Методы глубокого обучения классификации износа сверл на основе изображений отверстий просверленных при изготовлении мебели
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-03-17 01:37

В данной работе представлен комплекс усовершенствований, внесенных в алгоритм распознавания износа сверла, полученный в ходе предыдущей работы. В качестве входных значений использовались изображения просверленных отверстий, выполненных на меламиновой облицовке ДСП. В ходе представленных экспериментов были признаны три класса: зеленый, желтый и красный, которые непосредственно соответствуют инструменту, находящемуся в хорошем состоянии, форма которого должна быть подтверждена оператором и который должен быть немедленно заменен, так как его дальнейшее использование в производственном процессе может привести к потерям из-за низкого качества продукции. В ходе экспериментов и непосредственно в результате диалога с производителем было отмечено, что, хотя общая точность важна, гораздо важнее, чтобы используемый алгоритм мог правильно различать красный и зеленый классы и не делать (или как можно меньше) неправильных классификаций между ними. Предложенный алгоритм основан на ансамбле, возможно, разнообразных моделей, которые лучше всего работают в указанных выше условиях. Модель имеет относительно высокую общую точность, при этом почти нет ошибок в классификации между указанными классами. Окончательная точность классификации достигла 80,49% для самого большого используемого окна, при этом было сделано всего 7 критических ошибок (переклассификация между красным и зеленым классами).
Введение
Процесс изготовления мебели - сложный, с множеством различных этапов, требующих высокой точности и продуманных действий. Каждое из решений, которое заканчивается некачественным продуктом или какими-то ошибками в его общих чертах, может привести к огромным потерям для компании, так как такие элементы не будут соответствовать общим требованиям. Из многих факторов один, который очень важен и также трудно измерить без участия пользователя, - это контроль остроты сверла, чтобы указать точный момент, когда его следует заменить новым. Точный прогноз этого момента может предотвратить некоторые потери бюджета из-за низкого качества продукции. Хотя оператор может вручную проверить состояние сверла, это недостаточно эффективно, и для ускорения всего процесса требуется более автоматизированное решение.
Из существующих решений весь раздел алгоритмов и методик, используемых для оценки и оценки различных приборов, называется tool condition monitoring (TCM). Из этих решений также довольно мало тех, которые фокусируются на мониторинге состояния буровых установок. В большинстве таких подходов обычно требуется большое количество разнообразных датчиков для измерения различных сигналов. Полученные таким образом данные впоследствии используются для диагностики каждого состояния сверла. Наиболее распространенные сигналы, используемые для таких методов, включают измерение шума, проверку вибраций, проверку акустической эмиссии или таких элементов, как крутящий момент резания или сила подачи (Kurek et al. 2015Подходы, включающие вышеприведенные методы получения измерений, используемых для оценки состояния буровой установки, могут дать точные результаты. К сожалению, они также обычно требуют длительных и многочисленных этапов предварительной обработки, прежде чем будет достигнута требуемая точность. Кроме того, любые ошибки на этих этапах (например, правильный выбор датчика и сигнала, генерация и выбор наилучших признаков, используемых для диагностики, или, наконец, построение классификационной модели) могут привести к тому, что конечный результат будет неприемлемым. Такие решения также очень сложны с точки зрения их настройки и настройки каждого элемента, в то время как необходимое оборудование, как правило, дорого покупается или арендуется. Кроме того, необходимо учитывать время подготовки, необходимое, например, для настройки и калибровки датчиков в случае, когда такая установка не может оставаться в развернутом состоянии. Если как время, необходимое для подготовки испытательного стенда, так и время вычислений, необходимое для получения первоначальных результатов, являются значительными, то практичность и удобство такого решения еще больше уменьшаются. Все вышеперечисленные недостатки делают большинство существующих решений, ориентированных на мониторинг состояния инструмента, трудными в использовании, без немедленной выгоды для компании, которая решает их использовать, или даже уверенности в том, что такие выгоды будут существовать в ближайшем будущем. Эксперименты в предыдущих работах (Jemielniak et al. 2012; Kuo 2000; Panda et al. 2006) показывают, что даже при учете тех разнообразных признаков, которые генерируются на основе разнообразного набора зарегистрированных сигналов, точность таких решений не превышает 90% при распознавании трех определенных классов.
Применение алгоритмов машинного обучения в деревообрабатывающей промышленности в настоящее время стремительно растет. Например, в Ibrahim et al. (2017), авторы подготовили специальный алгоритм распознавания древесных пород, основанный на макроскопических текстурных изображениях, включающих нечеткое управление базами данных. Они разделили набор данных на 4 части, основываясь на размере пор в каждом образце, и использовали SVM (support vector machine) для окончательной классификации. Это позволяет легче добавлять новые породы древесины (таким образом, при добавлении нового класса требуется переобучить только классификатор SVM для этой части базы данных).
При учете выборок в виде изображений часто используются сверточные нейронные сети “CNN” (Hu et al. 2019; Kurek et al. 2017a, b, 2019a, bНесмотря на его возросшую популярность, существуют некоторые проблемы с адаптацией решений глубокого обучения к представленной проблеме. Прежде всего, для большинства существующих алгоритмов требуется большое количество обучающих данных, которые не всегда легко доступны. Обычно ситуация совершенно противоположная, с небольшим набором исходных данных. Во-вторых, в зависимости от поставленной задачи требования могут отличаться, поэтому каждая задача требует тесного сотрудничества с производителем, иначе окончательное решение может оказаться неудовлетворительным даже при высокой точности выходных результатов.
