Пару слов о распознавании образов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-03-30 20:04

Давно хотел написать общую статью, содержащую в себе самые основы Image Recognition, некий гайд по базовым методам, рассказывающий, когда их применять, какие задачи они решают, что возможно сделать вечером на коленке, а о чём лучше и не думать, не имея команды человек в 20.
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ - много времени, которого часто нет, становится всё ещё печальнее.
Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке.
Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:
Очень сложно давать какой-то универсальный совет, или рассказать как создать какую-то структуру, вокруг которой можно строить решение произвольных задач компьютерного зрения. Цель этой статьи в структуризации того, что можно использовать. Я попробую разбить существующие методы на три группы. Первая группа это предварительная фильтрация и подготовка изображения. Вторая группа это логическая обработка результатов фильтрации. Третья группа это алгоритмы принятия решений на основе логической обработки. Границы между группами очень условные. Для решения задачи далеко не всегда нужно применять методы из всех групп, бывает достаточно двух, а иногда даже одного.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.
Самое просто преобразование - это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:


Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды. А можно выбрать наибольший пик гистограммы.
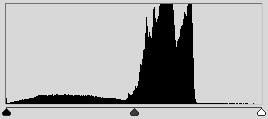
Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.


Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее - БПФ ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, - компрессия изображений. Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование.
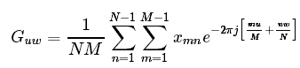
Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.
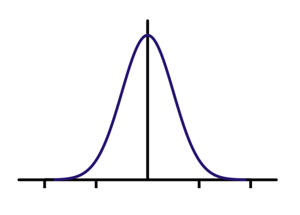
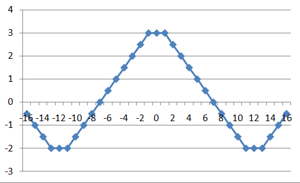
Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора).
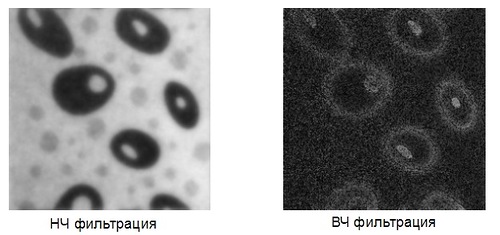
Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:

Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара, вейвлет Морле, вейвлет мексиканская шляпа, и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей (1, 2), относятся к таким функциям для двумерного пространства.

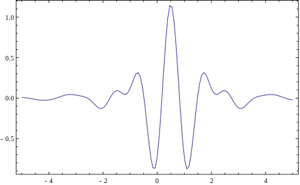
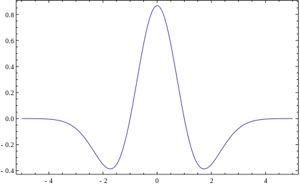
Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:
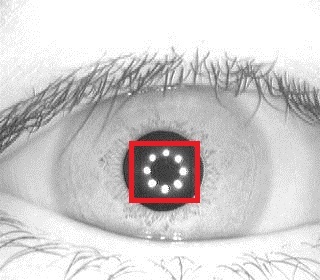
Классические вейвлеты обычно используются для сжатия изображений, или для их классификации (будет описано ниже).
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение - корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига - тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют - было движение.



Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки:

(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено)
Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности. Есть модифицированное преобразование, которое позволяет искать любые фигуры. Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.
Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
Отдельный класс фильтров - фильтрация границ и контуров . Контуры очень полезны, когда мы хотим перейти от работы с изображением к работе с объектами на этом изображении. Когда объект достаточно сложный, но хорошо выделяемый, то зачастую единственным способом работы с ним является выделение его контуров. Существует целый ряд алгоритмов, решающих задачу фильтрации контуров:
Чаще всего используется именно Кэнни, который хорошо работает и реализация которого есть в OpenCV (Собель там тоже есть, но он хуже ищёт контуры).


Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например активная модель внешнего вида), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры:
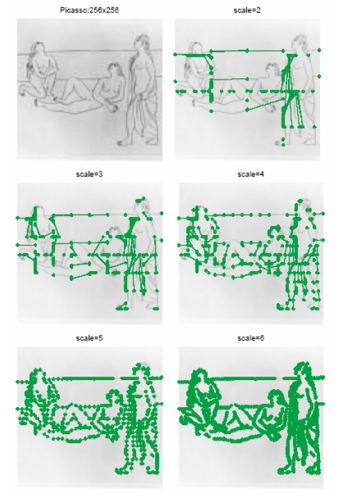
Но эти преобразования весьма специфичны и заточены под редкие задачи.
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.
Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии (1, 2 , 3). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.

В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука.
Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом (1, 2 ).

Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях - то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:
Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.
Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица - это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).
Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это SURF и SIFT. Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр курс по этой тематике, там очень хорошая подборка. Вот тут оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов.
В 80% ситуаций суть обучения в задаче распознавания в следующем:
Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении.
Как это делается? Каждое из тестовых изображений - это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д- Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка [1;1;1;1;..]. Для обезьяны точка [1;0;1;0...] для лошади [1;0;0;0...]. Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5<x<1, второй 0.7<y<1, и.т.д., тогда это человек.
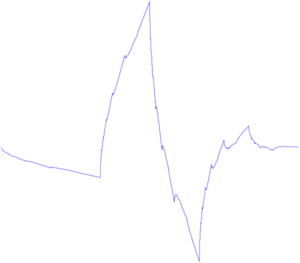
По существу цель классификатора - отрисовать в пространстве признаков области, характеристические для объектов классификации. Вот так будет выглядеть последовательное приближение к ответу для одного из классификаторов (AdaBoost) в двумерном пространстве:

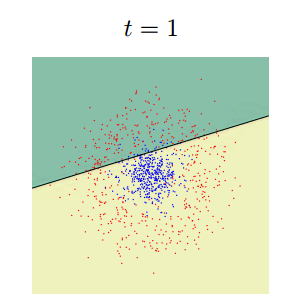
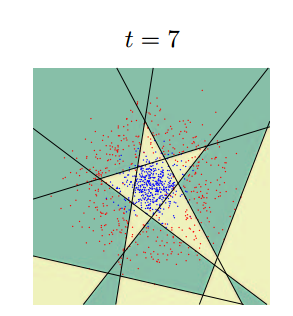
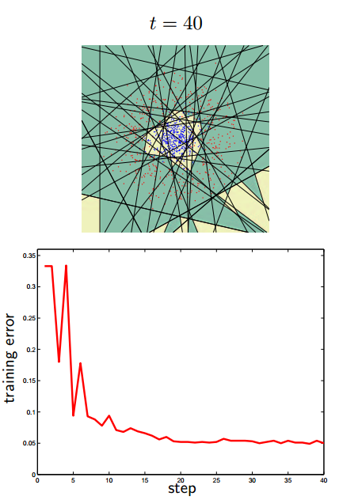
Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот тут немножко красивых картинок на тему.
Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя - получается левая гауссиана. Когда не похож - правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.

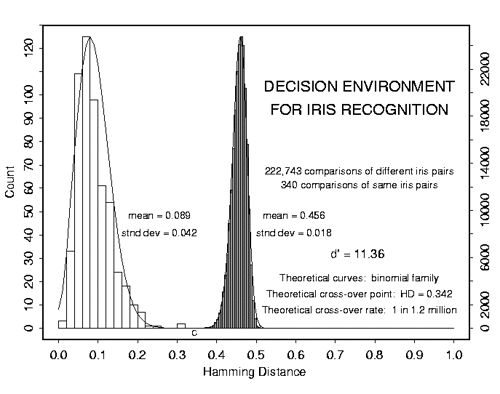
Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график - это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
Алгоритмов много. Даже очень много. Если хотите подробно узнать про каждый из них читайте курс Воронцова, ссылка на который дана выше, и смотрите лекции Яндыкса. Сказать, какой из алгоритмов лучше для какой задачи часто заранее невозможно. Тут я попробую выделить основные, которые в 90% помогут новичку с первой задачей и реализацию которых на вашем языке программирования вы достоверно найдёте в интернете.
k-means (1, 2, 3 ) - один из самых простых алгоритмов обучения. Конечно, он в основном для кластеризации, но и обучить через него тоже можно. Работает в ситуации, когда группы объектов имеют неплохо разнесённый центр масс и не имеют большого пересечения.
