R и Spark
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-08-25 21:05

Spark - проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.
Помимо официального пакета SparkR, возможности в машинном обучении которого слабы (в версии 1.6.2 всего одна модель, в версии 2.0.0 их четыре), имеется еще два варианта доступа к Spark.
Первый вариант - это использование продукта от Microsoft - Microsoft R Server for Hadoop, в который недавно была интегрирована поддержка Spark. Используя данный продукт, можно производить вычисления по одним и тем же функциям R, в контексте локальных вычислений, Hadoop (map-reduce) или Spark. Помимо локальной установки R и доступа к кластеру Spark, облачная служба Microsoft Azure HDInsight позволяет развернуть готовые кластеры, и, кроме обычного кластера Spark, имеется возможность развернуть кластер R Server on Spark. Данный сервис представляет собой кластер Spark с предустановленным R server for Hadoop на дополнительном, пограничном узле, что позволяет сразу производить вычисления, как локально на данном сервере, так и переключаться на контекст Spark или Hadoop. Использование данного продукта достаточно хорошо описано в официальной документации к HDInsight на сайте Microsoft.
Второй вариант -это использование нового пакета sparklyr, который пока находится в стадии разработки. Этот продукт разрабатывается под эгидой RStudio - компании, под крылом которой выпущены одни из самых полезных и необходимых пакетов -knitr, ggplot2, tidyr, lubridate, dplyr и другие, поэтому этот пакет может стать еще одним лидером. Пока данный пакет слабо документирован, так как еще официально не выпущен.
На основе документации и экспериментов с каждым из этих способов работы со Spark, подготовил следующую таблицу (Табл. 1) с обобщенными функциональными возможностями каждого из способов (также добавил SparkR 2.0.0, в котором возможностей стало чуть больше).
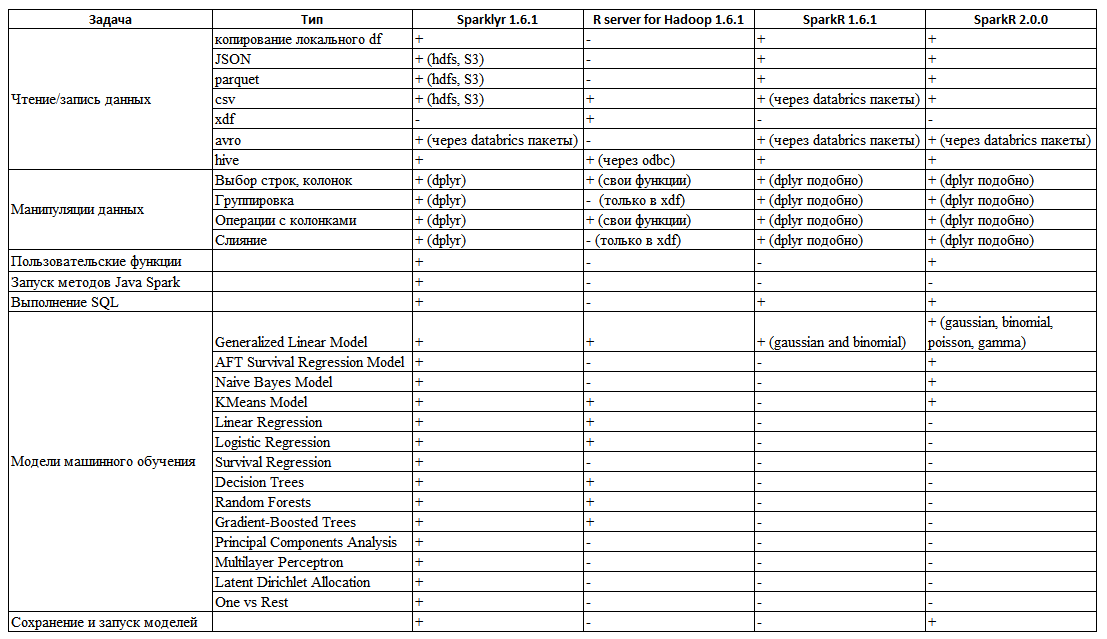
Таблица 1. Обзор возможностей разных способов взаимодействия с Spark
Как видно из таблицы, нет ни одного средства в полной мере реализующие необходимые потребности «из коробки», но пакет sparklyr выгодно отличается от SparkR и R Server. Основные его достоинства - чтение csv, json, parquet файлов из hdfs. Полностью совместимый с dplyr синтаксис манипулирования данными - включающий в себя операции фильтрации, выбора колонок, агрегирующие функции, возможности выполнять слияние данных, модификацию имен колонок и многое другое. В отличии от SparkR или R server for Hadoop, где некоторые из этих задач либо не выполняются, либо выполняются очень неудобно (в R server for Hadoop слияния данных для объектов нет вовсе, оно поддерживается только для встроенного типа данных xdf). Еще одним достоинством пакета является возможность написания функций для запуска методов Java непосредственно из R кода.
