Как мы учили нейронную сеть распознавать платья и туфли
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-08-08 22:06

Михаил Погребняк, СЕО Kuznech, рассказал Rusbase, как компания разрабатывала систему, которая распознает типы одежды и обуви, сложно ли обучать нейронную сеть и что делать тем, кто только собирается этим заняться.
Поиск одежды по фото с телефона - это для девочек, скажете вы. Это не для серьёзных айтишников, скажете вы. И вообще, где высоконаучные технологии, а где ммм- мир ванильной моды и гламура?
Когда в 11 году мы стали резидентом ИТ-кластера «Сколково» и чуть позже подписали контракт с «Одноклассниками» на разработку сложной вычислительной программы по обнаружению лиц, мы тоже так рассуждали. Мол, всю жизнь будем работать в крутых научных сферах, никаких тебе няшек.
Но какое-то время спустя, изучая мировую статистику по визуальному поиску, онлайн- и мобильной коммерции, общим тенденциям на мировом рынке ритейла, мы поняли, что интерес бизнеса к мобильному распознаванию одежды, обуви и аксессуаров (внутри команды мы называем это общим словом fashion) быстро растёт.
Проиллюстрируем.
Немного цифр
Индустрии одежды, моды и предметов роскоши - рынок очень перспективный. Маркетологи и финансисты McKinsey в своём исследовании утверждают, что в период между 2014 и 2020 годами темпы роста мировой индустрии одежды будут выражаться двузначными числами. Причём рост будет происходить за счёт развивающихся рынков (Россия, конечно, тоже сюда относится) и в значительной степени за счёт азиатских покупателей (урбанизация Китая по темпам сейчас в 10 раз превосходит аналогичный процесс в Великобритании в 19 веке).
Если говорить только о рынке женской одежды, то в ближайшие 12 лет его рост составит свыше 50% про всему миру (согласно исследованию McKinsey - Unleashing Fashion Growth City by City).
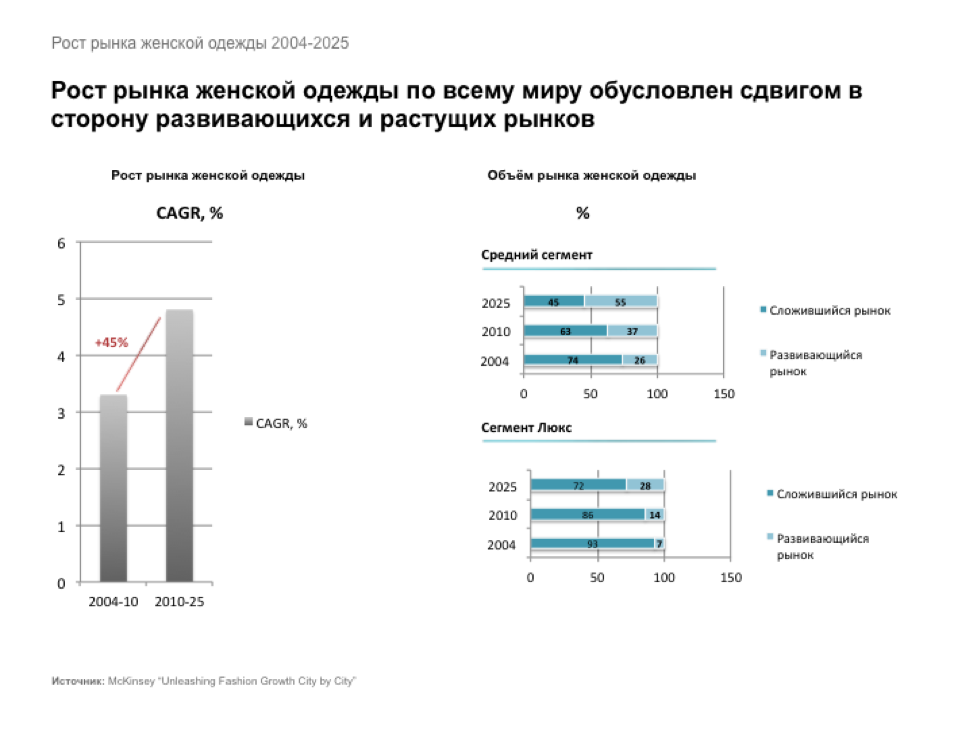
С одеждой разобрались. Поняли, что рынок растёт - значит, тут есть возможности для развития технологий. Хорошо.
