GSLM: NLP-модель FAIR, обучаемая без текстов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-09-13 14:57

GSLM — модель обработки естественного языка FAIR, не требующая обучения на датасетах с текстами. Особенностями GSLM являются возможность ее обучения потенциально любому языку и эмоциональная выразительность генерируемой речи.
Текстовые языковые модели, такие как BERT, RoBERTa и GPT-3, используются в широком классе приложений обработки естественного языка, включая анализ тональности, перевод, поиск информации, генерацию выводов и обобщений. Однако их применение ограничено языками, для которых существуют большие датасеты с текстами.
Модель Generative Spoken Language Model (GSLM) не требует текстовых обучающих датасетов. Построенная на основе обучения представлениям, GSLM работает только с необработанными аудиосигналами. Это обстоятельство потенциально использовать модель с любым языком. Разработчики GSLM утверждают, что такая возможность обусловлена способностью детей изучать язык исключительно на основе необработанных звуков.
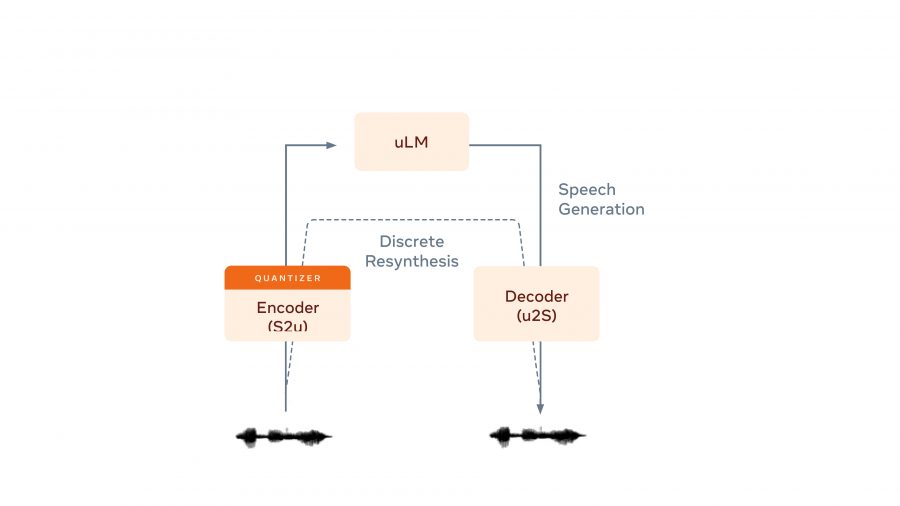
GSLM которая состоит из трех компонентов:
- энкодера, преобразующего речь в дискретные единицы, представляющие собой часто повторяющиеся звуки в разговорной речи;
- авторегрессионной языковой модели, обученной предсказывать следующую дискретную единицу на основе уже имеющихся данных;
- декодера, преобразующего дискретные единицы в речь.
Помимо возможности использовать модель для любого языка, GSLM обладает тремя преимуществами по сравнению с текстовыми моделями. Во-первых, она обеспечивает большую выразительность речи, включая интонации, иронию, гнев, неуверенность, смех и другие. Во-вторых, GSLM можно обучать на новых источниках речи, таких как подкасты и радио. В-третьих, модель позволит психологам, занимающимся вопросами развития, и врачам, занимающимся речью и языком, исследовать, как на способность младенцев учиться говорить и понимать речь влияют различия языков.
Источник: neurohive.io