Революция машинного обучения: общие принципы и влияние на SEO
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2016-02-12 13:35


Машинное обучение уже само по себе является серьезной дисциплиной. Оно активно используется вокруг нас, причем в гораздо более серьезных масштабах, чем вы можете себе представить. Несколько месяцев назад я решил углубиться в эту тему, чтобы узнать о ней больше. В этой статье я расскажу о некоторых базовых принципах машинного обучения, а также поделюсь своими рассуждениями по поводу его влияния на SEO и digital-маркетинг.
Для справки, рекомендую посмотреть презентацию Рэнда Фишкина «SEO in a Two Algorithm World», где Рэнд подробно рассматривает влияние машинного обучения на поиск и SEO. К этой теме я еще вернусь.
Я также упомяну сервис, который позволяет спрогнозировать шансы ретвита вашего поста на основании следующих параметров: показатель Followerwonk Social Authority, наличие изображений, хэштегов и некоторых других факторов. Я назвал этот сервис Twitter Engagement Predictor (TEP). Чтобы разработать такую систему мне понадобилось создать и обучить нейронную сеть. Вы указываете исходные параметры твита, сервис обрабатывает их и прогнозирует шансы ретвита.
TEP использует данные исследования, опубликованного в декабре 2014 «Twitter engagement» (вовлечение в Twitter), где мы проанализировали 1,9 миллионов оригинальных твитов (исключая ретвиты и избранное), чтобы определить основные факторы, которые влияют на получение ретвитов.
Свое первое представление о машинном обучении я получил в 2011 году, когда брал интервью у гуглера Питера Норвига, который рассказал мне как с помощью этой технологии Google обучает сервис Google Translate.
Если вкратце, они собирают информацию о всех вариантах перевода слова в сети и на основе этих данных проводят обучение. Это очень серьезный и сложный пример машинного обучения, Google применила его в 2011 году. Стоит сказать, что сегодня все лидеры рынка - например, Google, Microsoft, Apple и Facebook используют машинное обучение для многих интересных направлений.
Еще в ноябре, когда я захотел серьезнее разобраться в этой теме, я приступил к поиску статей в сети. Вскоре я обнаружил отличный курс по машинному обучению на Coursera. Его преподает Andrew Ng (Эндрю Ын) из Стэнфордского университета, курс дает хорошее представление об основах машинного обучения.
Внимание: Курс довольно объемный (19 занятий, каждое в среднем занимает около часа или больше). Он также требует определенного уровня подготовки в области математики, чтобы вникнуть в вычисления. В ходе курса вы погрузитесь в математику с головой. Но суть в следующем: если вы владеете необходимым бэкграундом в математике и полны решимости, то это хорошая возможность пройти бесплатный курс, чтобы усвоить каноны машинного обучения.
Кроме этого, Ын продемонстрирует вам множество примеров на языке Octave. На основе изученного материала вы сможете разработать собственные системы машинного обучения. Именно это я и сделал в примере программы из статьи.
Прежде всего, позвольте прояснить одну вещь: я не являюсь ведущим специалистом в области машинного обучения. Тем не менее, я узнал достаточно, чтобы рассказать вам о некоторых базовых положениях. В машинном обучении можно выделить два основных способа: обучение с учителем и обучение без учителя. Для начала я рассмотрю обучение с учителем.
На базовом уровне можно представить обучение с учителем как создание серии уравнений для соответствия известному набору данных. Допустим, вам нужен алгоритм для оценки стоимости недвижимости (этот пример Ын часто использует в курсе Coursera). Возьмем некоторые данные, которые будут выглядеть следующим образом: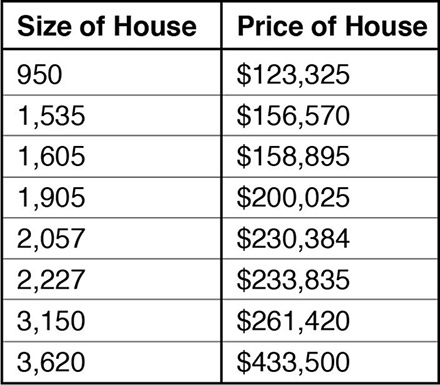
В этом примере у нас есть (вымышленные) исторические данные, которые показывают стоимость дома в зависимости от его размера. Как вы уже могли заметить, чем больше дом, тем дороже он стоит, но эта зависимость не ложится на прямую. Тем не менее, мы можем вычислить такую прямую, которая довольно неплохо будет соответствовать исходным значениям, она будет выглядеть так: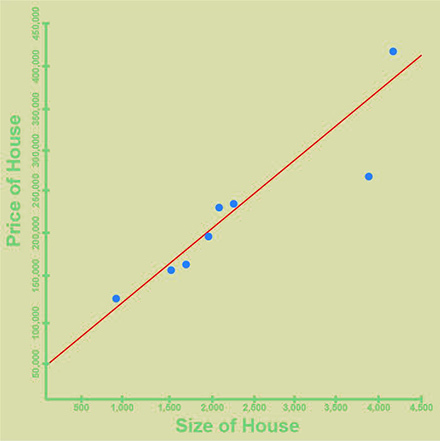
Эта линия может быть использована для прогнозирования цен на новые дома. Мы рассматриваем размер дома как «входной» параметр и прогнозируемую алгоритмом цену как «выходной» параметр.
В целом, эта модель совсем упрощенная. Ведь существуют и другие значимые факторы, которые влияют на цену недвижимости - это количество комнат, количество спален, количество санузлов, общая площадь. Исходя из этого, мы можем построить более сложную модель, с таблицей данных вроде этой: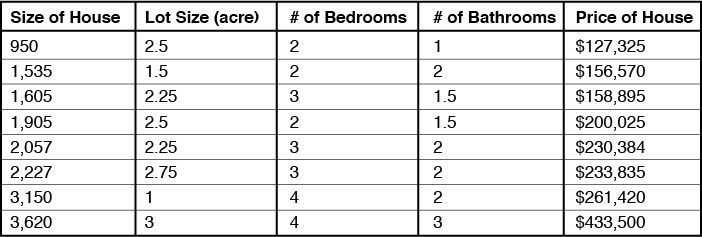
Отметим, что для этого варианта прямая не подойдёт, нам необходимо назначить каждому фактору свой вес в прогнозировании цены. Возможно, основными факторами будут размер и площадь дома, но комнаты, спальни и санузлы тоже требуют указания веса. Все эти факторы будут использоваться в качестве «входных» параметров.
Даже сейчас, нашу модель можно считать весьма упрощенной. Еще одним существенным фактором в ценах на недвижимость является локация. Цены в Сиэттле (штат Вашингтон) отличаются от цен в Галвестоне (штат Техас). Если вы попытаетесь построить подобный алгоритм в национальном масштабе, используя локацию в качестве дополнительного «входного» параметра, вы столкнетесь с серьезной задачей.
Машинное обучение можно использовать для решения всех вышеизложенных задач. В каждом из примеров мы использовали наборы данных (их чаще называют «обучающие выборки») для запуска программ, алгоритм которых основан на соответствии этим данным. Этот метод позволяет задействовать новые «входные» параметры для прогнозирования результата (в нашем случае, цены). Таким образом, способ машинного обучения, при котором система обучается на основе обучающих выборок называют «обучением с учителем».
Существует особый тип задач, в которых основной целью является прогнозирование конкретных результатов. Представьте к примеру, что мы хотим определить вероятность того, что новорожденный со временем вырастет, как минимум, до 6 футов (~183 см). Набор входных данных будет выглядеть приблизительно так:
На выходе данного алгоритма мы получим значение 0, если человек, вероятно, будет ниже чем 183 см и значение 1, если рост прогнозируется выше заданного. Для решения этой задачи классификации мы указываем входные параметры для специфического класса. В этом случае мы не пытаемся определить точный рост, а просто прогнозируем вероятность, что он будет выше или ниже заданного.
Примерами более сложных вопросов классификации является распознавание рукописного текста или спама в письмах.
Данный способ машинного обучения используют при отсутствии обучающей выборки. Идея заключается в том, чтобы научить систему выделять группы объектов с общими свойствами. Например, у нас может быть следующий набор данных: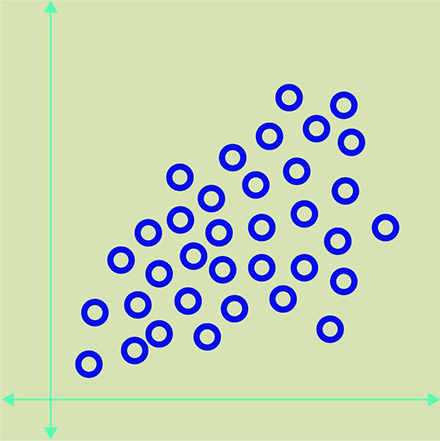
Алгоритм анализирует эти данные и группирует их на основании общих свойств. В примере ниже показаны объекты «x» имеют общие свойства: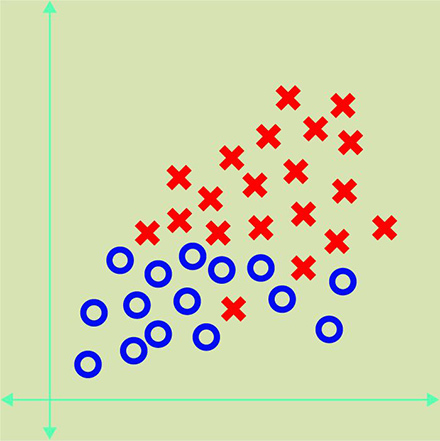
Тем не менее, алгоритм может ошибаться при распознавании объектов и группировать их примерно так: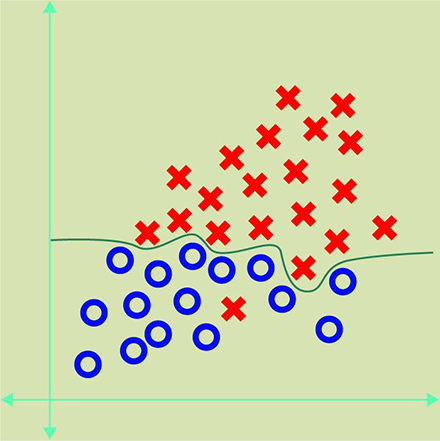
В отличие от обучения с учителем, этот алгоритм сам определил параметры, свойственные каждой из групп и сгруппировал их. Одним из примеров реализации системы обучения без учителя является сервис Google News. Посмотрим на следующий пример: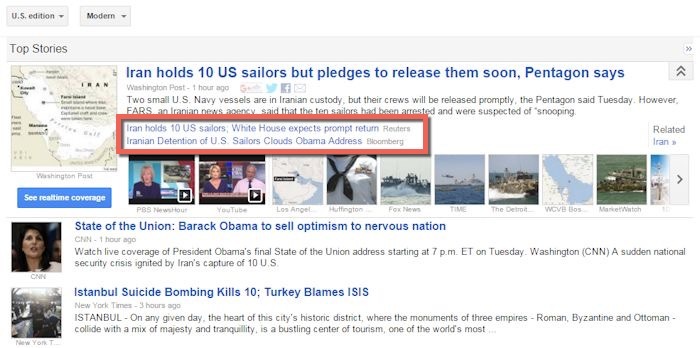
Мы видим новость о задержании Ираном 10 американских моряков, а также ссылки на связанные новости от агентств Reuters и Bloomberg (обведено красным). Группировка этих новостей является хорошим примером системы машинного обучения без учителя, когда алгоритм учится находить связи между объектами и объединять их.
Замечательным примером использования машинного обучения является алгоритм определения автора, который Moz реализовали в своем сервисе для работы с контентом. Узнать об этом алгоритме больше можно здесь. В статье по ссылке подробно описываются проблемы, с которыми специалистам из Moz пришлось столкнуться и каким образом они решили поставленную задачу.
Теперь расскажу немного об упомянутом в начале статьи сервисе Twitter Engagement Predictor, система которого построена на базе нейронной сети. Пример его работы можно увидеть на скриншоте: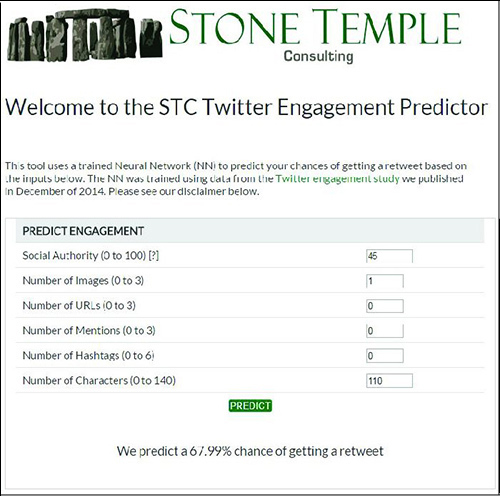
Программа делает бинарный прогноз ретвитнут ваш пост или нет, и в случае положительного ответа высчитывает вероятность ретвита.
При анализе исходных данных, используемых для обучения сети можно обнаружить немало интересных нюансов, например:
Таблица показывает статистику для твитов пользователей с уровнем Social Authority от 0 до 9, без изображений, без ссылок и упоминаний, содержащих 2 хештега и от 0 до 40 символов текста. Мы видим 1156 таких твитов без ретвитов и только 17 твитов с ретвитами.
Наш алгоритм показывает, что с высокой вероятностью твит с такими параметрами не получит ретвитов, но этот прогноз будет неверным для 1,4% случаев (17 из 1173). Нейронная сеть прогнозирует вероятность получения ретвита в 2,1%.
Я рассчитал таблицу возможных случаев и обнаружил, что у нас было 102045 примеров с возможностью ошибки, или примерно 10% от всей обучающей выборки. Это значит, что нейронная сеть будет делать верные прогнозы в лучшем случае для 90% ситуаций.
Кроме того, я проверил два дополнительных набора данных (содержащие 470к и 473к примеров) через нейронную сеть, чтобы оценить точность показаний TEP. В абсолютном прогнозе (да/нет) система оказалась права в 81% случаев. Учитывая, что здесь тоже присутствовали около 10% примеров с возможной ошибкой, можно сказать, что результат довольно неплох! По этой причине сервис TEP дополнительно отображает вероятность ретвита в процентах, вместо обычного прогноза (да/нет).
Теперь, когда мы разобрались с основными способами машинного обучения, давайте перейдем ко второй части статьи и посмотрим, для чего Google может использовать эти методы:
Одним из подходов к реализации алгоритма Google Penguin может быть построение связей между ссылочными характеристиками, которые могут быть потенциальными индикаторами ссылочного спама:
- Внешняя ссылка размещена в области футера;
- Внешняя ссылка размещена в сайдбаре;
- Ссылка размещена близко к слову «Реклама» (и/или подобным);
- Ссылка размещена близко к изображению, на котором написано слово «Реклама» (и/или подобным);
- Ссылка размещена в блоке с ссылками, имеющими низкую релевантность по отношению друг к другу;
- Анкор ссылки не имеет отношения к контенту страницы;
- Внешняя ссылка размещена в области навигации;
- У внешней ссылки отсутствует отдельный стиль (выделение цветом или подчеркиванием);
- Ссылка расположена на «плохом» типе сайта (заспамленный каталог; из страны, не имеющей отношения к сайту);
- - Другие факторы
Само собой, соответствие ссылки лишь одному из этих факторов не обязательно делает ее «плохой», но алгоритм может выявлять сайты, где значительная часть внешних ссылок имеет указанные свойства.
Изложенный мной пример демонстрирует систему обучения с учителем, где вы тренируете алгоритм на основании имеющихся у вас данных о плохих и хороших ссылках (сайтах), обнаруженных за последние годы. После обучения алгоритма с его помощью можно проверять ссылки для определения их «качества». Основываясь на процентном соотношении «плохих» ссылок (и/или показателе PageRank), можно принимать решение - понижать рейтинг сайта в поиске или нет.
Другой подход в решении этой задачи предполагает использование базы хороших и плохих ссылок, где алгоритм сам определяет их характеристики. При таком подходе алгоритм наверняка обнаружит дополнительные факторы, которые не замечают люди.
После того, как мы рассмотрели потенциальные возможности алгоритма Пингвин, ситуация немного прояснилась. Теперь представим возможности алгоритма оценки качества контента.
- Малый объем контента в сравнении со страницами конкурентов;
- Недостаточно широкое использование синонимов в тексте;
- Злоупотребление ключевыми словами на странице;
- Большие блоки текста, расположенные в нижней части страницы;
- Множество ссылок на не связанные по смыслу страницы;
- Страницы со скопированным с других сайтов содержанием;
- - Другие факторы
Для этой задачи можно обучить алгоритм на основании примеров хороших сайтов, чтобы выделить их качественные характеристики.
Как и в случае с Пингвином выше, я ни в коем случае не утверждаю, что конкретно эти пункты используются в алгоритме Панда - они лишь демонстрируют общую концепцию, как все это может работать.
Ключ к пониманию степени влияния машинного обучения на SEO лежит в вопросе, зачем Google (и другие поисковые системы) использует эти методы. Важно то, что существует сильная корреляция между качеством результатов органической выдачи и доходом Google от контекстной рекламы.
Еще в 2009 году Bing и Google проводили ряд экспериментов, которые показали, что появление даже небольших задержек в результатах поиска значительно влияют на удовлетворенность пользователей. В свою очередь, менее довольные пользователи меньше кликали на рекламные объявления, а поисковые системы получали меньший доход: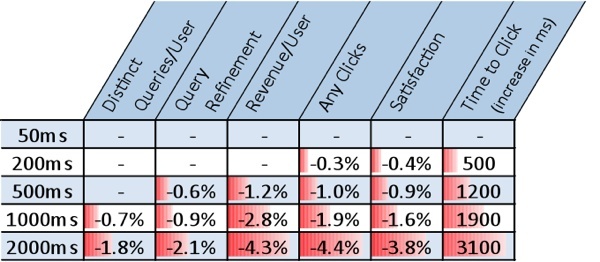
Объясняется все это очень просто. У Google полно конкурентов, и это касается не только поиска Bing. Борьба за аудиторию в остальных (непоисковых) сервисах также является формой конкуренции. Здесь уже подключаются Facebook, Apple/Siri и Amazon. Существует множество альтернативных источников получения и обмена информацией, и они каждый день работают над тем, чтобы стать лучше. Поэтому и Google должен.
Я уже предположил, что машинное обучение может использоваться в алгоритмах Пингвин и Панда, и это вполне может быть частью глобального алгоритма оценки «качества поиска». Скорее всего, вы увидим еще много примеров использования подобных алгоритмов в будущем.
Учитывая, что повышение удовлетворенности пользователя имеет решающее значение для Google, нам стоит рассматривать этот показатель в качестве основного фактора ранжирования для SEO. Вам нужно научиться измерять его и повышать показатель со временем. Рекомендую задать себе следующие вопросы:
- Соответствует ли контент вашей страницы ожиданию большинства пользователей? Если пользователь заинтересован в вашем товаре, нужна ли ему помощь в выборе? Нужны ли ему советы по использованию товара?
- Как насчет связанных намерений? Если пользователь пришел к вам за конкретным продуктом, какие сопутствующие товары могут его заинтересовать?
- Чего не хватает в контенте вашей страницы?
- Выглядит ли ваша страница качественнее, чем страницы конкурентов?
- Как вы измеряете показатели качества страниц и улучшаете ли их со временем?
У Google есть множество способов, с помощью которых можно оценить качество вашей страницы и использовать эти данные для изменения ее рейтинга в результатах поиска. Вот некоторые из них:
- Как долго пользователи задерживаются на странице сайта и насколько этот показатель отличается от конкурентов?
- Какой уровень CTR имеют страницы вашего сайта в сравнении с конкурентами?
- Много ли пользователей приходит на ваш сайт по брендовым запросам?
- Если у вас есть страницы конкретного продукта, вы предоставляете более полную или краткую информацию о нем по сравнению с конкурентами?
- Если пользователь возвращается с вашего сайта к результатам поиска, продолжает ли он просматривать другие сайты или вводит другой запрос?
Машинное обучение стремительно распространяется. Препятствия для обучения базовых алгоритмов исчезают. Все основные компании на рынке в той или иной мере используют методы машинного обучения. Вот немного информации для чего машинное обучение использует Facebook, а вот как активно вербует специалистов по машинному обучению Apple. Другие компании предоставляют платформы, чтобы облегчить внедрение машинного обучения, например, Microsoft и Amazon.
Людям, занятым в области SEO и digital-маркетинга, стоит ожидать, что топовые компании будут активно развивать алгоритмы для решения своих задач. Поэтому лучше настраиваться на работу в соответствии с основными целями лидеров рынка.
В случае с SEO машинное обучение со временем будет повышать планку качества контента и опыта взаимодействия пользователей. Самое время учесть все эти факторы в своих стратегиях продвижения, чтобы успеть на борт стремительно движущегося лайнера технологий.
Телеграм: t.me/ainewsline
Источник: vk.com