тСМДЮЛЕМРЮКЭМШЕ НЯМНБШ УЮЙЕПЯРБЮ. аНПЕЛЯЪ Я ДХГЮЯЯЕЛАКЕПЮЛХ Х ГЮРПСДМЪЕЛ ПЕБЕПЯ ОПНЦПЮЛЛ
лемч
цКЮБМЮЪ ЯРПЮМХЖЮ
оНХЯЙ
пЕЦХЯРПЮЖХЪ МЮ ЯЮИРЕ
оНЛНЫЭ ОПНЕЙРС
юПУХБ МНБНЯРЕИ
релш
мНБНЯРХ хх
цНПНДЯЙХЕ ЯСЛЮЯЬЕДЬХЕ
хх Б ЛЕДХЖХМЕ
хх ОПНЕЙРШ
хЯЙСЯЯРБЕММШЕ МЕИПНЯЕРХ
хЯЙСЯЯРБЕММШИ ХМРЕККЕЙР
яКЕФЙЮ ГЮ КЧДЭЛХ
сЦПНГЮ хх
йНЛОЭЧРЕПМШЕ МЮСЙХ
лЮЬХММНЕ НАСВ. (нЬХАЙХ)
лЮЬХММНЕ НАСВЕМХЕ
лЮЬХММШИ ОЕПЕБНД
мЕИПНММШЕ ЯЕРХ МЮВХМЮЧЫХЛ
оЯХУНКНЦХЪ хх
пЕЮКХГЮЖХЪ хх
пЕЮКХГЮЖХЪ МЕИПНЯЕРЕИ
яНГДЮМХЕ АЕЯОХКНРМШУ ЮБРН
рПЕГБН ОПН хх
тХКНЯНТХЪ хх
цЕМЕРХВЕЯЙХЕ ЮКЦНПХРЛШ
йЮОЯСКЭМШЕ МЕИПНЯЕРХ
нЯМНБШ МЕИПНММШУ ЯЕРЕИ
пЮЯОНГМЮБЮМХЕ КХЖ
пЮЯОНГМЮБЮМХЕ НАПЮГНБ
пЮЯОНГМЮБЮМХЕ ПЕВХ
рБНПВЕЯРБН хх
рЕУМХВЕЯЙНЕ ГПЕМХЕ
вЮР-АНРШ
юБРНПХГЮЖХЪ
2024-04-09 12:08

йПХЯ йЮЯОЕПЯЙХ, чПХИ ъГЕБ
йЮФґДШИ ПЮГґПЮАНРґВХЙ ОПНЦґПЮЛЛ ЯРПЕґЛХРґЯЪ ГЮЫХРХРЭ ПЕГСКЭґРЮР ЯБНґЕЦН РПСґДЮ НР БГКНґЛЮ. яЕЦНДґМЪ МЮЛ ОПЕДґЯРНґХР ХЯЯКЕґДНБЮРЭ ЯОНґЯНАШ ОПНґРХБНЯґРНЪМХЪ ЯЮЛНЛС ОНОСКЪПґМНЛС БХДС УЮЙЕПґЯЙНґЦН ХМЯґРПСґЛЕМґРЮПХЪ ≈ ДХГЮЯґЯЕЛґАКЕґПЮЛ. мЮЬЕИ ЖЕКЭЧ АСДЕР ГЮОСРЮРЭ УЮЙЕПЮ, НРБЮґДХРЭ ЕЦН НР БГКНґЛЮ МЮЬЕИ ОПНЦґПЮЛЛШ, БЯЕґБНГґЛНФМШґЛХ ЯОНґЯНАЮґЛХ ГЮРґПСДМХРЭ ЕЕ ЮМЮґКХГ.
тСМДЮЛЕМРЮКЭМШЕ НЯМНБШ УЮЙЕПЯРБЮ
оЪРґМЮДЖЮРЭ КЕР МЮГЮД ЩОХґВЕЯґЙХИ РПСД йПХґЯЮ йЮЯґОЕПґЯЙХ ╚тСМґДЮЛЕМґРЮКЭґМШЕ НЯМНґБШ УЮЙЕПЯґРБЮ╩ АШК МЮЯґРНКЭґМНИ ЙМХґЦНИ ЙЮФґДНЦН МЮВХМЮґЧЫЕґЦН ХЯЯКЕґДНБЮґРЕКЪ Б НАКЮЯРХ ЙНЛОЭґЧРЕПґМНИ АЕГНОЮЯґМНЯРХ. нДМЮґЙН БПЕґЛЪ ХДЕР, Х ГМЮґМХЪ, НОСАґКХЙНБЮМґМШЕ йПХґЯНЛ, РЕПЪґЧР ЮЙРСґЮКЭґМНЯРЭ. пЕДЮЙґРНПШ ╚уЮЙЕПЮ╩ ОНОШРЮґКХЯЭ НАМНґБХРЭ ЩРНР НАЗґЕЛМШИ РПСД Х ОЕПЕМЕЯґРХ ЕЦН ХГ БПЕґЛЕМ Windows 2000 Х Visual Studio 6.0 БН БПЕґЛЕМЮ Windows 10 Х Visual Studio 2019.
оПНґДНКґФЮЕЛ ДЕПґФЮРЭ НАНґПНМС МЮЬЕЦН ОПХґКНФЕґМХЪ НР ЮРЮЙ ГКНАґМШУ УЮЙЕПНБ ≈ НР ХУ ОНОШРНЙ ╚ГЮ ОПНЯґРН РЮЙ╩ БНЯґОНКЭґГНБЮРЭґЯЪ ОКНґДЮЛХ МЮЬЕЦН РПСґДЮ, НР ХУ ОНДНГґПХРЕКЭґМНЦН ХМРЕґПЕЯЮ Й МЮЬХЛ ОПНЦґПЮЛЛЮЛ Х ЯЙПШґБЮЕЛШЛ Б МХУ ЯЕЙґПЕРЮЛ. дКЪ ЩРНґЦН ЛШ ОПНґДНКґФХЛ ЯНГґДЮБЮРЭ ХГНЫґПЕММШЕ ЯХЯґРЕЛШ ГЮЫХРШ, МЮ ЯЕИ ПЮГ ≈ НР ДХГЮЯґЯЕЛґАКХґПНБЮґМХЪ.
вРНґАШ ЯОПЮґБХРЭґЯЪ Я ГЮДЮВЕИ, МЮЛ МЕНАґУНДХЛН СГМЮРЭ Н БМСРґПЕММХУ ЛЕУЮМХГґЛЮУ НОЕґПЮЖХґНММНИ ЯХЯґРЕЛШ, Н ЯПЕДЯґРБЮУ ПЮАНРШ Я ОЮЛЪРЭЧ. рЮЙґФЕ ОПХґДЕРґЯЪ ПЮГНАґПЮРЭґЯЪ Б ПЮАНРЕ ЙНЛґОХКЪРНґПНБ, ОНМЪРЭ, ЙЮЙ НМХ ЦЕМЕПХґПСЧР ЙНД, БШВХЯґКХРЭ ОКЧґЯШ Х ЛХМСЯШ НОРХґЛХГЮґЖХХ. х МЮЙНМЕЖ, ОНЦґПСГХРЭґЯЪ Б ЬХТґПНБЮМХЕ, МЮСВХРЭґЯЪ ПЮЯґЬХТПНґБШБЮРЭ ОПНЦґПЮЛґЛМШИ ЙНД МЮ КЕРС МЕОНЯґПЕДЯґРБЕМґМН ОЕПЕД БШОНКґМЕМХґЕЛ.
яюлнлндхтхжхпсчыхияъ йнд б янбпелеммшу ноепюжхнммшу яхярелюу
б ЩОНґУС ПЮЯґЖБЕґРЮ MS-DOS ОПНЦґПЮЛЛХЯґРШ ЬХПНЙН ХЯОНКЭґГНБЮКХ ЯЮЛНЛНґДХТХґЖХПСґЧЫХИґЯЪ ЙНД, АЕГ ЙНРНПНґЦН МЕ НАУНґДХКЮЯЭ ОПЮЙґРХВЕЯґЙХ МХ НДМЮ ЛЮКН?ЛЮКЭґЯЙХ ЯЕПЭґЕГМЮЪ ГЮЫХРЮ. дЮ Х МЕ РНКЭґЙН ГЮЫХРЮ ≈ НМ БЯРПЕґВЮКґЯЪ Б ЙНЛґОХКЪРНґПЮУ, ЙНЛґОХКХПСґЧЫХУ ЙНД МЕОНЯґПЕДЯґРБЕМґМН Б ОЮЛЪРЭ, Б ПЮЯґОЮЙНБґЫХЙЮУ ХЯОНКМЪґЕЛШУ ТЮИґКНБ, Б ОНКХЛНПґТМШУ ЦЕМЕПЮґРНПЮУ Х РЮЙ ДЮКЕЕ.
йНЦґДЮ МЮВЮКЮЯЭ ЛЮЯґЯНБЮЪ ЛХЦґПЮЖХЪ ОНКЭґГНБЮРЕґКЕИ МЮ Windows, ПЮГґПЮАНРґВХЙЮЛ ОПХЬґКНЯЭ ГЮДСЛЮРЭґЯЪ Н ОЕПЕМНґЯЕ МЮЙНОґКЕММНґЦН НОШґРЮ Х ОПХґЕЛНБ ОПНЦґПЮЛЛХґПНБЮґМХЪ МЮ МНБСЧ ОКЮРґТНПЛС. нР АЕЯґЙНМґРПНКЭґМНЦН ДНЯґРСОЮ Й ФЕКЕГС, ОЮЛЪРХ, ЙНЛґОНМЕМґРЮЛ НОЕґПЮЖХґНММНИ ЯХЯґРЕЛШ Х ЯБЪґГЮМґМШУ Я МХЛХ УХРґПНСЛґМШУ РПЧґЙНБ ОПНЦґПЮЛЛХґПНБЮґМХЪ ОПХЬґКНЯЭ НРБШґЙЮРЭ. б ВЮЯґРМНЯґРХ, ЯРЮґКЮ МЕБНГґЛНФМЮ МЕОНЯґПЕДЯґРБЕМґМЮЪ ЛНДХТХґЙЮЖХЪ ХЯОНКМЪґЕЛНґЦН ЙНДЮ ОПХґКНФЕґМХИ, ОНЯґЙНКЭґЙС Windows ГЮЫХЫЮґЕР ЕЦН НР МЕОґПЕДМЮґЛЕПЕМґМШУ ХГЛЕґМЕМХИ. щРН ОПХґБЕКН Й ПНФґДЕМХЧ МЕКЕОНґЦН САЕФґДЕМХЪ, АСДґРН ОНД Windows ЯНГґДЮМХЕ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ БННАґЫЕ МЕБНГґЛНФМН, ОН ЙПЮИґМЕИ ЛЕПЕ АЕГ ХЯОНКЭґГНБЮМХЪ МЕДНЙСґЛЕМґРХПНБЮМґМШУ БНГґЛНФМНЯґРЕИ НОЕґПЮЖХґНММНИ ЯХЯґРЕЛШ.
мЮ ЯЮЛНЛ ДЕКЕ ЯСЫЕЯґРБСґЕР ЙЮЙ ЛХМХЛСЛ ДБЮ ДНЙСЛЕМґРХПНБЮМґМШУ ЯОНґЯНАЮ ХГЛЕґМХРЭ ЙНД ОПХґКНФЕґМХИ, УНПНЬН ПЮАНРЮґЧЫХУ ОНД Windows NT Х БОНКґМЕ СДНБґКЕРБНґПЪЧЫХУґЯЪ ОПХґБХКЕґЦХЪЛХ ЦНЯґРЕБНЦН ОНКЭґГНБЮРЕґКЪ.
бН?ОЕПґБШУ, kernel32.dll ЩЙЯОНПґРХПСґЕР ТСМґЙЖХЧ WriteProcessMemory, ОПЕДґМЮГМЮґВЕМґМСЧ, ЙЮЙ Х ЯКЕґДСЕР ХГ ЕЕ МЮГґБЮМХЪ, ДКЪ ЛНДХТХґЙЮЖХХ ОЮЛЪРХ ОПНґЖЕЯґЯЮ. бН?БРНґПШУ, ОПЮЙґРХВЕЯґЙХ БЯЕ НОЕґПЮЖХґНММШЕ ЯХЯґРЕЛШ, БЙКЧґВЮЪ Windows Х Linux, ПЮГґПЕЬЮґЧР БШОНКґМЕМХЕ Х ЛНДХТХґЙЮЖХЧ ЙНДЮ, ПЮГґЛЕЫЕМґМНЦН Б ЯРЕґЙЕ. лЕФґДС РЕЛ ЯНБґПЕЛЕМґМШЕ БЕПґЯХХ СЙЮґГЮМґМШУ НОЕґПЮЖХґНММШУ ЯХЯґРЕЛ МЮЙґКЮДШБЮґЧР МЮ ЯРЕЙ НЦПЮґМХВЕґМХЪ, ЛШ ОНДґПНАМН ОНЦНБНґПХЛ НА ЩРНЛ ВСРЭ ОНГґДМЕЕ.
б ОПХМґЖХОЕ, ГЮДЮВЮ ЯНГґДЮМХЪ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ ЛНФЕР АШРЭ ПЕЬЕМЮ ХЯЙКЧґВХРЕКЭґМН ЯПЕДЯґРБЮґЛХ ЪГШґЙНБ БШЯНЙНґЦН СПНБґМЪ, РЮЙХУ, МЮОґПХЛЕП, ЙЮЙ C/C++ Х Delphi, АЕГ ОПХґЛЕМЕґМХЪ ЮЯЯЕЛґАКЕґПЮ.
юПУХРЕЙРСПЮ ОЮЛЪРХ Windows
яНГґДЮМХЕ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ РПЕґАСЕР ГМЮґМХЪ МЕЙНРНґПШУ РНМґЙНЯРЕИ ЮПУХґРЕЙґРСПШ Windows, МЕ НВЕМЭ?РН УНПНЬН НЯБЕґЫЕМґМШУ Б ДНЙСЛЕМґРЮЖХХ. рНВґМЕЕ, ЯНБґЯЕЛ МЕ НЯБЕґЫЕМґМШУ, МН НР ЩРНґЦН НРМЧДЭ МЕ ОПХґНАПЕґРЮЧЫХУ ЯРЮґРСЯ ╚МЕДНЙСґЛЕМґРХПНБЮМґМШУ НЯНґАЕМґМНЯРЕИ╩, ОНЯґЙНКЭґЙС, БН?ОЕПґБШУ, НМХ НДХґМЮЙНґБН ПЕЮКХґГНБЮґМШ МЮ БЯЕУ Windows-ОКЮРґТНПЛЮУ, Ю БН?БРНґПШУ, ХУ ЮЙРХБМН ХЯОНКЭґГСЕР ЙНЛґОХКЪРНП Visual C++ НР Microsoft. нРЯЧґДЮ ЯКЕґДСЕР, ВРН МХЙЮЙХУ ХГЛЕґМЕМХИ ДЮФЕ Б НРДЮґКЕМґМНЛ АСДСЫЕЛ ЙНЛґОЮМХЪ МЕ ОКЮґМХПСґЕР; Б ОПНґРХБґМНЛ ЯКСґВЮЕ ЙНД, ЯЦЕґМЕПХґПНБЮМґМШИ ЩРХЛ ЙНЛґОХКЪРНґПНЛ, НРЙЮґФЕР Б ПЮАНРЕ, Ю МЮ ЩРН Microsoft МЕ ОНИґДЕР (БЕПґМЕЕ, МЕ ДНКґФМЮ ОНИґРХ, ЕЯКХ БЕПХРЭ ГДПЮґБНЛС ЯЛШЯґКС).
б ПЕФХЛЕ НАПЮРМНИ ЯНБґЛЕЯРХґЛНЯґРХ ДКЪ ЮДПЕґЯЮЖХХ ВЕРШПЕУ ЦХЦЮАЮИР БХПґРСЮКЭґМНИ ОЮЛЪРХ, БШДЕКЕМґМНИ Б ПЮЯґОНПЪФЕґМХЕ ОПНґЖЕЯґЯЮ, Windows ХЯОНКЭґГСЕР ДБЮ ЯЕКЕЙґРНПЮ, НДХМ ХГ ЙНРНПШУ ГЮЦґПСФЮґЕРЯЪ Б ЯЕЦґЛЕМґРМШИ ПЕЦХЯРП CS, Ю ДПСґЦНИ ≈ Б ПЕЦХЯґРПШ DS, ES Х SS. нАЮ ЯЕКЕЙґРНПЮ ЯЯШґКЮЧРґЯЪ МЮ НДХМ Х РНР ФЕ АЮГНБШИ ЮДПЕЯ ОЮЛЪРХ, ПЮБґМШИ МСКЧ, Х ХЛЕґЧР ХДЕМґРХВМШЕ КХЛХРШ, ПЮБґМШЕ ВЕРШПЕЛ ЦХЦЮАЮИґРЮЛ. оНЛХЛН ОЕПЕВХЯґКЕММШУ ЯЕЦґЛЕМґРМШУ ПЕЦХЯґРПНБ, Windows ЕЫЕ ХЯОНКЭґГСЕР ПЕЦХЯРП FS, Б ЙНРНПШИ ГЮЦґПСФЮґЕР ЯЕКЕЙґРНП ЯЕЦґЛЕМРЮ, ЯНДЕПґФЮЫЕЦН ХМТНПЛЮґЖХНМґМШИ АКНЙ ОНРНЙЮ ≈ TIB.
тЮЙґРХВЕЯґЙХ ЯСЫЕЯґРБСґЕР БЯЕґЦН НДХМ ЯЕЦґЛЕМР, БЛЕґЫЮЧЫХИ Б ЯЕАЪ Х ЙНД, Х ДЮМґМШЕ, Х ЯРЕЙ ОПНґЖЕЯґЯЮ. аКЮґЦНДЮґПЪ ЩРНґЛС СОПЮБКЕґМХЕ ЙНДС, ПЮЯґОНКНФЕМґМНЛС Б ЯРЕґЙЕ, ОЕПЕДЮґЕРЯЪ АКХГґЙХЛ (near) БШГНБНЛ ХКХ ОЕПЕУНґДНЛ, Х ДКЪ ДНЯґРСОЮ Й ЯНДЕПґФХЛНЛС ЯРЕґЙЮ ХЯОНКЭґГНБЮМХЕ ОПЕґТХЙґЯЮ SS ЯНБЕПґЬЕММН МЕНАЪґГЮРЕКЭґМН. мЕЯґЛНРПЪ МЮ РН ВРН ГМЮґВЕМХЕ ПЕЦХЯґРПЮ CS МЕ ПЮБґМН ГМЮґВЕМХЧ ПЕЦХЯґРПНБ DS, ES Х SS, ЙНЛЮМґДШ
∙ MOV dest,CS:[src]
∙ MOV dest,DS:[src]
∙ MOV dest,SS:[src]
Б ДЕИґЯРБХґРЕКЭґМНЯґРХ НАПЮґЫЮЧРґЯЪ Й НДМНИ Х РНИ ФЕ ЪВЕИґЙЕ ОЮЛЪРХ.
щРН РНВґМШИ ОПНґНАПЮГ ПЕЮКХґГНБЮМґМНИ Б ОПНґЖЕЯґЯНПЮУ МЮ ЮПУХґРЕЙґРСПЕ x86-64 RIP-НРМНґЯХРЕКЭґМНИ ЮДПЕґЯЮЖХХ ОЮЛЪРХ, Б ЙНРНПНИ МЕ ХЯОНКЭґГСЧРґЯЪ ЯЕЦґЛЕМРШ.
нРґКХВХЪ ЛЕФґДС ПЕЦХґНМЮґЛХ ЙНДЮ, ЯРЕґЙЮ Х ДЮМґМШУ ГЮЙґКЧВЮґЧРЯЪ Б ЮРПХґАСРЮУ ОПХґМЮДґКЕФЮЫХУ ХЛ ЯРПЮґМХЖ: ЯРПЮґМХЖШ ЙНДЮ ДНОСЯґЙЮЧР ВРЕґМХЕ Х ХЯОНКМЕґМХЕ, ЯРПЮґМХЖШ ДЮМґМШУ ≈ ВРЕґМХЕ Х ГЮОХЯЭ, Ю ЯРЕґЙЮ ≈ ВРЕґМХЕ, ГЮОХЯЭ Х ХЯОНКМЕґМХЕ НДМНБПЕґЛЕМґМН.
оНґЛХЛН ЩРНґЦН, ЙЮФґДЮЪ ЯРПЮґМХЖЮ ХЛЕґЕР ЯОЕґЖХЮКЭґМШИ ТКЮЦ, НОПЕґДЕКЪґЧЫХИ СПНґБЕМЭ ОПХґБХКЕґЦХИ, ЙНРНПШЕ МЕНАґУНДХЛШ ДКЪ ДНЯґРСОЮ Й ЩРНИ ЯРПЮґМХЖЕ. мЕЙНРНґПШЕ ЯРПЮґМХЖШ, МЮОґПХЛЕП РЕ, ВРН ОПХґМЮДґКЕФЮР НОЕґПЮЖХґНММНИ ЯХЯґРЕЛЕ, РПЕґАСЧР МЮКХВХЪ ОПЮБ ЯСОЕПґБХГНПЮ, ЙНРНПШґЛХ НАКЮґДЮЕР РНКЭґЙН ЙНД МСКЕБНґЦН ЙНКЭґЖЮ. оПХЙґКЮДМШЕ ОПНЦґПЮЛЛШ, ХЯОНКМЪґЧЫХЕЯЪ Б ЙНКЭґЖЕ 3, РЮЙХУ ОПЮБ МЕ ХЛЕґЧР Х ОПХ ОНОШРґЙЕ НАПЮґЫЕМХЪ Й ГЮЫХЫЕМґМНИ ЯРПЮґМХЖЕ ОНПНФґДЮЧР ХЯЙКЧґВЕМХЕ. лЮМХОСґКХПНґБЮРЭ ЮРПХґАСРЮґЛХ ЯРПЮґМХЖ, ПЮБґМН ЙЮЙ Х ЮЯЯНґЖХХПНґБЮРЭ ЯРПЮґМХЖШ Я КХМЕИґМШЛХ ЮДПЕґЯЮЛХ, ЛНФЕР РНКЭґЙН НОЕґПЮЖХґНММЮЪ ЯХЯґРЕЛЮ ХКХ ЙНД, ХЯОНКМЪґЧЫХИґЯЪ Б МСКЕБНЛ ЙНКЭґЖЕ.
яПЕґДХ МЮВХМЮґЧЫХУ ОПНЦґПЮЛЛХЯґРНБ УНДХР ЯНБЕПґЬЕММН МЕКЕОЮЪ АЮИґЙЮ Н РНЛ, ВРН, ЕЯКХ НАПЮґРХРЭґЯЪ Й ЙНДС ОПНЦґПЮЛЛШ ЙНЛЮМґДНИ, ОПЕДґБЮПЕМґМНИ ОПЕґТХЙґЯНЛ DS, Windows ЪЙНґАШ АЕЯґОПЕґОЪРЯґРБЕМґМН ОНГґБНКХР ЕЦН ХГЛЕґМХРЭ. мЮ ЯЮЛНЛ ДЕКЕ ЩРН Б ЙНПґМЕ МЕБЕПґМН ≈ НАПЮґРХРЭґЯЪ?РН НМЮ ОНГґБНКХР, Ю БНР ХГЛЕґМХРЭ ≈ МЕР, ЙЮЙХЛ АШ ЯОНґЯНАНЛ МХ ОПНґХЯУНґДХКН НАПЮґЫЕМХЕ, РЮЙ ЙЮЙ ГЮЫХРЮ ПЮАНРЮґЕР МЮ СПНБґМЕ ТХГХВЕЯґЙХУ ЯРПЮґМХЖ, Ю МЕ КНЦХВЕЯґЙХУ ЮДПЕґЯНБ.
хЯОНКЭГНБЮМХЕ ТСМЙЖХХ WriteProcessMemory
еЯґКХ РПЕґАСЕРґЯЪ ХГЛЕґМХРЭ МЕЙНРНґПНЕ ЙНКХВЕЯґРБН АЮИґРНБ ЯБНґЕЦН (ХКХ ВСФНЦН) ОПНґЖЕЯґЯЮ, ЯЮЛШИ ОПНЯґРНИ ЯОНґЯНА ЯДЕґКЮРЭ ЩРН ≈ БШГґБЮРЭ ТСМґЙЖХЧ WriteProcessMemory. нМЮ ОНГґБНКЪґЕР ЛНДХТХґЖХПНґБЮРЭ ЯСЫЕЯґРБСґЧЫХЕ ЯРПЮґМХЖШ ОЮЛЪРХ, ВЕИ ТКЮЦ ЯСОЕПґБХГНПЮ МЕ БГБЕґДЕМ, РН ЕЯРЭ БЯЕ ЯРПЮґМХЖШ, ДНЯґРСОМШЕ ХГ ЙНКЭґЖЮ 3, Б ЙНРНПНЛ БШОНКґМЪЧРґЯЪ ОПХЙґКЮДМШЕ ОПХґКНФЕґМХЪ. яНБЕПґЬЕММН АЕЯґОНКЕГґМН Я ОНЛНЫЭЧ WriteProcessMemory ОШРЮРЭґЯЪ ХГЛЕґМХРЭ ЙПХґРХВЕЯґЙХЕ ЯРПСЙґРСПШ ДЮМґМШУ НОЕґПЮЖХґНММНИ ЯХЯґРЕЛШ (МЮОґПХЛЕП, page directory ХКХ page table) ≈ НМХ ДНЯґРСОМШ КХЬЭ ХГ МСКЕБНґЦН ЙНКЭґЖЮ. оНЩРНґЛС СЙЮґГЮМґМЮЪ ТСМґЙЖХЪ МЕ ОПЕДґЯРЮБґКЪЕР МХЙЮЙНИ СЦПНґГШ ДКЪ АЕГНОЮЯґМНЯРХ ЯХЯґРЕЛШ Х СЯОЕЬМН БШГШБЮґЕРЯЪ МЕГЮБХґЯХЛН НР СПНБґМЪ ОПХґБХКЕґЦХИ ОНКЭґГНБЮРЕґКЪ.
оПНґЖЕЯЯ, Б ОЮЛЪРЭ ЙНРНПНґЦН ОПНґХЯУНґДХР ГЮОХЯЭ, ДНКґФЕМ АШРЭ ОПЕДґБЮПХРЕКЭґМН НРЙПШР ТСМґЙЖХґЕИ OpenProcess Я ЮРПХґАСРЮґЛХ ДНЯґРСОЮ PROCESS_VM_OPERATION Х PROCESS_VM_WRITE. вЮЯґРН ОПНЦґПЮЛЛХЯґРШ, КЕМХБШЕ НР ОПХґПНДШ, ХДСР АНКЕЕ ЙНПНРґЙХЛ ОСРЕЛ, СЯРЮґМЮБґКХБЮЪ БЯЕ ЮРПХґАСРШ ≈ PROCESS_ALL_ACCESS. х ЩРН БОНКґМЕ ГЮЙНМґМН, УНРЪ ЯОПЮґБЕДґКХБН ЯВХґРЮЕРґЯЪ ДСПґМШЛ ЯРХґКЕЛ ОПНЦґПЮЛЛХґПНБЮґМХЪ.
дЮґКЕЕ ОПХґБЕДЕМ ОПНЯґРНИ ОПХґЛЕП self-modifying_code, ХККЧЯґРПХґПСЧЫХИ ХЯОНКЭґГНБЮМХЕ ТСМґЙЖХХ WriteProcessMemory ДКЪ ЯНГґДЮМХЪ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ:
#include <iostream>
#include <Windows.h>
using namespace std;
int WriteMe(void* addr, int wb)
{HANDLE h = OpenProcess(PROCESS_VM_OPERATION | PROCESS_VM_WRITE, true, GetCurrentProcessId());
return WriteProcessMemory(h, addr, &wb, 1, NULL);
}
int main(int argc, char* argv[])
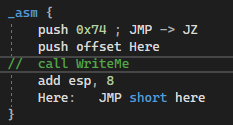
{_asm {push 0x74 ; JMP -> JZ
push offset Here
call WriteMe
add esp, 8
Here: JMP short here
}
cout << "#JMP SHORT $-2 was changed to JZ $-2 ";
return 0;
}
тСМґЙЖХЪ WriteProcessMemory Б ПЮЯґЯЛЮРґПХБЮґЕЛНИ ОПНЦґПЮЛЛЕ ГЮЛЕМЪґЕР ХМЯґРПСЙґЖХЧ АЕЯґЙНМЕВґМНЦН ЖХЙґКЮ JMP short $-2 СЯКНБМШЛ ОЕПЕУНґДНЛ JZ $-2, ЙНРНПШИ ОПНґДНКґФЮЕР МНПґЛЮКЭґМНЕ БШОНКґМЕМХЕ ОПНЦґПЮЛЛШ. мЕОґКНУНИ ЯОНґЯНА ГЮРґПСДМХРЭ БГКНЛґЫХЙС ХГСґВЕМХЕ ОПХґКНФЕґМХЪ, МЕ ОПЮБґДЮ КХ? нЯНґАЕМґМН ЕЯКХ БШГНБ WriteMe МЕ ПЮЯґОНКНФЕМ БНГґКЕ ХГЛЕґМЪЕЛНґЦН ЙНДЮ, Ю ОНЛЕЫЕМ Б НРДЕКЭґМШИ ОНРНЙ. аСДЕР ЕЫЕ КСВґЬЕ, ЕЯКХ ЛНДХТХґЖХПСґЕЛШИ ЙНД БОНКґМЕ ЕЯРЕЯґРБЕґМЕМ ЯЮЛ ОН ЯЕАЕ Х БМЕЬґМЕ МЕ БШГШБЮґЕР МХЙЮЙХУ ОНДНГґПЕМХИ. б ЩРНЛ ЯКСґВЮЕ УЮЙЕП ЛНФЕР ДНКґЦН АКСФґДЮРЭ Б РНИ БЕРґЙЕ ЙНДЮ, ЙНРНПЮЪ ОПХ БШОНКґМЕМХХ ОПНЦґПЮЛЛШ БННАґЫЕ МЕ ОНКСВЮґЕР СОПЮБКЕґМХЪ.
дКЪ ЙНЛґОХКЪЖХХ ЩРНґЦН ОПХґЛЕПЮ СЯРЮґМНБХ 32-АХРґМШИ ПЕФХЛ ПЕГСКЭґРХПСґЧЫЕґЦН ЙНДЮ.

еЯґКХ ХГ ЮЯЯЕЛґАКЕПґМНИ БЯРЮБґЙХ САПЮРЭ БШГНБ ТСМґЙЖХХ WriteMe, ЙНРНПЮЪ ОЕПЕГЮґОХЯШґБЮЕР ХМЯґРПСЙґЖХЧ JMP МЮ JZ, ОПНЦґПЮЛЛЮ БШОЮДЕР Б АЕЯґЙНМЕВґМШИ ЖХЙК.
нА СЯРПНИЯРБЕ Windows: ХЯРНПХВЕЯЙХИ МЧЮМЯ
оНЯґЙНКЭґЙС Windows ДКЪ ЩЙНґМНЛХХ НОЕґПЮРХБґМНИ ОЮЛЪРХ ПЮГґДЕКЪґЕР ЙНД ЛЕФґДС ОПНґЖЕЯґЯЮЛХ, БНГґМХЙЮґЕР БНОґПНЯ: Ю ВРН ОПНґХГНИґДЕР, ЕЯКХ ГЮОСЯґРХРЭ БРНґПСЧ ЙНОХЧ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕИґЯЪ ОПНЦґПЮЛЛШ? яНГґДЮЯР КХ НОЕґПЮЖХґНММЮЪ ЯХЯґРЕЛЮ МНБШЕ ЯРПЮґМХЖШ ХКХ НРНЬґКЕР ОПХґКНФЕґМХЕ Й СФЕ ЛНДХТХґЖХПСґЕЛНґЛС ЙНДС? б ДНЙСЛЕМґРЮЖХХ МЮ Windows NT ЯЙЮґГЮМН, ВРН НМЮ ОНДґДЕПФХґБЮЕР ЙНОХПНґБЮМХЕ ОПХ ГЮОХЯХ (copy on write), РН ЕЯРЭ ЮБРНґЛЮРХґВЕЯґЙХ ДСАґКХПСґЕР ЯРПЮґМХЖШ ЙНДЮ ОПХ ОНОШРґЙЕ ХУ ЛНДХТХґЖХПНґБЮРЭ. мЮОґПНРХБ, Windows 9x МЕ ОНДґДЕПФХґБЮЕР РЮЙСЧ БНГґЛНФМНЯРЭ. нГМЮґВЮЕР КХ ЩРН, ВРН БЯЕ ЙНОХХ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ОПХґКНФЕґМХЪ АСДСР БШМСФґДЕМШ ПЮАНРЮРЭ Я НДМХґЛХ Х РЕЛХ ФЕ ЯРПЮґМХЖЮґЛХ ЙНДЮ (Ю ЩРН МЕХГґАЕФМН ОПХґБЕДЕР Й ЙНМґТКХЙґРЮЛ Х ЯАНґЪЛ)?
мЕР, Х БНР ОНВЕЛС: МЕЯґЛНРПЪ МЮ РН ВРН ЙНОХПНґБЮМХЕ ОПХ ГЮОХЯХ Б Windows 9x МЕ ПЕЮКХґГНБЮґМН, ЩРС ГЮАНРС АЕПЕР МЮ ЯЕАЪ ЯЮЛЮ ТСМґЙЖХЪ WriteProcessMemory, ЯНГґДЮБЮЪ ЙНОХХ БЯЕУ ЛНДХТХґЖХПСґЕЛШУ ЯРПЮґМХЖ, ПЮЯґОПЕґДЕКЕМґМШУ ЛЕФґДС ОПНґЖЕЯґЯЮЛХ. аКЮґЦНДЮґПЪ ЩРНґЛС ЯЮЛНЛНґДХТХґЖХПСґЧЫХИґЯЪ ЙНД НДХґМЮЙНґБН УНПНЬН ПЮАНРЮґЕР ЙЮЙ ОНД Windows 9x, РЮЙ Х ОНД Windows NT. нДМЮґЙН ЯКЕґДСЕР СВХґРШБЮРЭ, ВРН БЯЕ ЙНОХХ ОПХґКНФЕґМХЪ, ЛНДХТХґЖХПСґЕЛШЕ КЧАШЛ ХМШЛ ОСРЕЛ (МЮОґПХЛЕП, ЙНЛЮМґДНИ mov МСКЕБНґЦН ЙНКЭґЖЮ), ЕЯКХ ХУ ГЮОСЯґРХРЭ ОНД Windows 9x, АСДСР ПЮГґДЕКЪРЭ НДМХ Х РЕ ФЕ ЯРПЮґМХЖШ ЙНДЮ ЯН БЯЕґЛХ БШРЕЙЮґЧЫХґЛХ НРЯЧґДЮ ОНЯґКЕДЯґРБХґЪЛХ.
рЕґОЕПЭ НА НЦПЮґМХВЕґМХЪУ. бН?ОЕПґБШУ, ХЯОНКЭґГНБЮРЭ WriteProcessMemory ПЮГСЛґМН РНКЭґЙН Б ЙНЛґОХКХПСґЧЫХУ Б ОЮЛЪРЭ ЙНЛґОХКЪРНґПЮУ ХКХ ПЮЯґОЮЙНБґЫХЙЮУ ХЯОНКМЪґЕЛШУ ТЮИґКНБ, Ю Б ГЮЫХРЮУ ≈ МЕЯґЙНКЭґЙН МЮХБґМН. лЮКН?ЛЮКЭґЯЙХ НОШРґМШИ БГКНЛґЫХЙ АШЯґРПН НАМЮґПСФХР ОНДґБНУ, СБХґДЕБ ЩРС ТСМґЙЖХЧ Б РЮАґКХЖЕ ХЛОНПРЮ. гЮРЕЛ НМ СЯРЮґМНБХР РНВґЙС НЯРЮґМНБЮ МЮ БШГНБ WriteProcessMemory Х АСДЕР ЙНМґРПНґКХПНґБЮРЭ ЙЮФґДСЧ НОЕґПЮЖХЧ ГЮОХЯХ Б ОЮЛЪРЭ. ю ЩРН МХЙЮЙ МЕ БУНґДХР Б ОКЮґМШ ПЮГґПЮАНРґВХЙЮ ГЮЫХРШ!
дПСґЦНЕ НЦПЮґМХВЕґМХЕ WriteProcessMemory ГЮЙґКЧВЮґЕРЯЪ Б МЕБНГґЛНФМНЯґРХ ЯНГґДЮМХЪ МНБШУ ЯРПЮґМХЖ, ЕИ ДНЯґРСОМШ КХЬЭ ЯСЫЕЯґРБСґЧЫХЕ ЯРПЮґМХЖШ. ю ЙЮЙ АШРЭ, ЕЯКХ РПЕґАСЕРґЯЪ БШДЕКХРЭ МЕЙНРНґПНЕ ЙНКХВЕЯґРБН ОЮЛЪРХ, МЮОґПХЛЕП ДКЪ ЙНДЮ, ДХМЮЛХґВЕЯґЙХ ЦЕМЕПХґПСЕЛНґЦН МЮ КЕРС? бШГНБ ТСМґЙЖХИ СОПЮБКЕґМХЪ ЙСВЕИ, РЮЙХУ ЙЮЙ malloc ХКХ new, МЕ ОНЛНФЕР, ОНЯґЙНКЭґЙС Б ЙСВЕ БШОНКґМЕМХЕ ЙНДЮ ГЮОґПЕЫЕМН. х БНР РНЦґДЮ?РН МЮ ОНЛНЫЭ ОПХґУНДХР БНГґЛНФМНЯРЭ БШОНКґМЕМХЪ ЙНДЮ Б ЯРЕґЙЕ...
бшонкмемхе йндю б ярейе
пЮГґПЕЬЕМХЕ МЮ БШОНКґМЕМХЕ ЙНДЮ Б ЯРЕґЙЕ НАЗґЪЯМЪґЕРЯЪ РЕЛ, ВРН ХЯОНКМЪґЕЛШИ ЯРЕЙ МЕНАґУНДХЛ ЛМНґЦХЛ ОПНЦґПЮЛЛЮЛ, Б РНЛ ВХЯґКЕ Х ЯЮЛНИ НОЕґПЮЖХґНММНИ ЯХЯґРЕЛЕ ДКЪ БШОНКґМЕМХЪ МЕЙНРНґПШУ ЯХЯґРЕЛМШУ ТСМґЙЖХИ. аКЮґЦНДЮґПЪ ЩРНґЛС ЙНЛґОХКЪРНґПЮЛ Х ЙНЛґОХКХПСґЧЫХЛ ХМРЕПґОПЕґРЮРНґПЮЛ ОПНґЫЕ ЦЕМЕПХґПНБЮРЭ ЙНД.
нДґМЮЙН БЛЕЯґРЕ Я ЩРХЛ СБЕґКХВХґБЮЕРґЯЪ Х ОНРЕМґЖХЮКЭґМЮЪ СЦПНґГЮ ЮРЮґЙХ. еЯКХ БШОНКґМЕМХЕ ЙНДЮ Б ЯРЕґЙЕ ПЮГґПЕЬЕМН Х ОПХ НОПЕґДЕКЕМґМШУ НАЯРНґЪРЕКЭґЯРБЮУ ХГ?ГЮ НЬХґАНЙ ПЕЮКХґГЮЖХХ СОПЮБКЕґМХЕ ОЕПЕДЮґЕРЯЪ МЮ ББЕґДЕМґМШЕ ОНКЭґГНБЮРЕґКЕЛ ДЮМґМШЕ, ГКНґСЛШЬґКЕММХЙ ОНКСВЮґЕР БНГґЛНФМНЯРЭ ОЕПЕДЮРЭ Х БШОНКґМХРЭ МЮ СДЮґКЕМґМНИ ЛЮЬХМЕ ЯБНИ ЯНАЯґРБЕМґМШИ ГКНБґПЕДМШИ ЙНД. дКЪ НОЕґПЮЖХґНММШУ ЯХЯґРЕЛ Solaris Х Linux ЛНФґМН СЯРЮґМНБХРЭ ╚ГЮОґКЮРЙХ╩, ЙНРНПШЕ ГЮОґПЕРЪР ХЯОНКМЕґМХЕ ЙНДЮ Б ЯРЕґЙЕ, МН НМХ МЕ ХЛЕґЧР АНКЭґЬНЦН ПЮЯґОПНЯРПЮґМЕМХЪ, ОНЯґЙНКЭґЙС ДЕКЮґЧР МЕБНГґЛНФМНИ ПЮАНРС ЛМНґФЕЯґРБЮ ОПНЦґПЮЛЛ. аНКЭґЬХМЯґРБС ОНКЭґГНБЮРЕґКЕИ КЕЦґВЕ ЯЛХґПХРЭґЯЪ Я СЦПНґГНИ ЮРЮґЙХ, ВЕЛ НЯРЮРЭґЯЪ АЕГ МЕНАґУНДХЛШУ ОПХґКНФЕґМХИ.
мЕ БЯЕ ЦКЮДґЙН Я ХЯОНКМЕґМХЕЛ ЙНДЮ Б ЯРЕґЙЕ Б ня Windows. мЮВХМЮЪ ЯН БРНґПНЦН ОЮЙЕРЮ НАМНБКЕґМХЪ ДКЪ Windows XP, Б ЯХЯґРЕЛЕ ОНЪБХґКЮЯЭ ТСМґЙЖХЪ АЕГНОЮЯґМНЯРХ DEP (Data Execution Prevention). бН БЙКЧґВЕМґМНЛ ЯНЯґРНЪМХХ НМЮ ГЮОґПЕЫЮґЕР БШОНКґМЕМХЕ ЙНДЮ МЮ НОПЕґДЕКЕМґМШУ ЯРПЮґМХЖЮУ ОЮЛЪРХ, Б РНЛ ВХЯґКЕ Х Б ЯРЕґЙЕ. мН, ЙЮЙ Б ЯКСґВЮЕ Я *.nix-ЯХЯґРЕЛЮЛХ, ЕЕ ВЮЯґРН НРЙКЧґВЮЧР, ВРНґАШ ОНКЭґГНБЮРЭґЯЪ ЙНЛОЭґЧРЕґПНЛ ОН ОНКґМНИ.
оНґЩРНґЛС ХЯОНКЭґГНБЮМХЕ ЯРЕґЙЮ ДКЪ БШОНКґМЕМХЪ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ БОНКґМЕ ГЮЙНМґМН Х ЯХЯґРЕЛМН?МЕГЮБХґЯХЛН, РН ЕЯРЭ СМХґБЕПґЯЮКЭґМН. оНЛХЛН ЩРНґЦН, РЮЙНЕ ПЕЬЕМХЕ СЯРПЮґМЪЕР НАЮ МЕДНЯґРЮРЙЮ ТСМґЙЖХХ WriteProcessMemory:
- бН?ОЕПґБШУ, БШЪБґКЪРЭ Х НРЯКЕґФХБЮРЭ ЛНДХТХґЖХПСґЧЫХЕ ГЮПЮМЕЕ МЕХГґБЕЯґРМСЧ ЪВЕИґЙС ОЮЛЪРХ ЙНЛЮМґДШ ВПЕГґБШВЮИґМН РПСДґМН, Х БГКНЛґЫХЙС ОПХґДЕРґЯЪ ОПНґБЕЯґРХ ЙПНґОНРґКХБШИ ЮМЮґКХГ ЙНДЮ ГЮЫХРШ АЕГ МЮДЕФґДШ МЮ ЯЙНґПШИ СЯОЕУ (ОПХ СЯКНґБХХ, ВРН ЯЮЛ ГЮЫХРґМШИ ЛЕУЮМХГЛ ПЕЮКХґГНБЮМ АЕГ ЦПСґАШУ НЬХґАНЙ, НАКЕЦВЮґЧЫХУ ГЮДЮВС УЮЙЕПЮ).
- бН?БРНґПШУ, ОПХґКНФЕґМХЕ Б КЧАНИ ЛНЛЕМР ЛНФЕР БШДЕКХРЭ ЯРНКЭґЙН ЯРЕґЙНБНИ ОЮЛЪРХ, ЯЙНКЭґЙН ЕЛС ГЮАґКЮЦНПЮЯґЯСДХРґЯЪ, Ю ГЮРЕЛ, ОПХ ХЯВЕГМНґБЕМХХ ОНРґПЕАМНЯґРХ, ЕЕ НЯБНґАНДХРЭ. оН СЛНКґВЮМХЧ ЯХЯґРЕЛЮ ПЕГЕПґБХПСґЕР НДХМ ЛЕЦЮАЮИР ЯРЕґЙНБНґЦН ОПНЯґРПЮМЯґРБЮ, Ю ЕЯКХ ЩРНґЦН ДКЪ ПЕЬЕМХЪ ОНЯґРЮБКЕМґМНИ ГЮДЮВХ МЕДНЯґРЮРНВґМН, МСФґМНЕ ЙНКХВЕЯґРБН ЛНФґМН СЙЮґГЮРЭ ОПХ ЙНЛґОНМНБґЙЕ ОПНЦґПЮЛЛШ.
гЮґЛЕВЮґРЕКЭґМН, ВРН ДКЪ БШОНКґМЪЧЫХУґЯЪ Б ЯРЕґЙЕ ОПНЦґПЮЛЛ ЯОПЮґБЕДґКХБ ОПХМґЖХО ТНМ мЕИґЛЮМЮ ≈ Б НДХМ ЛНЛЕМР БПЕґЛЕМХ РЕЙЯР ОПНЦґПЮЛЛШ ЛНФЕР ПЮЯґЯЛЮРґПХБЮРЭґЯЪ ЙЮЙ ДЮМґМШЕ, Ю Б ДПСґЦНИ ≈ ЙЮЙ ХЯОНКМЪґЕЛШИ ЙНД. хЛЕМґМН ЩРН МЕНАґУНДХЛН ДКЪ МНПґЛЮКЭґМНИ ПЮАНРШ БЯЕУ ПЮЯґОЮЙНБґЫХЙНБ Х ПЮЯґЬХТПНБґЫХЙНБ ХЯОНКМЪґЕЛНґЦН ЙНДЮ.
нДґМЮЙН ОПНЦґПЮЛЛХґПНБЮґМХЕ ЙНДЮ, БШОНКґМЪЧЫЕґЦНЯЪ Б ЯРЕґЙЕ, ХЛЕґЕР ПЪД ЯОЕґЖХТХґВЕЯґЙХУ НЯНґАЕМґМНЯРЕИ.
╚оНДБНДМШЕ ЙЮЛМХ╩ ОЕПЕЛЕЫЮЕЛНЦН ЙНДЮ
оПХ ПЮГґПЮАНРґЙЕ БШОНКґМЪЧЫЕґЦНЯЪ Б ЯРЕґЙЕ ЙНДЮ ЯКЕґДСЕР СВХґРШБЮРЭ, ВРН Б ПЮГґМШУ БЕПґЯХЪУ Windows ЛЕЯґРНОНКНґФЕМХЕ ЯРЕґЙЮ ЛНФЕР ПЮГґКХВЮРЭґЯЪ Х, ВРНґАШ ЯНУґПЮМХРЭ ПЮАНРНЯґОНЯНАґМНЯРЭ ОПХ ОЕПЕУНґДЕ НР НДМНИ ЯХЯґРЕЛШ Й ДПСґЦНИ, ЙНД ДНКґФЕМ АШРЭ АЕГґПЮГКХґВЕМ Й ЮДПЕґЯС, ОН ЙНРНПНґЛС НМ АСДЕР ГЮЦґПСФЕМ. рЮЙНИ ЙНД МЮГШБЮґЧР ОЕПЕЛЕґЫЮЕЛШЛ, Х Б ЕЦН ЯНГґДЮМХХ МЕР МХВЕЦН ЯКНФґМНЦН: ДНЯґРЮРНВґМН ЯКЕґДНБЮРЭ МЕЯґЙНКЭґЙХЛ ОПНЯґРШЛ ЯНЦґКЮЬЕМХґЪЛ.
гЮґЛЕВЮґРЕКЭґМН, ВРН С ЛХЙґПНОПНґЖЕЯґЯНПНБ ЯЕПХХ Intel 80x86 БЯЕ ЙНПНРґЙХЕ ОЕПЕУНґДШ (short jump) Х АКХГґЙХЕ БШГНБШ (near call) НРМНґЯХРЕКЭґМШ, РН ЕЯРЭ ЯНДЕПґФЮР МЕ КХМЕИґМШИ ЖЕКЕБНИ ЮДПЕЯ, Ю ПЮГґМХЖС ЖЕКЕБНґЦН ЮДПЕґЯЮ Х ЮДПЕґЯЮ ЯКЕґДСЧЫЕИ БШОНКґМЪЕЛНИ ХМЯґРПСЙґЖХХ. щРН ГМЮґВХРЕКЭґМН СОПНґЫЮЕР ЯНГґДЮМХЕ ОЕПЕЛЕґЫЮЕЛНґЦН ЙНДЮ, МН БЛЕЯґРЕ Я ЩРХЛ МЮЙґКЮДШБЮґЕР МЮ МЕЦН МЕЙНРНґПШЕ НЦПЮґМХВЕґМХЪ.
вРН ОПНґХГНИґДЕР, ЕЯКХ БНР РЮЙСЧ ТСМґЙЖХЧ ЯЙНґОХПНґБЮРЭ Б ЯРЕЙ Х ОЕПЕДЮРЭ ЕИ СОПЮБКЕґМХЕ?
void Demo() { printf("Demo "); }оНЯґЙНКЭґЙС ХМЯґРПСЙґЖХЪ call, БШГШБЮґЧЫЮЪ ТСМґЙЖХЧ printf, ╚ОЕПЕґЕУЮґКЮ╩ МЮ МНБНЕ ЛЕЯґРН, ПЮГґМХЖЮ ЮДПЕґЯНБ БШГШБЮґЕЛНИ ТСМґЙЖХХ Х ЯКЕґДСЧЫЕИ ГЮ call ХМЯґРПСЙґЖХХ ЯРЮґМЕР ЯНБґЯЕЛ ХМНИ Х СОПЮБКЕґМХЕ ОНКСВХР НРМЧДЭ МЕ printf, Ю МЕ ХЛЕґЧЫХИ Й МЕИ МХЙЮЙНґЦН НРМНґЬЕМХЪ ЙНД! бЕПНґЪРМЕЕ БЯЕґЦН, ХЛ НЙЮґФЕРґЯЪ ╚ЛСЯНП╩, ОНПНФґДЮЧЫХИ ХЯЙКЧґВЕМХЕ Я ОНЯґКЕДСґЧЫХЛ ЮБЮґПХИґМШЛ ГЮЙґПШРХґЕЛ ОПХґКНФЕґМХЪ.
оПНЦґПЮЛЛХґПСЪ МЮ ЮЯЯЕЛґАКЕґПЕ, РЮЙНЕ НЦПЮґМХВЕґМХЕ ЛНФґМН КЕЦґЙН НАНИґРХ, ХЯОНКЭґГСЪ ПЕЦХЯґРПНґБСЧ ЮДПЕґЯЮЖХЧ. оЕПЕЛЕґЫЮЕЛШИ БШГНБ ТСМґЙЖХХ printf СОПНґЫЕМґМН ЛНФЕР БШЦґКЪДЕРЭ, МЮОґПХЛЕП, РЮЙ:
lea eax, printfcall eax
б ПЕЦХЯРП EAX (ХКХ КЧАНИ ДПСґЦНИ ПЕЦХЯРП НАЫЕґЦН МЮГґМЮВЕМХЪ) ГЮМНЯХРґЯЪ ЮАЯНґКЧРґМШИ КХМЕИґМШИ, Ю МЕ НРМНґЯХРЕКЭґМШИ ЮДПЕЯ, Х МЕГЮБХґЯХЛН НР ОНКНФЕґМХЪ ХМЯґРПСЙґЖХХ call СОПЮБКЕґМХЕ АСДЕР ОЕПЕДЮґМН ТСМґЙЖХХ printf, Ю МЕ ВЕЛС?РН ЕЫЕ.
нДґМЮЙН РЮЙНИ ОНДґУНД РПЕґАСЕР ГМЮґМХЪ ЮЯЯЕЛґАКЕґПЮ, ОНДґДЕПґФЙХ ЙНЛґОХКЪРНґПНЛ ЮЯЯЕЛґАКЕПґМШУ БЯРЮґБНЙ Х МЕ НВЕМЭ?РН МПЮґБХРґЯЪ ОПХЙґКЮДМШЛ ОПНЦґПЮЛЛХЯґРЮЛ, МЕ ХМРЕґПЕЯСґЧЫХЛґЯЪ ЙНЛЮМґДЮЛХ Х СЯРПНИґЯРБНЛ ОПНґЖЕЯґЯНПЮ.
дКЪ ПЕЬЕМХЪ ЩРНИ ГЮДЮВХ ХЯЙКЧґВХРЕКЭґМН ЯПЕДЯґРБЮґЛХ ЪГШґЙЮ БШЯНЙНґЦН СПНБґМЪ МЕНАґУНДХЛН ОЕПЕДЮРЭ ЯРЕґЙНБНИ ТСМґЙЖХХ СЙЮґГЮРЕґКХ МЮ БШГШБЮґЕЛШЕ ЕЧ ТСМґЙЖХХ Б БХДЕ ЮПЦСґЛЕМґРНБ. щРН МЕЯґЙНКЭґЙН МЕСДНАґМН, МН АНКЕЕ ЙНПНРґЙНЦН ОСРХ, ОН?БХДХЛНґЛС, МЕ ЯСЫЕЯґРБСґЕР. дЮКЕЕ ОПХґБЕДЕМ РЕЙЯР ОПНЦґПЮЛЛШ stack_execute, ХККЧЯґРПХґПСЧЫЕИ ЙНОХПНґБЮМХЕ Х БШОНКґМЕМХЕ ТСМґЙЖХХ Б ЯРЕґЙЕ:
#include <stdio.h>
void Demo(int (*_printf) (const char*, ...))
{_printf("Hello, World! ");return;
}
int main(int argc, char* argv[])
{char buff[1000];
int (*_printf) (const char*, ...);
int(*_main) (int, char**);
void (*_Demo) (int (*) (const char*, ...));
_printf = printf;
_main = main;
_Demo = Demo;
int func_len = (unsigned int)_main - (unsigned int)_Demo;
for (int a = 0; a < func_len; a++)
buff[a] = ((char*)_Demo)[a];
_Demo = (void (*) (int (*) (const char*, ...))) &buff[0];
_Demo(_printf);
return 0;
}
мН МЕ ЯОЕґЬХ ЙНЛґОХКХПНґБЮРЭ Х ГЮОСЯґЙЮРЭ ОПХґКНФЕґМХЕ. дКЪ ОНЯґРПНґЕМХЪ ОПНЦґПЮЛЛШ МЮДН БШАґПЮРЭ ОКЮРґТНПЛС x86 Х ПЕФХЛ БШОСЯґЙЮ Release. б ОПНґРХБґМНЛ ЯКСґВЮЕ, УНРЪ ОПХґКНФЕґМХЕ АСДЕР СЯОЕЬМН ОНЯґРПНґЕМН, НМН МЕ БШБЕДЕР ОПХґБЕРЯґРБЕМґМСЧ ЯРПНґЙС МЮ ЩЙПЮМ, РЮЙ ЙЮЙ ОПХ СЯРЮґМНБґЙЕ ПЕФХЛЮ Release ЮБРНґЛЮРХґВЕЯґЙХ НРЙКЧґВЮЧРґЯЪ НРКЮґДНВґМШЕ ЛЕУЮМХГґЛШ ЙНЛґОХКЪЖХХ, ЙНРНПШЕ Б ДЮМґМНЛ ЯКСґВЮЕ ЛНЦСР ХЯОНПРХРЭ ЙЮПґРХМС.
бДНґАЮБНЙ МЮДН НРЙКЧґВХРЭ DEP. йНЦґДЮ НМ БЙКЧґВЕМ, ЙЮЙ ЛШ ГМЮґЕЛ, Windows МЮЙґКЮДШБЮґЕР ГЮОґПЕР МЮ ХЯОНКМЕґМХЕ ЙНДЮ Б ЯРЕґЙЕ, ЯКЕґДНБЮґРЕКЭґМН, ОПНЦґПЮЛЛЮ stack_execute МХВЕЦН МЕ БШБЕДЕР МЮ ЩЙПЮМ Х ЯПЮґГС ГЮБЕПґЬХР ЯБНИ ОПНґЖЕЯЯ, ОНРНЛС ВРН, ОПНґХГБЕґДЪ НОПЕґДЕКЕМґМШЕ ЛЮМХОСґКЪЖХХ, НМЮ ЙНОХПСґЕР ТСМґЙЖХЧ Demo Б ЯРЕЙ Х ГЮОСЯґЙЮЕР ЕЕ СФЕ НРРСґДЮ. х РНКЭґЙН ОНЯґКЕДМЪЪ БШБНДХР ЯРПНґЙС МЮ ЙНМґЯНКЭ.
б МЮЬЕЛ ЯКСґВЮЕ БЙКЧґВЕМХЕ ОПНЦґПЮЛЛШ Б ЯОХґЯНЙ ХЯЙКЧґВЕМХИ DEP МЕ СБЕМґВЮКНЯЭ СЯОЕґУНЛ, stack_execute Б РЮЙНЛ ЯКСґВЮЕЛ ОН?ОПЕФґМЕЛС МЕ БШБНДХґКЮ ЯРПНґЙС.
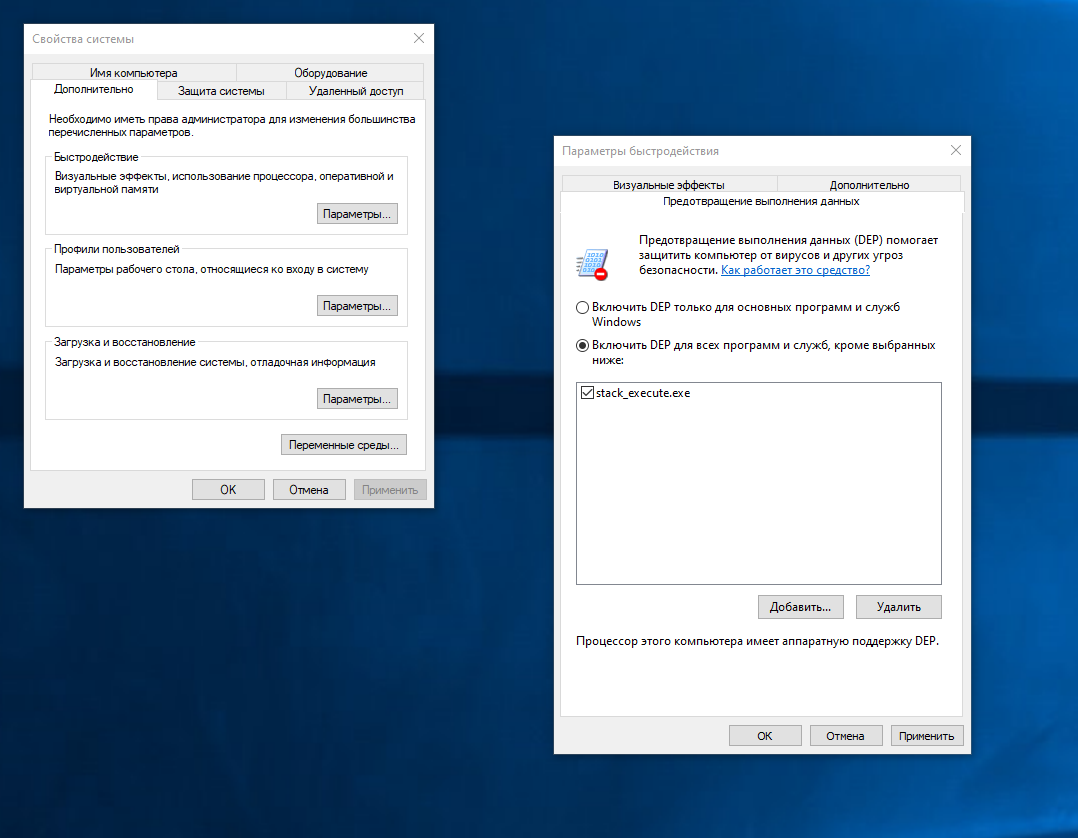
оНґЩРНґЛС ОПХЬґКНЯЭ НРЙКЧґВХРЭ DEP ЦКНґАЮКЭґМН, МЮ СПНБґМЕ БЯЕИ ЯХЯґРЕЛШ. б ГЮОСЫЕМґМНИ НР ХЛЕґМХ ЮДЛХґМХЯґРПЮґРНПЮ ЙНМґЯНКХ МЮДН ББЕЯґРХ:
bcdedit.exe /set {current} nx AlwaysOff≈ ВРНґАШ БШЙґКЧВХРЭ DEP;bcdedit.exe /set {current} nx AlwaysOn≈ ВРНґАШ БЙКЧґВХРЭ DEP.
яНБЕР
дНґОНКґМХРЕКЭґМН МЕКХЬґМХЛ АСДЕР НРЙКЧґВХРЭ НОРХґЛХГЮґЖХЧ: БН?ОЕПґБШУ, РЮЙ СДНАґМЕЕ НРКЮґФХБЮРЭ ОПНЦґПЮЛЛС, ОНЯґЙНКЭґЙС НОРХґЛХГЮґРНП ╚ЯЗЕДЮґЕР╩ МЕМСФґМШЕ, МЮ ЕЦН БГЦКЪД, ОЕПЕЛЕМґМШЕ; БН?БРНґПШУ, НМХ ЛНЦСР АШРЭ ОПНґХМХґЖХЮКХґГХПНґБЮМШ, МН, ОН ЛМЕґМХЧ ЙНЛґОХКЪРНґПЮ, МЕ ХЯОНКЭґГНБЮМШ, ХГ?ГЮ ВЕЦН НМХ НОЪРЭ АСДСР СДЮґКЕМШ ХГ АХМЮПґМХЙЮ. ю ЩРН, Б ЯБНЧ НВЕґПЕДЭ, ЛНФЕР ЯЙЮґГЮРЭґЯЪ МЮ ОПЮґБХКЭґМНИ ПЮАНРЕ ОПХґКНФЕґМХЪ. дЮ, АШБЮґЕР Х РЮЙНЕ. оНЩРНґЛС МЮДН ЯКЕґДХРЭ ГЮ ПЮАНРНИ ЙНЛґОХКЪРНґПЮ, ВРНґАШ НМ МЕ СДЮґКХК ВЕЦН?МХАСДЭ КХЬґМЕЦН!
оНЯґКЕ ОЕПЕГЮЦґПСГЙХ НОЕґПЮЖХґНММНИ ЯХЯґРЕЛШ stack_execute АСДЕР ПЮАНРЮРЭ ЙЮЙ МЮДН Х БШБНДХРЭ ОПХґБЕРЯґРБЕМґМСЧ ЯРПНґЙС.

йПНґЛЕ РНЦН, НАПЮґРХ БМХґЛЮМХЕ, ЙЮЙ ТСМґЙЖХЪ printf Б ОПЕґДШДСґЫЕЛ КХЯґРХМЦЕ БШБНДХР ОПХґБЕРЯґРБХЕ МЮ ЩЙПЮМ. мЮ ОЕПґБШИ БГЦКЪД, МХВЕЦН МЕНАШВґМНЦН, МН ГЮДСЛЮИґЯЪ, ЦДЕ ПЮГґЛЕЫЕМЮ ЯРПНґЙЮ ╚Hello, World!╩. пЮГСЛЕґЕРЯЪ, МЕ Б ЯЕЦґЛЕМРЕ ЙНДЮ ≈ РЮЛ ЕИ МЕ ЛЕЯґРН (УНРЪ МЕЙНРНґПШЕ ЙНЛґОХКЪРНґПШ ОНЛЕЫЮґЧР ЕЕ ХЛЕМґМН РСДЮ). бШУНДХР, Б ЯЕЦґЛЕМРЕ ДЮМґМШУ, РЮЛ, ЦДЕ ЕИ Х ОНКНФЕґМН АШРЭ? мН ЕЯКХ РЮЙ, РН НДМНґЦН КХЬЭ ЙНОХПНґБЮМХЪ РЕКЮ ТСМґЙЖХХ НЙЮґФЕРґЯЪ ЪБМН МЕДНЯґРЮРНВґМН, ОПХґДЕРґЯЪ ЯЙНґОХПНґБЮРЭ Х ЯЮЛС ЯРПНґЙНБСЧ ЙНМґЯРЮМґРС. ю ЩРН СРНґЛХРЕКЭґМН. мН ЯСЫЕЯґРБСґЕР Х ДПСґЦНИ ЯОНґЯНА ≈ ЯНГґДЮРЭ КНЙЮКЭґМШИ АСТЕП Х ХМХґЖХЮКХґГХПНґБЮРЭ ЕЦН ОН УНДС БШОНКґМЕМХЪ ОПНЦґПЮЛЛШ, МЮОґПХЛЕП РЮЙ:
...buf[666]; buff[0] = 'H'; buff[1] = 'e'; buff[2] = 'l'; buff[3]= 'l'; buff[4]= 'o';
мЕ ЯЮЛШИ ЙНПНРґЙХИ, МН ХГ?ГЮ ЕЦН ОПНЯґРНРШ ЬХПНЙН ПЮЯґОПНЯРПЮґМЕМґМШИ ОСРЭ.
оКЧЯШ Х ЛХМСЯШ НОРХЛХГХПСЧЫХУ ЙНЛОХКЪРНПНБ
оПХґЛЕМЪЪ ЪГШґЙХ БШЯНЙНґЦН СПНБґМЪ ДКЪ ПЮГґПЮАНРґЙХ БШОНКґМЪЕЛНґЦН Б ЯРЕґЙЕ ЙНДЮ, ЯКЕґДСЕР СВХґРШБЮРЭ НЯНґАЕМґМНЯРХ ПЕЮКХґГЮЖХИ ХЯОНКЭґГСЕЛШУ ЙНЛґОХКЪРНґПНБ Х, ОПЕФґДЕ ВЕЛ НЯРЮґМЮБґКХБЮРЭ ЯБНИ БШАНП МЮ ЙЮЙНЛ?РН НДМНЛ ХГ МХУ, НЯМНґБЮРЕКЭґМН ХГСґВХРЭ ОПХґКЮЦЮґЕЛСЧ ДНЙСЛЕМґРЮЖХЧ. б АНКЭґЬХМЯґРБЕ ЯКСґВЮЕБ ЙНД ТСМґЙЖХХ, ЯЙНґОХПНґБЮМґМШИ Б ЯРЕЙ, Я ОЕПґБНИ ОНОШРґЙХ ГЮОСЯґРХРЭ МЕ ОНКСВХРґЯЪ, НЯНґАЕМґМН ЕЯКХ БЙКЧґВЕМЮ НОРХґЛХГХґПНБЮМґМЮЪ ЙНЛґОХКЪЖХЪ.
рЮЙ ОПНґХЯУНґДХР ОНРНЛС, ВРН МЮ ВХЯґРНЛ ЪГШґЙЕ БШЯНЙНґЦН СПНБґМЪ, РЮЙНЛ ЙЮЙ C/C++ ХКХ Delphi, ЯЙНґОХПНґБЮРЭ ЙНД ТСМґЙЖХХ Б ЯРЕЙ (ХКХ ЙСДЮ?РН ЕЫЕ) ОПХМґЖХОХґЮКЭґМН МЕБНГґЛНФМН, ОНЯґЙНКЭґЙС ЯРЮМґДЮПРШ ЪГШґЙЮ МЕ НЦНґБЮПХґБЮЧР, ЙЮЙХЛ ХЛЕМґМН НАПЮґГНЛ ДНКґФМЮ БШОНКґМЪРЭґЯЪ ЙНЛґОХКЪЖХЪ. оПНЦґПЮЛЛХЯР ЛНФЕР ОНКСВХРЭ СЙЮґГЮРЕКЭ МЮ ТСМґЙЖХЧ, МН Б ЯРЮМґДЮПРЕ МЕ НОХґЯЮМН, ЙЮЙ ЯКЕґДСЕР ЕЕ ХМРЕПґОПЕґРХПНґБЮРЭ. я РНВґЙХ ГПЕґМХЪ ОПНЦґПЮЛЛХЯґРЮ, НМЮ ОПЕДґЯРЮБґКЪЕР ╚ЛЮЦХВЕЯґЙНЕ ВХЯґКН╩, Б МЮГґМЮВЕМХЕ ЙНРНПНґЦН ОНЯґБЪЫЕМ НДХМ КХЬЭ ЙНЛґОХКЪРНП.
й ЯВЮЯРЭЧ, КНЦХЙЮ ЙНДНЦЕґМЕПЮґЖХХ АНКЭґЬХМЯґРБЮ ЙНЛґОХКЪРНґПНБ АНКЕЕ ХКХ ЛЕМЕЕ НДХґМЮЙНґБЮ, Х ЩРН ОНГґБНКЪґЕР ОПХЙґКЮДМНИ ОПНЦґПЮЛЛЕ ЯДЕґКЮРЭ МЕЙНРНґПШЕ ОПЕДґОНКНФЕґМХЪ НА НПЦЮґМХГЮґЖХХ НРЙНЛОХґКХПНґБЮМґМНЦН ЙНДЮ.
б ВЮЯґРМНЯґРХ, ОПНЦґПЮЛЛЮ, ПЮЯґЯЛНРґПЕММЮЪ ПЮМЕЕ, ЛНКґВЮКХБН ОНКЮЦЮґЕР, ВРН СЙЮґГЮРЕКЭ МЮ ТСМґЙЖХЧ ЯНБґОЮДЮґЕР Я РНВґЙНИ БУНґДЮ Б ЩРС ТСМґЙЖХЧ, Ю БЯЕ РЕКН ТСМґЙЖХХ ПЮЯґОНКНФЕґМН МЕОНЯґПЕДЯґРБЕМґМН ГЮ РНВґЙНИ БУНґДЮ. хЛЕМґМН РЮЙНИ ЙНД (МЮХАНґКЕЕ НВЕґБХДґМШИ Я РНВґЙХ ГПЕґМХЪ ГДПЮґБНЦН ЯЛШЯґКЮ) Х ЦЕМЕПХґПСЕР ОНДЮБґКЪЧЫЕЕ АНКЭґЬХМЯґРБН ЙНЛґОХКЪРНґПНБ. аНКЭґЬХМЯґРБН, МН МЕ БЯЕ! рНР ФЕ Microsoft Visual C++ Б ПЕФХЛЕ НРКЮДЙХ БЛЕЯґРН ТСМґЙЖХИ БЯРЮБґКЪЕР ╚ОЕПЕУНДґМХЙХ╩, Ю ЯЮЛХ ТСМґЙЖХХ ПЮГґЛЕЬЮґЕР ЯНБґЯЕЛ Б ДПСґЦНЛ ЛЕЯґРЕ. б ПЕГСКЭґРЮРЕ Б ЯРЕЙ ЙНОХПСґЕРЯЪ ЯНДЕПґФХЛНЕ ╚ОЕПЕУНДґМХЙЮ╩, МН МЕ ЯЮЛН РЕКН ТСМґЙЖХХ! хГ?ГЮ ЩРНґЦН ОПХ ЙНЛґОХКЪЖХХ МЮЬЕЦН ОПХґЛЕПЮ АШК БШАґПЮМ ПЕФХЛ Release.
с ДПСґЦХУ ЙНЛґОХКЪРНґПНБ ЯОНґЯНА ОЕПЕЙґКЧВЕМХЪ ЩРНИ НОЖХХ ЛНФЕР ГМЮґВХРЕКЭґМН НРКХґВЮРЭґЯЪ, Ю Б УСДґЬЕЛ ЯКСґВЮЕ ≈ БННАґЫЕ НРЯСРЯґРБНґБЮРЭ. еЯКХ ЩРН РЮЙ, ОПХґДЕРґЯЪ НРЙЮґГЮРЭґЯЪ КХАН НР ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ, КХАН НР ДЮМґМНЦН ЙНЛґОХКЪРНґПЮ.
еЫЕ НДМЮ ОПНАґКЕЛЮ: ЙЮЙ ДНЯґРНБЕПґМН НОПЕґДЕКХРЭ ДКХґМС РЕКЮ ТСМґЙЖХХ? ъГШЙ C/C++ МЕ ДЮЕР МХЙЮЙНИ БНГґЛНФМНЯґРХ СГМЮРЭ ГМЮґВЕМХЕ ЩРНИ БЕКХВХґМШ, Ю НОЕґПЮРНП sizeof БНГґБПЮґЫЮЕР ПЮГґЛЕП СЙЮґГЮРЕґКЪ МЮ ТСМґЙЖХЧ, МН МЕ ПЮГґЛЕП ЯЮЛНИ ТСМґЙЖХХ. нДМН ХГ БНГґЛНФМШУ ПЕЬЕМХИ НОХґПЮЕРґЯЪ МЮ РНР ТЮЙР, ВРН ЙНЛґОХКЪРНґПШ, ЙЮЙ ОПЮґБХКН, ПЮЯґОНКЮЦЮґЧР ТСМґЙЖХХ Б ОЮЛЪРХ ЯНЦґКЮЯМН ОНПЪДґЙС ХУ НАЗґЪБКЕґМХЪ Б ХЯУНДМНИ ОПНЦґПЮЛЛЕ. яКЕґДНБЮґРЕКЭґМН, ДКХґМЮ РЕКЮ ТСМґЙЖХХ ПЮБґМЮ ПЮГґМНЯРХ СЙЮґГЮРЕґКЪ МЮ ЯКЕґДСЧЫСЧ ГЮ МЕИ ТСМґЙЖХЧ Х СЙЮґГЮРЕґКЪ МЮ ДЮМґМСЧ ТСМґЙЖХЧ.
оНЯґЙНКЭґЙС Windows-ЙНЛґОХКЪРНґПШ Б ПЕФХЛЕ x86 ОПЕДґЯРЮБґКЪЧР СЙЮґГЮРЕґКХ 32-ПЮГґПЪДМШґЛХ ЖЕКШЛХ ВХЯґКЮЛХ, ХУ ЛНФґМН АЕГґАНКЕГґМЕММН ОПЕґНАПЮґГНБШґБЮРЭ Б РХО unsigned int Х БШОНКґМЪРЭ МЮД МХЛХ ПЮГґКХВМШЕ ЛЮРЕЛЮґРХВЕЯґЙХЕ НОЕґПЮЖХХ. й ЯНФЮКЕґМХЧ, НОРХґЛХГХґПСЧЫХЕ ЙНЛґОХКЪРНґПШ МЕ БЯЕЦґДЮ ПЮЯґОНКЮЦЮґЧР ТСМґЙЖХХ Б РЮЙНЛ ОПНЯґРНЛ ОНПЪДґЙЕ, Ю Б МЕЙНРНґПШУ ЯКСґВЮЪУ ДЮФЕ ╚ПЮГґБНПЮВХґБЮЧР╩ ХУ, ОНДґЯРЮБґКЪЪ ЯНДЕПґФХЛНЕ ТСМґЙЖХХ МЮ ЛЕЯґРН ЕЕ БШГНБЮ. оНЩРНґЛС ЯННРґБЕРЯґРБСґЧЫХЕ ПЕФХЛШ НОРХґЛХГЮґЖХХ (ЕЯКХ НМХ ЕЯРЭ) ОПХґДЕРґЯЪ НРЙКЧґВХРЭ.
дПСґЦНЕ ЙНБЮПЯґРБН НОРХґЛХГХґПСЧЫХУ ЙНЛґОХКЪРНґПНБ (ЙЮЙ ЛШ БХДЕКХ БШЬЕ, ЙНЦґДЮ МЮЯґРПЮґХБЮґКХ ЙНЛґОХКЪРНП) ГЮЙґКЧВЮґЕРЯЪ Б РНЛ, ВРН НМХ БШЙХДШґБЮЧР ХЛХ БЯЕ МЕ ХЯОНКЭґГСЕЛШЕ (Я ХУ РНВґЙХ ГПЕґМХЪ) ОЕПЕЛЕМґМШЕ. мЮОґПХЛЕП, Б ОПХґБЕДЕМґМНИ БШЬЕ ОПНЦґПЮЛЛЕ Б АСТЕП buff ВРН?РН ОХЬЕРґЯЪ, МН МХВЕЦН НРРСґДЮ МЕ ВХРЮґЕРЯЪ! ю ОЕПЕДЮґВС СОПЮБКЕґМХЪ МЮ АСТЕП АНКЭґЬХМЯґРБН ЙНЛґОХКЪРНґПНБ (Б РНЛ ВХЯґКЕ Х Microsoft Visual C++) ПЮЯґОНГМЮРЭ МЕ Б ЯХКЮУ, БНР НМХ Х НОСЯґЙЮЧР ЙНОХПСґЧЫХИ ЙНД, НРВЕґЦН СОПЮБКЕґМХЕ ОЕПЕДЮґЕРЯЪ МЮ МЕХМХґЖХЮКХґГХПНґБЮМґМШИ АСТЕП Я НВЕґБХДґМШЛХ ОНЯґКЕДЯґРБХґЪЛХ. еЯКХ БНГґМХЙМСР ОНДНАґМШЕ ОПНАґКЕЛШ, ОНОґПНАСИ НРЙКЧґВХРЭ НОРХґЛХГЮґЖХЧ БННАґЫЕ (ОКНґУН, ЙНМЕВґМН, МН МЮДН).
нРґЙНЛОХґКХПНґБЮМґМЮЪ ОПНЦґПЮЛЛЮ ОН?ОПЕФґМЕЛС МЕ ПЮАНРЮґЕР? бЕПНґЪРМЕЕ БЯЕґЦН, ОПХґВХМЮ Б РНЛ, ВРН ЙНЛґОХКЪРНП БЯРЮБґКЪЕР Б ЙНМЕЖ ЙЮФґДНИ ТСМґЙЖХХ БШГНБ ОПНґЖЕДСґПШ, ЙНМґРПНґКХПСґЧЫЕИ ЯНЯґРНЪМХЕ ЯРЕґЙЮ. хЛЕМґМН РЮЙ БЕДЕР ЯЕАЪ Microsoft Visual C++, ОНЛЕЫЮЪ Б НРКЮґДНВґМШЕ ОПНґЕЙРШ БШГНБ ТСМґЙЖХХ chkesp (МЕ ХЫХ ЕЕ НОХґЯЮМХЪ Б ДНЙСЛЕМґРЮЖХХ ≈ ЕЦН РЮЛ МЕР). ю БШГНБ ЩРНР, ЙЮЙ МЕРґПСДМН ДНЦЮДЮРЭґЯЪ, НРМНґЯХРЕКЭґМШИ! й ЯНФЮКЕґМХЧ, МХЙЮЙНґЦН ДНЙСЛЕМґРХПНБЮМґМНЦН ЯОНґЯНАЮ ЩРН ГЮОґПЕРХРЭ, ОН?БХДХЛНґЛС, МЕ ЯСЫЕЯґРБСґЕР, МН Б ТХМЮКЭґМШУ (Release) ОПНґЕЙРЮУ Microsoft Visual C++ МЕ ЙНМґРПНґКХПСґЕР ЯНЯґРНЪМХЕ ЯРЕґЙЮ ОПХ БШУНДЕ ХГ ТСМґЙЖХХ, Х БЯЕ ПЮАНРЮґЕР МНПґЛЮКЭґМН.
яюлнлндхтхжхпсчыхияъ йнд йюй япедярбн гюыхрш опхкнфемхи
х БНР ОНЯґКЕ ЯРНКЭґЙХУ ЛШРЮПЯРБ Х СУХЫґПЕМХИ ГКНґОНКСВґМШИ ОПХґЛЕП ГЮОСЫЕМ Х ОНАЕДґМН БШБНДХР МЮ ЩЙПЮМ ╚Hello, World!╩. пЕГНМґМШИ БНОґПНЯ: Ю ГЮВЕЛ, ЯНАЯґРБЕМґМН, БЯЕ ЩРН МСФґМН? йЮЙЮЪ БШЦНДЮ НР РНЦН, ВРН ТСМґЙЖХЪ АСДЕР ХЯОНКМЕґМЮ Б ЯРЕґЙЕ? нРБЕР: ЙНД ТСМґЙЖХХ, ХЯОНКМЪґЧЫЕИґЯЪ Б ЯРЕґЙЕ, ЛНФґМН ОПЪґЛН МЮ КЕРС ХГЛЕґМЪРЭ, МЮОґПХЛЕП ПЮЯґЬХТПНґБЮРЭ ЕЕ.
ьХТґПНБЮМґМШИ ЙНД ВПЕГґБШВЮИґМН ГЮРґПСДМЪґЕР ДХГЮЯґЯЕЛґАКХґПНБЮґМХЕ Х СЯХґКХБЮґЕР ЯРНИґЙНЯРЭ ГЮЫХРШ, Ю ЙЮЙНИ ПЮГґПЮАНРґВХЙ МЕ УНВЕР САЕґПЕВЭ ЯБНЧ ОПНЦґПЮЛЛС НР УЮЙЕПНБ? пЮГСЛЕґЕРЯЪ, НДМЮ КХЬЭ ЬХТґПНБЙЮ ЙНДЮ МЕ НВЕМЭ?РН ЯЕПЭґЕГМНЕ ОПЕґОЪРЯґРБХЕ ДКЪ БГКНЛґЫХЙЮ, ЯМЮАґФЕММНґЦН НРКЮДВХґЙНЛ ХКХ ОПНДґБХМСРШЛ ДХГЮЯґЯЕЛґАКЕґПНЛ МЮОНДНґАХЕ IDA Pro.
оПНЯґРЕИґЬХИ ЮКЦНґПХРЛ ЬХТґПНБЮМХЪ ГЮЙґКЧВЮґЕРЯЪ Б ОНЯґКЕДНБЮґРЕКЭґМНИ НАПЮґАНРґЙЕ ЙЮФґДНЦН ЩКЕґЛЕМґРЮ ХЯУНДМНґЦН РЕЙґЯРЮ НОЕґПЮЖХґЕИ ╚ХЯЙКЧґВЮЧЫЕЕ хкх╩ (XOR). оНБґРНПМНЕ ОПХґЛЕМЕґМХЕ XOR Й ГЮЬХТґПНБЮМґМНЛС РЕЙґЯРС ОНГґБНКЪґЕР БМНБЭ ОНКСВХРЭ ХЯУНДМШИ РЕЙЯР.
яКЕґДСЧЫХИ ОПХґЛЕП save_demo_to_file ВХРЮґЕР ЯНДЕПґФХЛНЕ ТСМґЙЖХХ Demo, ГЮЬХТґПНБШБЮґЕР ЕЦН Х ГЮОХЯШґБЮЕР ОНКСВЕМґМШИ ПЕГСКЭґРЮР Б ТЮИК, ОНЯґКЕ ВЕЦН НРЙПШґБЮЕР ТЮИК Я ДХЯґЙЮ, ГЮЦґПСФЮґЕР ДЮМґМШЕ, ПЮЯґЬХТПНґБШБЮґЕР ОНЯґКЕДНБЮґРЕКЭґМНЯРЭ АЮИґРНБ Х ХЯОНКМЪґЕР ХУ, ЙЮЙ МХ Б ВЕЛ МЕ АШБЮКН:
#include <stdio.h>
#include <memory.h>
void Demo(int (*_printf) (const char*, ...))
{_printf("Hello, World! ");return;
}
int write_file(const char* filename, unsigned char* buff, const int func_len)
{FILE* f;
if (fopen_s(&f, filename, "wb") == 0) {for (int a = 0; a < func_len; a++) {unsigned char c = buff[a] ^ 0x77;
buff[a] = c;
fputc(c, f);
}
fclose(f);
}
else return -1;
return 0;
}
int read_file(const char* filename, unsigned char* buff, const int func_len)
{FILE* f;
if (fopen_s(&f, "Data.bin", "rb") == 0) {int bc = 0;
while (!feof(f)) {unsigned char c = fgetc(f);
buff[bc] = c ^ 0x77;
bc++;
}
fclose(f);
}
else return -1;
return 0;
}
int main(int argc, char* argv[])
{unsigned char buff[1000];
void (*_Demo) (int (*) (const char*, ...));
int(*_main) (int, char**);
int (*_printf) (const char*, ...);
_Demo = Demo;
_main = main;
_printf = printf;
int func_len = (unsigned int)_main - (unsigned int)_Demo;
for (int a = 0; a < func_len; a++)
buff[a] = ((unsigned char*)_Demo)[a];
const char* fname = "Data.bin";
// бШБНДХЛ ОНЯКЕДНБЮРЕКЭМНЯРЭ АЮИРНБ МЮ ЩЙПЮМ
printf("%s ", buff);// гЮЬХТПНБШБЮЕЛ ОНЯКЕДНБЮРЕКЭМНЯРЭ АЮИРНБ Х ОХЬЕЛ Б ТЮИК
write_file(fname, buff, func_len);
// бШБНДХЛ ХГЛЕМЕММСЧ ОНЯКЕДНБЮРЕКЭМНЯРЭ АЮИРНБ МЮ ЩЙПЮМ
printf("%s ", buff);// нВХЫЮЕЛ ЛЮЯЯХБ АЮИРНБ
memset(buff, 0, 1000);
// бШБНДХЛ НАМСКЕММСЧ ОНЯКЕДНБЮРЕКЭМНЯРЭ АЮИРНБ МЮ ЩЙПЮМ
printf("%s ", buff);// вХРЮЕЛ АЮИРШ ХГ ТЮИКЮ, НДМНБПЕЛЕММН ПЮЯЬХТПНБШБЮЪ ХУ
read_file(fname, buff, func_len);
// бШБНДХЛ ХРНЦНБСЧ ОНЯКЕДНБЮРЕКЭМНЯРЭ АЮИРНБ МЮ ЩЙПЮМ
printf("%s ", buff);_Demo = (void (*) (int (*) (const char*, ...))) &buff[0];
_Demo(_printf);
return 0;
}
вРНґАШ ЯЙНЛґОХКХПНґБЮРЭ ОПНЦґПЮЛЛС, СЯРЮґМНБХ ДКЪ ЯПЕґДШ ПЮГґПЮАНРґЙХ РЕ ФЕ ОЮПЮЛЕРґПШ, ВРН АШКХ Б ОПНЬґКНЛ ОПНґЕЙРЕ: ОКЮРґТНПЛЮ ≈ x86, ПЕФХЛ ≈ Release. рЮЙґФЕ ЛНФЕЬЭ НРЙКЧґВХРЭ НОРХґЛХГЮґЖХЧ.
дКЪ МЮЦґКЪДМНЯґРХ БШОНКґМЪЕЛШЕ ОПНЦґПЮЛЛНИ НОЕґПЮЖХХ ОНЛЕЫЕґМШ Б НРДЕКЭґМШЕ ТСМґЙЖХХ. йЮЙ СФЕ АШКН ЯЙЮґГЮМН БШЬЕ, ТСМґЙЖХЪ Demo БШЯґРСОЮґЕР НАЗґЕЙРНЛ ЩЙЯОЕґПХЛЕМґРЮ: ЯМЮґВЮКЮ НМЮ ВХРЮґЕРЯЪ ХГ НЯМНБМНИ ТСМґЙЖХХ main, РЕЛ ЯЮЛШЛ ЕЕ РЕКН ЯНУґПЮМЪґЕРЯЪ Б ЛЮЯґЯХБЕ АЮИґРНБ buff. гЮРЕЛ ХЛЪ ТЮИґКЮ ДКЪ ЯНУґПЮМЕМХЪ, ЩРНР АСТЕП Х ЕЦН ДКХґМЮ ОЕПЕДЮґЧРЯЪ ТСМґЙЖХХ write_file, ЙНРНПЮЪ ОНАЮИґРМН ГЮОХЯШґБЮЕР ЯНДЕПґФХЛНЕ АСТЕПЮ Б ТЮИК, НДМНБПЕґЛЕМґМН ЬХТґПСЪ ЙЮФґДШИ АЮИР. оПХ ЩРНЛ Б АСТЕПЕ ГЮЬХТґПНБЮМґМШИ АЮИР ГЮЛЕМЪґЕР ХЯУНДМШИ. гЮЙНМґВХБ ЯБНЕ БШОНКґМЕМХЕ, ТСМґЙЖХЪ write_file БНГґБПЮґЫЮЕР Б ОНКСВЕМґМНЛ ОЮПЮЛЕРґПЕ СЙЮґГЮРЕКЭ МЮ ЛНДХТХґЖХПНґБЮМґМШИ АСТЕП.
