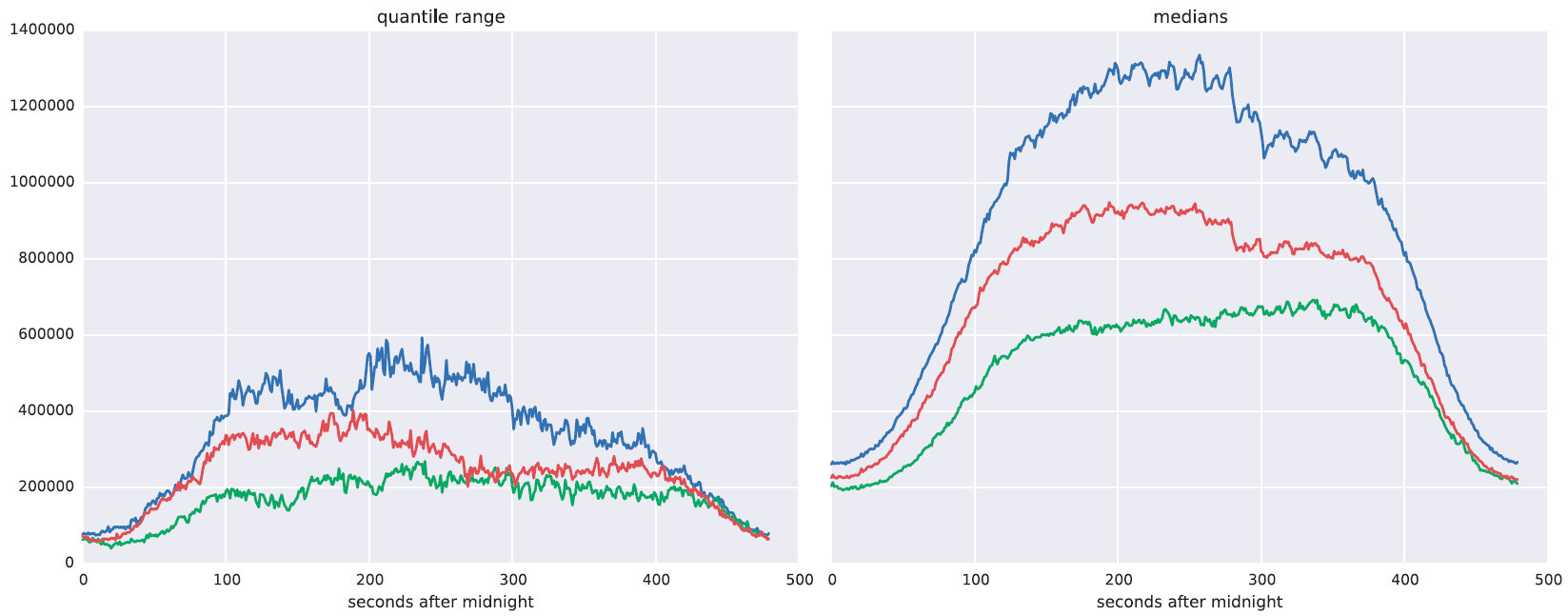
Справа - ожидаемая нагрузка в разные типы дней. Слева - робастный аналог стандартного отклонения (разброс квантилей).
Применим это к реальной ситуации. Фиолетовая линия отражает нагрузку в течение некоторого периода времени. Она ближе всего к синей пунктирной кривой. То есть это тот тип, на который нужно ориентироваться при прогнозе нагрузки.

Поиск групп признаков
Работать с логами сложнее, т.к. информация в них хранится в форме сложных вложенных структур. Логи для машинного обучения не годятся без предварительной подготовки. В зависимости от того, какая у нас задача, мы можем выделять признаки либо у запросов, либо у сессий.
В первом случае анализируем каждый запрос в отдельности, ищем, например, признаки нелегитимных ботов- Во втором случае анализируем, по сути, поведение пользователей.
Примеры признаков запросов:
- статический или динамический запрос
- время обработки запроса
- объём памяти, который потребовался для обработки этого запроса
Примеры признаков сессий:
- пользуется ли посетитель последней версией браузера
- совпадают ли язык интерфейса его браузера с тем языком, который выбрал он в настроках на сайте;
- загружает ли посетитель статику;
- сколько раз запрошен favicon.ico;
- заходил ли посетитель на страницу оформления заказа.