Основываясь на первоначальных подходах к проблеме существующих работ (Bengio 2009; Deng and Yu 2014; Schmidhuber 2015), а затем на проведенных экспериментах (Kurek et al. 2017a, b, 2019a, b), что в конечном итоге привело к работе, представленной в данной работе, авторы сосредоточились на снижении общей сложности решения, а также его корректировке под конкретные требования производителя. Первым серьезным улучшением является исключение любого более сложного оборудования, требующего калибровки или регулировки. Единственным внешним элементом, который все еще используется в представленном подходе, является камера, используемая для съемки просверленных отверстий (которые позже используются для оценки общего состояния сверла). Такая система легко внедряется в любую производственную установку и не требует больших финансовых вложений от компании, прежде чем можно будет провести первоначальные измерения. В ходе предыдущих подходов к этой проблеме, были различные типы алгоритмов тестирования, используя сверточные нейронные сети (CNN, которая является одним из наиболее эффективных решений, которые не требуют специальных диагностических признаков (Гудфеллоу и соавт. 2016; Курек и соавт. 2017a, б) с переходом обучения и данных по увеличению методологии (Курек и соавт. 2019a, бПроведенные эксперименты не только подтвердили, что выбранное решение позволяет точно прогнозировать состояние сверла только по показанным изображениям, но и смогли повысить общую точность прогнозирования по отношению к методам, использующим более сложные сигналы при оценке состояния инструмента. Поскольку после того, как такое решение подготовлено, оно не требует специальных знаний для использования (как это происходит в случае, когда датчики должны быть настроены и откалиброваны), оно также может быть более легко адаптировано к конкретным требованиям различных производителей. В то время как специализированное оборудование все еще может потребоваться, т. е. если производитель хотел контролировать состояние сверла на постоянной основе (в этом случае потребовалась бы специализированная система мониторинга, настроенная на получение четких снимков последующих отверстий), он также допускает подход, который не включает в себя такие элементы, и состояние сверла проверяется каждое установленное количество сверл. Учитывая все вышесказанное, решения на основе сетей CNN дешевле с точки зрения начальных затрат на оборудование и проще в реализации, при этом достигая аналогичной или более высокой точности, чем более сложные решения на основе наборов различных датчиков.
Первая из предыдущих работ, рассмотренных в рамках текущего подхода (Kurek et al. 2017b), была посвящена применению CNN к задаче прогнозирования износа сверл с очень ограниченным набором обучающих данных (242 изображения, представляющие три класса: 102 зеленых образца, 60 желтых образцов и 80 красных образцов). Даже при такой ограниченной коллекции точность 85% была достигнута с помощью представленного алгоритма CNN с использованием модели AlexNet (Krizhevsky et al. 2012; Russakovsky et al. 2015; Shelhamer 2017), а точность была дополнительно увеличена до 93,4% за счет использования машины опорных векторов (SVN) в качестве конечного слоя CNN. В работе Kurek et al. (2017А), простые операции с изображениями использовались для искусственного расширения доступного набора данных. При таком подходе были распознаны только два класса, и исходный набор данных содержал в общей сложности 900 изображений (300 образцов для первого класса и 600 образцов для второго). Первоначальная система имела точность 66,6%, но после расширения доступного набора данных с помощью вращения, масштабирования, добавления шума и т. д. Окончательные результаты составили 89% точности для 11700 образцов и 95,5% для 33300 образцов. Главным недостатком в этом случае был довольно длительный процесс обучения, который длился более 20 часов. Третье решение (Kurek et al. 2019b) объединило идеи увеличения данных и использования предварительно обученного CNN для классификации изображений. В этом подходе был использован предварительно обученный CNN с использованием модели AlexNet, а начальный обучающий набор, содержащий 242 изображения, был расширен с помощью простой операции с изображениями (конечный набор содержал 4598 изображений). Точность этого решения составила 93,48%. Окончательный подход представлен в работе Kurek et al. (2019а) использовал ансамбль классификаторов, содержащий три наиболее популярных предварительно обученных сети CNN: AlexNet, VGG16 и VGG19, и достиг точности 95,65% (в то время как отдельные классификаторы достигли точности 94,30% для AlexNet, 92,39% для VGG16 и 96,73% для VGG19).
Несмотря на то, что все вышеперечисленные подходы демонстрируют повышенную точность, без ненужного увеличения времени вычислений или усложнения настройки оборудования, во время этих экспериментов возникла одна дополнительная проблема. Хотя общая точность алгоритма по-прежнему является важным фактором, оказалось, что для мебельных компаний наиболее важным параметром является предотвращение любых неправильных классификаций между красными и зелеными классами (называя их “критическими ошибками”). В то время как инструмент, обозначенный желтым состоянием, дополнительно оценивается человеческим экспертом, и поэтому любые ошибки с оценкой могут быть исправлены, красный и зеленый классы являются окончательными. Поэтому зеленый инструмент, классифицированный как красный, будет отброшен, даже если он все еще может использоваться в течение длительного периода времени, и что еще хуже, красный инструмент, классифицированный как зеленый, будет использоваться в дальнейшем, возможно, вызывая некоторые финансовые потери из-за низкого качества продукции. В нынешнем подходе основное внимание уделяется в основном этой проблеме неправильной классификации, пытаясь избежать, особенно, присвоения зеленого класса красным инструментам, сохраняя при этом, возможно, высокий общий показатель точности классификации. Были выбраны и протестированы несколько различных классификаторов, а также ансамбли классификаторов. Лучшие из них были дополнительно модифицированы, чтобы улучшить полученные результаты в соответствии с отсутствием требований к неправильной классификации зелено-красного цвета.
Остальная часть этой работы организована следующим образом. Методологии, используемые для увеличения и корректировки данных, а также подготовки наборов данных для различных методов, описаны в разделе Материалы . В разделе Подготовка данных представлены настройки и операции, выполненные на начальных этапах. В разделе методы представлен обзор различных алгоритмов, проверенных в ходе экспериментов, и окончательная методология, основанная на наилучших результатах из исходного набора методов. Обзор полученных результатов и некоторые возможные направления будущей работы представлены в разделе Результаты эксперимента и их обсуждение. В последнем разделе кратко излагается работа, описанная в настоящем документе, и даются некоторые заключительные замечания.
Материалы
Материалом, использованным в процессе сверления, служила стандартная ламинированная ДСП (Kronopol U 511 SM; Swiss Krono Sp. z o. o., жары, Польша), которая обычно используется в мебельной промышленности (Рис. 1а). Размеры испытуемого образца составляли 300 x 35 x 18 мм. Для процесса сверления использовали обычное 12-мм сверло (FABA WP-01; Faba SA, Baboszewo, Польша), оснащенное наконечником из карбида вольфрама (Рис. 1б). Отверстия выполнялись в трехслойной ламинированной ДСП при частоте вращения шпинделя 4500 об/мин и скорости подачи 1,35 м / мин (в соответствии с рекомендациями производителя сверла).
Рис. 1

Примеры материалов, используемых в процессе сверления: боковая секция меламиновой облицованной ДСП (а) и примерное сверло (б)
Полноразмерное изображение
Существуют различные подходы к мониторингу состояния инструмента, каждый из которых связан с различными деталями станка и их спецификой, но обычно в этих случаях для обозначения общего состояния испытуемого элемента рассматриваются три класса: красный, зеленый и желтый (Jegorowa et al. 2019, 2020). Первый класс описывает инструменты, которые находятся в плохом состоянии и должны быть немедленно заменены из-за этого. Второй набор прямо противоположен ему и состоит из инструментов, которые находятся в хорошей форме и могут быть использованы в дальнейшем, без каких-либо возможных потерь для компании. Последний класс обозначает инструменты, которые подозреваются в износе, возможно, требующем дополнительной ручной оценки от человека—эксперта, чтобы окончательно определить их состояние-в зависимости от данного мнения, они могут быть либо отброшены как недостаточно хорошие, либо использованы в дальнейшем в процессе производства, если их состояние все еще удовлетворительно. Степень износа наружного угла [W (мм)] принималась в качестве индикатора состояния сверла и периодически контролировалась с помощью микроскопа (Mitutoyo TM-500) (Рис. 2). Исходя из этого, дрель сразу же получила классификацию “зеленая” (для W < 0,2 мм), “желтый” (0,2 мм < W < 0,35 мм) или “красный” (W > 0,35 мм) .
Рис. 2

Примеры изображений, полученных в процессе мониторинга с помощью микроскопа, используемого для определения внешнего углового износа сверла (Mitutoyo TM-500)
Сбор данных
Образцы данных с изображениями просверленных отверстий, использованных в процессе обучения, были собраны в сотрудничестве с Институтом древесных наук и мебели Варшавского университета живых наук с использованием стандартного вертикального обрабатывающего центра с ЧПУ (Busellato Jet 100, Thiene, Италия). В тестовых целях процесс сверления проводился на стандартной меламиновой ДСП (U511SM—Swiss Krono Group), которая обычно используется в мебельной промышленности. Размеры испытуемого образца составляли 2500 x 300 x 18 мм, используемого для процесса сверления (использовалось сверло 12 мм Faba WP-01 с наконечником из карбида вольфрама). Испытуемый образец с просверленными отверстиями позже разрезали на более мелкие (размером 300 x 35 x 18 мм) и сфотографировали (с помощью Nikon D810, Nikon Corporation, Shinagawa, Tokyo, Japan).
В ходе этого процесса было использовано в общей сложности пять новых сверл. В ходе эксперимента каждый инструмент достиг уровня износа выше 0,35 мм, что дает право на его замену новым. Измерение износа на микроскопе производилось через каждые 140 отверстий. Поскольку сверла обоюдоострые, микроскоп измеряли отдельно для каждого из лезвий, а затем определяли средний арифметический износ обоих лезвий. Для каждого из сверл процесс повторялся циклически, при этом между каждым циклом контролировался параметр внешнего углового износа с целью присвоения полученным изображениям соответствующего класса. Изображения отверстий, выполненных каждым сверлом, хранились отдельно, сохраняя порядок, в котором они были сделаны (так как это показывает постепенное вырождение состояния износа сверла и может быть использовано в качестве дополнительной информации в процессе обучения). В таблице 1 описан процесс сбора данных с измерением конечного углового износа для каждого сверла в конце последнего цикла сверления. На рис. 3 представлены примеры изображений, представляющих каждый из классов износа сверла, используемых в текущем подходе.
Таблица 1 краткое описание процесса сбора данных с первоначальными измерениями
Рис. 3

Примеры отверстий, производимых каждым классом износа сверла: зеленый, желтый и красный
Подготовка данных
Набор данных , использованных в процессе обучения , был аналогичен набору данных в предыдущих работах (Kurek et al. 2017b, 2019a, b), но в данном случае он был больше, содержал 5 наборов изображений, по одному для каждого из используемых сверл, в общей сложности 8526 образцов: 3780 для зеленого класса, 2800 для желтого класса и 1946 для красного класса. Поскольку зеленый класс был значительно лучше представлен (почти половина выборок), существовала вероятность того, что такое отсутствие баланса в наборе данных может привести к низкой точности после обучения, поэтому было решено оптимизировать набор данных. Во время первоначальной подготовки было обеспечено, чтобы каждый набор содержал одинаковое количество образцов для каждого класса. Вращение на 180 градусов использовалось для получения предполагаемого количества образцов. Таблица 2 содержит начальные количества образцов для каждого класса в наборе, представляющем каждое из используемых сверл, до и после использования увеличения данных. Эта операция делает каждую коллекцию сбалансированной, гарантируя, что процесс обучения будет работать правильно. В проведенных экспериментах один из исходных наборов использовался для тестирования, а остальные-в процессе обучения. Каждый обучающий набор был дополнительно разделен, так что 90% образцов были использованы для фактического обучения, а остальные 10% образцов были использованы для валидации.