AdaBoost (1, 2, 3) АдаБуста - один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов.
SVM (1, 2, 3, 4 ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.
Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта.
________________________________________________
Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе.
Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
Что почитать?
1) Когда-то мне очень понравилась книга «Цифровая обработка изображений» Б. Яне, которая написана просто и понятно, но в то же время приведена почти вся математика. Хороша для того, чтобы ознакомиться с существующими методами.
2) Классикой жанра является Р Гонсалес, Р. Вудс " Цифровая обработка изображений ". Почему-то она мне далась сложнее, чем первая. Сильно меньше математики, зато больше методов и картинок.
3) «Обработка и анализ изображений в задачах машинного зрения» - написана на базе курса, читаемого на одной из кафедр ФизТеха. Очень много методов и их подробного описания. Но на мой взгляд в книге есть два больших минуса: книга сильно ориентирована на пакет софта, который к ней прилагается, в книге слишком часто описание простого метода превращается в математические дебри, из которых сложно вынести структурную схему метода. Зато авторы сделали удобный сайт, где представлено почти всё содержание - wiki.technicalvision.ru
4) Почему-то мне кажется, что хорошая книжка, которая структурирует и увязывает картину мира, возникающую при занятии Image Recognition и Machine Learning - это «Об интеллекте» Джеффа Хокинса. Прямых методов там нет, но есть много мыслей на подумать, откуда прямые методы обработки изображений происходят. Когда вчитываешься, понимаешь, что методы работы человеческого мозга ты уже видел, но в задачах обработки видео.
Какие-то статьи по Optical Recognition я пишу давненько, так что пару раз в месяц мне пишут различные люди с вопросами по этой тематике. Иногда создаётся ощущение, что живёшь с ними в разных мирах. С одной стороны понимаешь, что человек скорее всего профессионал в смежной теме, но в методах оптического распознавания знает очень мало. И самое обидное, что он пытается применить метод из близрасположенной области знаний, который логичен, но в Image Recognition полностью не работает, но не понимает этого и сильно обижается, если ему начать рассказывать что-нибудь с самых основ. А учитывая, что рассказывать с основ - много времени, которого часто нет, становится всё ещё печальнее.
Эта статья задумана для того, чтобы человек, который никогда не занимался методами распознавания изображений, смог в течении 10-15 минут создать у себя в голове некую базовую картину мира, соответствующую тематике, и понять в какую сторону ему копать. Многие методы, которые тут описаны, применимы к радиолокации и аудио-обработке.
Начну с пары принципов, которые мы всегда начинаем рассказывать потенциальному заказчику, или человеку, который хочет начать заниматься Optical Recognition:
- При решении задачи всегда идти от простейшего. Гораздо проще повесить на персону метку оранжевого цвета, чем следить за человеком, выделяя его каскадами. Гораздо проще взять камеру с большим разрешением, чем разрабатывать сверхразрешающий алгоритм.
- Строгая постановка задачи в методах оптического распознавания на порядки важнее, чем в задачах системного программирования: одно лишнее слово в ТЗ может добавить 50% работы.
- В задачах распознавания нет универсальных решений. Нельзя сделать алгоритм, который будет просто «распознавать любую надпись». Табличка на улице и лист текста - это принципиально разные объекты. Наверное, можно сделать общий алгоритм(вот хороший пример от гугла), но это будет требовать огромного труда большой команды и состоять из десятков различных подпрограмм.
- OpenCV - это библия, в которой есть множество методов, и с помощью которой можно решить 50% от объёма почти любой задачи, но OpenCV - это лишь малая часть того, что в реальности можно сделать. В одном исследовании в выводах было написано: «Задача не решается методами OpenCV, следовательно, она неразрешима». Старайтесь избегать такого, не лениться и трезво оценивать текущую задачу каждый раз с нуля, не используя OpenCV-шаблоны.
Очень сложно давать какой-то универсальный совет, или рассказать как создать какую-то структуру, вокруг которой можно строить решение произвольных задач компьютерного зрения. Цель этой статьи в структуризации того, что можно использовать. Я попробую разбить существующие методы на три группы. Первая группа это предварительная фильтрация и подготовка изображения. Вторая группа это логическая обработка результатов фильтрации. Третья группа это алгоритмы принятия решений на основе логической обработки. Границы между группами очень условные. Для решения задачи далеко не всегда нужно применять методы из всех групп, бывает достаточно двух, а иногда даже одного.