Это простые признаки, мы знаем о них до начала анализа, и их можно получить с помощью элементарной функции, которая принимает запрос или сессию и возвращает массив значений конкретных признаков. Но на практике таких признаков для анализа недостаточно. Нам нужно извлечь больше информации, то есть необходимо научиться выделять новые признаки, о которых мы ещё не знаем.
Например, если в логе есть часть запросов, URL которых заканчивается на /login, то мы можем выделить это как признак и разметить каждый запрос по этому признаку (пометить единицей или нулём - заканчивается URL запроса на /login или нет). Или мы можем пометить запросы, которые пришли с сайта example.com, единицами, а все остальные - нулями. Или можем выделить признак по длительности обработки запроса: длительные, быстрые и средние.
То есть по сути мы смотрим на данные и пытаемся понять, какие признаки нам могут понадобиться. В этом суть процесса так называемого feature extraction. Потенциальных признаков бесконечно много. При этом любая группа или множество признаков также формирует новый признак. Это усложняет задачу.
Итак, задача разбивается на две подзадачи:
- требуется выделить важные признаки;
- выделить группы признаков, каждая из которых по сути тоже признак.
В реальности это может выглядеть вот так:
На картинке выше запросы превращены в признаки. На следующей картинке мы сгруппировали признаки, выделили новые и посчитали, как часто они встречаются.
В этой задаче мы анализировали около 60 000 запросов (что не так уж и много, но это просто пример).

В правом столбике указано сколько запросов соответствует данной группе признаков. Видно, что количество разное, и что один запрос может попасть в несколько групп. То есть есть запросы, которые не попали в некоторые группы. Мы помечаем каждый запрос массивом из десяти нулей или единиц. Единица означает, что запрос соответствует группе, ноль - что не попадает в неё. Таким образом, у нас получается массив в виде матрицы 60 000х10. С этой числовой информацией можно работать также, как описано выше.
Чтобы выделить такие признаки, используются специальные алгоритмы. Описывать их здесь подробно не буду.
Общая идея заключается в том, чтобы преобразовать лог в специальную базу данных. Эта база данных должна уметь отвечать на ряд запросов. Например: найти в логе для всех элементарных признаков все их возможные сочетания, удовлетворяющие некоторому критерию, и отсортировать по частоте встречаемости.
Другой тип базы данных работает не с множествами, а с последовательностями. Это нужно для анализа сессий, потому что сессия, по сути, - последовательность запросов. Такая БД умеет выделять все подпоследовательности определённого типа. Например, запрос к ней: найти в логе среди всех подпоследовательностей во всех сессиях такие, которые удовлетворяют определённому критерию, и отсортировать эти подпоследовательности по количеству сессий, в которых они встретились.
Третий тип баз данных позволяет работать с переходами из одной части сайта в другую в рамках одной сессии. То есть каждая сессия теперь - граф. БД должна уметь находить все подграфы, удовлетворяющие определенному критерию, и сортировать их по количеству сессий, в которых они встретились.
Этот процесс называется pattern discovery. В качестве паттернов выступают множества, последовательности или графы.
С помощью такого анализа можно найти интересующие нас группы пользователей. Результат такого анализа можно изучать даже вручную.
Нужно ко всему этому готовиться заранее
Ещё раз подчеркну, что на всё это понадобится время. Защиту от DDoS нельзя просто взять и включить (в момент атаки) - её нужно готовить заранее.
Нужно найти подходящих людей и обучить их. Нужно собрать данные, которые можно будет использовать для обучения. Возможно, потребуется что-то изучить, посмотреть вручную, найти узкие места. Алгоритмы системы защиты нужно обучить. Необходимо проверить, что сервер или, напрмер, почтовый демон не «светит» незащищённый IP.
Всё это - часть большого процесса и не может произойти моментально.
С другой стороны, хочу заметить, что, результаты работы системы защиты от DDOS можно использовать для бизнес-аналитики. Например, отдать в работу маркетинговому отделу данные группы пользователей, которых мы решили не банить, потому что они приносят доход.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru