SOINN - самообучающийся алгоритм для роботов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-08-24 13:57

Пост -1. Что такое SOINN
SOINN - это самоорганизующаяся инкрементная нейронная сеть. Структура и алгоритм такой нейронной сети повидимому хорошо себя зарекомендовал в японской лаборатории Hasegawa (сайт - haselab.info), потому что он в итоге был взят за основу и дальнейшее развитие алгоритмов искусственного интеллекта шло путем небольших модификаций и надстроек к сети SOINN.
Базовая сеть SOINN состоит из двух слоев. Сеть получает входной вектор и на первом слое после обучения создает узел (нейрон) - определяющий класс для входных данных. Если входной вектор похож на существующий класс (мера похожести определяется настройками алгоритма обучения) то два самых похожих нейрона первого слоя объединяются связью, либо если входной вектор не похож не на один существующей класс, то в первом слое создается новый нейрон, определяющий текущий класс. Очень похожие нейроны первого слоя, объединенные связью, определяются как один класс. Первый слой является входным слоем для второго слоя, и по аналогичному алгоритму, с небольшим исключением, создаются классы во втором слое.
На основе SOINN созданы такие сети, как (далее представлены название сети и описание сети от ее создателей):
ESOINN - расширение нейронной сети SOINN обучается в онлайн режиме без стороннего вмешательства и без постановки задачи обучения. Это улучшенный вариант сети SOINN для on-line неконтролируемой классификации и топологии обучения. 1 - эта сеть состоит из одного слоя в отличие от двух слоев в SOINN; 2 - ее кластеры с высокой плотностью перекрытия; 3 - она использует меньшее количество параметров, чем SOINN; и 4 - она более стабильна, чем SOINN. Эксперименты на демо данных и реальных данных также показывают, что ESOINN работает лучше, чем SOINN.
ASC классификатор данных на основе SOINN. Она автоматически определяет количество опытных образцов и усваивает новую информацию, не удаляя при этом уже запомненную информацию. Она устойчива к зашумленным данным, классификация проходит очень быстро. В эксперименте, мы используем как демо данные так и реальные наборы данных для иллюстрации ASC. Кроме того, мы сравниваем ASC с другими результатами на основе классификаторов с учетом его классификации ошибок, сжатия и скорости классификации. Результаты показывают, что ASC имеет лучшую производительность и это очень эффективный классификатор ( Ссылка на оригинал ).
GAM - общая ассоциативная память (GAM) это система, которая сочетает в себе функции другого типа ассоциативной памяти (AM). GAM-это сеть, состоящая из трех слоев: входной слой, слой памяти и ассоциативный слой. Входной слой принимает входные вектора. Слой памяти сохраняет входные данные в похожие классы. Ассоциативный слой строит ассоциативные связи между классами. GAM можете хранить и вызывать двоичную или не двоичную информацию, строить ассоциации многие-ко-многим, хранить и вспоминать, как статические данные, так и временную последовательность информации. Может вспоминать информацию даже если имеет неполные входные данные или зашумленные данные. Эксперименты с использованием двоичных данных в режиме реального времени получая статичные данные и данные временных последовательностей показывают, что GAM является эффективной системой. В экспериментах с использованием человекоподобных роботов демонстрирует, что GAM может решать реальные задачи и строить связи между структурами данных с различными размерами ( Ссылка на оригинал ).
Новинка STAR-SOINN(STAtistical Recognition - Self-Organizing and Incremental Neural Networks) - для построения умного робота, мы должны развивать психическую систему автономного робота, которая последовательно и быстро учится у человека, его среды и Интернета. Поэтому мы предлагаем сеть STAR-SOINN - это ультрабыстрая, мультимодальная сеть обучающаяся в режиме реального времени и обладающая возможностью дополнительно обучатся через интернет. Мы провели эксперименты для оценки этого метода обучения и сравнили результаты с другими методами обучения. Результат показывает, что точность распознавания выше, чем система, которая просто добавляет условия. Кроме того, предлагаемый способ может работать очень быстро (примерно на 1 сек для изучения объекта, 25 миллисекунд, для узнавания объкта). Алгоритм смог выявить атрибуты «неизвестных» объектов путем поиска атрибутивной информации известных объектов. Наконец, мы решили, что эта система потенциально становится базовой технологией для будущих роботов.
SOIAM - модификация SOINN для ассоциативной памяти.
SOINN-PBR - модификация SOINN для создания правил с помощью условий если -> тогда (if-then)
AMD (Autonomous Mental Development) - робот с помощью этого алгоритма учиться решать различные задачи.
Блок схемы алгоритма SOINN можно посмотреть здесь
Ссылка на журнал в формате pdf, где дается описание нескольких разновидностей сетей SOINN на английском и где я делал пометки на русском (журнал я запаковал в архив rar, исходный размер журнала 20 мб (читать онлайн), размер архива 13 мб (скачать архив).
Ссылка на еще один журнал в формате pdf, где дается описание нескольких разновидностей сетей SOINN на английском и где я делал пометки на русском (журнал я запаковал в архив rar, исходный размер журнала 4мб (читать онлайн), размер архива 2,5мб (скачать архив).
В русскоязычном интернете про сеть SOINN есть только пару статей о том, что робот работая по этому алгоритму сам находит решения поставленных задач и если ему не объяснили как решить задачу, то он подключается к интернету и ищет решение там. Но примеров работы алгоритма и кодов я не нашел. Только была одна статья на robocraft где приведен маленький пример работы базового алгоритма сети SOINN в связке с OpenCV. Если кто-то экспериментировал с сетью SOINN было бы интересно посмотреть на код, если возможно.