Список приведённых тут методов не полон. Предлагаю в комментариях добавлять критические методы, которые я не написал и приписывать каждому по 2-3 сопроводительных слова.
Часть 1. Фильтрация
В эту группу я поместил методы, которые позволяют выделить на изображениях интересующие области, без их анализа. Большая часть этих методов применяет какое-то единое преобразование ко всем точкам изображения. На уровне фильтрации анализ изображения не производится, но точки, которые проходят фильтрацию, можно рассматривать как области с особыми характеристиками.
Бинаризация по порогу, выбор области гистограммы
Самое просто преобразование - это бинаризация изображения по порогу. Для RGB изображения и изображения в градациях серого порогом является значение цвета. Встречаются идеальные задачи, в которых такого преобразования достаточно. Предположим, нужно автоматически выделить предметы на белом листе бумаги:
Выбор порога, по которому происходит бинаризация, во многом определяет процесс самой бинаризации. В данном случае, изображение было бинаризовано по среднему цвету. Обычно бинаризация осуществляется с помощью алгоритма, который адаптивно выбирает порог. Таким алгоритмом может быть выбор матожидания или моды. А можно выбрать наибольший пик гистограммы.
Бинаризация может дать очень интересные результаты при работе с гистограммами, в том числе в ситуации, если мы рассматриваем изображение не в RGB, а в HSV . Например, сегментировать интересующие цвета. На этом принципе можно построить как детектор метки так и детектор кожи человека.
Классическая фильтрация: Фурье, ФНЧ, ФВЧ
Классические методы фильтрации из радиолокации и обработки сигналов можно с успехом применять во множестве задач Pattern Recognition. Традиционным методом в радиолокации, который почти не используется в изображениях в чистом виде, является преобразование Фурье (конкретнее - БПФ ). Одно из немногих исключение, при которых используется одномерное преобразование Фурье, - компрессия изображений. Для анализа изображений одномерного преобразования обычно не хватает, нужно использовать куда более ресурсоёмкое двумерное преобразование.
Мало кто его в действительности рассчитывает, обычно, куда быстрее и проще использовать свёртку интересующей области с уже готовым фильтром, заточенным на высокие (ФВЧ) или низкие(ФНЧ) частоты. Такой метод, конечно, не позволяет сделать анализ спектра, но в конкретной задаче видеообработки обычно нужен не анализ, а результат.
Самые простые примеры фильтров, реализующих подчёркивание низких частот (фильтр Гаусса) и высоких частот (Фильтр Габора).
Для каждой точки изображения выбирается окно и перемножается с фильтром того же размера. Результатом такой свёртки является новое значение точки. При реализации ФНЧ и ФВЧ получаются изображения такого типа:
Вейвлеты
Но что если использовать для свёртки с сигналом некую произвольную характеристическую функцию? Тогда это будет называться "Вейвлет-преобразование". Это определение вейвлетов не является корректным, но традиционно сложилось, что во многих командах вейвлет-анализом называется поиск произвольного паттерна на изображении при помощи свёртки с моделью этого паттерна. Существует набор классических функций, используемых в вейвлет-анализе. К ним относятся вейвлет Хаара, вейвлет Морле, вейвлет мексиканская шляпа, и.т.д. Примитивы Хаара, про которые было несколько моих прошлых статей (1, 2), относятся к таким функциям для двумерного пространства.
Выше приведено 4 примера классических вейвлетов. 3х-мерный вейвлет Хаара, 2х-мерные вейвлет Мейера, вейвлет Мексиканская Шляпа, вейвлет Добеши. Хорошим примером использования расширеной трактовки вейвлетов является задачка поиска блика в глазу, для которой вейвлетом является сам блик:
Классические вейвлеты обычно используются для сжатия изображений, или для их классификации (будет описано ниже).
Корреляция
После такой вольной трактовки вейвлетов с моей стороны стоит упомянуть собственно корреляцию, лежащую в их основе. При фильтрации изображений это незаменимый инструмент. Классическое применение - корреляция видеопотока для нахождения сдвигов или оптических потоков. Простейший детектор сдвига - тоже в каком-то смысле разностный коррелятор. Там где изображения не коррелируют - было движение.