Пример
Благодаря этому, можно реализовать отсутствующую функциональность пакета, используя существующие методы java в Spark или реализовав их самостоятельно.
И, разумеется, количество моделей машинного обучения значительно больше, чем у SparkR (даже в версии 2.0) и R server for Hadoop. Поэтому остановим свой выбор на данном пакете, как наиболее перспективном и удобном в использовании. Кластер Spark был развернут, при использовании Azure HDInsight облачной службы предлагающей развертывание 5 типов кластеров (HBase, Storm, Hadoop, Spark, R Server on Spark), в разных конфигурациях при минимальных усилиях.
Вначале разворачиваем кластер Spark - я выбрал конфигурацию с 2 головными узлами D12v2 и 4 рабочими узлами D12v2. (D12v2: 4 ядра/28 ГБ ОЗУ, 200 ГБ диск, данная конфигурация не совсем оптимальна, но для демонстрации синтаксиса sparklyr подходит). Описание разворачивания разных типов кластером и работы с ними описано в документации на HDInsight. После успешного разворачивания кластера, используя подключение по SSH к рабочему узлу, устанавливаем туда R и RStudio, с необходимыми зависимостями. RStudio желательно использовать preview редакции, так как в ней появились дополнительные возможности для пакета sparklyr - дополнительное окно, в котором отображаются исходные датафреймы в Spark, и возможность просмотреть их свойства или их самих. После установки R, R Studio, переустанавливаем соединение, используя туннелирование на localhost:8787.
Итак, теперь в браузере по адресу localhost:8787 мы подключаемся к RStudio и продолжаем работать.
Весь код данной задачи приведен в конце данного поста.
Для данной тестовой задачи, будем использовать csv файлы NYC Taxi датасета, расположенные по адресу NYC Taxi Trips. Данные представляют собой информации о поездках на такси и их оплате. Для целей ознакомления, ограничимся одним месяцем. Построение модели на том же полном наборе данных, но используя R Server for Hadoop (в контексте Hadoop), описано в следующей статье: Exploring NYC Taxi Data with Microsoft R Server and HDInsight. Но там чтение файлов, вся предобработка - фильтрация данных, слияние таблиц было выполнено в Hive, и в R Server лишь строили модель, здесь же все, сделано на обычном R используя sparklyr.
Переместив оба файла в hdfs кластера Spark, и используя функцию sparklyr, читаем данные файлы.
Файлы по поездкам и тарифам связаны по ключу - столбцам "medallion", "hack_licence" и "pickup_datetime", поэтому выполним присоединение слева к датафрейму data, датафрейма fare. После объединения данных и манипуляций, сохраняем датафрейм в формате parquet. Прежде чем строить модель, посмотрим на данные, для этого создадим выборку из 2000 случайных наблюдений и передадим их в R, используя collect. На данной малой выборке, построили стандартную диаграмму ggplot2 (зависимость чаевых от платы за проезд, с указанием размера точки - расстоянием маршрута и цветом точки количеством пассажиров, и разбитой на панель-сетку по типам оплаты и оператору такси) (рис. 1).
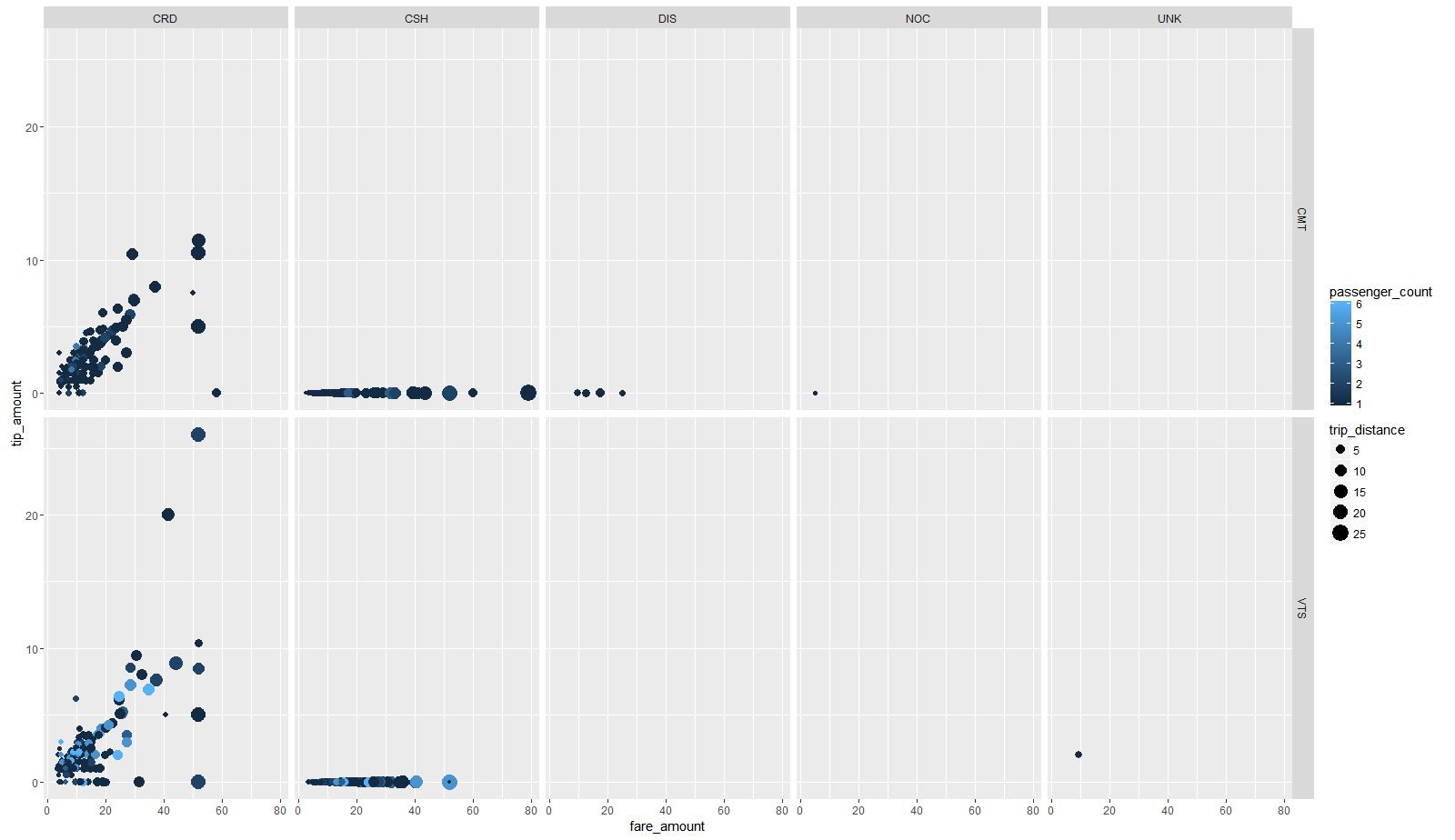
Рисунок 1 Диаграмма изображающая основные зависимости
На ней видно, что присутствует зависимость (линейная, как «стандарт» % от счета) размера чаевых от стоимости проезда, большая часть платежей осуществлена с использованием кредитной карты (панель CRD) и наличных (панель CSH), и что при оплате наличными чаевые всегда отсутствуют (вероятно, это объясняется тем, что при оплате наличными чаевые уже входят в стоимость оплаты, а при оплате картой нет). Поэтому в выборке для обучения оставляем только те поездки, которые оплачивались кредитной картой. Объединенный датафрейм, используя удобный синтаксис dplyr, и пайпинг magrittr, передаем дальше по цепочке: последующий отбор строк (исключая выбросы и нелогичные значения) и колонок (оставляя только необходимые для построения модели), передаем финальный датасет в функцию линейной регрессии. Для тренировки модели используем 70% всех данных, для теста оставшиеся 30%. Для данной задачи используем простую линейную регрессию. Зависимость, которую мы хотим обнаружить, это размер чаевых от параметров поездки. Данная модель на этих данных достаточно вырождена и не вполне корректна (имеется большое число чаевых равных 0), но она проста, покажет интерпретируемые коэффициенты модели и позволит продемонстрировать основные возможности sparklyr. В модели будем использовать следующие предикторы: vendor_id - идентификатор оператора такси, passenger_count - число пассажиров, trip_time_in_secs - время поездки, trip_distance - расстояние поездки, payment_type - тип платежа, fare_amount - цена поездки, surcharge - сбор. В результате обучения, модель имеет следующий вид:
Используя данную модель, предсказываем значения на тестовой выборке.
В данной статье приведены основные функциональные возможности трех способов взаимодействия с Spark в R и приведен пример, реализующий чтение файлов, их предобработку, манипуляции с ними и построение простейшей модели машинного обучения, используя пакет sparklyr.
Обзор средств взаимодействия со Spark
Помимо официального пакета SparkR, возможности в машинном обучении которого слабы (в версии 1.6.2 всего одна модель, в версии 2.0.0 их четыре), имеется еще два варианта доступа к Spark.
Первый вариант - это использование продукта от Microsoft - Microsoft R Server for Hadoop, в который недавно была интегрирована поддержка Spark. Используя данный продукт, можно производить вычисления по одним и тем же функциям R, в контексте локальных вычислений, Hadoop (map-reduce) или Spark. Помимо локальной установки R и доступа к кластеру Spark, облачная служба Microsoft Azure HDInsight позволяет развернуть готовые кластеры, и, кроме обычного кластера Spark, имеется возможность развернуть кластер R Server on Spark. Данный сервис представляет собой кластер Spark с предустановленным R server for Hadoop на дополнительном, пограничном узле, что позволяет сразу производить вычисления, как локально на данном сервере, так и переключаться на контекст Spark или Hadoop. Использование данного продукта достаточно хорошо описано в официальной документации к HDInsight на сайте Microsoft.
Второй вариант -это использование нового пакета sparklyr, который пока находится в стадии разработки. Этот продукт разрабатывается под эгидой RStudio - компании, под крылом которой выпущены одни из самых полезных и необходимых пакетов -knitr, ggplot2, tidyr, lubridate, dplyr и другие, поэтому этот пакет может стать еще одним лидером. Пока данный пакет слабо документирован, так как еще официально не выпущен.
На основе документации и экспериментов с каждым из этих способов работы со Spark, подготовил следующую таблицу (Табл. 1) с обобщенными функциональными возможностями каждого из способов (также добавил SparkR 2.0.0, в котором возможностей стало чуть больше).
Таблица 1. Обзор возможностей разных способов взаимодействия с Spark
Как видно из таблицы, нет ни одного средства в полной мере реализующие необходимые потребности «из коробки», но пакет sparklyr выгодно отличается от SparkR и R Server. Основные его достоинства - чтение csv, json, parquet файлов из hdfs. Полностью совместимый с dplyr синтаксис манипулирования данными - включающий в себя операции фильтрации, выбора колонок, агрегирующие функции, возможности выполнять слияние данных, модификацию имен колонок и многое другое. В отличии от SparkR или R server for Hadoop, где некоторые из этих задач либо не выполняются, либо выполняются очень неудобно (в R server for Hadoop слияния данных для объектов нет вовсе, оно поддерживается только для встроенного типа данных xdf). Еще одним достоинством пакета является возможность написания функций для запуска методов Java непосредственно из R кода.
Пример
count_lines <- function(sc, file) { spark_context(sc) %>% invoke("textFile", file, 1L) %>% invoke("count") } count_lines(sc, "/text.csv")Благодаря этому, можно реализовать отсутствующую функциональность пакета, используя существующие методы java в Spark или реализовав их самостоятельно.
И, разумеется, количество моделей машинного обучения значительно больше, чем у SparkR (даже в версии 2.0) и R server for Hadoop. Поэтому остановим свой выбор на данном пакете, как наиболее перспективном и удобном в использовании. Кластер Spark был развернут, при использовании Azure HDInsight облачной службы предлагающей развертывание 5 типов кластеров (HBase, Storm, Hadoop, Spark, R Server on Spark), в разных конфигурациях при минимальных усилиях.
Используемые ресурсы
- Кластер HDInsight Apache Spark 1.6 на Linux (развертывание кластера подробно описано в документации Microsoft Azure)
- R 3.3.2 инсталлированный на головной узел
- RStudio preview редакции (доп. возможности для sparklyr), инсталлированный также на головной узел
- Putty клиент, для установления сессии с головным узлом кластера и туннелирования порта RStudio на порт локального хоста (настройка RStudio и его туннелирования описана в документации Microsoft Azure)
Настройка среды
Вначале разворачиваем кластер Spark - я выбрал конфигурацию с 2 головными узлами D12v2 и 4 рабочими узлами D12v2. (D12v2: 4 ядра/28 ГБ ОЗУ, 200 ГБ диск, данная конфигурация не совсем оптимальна, но для демонстрации синтаксиса sparklyr подходит). Описание разворачивания разных типов кластером и работы с ними описано в документации на HDInsight. После успешного разворачивания кластера, используя подключение по SSH к рабочему узлу, устанавливаем туда R и RStudio, с необходимыми зависимостями. RStudio желательно использовать preview редакции, так как в ней появились дополнительные возможности для пакета sparklyr - дополнительное окно, в котором отображаются исходные датафреймы в Spark, и возможность просмотреть их свойства или их самих. После установки R, R Studio, переустанавливаем соединение, используя туннелирование на localhost:8787.
Итак, теперь в браузере по адресу localhost:8787 мы подключаемся к RStudio и продолжаем работать.
Подготовка данных
Весь код данной задачи приведен в конце данного поста.
Для данной тестовой задачи, будем использовать csv файлы NYC Taxi датасета, расположенные по адресу NYC Taxi Trips. Данные представляют собой информации о поездках на такси и их оплате. Для целей ознакомления, ограничимся одним месяцем. Построение модели на том же полном наборе данных, но используя R Server for Hadoop (в контексте Hadoop), описано в следующей статье: Exploring NYC Taxi Data with Microsoft R Server and HDInsight. Но там чтение файлов, вся предобработка - фильтрация данных, слияние таблиц было выполнено в Hive, и в R Server лишь строили модель, здесь же все, сделано на обычном R используя sparklyr.
Переместив оба файла в hdfs кластера Spark, и используя функцию sparklyr, читаем данные файлы.
Манипуляция данными
Файлы по поездкам и тарифам связаны по ключу - столбцам "medallion", "hack_licence" и "pickup_datetime", поэтому выполним присоединение слева к датафрейму data, датафрейма fare. После объединения данных и манипуляций, сохраняем датафрейм в формате parquet. Прежде чем строить модель, посмотрим на данные, для этого создадим выборку из 2000 случайных наблюдений и передадим их в R, используя collect. На данной малой выборке, построили стандартную диаграмму ggplot2 (зависимость чаевых от платы за проезд, с указанием размера точки - расстоянием маршрута и цветом точки количеством пассажиров, и разбитой на панель-сетку по типам оплаты и оператору такси) (рис. 1).