Еще в 2006 году был предложен метод постепенного (возрастающего) обучения, названый самоорганизующейся возрастающей нейронной сетью (SOINN), для того, чтобы попытаться осуществить неконтролируемое обучение (самообучение без учителя). SOINN хорошо справляется с обработкой нестационарных данных в режиме онлайн, сообщает о числе определенных кластеров и представляет топологическую структуру входных данных с учетом вероятности плотности вероятности распределения. Hasagawa, предложивший вариант сети SOINN, сравнивал результаты работы своей сети с GNG сетью (расширяющегося нейронного газа) и результат сети SOINN получался лучше чем у GNG.
С сетью SOINN была такие проблемы:
1. В связи с тем что она состояла из двух обрабатывающих слоев, что пользователь должен был принимать участие в работе сети. Пользователь должен был решить, когда остановить обучение первого слоя и когда начать приобретение знаний во втором слое.
2. Если группы имеют высокую плотность, то сеть хорошо справлялась с их распознаванием, но если сеть группы частично перекрывались, то сеть думала что это одна группа и объединяла их вместе.
Для решения этих проблем и упрощения архитектуры сети была предложена сеть на основе SOINN с увеличенной самоорганизацией и получила название ESOINN.
Краткий обзор SOINN.
Soinn состоит из сети с двумя слоями. Первый слой изучает плотность распределения входных данных и использует узлы и связи между ними для представления результата распределения данных. Второй слой ищет в первом слое данные с наименьшей плотностью распределения определяя для них группы и использует меньше узлов, чем первый слой, для предоставления топологической структуры изучаемых данных. Когда обучение второго слоя закончено, SOINN сообщает о числе найденных групп и относит входные данные к наиболее подходящей для него группе. Первый и второй слои работают по одинаковому алгоритму.
Когда на сеть подан входной вектор, она находит самый близкий узел (победитель) и второй самый близкий узел (второй победитель) к входному вектору. Используя пороговые критерии подобия, сеть определяет относиться ли входной вектор к той же самой группе как у победителя и второго победителя. Первый слой SOINN адаптивно обновляет порог подобия для каждого узла в отдельности, потому что критерий распределения входных данных заранее неизвестен.
Если некий узел i имеет соседние узлы, тогда порог подобия Ti вычисляется используя максимальное расстояние между этим узлом i и его соседними узлами.
ФОРМУЛА 1А
![]()
Здесь, Ti (порог подобия) - это дистанция до самого удаленного соседа узла i. Wi - вес узла i, Ws - вес соседнего узла i
Если узел i соседних узлов не имеет, тогда порог подобия Ti вычисляется как дистанция между вектором i и самым близким к нему вектором имеющимся в сети.
ФОРМУЛА 1Б
![]()
Здесь, Wn - вес любого узла сети, кроме узла i
В случае если расстояние между входным вектором и победителем или вторым победителем будет больше, чем порог подобия победителя или второго победителя соответственно, тогда входной вектор вставляется в сеть как новый узел и теперь представляет первый узел нового класса. Эту вставку называют вставкой между классами, потому что эта вставка создает поколение нового класса даже если новый класс может быть в будущем классифицирован как какой либо из уже существующих классов.
Если входной вектор определен как принадлежащий к одному кластеру как у победителя или второго победителя, и если нет связей соединяющих победителя и второго победителя, тогда соединим победителя и второго победителя с помощью связи и установим возраст этой связи равной нулю; дальше увеличим возраст всех связей соединенных с победителем на 1.
Потом обновим вес вектора победителя и его узлов соседей. Мы используем узел i с входными данными чтобы найти узел победитель и в переменной узла - Количество_побед -показываем сколько раз узел i был победителем.
Изменим вес победителя по формуле:
ФОРМУЛА 1С
![]()
где Wwin - вес победителя, Cwin - количество побед победителя, Wi - вес входного вектора
Изменим веса всех соседей победителя по формуле:
ФОРМУЛА 1Д
![]()
где Wswin - вес соседа победителя, Cwin - количество побед победителя, Wi - вес входного вектора
Если возраст связи между узлами больше чем предустановленный параметр Максимальный_возраст_связи, тогда удалим эту связь.
Когда во время итерационного обучения сети предустановленный параметр-таймер Время_обучения подошел к концу, тогда SOINN понимает что время для обучения закончено, она вставляет новый узел в точку в топологической карте, где накопленная ошибка является самой большой. Отменим вставку узла, если вставка не может уменьшить размер ошибки. Эта вставка называется вставкой в пределах класса потому, что вставка происходит в пределах класса. Также во время этой вставки никакого нового класса создано не будет. Затем SOINN находит узлы, число соседей у которых меньше или равно одному и удаляет такие узлы, основываясь на предположении о том, что такие узлы лежат в области имеющей малую плотность. Такие узлы называются шумовыми узлами (зашумленными узлами).
По факту, потому что порог подобия первого слоя SOINN обновляется адаптивно, ошибка накопления будет не высока. Поэтому вставка в пределах класса является мало полезной. Вставка в пределах класса для первого слоя не нужна.
После истечения времени итерационного обучения первого слоя, результаты обучения первого слоя подаются в качестве входных данных на второй слой. Второй слой использует такой же алгоритм обучения как и в первом слое. Для второго слоя порог подобия (Ti) является постоянным. Он вычисляется используя расстояние в пределах класса и расстояния между классами. С большим постоянным порогом подобия в отличие от первого слоя, накопленная ошибка для узлов второго слоя будет очень высока, и тут вставка в пределах класса играет большую роль в процессе обучения. С большим постоянным порогом подобия второй слой также может удалить некоторые шумные узлы, которые остаются неудаленными во время обучения первого слоя.