Фильтрации функций
Интересным классом фильтров является фильтрация функций. Это чисто математические фильтры, которые позволяют обнаружить простую математическую функцию на изображении (прямую, параболу, круг). Строится аккумулирующее изображение, в котором для каждой точки исходного изображения отрисовывается множество функций, её порождающих. Наиболее классическим преобразованием является преобразование Хафа для прямых. В этом преобразовании для каждой точки (x;y) отрисовывается множество точек (a;b) прямой y=ax+b, для которых верно равенство. Получаются красивые картинки:
(первый плюсег тому, кто первый найдёт подвох в картинке и таком определении и объяснит его, второй плюсег тому, кто первый скажет что тут изображено)
Преобразование Хафа позволяет находить любые параметризуемые функции. Например окружности. Есть модифицированное преобразование, которое позволяет искать любые фигуры. Это преобразование ужасно любят математики. Но вот при обработке изображений, оно, к сожалению, работает далеко не всегда. Очень медленная скорость работы, очень высокая чувствительность к качеству бинаризации. Даже в идеальных ситуациях я предпочитал обходиться другими методами.
Аналогом преобразования Хафа для прямых является преобразование Радона . Оно вычисляется через БПФ, что даёт выигрыш производительности в ситуации, когда точек очень много. К тому же его возможно применять к не бинаризованному изображению.
Фильтрации контуров
Отдельный класс фильтров - фильтрация границ и контуров . Контуры очень полезны, когда мы хотим перейти от работы с изображением к работе с объектами на этом изображении. Когда объект достаточно сложный, но хорошо выделяемый, то зачастую единственным способом работы с ним является выделение его контуров. Существует целый ряд алгоритмов, решающих задачу фильтрации контуров:
Чаще всего используется именно Кэнни, который хорошо работает и реализация которого есть в OpenCV (Собель там тоже есть, но он хуже ищёт контуры).
Прочие фильтры
Сверху приведены фильтры, модификации которых помогают решить 80-90% задач. Но кроме них есть более редкие фильтры, используемые в локальных задачах. Таких фильтров десятки, я не буду приводить их все. Интересными являются итерационные фильтры (например активная модель внешнего вида), а так же риджлет и курвлет преобразования, являющиеся сплавом классической вейвлет фильтрации и анализом в поле радон-преобразования. Бимлет-преобразование красиво работает на границе вейвлет преобразования и логического анализа, позволяя выделить контуры:
Но эти преобразования весьма специфичны и заточены под редкие задачи.
Часть 2. Логическая обработка результатов фильтрации
Фильтрация даёт набор пригодных для обработки данных. Но зачастую нельзя просто взять и использовать эти данные без их обработки. В этом разделе будет несколько классических методов, позволяющих перейти от изображения к свойствам объектов, или к самим объектам.
Морфология
Переходом от фильтрации к логике, на мой взгляд, являются методы математической морфологии (1, 2 , 3). По сути, это простейшие операции наращивания и эрозии бинарных изображений. Эти методы позволяют убрать шумы из бинарного изображения, увеличив или уменьшив имеющиеся элементы. На базе математической морфологии существуют алгоритмы оконтуривания, но обычно пользуются какими-то гибридными алгоритмами или алгоритмами в связке.
Контурный анализ
В разделе по фильтрации уже упоминались алгоритмы получения границ. Полученные границы достаточно просто преобразуются в контуры. Для алгоритма Кэнни это происходит автоматически, для остальных алгоритмов требуется дополнительная бинаризация. Получить контур для бинарного алгоритма можно например алгоритмом жука.
Контур является уникальной характеристикой объекта. Часто это позволяет идентифицировать объект по контуру. Существует мощный математический аппарат, позволяющий это сделать. Аппарат называется контурным анализом (1, 2 ).
Если честно, то у меня ни разу ни получилось применить контурный анализ в реальных задачах. Уж слишком идеальные условия требуются. То граница не найдётся, то шумов слишком много. Но, если нужно что-то распознавать в идеальных условиях - то контурный анализ замечательный вариант. Очень быстро работает, красивая математика и понятная логика.
