Как обучается ИИ
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-07-13 00:52
новости нейронных сетей, искусственный интеллект, реализация нейронной сети

Есть ли связь между трехглазой жабой и нейронными сетями? Что общего у программы, выигрывающей в го, и приложением Prisma, перерисовывающим фотографии под стили картин известных художников? Как компьютеры одолели нарды, а затем покусились на святое - и выиграли у человека в -Космических захватчиков-?
Дадим ответы на все эти вопросы, а еще поговорим о революции, связанной с глубоким обучением, благодаря которому удалось добиться прорыва во многих областях.
Об авторах:
Сергей Николенко, математик, информатик, сотрудник лаборатории математической логики Санкт-Петербургского отделения Математического института РАН, лаборатории интернет-исследований НИУ ВШЭ и Deloitte Analytics Institute, также известный как игрок телеклуба -Что? Где? Когда?-. Сергей занимается исследованиями, практическими разработками и преподаванием в области машинного обучения и обработки данных, сетевых алгоритмов, теоретической информатики и криптографии.
Артур Кадурин, руководитель группы сегментирования аудитории в рекламном департаменте Mail.Ru Group, руководитель студенческой лаборатории проекта Техносфера при ВМК МГУ. Артур занимается анализом данных от различных сервисов Mail.Ru Group, в том числе используя технологии машинного обучения.
Самый интересный объект во вселенной

Во многих областях человеческий мозг до сих пор умеет больше, чем компьютер. Например, мы лучше обращаемся с естественным языком: можем прочитать, понять и содержательно изучить книгу. Да и вообще мы хорошо умеем обучаться в широком смысле этого слова. Что же, собственно, делает человеческий мозг и как он умудряется достичь таких высот? В чём разница между тем, что делают нейроны в мозге, и тем, что делают транзисторы в процессоре? Тема эта, конечно, совершенно неисчерпаема, поэтому давайте мы приведём только пару локальных примеров.
Как известно, каждый нейрон время от времени посылает по аксону электрический импульс, так называемый spike. Пока нейрон жив, он никогда не останавливается и продолжает подавать сигналы. Но когда нейрон находится в -выключенном- состоянии, частота подачи сигналов маленькая, а когда нейрон возбуждается, -включается-, частота спайкового разряда сильно увеличивается.
Нейрон работает стохастически: он выдаёт электрические сигналы через случайные промежутки времени, и последовательность этих сигналов можно очень хорошо приблизить случайным пуассоновским процессом. В компьютерах тоже есть гейты, обменивающиеся сигналом друг с другом, но они как раз делают это совершенно не случайно, а с очень жёсткой синхронизацией; -частота процессора-, давно уже измеряющаяся в гигагерцах, это и есть частота такой синхронизации. Каждый такт гейт одного уровня передает сигнал следующему уровню, и делают они это хоть и несколько миллиардов раз в секунду, но строго одновременно, как по команде.
Однако очень простые наблюдения показывают, что на самом деле нейроны хорошо умеют синхронизироваться и очень точно засекать очень маленькие промежутки времени. В частности, самая простая и яркая иллюстрация - стереозвук. Когда вы идёте с одной стороны комнаты на другую, вы можете, опираясь исключительно на звук от телевизора, легко определить направление к нему (и умение определить, откуда идёт звук, было как раз крайне важно для выживаемости в доисторические времена). Чтобы определить направление, вы отмечаете разницу во времени, с которой звук приходит в левое и правое ухо. Расстояние между внутренними ушами не слишком большое (сантиметров 20), и если разделить его на скорость звука (340 м/c), получится очень короткий интервал в приходе звуковых волн, десятые доли миллисекунды, который, тем не менее, нейроны отлично замечают и позволяют определить направление с хорошей точностью. То есть ваш мозг в принципе мог бы работать как компьютер с частотой, измеряющейся килогерцами; с учётом огромной степени параллелизации, достигнутой в архитектуре мозга, это могло бы привести ко вполне разумной вычислительной мощности- но почему-то мозг этого не делает.
Кстати, о параллелизации. Второе важное замечание про работу мозга: мы распознаём лицо человека за пару сотен миллисекунд. Причем связи между отдельными нейронами активируются за десятки миллисекунд, то есть в полном цикле распознавания не может быть последовательной цепочки вычислений длиннее нескольких штук нейронов - скорее всего, их меньше десятка. Мозг, с одной стороны, содержит огромное количество нейронов, но, с другой стороны, он устроен плоско по сравнению с обычным процессором. У процессора очень длинные последовательные цепочки исполнения, которые он обрабатывает, а в мозге последовательные цепочки короткие, но зато он работает параллельно, потому что нейроны зажигаются сразу во многих местах мозга, когда начинают распознавать лицо и делать много других увлекательных вещей.
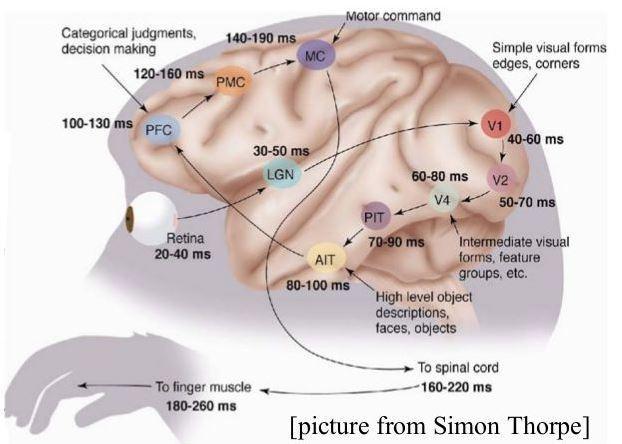
На иллюстрации показано, как во времени происходит процесс обработки зрительного сигнала. Свет попадает на сетчатку, там он преобразуется в электрические импульсы и через 20-40 миллисекунд -изображение- передается дальше. Первый уровень обработки занимает 10-20 миллисекунд (на картинке время показано нарастающим итогом, т.е., например, до выдачи команды моторной системе проходит всего 140-190 мс). На втором уровне обработки, ещё через 20-30 миллисекунд, сигнал приходит на нейроны, которые распознают простые локальные формы. Потом еще один уровень, ещё один уровень, и вот на четвёртом уровне мы уже видим промежуточные формы: можно найти нейроны, которые -зажигаются- при виде квадратов, градиентов цветов или других подобных объектов. Потом ещё пара уровней нейронов, и вот, через 100 миллисекунд от начала процесса, у нас уже зажигаются нейроны, отвечающие высокоуровневым объектам. Например, если вы познакомились с человеком, у вас в мозге появляется нейрон, отвечающий за его лицо (мы не готовы ручаться за это утверждение, но скорее всего именно так); более того, скорее всего появляется и нейрон или группа нейронов, -отвечающая- за этого человека в целом и срабатывающая при любом контакте с ним, в том числе письменном, когда лица не видно. Если вы увидите лицо снова (а нейрон за это время не разобучится обратно, «забыв» прежнюю информацию), то через ~100 миллисекунд в вашей голове активируется тот самый нейрон.