Сеть SOINN с двумя слоями имеет следующие недостатки:
Трудно выбрать, когда остановить обучение первого слоя и начать обучение второго слоя;
Если результаты изучения первого слоя были изменены, все изученные результаты второго слоя будут разрушены, таким образом потребуется переклассификация второго слоя. Второй слой SOINN является неподходящим для постепенного онлайн обучения.
Вставка в пределах класса необходима для второго слоя, однако требует много определенных пользователями параметров.
SOINN неустойчива - она не может отделить классы с высокой плотностью частично перекрывающих друг друга.
Для того чтобы избавиться от вышеупомянутых недостатков, разработчики удалили второй слой SOINN и изменили некоторые методы, чтобы помочь единственному слою получать улучшенные результаты классификации, чем SOINN с двумя слоями. Такая сеть называется ESOINN.
ESOINN принимает данные на единственный слой. Для вставки между классами используется тот же алгоритм что и у SOINN. При создании связи между узлами ESOINN добавляет условие нужно ли создавать связь.
После истечения таймера Время_обучения, ESOINN отделяет узлы на различные подклассы и удаляет связи, которые лежат в перекрытых областях. ESOINN не использует вставку в пределах класса.
Удаление второго слоя делает ESOINN более подходящей для постоянного (возрастающего) онлайн обучения, чем двуслойная SOINN. Это также убирает трудность выбора того, когда нужно заканчивать обучение первого слоя и начинать обучение второго слоя. Отказ от вставки в пределах класса удаляет из сети пять параметров, которые были необходимы для осуществления такой вставки, упрощается понимание алгоритма работы сети.
Алгоритм работы ESOINN
Перекрытие классов (частичное наложение классов друг на друга). Обсудим как определить плотность узла, с помощью какого метода можно найти перекрытие одного класса другим, необходимо ли построить связь между победителем и вторым победителем. Плотность пространственного распределения узлов в перекрытой области ниже, чем в центре класса.
Плотность узлов
Плотность узла определяется локальным аккумулированием числа примеров (входных данных). Если много входных образцов около узла, тогда плотность узла считается высокой, если входных примеров возле узла не много, тогда плотность узла считается низкой. Поэтому, в то время, когда сеть обучается, мы должны считать сколько раз узел был победителем в переменной был_победителем которая и будет показывать плотность этого узла. Определить плотность узла можно таким алгоритмом как SOINN. Здесь появляются следующие проблемы:
1. Будут многочисленные узлы, которые лежат в областях с высокой плотностью. В области с высокой плотностью шанс для узла быть победителем не будет значительно выше чем в области с низкой плотностью. Следовательно мы не можем просто использовать был_победителем узла для того чтобы измерить его плотность.
2. В нарастающих задачах обучения, некоторые узлы, созданные на более ранних стадиях, опять не будут победителями в течение долгого времени. Используя определение был_победителем, такие узлы могут быть оценены как узлы имеющие малую плотность на более поздней стадии обучения.
В ESOINN используется новое определение плотности, помогающее решить проблемы описанные выше. Основная идея такая же как и в локальном накоплении количества входных примеров (данных), но мы определяем «точку» занимающую пространство «чисел» и используем среднее от накопленных точек узла чтобы описать плотность этого узла. В отличие от был_победителем который связывает себя только с одним специальным узлом, здесь рассматривается отношение между узлами, когда мы рассчитываем точку узла. Сначала мы вычисляем среднюю дистанцию ![]() узла i от его соседей.
узла i от его соседей.
ФОРМУЛА 1

Где m - число соседей узла i, Wi - вес вектора узла i, Wj - вес вектора соседа узла i
Потом рассчитываем ТОЧКУ узла i следующим образом:
ФОРМУЛА 2
![]() если узел i является победителем
если узел i является победителем
![]() если узел i не является победителем
если узел i не является победителем
Из определения ТОЧКИ мы видим, что если средняя дистанция от узла i до его соседей является большой, тогда число узлов в этой области маленькое. Следовательно распределение узлов редкое и плотность в этой области будет низка. Таким образом мы даем низкую ТОЧКУ узлу i. Если средняя дистанция маленькая, то это означает что число узлов в этой области высоко и плотность в этой области будет высокая. Поэтому мы даем высокую ТОЧКУ узлу i. Для одной итерации мы вычисляем только ТОЧКИ для узла i, когда узел i - победитель. ТОЧКИ других узлов в этой итерации равны 0. Поэтому для одной итерации, накопленные ТОЧКИ победителя будут изменены, но накопленные ТОЧКИ других узлов остаются неизменными.
Накопление ТОЧЕК Si рассчитывается как сумма ТОЧЕК для узла i в процессе периода его обучения.
ФОРМУЛА 3
")
Здесь sig - это количество входных сигналов в течение одного обучающего периода. n - показывает время периода обучения (которое может быть рассчитано как LT/sig, где LT это среднее итоговое количество входных сигналов).
Поэтому мы берем среднюю накопленную ТОЧКУ (плотность) узла i
ФОРМУЛА 4
")
Здесь N представляет число периодов когда накопленные ТОЧКИ Si больше чем 0. Обратите внимание что N не обязательно равен n. Мы не используем n чтобы брать пространство N потому что, для возрастающего обучения в течение некоторого периода обучения, накопленные ТОЧКИ Si будут равны 0. Если мы используем n чтобы рассчитать среднее накопленных ТОЧЕК, то плотность некоторых старых изученных узлов уменьшится. Используя N для того, чтобы рассчитать среднее накопленных ТОЧЕК, даже во время пожизненного обучения плотность старых изученных узлов будут оставаться неизменной если к системе не будут поданы никакие новые сигналы близкие к этим узлам. Однако для некоторых приложений необходимо чтобы очень старая изученная информация была забыта. В таких случаях мы должны использовать n чтобы брать пространство N. Таким образом мы можем изучать новые знания и забывать очень старые знания. Для того чтобы все изученные знания оставались в сети нужно брать N для определения плотности узла.
