Нейросеть машинного зрения обучают на реалистичных компьютерных играх
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-09-12 20:09

Кадры из компьютерной игры Grand Theft Auto V и семантическая разметка для обучения нейросети машинного зрения
Нейросети ставят новые рекорды почти на всех соревнованиях по компьютерному зрению, а также всё шире используются в других приложениях ИИ. Один из ключевых компонентов такой невероятной эффективности нейросетей - доступность больших наборов данных для их обучения и оценки. Например, для оценки современных нейросетей используется Imagenet Large Scale Visual Recognition Challenge (ILSVRC) с более чем 1 миллионом изображений. Но судя по последним результатам (ResNet показател результат всего лишь 3,57% ошибок), скоро исследователям придётся составлять более обширные наборы данных. А потом - ещё более обширные. Между прочим, аннотирование таких фотографий - немалая работа, часть которой приходится делать вручную.
Некоторые разработчики систем компьютерного зрения предлагают альтернативный способ обучения и проверки таких систем. Вместо ручного аннотирования тренировочных фотографий они используют синтезированные кадры из реалистичных компьютерных игр.
Это вполне логичный подход. В современных играх графика достигла такого уровня реализма, что синтезированные изображения слабо отличаются от фотографий реального мира. В то же время игровой движок может сгенерировать бесконечное количество таких кадров - это сразу кардинально решает проблему сбора миллионов фотографий для тренировки и оценки нейросети.
Хотя игровой движок использует конечное число текстур, но существует большое разнообразие сочетаний углов зрения, освещения, погоды и уровня детализации, что обеспечивает достаточное разнообразие набора данных.
В этом году сразу две группы исследователей проверили на практике, можно ли использовать для обучения нейросетей машинного зрения сгенерированные кадры из компьютерных игр. Группа исследователей с факультета информатики Университета Британской Колумбии (Канада) опубликовала научную статью, для которой собрали более 60 000 кадров из компьютерной игры с дорожными видами, схожими с наборами данных CamVid и Cityscapes. Исследователям удалось доказать, что нейросеть после тренировки на синтетических изображениях демонстрирует схожий уровень ошибок, что и после тренировки на настоящих фотографиях. Более того, тренировка на синтезированных изображениях с использованием реальных фотографий демонстрирует ещё лучший результат.
Все 60 000 кадров сделаны в виртуальную солнечную погоду, в виртуальное время 11:00, с разрешением 1024-768 и максимальными настройками графики (название игры не разглашается из-за опасений, связанных с копирайтом). Беспилотный автомобиль случайно ездил по игровым улицам, соблюдая правила дорожного движения. Кадры снимались 1 раз в секунду. Каждый из них сопровождается автоматической семантической сегментацией (небо, пешеход, автомобили, деревья, фон - сегментация абсолютно точная и взята из игры), глубинным изображением (depth image, карта с разметкой объектов), а также нормалями к поверхности.
Кроме базового набора данных VG, исследователи сделали ещё один набор VG+ с большим количеством семантической информации, не ограничиваясь пятью метками - здесь сегментация не точная. Разметка осуществлялась автоматически с помощью SegNet.

Плотно размеченные кадры из набора VG+
Для сравнения эффективности обучения нейросети были подготовлены наборы данных CamVid и Cityscapes (пять меток), а также CamVid+ и Cityscapes+ с расширенными наборами меток.