Почему мозг работает именно так? Самым простой и ничего не объясняющий ответ на этот вопрос - -так получилось-. В ходе эволюции мозг сформировался таким образом, и этого оказалось достаточно для решения эволюционных задач. В рационалистском сообществе об этом говорят так: живые существа - не fitness-maximizers, которые оптимизируют некую целевую функцию выживаемости, а adaptation-executers, которые исполняют когда-то случайно выбранные -достаточно удачные- решения. Ну и так получилось, что жёсткой синхронизации со встроенным метрономом так и не сформировалось, а почему именно так - мы ответить не готовы.
На самом деле нам представляется, что вопрос -почему?- здесь действительно не совсем уместен, и лучше, интереснее и продуктивнее задавать вопрос -как?-: как же именно работает мозг? Точно мы не знаем, но на уровне отдельных нейронов, а местами и групп нейронов, происходящие в нашей голове процессы уже сейчас можно описать достаточно хорошо.
Чему ещё надо поучиться у мозга - это извлечению признаков (feature extraction, feature engineering). Мозг отлично умеет обучаться и обобщать на очень-очень ограниченной выборке данных. Если маленькому ребёнку показать стол и сказать, что это стол, то ребёнок быстро начнет другие столы тоже называть столами, хотя они, казалось бы, не имеют ничего общего: один круглый, другой квадратный, один на одной ноге, другой на четырех. Совершенно очевидно, что ребёнок не делает это методом обучения с учителем, у него явно не хватило бы тренировочного множества для этого; можно предположить, что у ребёнка сначала появился в голове некий кластер -объектов на ножках, на которые ставят вещи-, затем мозг извлёк, так сказать, платоновский эйдос стола, а потом уже услышал слово, которым это называется, и просто пометил готовую идею этим словом.
Небольшое лирическое отступление: этот процесс идёт, конечно, и в обратном направлении; хотя при упоминании Уорфа с Сапиром у многих лингвистов начинают нервно подёргиваться не только нейроны, нельзя не признать, что многие идеи, особенно абстрактные, являются во многом социально-культурными конструктами. Например, у любой культуры найдётся слово, похожее по смыслу на -любовь-, но его содержание может быть очень разным, наша -любовь- совсем не похожа на древнеяпонскую. Поскольку физиологическая основа у всех людей, в общем, одинаковая, получается, что возникающая в мозгу абстрактная идея -влечения к другому человеку- не просто маркируется, а активно подправляется и конструируется теми текстами и культурными объектами, которые её для человека определяют. Но мы отвлеклись.
Другая сторона вопроса - нейропластичность. Ученые проводили эксперименты, выясняя, как разные части мозга могут легко обучиться делать вещи, для которых они, казалось бы, не предназначены. Нейроны везде одинаковые, но, в принципе, в мозге есть области, отвечающие за разные вещи. Есть зона Брока, отвечающая за речь, есть зона, отвечающая за зрение, и так далее. Однако мы можем нарушить условные биологические границы.
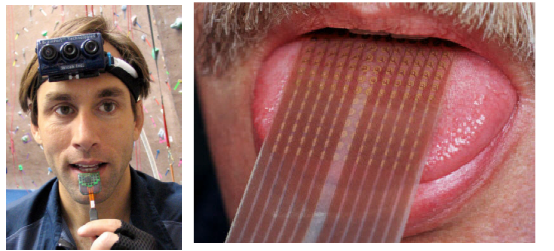
Этот человек обучается видеть языком. Он прикрепляет на язык электроды, вешает на лоб камеру, и камера попиксельно транслирует изображение на электроды, покалывающие язык. Человек цепляет на себя такую штуку, ходит с ней с открытыми глазами несколько дней. Часть мозга, получающая сигналы из языка, начинает соображать: это же очень похоже на то, что приходит из глаз. Если через неделю издевательства глаза завязать, то человек начинает реально видеть языком. Человек распознает формы, не натыкается на стенки.

На этой фотографии человек превращается в летучую мышь. Он ходит с завязанными глазами и пользуется эхолокатором, сигналы с которого поступают через кожу на осязательные нейроны. И тоже через несколько дней человек развивает в себе способности к эхолокации. Специального органа, распознающего ультразвук, у нас нет, нужно прикрепить внешний локатор, но обрабатывать информацию мы учимся без проблем, то есть можем ходить в темноте и не наталкиваться на стены.

А здесь жабе вживили третий глаз. Сначала жаба немножко походила с тремя глазами, потом два других ей закрыли, и она начала отлично пользоваться третьим.
Мозг может адаптироваться к очень большому числу новых источников данных. То есть получается, что у мозга есть некий -единый алгоритм-, которому всё равно, что подают, он из этого извлекает смысл. Этот единый алгоритм - это и есть святой Грааль современного искусственного интеллекта; как нам представляется, глубокое обучение -это самое близкое к нему из того, что было сделано до сих пор.
Однако, конечно, надо быть осторожным в утверждениях о том, действительно ли всё это похоже на то, что делает мозг. Очень яркая недавняя работа -Could a neuroscientist understand a microprocessor?- пытается проследить, насколько бы получилось у методов современной нейробиологии проанализировать какой-нибудь очень простой -мозг- -скажем, простенький процессор из Apple I и Atari, запускающий ту самую игру Space Invaders, к которой мы ещё вернёмся. Подробно сейчас об этом рассказывать не будем, но статью прочитать рекомендуем. Спойлер: ни-че-го у нейробиологии не получилось-
Извлечение признаков
Неструктурированная информация (текст, картинки, музыка) обрабатывается так: есть сырой вход, потом из него получаются признаки, несущие содержательную информацию, а потом на этих признаках строятся классификаторы. Самое сложное в этом процессе - понять, как из неструктурированного входа выделить хорошие признаки. И системы обработки неструктурированной информации до недавнего времени выглядели так: люди старательно пытались вручную придумать хорошие признаки, оценивая то, что у них получается, по качеству построенных на них уже достаточно простых регрессоров и классификаторов.
В качестве примера можно рассмотреть Mel Frequency Cepstral Coefficients (MFCC), или мел-частотные кепстральные коэффициенты, которые часто применяют в качестве характеристики речевых сигналов. В частности, MFCC используют для распознавания речи, а в 2000 г. Европейский институт телекоммуникационных стандартов определил стандартизированный MFCC алгоритм для использования в сотовой связи. До определенного момента собранные руками признаки доминировали в машинном обучений. Так например в обработке изображений повсеместно использовался SIFT (Scale Invariant Feature Transform), который позволяет выделять устойчивые к разного рода преобразованиям признаки картинки и опираясь на них уже проводить поиск дубликатов или классификацию.
В целом, признаков придумано много, но мы всё ещё не можем повторить успехи мозга. В голове человека нет никакого биологического предопределения - нет нейронов, генетически созданных, только для речи, не существует нейронов, «приученных» только к запоминанию лиц, и так далее. Похоже на то, что любая часть мозга может обучиться чему угодно. Да и безотносительно мозга нам очень хотелось бы, конечно, научиться выделять признаки автоматически; чтобы сделать сложные ИИ, большие модели, в которых есть нейроны, связанные друг с другом для передачи сигналов, сочетающих любую информацию, скорее всего человеческих сил для ручной разработки признаков не хватит.
Искусственные нейронные сети

Когда Фрэнк Розенблатт предложил свой линейный перцептрон, все начали представлять, что вот-вот машины станут по-настоящему умными. Для конца 1950-х годов было очень круто, что сеть сама обучалась распознавать буквы на фотографиях. Около того же времени появились нейронные сети из многих перцептронов, которые обучаются алгоритмом backpropagation (это метод градиентного спуска с небольшой модификацией, называемый метод обратного распространения ошибки). Алгоритм backpropagation - это, по сути, способ вычислять градиенты, то есть производные ошибки.
Идеи для автоматического дифференцирования появились еще в 1960-х годах, но переоткрыл backpropagation для широкого использования британский информатик Джеффри Хинтон - один из ключевых исследователей в революции глубокого обучения. К слову, прапрадедом Хинтона был сам Джордж Буль, один из основателей математической логики.
Многоуровневые нейронные сети появились во второй половине 1970-х. Не было никаких технических препятствий: возьмём сеть с одним слоем нейронов, потом добавим скрытый слой нейронов, потом ещё один - вот таким нехитрым образом получается глубокая сеть, и backpropagation на ней, формально говоря, работает точно так же. Дальше эти сети начали применять для распознавания речи и изображений, стали появляться рекуррентные сети, сети с учётом времени и так далее. Но к концу 1980-х годов выяснилось, что с обучением нейронных сетей есть несколько существенных проблем.
В первую очередь стоит сказать о технической проблеме. Для того чтобы нейронная сеть делала что-то разумное, в основе должно быть хорошее железо. В конце восьмидесятых и начале девяностых работы в области распознавания речи нейронными сетями выглядели примерно так: давайте изменим параметр обучения и запустим сеть обучаться на неделю. Потом посмотрим на результат, ещё раз изменим параметры и подождём ещё неделю. Это, конечно, было очень романтическое время, но поскольку в нейронных сетях настройка параметров чуть ли не важнее собственно архитектуры, для хорошего результата на каждой конкретной задаче требовалось слишком много времени или слишком мощное -железо-.
Теперь коснёмся содержательной проблемы: backpropagation формально действительно работает, но лишь формально. Долгое время не удавалось эффективно обучать нейронные сети с более чем двумя скрытыми слоями из-за проблемы исчезающих градиентов (vanishing gradients) - при вычислении градиента (направления наибольшего роста ошибки сети в пространстве весовых коэффициентов) методом обратного распространения он уменьшается по мере прохождения от выходного слоя сети к входному. Обратная проблема - exploding gradients («взрывной рост градиента») - проявляется в рекуррентных сетях. Если начать разворачивать рекуррентную сеть, может так сложиться, что градиент пойдет вразнос и станет экспоненциально расти. Более подробно об этих проблемах написано, например, в статье «Предобучение нейронной сети с использованием ограниченной машины Больцмана».
В конечном счёте эти проблемы привели ко второй «зиме» нейронных сетей, которая продолжалась все 1990-е годы и начало 2000-х; как писал один из классиков нейронных сетей Джон Денкер, -neural networks are the second best way of doing just about anything- (менее известно продолжение этой фразы: -...and genetic algorithms are the third-). Но десять лет назад случилась настоящая революция в машинном обучении. Джеффри Хинтон и его группа изобрели способ правильно обучать глубокие модели. Сначала они это сделали для так называемых deep belief networks, основанных на машинах Больцмана, а потом научились хорошо делать и для классических нейронных сетей.
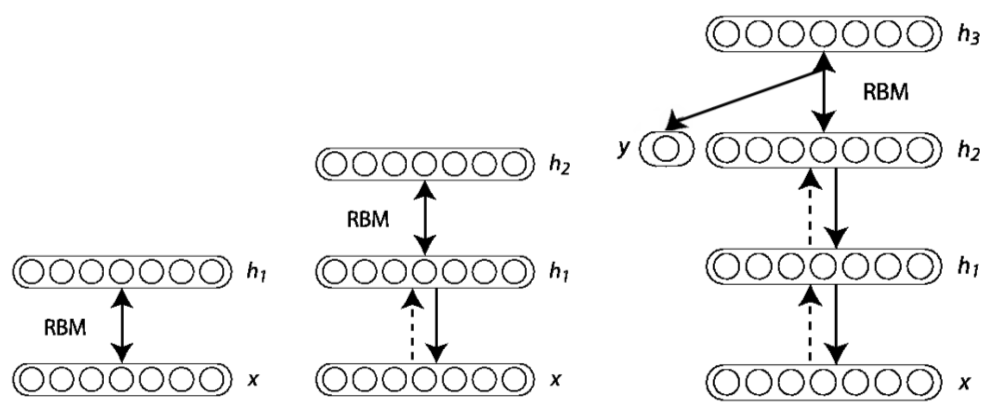
В чем же заключалась идея Хинтона? У нас есть глубокая сеть, которую мы хотим обучить. То, что близко к выходам сети, как мы знаем, хорошо обучается методом обратного распространения ошибки. Как обучать то, что близко ко входу? Сначала на первом уровне запустим обучение без учителя. Выделим какие-нибудь признаки, поищем общее между входами. После того как мы это сделали, попредобучаем второй уровень, затем - третий. А потом, когда мы все уровни предобучили, используем систему как начальное приближение и уже дообучаем с помощью backpropagation нашу конкретную задачу. Это прекрасный метод- и он, конечно, тоже был предложен ещё в семидесятых-восьмидесятых годах. Но, как и обычный backpropagation, это работало плохо; существенные успехи в начале 1990-х были достигнуты в обработке изображений посредством автокодировщиков (группа Яна ЛеКуна), но в целом это всё равно работало не лучше решений, основанных на вручную сконструированных признаках. Заслугой Хинтона (объяснять которую детально здесь было бы слишком долго и сложно) было именно то, что он заставил этот подход работать для глубоких сетей.
С другой стороны, к концу нулевых годов появились достаточные вычислительные мощности для реализации этого метода. Основная техническая революция произошла, когда Руслан Салахутдинов (под руководством того же Хинтона) смог реализовать обучение глубоких сетей на GPU (на видеокартах). Поскольку обучение можно представить как большое число относительно независимых и относительно нетребовательных вычислительных процессов, всё заработало в десятки раз быстрее. На сегодняшний день все серьёзные глубокие модели нужно обучать на видеокартах, а для самих производители видеокарт глубокое обучение стало первоочередным приложением, на которое они оглядываются не меньше, чем на современные игры; посмотрите, например, этот питч от CEO NVIDIA.
Глубокая архитектура

Зачем вообще нужны глубокие нейронные сети с десятками скрытых слоев? Почему нельзя обучать нейронные сети с одним скрытым уровнем? В 1991 году Курт Хорник сформулировал универсальную теорему аппроксимации, которая говорит, что для любой непрерывной функции найдется нейронная сеть с линейным выходом, которая аппроксимирует эту функцию с заданной точностью. То есть нейронная сеть с одним скрытым уровнем может приблизить любую заданную функцию с любой заданной точностью. Но, как это обычно бывает, сеть эта будет экспоненциального размера, да и даже если оставить в стороне эффективность, непонятно, как перейти от того, что такая сеть существует в пространстве возможных сетей, к тому, что мы её обучим в реальности.
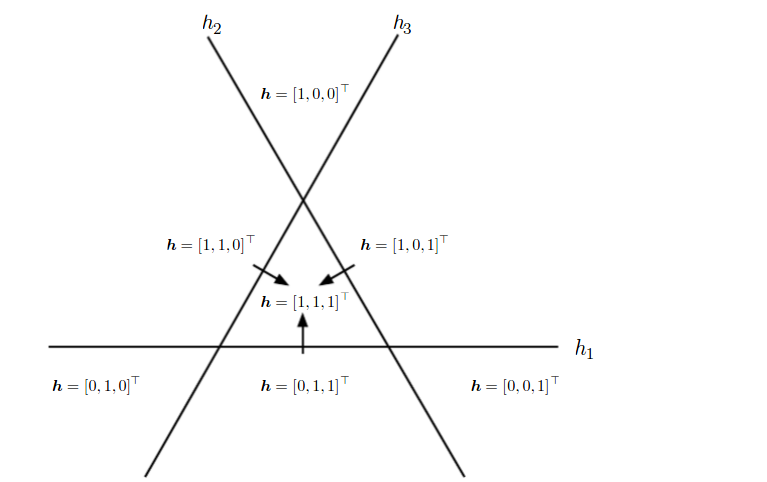
На самом деле, если взять более глубокое представление, то одну и ту же функцию и одну и ту же задачу можно решить более компактно, или можно решить больше задач за то же время. Например, в классической информатике можно смотреть, какие схемы выражают булевы функции, и оказывается, что многие функции можно выразить гораздо эффективнее, если позволить иметь глубину не 2, а 3, для некоторых функций - глубину 4 и так далее. Что-то похожее происходит и в машинном обучении: представьте себе пространство примеров, которые мы хотим, скажем классифицировать на две части. Если у нас есть только условный -один уровень-, мы можем разделить их (гипер)плоскостью. Если есть два уровня - можем позволить себе линейные разделяющие поверхности, склеенные из нескольких гиперплоскостей (примерно поэтому работает бустинг: даже очень простые модели становятся гораздо мощнее, если разрешить их склеивать правильным образом). На третьем уже появляются сложные конструкции из таких разделяющих поверхностей, которые даже визуализировать непросто. И так далее; вот в качестве простейшего примера иллюстрация из книги Goodfellow, Bengio, Courville -Deep Learning-, на которой видно, что если скомбинировать даже простейшие линейные классификаторы, каждый из которых делит плоскость на две полуплоскости, в результате можно описать области гораздо более сложной формы:
Итак, мы пытаемся строить более глубокие архитектуры. Основную идею мы уже описали: мы предобучаем внешние уровни один за другим, а затем дообучаем всю сеть, используя обычный backpropagation. Поэтому, давайте чуть-чуть подробнее остановимся на предобучении.
Одна из самых простых идей - научить нейронную сеть копировать входы в выходы через внутренний слой. Если внутренний слой будет меньшего размера, то кажется, что нейронная сеть должна научиться выделять какие-то существенные признаки из данных, благодаря которым сможет восстановить исходную информацию. Такая архитектура нейронных сетей получила название autoencoder (автокодировщик).
Архитектура автокодировщика - это сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая входной слой, промежуточный слой и выходной слой. В отличие от перцептрона, выходной слой автоэнкодера должен содержать столько же нейронов, сколько и входной слой.
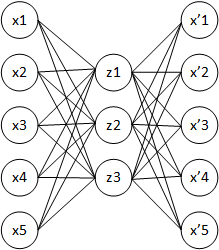
При обучении стремятся получить выходной вектор x', наиболее близкий к входному вектору x
Основной принцип работы и обучения сети автокодировщика - получить на выходном слое отклик, наиболее близкий к входному. Как правило, под автокодировщиками понимаются неглубокие сети (хотя есть и исключения).
Ранние автокодировщики фактически снижали размерность. Если мы возьмём намного меньше скрытых нейронов, чем размерность входа и выхода, то получится, что мы заставляем сеть наилучшим образом сжать полученную информацию в компактное представление, требуя при этом, чтобы потом можно было разжать её обратно. Это то, что делают сжимающие автокодировщики (undercomplete autoencoders) с размерностью скрытого слоя ниже, чем у входа. Но сейчас, как правило, используются так называемые overcomplete autoencoders, когда размерность скрытого уровня больше, иногда гораздо больше, чем размерность входа. С одной стороны, это хорошо, потому что можно выделить больше признаков, с другой - сеть может обучиться просто копировать вход-выход с ошибкой 0. Чтобы такого не случилось, нужно не просто оптимизировать ошибку, а вводить регуляризацию.

Возвращаем точки на многообразие входов в датасете
Обычная регуляризация в том смысле, чтобы делать веса поменьше по модулю при помощи того или иного априорного распределения, как в линейной регрессии, нам не подходит. С автокодировщиками обычно работают более хитрые способы регуляризации, связанные с изменением входов и выходов. Один классический подход - это автокодировщик с шумоподавлением (denoising autoencoder), убирающий шум. Для этого при обучении на входной образ накладывают шум и требуют от сети восстановить исходный образ. В этом случае размер скрытого слоя можно задавать больше, чем размер входного (и, соответственно, выходного) слоёв - сети всё равно будет чем заняться, задача будет сложной в любом случае.
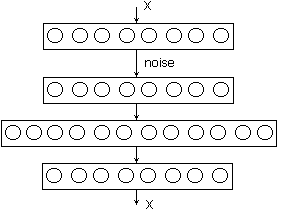
Автокодировщик с шумоподавлением
Под -шумом- здесь, кстати, может понимается довольно радикальное изменение входа. Например, если это бинарная картинка из пикселей, то можно просто убрать часть пикселей, заменив их нулями (часто убирают половину!). Но целевая функция, которую мы реконструируем, - это всё равно правильный X. Получается, что мы заставляем автокодировщик реконструировать часть входа по данной другой части: фактически, автокодировщик должен понять, как устроены все входы вообще, понять структуру того самого многообразия в чертовски многомерном пространстве.
Как проходит глубокое обучение
Предположим, что мы решаем задачу поиска лиц на картинках. Тогда единицей входных данных будет произвольное изображение заданного размера или, по сути, точка в пространстве очень большой размерности. А функция, которую мы пытаемся найти, должна принимать значения 0 или 1 в зависимости от того, есть лицо на картинке или нет. Совершенно очевидно, что среди всех возможных изображений лишь малая часть содержит лица, и расположены эти изображения в нашем многомерном пространстве островками из единиц в океане нулей. Если -прогуляться- от одного лица к другому в пространстве картинок, представленных пикселями, в середине прогулки будут бредовые изображения. Но оказывается, что если предобучить нейронную сеть, например с помощью нескольких слоёв из автокодировщиков, то ближе к выходному слою исходное пространство изображений превращается в пространство признаков, в котором -пики- нашей искомой функции расположены существенно более плотно, и -прогулка- в пространстве признаков уже выглядит куда более осмысленно.

В общем случае, описанный подход действительно приносит дивиденды, однако выделенные признаки часто оказываются не интерпретируемы с точки зрения человека. Более того, многие признаки выделяются совокупностью нейронов, что ещё больше усложняет понимание. Конечно, нельзя категорически утверждать, что это плохо, однако наши современные представления о мозге говорят нам, что в мозге всё происходит не так: у нас практически нет плотных слоёв, что как раз означает, что в решении очередной задачи на каждом уровне участвует только малая часть нейронов, отвечающая за -выделение- соответствующих признаков.
Как же всё-таки сделать так, чтобы каждый нейрон обучался какому-нибудь полезному признаку? И снова мы возвращаемся к регуляризации. В данном случае речь идет о дропауте (dropout; переводов хороших для этого слова мы не знаем, да и бог с ним). Как мы уже упоминали, обучение нейронной сети обычно производят стохастическим градиентным спуском, случайно выбирая по одному объекту из выборки. Дропаут-регуляризация заключается в том, что при выборе очередного объекта изменяется структура сети: каждая вершина выбрасывается из обучения с некоторой вероятностью. Выбросив, скажем, половину нейронов, мы получим -новую- архитектуру сети.
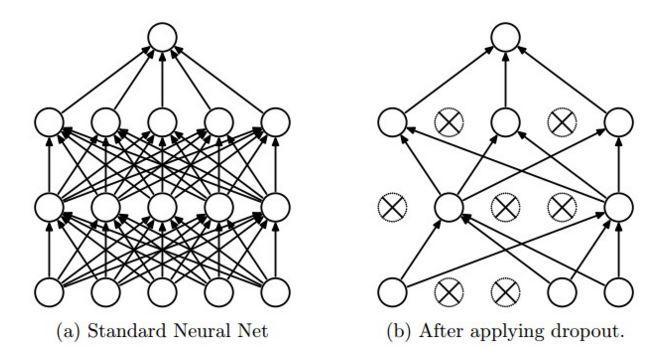
Проведя обучение на оставшейся половине нейронов, мы увидим очень интересный результат. Теперь каждый нейрон должен обучиться выделять какой-нибудь признак сам. Он не может -рассчитывать- на то, что объединится с другими нейронами, потому что те могут быть выключены.
С дропаутом мы словно усредняем гигантскую смесь разных архитектур: получается, что мы на каждом тестовом примере строим новую модель, на каждом тестовом примере берём одну модель из гигантского ансамбля и обучаем на один шаг, затем для следующего примера берём другую модель и обучаем её на один шаг, а потом в конце на выходе усредняем все эти модели. Это очень простая с виду идея; но оказывается, что дропаут дает очень сильный эффект практически на всех глубоких моделях.
И ещё одно небольшое лирическое отступление, которое свяжет то, что происходит сейчас, с тем, с чего мы начинали. Что делает нейрон при дропауте? У него есть своё значение, это обычно число от 0 до 1 или от -1 до 1. И он его посылает, но не всегда, а с вероятностью m. Но что если поменять местами эти числа? Пускай теперь нейроны посылают всегда один и тот же по величине сигнал, а именно m, но с вероятностью, равной своему значению. Средний выход нейрона от этого не изменится, но в результате у нас получатся стохастические нейроны, случайно посылающие сигналы. Интенсивность, с которой они это делают, зависит от их выхода. Чем больше выход, чем более нейрон активирован, тем чаще он будет посылать сигналы. Ничего не напоминает? Мы говорили об этом в самом начале статьи: нейроны в мозге работают именно так. Как и в мозге, нейрон не передает амплитуду спайка, нейроны передают один бит - факт спайка. Вполне возможно, что наши стохастические нейроны в мозге выполняют именно функцию регуляризатора, и, возможно, именно благодаря этому мы так хорошо учимся отличать столы от стульев, котиков и иероглифов.
На сегодняшний день дропаут применяют постоянно. После того как к дропауту добавили еще несколько трюков с обучением, оказалось, что способ unsupervised pre-training не так уж и нужен. Иначе говоря, проблему исчезающих градиентов в наше время можно считать в основном решённой, по крайней мере для обычных нейронных сетей (у рекуррентных всё не так просто).
Сверточные сети
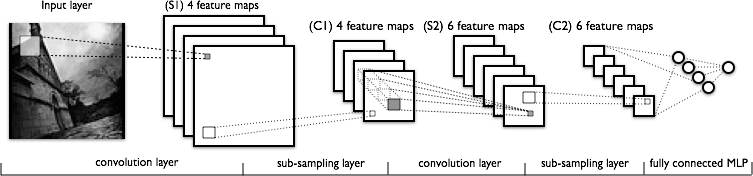
Схема сверточной сети
А теперь поговорим о сверточных сетях. Архитектура сверточной нейронной сети (convolutional neural network, CNN) была представлена в 1998 году французским исследователем Яном ЛеКуном. Сеть названа в честь операции свёртки, которая часто используется для обработки изображений и описывается следующей формулой:
где f - исходная матрица изображения, g - ядро (матрица) свертки.
Предположим, что у нас на входе не дискретный набор независимых размерностей, а изображение, в котором относительное расположение пикселей играет существенную роль. Некоторые пиксели располагаются рядом друг с другом, какие-то, наоборот, далеко друг от друга. В свёрточной нейронной сети один нейрон второго уровня связан не со всеми нейронами первого уровня, а с их частью, расположенной локально. Тогда эти нейроны будут постепенно обучаться распознавать локальные признаки, нейроны второго уровня, устроенные таким же образом, будут реагировать на локальные комбинации локальных признаков первого уровня и так далее. Свёрточная сеть почти всегда состоит из нескольких уровней, и уровне может быть много, до нескольких десятков.
Каждый уровень свёрточной сети в общем случае состоит из трех операций:
- свёртки, которую мы уже описали,
- нелинейности, например сигмоид-функции или гиперболического тангенса,
- пулинга (субдискретизации).
Пулинг, или субдискретизация, - это применение простой математической функции (mean, max, min...) к локальной группе нейронов. В большинстве случаев считается, что для нейронов более высоких уровней важнее проверить, есть ли тот или иной признак в данной области, чем запомнить точно его координаты; обычно на этом этапе просто берут максимум значения активации признака по локальной группе (max-pooling). Кроме прочего, такой подход позволяет сделать свёрточную сеть устойчивой к небольшим изменениям.
Огромное количество соверменных приложений работает на основе сверточных сетей. Например, приложение Prisma, о котором вы все уже наслышаны (и которое теперь тоже имеет прямое отношение к Mail.Ru Group), также работает на основе свёрточных нейронных сетей. Распознавание объектов на изображении с помощью свёрточных сетей используется практически во всех современных приложениях компьютерного зрения. Например, основанные на свёрточных сетях решения для scene labeling - задача, в которой изображение с камеры автоматически разделяется на зоны, которые затем классифицируют как изображения известных системе объектов, позволяют реализовать системы помощи водителям в автомобиле. Впрочем, можно обойтись и без водителя, - именно такие методы сейчас используются в создании самоуправляемых машин.

Ну и, конечно же, свёрточные сети используются в AlphaGo, о которой мы писали в прошлый раз.
Обучение с подкреплением
Обычно задачи машинного обучения делятся на два вида: supervised learning - это когда даны правильные ответы и по ним надо обучиться, unsupervised learning - когда даны вопросы, а ответы нет. В реальной жизни всё не так. Как обучается ребёнок? Когда он подходит к столу и ударяется о него головой, в мозг поступает сигнал, что стол - это боль. В следующий раз (ну, или через один) ребёнок головой об стол не стукнется. Иначе говоря, происходит активное исследование окружающей среды, в котором заранее правильного ответа не дано: в мозге нет никакого априорного знания о том, что стол - это боль. Кроме того ребёнок не будет ассоциировать непосредственно стол с болью (чтобы это произошло, нужен обычно специальный внешний инжиниринг нейронных связей, примерно как в -Заводном апельсине-), скорее конкретное действие по отношению к столу, а со временем перенесёт это знание на более общий класс предметов, например, на большие твёрдые предметы с углами.
Ставить эксперименты, получать результаты и на этом обучаться - это и есть обучение с подкреплением. Агент взаимодействует с окружающей средой, совершает действия, окружающая среда его поощряет за эти действия, агент продолжает их совершать. Иначе говоря, целевая функция представлена в виде награды, и на каждом шаге агент, находясь в каком-то состоянии S, выбирает из имеющегося набора действий какое-то действие А, а затем окружающая среда сообщает агенту, какую награду он получил и в каком новом состоянии S- оказался.
Одна из проблем обучения с подкреплением заключается в том, чтобы случайно не переобучиться совершать в похожих состояниях одно и то же действие. Иногда мы можем ошибочно связать реакцию окружающей среды с нашим непосредственно предшествовавшим этой реакции действием; это известный -баг- в программе нашего мозга, который старательно ищет паттерны даже там, где их нет и быть не может. Знаменитый американский психолог Беррес Скиннер (один из отцов бихевиоризма; именно он изобрёл знаменитый Skinner box для издевательств над мышами) поставил такой эксперимент над голубями: он сажал голубя в клетку и через равные (!), ни от чего не зависящие интервалы времени насыпал в клетку корм. В конце концов голубь решал, что получение корма как-то зависит от его действий. Например, если непосредственно перед кормлением голубь махал крыльями, то в дальнейшем он пытался добыть себе еду именно таким способом - помахав крыльями. Такой эффект впоследствии получил название -голубиное суеверие-; подобный механизм, вероятно, приводит и к человеческим суевериям.
Вышеописанная проблема - это так называемая дилемма exploitation vs exploration, то есть, с одной стороны, надо исследовать новые возможности, изучать окружающую среду так, чтобы в ней что-то интересное найти. С другой стороны, в какой-то момент можно решить: «Я уже исследовал, и я уже понимаю, что стол - это больно, а конфетка - это вкусно, и я могу продолжать идти и получать конфетку, а не пытаться принюхиваться к тому, что лежит на столе, в надежде, что оно еще вкуснее».
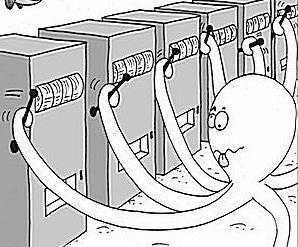
Есть очень простой, но от этого не менее важный пример задачи обучения с подкреплением - многорукие бандиты (multiarmed bandits). Смысл метафоры в том, что агент -сидит- в комнате, в которой находится несколько игровых автоматов. Агент может кинуть монетку в автомат, дёрнуть за ручку, и в результате автомат выдаст ему какой-то выигрыш. У каждого автомата есть своё собственное математическое ожидание выигрыша, и оптимальная стратегия очень проста: достаточно всё время дёргать за ручку автомата с наибольшим ожиданием. Проблема только в том, что агент не знает, у какого автомата какое ожидание, и его задача состоит в том, чтобы за ограниченное количество попыток выбрать лучший автомат. Или хотя бы -достаточно хороший- - понятно, что если несколько автоматов имеют очень близкие ожидания выигрыша, то их трудно и, вероятно, не нужно будет различать. В этой задаче состояние среды всегда одно и то же: хотя в некоторых жизненных приложениях вероятность получить выигрыш от конкретного автомата может меняться со временем, в нашей постановке этого не происходит и всё сводится только к тому, чтобы найти оптимальную стратегию выбора очередной ручки.
Очевидно, что нельзя всегда дёргать наиболее выгодную в среднем ручку, так как если нам случайно повезет на высокодисперсионном, но в среднем совершенно невыгодном автомате в самом начале, мы после этого долго с него не слезем. В то же время самый выгодный автомат может и не выдать большого выигрыша в первые же несколько попыток, и тогда вернуться к нему мы сможем только ещё очень и очень не скоро.
Хорошие стратегии для многоруких бандитов строятся на разных реализациях принципа оптимизма при неопределённости. Это значит, что если в наших знаниях об автомате осталась достаточно большая неопределённость, мы будем трактовать её в свою пользу и исследовать дальше, всегда оставляя себе право, пусть и с небольшой вероятностью, перепроверить свои знания относительно ручек, показавшихся нам невыгодными.
В качестве целевой функции в этой задаче часто выступает цена обучения (regret). Это то, насколько ожидаемый доход от вашего алгоритма меньше, чем ожидание выигрыша у оптимальной стратегии, когда алгоритм просто сразу же божественным вмешательством понял, какая ручка у «бандита» правильная. Оказывается, для некоторых очень простых стратегий можно доказать, что они оптимизируют цену обучения среди всех стратегий вообще (с точностью до константных множителей). Одна из таких стратегий называется UCB-1 (Upper Confidence Bound), и выглядит она так:
Дернуть за ручку j, для которой максимальна величина
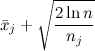 ,
,где
Проще говоря, мы всегда дёргаем за ручку с наивысшим приоритетом, где приоритет - это средний доход от этой ручки плюс дополнительный член, который с одной стороны растёт со временем игры, чтобы периодически возвращаться к каждой ручке и проверять, не пропустили ли мы что-нибудь у неё, а с другой стороны, убывает каждый раз, когда мы эту ручку дёрнули.
Несмотря на то, что задача о многоруких бандитах в базовом варианте не подразумевает перехода между состояниями, именно из UCB-1 происходят алгоритмы, используемые для поиска в дереве ходов игры го, с помощью которого AlphaGo одержала историческую победу.
А теперь давайте вернёмся к обучению с подкреплением с несколькими состояниями. Есть агент, есть среда, и среда даёт агенту вознаграждение на каждом шаге. Агент хочет получать, как мышка в лабиринте, сыра побольше, а разрядов тока поменьше. В отличие от задачи о многоруких бандитах, ожидаемый -выигрыш- теперь зависит не только от текущего выбранного действия, но и от текущего состояния среды, то есть, с точки зрения агента, от истории совершённых им действий. Вообще, в среде с несколькими состояниями оказывается, что стратегия, приносящая максимальную прибыль -здесь и сейчас-, не всегда будет оптимальной, так как может приводить в менее выгодные состояния среды в будущем. Таким образом, мы приходим к максимизации суммарной прибыли за всё время вместо поиска оптимального действия в текущем состоянии (точнее, оптимальное-то действие мы всё равно, конечно, ищем, но оптимальность теперь будет определена по-другому).
С точки зрения суммарной прибыли мы можем оценить и каждое состояние среды. Введем понятие функции ценности состояния (value function) как прогноза общего вознаграждения после посещения состояния. Задаваться функция ценности состояния может, например, так:
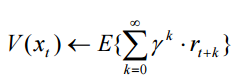 ,
,где rt - непосредственная награда, полученная при переходе системы из состояния хt в состояние хt+1, а c - дисконт-фактор (0 - c - 1).
Другой вариант функции ценности - это Q-функция, аргументом которой является не только состояние, но и действие. Это то же самое, что и функция ценности состояния, но с более высоким -уровнем детализации-: функция Q оценивает ожидаемый выигрыш при условии, что в текущем состоянии агент сделает данное действие.
Суть алгоритмов обучения с подкреплением часто состоит в том, чтобы агент на основе получаемого от среды вознаграждения сформировал для себя функцию полезности Q, что впоследствии даст ему возможность уже не случайно выбирать стратегию поведения, а учитывать опыт предыдущего взаимодействия со средой.
Deep Q-Network
В 2013 году Мних с соавторами опубликовали статью, в которой один из стандартных для обучения с подкреплением методов применяется в сочетании с глубокими нейронными сетями для игры в консольные игры Atari.
TD-обучение (temporal difference learning, TD-learning) обычно применяется в контекстах, где награда представляет собой результат достаточно длинной последовательности действий, и проблема состоит ещё и в том, чтобы распределить конфетку по приведшим к ней ходам и/или состояниям среды. Например, та же игра го может продолжаться несколько сотен ходов, но -конфетку- за выигрыш или -удар током- за проигрыш модель получит только в самом-самом конце, когда станет известен результат; какие ходы из вашей сотни были хорошими, а какие плохими - большой вопрос, даже когда результат известен. Вполне возможно, что в середине партии вы стояли на проигрыш, но так получилось, что противник ошибся, и вы выиграли. И нет, пытаться искусственно вводить -промежуточные цели- вроде -выигрыша материала- - это плохая идея, практика показывает, что соперник легко сможет воспользоваться неизбежными дефектами такой системы.
Основная идея TD-обучения заключается в том, чтобы переиспользовать уже обученные оценки -поздних- состояний, близких к -конфетке-, в качестве целей для обучения предыдущих состояний. Мы начинаем со случайных (вполне бредовых) оценок состояния в игре, но потом после каждой проведённой партии происходит такой процесс: результат в финальной позиции известен твёрдо; скажем, мы выиграли, и результат равен +1 (ура!). Мы подтягиваем оценку предпоследней позиции к единичке, предпредпоследней - к этой предпоследней, которая была подтянута к единичке, и так далее. Если достаточно долго обучаться, в конце концов мы получим хорошие оценки для каждого состояния.
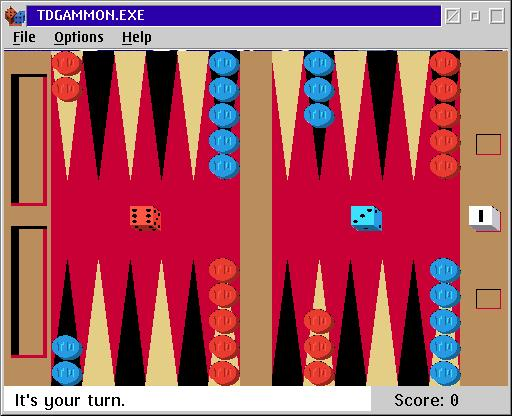
Первый большой успех этого метода в играх был достигнут в программе для игры в нарды TD-Gammon. Нарды оказались для компьютера достаточно простой игрой, потому что в них есть кубики. Так как кубики ложатся по-разному, нет большой проблемы с тем, откуда взять обучающие партии или разумного противника, который позволит исследовать всё пространство возможных партий: можно просто отправить программу играть против самой себя, и встроенная в нарды случайность позволит исследовать достаточно широко и много.
TD-Gammon был разработан около 30 лет назад; однако уже тогда основу программы составляла именно нейронная сеть. На вход сети подавалась позиция из игры, и сеть предсказывала оценку этой позиции, то есть вероятность победы. После каждой партии программы против самой себя получался набор тестовых примеров, новых для сети, сеть дообучалась на них и продолжала играть против самой себя (или чуть более ранних версий самой себя).
TD-Gammon обыграл всех людей ещё в конце восьмидесятых, но считалось, что это обусловлено специфичностью игры в нарды из-за наличия кубиков. Однако оказалось, что глубокое обучение помогает компьютерам выигрывать во множество других игр. Так, например, недавно произошло с уже упомянутыми играми Atari. Отличие эксперимента от нард или даже шахмат заключалось в том, что в консольной игре никто заранее не объяснял модели правила. Все что было известно компьютеру - это изображение, такое же, каким его бы видел человек, и набранные очки (это приходится задавать явно, иначе было бы непонятно, чем выиграть лучше, чем проиграть). Компьютер же мог в свою очередь совершать одно из доступных на джойстике действий - поворот самого джойстика и/или нажатие кнопки.
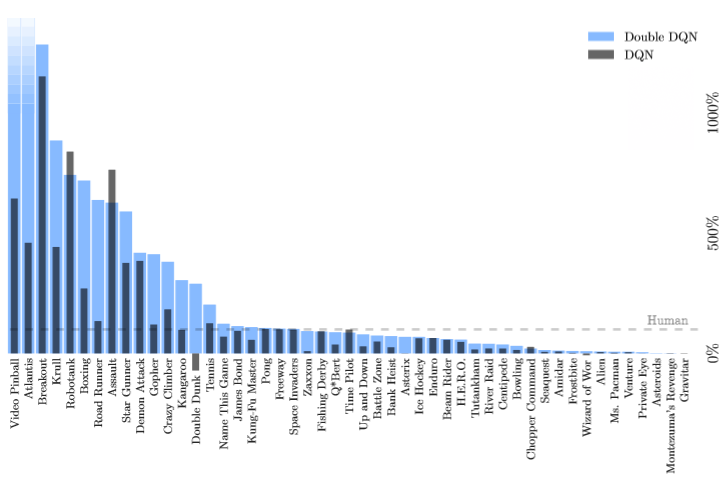
Около 200 попыток у машины ушло на то, чтобы -разобраться- в сути игры, ещё 400 - чтобы получить навык, и вот на 600-м забеге компьютер выигрывает.
Здесь тоже используется Q-обучение, мы точно так же пытаемся построить модель, которая приближает функцию Q, но в качестве этой модели теперь рассматривается глубокая сверточная сеть. И оказалось, что это прекрасно работает. В 29 играх, включая такие хиты, как Space Invaders, Pong, Boxing и Breakout, система вообще оказалась лучше человека. Сейчас команда из DeepMind, ответственная за эту разработку, занимается играми из 1990-х (первым проектом, возможно, станет Doom). Нет никаких сомнений в том, что они справятся в самое ближайшее время и пойдут дальше - к современности.
Еще один интересный пример применения модели Deep Q-Network - это решение задачи перефразирования. Вам даётся предложение, а вы хотите написать его по-другому, но при этом передать тот же смысл. Немножко искусственная задача, но она очень тесно связана вообще с задачей создания текста. В недавно предложенном для этого подходе берётся цепочка LSTM-RNN (Long Short-Term Memory Recurent Neural Network, разновидность рекуррентной нейронной сети), которая называется кодировщиком (encoder), и с её помощью текст сворачивается в компактное представление в виде вектора. Затем компактное представление разворачивается в предложение с другой стороны аналогичной цепочкой - декодером. Поскольку оно декодируется из свёрнутого представления, то, скорее всего, предложение будет другое. Называется этот процесс encoder-decoder architecture. Похожим образом работает машинный перевод: мы сворачиваем текст на одном языке, а потом разворачиваем примерно такими же моделями на другом языке, предполагая, что внутреннее скрытое представление в семантическом пространстве общее. Так вот, оказалось, что Deep Q-Network может итеративно генерировать разные предложения из скрытого представления и разные варианты декодирования, чтобы со временем больше приблизить его к исходному предложению. Поведение модели получается весьма разумным: в экспериментах DQN сначала фиксирует части, которые мы уже хорошо перефразировали, а затем переходит к сложным частям, на которых полученное качество пока ещё так себе; иными словами, DQN подставляется на место декодера в этой архитектуре.
Что же дальше?

Современные нейронные сети становятся -умнее- день от дня. Революция глубокого обучения произошла в 2005-2006 году, и с тех пор интерес к этой теме только растёт, каждый месяц и чуть ли не каждую неделю выходят новые работы и появляются новые интересные применения глубоких сетей. В последнее время мы стали свидетелями огромного успеха приложений Prisma и Mlvch, вынудивших писать о нейронных сетях даже не специализирующиеся на технологиях издания. В этой, надеемся, достаточно популярной статье мы попытались объяснить, каково место революции глубокого обучения последних десяти лет в общей истории и структуре развития нейронных сетей, что, собственно, было сделано, и чуть подробнее остановились на обучении с подкреплением и тем, как глубокие сети могут научиться взаимодействовать со средой.
Практика показывает, что сейчас, на этапе взрывного роста глубокого обучения, вполне возможно создать что-то новое, увлекательное и решающее реальные задачи людей буквально -на коленке-, нужна только современная видеокарта (это, пожалуй, да), энтузиазм и желание пробовать. Как знать, возможно, именно вы оставите след в истории этой всё продолжающейся -революции- - во всяком случае, попробовать стоит.
Источник: geektimes.ru