Поиск перекрывающихся областей между классами.
Относительно определения плотности, самый простой способ для того чтобы найти перекрытые области это искать области с низкой плотностью. Некоторые методы, такие как GCS и SOINN используют эту технику для определения перекрытых областей. Однако эта техника не может гарантировать, что область с низкой плотностью точно является перекрытой областью. Например, для некоторого класса, который следует Гауссовскому распределению, на границе класса плотность будет низкая. Наложение включает некоторые границы перекрытых классов. Поэтому плотность перекрытия должна быть больше чем в неперекрытой граничной области. Чтобы решить эту проблему, ESOINN не использует правило самой низкой плотности, а скорее создает новую технику для того, чтобы найти перекрытую область.
В SOINN, после периода обучения, если между классами существует перекрытие, все узлы таких классов соединяют чтобы сформировать один класс. Наша цель найти перекрытую область в сложном классе (который включает много групп), избежать построения новых связей между различными классами и таким образом эффективно отделить перекрытые классы.
Чтобы обнаружить перекрытую область, нужно сначала разделить сложный класс на несколько подклассов, используя следующее правило:
Алгоритм 1. Разделение составного класса на подклассы
1. Мы назовем узел вершиной подкласса если узел имеет максимальную локальную плотность. Найдем все вершины в сложном классе и дадим каждой вершине различные метки.
2. Классифицируем все другие узлы с такой же меткой подкласса как и у ихних вершин.
3. Каждый узел лежит в перекрытой области, если соединенные узлы имеют различные метки подклассов.
Такой метод кажется разумным, но для фактической задачи он приведет к нескольким проблемам. Например, существуют два класса в которых распределение плотности узлов не является сглаженным а скорее похоже на наличие шума. С алгоритмом 1 эти два класса будут разделены на слишком большое число подклассов и будет обнаружено много перекрытых областей. Нужно сгладить входные данные прежде чем разделять сложный класс на подклассы.

Рисунок 1
На рисунке 1, два несглаженных входных класса.
Возьмем подкласс А и подкласс В из рисунка 1. Предположим что плотностью вершины подкласса А является Аmax, а плотностью вершины подкласса В является Вmax. Мы объединяем подклассы А и В в один класс, если выполняется следующее условие:
Если
ФОРМУЛА 5
![]()
Или
ФОРМУЛА 6
![]()
Здесь победитель и второй победитель лежат в области перекрытия между подклассами А и В. На самом деле L является параметром, который принадлежит [0,1] который может быть рассчитан автоматически с помощью пороговой функции.
ФОРМУЛА 7
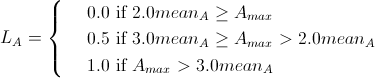
Здесь ![]() является средней плотностью узлов в подклассе.
является средней плотностью узлов в подклассе.
ФОРМУЛА 8
![]()
Здесь N - это количество узлов в подклассе А.
Таким образом, разделяя составной класс на различные подклассы с последующим их объединением без перекрытия подклассов в один подкласс, можно найти перекрытую область внутри составного класса. После того, как мы нашли перекрытую область, мы удаляем связи между уздами, которые принадлежат к различным подклассам и отделяем перекрывающиеся классы.
Алгоритм 2. Создание связей между узлами
1. Соединим два узла связью, если победитель и второй победитель являются новыми узлами (еще не определено к какому подклассу эти узлы относятся)
2. Соединим два узла связью, если победитель и второй победитель принадлежат одинаковому подклассу.
3. Если победитель принадлежит подклассу А, а второй победитель принадлежит подклассу В. Если формулы 5 и 6 выполняются, соединим эти узлы связью и объединим подклассы А и В. В противном случае не будем соединять эти узлы связью, а если соединение между этими узлами уже существует, тогда удалим его.
Используем алгоритм 2, если победитель и второй победитель принадлежат к разным подклассам, ESOINN в таком случае дает этим двум узлам возможность быть соединенными связью. Мы можем сделать так, чтобы ограничить влияние шума во время разделения подклассов и попытаться сгладить колебания подклассов. Подклассы все еще могут быть связаны друг с другом (например подкласс А и подкласс В на рис 1) если два подкласса разделены ошибочно.
Алгоритм 2 показывает что результат ESOINN будет более стабильный, чем у сети SOINN потому, что даже с низкой плотностью перекрытия, SOINN временами будет разделять различные классы правильно, а временами будет распознавать различные классы как один класс. Используя метод сглаживания, ESOINN может стабильно разделять такие перекрытые классы. ESOINN также решает проблемы чрезмерного разделения.
Удаление узлов, вызванных шумом
Чтобы удалить узлы вызванные шумом, SOINN удаляет узлы в регионах с очень низкой вероятной плотностью. SOINN использует такую стратегию: если количество входных сигналов сгенерированных до сих пор являются кратными параметру ![]() , удалим узлы у которых есть только один соседний узел или соседних узлов нет вообще. Для одномерных входных данных и набором данных с низким шумом, SOINN использует локальное накопление количества сигналов узла-кандидата к удалению, чтобы контролировать поведение удаления. Кроме того в двуслойной структуре сети SOINN, второй слой помогает удалить узлы, вызванные шумом.