оНЯґКЕ БШБНДЮ ЯНДЕПґФХЛНЦН АСТЕПЮ МЮ ЙНМґЯНКЭ ОПНЦґПЮЛЛЮ НВХґЫЮЕР ЕЦН Х БШГШБЮґЕР ТСМґЙЖХЧ read_file, ОЕПЕДЮґБЮЪ ЕИ ХЛЪ ТЮИґКЮ, ЙНРНПШИ МЮДН ОПНґВЕЯРЭ, НАМСґКЕМґМШИ АСТЕП Х ЕЦН ДКХґМС. нРЙПШБ ГЮДЮМґМШИ ДБНґХВМШИ ТЮИК, read_file ВХРЮґЕР ЕЦН ДН ЙНМґЖЮ, ОЕПЕАХґПЮЪ, ПЮЯґЬХТПНґБШБЮЪ Х ЯНУґПЮМЪЪ Б АСТЕПЕ ЙЮФґДШИ АЮИР. йНЦґДЮ БЕЯЭ ТЮИК ПЮЯґЬХТПНґБЮМ, Ю АСТЕП ГЮОНКґМЕМ, СЙЮґГЮРЕКЭ МЮ МЕЦН Б ОНКСВЕМґМНЛ ОЮПЮЛЕРґПЕ БНГґБПЮґЫЮЕРґЯЪ Б НЯМНБМСЧ ТСМґЙЖХЧ, ЦДЕ ОПНґХЯУНґДХР ОПХЯґБНЕМХЕ ЯНДЕПґФХЛНЦН ЛЮЯґЯХБЮ АЮИґРНБ ПЮМЕЕ НАЗґЪБКЕММНґЛС СЙЮґГЮРЕґКЧ _Demo МЮ ТСМґЙЖХЧ, ХЛЕґЧЫСЧ ОПНґРНРХО ТСМґЙЖХХ Demo.
мЮґЙНМЕЖ, Я ОНЛНЫЭЧ СЙЮґГШБЮґЧЫЕґЦН Б ЯРЕЙ СЙЮґГЮРЕґКЪ ОПНЦґПЮЛЛЮ БШГШБЮґЕР ТСМґЙЖХЧ Demo, РНКЭґЙН ВРН ГЮЦґПСФЕМґМСЧ ХГ ТЮИґКЮ.
нАґПЮРХ БМХґЛЮМХЕ: ОНЯґКЕ ЙЮФґДНИ НОЕґПЮЖХХ ОПНЦґПЮЛЛЮ БШБНДХР ЯНДЕПґФХЛНЕ АСТЕПЮ МЮ ЩЙПЮМ. рЮЙХЛ НАПЮґГНЛ, ГЮБЕПґЬХБ ЯБНЕ БШОНКґМЕМХЕ, ОПНЦґПЮЛЛЮ НЯРЮБКЪґЕР Б ЙНМґЯНКХ ЯКЕґДСЧЫХИ БШБНД.

оКЧЯ Б ОЮОґЙЕ Я ОПНЦґПЮЛЛНИ ОНЪБґКЪЕРґЯЪ ТЮИК Data.bin, ЯНДЕПґФЮЫХИ ДБНґХВМШИ ГЮЬХТґПНБЮМґМШИ ЙНД ТСМґЙЖХХ Demo.
гЮЬХТПНБЮММШИ ЙНД ≈ ЯКЕДСЧЫХИ СПНБЕМЭ ГЮЫХРШ ОПХКНФЕМХИ
уНґРЪ РЕОЕПЭ ОПЕФґДЕ, ВЕЛ БШОНКґМЪРЭ ЙНД, ОПНЦґПЮЛЛЮ ОПНґБНПЮґВХБЮґЕР Я МХЛ ЙЮБЕПґГМШЕ ЛЮМХОСґКЪЖХХ, ДКЪ УЮЙЕПЮ Я ДХГЮЯґЯЕЛґАКЕґПНЛ Х ОЪРЭЧ ЛХМСРЮґЛХ КХЬґМЕЦН БПЕґЛЕМХ МЕ ЯНЯґРЮБХР АНКЭґЬНЦН РПСґДЮ ПЮГНАґПЮРЭґЯЪ Б УХРґПНЯґОКЕґРЕМХґЪУ ЙНДЮ.
ю ВРН, ЕЯКХ ХГ ХЯУНДМНґЦН РЕЙґЯРЮ ОПНЦґПЮЛЛШ МЮОґПНВЭ СДЮґКХРЭ ТСМґЙЖХЧ Demo, Ю БГЮґЛЕМ ОНЛЕЯґРХРЭ ЕЕ ГЮЬХТґПНБЮМґМНЕ ЯНДЕПґФХЛНЕ Б ЯРПНґЙНБНИ ОЕПЕЛЕМґМНИ (БОПНґВЕЛ, МЕНАЪґГЮРЕКЭґМН ХЛЕМґМН ЯРПНґЙНБНИ)? гЮРЕЛ Б МСФґМШИ ЛНЛЕМР ЩРН ЯНДЕПґФХЛНЕ ЛНФЕР АШРЭ ПЮЯґЬХТПНґБЮМН, ЯЙНґОХПНґБЮМН Б КНЙЮКЭґМШИ АСТЕП Х БШГґБЮМН ДКЪ БШОНКґМЕМХЪ. нДХМ ХГ БЮПХґЮМРНБ ПЕЮКХґГЮЖХХ ГЮЬХТґПНБЮМґМНИ ОПНЦґПЮЛЛШ ОПХґБЕДЕМ Б ЯКЕґДСЧЫЕЛ КХЯґРХМЦЕ ≈ cipher_program:
#include <stdio.h> #include <string.h> #include <cstdlib> int main(int argc, char* argv[]) { char buff[1000] = ""; int (*_printf) (const char*, ...); void (*_Demo) (int (*) (const char*, ...)); // щРЮ ОНЯКЕДНБЮРЕКЭМНЯРЭ АЮИРНБ ДНКФМЮ АШРЭ ГЮОХЯЮМЮ Б НДМС ЯРПНЙС char code[] = "x22xFCx9BxF4x9Bx67xB1x32x87x3FxB1x32x86x12xB1x32x85x1BxB1x32x84x1BxB1x32x83x18xB1x32x82x5BxB1x32x81x57xB1x32x80x20xB1x32x8Fx18xB1x32x8Ex05xB1x32x8Dx1BxB1x32x8Cx13xB1x32x8Bx56xB1x32x8Ax7DxB1x32x89x77xFAx32x87x27x88x22x7FxF4xB3x73xFCx92x2AxB4"; _printf = printf; int code_size = _countof(code); if (strcpy_s(buff, code_size, code) == 0) { for (int a = 0; a < code_size; a++) buff[a] = buff[a] ^ 0x77; _Demo = (void (*) (int (*) (const char*, ...))) &buff[0]; _Demo(_printf); } return 0; }вРНґАШ ОНЯґРПНґХРЭ ОПНЦґПЮЛЛС, МСФґМН, ЙЮЙ Б ОПНЬґКШИ ПЮГ, БШАґПЮРЭ ОКЮРґТНПЛС x86, ПЕФХЛ ≈ Release. х, БНГґЛНФМН, НРЙКЧґВХРЭ НОРХґЛХГЮґЖХЧ.

рЕґОЕПЭ ДЮФЕ ОПХ МЮКХВХХ ХЯУНДМШУ РЕЙґЯРНБ ЮКЦНґПХРЛ ПЮАНРШ ТСМґЙЖХХ Demo АСДЕР ОПЕДґЯРЮБґКЪРЭ ГЮЦЮДґЙС! щРХЛ НАЯРНґЪРЕКЭґЯРБНЛ ЛНФґМН БНЯґОНКЭґГНБЮРЭґЯЪ, ВРНґАШ ЯЙПШРЭ МЕЙНРНґПСЧ ЙПХґРХВЕЯґЙСЧ ХМТНПЛЮґЖХЧ, МЮОґПХЛЕП ОПНґЖЕДСґПС ЦЕМЕПЮґЖХХ ЙКЧґВЮ ХКХ ОПНґБЕПґЙС ЯЕПХИґМНЦН МНЛЕПЮ.
оПНґБЕПґЙС ЯЕПХИґМНЦН МНЛЕПЮ ФЕКЮРЕКЭґМН НПЦЮґМХГНґБЮРЭ РЮЙ, ВРНґАШ ДЮФЕ ОНЯґКЕ ПЮЯґЬХТПНБґЙХ ЙНДЮ ЕЕ ЮКЦНґПХРЛ ОПЕДґЯРЮБґКЪК АШ ЦНКНБНґКНЛґЙС ДКЪ УЮЙЕПЮ.
гюйкчвемхе
лМНґЦХЕ ЯВХґРЮЧР ХЯОНКЭґГНБЮМХЕ ЯЮЛНЛНґДХТХґЖХПСґЧЫЕґЦНЯЪ ЙНДЮ ╚ДСПґМШЛ╩ ОПХґЛЕПНЛ ОПНЦґПЮЛЛХґПНБЮґМХЪ Х НАБХґМЪЧР ЕЦН Б РНЛ, ВРН НМ МЕ ОЕПЕМНґЯХЛ, ОКНґУН ЯНБґЛЕЯРХЛ Я ПЮГґМШЛХ НОЕґПЮЖХґНММШґЛХ ЯХЯґРЕЛЮЛХ, РПЕґАСЕР НАЪґГЮРЕКЭґМН НАПЮґЫЮРЭґЯЪ Й ЮЯЯЕЛґАКЕґПС Х РЮЙ ДЮКЕЕ. я ОНЪБґКЕМХґЕЛ Windows NT ЩРНР ЯОХґЯНЙ ОНОНКґМХКЯЪ ЕЫЕ НДМХЛ СЛНґГЮЙґКЧВЕМХґЕЛ, ДЕЯґЙЮРЭ, ЯЮЛНЛНґДХТХґЖХПСґЧЫХИґЯЪ ЙНД ≈ РНКЭґЙН ДКЪ MS-DOS, Б МНПґЛЮКЭґМШУ ФЕ НОЕґПЮЖХґНММШУ ЯХЯґРЕЛЮУ НМ МЕБНГґЛНФЕМ.
йЮЙ ОНЙЮГШґБЮЕР ЯРЮРЭЪ, БЯЕ ЩРХ ОПЕДґОНКНФЕґМХЪ, ЛЪЦґЙН БШПЮФЮґЪЯЭ, МЕБЕПґМШ. дПСґЦНИ БНОґПНЯ: РЮЙ КХ МЕНАґУНДХЛ ЯЮЛНЛНґДХТХґЖХПСґЧЫХИґЯЪ ЙНД Х ЛНФґМН КХ АЕГ МЕЦН НАНИґРХЯЭ? мХГґЙЮЪ ЩТТЕЙРХБґМНЯРЭ ЯСЫЕЯґРБСґЧЫХУ ГЮЫХР (НАШВґМН ОПНЦґПЮЛЛШ КНЛЮґЧРЯЪ АШЯґРПЕЕ, ВЕЛ СЯОЕґБЮЧР ДНИґРХ ДН КЕЦЮКЭґМНЦН ОНРґПЕАХРЕґКЪ) Х НЦПНЛМНЕ ЙНКХВЕЯґРБН ОПНЦґПЮЛЛХЯґРНБ, ЯРПЕґЛЪЫХУґЯЪ ╚РНОґРЮМХґЕЛ ЙКЮґБХЬ╩ ГЮПЮАНґРЮРЭ ЯЕАЕ МЮ УКЕА, ЯБХґДЕРЕКЭґЯРБСґЕР, ВРН МЕНАґУНДХЛН СЯХґКХБЮРЭ ГЮЫХРґМШЕ ЛЕУЮМХГґЛШ КЧАШЛХ ДНЯґРСОМШґЛХ ЯПЕДЯґРБЮґЛХ, Б РНЛ ВХЯґКЕ Х ПЮЯґЯЛНРґПЕММШЛ БШЬЕ ЯЮЛНЛНґДХТХґЖХПСґЧЫХЛґЯЪ ЙНДНЛ.
б ОПНґРХБНЯґРНЪМХХ ПЮГґПЮАНРґВХЙНБ КЕЦЮКЭґМНЦН ЯНТґРЮ Х БГКНЛґЫХЙНБ Я ХУ ХГНЫґПЕММШЛ ХМЯґРПСґЛЕМґРЮПХґЕЛ ЯЮЛНЛНґДХТХґЖХПСґЧЫХИґЯЪ ЙНД БШЯґРСОЮґЕР МЮ ЯРНґПНМЕ ОЕПґБШУ. уНРЪ Б РЕЙСЫХУ СЯКНґБХЪУ НМ ОПЕґДНЯґРЮБКЪґЕР МЕ МЮЯґРНКЭґЙН ХГЪЫґМШЕ ЛЕУЮМХГґЛШ, ЙНРНПШЕ АШКХ ДНЯґРСОМШ Б ЩОНґУС MS-DOS, ДЮФЕ ЯЕИґВЮЯ Б ПСЙЮУ НОШРґМНЦН ОПНЦґПЮЛЛХЯґРЮ НМХ ОНГґБНКЪґЧР ПЕЮКХґГНБЮРЭ ДНЯґРНИґМСЧ ГЮЫХРС РНКЭґЙН Я ХЯОНКЭґГНБЮМХґЕЛ ЪГШґЙНБ БШЯНЙНґЦН СПНБґМЪ.
хЯРНВМХЙ: teletype.in