Рисунок 1 Диаграмма изображающая основные зависимости
На ней видно, что присутствует зависимость (линейная, как «стандарт» % от счета) размера чаевых от стоимости проезда, большая часть платежей осуществлена с использованием кредитной карты (панель CRD) и наличных (панель CSH), и что при оплате наличными чаевые всегда отсутствуют (вероятно, это объясняется тем, что при оплате наличными чаевые уже входят в стоимость оплаты, а при оплате картой нет). Поэтому в выборке для обучения оставляем только те поездки, которые оплачивались кредитной картой. Объединенный датафрейм, используя удобный синтаксис dplyr, и пайпинг magrittr, передаем дальше по цепочке: последующий отбор строк (исключая выбросы и нелогичные значения) и колонок (оставляя только необходимые для построения модели), передаем финальный датасет в функцию линейной регрессии. Для тренировки модели используем 70% всех данных, для теста оставшиеся 30%. Для данной задачи используем простую линейную регрессию. Зависимость, которую мы хотим обнаружить, это размер чаевых от параметров поездки. Данная модель на этих данных достаточно вырождена и не вполне корректна (имеется большое число чаевых равных 0), но она проста, покажет интерпретируемые коэффициенты модели и позволит продемонстрировать основные возможности sparklyr. В модели будем использовать следующие предикторы: vendor_id - идентификатор оператора такси, passenger_count - число пассажиров, trip_time_in_secs - время поездки, trip_distance - расстояние поездки, payment_type - тип платежа, fare_amount - цена поездки, surcharge - сбор. В результате обучения, модель имеет следующий вид:
Call: ml_linear_regression(., response = "tip_amount", features = c("vendor_id", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount", "surcharge")) Deviance Residuals: (approximate): Min 1Q Median 3Q Max -27.55253 -0.33134 0.09786 0.34497 31.35546 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.2743e-01 1.4119e-03 231.9043 < 2e-16 *** vendor_id_VTS -1.0557e-01 1.1408e-03 -92.5423 < 2e-16 *** passenger_count -1.0542e-03 4.1838e-04 -2.5197 0.01175 * trip_time_in_secs 1.3197e-04 2.0299e-06 65.0140 < 2e-16 *** trip_distance 1.0787e-01 4.7152e-04 228.7767 < 2e-16 *** fare_amount 1.3266e-01 1.9204e-04 690.7842 < 2e-16 *** surcharge 1.4067e-01 1.4705e-03 95.6605 < 2e-16 *** --- Signif. codes: 0 -***- 0.001 -**- 0.01 -*- 0.05 -.- 0.1 - - 1 R-Squared: 0.6456 Root Mean Squared Error: 1.249Используя данную модель, предсказываем значения на тестовой выборке.
Выводы
В данной статье приведены основные функциональные возможности трех способов взаимодействия с Spark в R и приведен пример, реализующий чтение файлов, их предобработку, манипуляции с ними и построение простейшей модели машинного обучения, используя пакет sparklyr.
Исходный код
devtools::install_github("rstudio/sparklyr") library(sparklyr) library(dplyr) spark_disconnect_all() sc <- spark_connect(master = "yarn-client") data_tbl<-spark_read_csv(sc, "data", "taxi/data") fare_tbl<-spark_read_csv(sc, "fare", "taxi/fare") fare_tbl <- rename(fare_tbl, medallionF = medallion, hack_licenseF = hack_license, pickup_datetimeF=pickup_datetime) taxi.join<-data_tbl %>% left_join(fare_tbl, by = c("medallion"="medallionF", "hack_license"="hack_licenseF", "pickup_datetime"="pickup_datetimeF", )) taxi.filtered <- taxi.join %>% filter(passenger_count > 0 , passenger_count < 8 , trip_distance > 0 , trip_distance <= 100 , trip_time_in_secs > 10 , trip_time_in_secs <= 7200 , tip_amount >= 0 , tip_amount <= 40 , fare_amount > 0 , fare_amount <= 200, payment_type=="CRD" ) %>% select(vendor_id,passenger_count,trip_time_in_secs,trip_distance, fare_amount,surcharge,tip_amount)%>% sdf_partition(training = 0.7, test = 0.3, seed = 1234) spark_write_parquet(taxi.filtered$training, "taxi/parquetTrain") spark_write_parquet(taxi.filtered$test, "taxi/parquetTest") for_plot<-sample_n(taxi.filtered$training,1000)%>%collect() ggplot(data=for_plot, aes(x=fare_amount, y=tip_amount, color=passenger_count, size=trip_distance))+ geom_point()+facet_grid(vendor_id~payment_type) model.lm <- taxi.filtered$training %>% ml_linear_regression(response = "tip_amount", features = c("vendor_id", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount", "surcharge")) print(model.lm) summary(model.lm) predicted <- predict(model.lm, newdata = taxi.filtered$test) actual <- (taxi.filtered$test %>% select(tip_amount) %>% collect())$tip_amount data <- data.frame(predicted = predicted,actual = actual) Телеграм: t.me/ainewsline
Источник: habrahabr.ru