, удалим узлы у которых есть только один соседний узел или соседних узлов нет вообще. Для одномерных входных данных и набором данных с низким шумом, SOINN использует локальное накопление количества сигналов узла-кандидата к удалению, чтобы контролировать поведение удаления. Кроме того в двуслойной структуре сети SOINN, второй слой помогает удалить узлы, вызванные шумом.
Для ESOINN мы используем практически такую же технику удаления узлов в результате шуми, что и у SOINN. Если число входных сигналов, сгенерированных до сих пор, является кратным параметру ![]() , тогда удалим такие узлы, у которых топологических соседей 2 или меньше двух (<=2). Различие между ESOINN и SOINN в том, что мы также удаляем узлы с двумя топологическими соседями. Мы используем локальное накопление ТОЧКИ и различные параметры управления С1 (для двух соседних узлов) и С2 (для одного соседнего узла) для выбора поведения удаления узлов. Также удаляются узлы с двумя соседями, потому что ESOINN принимает данные только на один слой в котором адаптивно изменяющийся порог подобия создает зашумленные узлы, которые сложно удалить используя оригинальную стратегию SOINN. Ведь SOINN удаляла зашумленные узлы во втором слое. Для однослойной ESOINN, мы должны изменить условия для удаления узлов. Мы добавляем параметр С1 чтобы контролировать процесс удаления и избежать удаления некоторых полезных узлов.
, тогда удалим такие узлы, у которых топологических соседей 2 или меньше двух (<=2). Различие между ESOINN и SOINN в том, что мы также удаляем узлы с двумя топологическими соседями. Мы используем локальное накопление ТОЧКИ и различные параметры управления С1 (для двух соседних узлов) и С2 (для одного соседнего узла) для выбора поведения удаления узлов. Также удаляются узлы с двумя соседями, потому что ESOINN принимает данные только на один слой в котором адаптивно изменяющийся порог подобия создает зашумленные узлы, которые сложно удалить используя оригинальную стратегию SOINN. Ведь SOINN удаляла зашумленные узлы во втором слое. Для однослойной ESOINN, мы должны изменить условия для удаления узлов. Мы добавляем параметр С1 чтобы контролировать процесс удаления и избежать удаления некоторых полезных узлов.
Классификация узлов к различным классам
Допустим у нас есть узел 1 и узел 2 не соединенных друг с другом прямой непосредственной связью. Мы видим что узел 1 соединен связью с узлом 5, узел 5 соединен с узлом 3, а узел 3 соединен с узлом 2. Значит мы можем сказать что между узлом 1 и узлом 2 существует ПУТЬ который их связывает вместе.
Конкурентоспособное правило Хебба здесь подходит для того, чтобы создать ПУТЬ который сохраняет представление данного многообразия узлов. Сетевая структура ПУТЕЙ великолепно позволяет представить топологию карты и сохранить пути представления, если число узлов достаточно для того чтобы получить плотное распределение. С сохранением ПУТЕЙ распределения, конкурентное правило Хебба позволяет определить какие части карты шаблона разделены и образуют различные кластера. Если два узла соединены одним ПУТЕМ, то эти два узла принадлежат одному кластеру. Для классификации узлов здесь мы используем тот же алгоритм, как и у SOINN.
Алгоритм 3. Классификация узлов к различным классам
1. Инициализируем все узлы как неклассифицированные.
2. Случайно выбираем один неклассифицированный узел i из набора узлов А. Помечаем узел i как классифицированный и назначаем ему метку класса Ci
3. Ищем в наборе узлов А все неклассифицированные узлы, которые соединены ПУТЕМ с узлом i. Помечаем эти узлы как классифицированные и назначаем им метку класса такую же как и у узла i.
4. Переходим к шагу 2 до тех пор, пока все узлы не будут классифицированы и не останется неклассифицированных узлов.
И наконец мы подошли к тому, чтобы увидеть полный алгоритм работы сети ESOINN
Алгоритм 4. Расширенный алгоритм самоорганизующейся нейронной сети ESOINN
1. Инициализируем набор узлов А, который содержит два узла с весами векторов выбранными случайным образом из входных данных. Инициализируем пустой набор связей С, где С -А-А
2. Подаем на сеть новый паттерн ![]()
3. Ищем ближайший узел (победитель) a1 и второй ближайший узел (второй победитель) a2 следующим способом:
![]()
![]() Если дистанция между n и a1 или a2 больше чем порог подобия
Если дистанция между n и a1 или a2 больше чем порог подобия ![]() или
или ![]() тогда входной сигнал является новым узлом, добавим его в набор узлов А и перейдем к шагу 2 для получения следующего входного сигнала. Порог T рассчитывается используя формулу 1А или 1Б
тогда входной сигнал является новым узлом, добавим его в набор узлов А и перейдем к шагу 2 для получения следующего входного сигнала. Порог T рассчитывается используя формулу 1А или 1Б
4. Увеличиваем возраст всех связей соединенных с a1 на 1
5. Используем алгоритм 2 для того чтобы определить нужно ли создавать связи между узлами a1 и a2.
А) Если необходимо создавать связь: Если связь между узлами a1 и a2 существует, установим возраст этой связи равный 0; если связи между узлами a1 и a2 не существует, тогда создадим связь между узлами a1 и a2 и установим возраст этой связи равной 0.
Б) Если в создании связи нет необходимости: Если связь между узлами a1 и a2 существует, тогда удалим связь между узлами a1 и a2.
6. Обновим плотность победителя используя формулу 4.
7. Добавим 1 к локальному накопленному количеству сигналов ![]() ,
,![]()
8. Подстроим вес вектора победителя и его топологических соседей фракциями ![]() и
и ![]() от общей дистанции входного сигнала.