Таблица 2 количество выборок для каждого класса до и после увеличения данных
Методы
В предыдущих экспериментах (Kurek et al. 2017a, b, 2019a, b) даже небольшие корректировки различных алгоритмов приводили к значительным различиям в конечной точности представленного решения. Поэтому, чтобы убедиться, что метод, используемый для текущего подхода, был наилучшим образом подходящим (тем более что основным фактором, помимо общей точности, была скорость неправильной классификации между зеленым и красным классами), первоначальные эксперименты касались тестирования различных алгоритмов в выбранных аспектах, начиная с решений, которые давали удовлетворительные результаты в предыдущих подходах. Во всех экспериментах использовались сверточные нейронные сети (CNN), в основе которых лежали различные предварительно обученные модели или обучение с нуля. Для каждого эксперимента использовался порог в 500 обучающих эпох, но ни один из тестируемых алгоритмов фактически не достиг этого числа (был реализован метод ранней остановки, чтобы убедиться, что весь процесс остановится, когда не произойдет значительного повышения точности модели). Точность валидации контролировалась в течение каждой тренировочной эпохи с параметром терпение = 50. Это означает, что если в течение следующих 50 эпох не было увеличения точности валидации, алгоритм был остановлен и Лучшая модель сохранена.
Все эксперименты проводились с использованием двух видеокарт NVIDIA TITAN RTX (всего 48 ГБ оперативной памяти), платформы Tensorflow с библиотекой Python и keras и с применением оптимизатора Adam.
Наборы данных для численных экспериментов
Классификация износа сверл уже довольно давно находится в центре внимания исследований авторов. В ходе проведенных экспериментов был проведен обширный диалог с производителем и экспертами относительно необходимых особенностей системы распознавания износа инструмента. В ходе этого общения было установлено несколько дополнительных требований, которые были опущены в предыдущих попытках, и к знанию авторов вообще игнорируются, когда речь заходит о представленной проблеме.
Прежде всего, хотя общая точность любого готового решения важна, способность алгоритма четко различать красный и зеленый классы гораздо важнее. Ошибки между этими двумя классами называются критическими ошибками, поскольку всякий раз, когда красный класс классифицируется как зеленый или зеленый класс классифицируется как красный, такие ситуации имеют высокий потенциал возникновения финансовых потерь для производителя. В первом случае продукт, полученный в процессе производства, имеет высокую вероятность быть некачественным. Во втором случае хороший инструмент будет преждевременно отброшен. Оба случая крайне нежелательны.
Вторым обсуждаемым элементом была общая производительность и время, необходимое для получения результатов. Хотя алгоритмы глубокого обучения чаще применяются к таким задачам, как мониторинг состояния инструмента, существует ряд проблем, связанных с общим процессом обучения и сбором данных. Прежде всего, алгоритм должен уметь корректно работать с ограниченным объемом данных, так как сбор больших объемов входных файлов не всегда возможен. Во-вторых, даже при наличии большого объема обучающих данных следует также учитывать общее время, необходимое для обучения применимого решения. Этот элемент отражается в выборе алгоритма в текущем подходе, а также в объеме используемого увеличения данных (эти методы используются только для балансировки всего набора, поэтому каждый класс представлен одинаково, но общее количество выборок далее не увеличивается, чтобы избежать ненужного продления процесса обучения). Окончательное разделение обучающих данных, используемых для текущих экспериментов, приведено в таблице 3.
Таблица 3 разделение наборов данных, участвующих в численных экспериментах
Полноразмерный стол
Поскольку искусственное расширение набора данных в этом случае не рассматривалось, для получения информации об изменениях состояния сверла был использован дополнительный метод. Для этого был введен параметр window, основанный на способе хранения изображений. В исходном наборе последовательные образцы хранились в точном порядке, в котором они были сделаны, что показывало постепенные изменения общего состояния сверла. Предполагалось, что используемый алгоритм выиграет от такой информации, и вместо использования одного изображения в качестве входных данных были включены наборы различных размеров, чтобы показать постепенное ухудшение состояния износа. В текущем подходе после консультаций с экспертами были протестированы окна размером 5, 10, 15 и 20 по сравнению с первоначальным подходом без такого расширения.
В ходе проведенных экспериментов оценивались различные алгоритмы для заданного набора требований. Каждый из них был отдельно подготовлен и испытан. Конечное решение, разработанное в этом подходе, является результатом тех испытаний, которые сталкиваются с требованиями производителя и общими результатами, полученными на разных этапах для выбранных алгоритмов. В следующих подразделах описываются тестируемые алгоритмы.
Базовая линия: анализ оттенков серого изображения
В ходе первоначальной подготовки был подготовлен базовый метод измерения точности и критической частоты ошибок, основанный на распределении цвета изображения. Каждое из изображений было преобразовано в оттенки серого и изменено до размера 500 на 500 пикселей, чтобы получить сопоставимые образцы. В то время как простые операции с изображениями могут быть использованы в случае алгоритмов CNN для выравнивания набора данных, это не так с этим подходом (так как даже после поворота изображения распределение пикселей останется прежним), следовательно, в случае этого решения исходный набор был использован без каких-либо изменений.
После преобразования оттенков серого значения были нормализованы для подачи в диапазоне 0-1. Позже пиксели были сгруппированы в соответствии с их значением и отнесены к одному из трех наборов: черному (представляющему отверстие), белому (представляющему ламинированную древесностружечную плиту) и серому (представляющему край). В то время как инструмент деградирует, край становится более зазубренным, и можно увидеть увеличение общего количества пикселей, классифицированных как серые. На этом этапе была проведена первоначальная классификация, подтвердившая первоначальные предположения об увеличении количества серых пикселей, но для повышения общей точности была использована дополнительная классификационная модель.
В модели, подготовленной для окончательной классификации, использовалась машина повышения светового градиента (Ke et al. 2017, также называемый LGBM или light GBM), и взял в качестве входных данных исходный массив, содержащий количество значений оттенков серого изображения (список из 256 элементов, содержащий количество пикселей на каждое значение оттенков серого). В подготовленной модели использовалась байесовская оптимизация гиперпараметров и мультилогарифмическая метрика потерь. Что касается алгоритма Light GBM, то в целом это древовидное решение, с другим подходом к расширению дерева. В то время как большинство методов будут выращивать деревья горизонтально, в этом случае они выращиваются вертикально (или по листьям), с максимальными Дельта-потерями, уменьшая больше потерь, чем в случае уровневых алгоритмов. Основное преимущество этих методов заключается в том, что они могут обрабатывать большие наборы данных с меньшим объемом памяти, фокусируются на точности результата и имеют параметр эффективности, используемый в качестве одного из показателей качества. В то время как легкий GBM может быть склонен к проблеме переоснащения, обширного набора данных, использованного в экспериментах, было достаточно, чтобы предотвратить это.
