Введение.Основы генетических алгоритмов | Лекция | НОУ ИНТУИТ
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-07-19 17:31
Предисловие
Среди множества проблем, которые возникают перед исследователями как в области теории, так и в многочисленных практических приложениях значительную долю составляют так называемые оптимизационные проблемы. Понятие оптимальности, по-видимому, знакомо почти каждому и вошло в практику большинства предметных областей. С оптимизационной проблемой мы сталкиваемся каждый раз, когда возникает необходимость выбора из некоторого множества возможных решений наилучшего по определенным критериями и, как правило, удовлетворяющего заданным условиям и ограничениям. Само понятие оптимальности получает совершенно строгое толкование в математических теориях, однако в других областях оно может интерпретироваться скорее содержательно. Тем не менее различие между строгим и содержательным понятиями оптимальности, как правило, очень незначительно.
Существуют классы оптимизационных задач, решение которых удается находить с помощью достаточно эффективных методов, вполне приемлемых по трудоемкости. Вместе с тем имеются и такие классы оптимизационных задач (так называемые NP- полные задачи), решение которых невозможно найти без полного перебора вариантов. В частности, к числу последних относятся многие разновидности задач многокритериальной оптимизации. Известно, что при большой размерности этих задач реализация перебора вариантов практически невозможна из-за чрезвычайно больших временных затрат.
В этой ситуации альтернативным походом к решению упомянутых задач является применение методов, базирующихся на методологии эволюционных вычислений. Предлагаемое пособие содержит изложение основ эволюционных вычислений и их приложений к решению различных проблем, включая проблемы экономики, прогнозирования финансовых рынков, инвестиций, бизнеса, комбинаторной оптимизации, сложных задач в различных технических разработках и т.п. Эффективность различных методов в рамках эволюционного подхода подтверждается многочисленными данными, касающимися достигаемым реальным эффектом. При этом хотя объем вычислений может оказаться большим, но скорость, с которой он растет при увеличении размерности задачи, обычно меньше, чем у остальных известных методов. Отметим, что после того как компьютерные системы стали достаточно быстродействующими и недорогими, эволюционные методы превратились в важный инструмент поиска близких к оптимальным решений задач, которые до этого считались неразрешимыми.
Основной целью учебного пособия является систематическое изложение перспективного направления в области теории и практики искусственного интеллекта. Пособие рассчитано на студентов и аспирантов вузов, обучающихся по направлениям, связанным с прикладной информатикой и математикой, компьютерными и программными системами, с интеллектуальными системами обработки информации.
Освоение представленного в пособии материала предполагает знакомство читателя с математикой и информатикой в объеме первых двух курсов технического вуза, основами дискретной математики и методов оптимизации.
Введение
В настоящее время оформилось и успешно развивается новое направление в теории и практике искусственного интеллекта - эволюционные вычисления (ЭВ). Этот термин обычно используется для общего описания алгоритмов поиска, оптимизации или обучения, основанных на некоторых формализованных принципах естественного эволюционного отбора. Особенности идей эволюции и самоорганизации заключаются в том, что они являются плодотворными и полезность их применения не только для биологических систем перманентно подтверждается. Эти идеи в настоящее время с успехом используются при разработке многих технических и, в особенности, программных систем.
Высокая согласованность и эффективность работы элементов биологических систем приводила целый ряд исследователей к естественной мысли о возможности использования принципов биологической эволюции для оптимизации важных для приложений систем, природа которых отлична от биологической. Так, в 1966 году Фогель Л., Оуенс С. и Уолш М. в [1] подобную идею использовали для построения схемы эволюции логических автоматов, решающих задачи прогноза. В 1975 году была опубликована основополагающая работа Дж. Холланда [2], в которой был предложен генетический алгоритм, развивающий ту же идею. Д.Гольдберг, ученик Дж. Холланда, в работе [3] , выполненной в Мичиганском университете, успешно развил и расширил области его применения.