от общей дистанции входного сигнала.
![]()
![]() для всех прямых соседей i узла a1
для всех прямых соседей i узла a1
Подстройка происходит по такой же схеме как в SOINN чтобы подстроить скорость времени обучения ![]() и
и ![]()
9. Ищем связи, возраст которых больше чем предопределенный в переменной ![]() и удаляем такие связи.
и удаляем такие связи.
10. Если количество входных сигналов в течение работы кратно параметру k:
А) Обновим метку подкласса для каждого узла по алгоритму 1
Б) Удалим узлы полученные в результате шума следующим образом:
1. Для всех узлов набора А, если узел a имеет два соседа, и 
, тогда удалим узел a. ![]() - это количество узлов в наборе узлов А.
- это количество узлов в наборе узлов А.
2. Для всех узлов в наборе А, если узел а имеет одного соседа и  , тогда удалим узел а.
, тогда удалим узел а.
3. Для всех узлов набора А, если узел а не имеет соседей, тогда удалим узел а.
11. Если процесс обучения закончен, классифицируем узлы к различным классам используя алгоритм 3; потом сообщим количество классов, выходные прототипы векторов каждого класса и остановим обучающий процесс.
12. Перейдем к шагу 2 для продолжения неконтролируемого процесса обучения если обучение еще не закончено.
Используя алгоритм показанный выше, мы вначале находим победителя и второго победителя от входного вектора. Потом мы определяем нужно ли создать связь между победителем и вторым победителем и в зависимости от принятого решения соединяем или удаляем связь между этими узлами. После обновления плотности и веса победителя, мы обновляем метки подклассов после каждого k периода времени обучения. Потом удаляем узлы, которые вызваны шумами. Здесь шум не зависит от k а зависит только от входных данных. После того, как обучение закончено, мы классифицируем все узлы к различным классам. В процессе обучения нам не нужно хранить обученные входные вектора; мы видим что этот алгоритм способен реализовать онлайн обучение. После процесса обучения на сеть подаются входные данные и если сеть знает похожие данные, то новым данным будет присвоен класс похожих данных. Сеть будет обучаться новой информации если дистанция между новыми данными и победителем или вторым победителем больше чем порог подобия. Если дистанция между новыми данными и победителем или вторым победителем меньше чем порога подобия, это означает что входные данные были хорошо усвоены ранее и никаких изменений в сети в этом случае не происходит. Этот процесс делает алгоритм пригодным для возрастающего обучения; сеть изучает новую информацию без удаления ранее усвоенных знаний. Следовательно, нам не нужно перетренировывать сеть, если мы планируем изученные знания узнавать в будущем.
Эксперименты от создателей сети ESOINN
Экспериментальный набор данных.
Сначала мы использовали такой же экспериментальный набор данных - 1 как и Hasegawa для своей сети SOINN. Набор содержит два перекрывающихся Гаусовских распределения, два концентрических кольца и синусоидальную кривую. К этому набору данных было добавлено 10% шума. С таким набором данных, как в стационарной среде так и в нестационарной среде, двуслойная SOINN сообщает, что существует пять классов. Она дает топологическую структуру каждого класса. Стационарная среда предписывает чтобы паттерны выбирались случайно из всего набора данных для онлайн обучения сети. Нестационарная среда предписывает чтобы паттерны выбирались последовательно, не случайно, из пяти областей исходного набора данных - 1 для онлайн обучения сети (рисунок 1). Нестационарная среда используется для симуляции процесса возрастающего онлайн обучения.
 Рисунок 1. Набор данных - 1
Рисунок 1. Набор данных - 1
 Рисунок 2. ESOINN стационарная среда набора данных - 1
Рисунок 2. ESOINN стационарная среда набора данных - 1
 Рисунок 3. ESOINN не стационарная среда набора данных - 1
Рисунок 3. ESOINN не стационарная среда набора данных - 1
Мы тестируем однослойную ESOINN с тем же набором данных. Мы установили параметр k=100, ![]() =100, c1=0.001 и c2=1. Рисунок 2 показывает результат при стационарной среде; рисунок 3 показывает результат при нестационарной среде. В обоих средах ESOINN сообщала что существует пять классов и давала топологическую структуру каждого класса. ESOINN может хорошо реализовать такую же функциональность как и у SOINN для одинаковых экспериментальных наборов данных.
=100, c1=0.001 и c2=1. Рисунок 2 показывает результат при стационарной среде; рисунок 3 показывает результат при нестационарной среде. В обоих средах ESOINN сообщала что существует пять классов и давала топологическую структуру каждого класса. ESOINN может хорошо реализовать такую же функциональность как и у SOINN для одинаковых экспериментальных наборов данных.
Потом мы использовали экспериментальный набор данных - 2 (рисунок 4), который включает в себя три перекрывающихся Гаусовских распределения, для тестирования как SOINN так и ESOINN. Мы добавили 10% шума к этому набору данных. В наборе данных плотность перекрытия области высокая, но используя картинку этого набора данных, зрительно все еще можно разделить его на три класса. При стационарной среде для тренировки сети мы выбираем образцы из набора данных случайным образом. При нестационарной среде образцы выбираются последовательно, не случайно, из трех классов. На первом этапе для тренировки сети мы в реальном времени выбираем образцы из класса 1. После 10000 циклов обучения, мы выбираем образцы только из класса 2. И после еще 10000 обучающих итераций, мы выбираем образцы из класса 3 и выполняем онлайн обучение. После того, как процесс обучения закончен, мы классифицируем узлы к различным классам и сообщаем результат.