CNN разработан с нуля
Поскольку всегда желательно начинать с самого простого решения, без лишних осложнений, то первым подготовленным алгоритмом реализуется сеть CNN, обученная с нуля на подготовленном наборе данных, без использования методики трансферного обучения. Поскольку объем собранных данных был достаточным для учебного процесса, использование сверточных нейронных сетей для поставленной задачи классификации износа сверл было очевидным выбором. CNN является одним из лучших методов классификации изображений, и при соответствующем объеме данных (как это было в текущем подходе) обучение такой сети может дать хорошие результаты без каких-либо дополнительных операций.
Общая схема подготовленной сети CNN представлена в таблице 4. Он состоит, во-первых, из слоев, принадлежащих базовой сетевой структуре, которые автоматически извлекают объекты изображения. Вторая часть представленной модели (начиная с плоского слоя) представляет собой DNN (плотную нейронную сеть), используемую для реального процесса обучения и классификации в виде последнего, 3-нейронного плотного слоя с функцией активации softmax. Представленная модель использует отсевные слои для решения и предотвращения проблемы чрезмерной подгонки (путем случайного удаления нейронов) и максимальное объединение слоев для снижения общей сложности модели. Более того, в процессе обучения использовался метод ранней остановки, останавливающий процесс обучения, когда не было достигнуто существенного улучшения (этот параметр контролируется в течение каждой эпохи точности валидации). В течение каждой эпохи лучшая модель сохраняется (для каждого повышения точности валидации), а после метода ранней остановки лучшая модель загружается и далее используется.
Таблица 4 архитектура модели CNN, разработанной с нуля
Полноразмерный стол
Пакетирование 5xCNN разработано с нуля
Эта модель была использована для агрегирования 5, разработанных с нуля, СУБМОДЕЛЕЙ CNN. При таком подходе число нейронов в плотных слоях рисуется в принятом диапазоне. Эта методология называется bagging и представляет собой методику командного обучения, где окончательная классификация получается большинством голосов всех используемых моделей (в данном случае 5). Каждый из индивидуальных результатов, полученных с помощью подмоделей, рассматривается эквивалентно. Это означает, что окончательная классификация основана на простой m-значной доминанте из всех индивидуальных результатов подмодели.
Диапазоны, используемые для каждого плотного слоя, рисуются в следующих диапазонах: Dense1: (500, 600), Dense2: (200, 300), Dense3: (100, 200), Dense4: (50, 100).
VGG19 предварительно обученная сеть
В этом подходе была применена техника трансфертного обучения.Первой из предварительно обученных сетей, используемых в текущем подходе, была VGG19. VGG19-это обученная сверточная нейронная сеть из группы визуальной геометрии факультета инженерных наук Оксфордского университета. Число 19 происходит от количества слоев, которые используются для тренировочного процесса (содержащих веса): 16 сверточных слоев и 3 плотных слоя. Предварительно обученная сеть VGG19 была обучена на основе более чем миллиона изображений из ImageNet (2016) база данных. VGG19 способен классифицировать 1000 различных типов объектов, таких как клавиатура, мышь, карандаш, множество животных и т. д.
Исходная модель была скорректирована таким образом, чтобы лучше соответствовать представленной задаче и распознавать 3 необходимых класса, как и в предыдущих подходах. Весы были загружены с http://www.image-net.org и замерзла. Только часть DNN всей модели была обучаема, в то время как сеть CNN была заморожена. Полный список слоев для VGG19 представлен в таблице 5. В этом случае для предварительно обученной модели VGG19 в конце ее была добавлена глубокая нейронная сеть (DNN). В таблице 6 представлена вся модель, которая была учтена в первом алгоритме.
Таблица 5 список слоев CNN в модели на основе VGG19
Таблица 6 список слоев DNN в модели на основе VGG19
Пакетирование 5xVGG16 и 10xVGG16 предварительно обученной сети
Следующее проверенное в ходе экспериментов решение использовало предварительно обученную модель VGG16 (которая также является предварительно обученной сетью CNN), дополнительно улучшив ее с помощью подхода bagging. Первоначальная сеть была обучена распознавать 1000 классов, которые были скорректированы до трех классов, используемых в текущей задаче. Модель VGG16 была выбрана для подхода мешкования, так как она менее сложна, чем VGG19, и с этим алгоритмом проблема чрезмерной подгонки менее вероятна. Были подготовлены два варианта этого подхода: первый с использованием 5 и второй с использованием 10 случайно инициализированных классификаторов. Схема структуры единого классификатора VGG16 представлена в таблице 7, а классификатор DNN-в таблице 8 Точно так же, как и в случае с 5xCNN, разработанным с нуля, четыре случайных числа нейронов, из интервалов: (300, 400), (200, 300), (100, 200) и (50, 100), были выбраны для всех оценок. Более того, в процессе обучения только 90% набора обучающих данных было случайным образом выбрано для каждого оценщика. После процесса обучения каждый из оценщиков показывал бы вероятность рассматриваемого примера. Эти вероятности затем суммировались, и в качестве окончательной классификации было выбрано максимальное значение.
Таблица 7 список слоев в модели CNN на основе VGG16
Таблица 8 список слоев в модели DNN на основе VGG16
Ансамбль из 3 лучших моделей
После первоначальных испытаний и получения результатов точности предыдущих алгоритмов для ансамбля классификаторов были выбраны три наиболее эффективных решения. В этом случае использовались модели CNN, обученные с нуля, VGG19 и 5xVGG16, поскольку они лучше всего работали с точки зрения общей точности, предполагая, что каждая выбранная модель должна работать по-разному и быть достаточно эффективной для требований производителя. Предполагалось, что объединение различных сетевых результатов для одной и той же задачи классификации повысит общую точность полученного решения.