Исходные фотографии CamVid с аннотациями

Два случайных изображения набора Cityscapes+ с подробными аннотациями
Для семантической классификации использовалась свёрточная нейросеть Лонга с простой архитектурой FCN8 поверх 16-слойной VGG Net Симоняна и Зиссермана.
Исследователи провели несколько экспериментов, чтобы оценить эффективность распознавания объектов нейросетью, которая обучалась на разных наборах данных. Практически во всех случаях нейросеть, обученная на синтетических данных, показывала лучший результат, чем нейросеть, обученная на настоящих фотографиях. Лучший результат она показывала даже при проверке на настоящих фотографиях.
Например, в таблице приведена оценка работы одинаковых нейросетей, обученных на трёх наборах данных (реальные фотографии, синтетические данные из игры, смешанный набор) при распознавании объектов на реальных фотографиях из наборов CamVid+ и Cityscapes+.
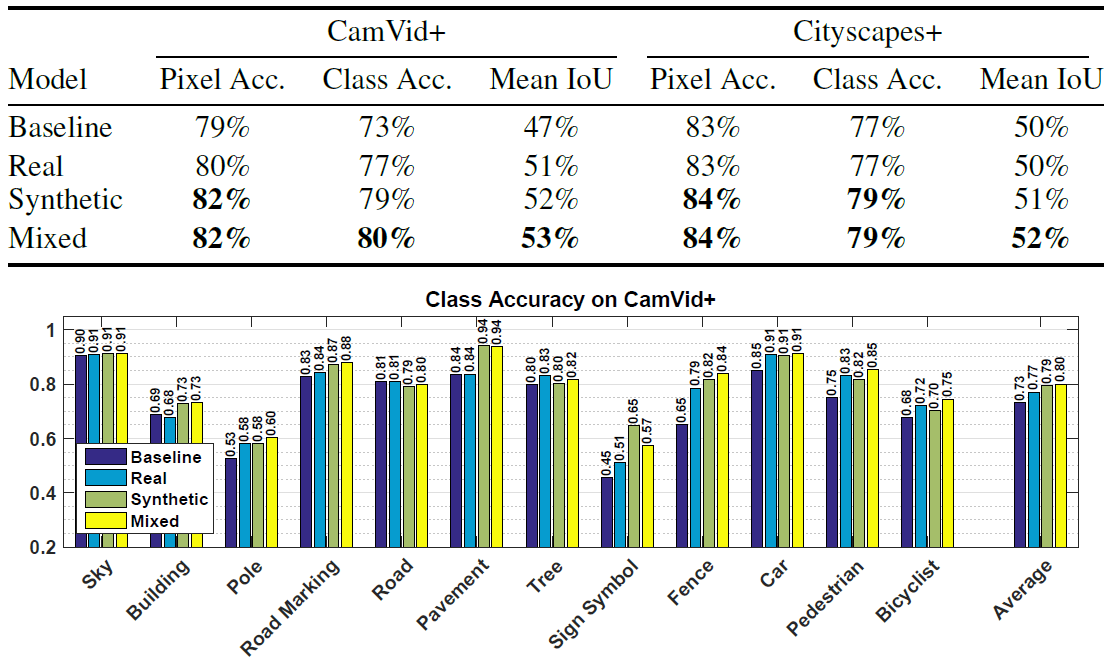
Как видно, лучше всего при обучении нейросети синтетические изображения из компьютерной игры дополнять настоящими фотографиями.
Научная статья опубликована 5 августа 2016 года на arXiv.org, вторая версия - 15 августа (pdf).
Кроме исследователей из Университета Британской Колумбии, практически одновременно аналогичную работу проделала другая группа учёных из Дармштадтского технического университета (Германия) и Intel Labs. Они взяли для обучения 24 966 кадров из компьютерной игры с открытым миром Grand Theft Auto V. Исследователи пришли к такому же результату: при использовании для обучении набора данных, составленного на 2/3 из синтетических изображений и на 1/3 из фотографий CamVid, точность распознавания оказывается выше, чем только при использовании фотографий CamVid.
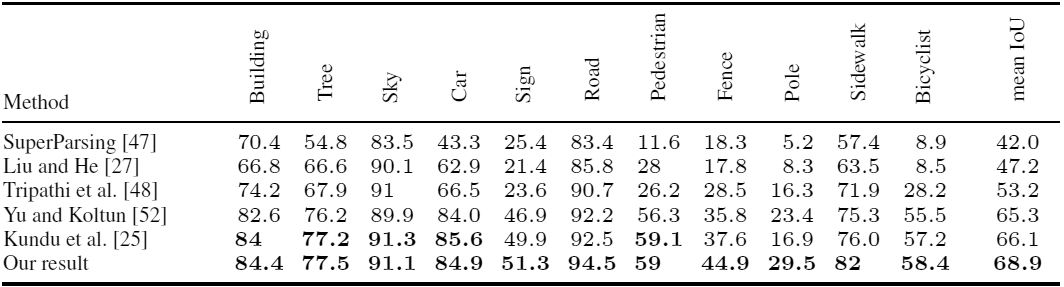
Точность распознавания различных объектов на фотографиях из набора CamVid при обучении обычными методами и при использовании кадров из GTA V (нижняя строчка)
При этом полуавтоматическое аннотирование в специально разработанном редакторе значительно сокращает время подготовки набора данных для обучения нейросети. Например, аннотирование одной фотографии CamVid требует 60 минут, одной фотографии Cityscapes - 90 минут, а полуавтоматическое аннотирование кадра GTA V - всего 7 секунд, в среднем (видео, демонстрация работы редактора).
Работа исследователей из Дармштадтского технического университета и Intel Labs подготовлена для Европейской конференции по компьютерному зрению ECCV'16 (11-14 октября) и опубликована на сайте университета. Авторы выложили исходный код для чтения меток и полные наборы данных: как исходные фотографии, так и глубинные изображения с семантической разметкой. Исходный код редактора для аннотирования, вероятно, опубликуют в будущем.
Благодаря прогрессу в создании реалистичных компьютерных игр разработчики систем искусственного интеллекта получат в своё распоряжение отличную платформу для обучения систем машинного зрения. Эти системы будут применяться в беспилотном транспорте и роботах.
Возможно, компьютерные игры можно использовать не только для машинного зрения, но и для создания естественных моделей поведения в обществе. Только при обучения ИИ следует осторожно отнестись к выбору игры.
Источник: geektimes.ru