Batch Normalization для ускорения обучения нейронных сетей
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-09-06 18:02
распознавание образов, новости нейронных сетей, реализация нейронной сети

В современном мире нейронные сети находят себе всё больше применений в различных областях науки и бизнеса. Причем чем сложнее задача, тем более сложной получается нейросеть.
Обучение сложных нейронных сетей иногда может занимать дни и недели только для одной конфигурации. А чтобы подобрать оптимальную конфигурацию для конкретной задачи, требуется запустить обучение несколько раз - это может занять месяцы вычислений даже на действительно мощной машине.
В какой-то момент, знакомясь с представленным в 2015 году методом Batch Normalization от компании Google мне, для решения задачи связанной с распознаванием лиц, удалось существенно улучшить скорость работы нейросети.
За подробностями прошу под кат.
В данной статье я постараюсь совместить две актуальные на сегодняшний день задачи - это задача компьютерного зрения и машинного обучения. В качестве проектировки архитектуры нейронной сети, как я уже и указывал, будет использоваться Batch Normalization для ускорения обучения нейронной сети. Обучение же нейронной сети (написанной с использованием популярной в рамках computer vision библиотеки Caffe) проводилось на базе из 3 миллионов лиц 14 тысяч различных людей.
В моей задаче была необходима классификация на 14700 классов. База разбита на две части: тренировочная и тестовая выборки. Известна точность классификации на тестовой выборке: 94,5%. При этом для этого потребовалось 420 тысяч итераций обучения - а это почти 4 суток (95 часов) на видеокарте NVidia Titan X.
Изначально для данной нейросети использовались некоторые стандартные способы ускорения обучения:
- Увеличение learning rate
- Уменьшение число параметров сети
- Изменение learning rate в процессе обучения особым способом
Все эти методы были применены к данной сети но затем возможность их применять сошла на нет, т.к. стала уменьшаться точность классификации.
В этот момент я открыл для себя новый метод ускорения нейронных сетей - Batch Normalization. Авторы данного метода тестировали его на стандартной сети Inception на базе LSVRC2012 и получили хорошие результаты:
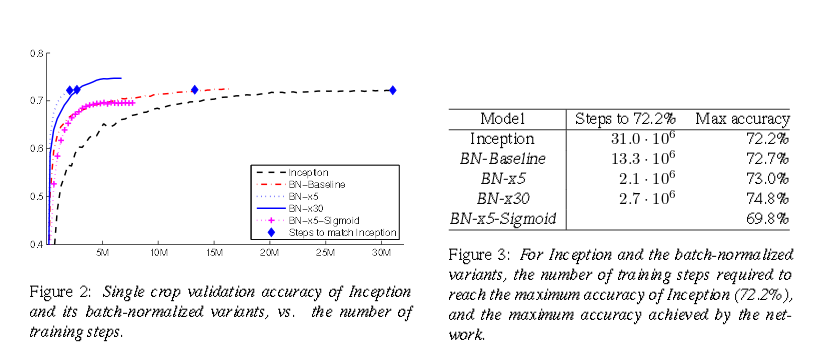
Из графика и таблицы видно что сеть обучилась в 15 раз быстрее и даже достигла более высокой точности в конечном итоге.
Что же из себя представляет Batch Normalization?
Рассмотрим классическую нейронную сеть с несколькими слоями. Каждый слой имеет множество входов и множество выходов. Сеть обучается методом обратного распространения ошибки, по батчам, то есть ошибка считается по какому-то подмножестве обучающей выборки.
Стандартный способ нормировки - для каждого k рассмотрим распределение элементов батча. Вычтем среднее и поделим на дисперсию выборки, получив распределение с центром в 0 и дисперсией 1. Такое распределение позволит сети быстрее обучатся, т.к. все числа получатся одного порядка. Но ещё лучше ввести две переменные для каждого признака, обобщив нормализацию следующим образом:

Получим среднее, дисперсию. Эти параметры будут входить в алгоритм обратного распространения ошибки.
Тем самым получаем batch normalization слой с 2*k параметрами, который и будем добавлять в архитектуру предложенной сети для распознавания лиц.
На вход в моей задаче подаётся черно-белое изображение лица человека размером 50x50 пикселей. На выходе имеем 14000 вероятностей классов. Класс с максимальной вероятностью считается результатом предсказания.
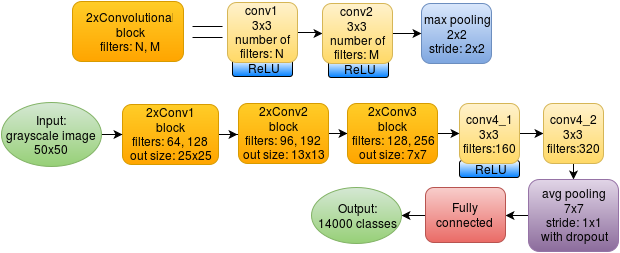
Оригинальная сеть при этом выглядит следующим образом:
Используется 8 свёрточных слоёв, каждый размером 3x3. После каждой свёртки, используется ReLU: max(x, 0). После блока из двух свёрток идёт max-pooling с размером ячейки 2x2 (без перекрытия ячеек). Последний pooling слой имеет размер ячейки 7x7, который усредняет значения, а не берёт максимум. В итоге получается массив 1x1x320, который и подаётся на полносвязный слой.
Сеть же с Batch Normalization выглядит несколько сложнее:
В новой архитектуре каждый блок из двух свёрток содержит слой Batch Normalization между ними. Также пришлось удалить один свёрточный слой из второго блока, так как добавление новых слоёв увеличило расход памяти графической карты.
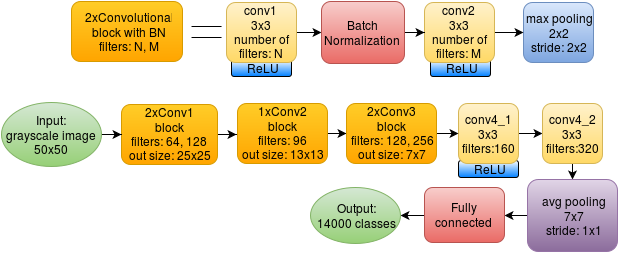
При этом я убран Dropout в соответствии с рекомендациями по применению BN авторов оригинальной статьи.
Экспериментальная оценка
Основная метрика - точность, делим количество правильно классифицированных изображений на количество всех изображений в тестовой выборке.
Основная сложность в оптимизации нейросети с помощью слоя Batch Normalization - подобрать learning rate и правильно его изменять в процессе обучения сети. Чтобы сеть сходилась быстрее, начальный learning rate должен быть больше, а потом снижаться, чтобы результат был точнее.
Было протестированы несколько вариантов изменения learning rate:
| Имя | Формула изменения learning rate | Итераций до точности 80% | Итераций до полной сходимости | Максимальная точность |
|---|---|---|---|---|
| original | 0.01*0.1[#iter/150000] | 64000 | 420000 | 94,5% |
| short step | 0.055*0.7[#iter/11000] | 45000 | 180000 | 86,7% |
| multistep without dropout | 0.055*0.7Nsteps | 45000 | 230000 | 91,3% |
[x] - целая часть
#iter - номер итерации
Nsteps - шаги заданные вручную на итерациях: 14000, 28000, 42000, 120000(x4),160000(x4), 175000, 190000, 210000.
График, демонстрирующий процесс обучения: точность на тестовой выборке в зависимости от количества выполненных итераций обучения нейронной сети:

Оригинальная сеть сходится за 420000 итераций, при этом learning rate за всё время изменяется только 2 раза на 150000-ой итерации и на 300000-ой. Такой подход был предложен автором оригинальной сети, и мои эксперименты с этой сетью показали, что этот подход оптимален.
Но если присутствует слой Batch Normalization, такой подход даёт плохие результаты - график long_step. Поэтому моей идеей было - на начальной стадии менять learning rate плавно, а потом сделать несколько скачков (график multistep_no_dropout). График short_step показывает, что просто плавное изменение learing rate работает хуже. По сути здесь я опираюсь на рекомендации статьи и пытаюсь их применить к оригинальному подходу.