Результаты эксперимента и их обсуждение
При подготовке текущего подхода к классификации износа сверл эксперименты были разделены на две основные части: первая-оценка различных корректировок алгоритма к выбранной задаче с дополнительными требованиями производителя, а вторая-подготовка индивидуального решения с использованием исходных результатов, полученных на первом этапе.
Оценка исходного набора алгоритмов
На первом этапе проведенных экспериментов была апробирована общая настройка алгоритма на задачу классификации износа сверл. Кроме того, было проверено, насколько хорошо каждое из выбранных решений соответствует дополнительным требованиям производителя к отсутствию зелено-красной неправильной классификации. Таблицы 9, 10, 11, 12, 13, 14 представьте результаты общей точности для каждого из оцениваемых алгоритмов с наибольшим используемым окном. Цифры 4, 5, 6, 7, 8, 9 покажите матрицы путаницы для двух граничных случаев, когда речь идет об используемом диапазоне изображений: случай без окна и с самым большим используемым окном (равным 20 последовательным изображениям).
Таблица 9 классификационный отчет для модели CNN, разработанной с нуля для window = 20
Таблица 10 классификационный отчет для модели CNN, разработанной с нуля с упаковкой для окна = 20
Таблица 11 классификационный отчет для предварительно подготовленной модели VGG19 для window = 20
Таблица 12 классификационный отчет для упаковки в мешки предварительно подготовленной сети 5xVGG16 для окна = 20
Таблица 13 классификационный отчет для упаковки в мешки предварительно подготовленной сети 10xVGG16 для окна = 20
Таблица 14 классификационный отчет для ансамбля из 3 лучших моделей для окна = 20
Рис. 4
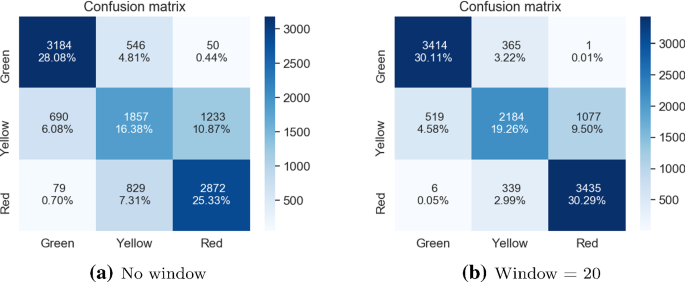
Матрицы путаницы для сети CNN разработаны с нуля для отсутствия окна и размера окна = 20
Рис. 5
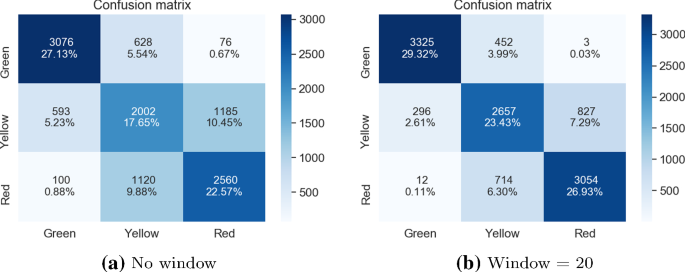
Матрицы путаницы для 5 случайных классификаторов с использованием сети CNN разработаны с нуля для отсутствия окна и размера окна = 20
Рис. 6
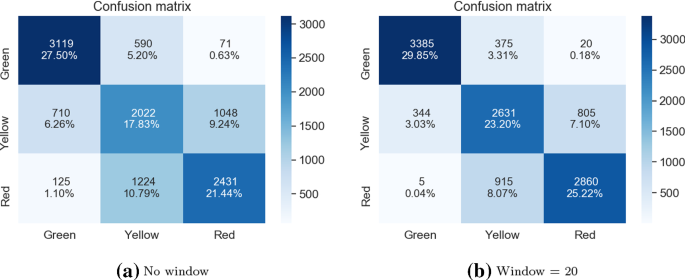
Матрица путаницы для алгоритма VGG19 для отсутствия окна и размера окна = 20
Рис. 7
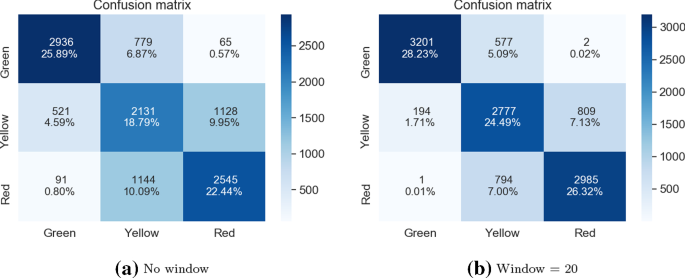
Матрицы путаницы для 5 случайных оценок VGG16 алгоритм голосования для отсутствия окна и размера окна = 20
Рис. 8
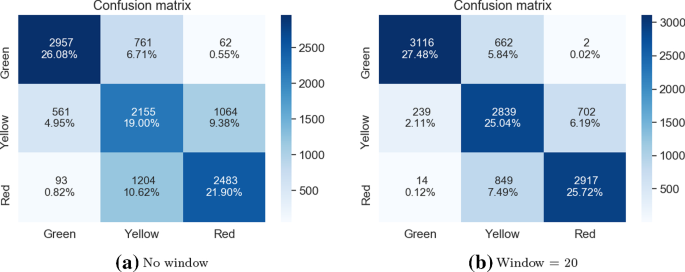
Матрицы путаницы для 10 случайных оценок VGG16 алгоритм голосования для отсутствия окна и размера окна = 20
Рис. 9
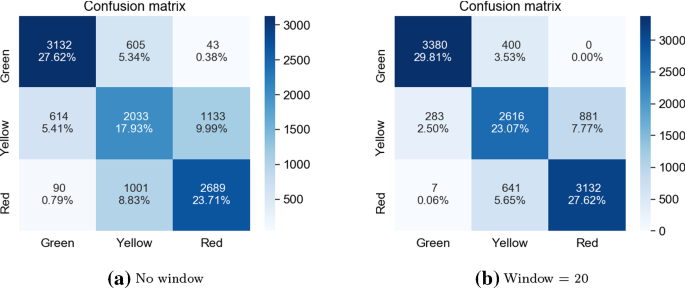
Матрицы путаницы для ансамбля классификаторов с использованием VGG19, ансамбля из 5 сетей VGG16 и сети CNN, созданной с нуля для no window и размера окна = 20
Из исходных алгоритмов два подхода с одним классификатором работали относительно хорошо, с высокой общей точностью (с 79,66% общей точности для пользовательского CNN и 78,27% для VGG19, при размере окна, равном 20) и небольшим количеством критических ошибок (3 для пользовательского CNN и 7 для VGG19, при том же размере окна). На том же этапе были отброшены два подхода к укладке мешков, поскольку они не дали удовлетворительных результатов. Первый, используя 5 случайных инициализаций сети CNN, обученной с нуля, хотя и получил несколько более высокую общую точность (79,04%), также сделал значительно больше критических ошибок (всего 16). Второй подход, использующий 10 случайных инициализаций классификатора VGG16, не только имел более низкую общую точность по сравнению с подходом пакетирования, использующим только 5 классификаторов такого рода (78,24% по сравнению с 79,04%), но и допускал более критические ошибки (25 по сравнению с 15 в общей сложности). Поскольку оба эти решения были также более сложными и трудоемкими, они были отброшены.