 Рисунок 4. Набор данных - 2
Рисунок 4. Набор данных - 2
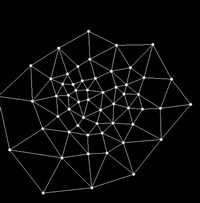 Рисунок 5. SOINN стационарная среда для набора данных - 2
Рисунок 5. SOINN стационарная среда для набора данных - 2
 Рисунок 6. SOINN не стационарная среда для набора данных - 2
Рисунок 6. SOINN не стационарная среда для набора данных - 2
Рисунок 5 и 6 показывают результат SOINN (сеть имела следующие параметры: параметр k=200, ![]() =50, и c =1 и другие параметры, которые идентичны описанным нами в журнале Shen, F., & Hasegawa, O. (2006a). An incremental network for on-line unsupervised classification and topology learning. Neural Networks, 19, 90-106.) Для обоих сред SOINN не смогла разделить три класса с большой плотностью перекрытия.
=50, и c =1 и другие параметры, которые идентичны описанным нами в журнале Shen, F., & Hasegawa, O. (2006a). An incremental network for on-line unsupervised classification and topology learning. Neural Networks, 19, 90-106.) Для обоих сред SOINN не смогла разделить три класса с большой плотностью перекрытия.
 Рисунок 7. ESOINN стационарная среда для набора данных - 2
Рисунок 7. ESOINN стационарная среда для набора данных - 2
 Рисунок 8. ESOINN не стационарная среда для набора данных - 2
Рисунок 8. ESOINN не стационарная среда для набора данных - 2
Рисунки 7 и 8 показывают результаты ESOINN (параметры сети были: параметр k=200, ![]() =50, c1=0.001 и c2=1). Используемые предлагаемые нами усовершенствования для сети SOINN, ESOINN смогла разделить три класса с высокой плотность перекрытия. Система сообщила, что существует три класса во входном наборе данных и дала топологическую структуру для каждого класса. Эксперимент с экспериментальным набором данных - 2 показывает, что ESOINN может разделять классы с высокой плотностью перекрытия лучше, чем SOINN.
=50, c1=0.001 и c2=1). Используемые предлагаемые нами усовершенствования для сети SOINN, ESOINN смогла разделить три класса с высокой плотность перекрытия. Система сообщила, что существует три класса во входном наборе данных и дала топологическую структуру для каждого класса. Эксперимент с экспериментальным набором данных - 2 показывает, что ESOINN может разделять классы с высокой плотностью перекрытия лучше, чем SOINN.
Реальные данные
Для использования реальных данных мы взяли 10 классов из AT&T_FACE набора данных; каждый класс включает в себя 10 примеров (Рисунок 9). Размер каждого изображения составляет 92х112 пикселей, с оттенком цвета на один пиксель 256 уровней серого. Особенности векторов таких изображений состоят в следующем. Первое, оригинальное изображение 92х112, повторной пробой приведено к изображению 23х28 использую интерполяцию ближайшего соседа. Потом использовался Гауссов метод для сглаживания изображения 23х28 с width=4, q=2 для получения 23х28 векторов признаков (рисунок 10)
 Рисунок 9. Оригинальные изображения лиц
Рисунок 9. Оригинальные изображения лиц
 Рисунок 10. Вектор признаков из оригинальных изображений лиц
Рисунок 10. Вектор признаков из оригинальных изображений лиц
В стационарной среде, образцы выбирались случайно из набора данных. Для нестационарной среды на первом шаге в сеть подавались примеры из класса 1, после 1000 итераций обучения, на вход сети подавались примеры из класса 2 и так далее. Параметры сети были установлены: параметр k=25, ![]() =25, c1=0.0 и c2=1.0. Для обоих сред, ESOINN сообщило что в оригинальном наборе данных существует 10 классов и дала прототипы векторов (узлы сети) каждому классу. Мы использовали эти прототипы векторов чтобы классифицировать оригинальные тренировочные данные к различным классам и сообщить об узнавании данных. По сравнению с SOINN, мы получаем практически такое же корректное соотношение узнавания данных (90% для стационарной среды и 86% для нестационарной среды).
=25, c1=0.0 и c2=1.0. Для обоих сред, ESOINN сообщило что в оригинальном наборе данных существует 10 классов и дала прототипы векторов (узлы сети) каждому классу. Мы использовали эти прототипы векторов чтобы классифицировать оригинальные тренировочные данные к различным классам и сообщить об узнавании данных. По сравнению с SOINN, мы получаем практически такое же корректное соотношение узнавания данных (90% для стационарной среды и 86% для нестационарной среды).
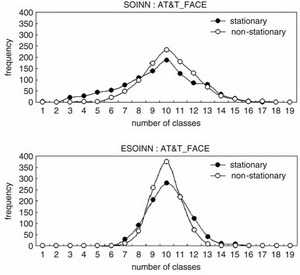 Рисунок 11. Распределение числа классов
Рисунок 11. Распределение числа классов
Для сравнения стабильности SOINN и ESOINN, мы провели 1000 тренировочных итераций для обоих сетей и записали частоту количества классов. На верхней панели рисунка 11 изображен результат SOINN, на нижней панели рисунка 11 - изображен результат ESOINN. Распределение числа классов для SOINN (2-16) гораздо шире, чем для ESOINN (6-14); причем частота вблизи числа 10 у SOINN намного меньше чем у ESOINN, что отражает то, что ESOINN более стабильна, чем SOINN.
Для второй группы реальных данных, мы использовали Optical Recognition of Handwritten Digits database (optdigits) ( www.ics.uci.eduєmlearn/MLRepository.html ) для тестирования SOINN и ESOINN. В этом наборе данных содержится 10 классов (рукописные цифры) написанных 43 людьми, написанные 30 людьми будут использоваться как тренировочный набор и написанные остальными 13 людьми - как тестовый набор. В тренировочном наборе содержится 3823 примера, а в тестовом наборе содержится 1797 примеров. Размерность образца составляет 64.
 Рисунок 12. Результаты рукописных цифр. Сверху SOINN, снизу ESOINN
Рисунок 12. Результаты рукописных цифр. Сверху SOINN, снизу ESOINN
Во-первых, мы использовали тренировочный набор для тренировки SOINN (параметры установили k=200, ![]() =50, и c =1.0 другие параметры описаны в другом нашем журнале). В обоих средах SOINN сообщила что существует 10 классов. Сверху, на рисунке 12, изображен типичный прототип результатов векторов SOINN. Потом мы использовали векторы результата SOINN для классификации тестовых данных. Корректность уровня распознавания для стационарной среды составил 92,2%; корректный уровень распознавания для нестационарной среды составил 90,4%. Мы произвели 100 циклов тестирования для SOINN. Количество классов колебалось от 6 до 13 для обоих сред (стационарной и нестационарной).
=50, и c =1.0 другие параметры описаны в другом нашем журнале). В обоих средах SOINN сообщила что существует 10 классов. Сверху, на рисунке 12, изображен типичный прототип результатов векторов SOINN. Потом мы использовали векторы результата SOINN для классификации тестовых данных. Корректность уровня распознавания для стационарной среды составил 92,2%; корректный уровень распознавания для нестационарной среды составил 90,4%. Мы произвели 100 циклов тестирования для SOINN. Количество классов колебалось от 6 до 13 для обоих сред (стационарной и нестационарной).
Мы использовали тренировочный набор для тренировки ESOINN. Для обоих сред (k=200, ![]() =50, c1=0.001 и c2=1), ESOINN сообщила что существует 12 классов. Снизу на рисунке 12 изображены типичные прототипы результатов векторов ESOINN. ESOINN разделила цифру 1 на два класса и разделила цифру 9 на два класса потому, что на оригинальных изображениях цифр существует разница в написании цифры 1 и 1- так и в написании цифры 9 и 9-. SOINN удалила те узлы, которые были созданы образцами 1- и 9-. ESOINN смогла разделить эти перекрывающиеся классы цифр 1 и 1- (9 и 9-), информация оригинального набора данных сохраняется хорошо.
=50, c1=0.001 и c2=1), ESOINN сообщила что существует 12 классов. Снизу на рисунке 12 изображены типичные прототипы результатов векторов ESOINN. ESOINN разделила цифру 1 на два класса и разделила цифру 9 на два класса потому, что на оригинальных изображениях цифр существует разница в написании цифры 1 и 1- так и в написании цифры 9 и 9-. SOINN удалила те узлы, которые были созданы образцами 1- и 9-. ESOINN смогла разделить эти перекрывающиеся классы цифр 1 и 1- (9 и 9-), информация оригинального набора данных сохраняется хорошо.
Потом мы использовали результаты прототипов векторов ESOINN для классификации тестового набора дынных на классы. Корректный уровень распознавания для стационарной среды составил 94,3% и корректный уровень распознавания для нестационарной среды составил 95,8%. Мы провели 100 циклов тестирования для ESOINN. Количество классов колеблется от 10 до 13 для обоих сред.
Из экспериментов с реальными данными рукописных цифр, мы узнали что ESOINN может разделить перекрывающиеся классы лучше, чем SOINN. ESOINN дает больший уровень узнавания и работает более стабильно чем SOINN.
Заключение
В этой статье была предложена улучшенная разрастающаяся самоорганизующаяся нейронная сеть ESOINN, которая основана на базе SOINN. В отличие от двуслойной SOINN, ESOINN имеет только один слой. ESOINN хорошо справляется с задачей постепенного (возрастающего) изучения информации. В алгоритм ESOINN внесено условие определяющее необходимость создания связи между узлами, что помогло сети находить классы которые перекрывают друг друга. В ESOINN принята только вставка узлов между классов для реализации дополнительного обучения. По этой причине ESOINN легче находит решения и имеет меньше параметров чем SOINN. Используя некоторые методы сглаживания, ESOINN также более стабильна чем SOINN.
Существуют также и другие методы для разделения перекрывающихся классов, такие как Learning Vector Quantization (LVQ). Такие методы принадлежат к методам обучения с учителем и обязаны маркировать все тренировочные примеры. Однако приобретение помеченных данных в процессе обучения требует много ресурсов, в то время как образцы не помеченных данных получать легко и быстро. Даже если некоторые контролируемы методы обучения могут снимать необходимость в контроле за нахождение перекрывающих друг друга классов, все равно очень важно найти такие неконтролируемые методы обучения, которые не нуждаются в использовании помеченных данных. ESOINN и SOINN принадлежат к неконтролируемым методам обучения, которые сами могут оценить область перекрытия классов, где ESOINN хорошо справляется с поставленной задачей. Кроме того она легко находит перекрывающиеся области. Эта особенность делает ESOINN чрезвычайно полезной для некоторых реальных задач.
Блок-схему ESOINN можно посмотреть здесь
Журнал на английском языке с описанием ESOINN размер 1,8 мб. (Читать онлайн)
Для более лучшего понимания работы сети ESOINN нужен реальный код, но в интернете я его не нашел. Наверно придется писать самому.
Зато на Github есть пример кода SOINN на С++ (Ссылка)
А на робокрафте есть небольшой пример работы SOINN в связке с OpenCV ( Ссылка SOINN на робокрафте )
Телеграм: t.me/ainewsline
Источник: habrahabr.ru