В 60-х годах прошлого века в Германии Рохенберг И., Швефель Г.-П., и др. [4] начали разработку так назывемой эволюционной стратегии. Перечисленные работы послужили толчком и основой развития прикладного направления, которое можно назвать эволюционными алгоритмами. К их числу, помимо упомянутых генетических алгоритмов и эволюционных стратегий, относятся также эволюционное программирование, ориентированное на оптимизацию функций без использования рекомбинаций, и генетическое программирование, использующее эволюционные идеи для оптимизации компьютерных программ. Основополагающая работа по эволюционному программированию принадлежит Дж. Коза [5] из Массачусетского технологического института.
Отметим, что аналогичные исследования успешно проводились отечественными учеными еще в Советском Союзе. Так, значительный вклад в развитие указанных направлений внесли Ивахненко А.Г. [6], Цыпкин Я.З. [7], Расстригин Л.А. [8] и др. В настоящее время исследования по ЭВ активно ведутся Букатовой [9,10], Курейчиком В.М. [11,12,13], их сотрудниками и учениками, а также многими другими исследователями.
Учебное пособие состоит из пяти частей.
В первой части "Основы генетических алгоритмов" (разделы пособия 1-5) изложены идейная сторона простых генетических алгоритмов, их математические основы, подробно описаны примеры построения генетических алгоритмов для решения конкретных задач комбинаторной оптимзации и, наконец, представлены современные модификации и обобщения этих алгоритмов.
Во второй части "Генетическое программирование и машинное обучение" (разделы 6-7) описана концепция компьютерного синтеза программ (с различными структурами их представления - линейными, древовидными, графоподобными) с использованием генетических алгоритмов. Изложены два основных подхода при машинном обучении - Мичиганский и Питтсбургский.
В третьей части "Вероятностные генетические алгоритмы"(раздел 8) приведен другой - вероятностный подход в эволюционных вычислениях, где популяция представляется вектором вероятностей.
В четвертой части "Эволюционные стратегии" (раздел 9) представлена оригинальная парадигма, основанная на эволюции популяции потенциальных решений. Ее принципиалное отличие состоит в том, что генетические операторы используются здесь на уровне фенотипа, а не генотипа, как это было в генетических алгоритмах.
В пятой части "Эволюционное программирование" (раздел 10) содержится описание основанного Фогелем Л.Дж. гибкого подхода в эволюционных вычислениях. В нем форма представления потенциального решения и генетические операторы адаптируются к решаемой проблемы в достаточно широких пределах. В частности, в качестве особи в процессе эволюции Фогелем используются конечные автоматы и целью эволюции является способность решения задач прогнозирования.
В шестой части "Роевой интеллект" (разделы 11-12) описаны принципы и методы оптимизации, базирующиеся на коллективном поведении децентрализованных самоорганизующихся систем. Такие системы представляются, например, в виде графа, содержащего множество вершин (агентов), локально взаимодействующих между собой и с окружающей средой. Имеющиеся экспериментальные данные подверждают эффективность роевого интеллекта (муравьиных, пчелиных, роевых и т.п. алгоритмов) для решения многих оптимизационных задач.
Заканчивая введение заметим, что в пособии представлены не все аспекты быстро развивающихся эволюционных вычислений. Мы ограничились здесь расмотрением только наиболее важных и принципиальных с нашей точки зрения моментов эволюционных вычислений, хотя по этому поводу могут быть и другие мнения.
1. Введение в генетические алгоритмы
В этом разделе описывается концепция простого генетического алгоритма (ГА), ориентированного на решение различных оптимизационных задач. Вводятся и содержательно описываются понятия, используемые в теории и приложениях ГА. Приводится фундаментальная теорема ГА и излагается теория схем, составляющие теоретическую базу ГА. Обсуждаются концептуальные вопросы, касающиеся преимуществ и недостатков ГА.
1.1. Простой генетический алгоритм
Основы теории генетических алгоритмов сформулированы Дж. Г.Холландом в основополагающей работе [2] и в дальнейшем были развиты рядом других исследователей. Наиболее известной и часто цитируемой в настоящее время является монография Д.Голдберга [3], где систематически изложены основные результаты и области практического применения ГА.
ГА используют принципы и терминологию, заимствованные у биологической науки - генетики. В ГА каждая особь представляет потенциальное решение некоторой проблемы. В классическом ГА особь кодируется строкой двоичных символов - хромосомой, каждый бит которой называется геном. Множество особей - потенциальных решений составляет популяцию. Поиск оптимального или субоптимального решения проблемы выполняется в процессе эволюции популяции, т.е. последовательного преобразования одного конечного множества решений в другое с помощью генетических операторов репродукции, кроссинговера и мутации. ЭВ используют механизмы естественной эволюции, основанные на следующих принципах:
- Первый принцип основан на концепции выживания сильнейших и естественного отбора по Дарвину, который был сформулирован им в 1859 году в книге "Происхождение видов путем естественного отбора". Согласно Дарвину особи, которые лучше способны решать задачи в своей среде, чаще выживают и чаще размножаются (репродуцируют). В генетических алгоритмах каждая особь представляет собой решение некоторой проблемы. По аналогии с этим принципом особи с лучшими значениями целевой (фитнесс) функции имеют большие шансы выжить и репродуцировать. Формализацию этого принципа, как мы увидим далее, реализует оператор репродукции.
- Второй принцип обусловлен тем фактом, что хромосома потомка состоит из частей, полученных из хромосом родителей. Этот принцип был открыт в 1865 году Г.Менделем. Его формализация дает основу для оператора скрещивания (кроссинговера).
- Третий принцип основан на концепции мутации, открытой в 1900 году де Вре. Первоначально этот термин использовался для описания существенных (резких) изменений свойств потомков и приобретение ими свойств, отсутствующих у родителей. По аналогии с этим принципом генетические алгоритмы используют подобный механизм для резкого изменения свойств потомков и, тем самым, повышают разнообразие (изменчивость) особей в популяции (множестве решений).
Эти три принципа составляют ядро ЭВ. Используя их, популяция (множество решений данной проблемы) эволюционирует от поколения к поколению.
Эволюцию искусственной популяции - поиск множества решений некоторой проблемы, формально можно описать в виде алгоритма, который представлен на рис.1.1.
ГА получает множество параметров оптимизационной проблемы и кодирует их последовательностями конечной длины в некотором конечном алфавите (в простейшем случае в двоичном алфавите "0" и "1").
Предварительно простой ГА случайным образом генерирует начальную популяцию хромосом (стрингов). Затем алгоритм генерирует следующее поколение (популяцию) с помощью трех следующих основных генетических операторов:
- оператора репродукции (ОР);
- оператора скрещивания (кроссинговера, ОК);
- оператора мутации (ОМ).
Генетические алгоритмы - это не просто случайный поиск, они эффективно используют информацию, накопленную в процессе эволюции.
В процессе поиска решения необходимо соблюдать баланс между "эксплуатацией" полученных на текущий момент лучших решений и расширением пространства поиска. Различные методы поиска решают эту проблему по-разному.
Например, градиентные методы практически основаны только на использовании лучших текущих решений, что повышает скорость сходимости с одной стороны, но порождает проблему локальных экстремумов с другой. В полярном подходе случайные методы поиска используют все пространство поиска, но имеют низкую скорость сходимости. В ГА предпринята попытка объединить преимущества этих двух противоположных подходов. При этом операторы репродукции и кроссинговера делают поиск направленным. Широту поиска обеспечивает то, что процесс ведется на множестве решений - популяции и используется оператор мутации.

Рис. 1.1. Простой генетический алгоритм
В отличие от других методов оптимизации ГА оптимизируют различные области пространства решений одновременно и более приспособлены к нахождению новых областей с лучшими значениями целевой функции за счет объединения квазиоптимальных решений из разных популяций.
Упомянутые генетические операторы являются математической формализацией приведенных выше трех основополагающих принципов Ч.Дарвина, Г.Менделя и де Вре естественной эволюции. Каждый из функциональных блоков ГА на рис. 1.1. может быть реализован различными способами. Но сначала на простом примере мы рассмотрим основные моменты классического ГА.
1.2. Генетические операторы
Рассматриваемый ниже пример заимствован из популярной монографии Голдберга [3] и состоит в поиске целочисленного значения (для простоты) ![]() на отрезке от [0,31], при котором функции
на отрезке от [0,31], при котором функции ![]() принимает максимальное значение.
принимает максимальное значение.

Рис. 1.2. Пример функции
Начальный этап работы ГА для данного примера приведен в верхней таблице (репродукция) рис.1.3 Здесь особи начальной популяции (двоичные коды значений переменных ![]() - столбец 2) сгенерированы случайным образом. Двоичный код значения х называется хромосомой (она представляет генотип). Популяция образует множество потенциальных решений данной проблемы. В третьем столбце представлены их десятичные значения (фенотип). Далее на этом примере проиллюстрируем работу трех основных генетических операторов.
- столбец 2) сгенерированы случайным образом. Двоичный код значения х называется хромосомой (она представляет генотип). Популяция образует множество потенциальных решений данной проблемы. В третьем столбце представлены их десятичные значения (фенотип). Далее на этом примере проиллюстрируем работу трех основных генетических операторов.
1.2.1. Репродукция
Репродукция - это процесс, в котором хромосомы копируются в промежуточную популяцию для дальнейшего "размножения" согласно их значениям целевой (фитнесс-) функции. При этом хромосомы с лучшими значениями целевой функции имеют большую вероятность попадания одного или более потомков в следующее поколение.
Очевидно, оператор репродукции (ОР) является искусственной версией естественной селекции - выживания сильнейших по Ч. Дарвину. Этот оператор представляется в алгоритмической форме различными способами (подробнее различные варианты ОР будут рассмотрены далее). Самый простой (и популярный) метод реализации ОР - построение колеса рулетки, в которой каждая хромосома имеет сектор, пропорциональный по площади значению ее целевой функции. Для нашего примера "колесо рулетки" имеет вид, представленный на рис.1.4.
Для селекции хромосом используется случайный поиск на основе колеса рулетки. При этом колесо рулетки вращается и после останова ее указатель определяет хромосому для селекции в промежуточную популяцию (родительский пул).

Рис. 1.3. Эволюция популяции
Очевидно, что хромосома, которой соответствует больший сектор рулетки, имеет большую вероятность попасть в следующее поколение. В результате выполнения оператора репродукции формируется промежуточная популяция, хромосомы которой будут использованы для построения поколения с помощью операторов скрещивания.
В нашем примере выбираем хромосомы для промежуточной популяции, вращая колесо рулетки 4 раза, что соответствует мощности начальной популяции. Величину ![]() обозначим как
обозначим как ![]() , тогда ожидаемое количество копий i-ой хромосомы определяется значением
, тогда ожидаемое количество копий i-ой хромосомы определяется значением ![]()
, где N-мощность популяции. Число копий хромосомы, переходящих в следующее поколение, иногда определяется и так: ![]() , где
, где ![]() - среднее значение хромосомы в популяции.
- среднее значение хромосомы в популяции.

Рис. 1.4. Колесо рулетки
Расчетные числа копий хромосом по приведенной формуле следующие: хромосома 1 - 0,56; хромосома 2 - 1,97; хромосома 3 - 0,22; хромосома 4 - 1,23. В результате, в промежуточную популяцию 1-я хромосома попадает в одном экземпляре, 2-я - в двух, 3-я - совсем не попадает, 4-я - в одном экземпляре. Полученная промежуточная популяция является исходной для дальнейшего выполнения операторов кроссинговера и мутации.
1.2.2 Оператор кроссинговера (скрещивания)
Одноточечный или простой оператор кросинговера (ОК) с заданной вероятностью ![]() выполняется в три этапа:
выполняется в три этапа:
1-й этап. Две хромосомы (родители) выбираются случайно (или одним из методов, рассмотренных далее) из промежуточной популяции, сформированной при помощи оператора репродукции (ОР).

2-й этап. Случайно выбирается точка скрещивания - число ![]() из диапазона
из диапазона ![]() , где
, где ![]() - длина хромосомы (число бит в двоичном коде).
- длина хромосомы (число бит в двоичном коде).
Две новых хромосомы A', B' (потомки) формируются из A и B путем обмена подстрок после точки скрещивания:
![]()
Например, рассмотрим выполнение кроссинговера для хромосом 1 и 2 из промежуточной популяции:
![]()
Следует отметить, что ОК выполняется с заданной вероятностью (отобранные два родителя не обязательно производят потомков). Обычно величина вероятности полагается равной
![]() .
.
Таким образом, операторы репродукции и скрещивания очень просты - они выполняют копирование особей и частичный обмен частей хромосом. Продолжение нашего примера представлено на рис.1.3 во второй таблице (кроссинговер).
Сравнение с предыдущей таблицей показывает, что в промежуточной популяции после скрещивания улучшились все показатели популяции (среднее и максимальное значения целевой функции - ЦФ).
1.2.3 Мутация
Далее согласно схеме классического ГА с заданной вероятностью ![]() выполняется оператор мутации. Иногда этот оператор играет вторичную роль. Обычно вероятность мутации мала -
выполняется оператор мутации. Иногда этот оператор играет вторичную роль. Обычно вероятность мутации мала - ![]()
Оператор мутации (ОМ) выполняется в два этапа:
1-й этап. В хромосоме ![]()
случайным образом выбирается ![]() -ая позиция (бит)
-ая позиция (бит) ![]()
.
2-й этап. Производится инверсия значения гена в ![]() -й позиции:
-й позиции: ![]()
Например, для хромосомы 11011 выбирается ![]() и после инверсии значения третьего бита получается новая хромосома - 11111. Продолжение нашего примера представлено в третьей таблице (мутация) рис.1.3 образом, в результате применения генетических операторов найдено оптимальное решение
и после инверсии значения третьего бита получается новая хромосома - 11111. Продолжение нашего примера представлено в третьей таблице (мутация) рис.1.3 образом, в результате применения генетических операторов найдено оптимальное решение ![]() .
.
В данном случае, поскольку пример искусственно подобран, мы нашли оптимальное решение за одну итерацию. В общем случае ГА работает до тех пор, пока не будет выполнен критерий окончания процесса поиска и в последнем полученном поколении определяется лучшая особь, которая и принимается в качестве решения задачи.
1.3. Представление вещественных решений в двоичной форме
В предыдущем примере мы рассматривали только целочисленные решения. Обобщим ГА на случай вещественных чисел на примере функции ![]()
, представленной на рис.1.5 [14]. Рассматривается та же задача: необходимо найти вещественное ![]()
, которое максимизирует ![]() , т.е. такое
, т.е. такое ![]() , для которого
, для которого ![]()
для всех ![]()
.

Рис. 1.5. Пример функции с популяцией особей в начале эволюции
Для решения этой задачи с помощью ГА будем использовать представления вещественного решения (хромосомы) в виде двоичного вектора [15], который применяется в классическом простом ГА. Его длина зависит от требуемой точности решения, которую в данном случае положим, например, равной 3 знакам после запятой.
Поскольку отрезок области решения имеет длину 20, для достижения заданной точности отрезок ![]()
должен быть разбит на равные части (маленькие отрезки), число которых должно быть не менее 20*1000. В качестве двоичного представления используем двоичный код номера (маленького) отрезка. Этот код позволяет определить соответствующее ему вещественное число, если известны границы области решения. Отсюда следует, что двоичный вектор для кодирования вещественного решения должен иметь 15 бит, поскольку
![]()
Отсюда следует, что для обеспечения необходимой точности требуется разбить отрезок [-10,+10] на 32768 частей. Отображение из двоичного представления ![]()
в вещественное число из отрезка ![]()
выполняется в два шага.
- Перевод двоичного числа в десятичное:
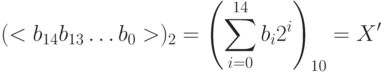
- Вычисление соответствующего вещественного числа
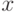 :
:
, где (- 10) левая граница области решения. Естественно хромосомы (000000000000000) и (111111111111111) представляют границы отрезка -10 и +10 соответственно.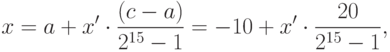
Очевидно, при данном двоичном представлении вещественных чисел можно использовать классический простой ГА. На рис.1.6,рис.1.7,рис.1.8 представлено расположение особей (потенциальных решений) на различных этапах ГА в процессе поиска решения[14]. На рис.1.5 показана начальная популяция потенциальных решений, которая равномерно покрывает область поиска решения. Далее явно видно, как постепенно с увеличением номера поколения особи "конденсируются" в окрестностях экстремумов и, в конечном счете, находится лучшее решение.

Рис. 1.6. Начальная "конденсация" особей популяции в окрестностях экстремумов

Рис. 1.7. "Конденсация" особей в окрестностях экстремумов

Рис. 1.8. Положение особей популяции в конце эволюции
Для сокращения длины хромосом иногда применяют логарифмическое кодирование, при котором первый бит ![]() кодовой последовательности используется для знака показательной функции, второй бит
кодовой последовательности используется для знака показательной функции, второй бит ![]() - для знака степени этой функции, и остальные биты
- для знака степени этой функции, и остальные биты ![]() представляют значение самой степени [16]. Таким образом, двоичный код
представляют значение самой степени [16]. Таким образом, двоичный код ![]()
представляет вещественное число ![]()
. Здесь ![]() означает десятичное число, представленное двоичным кодом
означает десятичное число, представленное двоичным кодом ![]() .
.
Например, двоичный код ![]()
представляет вещественное число ![]()
. Следует отметить, что при таком кодировании пять битов позволяет кодировать вещественные числа из интервала ![]() , что значительно больше, чем это позволяет, например, метод кодирования, представленный ранее.
, что значительно больше, чем это позволяет, например, метод кодирования, представленный ранее.
1.4. Использование кода Грея в ГА
Рассмотренное двоичное представление вещественного числа имеет существенный недостаток: расстояние между вещественными числами (на числовой оси) часто не соответствует расстоянию (по Хеммингу) между их двоичными представлениями. Поэтому желательно получить двоичное представление, где близкие расстояния между хромосомами (двоичными представлениями) соответствовали близким расстояниям в проблемной области (в данном случае расстоянию на числовой оси) [3,14,15]. Это можно сделать, например, с помощью кода Грея. В таблице 1.1 приведен для примера код Грея для 4-х битовых слов.
| Двоичный код | Код Грея |
|---|---|
| 0000 | 0000 |
| 0001 | 0001 |
| 0010 | 0011 |
| 0011 | 0010 |
| 0100 | 0110 |
| 0101 | 0111 |
| 0110 | 0101 |
| 0111 | 0100 |
| 1000 | 1100 |
| 1001 | 1101 |
| 1010 | 1111 |
| 1011 | 1110 |
| 1100 | 1010 |
| 1101 | 1011 |
| 1110 | 1001 |
| 1111 | 1000 |
Заметим, что в коде Грея соседние двоичные слова отличаются на один бит (расстояние по Хеммингу равно 1).
Рассмотрим алгоритмы преобразования двоичного числа ![]()
в код Грея ![]()
и наоборот.

Рис. 1.9. Преобразование в код Грея
Здесь параметр m определяет разрядность двоичного числа. Существует и другая, матричная, процедура преобразования в код Грея. Например, для ![]() матрицы
матрицы
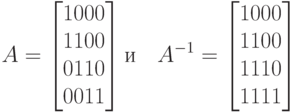
позволяют выполнять следующие преобразования:
![]()
где умножение матриц выполняются в арифметике по mod 2.
Отметим, что применение кода Грея прежде всего оправдано при использовании операторов мутации.
1.5. Фитнесс-функция
Как видно из основной блок-схемы ГА на рис.1.1, каждая особь популяции (потенциальное решение проблемы) оценивается путем вычисления значения фитнесс-функции. Следует отметить, что в общем случае целевая функция (ЦФ) и фитнесс-функция могут различаться. Целевая функция предназначена для оценки характеристик особи относительно конечной цели (например, экстремумов). Фитнесс-функция предназначена, прежде всего, для отбора особей для дальнейшей репродукции и здесь важны характеристики качества одной особи относительно других особей. После декодирования хромосомы, где выполняется преобразование "генотип ![]() фенотип" (например, двоичный код преобразуется в вещественное число), полученное значения далее используется в качестве аргумента для фитнесс-функции. Далее для каждой особи популяции вычисляются значения фитнесс-функции, которые ранжируют эти особи относительно друг друга в смысле перспективности получения из них хорошего решения.
фенотип" (например, двоичный код преобразуется в вещественное число), полученное значения далее используется в качестве аргумента для фитнесс-функции. Далее для каждой особи популяции вычисляются значения фитнесс-функции, которые ранжируют эти особи относительно друг друга в смысле перспективности получения из них хорошего решения.
Определение соответствующей фитнесс-функции является решающим для корректной работы ГА. В частности, вид фитнесс-функции может зависеть от накладываемых ограничений при решении оптимизационных задач. Отметим, что операторы кроссинговера и мутации не учитывают, попадают ли вновь построенные особи-потомки в область допустимых решений, которая обусловлена накладываемыми ограничениями.
В ГА используются четыре основных метода для учета накладываемых ограничений при решении оптимизационных задач. Вероятно, простейшим способом является метод отклонения (отбрасывания), где недопустимые хромосомы (не удовлетворяющие ограничениям) исключаются из дальнейшей эволюции. Второй метод основан на использовании процедуры восстановления, которая преобразует полученное недопустимое решение в допустимое. Другой альтернативой является применение проблемно-ориентированных генетических операторов, которые порождают только допустимые решения.
Рассмотренные методы не строят недопустимых решений. Но это не всегда дает хорошие результаты. Например, в том случае, когда оптимальные решения лежат на границе допустимой области, указанные методы могут давать неоптимальные решения. Одним из возможных вариантов преодоления этой проблемы является выполнение процедуры восстановления только для некоторого подмножества решений (например, 10% особей).
Для решения оптимизационных задач со сложными ограничениями иногда позволяют вести поиск решения и в недопустимых областях. Реализуется это подход часто с помощью метода штрафных функций, что позволяет расширить пространство поиска решений. Следует отметить, что часто недопустимая точка, близкая к оптимальному решению, содержит больше полезной информации, чем допустимая точка, далекая от оптимума. С другой стороны, построение штрафных функций является достаточно сложной проблемой, которая сильно зависит от решаемой задачи. Обычно нет априорной информации о расстоянии до оптимальных точек, есть только расстояние до границы области допустимых решений. Поэтому, как правило, штрафные функции используют расстояние до границ допустимой области. Штрафы, основанные на нарушении отдельных ограничений, работают обычно не очень хорошо.
Разработаны два основных способа построения штрафных функций со штрафным термом: аддитивная и мультипликативная формы. В первой форме функция представляется в виде ![]()
, где при максимизации для допустимых точек ![]() и в противном случае
и в противном случае ![]() . Максимум значения
. Максимум значения ![]() по абсолютной величине не может быть больше, чем минимальное значение
по абсолютной величине не может быть больше, чем минимальное значение ![]() по абсолютной величине для любой генерации, чтобы избежать отрицательных фитнесс-значений. Мультипликативная форма представляет функцию в виде
по абсолютной величине для любой генерации, чтобы избежать отрицательных фитнесс-значений. Мультипликативная форма представляет функцию в виде ![]()
, где при максимизации ![]() для допустимых точек и
для допустимых точек и ![]()
в противном случае.
При этом штрафной терм должен изменяться не только в зависимости от степени нарушения ограничения, но и от номера поколения ГА. Наряду с нарушением ограничения, штрафной терм обычно содержит штрафные коэффициенты (по одному для каждого ограничения). На практике большую роль играют значения этих коэффициентов. Маленькие значения коэффициентов могут привести к недопустимым значениям решения, в то время как большие значения полностью отвергают недопустимые подпространства. В среднем абсолютные значения целевой и штрафной функции должны быть соизмеримы. При таком подходе параметры штрафной функции можно включить в параметры ГА, что позволяет разработать адаптивный метод, где значения коэффициентов регулируются в процессе поиска решения.
В целом на выбор (построение) фитнесс-функции оказывают влияние следующие факторы:
- тип задачи - максимизация или минимизация;
- содержание шумов окружающей среды в фитнесс-функции;
- возможность динамического изменения фитнесс-функции в процессе решения задачи;
- объем допустимых вычислительных ресурсов - допускается ли использовать более точные методы и значительные ресурсы, или возможны только приближенные аппроксимации, не требующие больших ресурсов;
- насколько различные значения для особей должна давать фитнесс-функция для облегчения отбора родительских особей;
- должна ли она содержать ограничения решаемой задачи;
- может ли она совмещать различные подцели (например, для многокритериальных задач).
В ГА фитнесс-функция используется в виде черного ящика: для данной хромосомы она вычисляет значение, определяющее качество данной особи. Внутри она может быть реализована по-разному: в виде математической функции, программы моделирования (в том числе имитационного), нейронной сети, или даже экспертной оценки.
Для некоторых задач оценку значений фитнесс-функции можно выполнять с помощью объектно-ориентированной имитационной модели. Взаимодействие такой модели с ГА показано на рис.1.10.

Рис. 1.10. Схема взаимодействия объектной модели с ГА.
1.6. Теория схем
Теоретические основы ГА составляют двоичное стринговое представление решений (хромосом) и понятие схемы (schema) или шаблона. Это понятие было ведено Холландом для определения множества хромосом, которые обладают некоторыми общими свойствами, то есть в каком- то смысле подобны друг другу.Термин "схема" согласно Холланду [2] есть шаблон, описывающий подмножество стрингов, имеющих одинаковые значения в некоторых позициях. Для этого вводится новый троичный алфавит {0, 1, *}, где * означает неопределенное значение (0 или 1, т.е. неизвестно что именно). Например, схема (0*0001) соответствует двум стрингам {000001, 010001}, а (*0110*) описывает подмножество из 4-х стрингов {001100, 101100, 001101, 101101}. Очевидно, схема с ![]() неопределенными позициями "*" представляет
неопределенными позициями "*" представляет ![]() стрингов. Для стрингов длины
стрингов. Для стрингов длины ![]() , существует
, существует ![]() схем (возможны 3 символа {0, 1, *} в каждой из
схем (возможны 3 символа {0, 1, *} в каждой из ![]() позиций).
позиций).
В простом ГА основная идея заключается в объединении хромосом со значениями целевой функции (ЦФ) выше среднего. Например, пусть 1 в хромосоме соответствует наличию признака, способствующего выживанию (значение целевой функции больше среднего). Допустим, что имеются подстринги вида 11*** и **111. Тогда, применяя к ним ОК можно получить хромосому 11111 с признаками, способствующими наилучшим значениям
Фун
Телеграм: t.me/ainewsline
Источник: www.intuit.ru