Окончательное решение, протестированное на этом этапе, использовало ансамбль из трех моделей, которые до этого момента работали лучше всего: CNN trained from scratch, VGG19 и 5xVGG16. Поскольку в предыдущих экспериментах такой комбинированный подход имел тенденцию повышать общую точность представленного решения, предполагалось, что оно будет вести себя аналогично и в этом случае. В таблице 15 приведены общие показатели точности для всех тестируемых алгоритмов с различными размерами используемых последовательностей изображений (начиная с отсутствия окна и с максимальным размером окна, равным 20). Таблица 16 описывает критические частоты ошибок для тестируемых решений для двух граничных случаев: отсутствие окна и размер окна, установленный равным 20. Когда дело доходит до общей точности, ансамблевое решение работает лучше всего для всех случаев, за исключением случая без окна, где один пользовательский CNN достиг наилучших результатов. Он также смог достичь самого высокого общего показателя точности до этого момента, для размера окна 20, равного 80,49%. Когда дело доходит до критической частоты ошибок, он достиг наилучшего результата, когда дело доходит до случая без окна (всего 133 критических ошибки, когда второе лучшее решение, VGG19 имел 149 ошибок), и второго лучшего результата для окна = 20 (7 критических ошибок, причем лучшим решением является CNN, разработанный с нуля только с 3 такими ошибками).
Таблица 15 результаты классификации для выбранных алгоритмов, для классификации без окна и с различными размерами окна (5, 10, 15 и 20) для последовательных выборок
Таблица 16 количество критических ошибок между зеленым-красным и красно-зеленым для отсутствия окна и окна = 20
Хотя вышеприведенные результаты можно было бы принять как удовлетворительные, в конечном счете было решено, что ансамблевое решение достигло слишком схожих результатов с одной моделью CNN, обученной с нуля, когда дело доходит до общей точности (разница 0,83%). Кроме того, поскольку он допускал более критические ошибки, решение было отброшено, и были проведены дополнительные эксперименты, чтобы улучшить все решение, что привело к окончательному, улучшенному алгоритму классификации износа сверла.
Усовершенствованный подход к классификации износа сверл
Продолжая предположение , основанное на предыдущих исследованиях, проведенных в выбранном предмете (Kurek et al. 2019a, b), при соединении различных классификаторов в ансамбль и использовании метода голосования для получения окончательной классификации улучшенного общего решения, аналогичный подход был использован для окончательного решения, представленного в данной работе. Хотя первоначальные эксперименты дали некоторые приемлемые результаты, они все еще не были удовлетворительными, и потребовалась дополнительная работа по улучшению общих результатов.
Хотя окончательное решение, представленное в этой статье, также использует ансамбль классификаторов, при принятии решения о том, какие алгоритмы будут его частью, был использован другой подход. На этот раз вместо общей точности классификации были выбраны решения, основанные на их способности различать ключевые красные и зеленые классы. Исходя из этого аспекта, во-первых, и общей точности алгоритма, во-вторых, включая дополнительные параметры, связанные с общими свойствами ансамбля, были выбраны три следующих алгоритма:
- 1.
5 случайных оценокVGG16 —так как этот подход показал довольно хорошие результаты при общей точности (79,04% для размера окна 20) и относительно хорошие при различии классов красного и зеленого (176 критических ошибок для случая без окна и 7 для размера окна 20).
- 2.
Модель CNN была подготовлена с нуля, без использования трансферного обучения - так как эта модель имела удовлетворительные результаты для обоих рассматриваемых типов точности (156 критических ошибок в случае отсутствия окна и только 3 для размера окна 20, при общей точности 79,66% для самого большого окна).
- 3.
ансамбль из 5 случайных телеканал CNN моделей, написано с нуля, хотя это и не улучшило один телеканал CNN модели и значительно хуже в случае критической ошибки курсу на больших окна (155 критические ошибки без окна, и 16 для окна размером 20, с общей точностью 79.68% для больших окна) было решено, что в нее добавляют существенное разнообразие классификатору ансамбль.
Приведенные выше алгоритмы были выбраны по нескольким причинам. Во-первых, точность каждого алгоритма была связана с тем, насколько хорошо каждый из них может различать красный и зеленый классы. Были выбраны только те алгоритмы, которые имели эти значения в допустимом пороге. Во-вторых, для этих алгоритмов было проверено, что увеличение размера окна приводит к повышению точности (поскольку окно содержит последовательности изображений отверстий, просверленных одним и тем же сверлом, можно с уверенностью предположить, что любой алгоритм, соответствующим образом настроенный на выбранную задачу, должен быть способен значительно повысить свою точность при использовании большего окна для оценки). Третий и последний элемент, включенный при выборе алгоритмов, был выбран для увеличения разнообразия методов в конечном наборе. В случае ансамбля алгоритмов лучше всего, чтобы выбранные элементы были как можно более разнообразными, чтобы обеспечить более высокую точность конечного решения. Все алгоритмы, используемые в конечном наборе, существенно различаются либо по специфике сети CNN, используемой для классификации (VGG16 и сеть CNN, которая была разработана и обучена с нуля), либо по типу конечного метода, используемого для классификации (классификация CNN или голосование классификаторов).
После разработки окончательного решения для оценки его эффективности был использован тот же набор экспериментов, что и в предыдущем алгоритме. Алгоритм был протестирован с использованием одного и того же набора размеров окон (начиная с отсутствия окна и заканчивая размером окна = 20). Окончательная классификация получалась путем суммирования вероятностей принадлежности рассматриваемого изображения к каждому из трех классов и выбора того, которое имело наибольший балл. В целях тестирования образцы были перемешаны, чтобы гарантировать, что классификация будет основана на случайных примерах, а не на последовательных изображениях. Благодаря увеличению исходных данных каждый класс был в равной степени представлен в наборах, представляющих все упражнения, использованные в ходе экспериментов (всего 5), что обеспечивало сбалансированный набор как для обучения, так и для тестирования.
В ходе испытаний подготовленный алгоритм вел себя в соответствии с первоначальными прогнозами. Первый прогон, без установленного окна для проверки последовательности изображений (во время обучения), был худшим, с общей точностью 70% и значительно большим количеством ошибок классификации между красным и зеленым классами. На последующих этапах полученная общая точность неуклонно возрастала, в то время как количество ошибочных классификаций начало уменьшаться. Точность 75% была получена для размера окна = 5 и 78% для размера окна = 10. после этого общая точность классификации стабилизируется около значения 80%. На этом этапе была достигнута приемлемая точность (аналогичная тем, которые были получены в существующих подходах с гораздо более сложными установками, содержащими разнообразные датчики и сложные методологии, используемые для сбора и подготовки исходных данных) с почти нулевыми ошибками классификации между двумя противоположными классами (всего 7 критических ошибок).
Как уже упоминалось ранее, в случае таких приложений уменьшение числа ошибочных классификаций между удаленными классами в целом более важно, чем общая точность классификации алгоритмов. В этом случае подготовленный метод в настоящее время оценивается в реальных рабочих условиях, а онлайн-приложение, подготовленное в ходе экспериментов, тестируется фактическим производителем. Первоначальная обратная связь была очень положительной, и было передано, что подготовленное решение полностью применимо к проблеме распознавания износа сверла. Кроме того, его простота с точки зрения используемых входных данных и оборудования, необходимого для их получения, является дополнительным, огромным преимуществом перед большинством существующих решений.
Что касается возможных направлений будущей работы, то следующим шагом будет повышение общей точности алгоритма. Пока полученные результаты находятся в приемлемом диапазоне, все же было бы предпочтительнее, улучшить его. Кроме того, необходимо оценить возможные альтернативы параметру окна (обозначаемому как последовательность изображений, используемых во время обучения). Хотя использование наборов упорядоченных изображений в процессе обучения очень эффективно, получение таких данных не всегда легко, а иногда может оказаться невозможным. Поэтому было бы разумно найти какую-то альтернативу этому процессу с хотя бы такой же степенью точности.
Вывод
В данной работе представлен усовершенствованный алгоритм классификации износа сверл с использованием изображений пробуренных отверстий в качестве входных данных. Для экспериментов был подготовлен сбалансированный набор изображений, чтобы убедиться, что он не будет благоприятствовать ни одному из классов. Поскольку они были сделаны в определенной последовательности (то есть изображения отверстий, просверленных одним и тем же инструментом с течением времени, были приведены в порядок, в котором они были сделаны), эти данные использовались для повышения точности алгоритма. Затем была проведена серия тестов, оценивающих различные алгоритмы, основанные на сетях CNN (как с использованием методологий трансферного обучения, так и с подготовкой такой сети с нуля и обучением ее на полученных примерах). В ходе экспериментов была проверена общая точность каждого алгоритма для различных размеров окна последовательности изображений (используемого в процессе обучения). На этом этапе была также оценена частота неправильных классификаций между красными и зелеными классами. Этот последний параметр был добавлен в набор, так как он был очень важен для производителя—ошибки между этими двумя группами могут привести к потере из-за плохого качества продукта или выбрасывания инструмента, который все еще находится в хорошей форме. Окончательный алгоритм, который был подготовлен, состоял из ансамбля из трех методов: ансамбля из 5 случайных классификаторов VGG16, модели CNN, обученной с нуля, и ансамбля из 5 этих моделей CNN, случайно инициализированных. Точность 80% была достигнута при размере окна = 20, при этом почти не было допущено ошибок классификации (всего 7 критических ошибок).
Подготовленное решение имеет общую точность, которая укладывается в начальный допустимый диапазон, сохраняя при этом хорошую скорость неправильной классификации важных элементов. Хотя она и похожа на единственную модель CNN, она превосходит ее из-за разнообразия используемых классификаторов и, как следствие, менее подвержена проблеме переоснащения. Он также достаточно продвинут, чтобы использоваться с реальными данными, и онлайн-версия его доступна производителю. Первоначальная обратная связь была очень положительной, как из—за точности представленного решения, так и из-за его простоты-использования изображений вместо сложного набора данных (что требует не менее сложных датчиков и длительного периода времени, в течение которого эти датчики настраиваются, а затем оцениваются, чтобы правильно собрать необходимую информацию). Все это позволило ускорить сбор данных и упростить адаптацию представленного решения к реальной рабочей среде без высоких первоначальных затрат.
Источник: link.springer.com