Особые точки
Особые точки это уникальные характеристики объекта, которые позволяют сопоставлять объект сам с собой или с похожими классами объектов. Существует несколько десятков способов позволяющих выделить такие точки. Некоторые способы выделяют особые точки в соседних кадрах, некоторые через большой промежуток времени и при смене освещения, некоторые позволяют найти особые точки, которые остаются таковыми даже при поворотах объекта. Начнём с методов, позволяющих найти особые точки, которые не такие стабильные, зато быстро рассчитываются, а потом пойдём по возрастанию сложности:
Первый класс. Особые точки, являющиеся стабильными на протяжении секунд. Такие точки служат для того, чтобы вести объект между соседними кадрами видео, или для сведения изображения с соседних камер. К таким точкам можно отнести локальные максимумы изображения, углы на изображении (лучший из детекторов, пожалуй, детектор Хариса), точки в которых достигается максимумы дисперсии, определённые градиенты и.т.д.
Второй класс. Особые точки, являющиеся стабильными при смене освещения и небольших движениях объекта. Такие точки служат в первую очередь для обучения и последующей классификации типов объектов. Например, классификатор пешехода или классификатор лица - это продукт системы, построенной именно на таких точках. Некоторые из ранее упомянутых вейвлетов могут являются базой для таких точек. Например, примитивы Хаара, поиск бликов, поиск прочих специфических функций. К таким точкам относятся точки, найденные методом гистограмм направленных градиентов (HOG).
Третий класс. Стабильные точки. Мне известно лишь про два метода, которые дают полную стабильность и про их модификации. Это SURF и SIFT. Они позволяют находить особые точки даже при повороте изображения. Расчёт таких точек осуществляется дольше по сравнению с остальными методами, но достаточно ограниченное время. К сожалению эти методы запатентованы. Хотя, в России патентовать алгоритмы низя, так что для внутреннего рынка пользуйтесь.
Часть 3. Обучение
ретья часть рассказа будет посвящена методам, которые не работают непосредственно с изображением, но которые позволяют принимать решения. В основном это различные методы машинного обучения и принятия решений. Недавно Яндыкс выложил на Хабр курс по этой тематике, там очень хорошая подборка. Вот тут оно есть в текстовой версии. Для серьёзного занятия тематикой настоятельно рекомендую посмотреть именно их. Тут я попробую обозначить несколько основных методов используемых именно в распознавании образов.
В 80% ситуаций суть обучения в задаче распознавания в следующем:
Имеется тестовая выборка, на которой есть несколько классов объектов. Пусть это будет наличие/отсутствие человека на фотографии. Для каждого изображения есть набор признаков, которые были выделены каким-нибудь признаком, будь то Хаар, HOG, SURF или какой-нибудь вейвлет. Алгоритм обучения должен построить такую модель, по которой он сумеет проанализировать новое изображение и принять решение, какой из объектов имеется на изображении.
Как это делается? Каждое из тестовых изображений - это точка в пространстве признаков. Её координаты это вес каждого из признаков на изображении. Пусть нашими признаками будут: «Наличие глаз», «Наличие носа», «Наличие двух рук», «Наличие ушей», и.т.д- Все эти признаки мы выделим существующими у нас детекторами, которые обучены на части тела, похожие на людские. Для человека в таком пространстве будет корректной точка [1;1;1;1;..]. Для обезьяны точка [1;0;1;0...] для лошади [1;0;0;0...]. Классификатор обучается по выборке примеров. Но не на всех фотографиях выделились руки, на других нет глаз, а на третьей у обезьяны из-за ошибки классификатора появился человеческий нос. Обучаемый классификатор человека автоматически разбивает пространство признаков таким образом, чтобы сказать: если первый признак лежит в диапазоне 0.5<x<1, второй 0.7<y<1, и.т.д., тогда это человек.
По существу цель классификатора - отрисовать в пространстве признаков области, характеристические для объектов классификации. Вот так будет выглядеть последовательное приближение к ответу для одного из классификаторов (AdaBoost) в двумерном пространстве:
Существует очень много классификаторов. Каждый из них лучше работает в какой-то своей задачке. Задача подбора классификатора к конкретной задаче это во многом искусство. Вот тут немножко красивых картинок на тему.