Дальше мы стали изучать тенденции онлайн-шоппинга. Заглянули в Америку. В 2015 году 205 миллионов американцев (при населении 325 миллионов - то есть это больше 60%) хоть раз искали товары в интернете, сравнивали цены или покупали что-то онлайн. Ожидается, что к 2019 году что эта цифра достигнет 224 миллионов.
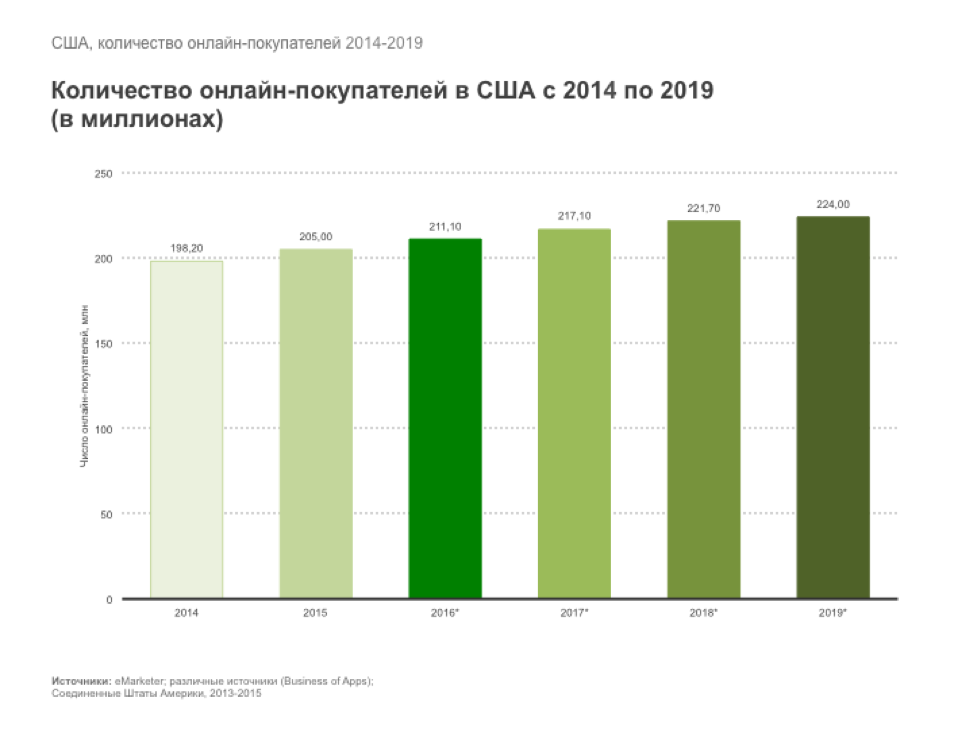
Похожая тенденция наблюдается и глобально: в исследовании к конференции ООН по торговле и развитию (United Nations Conference on Trade and Development) говорится, что к 2018 году около 1,623 миллиардов человек по всему миру будут покупать товары и услуги в интернете (сравнить с 1,039 миллиардов в 2013).
При этом интересно проследить, что сегмент мобильной коммерции (то есть покупок, сделанных с мобильных устройств) тоже растёт. В одной только Америке, по прогнозам eMarketer, доходы мобильного ритейла к 2018 достигнут 130.12 миллиардов долларов (с 56,67 миллиардов долларов в 2014) - это более чем в два раза.
Мировая тенденция к «мобилизации» онлайн-покупок тоже очевидна. Goldman Sachs опубликовали отчёт, согласно которому за 5 лет сегмент м-коммерции с точки зрения числа пользователей вырастет в 5 раз: с 379 миллионов пользователей в 2013 до более 1 миллиарда покупателей в 2018 (надо заметить, что в отчёте не учитываются онлайн-покупки в сегменте «Путешествия»).
Одежда, надо сказать, согласно исследованиям Nielsen, - это наиболее часто покупаемая в онлайне категория - ей уступают только книги, канцелярия и музыка.
По сути, происходит вот что: к нашему времени рынок интернет-доступа достиг своей точки насыщения, прирост пользователей значительно замедлился (прогнозируется на уровне 5-10% в последующие годы). Рост рынка смартфонов тоже стремится к нулю.
Посмотрите, например, презентацию выступления Марка Цукерберга на конференции Facebook F8.
Это значит, что интернет и рынок смартфонов стали тем, что называется commodity, товарами массового спроса, частью повседневности. А вот покупки через мобильные устройства - это новые паттерны поведения, которые дают пространство для развития новых технологий.
Все эти факты послужили основой для того, чтобы мы задумались, как можно применить нашу технологию нейронных сетей и сделать что-то интересное и нужное в этой сфере. Так, в 2014 году мы стали разрабатывать систему мобильного распознавания одежды.
Как и зачем учить систему распознавать платья?
Сама идея мобильного распознавания проста: пользователь видит какой-то понравившийся ему fashion-предмет (на человеке на улице, в витрине магазина или на обложке журнала), фотографирует его на мобильное устройство, загружает фото в установленное мобильное приложение, которое распознаёт товар на изображении и подбирает похожие товары из ассортимента магазина. Товары, конечно, можно сразу купить. Всё.
Иными словами, пользовательские ожидания от работы сервиса можно свести к трём шагам: увидел - сфотографировал - купил.
Чтобы разработать и построить такую систему, нам пришлось обработать более 30 000 000 изображений, понять разницу между пуловером и джемпером (есть ещё свитера и кофты, и это всё разные вещи), ботинками дерби и монки, сумками дафл и тоут, открыть свою «кунсткамеру», арендовать манекены, почувствовать себя юными (ну не совсем юными, ладно) модельерами - и много чего ещё. Но обо всём по порядку.
Систему мобильного распознавания мы решили строить на нейронных сетях - это квинтэссенция технологии глубинного обучения. Сети имитируют работу нейронов человеческого мозга с точки зрения обучения и исправления ошибок: сеть самостоятельно обучается (при достаточном количестве обучающих данных) и действует на основании предыдущего опыта, с каждым новым обучением допуская всё меньше и меньше ошибок.
Нейрон - это отдельный вычислительный элемент сети; каждый нейрон связан с нейронами предыдущего и следующего слоёв сети. Когда на вход поступает изображение, видео- или аудиофайл, оно последовательно проходит обработку всеми слоями сети. В зависимости от результатов, сеть может изменить свою конфигурацию (параметры каждого нейрона).
Для нашей задачи нейросети хороши тем, что при необходимом объёме обучающих данных они способны научиться распознавать практически любой тип объектов.
Шаг 1: Узнать о моде всё
Итак, с технологической точки зрения система должна работать в такой последовательности: анализ загруженного фото системой - выделение областей, потенциально содержащих товар - определение категории товара - отделение объекта от фона - создание цифрового отпечатка (digital fingerprint) изображения товара - поиск похожих товаров в заданной категории.
Первым пунктом в R&D-плане стало создание правильной, полной и точной классификации моды.
Начать мы решили с классификации обуви. Причём женской - нам показалось, что это проще (стоило сразу перекреститься, наивные глупцы). Поняли: чтобы система могла правильно распознавать категории, нам нужна подробная классификация видов women shoes. В ход пошли Википедия, толковые словари, сайты обувных онлайн-магазинов и картинки из Google типа такой:

Параллельно с поиском изображений по категориям и разметкой мы завели внутреннюю папку «Кунсткамера», которую стали пополнять примеры необычной (а то и откровенно странной) обуви, часть из которой хотелось сразу «развидеть». К примеру, у нас есть такие экспонаты:
Такие изображения для обучения сети мы, понятно, не брали. Это для себя - «чисто, чтобы поржать» (с).
После категоризации женского раздела (более 50 категорий) мы перешли к мужской обуви, выделив около 30 классов. Коллекция «Кунсткамеры» пополнялась.

А мы поняли, что существует обувь «унисекс». Например, такие категории обуви, как эспадрильи, мокасины или тимберленды внешне могут быть очень похожи - как у мужчин, так и у женщин.
Всего в унисекс мы отнесли 10 категорий.
Так, всего мы выделили чуть меньше 100 категорий обуви, после чего подвели итоги, с какими вызовами нам пришлось встретиться на этом шаге.
Первое - это сама по себе классификация. Какие именно категории выделять? Не будут ли они слишком мелкими? Или, наоборот, излишне укрупнёнными?
Тут нам помогала структура каталогов наших конечных клиентов - интернет-магазинов. Мы брали за основу их категоризацию, приводя её к тому виду, что могла удовлетворить нашим требованиям (быть универсальной для российских и американских магазинов, не слишком общей и не слишком подробной).
Второе - спорность в отнесении некоторых товаров к определённой категории. Например, что это? Ботильоны или кроссовки?

Внешне, конечно, ботильоны, но на сайтах некоторых онлайн-магазинов такая обувь находится в категории кроссовок. Как узнать, в какой категории захочет искать подобные ботинки клиент?
Третье - детальность классификатора. Иногда приходилось «занудничать» и для более точного поиска выделять дополнительные категории, не всегда коррелирующие с категориями магазинов (не путать с фильтрами поиска!), чтобы добиться лучших результатов распознавания.
Так у нас появились ботильоны на танкетке, ботильоны на шпильке, ботильоны на широком каблуке, ботильоны с мехом и т.д.
Четвёртое - сложность с подбором картинок в некоторые категории. Было время, когда, например, изображения топсайдеров можно было найти только на зарубежных ресурсах - в наших магазинах эта обувь ещё не была широко представлена.
И последнее. Мы не понимали, как будет вести себя нейронка с определением материала обуви. То есть будет ли сеть по высоким кожаным сапогам искать именно кожаные сапоги или в результатах поиска будут все сапоги похожей формы, но разного материала?
И, как следствие, мы не знали, нужно ли выделять категории по материалу: кожаные туфли, замшевые туфли, туфли из ткани и т.д.
Для пробы сделали 2 категории: «Замшевые сапоги» и «Кожаные сапоги» (они, разумеется, пересекаются с другими категориями - высокие сапоги, сапоги на танкетке и прочими). Сеть распознаёт их правильно. Но разделять все типы обуви по материалу на непересекающиеся категории мы в итоге не стали - было бы излишне. А эти две «исторически сложившиеся» категории оставили. Правильной работе они не мешают.
В общем, после того, как мы подготовили классификатор обуви, мы стали считать себя чем-то вроде микса из Александра Васильева, Вячеслава Зайцева и Валентина Юдашкина.
Наша внутренняя переписка
Затем по такому же принципу мы стали выделять женские и мужские сумки, а после - женскую и мужскую одежду.
Шаг 2: Обучить нейронные сети отличать монки от лоферов, а пуловер от джемпера
Итак, мы определили fashion-категории, с которыми предстоит работать нашей системе. Теперь нужно обучить нейронные сети распознавать категории на фото: то есть определять, в каком месте на снимке находится искомый объект, и корректно классифицировать его.
Чтобы обучить нейронную сеть распознавать одну категорию, первым делом нужно отобрать и загрузить в сеть (мы называем этот процесс «скормить сети») немалое количество картинок: от тысячи до нескольких сотен тысяч.
То есть, чтобы научить систему распознавать категорию «Туфли на каблуке», нужно скачать из интернета от двух и более тысяч разных картинок туфель на каблуке. Принцип простой: больше обучающих данных - лучше работа сети (точнее распознавание).
Скачивание картинок для обучения ведётся наполовину автоматически нашими внутренними алгоритмами, наполовину вручную. После массив фотографий проверяется, чтобы не было дублей и случайных неподходящих картинок. Далее все файлы приводятся к единообразным названиям и одному формату (расширению).
А потом начинается самое сложное: ручная разметка товаров на картинке. Наши сотрудники на фотографии обводят рамкой товар и определяют его категорию.
Например:
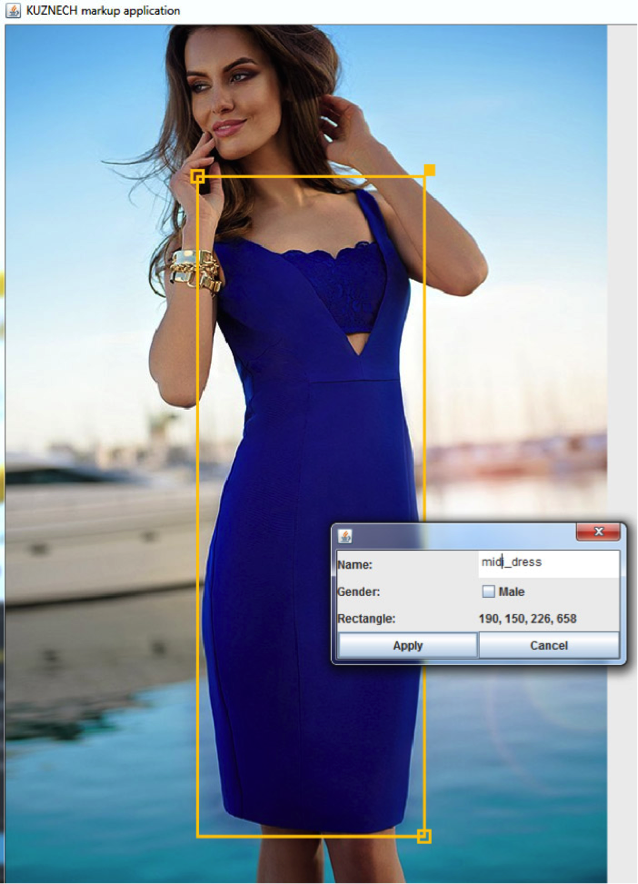
Это нужно, чтобы система поняла: вот конкретно то, что в прямоугольнике, - это товар определённой категории. На работы по разметке уходит больше всего времени: задача это кропотливая и движется очень не быстро. Если измерять человеко-часы, потраченные на разметку, в чашках кофе, то на выходе получится не одна тонна бодрящего напитка.
С чем тут бодались
На шаге разметки боком вышло отсутствие опыта и дальновидности: после выделения новых категорий сумок и одежды нам пришлось переразмечать на новые товары уже размеченные ранее фотографии обуви. Из-за отсутствия разметки на новые категории система находила одежду, но считала, что ошиблась, и заносила найденные товары в «фон».
То есть если бы мы сначала определили все возможные категории обуви, одежды и аксессуаров (привели классификатор к тому виду, что есть сейчас) и только потом размечали бы изображения на все категории сразу, то мы бы сэкономили массу ресурсов.
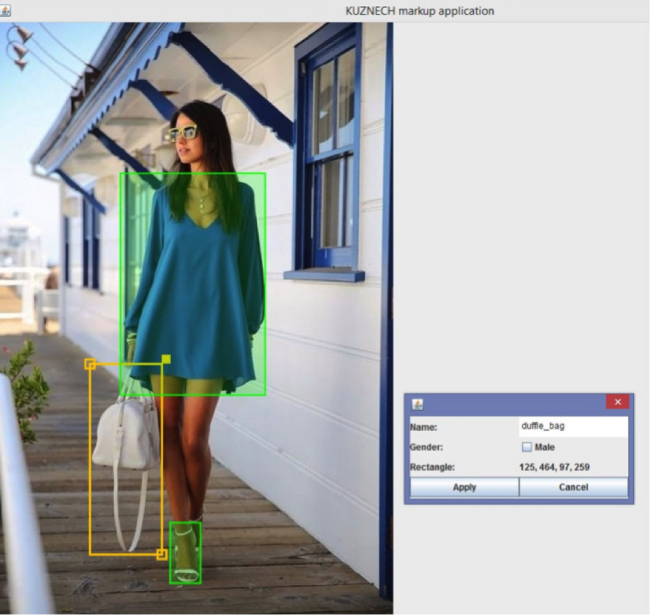
Ещё одним узким моментом оказалось то, что разметкой занималось несколько сотрудников. И случалось так, что каждый по-своему понимал, какой предмет одежды в какую категорию относить (о спорных случаях мы писали выше). Поэтому был назначен ответственный сотрудник, который принимал от своих коллег размеченные фотографии и перепроверял все папки и картинки на корректность разметки.
Вот как выглядит наш fashion-классификатор на примере женской обуви (одна из страниц):

Нейросетеводы, или кто ещё занимается распознаванием fashion
Нейронные сети сейчас популярны далеко за пределами узкопрофессиональных сообществ. Всплеск интереса к искусственному интеллекту со стороны массовой публики был зафиксирован в начале этой весны, когда AlphaGo, сеть-игрок в го от Google, выиграла раунд у Ли Си Дола, чемпиона мира по этой игре. Перцу в историю добавили пользовательские стартапы по стилизации изображений Prisma, Mlvch и более ранняя Deepart.io.
Не будет громким сказать, что за нейронными сетями будущее. Причём не только в сфере дорогих недостижимых гаджетов, о которых обычный человек может только читать в новостях, но и в повседневной жизни.
Нейросети сейчас широко используются для обработки и распознавания изображений, в системах распознавания речи, видеоаналитики, интеллектуальной безопасности. Сети создают музыку (Jukedeck). Не за горами времена, когда появятся нейросетевые боты, заменяющие человеческий интеллект в ряде видов деятельности (например, в колл-центре, консультирующем клиента по элементарным вопросам).
Вообще надо сказать, что сетями занимаются очень многие. Это акулы интернет-рынка: «Яндекс» (например, их недавняя фича для Auto.ru для распознавания марки и модели авто по изображению), Microsoft (сервис What-Dog.net, определяющий породы собак по фото), Mail.ru и Facebook (подразделение Facebook AI Research), и, понятно, Google. Но также это и молодые стартапы (те, у которых достаточно средств на вычислительные мощности).
Усердно сети изучают в технических вузах по всему миру, в частности, в МФТИ. Кстати, в конкурсах научных исследований мы регулярно выходим в финал вместе с разработчиками этого института.
Конкурентов в этом поле, конечно, немало. По нашим данным, на конец весны этого года в сфере распознавания fashion работают около 23 компании из 10 стран. Крупные игроки западных рынков онлайн-ритейла уже обработаны местными компаниями: e-Bay, Zalando, the Net Set, Macy's, Yoox - список можно продолжать. Но мы думаем, что места хватит всем.
Как заняться нейронными сетями и не сойти с ума
Возможно, вы сейчас тоже захотели заниматься сетями. Круто!
Тогда сразу озвучим два момента, к которым нужно быть готовыми.
Ещё раз проговорим, что немаловажная часть технологии - это обучающие данные. Это первое «но». Чтобы сеть умела успешно различать один вид объекта, необходимо собрать несколько тысяч примеров этого объекта, на которых провелось бы обучение. Зачастую количество объектов исчисляется сотнями. Итоговые обучающие базы данных могут насчитывать сотни тысяч, миллионы объектов.
Поэтому подготовка базы - это очень трудоёмкий процесс. К нам приходят иногда стартапы, говорят, вот, хотим сделать распознавание, как у Pinterest, со ссылками на товары из Amazon. «Классно, - говорим мы, -можно устроить. Но надо много картинок на каждый товар, чтобы сеть работала. Сможем собрать?». После этого заказчики почему-то растворяются в пространстве.
Хотя надо оговориться, что сейчас появляются различные технологии ускоренного обучения. Например, общедоступный массив уже обученных картинок ImageNet; предобученные нейронные сети, умеющие распознавать образы и не требующие долгой подготовки сети к работе.
По аппаратной части тоже виден прогресс - существуют высокопроизводительные видеокарты, позволяющие обучать и использовать сети в несколько сотен раз быстрее.
И второе - хранение и обработка больших массивов данных требует значительных вычислительных мощностей и средств на инфраструктуру. Для обучения и работы сетей нужны карты минимум с 3-4 Гб памяти, а для некоторых архитектур требуются и все 11 гигов. Карточки недешёвые: на один небольшой проект уходит карта стоимостью примерно 100 000 рублей. Плюс требуется много дискового пространства под сами данные.
Итог
Таким образом, технология нейросетей широко развивается, и спрос на неё велик. В интернете можно найти массу литературы и исследований по теме, доступен даже программный код сетей. То есть, с одной стороны, технология является вроде как общедоступной, но, с другой стороны, на настоящий момент она остаётся сложной и малоизученной. Крупные компании регулярно проводят всевозможные конкурсы на лучшие алгоритмы, и зачастую битва идёт всего лишь за десятые и сотые доли точности алгоритмов.
Так, с нашей бумагой по мобильному распознаванию в сфере fashion мы прошли в финал KDD, крупнейшей конференции в мире в области Knowledge Discovery and Data Mining. Текст доклада доступен по ссылке.
Мы продолжаем пахать развивать технологию.
Источник: rusbase.com