В итоге экспериментов я пришёл к выводу, что ускорить обучение можно, но точность в любом случае будет немного хуже. Можно сравнить задачу распознавания лиц с задачей рассмотренной в статьях Inception (Inception-v3, Inception-v4): авторы статьи сравнивали результаты классификации для различных архитектур и выяснилось, что всё-таки Inception-BN уступает новым версиям Inception без использования Batch Normalization. В нашей задаче получается такая же проблема. Но всё-таки если стоит задача как можно быстрее получить приемлимую точность, то BN как раз может помочь: чтобы достичь точности 80% требуется в 1,4 раза меньше времени по сравнению с оригинальной сетью (45000 итераций против 64000). Это можно использовать, например, для проектирования новых сетей и подбора параметров.
Программная реализация
Как я уже писал, в моей работе используется Caffe - удобный инструмент для глубинного обучения. Всё реализовано на C++ и CUDA, что обеспечивает оптимальное использование ресурсов компьютера. Для данной задачи это особенно актуально, т.к. если бы программа была написана не оптимально не было бы смысла ускорять обучение с помощью изменения архитектуры сети.
Caffe обладает модульностью - есть возможность подключить любой нейросетевой слой. Для слоя Batch Normalization удалось найти 3 реализации:
- BatchNorm в оригинальном caffe (от 25 февраля 2015)
- BN в caffe windows (от 31 марта 2015)
- BatchNorm в CUDNN (от 24 ноября 2015)
Для быстрого сравнения этих реализаций я взял стандартную базу Cifar10 и тестировал всё под операционной системой Linux x64, используя видеокарту NVidia GeForce 740M (2GB), процессор(4 ядра) Intel^ Core(TM) i5-4200U CPU @ 1.60GHz и 4GB RAM.
Реализацию от caffe windows встроил в стандартный caffe, т.к. тестировал под Linux.
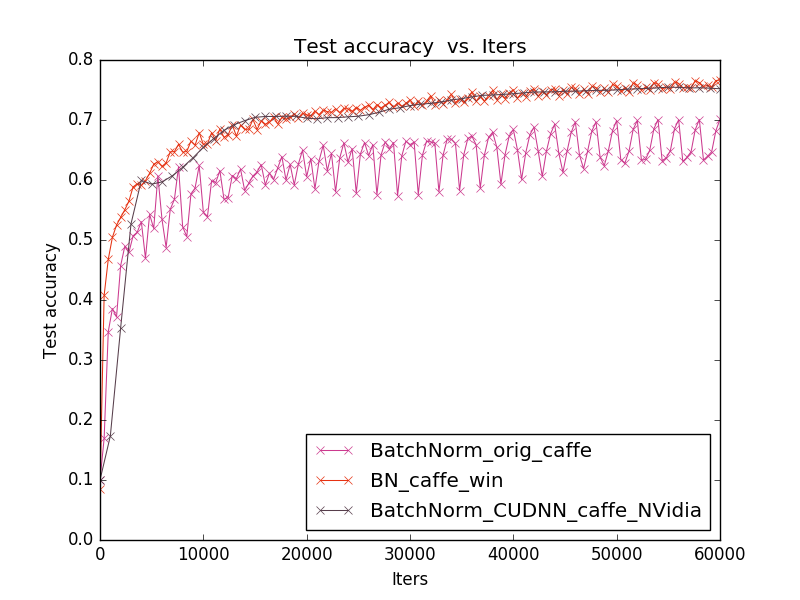
На графике видно, что 1-ая реализация уступает 2-ой и 3-ей по точности, кроме этого в 1-ом и 2-ом случаях точность предсказания изменяется скачками от итерации к итерации (в первом случае скачки намного сильнее). Поэтому для задачи распознавания лиц выбрана именно 3-я реализация (от NVidia) как более стабильная и более новая.
Данные модификации нейросети с помощью добавления слоев Batch Normalization показывают, что для достижения приемлемой точности (80%) потребуется в 1,4 раза меньше времени.
Источник: habrahabr.ru