Простой случай, одномерное разделение
Разберём на примере самый простой случай классификации, когда пространство признака одномерное, а нам нужно разделить 2 класса. Ситуация встречается чаще, чем может представиться: например, когда нужно отличить два сигнала, или сравнить паттерн с образцом. Пусть у нас есть обучающая выборка. При этом получается изображение, где по оси X будет мера похожести, а по оси Y -количество событий с такой мерой. Когда искомый объект похож на себя - получается левая гауссиана. Когда не похож - правая. Значение X=0.4 разделяет выборки так, что ошибочное решение минимизирует вероятность принятия любого неправильного решения. Именно поиском такого разделителя и является задача классификации.
Маленькая ремарка. Далеко не всегда оптимальным будет тот критерий, который минимизирует ошибку. Следующий график - это график реальной системы распознавания по радужной оболочке. Для такой системы критерий выбирается такой, чтобы минимизировать вероятность ложного пропуска постороннего человека на объект. Такая вероятность называется «ошибка первого рода», «вероятность ложной тревоги», «ложное срабатывание». В англоязычной литературе «False Access Rate ».
Что делать если измерений больше двух?
Алгоритмов много. Даже очень много. Если хотите подробно узнать про каждый из них читайте курс Воронцова, ссылка на который дана выше, и смотрите лекции Яндыкса. Сказать, какой из алгоритмов лучше для какой задачи часто заранее невозможно. Тут я попробую выделить основные, которые в 90% помогут новичку с первой задачей и реализацию которых на вашем языке программирования вы достоверно найдёте в интернете.
k-means (1, 2, 3 ) - один из самых простых алгоритмов обучения. Конечно, он в основном для кластеризации, но и обучить через него тоже можно. Работает в ситуации, когда группы объектов имеют неплохо разнесённый центр масс и не имеют большого пересечения.
AdaBoost (1, 2, 3) АдаБуста - один из самых распространённых классификаторов. Например каскад Хаара построен именно на нём. Обычно используют когда нужна бинарная классификация, но ничего не мешает обучить на большее количество классов.
SVM (1, 2, 3, 4 ) Один из самых мощных классификаторов, имеющий множество реализаций. В принципе, на задачах обучения, с которыми я сталкивался, он работал аналогично адабусте. Считается достаточно быстрым, но его обучение сложнее, чем у Адабусты и требуется выбор правильного ядра.
Ещё есть нейронные сети и регрессия. Но чтобы кратко их классифицировать и показать, чем они отличаются, нужна статья куда больше, чем эта.
________________________________________________
Надеюсь, у меня получилось сделать беглый обзор используемых методов без погружения в математику и описание. Может, кому-то это поможет. Хотя, конечно, статья неполна и нет ни слова ни о работе со стереоизображениями, ни о МНК с фильтром Калмана, ни об адаптивном байесовом подходе.
Если статья понравится, то попробую сделать вторую часть с подборкой примеров того, как решаются существующие задачки ImageRecognition.
И напоследок
Что почитать?
1) Когда-то мне очень понравилась книга «Цифровая обработка изображений» Б. Яне, которая написана просто и понятно, но в то же время приведена почти вся математика. Хороша для того, чтобы ознакомиться с существующими методами.
2) Классикой жанра является Р Гонсалес, Р. Вудс " Цифровая обработка изображений ". Почему-то она мне далась сложнее, чем первая. Сильно меньше математики, зато больше методов и картинок.
3) «Обработка и анализ изображений в задачах машинного зрения» - написана на базе курса, читаемого на одной из кафедр ФизТеха. Очень много методов и их подробного описания. Но на мой взгляд в книге есть два больших минуса: книга сильно ориентирована на пакет софта, который к ней прилагается, в книге слишком часто описание простого метода превращается в математические дебри, из которых сложно вынести структурную схему метода. Зато авторы сделали удобный сайт, где представлено почти всё содержание - wiki.technicalvision.ru
4) Почему-то мне кажется, что хорошая книжка, которая структурирует и увязывает картину мира, возникающую при занятии Image Recognition и Machine Learning - это «Об интеллекте» Джеффа Хокинса. Прямых методов там нет, но есть много мыслей на подумать, откуда прямые методы обработки изображений происходят. Когда вчитываешься, понимаешь, что методы работы человеческого мозга ты уже видел, но в задачах обработки видео.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru