Опытные программисты имеют точно настроенные кортикальные представления исходного кода
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2021-02-10 04:10

Опыт позволяет людям достигать выдающихся результатов в решении задач, специфичных для конкретной области, и программирование не является исключением. Многие исследования показали, что опытные программисты демонстрируют значительные отличия от новичков в поведении, структуре знаний и избирательном внимании. Однако глубинные различия в мозге программистов до сих пор остаются неясными. Здесь мы решаем эту проблему, связывая кортикальное представление исходного кода с индивидуальным опытом программирования, используя подход декодирования на основе данных. Этот подход позволил нам выделить семь областей мозга, широко распределенных в лобной, теменной и височной коре, которые тесно связаны с опытом программирования. В этих областях мозга функциональные категории исходного кода могли быть декодированы из мозговой активности, и точность декодирования была значительно коррелирована с индивидуальными поведенческими характеристиками в задаче категоризации исходного кода. Наши результаты показывают, что опыт программирования строится на тонко настроенных кортикальных представлениях, специализированных для области программирования.
Заявление О Значимости
Опыт, необходимый для программирования, вызывает все больший интерес среди исследователей и преподавателей в нашем компьютеризированном мире. Многие исследования показали, что опытные программисты демонстрируют превосходную поведенческую производительность, структуру знаний и избирательное внимание, но как их мозг приспосабливается к такому превосходству, не совсем понятно. В этой статье мы записали мозговую деятельность субъектов, охватывающих широкий спектр знаний в области программирования. Результаты показывают, что функциональные категории исходного кода могут быть декодированы из их мозговой активности, а точность декодирования в семи областях мозга в лобной, теменной и височной коре значительно коррелирует с индивидуальными поведенческими характеристиками. Это исследование предоставляет доказательства того, что выдающиеся результаты опытных программистов связаны с предметно-специфическими корковыми представлениями в этих широко распределенных областях мозга.
Введение
Опыт программирования является одним из наиболее заметных возможностей в современном компьютеризированном мире. Поскольку человеческий разработчиков программного обеспечения продолжать играть ключевую роль в проектах по разработке ПО и напрямую влияют на их успех, это относительно новый вид экспертиз привлекает все большее внимание современных производств (батарея Li и соавт., 2015; Балтес и Диля, 2018) и учебные заведения (Хайнс и соавт., 2016; Papavlasopoulou и соавт., 2018). Более того, огромные различия в производительности были неоднократно обнаружены даже между программистами с одинаковым уровнем опыта (Boehm and Papaccio, 1988; DeMarco and Lister, 2013). Предыдущие исследования показали психологические характеристики опытных программистов в их поведении (Vessey, 1985; Koenemann and Robertson, 1991), структурах знаний (Fix et al., 1993; Von Mayrhauser and Vans, 1995) и движениях глаз (Uwano et al., 2006; Busjahn et al., 2015). Хотя эти исследования ясно иллюстрируют поведенческую специфику опытных программистов, остается неясным, какие нейронные основы отличают опытных программистов от новичков.
Недавние исследования изучали мозговую активность программистов с помощью функциональной магнитно-резонансной томографии (фМРТ). Siegmund et al. (2014, 2017) сравнивали мозговую активность во время оценки выходных данных программы с поиском синтаксических ошибок и показали, что процессы оценки выходных данных программы активировали левосторонние области мозга, включая среднюю лобную извилину (MFG), нижнюю лобную извилину (IFG), нижнюю теменную дольку (IPL) и среднюю височную извилину (MTG). Их результаты показали, что понимание программ связано с обработкой естественного языка, разделением внимания и вербальной/числовой рабочей памятью. Peitek et al. (2018a) повторно проанализировали те же данные, что и Siegmund et al. (2014) исследовать корреляцию между силой смелой активации и индивидуальным опытом программирования, которая определялась самооценкой субъекта, но не обнаружила какой-либо значимой тенденции. В исследовательском исследовании утверждалось, что существует корреляция между различимостью паттернов деятельности и средними баллами оценки испытуемых (GPA), учитывающими только курсы из отдела компьютерных наук в качестве прокси для опыта программирования (Floyd et al., 2017Однако баллы GPA будут отражать смесь различных факторов (IQ, способность к запоминанию, навыки расчета и т. д.), и предполагаемую связь с опытом программирования было трудно проверить эмпирически. Кроме того, основным ограничением этих предыдущих исследований является использование однородной предметной группы, охватывающей лишь небольшой круг знаний в области программирования. Привлечение более разнообразных субъектов с точки зрения их опыта программирования может позволить выяснить потенциальные различия функций мозга, связанные с этим опытом.
Здесь мы стремимся выявить нейронные основы опыта программирования, которые способствуют выдающимся достижениям опытных программистов. Для этого мы определили два фундаментальных фактора в нашем эксперименте: объективно определенный эталон знаний в области программирования и лабораторное задание, демонстрирующее лучшие результаты экспертов в условиях общих ограничений экспериментов фМРТ. Во-первых, мы приняли рейтинги программистов в конкурсных соревнованиях по программированию (AtCoder; https://atcoder.jp/), которые объективно определяются относительными позициями их фактических показателей среди тысяч программистов. Мы привлекли программистов с высшим и средним рейтингом, а также начинающих контролеров, чтобы охватить широкий спектр программных знаний в нашем эксперименте fMRI. Во-вторых, мы разработали задачу категоризации программ и подтвердили, что поведенческие характеристики этой задачи были значительно коррелированы с принятой референцией опыта программирования. Это подтверждение позволяет нам ожидать связи между выдающимися результатами работы опытных программистов и паттернами мозговой активности, записанными с помощью фМРТ, когда они выполняли эту лабораторную задачу.
Наша основная гипотеза заключается в том, что более высокий уровень знаний в области программирования и выдающиеся результаты работы экспертов связаны с конкретными представлениями многосекционных паттернов, потенциально зависящими от их предметных знаний и опыта обучения. Эта гипотеза мотивирована предыдущими исследованиями, которые сравнивали паттерны многоселевой активности экспертов с новичками и показали, что предметно-специфическая экспертиза обычно ассоциируется с репрезентативными изменениями в мозге (de Borst et al., 2016; Martens et al., 2018; Gomez et al., 2019). Например, Bilali? et al. (2016) показано, что мультивоксельные паттерны в веретенообразной области лица опытных рентгенологов были более чувствительны к дифференцировке рентгеновских изображений от контрольных стимулов, чем новички. Точно так же идентификация многовокселевых паттерновых представлений, специфичных для опытных программистов, предлагает хорошую отправную точку для понимания когнитивных механизмов, лежащих в основе опыта программирования. Из предыдущих исследований, посвященных неопытным программистам и экспертным знаниям в других областях, можно сделать вывод, что высокоуровневые визуальные и левые лобно-теменные области могут быть выведены как потенциальные нейронные корреляты опыта программирования (Siegmund et al., 2014; Bilali?, 2017). Однако, насколько нам известно, нет никаких предварительных доказательств того, что опыт программирования напрямую связан с определенными областями мозга. Таким образом, мы используем полномозговой прожекторный анализ (Kriegeskorte et al., 2006) для выявления областей, связанных с опытом программирования.
Материалы и методы
Предметы
Чтобы начать это исследование, мы определили три критерия рекрутинга: эксперт, лучшие 20% ранкеров в AtCoder , которые имели скорость AtCoder равную или выше 1200; средний, 21-50% ранкеров, которые имели скорость AtCoder между 500 и 1199; новичок, испытуемые, которые имели четырехлетний или менее опыт программирования и не имели опыта в конкурентном программировании. Мы поделились нашим рекрутинговым сообщением через списки рассылки и приложения для обмена сообщениями с различными сообществами выпускников или студентов бакалавриата в Японии. С помощью этой процедуры 95 программистов из 28 университетов и трех компаний заполнили нашу вступительную анкету, чтобы зарегистрироваться в качестве кандидатов. Список кандидатов состоял из 19 экспертов (все мужчины), 43 средних специалистов (одна женщина) и 33 новичков (девять женщин). Из списка были исключены девять левшей и 20 испытуемых с менее чем полугодовым опытом программирования на Java. Пять субъектов в возрасте до 20 лет также были исключены, чтобы избежать дополнительных бюрократических процедур. Мы попросили остальных испытуемых-кандидатов принять участие в эксперименте в основном по стратегии "первым пришел-первым вышел". Обратите внимание, что настройка новичка как программисты, у которых уровень AtCoder был ниже 500, это был еще один потенциальный критерий рекрутинга, но мы не приняли этот критерий, потому что низкие значения в ставке отражают два неразличимых фактора: низкий опыт программирования или недостаточное участие в конкурсе. Кроме того, владение скоростью AtCoder само по себе может означать обладание умеренным опытом программирования. Таким образом, наши критерии подбора персонала определяют новичка как программиста с меньшим опытом программирования и отсутствием опыта конкурентного программирования.
В эксперименте приняли участие тридцать здоровых испытуемых (две женщины в возрасте от 20 до 24 лет) с нормальным или скорректированным до нормального зрением (демографическую информацию о набранных испытуемых см. В Таблице 1). Все они были правшами [оценено по Эдинбургской инвентаризации рук (Oldfield, 1971); коэффициент латеральности = 83,6 ± 24,0, варьировался от +5,9 до +100] и понимали основные грамматики Java с опытом программирования на Java не менее полугода. Усредненные ставки AtCoder (1967 в expert и 894 в middle) были эквивалентны топовым 6,5% и 34,1% позициям среди 7671 зарегистрированного игрока по данным рейтинга на 1 июля 2017 года соответственно. Семь дополнительных испытуемых были отсканированы, но не включены в анализ, потому что один (новичок) показал неврологические аномалии на МРТ-изображениях, трое (один эксперт и два средних) вышли из эксперимента без полного завершения, трое (один эксперт и два новичка) показали сильно предвзятые поведенческие реакции, оцениваемые, когда поведенческие характеристики одного или нескольких вариантов не достигали уровня случайности в обучающих экспериментах, сигнализируя о сильной предвзятости реакции прилипания к определенному выбору. Это исследование было одобрено комитетами по этике Института науки и техники Нара и CiNet, и испытуемые дали письменное информированное согласие на участие. Размер выборки был выбран таким образом, чтобы соответствовать предыдущим исследованиям фМРТ на человеческом опыте с аналогичными поведенческими протоколами (Amalric and Dehaene, 2016; Bilali? et al., 2016; de Borst et al., 2016).
Table 1
Demographic information of recruited subjects
| N | Sex (M/F) | Age | AtCoder rate | PE (year) | JE (year) | CPE (year) | |
|---|---|---|---|---|---|---|---|
| Expert | 10 | 10 / 0 | 22.6 ± 1.1 | 1969 ± 467 | 6.9 ± 2.8 | 2.8 ± 2.4 | 4.1 ± 2.6 |
| Middle | 10 | 9 / 1 | 22.5 ± 0.8 | 894 ± 175 | 4.8 ± 1.7 | 1.1 ± 0.8 | 1.3 ± 0.8 |
| Novice | 10 | 9 / 1 | 21.7 ± 1.2 | NA | 2.8 ± 0.6 | 1.4 ± 1.0 | NA |
-
Numerics from fourth (age) to last columns denote mean ± SD. PE, programming experience; JE, JAVA experience; CPE, competitive programming experience. Significant differences were observed between PE of expert-novice, middle-novice; CPE of expert-middle (two-sample t test, p < 0.05 FDR-corrected).
Раздражители
Для этого исследования 72 фрагмента кода написанные на Java были собраны из открытого набора кодов предоставленного AIZU ONLINE JUDGE (http://judge.u-aizu.ac.jp/onlinejudge/); онлайн-система оценки, в которой перечислены многие проблемы программирования, и каждый может представить свой собственный исходный код для ответа на эти проблемы онлайн. Мы выбрали четыре функциональные категории (category) и одиннадцать подчиненных конкретных алгоритмов (subcategory) на основе двух популярных учебников по компьютерным алгоритмам (Cormen et al., 2009; Sedgewick and Wayne, 2011; подробное описание см. На рис. 1а, расширенные данные рис. 1-1Сначала мы искали в открытом наборе кода фрагменты кода Java, реализующие один из выбранных алгоритмов, и нашли 1251 кандидата. Причины, по которым мы сосредоточились на Java в этом исследовании , заключались в том, что этот язык был одним из самых известных языков программирования, и предыдущие исследования fMRI на программистах также использовали фрагменты кода Java в качестве экспериментальных стимулов (Siegmund et al., 2014, 2017; Peitek et al., 2018aЧтобы удовлетворить ограничению размера экрана в МРТ-сканере, мы исключили фрагменты кода с количеством строк >30 и максимальным количеством символов в строке > > 120. Из всех оставшихся фрагментов мы создали набор из 72 фрагментов кода с минимальными отклонениями этих чисел строк и символов, чтобы минимизировать визуальные вариации в качестве экспериментальных стимулов; среднее и SD числа строк и максимальное количество символов в строке составили 26,4 ± 2,4 и 59,3 ± 17,1 соответственно. В наборе кодов 18 фрагментов каждый принадлежал к одному из классов категорий и шесть фрагментов каждый принадлежал к одному из классов подкатегорий, за исключением класса линейного поиска с двенадцатью фрагментами (подробную статистику по каждой категории и классу подкатегорий см. В расширенных данных рис. 1-2). Стили отступов фрагментов кода были нормализованы путем замены табуляционного пространства двумя пробелами, а пользовательские функции были переименованы в нейтральные, такие как “function1”, поскольку некоторые функции явно указывали свои алгоритмы (например, фрагменты, см. расширенные данные рис. 1-3Мы проверили, что все фрагменты кода не имеют синтаксической ошибки и работают правильно без ошибок во время выполнения.

Система управления проектами канбан доска Worksection
Экспериментальное проектирование. А, иерархия категорий, используемых в данном исследовании. Категория и подкатегория представляют собой абстрактную функциональность и конкретные алгоритмы, соответственно, основанные на двух популярных учебниках программирования. Каждый фрагмент кода, используемый в этом исследовании, принадлежал к одному классу подкатегорий и соответствующему классу категорий. Б, задача категоризации программы. После перекрестного представления фиксации в течение 2 с фрагмент кода Java отображался в течение 10 с белым текстом без какой-либо подсветки синтаксиса. Затем испытуемые отвечали на категорию данного фрагмента кода нажатием кнопки. С, Обзор структуры декодирования. Данные МРТ были собраны у 30 испытуемых с различным уровнем знаний программирования, когда они выполняли задачу категоризации программ. Цельномозговой прожекторный анализ (Kriegeskorte et al., 2006) был использован для изучения потенциальных локусов опыта программирования. Для каждого местоположения прожектора линейно-ядерный SVM-классификатор (декодер) обучался на многосекторных шаблонах для классификации категорий или подкатегорий заданных фрагментов кода Java.
Экспериментальное проектирование
Эксперимент фМРТ состоял из шести отдельных пробегов (9 мин 52 С для каждого пробега). Каждый запуск содержал 36 испытаний задачи категоризации программы (Рис. 1Б) плюс одно фиктивное испытание, чтобы избежать нежелательных эффектов нестабильности сигнала МРТ. Мы использовали 72 фрагмента кода в качестве стимулов, и каждый фрагмент был представлен трижды в течение всего эксперимента (всего 216 испытаний), но один и тот же фрагмент появлялся только один раз в ходе выполнения. Мы использовали PsychoPy (версия 1.85.1; Peirce, 2007) для отображения фрагментов кода в Белом тексте и сером фоне без подсветки синтаксиса, чтобы минимизировать визуальные вариации. В каждом испытании задач категоризации программы фрагмент кода Java отображался в течение 10 С после перекрестного представления фиксации в течение 2 С. Затем испытуемые отвечали в течение 4 с, нажимая кнопки, расположенные под правой рукой, чтобы указать, какой класс категории был наиболее правдоподобным для фрагмента кода, и все данные ответа автоматически собирались для расчета индивидуальной поведенческой производительности. Для уточнения критериев классификации перед началом эксперимента было дано краткое объяснение по каждому классу категорий. Порядок представления фрагментов кода был псевдослучайным при балансировке количества экземпляров для каждого класса категории в разных запусках. Соответствующие кнопки для каждого варианта ответа также были рандомизированы по всем испытаниям, чтобы избежать увязки конкретного выбора ответа с конкретным движением пальца. Испытуемым разрешалось сделать перерыв между пробежками и в любое время прекратить эксперимент по фМРТ.
Все испытуемые прошли два дополнительных сеанса, названных “тренинг” и “пост-МРТ”, вне МРТ-сканера, используя портативный компьютер и Психопию для отображения исходного кода стимулов. Тренинг проводился в течение 10 дней перед экспериментом фМРТ, чтобы смягчить потенциальные путаницы, вызванные незнанием задачи. Сеанс состоял из трех отдельных запусков с той же задачей категоризации программ, что и эксперимент фМРТ. В качестве стимулов на тренировке использовался другой набор из 72 фрагментов кода Java, отличный от тех, что использовались в эксперименте МРТ, который охватывал те же алгоритмы; каждый фрагмент был представлен один или два раза за весь сеанс, но один и тот же фрагмент не появлялся дважды во время выполнения. Сеанс пост-МРТ проводился в течение 10 дней после эксперимента фМРТ для оценки индивидуальных способностей в категоризации подкатегорий и состоял из двух отдельных запусков с использованием того же набора кодов, что и эксперимент фМРТ. Перед началом сеанса пост-МРТ мы объяснили испытуемым существование подкатегорий и оценили, распознают ли они классы подкатегорий во время эксперимента фМРТ с помощью вопросника. Задачи классификации программ в сеансе после МРТ выполнялись по той же процедуре, что и сеанс фМРТ. В каждом испытании фрагмент кода Java отображался в течение 10 С после перекрестной презентации фиксации в течение 2 с. Затем в течение 4 секунд испытуемым предлагалось классифицировать данный фрагмент кода из двух или трех вариантов классов подкатегорий в соответствии с его высшей категорией, например, “пузырьковая сортировка”, “вставка сортировки” и “выбор сортировки” отображались при представлении фрагмента в категории “сортировка”. Мы рассчитали поведенческую эффективность как отношение числа попыток с правильным ответом ко всем испытаниям; оставшиеся без ответа испытания, то есть отсутствие ввода кнопки в фазе ответа, рассматривались как “неправильные” для этого расчета. Поведенческие показатели на уровне вероятности составили 25% на тренировках и экспериментах с фМРТ и 37,25% на сеансах после МРТ с поправкой на несбалансированное число вариантов ответа. Опять же, эти два дополнительных сеанса проводились вне МРТ-сканера, другими словами, каждый испытуемый проводил только один эксперимент с МРТ-сканированием.
Сбор данных МРТ
Данные МРТ были собраны с помощью 3-Теслового сканера Siemens MAGNETOM Prisma с 64-канальной головной катушкой, расположенной в CiNet. Т2*-взвешенных многоканальный градиентных Эхо-ЭПИ последовательности были выполнены для приобретения функциональных изображений, охватывающих весь мозг [время повторения (TR) - с = 2000 МС, время Эхо (те) = 30 мс, Угол поворота = 75°, поле зрения (FOV) = 192 x 192 мм2, толщина среза 2 мм, нарезать ГАП = 0 мм, размер воксела = 2 x 2 x 2.01 мм3, многополосный коэффициент = 3]. На Т1-взвешенных намагниченности подготовленные быстрого приобретения с градиент-Эхо последовательности и выполняется приобрести штраф-структурные образы на всю голову (ТР = 2530 МС, te = 3.26 мс, Угол поворота = 9°, поле зрения = 256 x 256 мм2, толщина среза = 1 мм, нарезать ГАП = 0 мм, размер воксела = 1 x 1 x 1 мм3).
Предварительная обработка данных МРТ
Мы использовали инструментарий статистического параметрического картографирования (SPM12; http://www.fil.ion.ucl.ac.uk/spm/) для предварительной обработки. Первые восемь сканирований в фиктивных испытаниях для каждого запуска были отброшены, чтобы избежать нестабильности сигнала МРТ. Функциональные сканы были выровнены с первым томом в четвертом запуске, чтобы удалить артефакты движения. Затем они были скорректированы по времени среза и совместно зарегистрированы на структурном изображении Т1 всей головы. Как анатомические, так и функциональные изображения были пространственно нормализованы в стандартном пространстве 152-мозгового среднего шаблона Монреальского неврологического института и пересчитаны до размера вокселя 2 x 2 x 2 мм3 МРТ-сигналы на каждом вокселе были высокочастотно отфильтрованы с периодом отсечки 128 С для удаления низкочастотных дрейфов. Толстая маска серого вещества была получена из нормализованных анатомических изображений всех испытуемых для выбора вокселов внутри нейрональной ткани с помощью SPM Masking Toolbox (Ridgway et al., 2009). Для каждого субъекта независимо друг от друга мы затем установили общую линейную модель (GLM) для оценки параметров воксельного уровня (?) связывание записанных МРТ-сигналов и условий представления исходного кода в каждом испытании. Фазы фиксации и реакции в каждом испытании явно не моделировались. Модель также включала параметры перестройки движения для регрессии изменений сигнала из-за движения головы. Наконец, было получено 216 карт оценки ? (36 испытаний x шесть запусков) на каждого испытуемого и использовано в качестве входных данных для последующего многомерного анализа паттернов.
Анализ многосекционных паттернов
Мы использовали полномозговой прожекторный анализ (Kriegeskorte et al., 2006) для изучения наличия значительных погрешностей декодирования с помощью набора инструментов декодирования (версия 3.99; Hebart et al., 2015) и LIBSVM (версия 3.17; Chang and Lin, 2011Сферический прожектор радиусом в четыре вокселя, охватывающий сразу 251 воксель, систематически перемещался по всему мозгу, и точность декодирования определялась количественно на каждом месте расположения прожектора. Классификатор машины опорных векторов линейного ядра (SVM) был обучен и оценен с использованием процедуры кросс-валидации leave-one-run-out, которая итеративно обрабатывала данные в одном прогоне для тестирования, а другие-для обучения. В каждом сгибе обучающие данные сначала масштабировались до нулевого среднего и единичной дисперсии с помощью z-преобразования, а тестовые данные масштабировались с использованием оценочных параметров масштабирования. Затем мы применили уменьшение выбросов, используя [-3, +3] в качестве значений отсечки, и все масштабированные сигналы, большие, чем верхняя отсечка, или меньшие, чем нижняя отсечка, были установлены на ближайшее значение этих пределов. Классификатор SVM был обучен с тремя кандидатами параметров стоимости [0.1, 1, 10], которые контролируют компромисс между максимизацией маржи и допуском скорости неправильной классификации на этапе обучения, и лучший параметр был выбран путем поиска сетки во вложенных кросс-валидациях. Кандидаты на выборку границ выбросов и стоимостных параметров были выбраны на основе расчетной вычислительной нагрузки и документов используемых инструментов. В частности, мы здесь приняли относительно небольшой набор кандидатов параметров из-за ограничения высокой вычислительной нагрузки анализа прожектора. Наконец, обученный классификатор предсказывал категорию или подкатегорию видимого исходного кода на основе пропущенных тестовых данных, а точность декодирования вычислялась как отношение правильных классификаций ко всем классификациям. Обратите внимание, что при декодировании подкатегорий использовались скорректированные веса затрат на неправильную классификацию, чтобы компенсировать несбалансированное число экземпляров в разных классах подкатегорий.
Процедуры обучения и оценки проводились независимо для каждого испытуемого, и для каждого испытуемого была получена карта точности декодирования всего мозга. Затем мы провели анализ второго уровня для изучения значимости точности декодирования и корреляций между индивидуальной точностью декодирования и поведенческими характеристиками. Для этого карты точности декодирования были пространственно сглажены с использованием гауссовского ядра полной ширины 6 мм при половинном максимуме (FWHM) и подвергнуты анализу случайных эффектов, реализованному в SPM12. В ходе анализа была проверена значимость точности декодирования на уровне группы и коэффициента корреляции Пирсона между точностью индивидуального декодирования и поведенческими характеристиками. Для проверки точности декодирования использовался относительно строгий статистический порог воксельного уровня Р < 0,05 с поправкой на семейную ошибку (FWE) и стандартный порог воксельного уровня Р < 0,001 с поправкой на кластерный уровень Р < 0.05 фонда,-поправил был использован для корреляции тестов. В качестве нулевых гипотез были приняты точность на уровне вероятности (25% при декодировании категорий и 9,72% при декодировании подкатегорий; с поправкой на несбалансированное число примеров) и нулевая корреляция. Кроме того, полученные в результате значимые карты прожектора, то есть карта точности декодирования и карта корреляции с поведенческими характеристиками, были наложены на единую кортикальную поверхность шаблонного мозга ICBM152 с помощью BrainNet viewer (Xia et al., 2013Мы выполнили это наложение, чтобы идентифицировать центры прожекторов, которые имели как достаточную информацию для представления функциональных категорий исходного кода, так и значительную корреляцию между индивидуальными поведенческими характеристиками и точностью декодирования.
Доступность данных и кода
Экспериментальные данные и код, использованные в настоящем исследовании, доступны из нашего репозитория: https://github.com/Yoshiharu-Ikutani/DecodingCodeFromTheBrain -да.
Результаты
Поведенческие данные
Мы оценили взаимосвязь между принятой референцией опыта программирования и поведенческими показателями в задаче категоризации программ. Достоверная корреляция наблюдалась между частотой Аткодирования [среднее значение = 954,3, SD = 864,6] и поведенческими показателями в экспериментах фМРТ [среднее значение = 76,0, SD = 13,5 (%)], r = 0,593, p = 0,0059, n = 20 (Рис.2а). Корреляция оставалась значимой, если мы включали поведенческие характеристики не имеющих рейтинга (т. е. новичков) в качестве субъектов с нулевым рейтингом; r = 0,722, p = 0,000007, n = 30. Кроме того, мы обнаружили положительную корреляцию между частотой AtCoder и поведенческими показателями при категоризации подкатегорий в экспериментах после МРТ [среднее значение = 65,9, SD = 17,0 ( % )], r = 0,688, p = 0,0008, n = 20 (Рис. 2Б). Значимая корреляция также оставалась значимой, если мы включали испытуемых, не являющихся держателями ставок; r = 0,735, p = 0,000004, n = 30. Из всех поведенческих данных мы, безусловно, пришли к выводу, что поведенческие показатели по задаче категоризации программ существенно коррелируют с опытом конкурентного программирования. Полученные поведенческие данные позволили нам изучить потенциальную связь между выдающимися результатами экспертов и паттернами мозговой активности, измеренными с помощью фМРТ, когда испытуемые выполняли эту лабораторную задачу.

Рисунок 2.
Корреляции между поведенческой эффективностью и показателем компетентности в программировании. А, точечная диаграмма поведенческих характеристик классификаций категорий по отношению к значениям принятой экспертной ссылки (т. е. скорости кодирования ATC). Б, точечная диаграмма поведенческих характеристик классификаций подкатегорий по отношению к значениям одной и той же экспертной ссылки. Каждая точка представляет собой отдельный предмет. Значимость коэффициентов корреляции (r) обозначалась как *p < 0,05 и **p Сплошные линии указывают на подобранную линию регрессии, оцененную по всем данным объекта.
Мультивоксельные паттерны активности, связанные с опытом программирования
Сначала мы рассмотрели, как можно декодировать функциональные категории исходного кода из мозговой активности программистов. На рис. 3 визуализируются центры прожекторов, которые показали значительно более высокую точность декодирования, чем вероятность, оцененную по всем предметным данным с использованием относительно строгого статистического порога всего мозга (уровень вокселя p < 0.05 фонда-коррекцией). На рисунке показано, что значительная точность декодирования наблюдалась в широких областях двусторонней затылочной коры, теменной коры, задней и вентральной височной коры, а также двусторонней лобной коры вокруг IFGs. Учитывая полученный результат, мы подтвердили, что функциональные категории исходного кода представлены в широко распределенных областях мозга, а кортикальные представления каждого класса категорий линейно разделимы простым SVM-классификатором.

Рисунок 3.
Точность декодирования для функциональной категории исходного кода. Значимые местоположения прожекторов оцениваются по всем предметным данным (N = 30). Тепловые цветные воксели обозначают центры прожекторов со значительной точностью декодирования (уровень вокселя Р См. расширенные данные на рис. 3-1 для распределения точности декодирования пиков воксельного уровня. Визуализация поверхности мозга проводилась с помощью программы BrainNet viewer версии 1.61 (Xia et al., 2013).
Чтобы связать кортикальное представление исходного кода с индивидуальным опытом программирования, мы исследовали линейную корреляцию между поведенческими характеристиками и точностью декодирования для каждого местоположения прожектора. На рис. 4а визуализированы центры прожекторов,показавшие достоверно высокие коэффициенты корреляции с использованием порогов воксельного уровня Р < 0,001 нескорректированного и кластерного уровня Р < 0.05 фонда-коррекцией. Мы наблюдали значимые корреляции в областях билатеральной IFGs pars triangularis (IFG Tri), правой верхней лобной извилины (SFG), левой IPL, левой MTG и нижней височной извилины (IT); см. визуализацию ширины среза, показанную на Рис. 4Б и в таблице 2 для списка значимых кластеров. В этом корреляционном анализе правый IFG Tri показал самый высокий пиковый коэффициент корреляции. Эти результаты показали, что кортикальные репрезентации в различных областях мозга, расположенных в основном в лобной, теменной и височной коре, были значительно связаны с выдающимися поведенческими характеристиками экспертов в задаче категоризации программ. Напротив, кортикальные репрезентации в билатеральной затылочной коре, включая ранние зрительные области, не демонстрировали значимой корреляции с индивидуальными поведенческими характеристиками, в то время как значительная точность декодирования широко наблюдалась в коре, показанной на рис .3.
- Вид встроенный
- Просмотр всплывающего окна
Таблица 2
Кластеры, демонстрирующие значимые корреляции между поведенческими характеристиками и точностью декодирования категорий (уровень вокселя p < 0,001 и уровень кластера p)

Рисунок 4.
Корреляционный анализ на основе прожекторов между поведенческими характеристиками и точностью декодирования. А, расположение прожекторов, показывающих значительные корреляции. Значимость определялась порогом воксельного уровня Р < 0,001 и кластерного уровня Р B, Срезная визуализация значимых кластеров с помощью bspmview (http://www.bobspunt.com/software/bspmview). С, корреляция между поведенческими характеристиками и точностью декодирования. Каждая точка представляет собой отдельные данные субъекта. Для всех значимых кластеров и пиковых корреляций см. таблицу 2 SMG, супрамаргинальная извилина; IPL, нижняя теменная долька; MTG, средняя височная извилина; IT, нижняя височная извилина; SFG, верхняя лобная извилина; MFG, средняя лобная извилина; IFG Tri, нижняя лобная извилина pars triangularis; IFG Orb, нижняя лобная извилина pars orbitalis; MCC, медиальная поясная кора.
Два предыдущих анализа отдельно показали, где существуют значительные погрешности декодирования и существенно ли они коррелируют с поведенческими характеристиками. Чтобы получить более достоверные доказательства для кортикальных представлений, связанных с опытом программирования, мы объединили эти два анализа и определили центры прожекторов, которые обладали достаточной информацией для представления функциональных категорий исходного кода и их точности декодирования, значительно коррелирующей с индивидуальными поведенческими характеристиками. В частности, две значимые карты прожектора, то есть карта точности декодирования и карта корреляции с поведенческими характеристиками, были наложены на одну кортикальную поверхность, чтобы исследовать наложение между ними. В результате мы обнаружили 1205 прожекторных центров (равных 0,79%), которые сохранились как от статистических порогов точности декодирования, так и от корреляции с поведенческими характеристиками; они показаны красными точками на Рис. 5а. Выжившие прожекторные центры наблюдались в основном в билатеральной IFG Tri, левой IPL, левой супрамаргинальной извилине (SMG), левой MTG/IT и правой MFG, как показано на Рис. 5Б. Эти результаты выявили тесную связь между превосходными поведенческими характеристиками опытных программистов и улучшением точности декодирования в этих семи областях мозга.
- Скачать рисунок
-

Рисунок 5.
Выявление прожекторных центров, которые показали как значительную точность декодирования, так и значительную корреляцию с индивидуальными поведенческими характеристиками. А, точечная диаграмма результатов прожектора. по оси x показаны значения t ,рассчитанные на основе точности декодирования всех объектов в каждом месте расположения прожектора. y-ось указывает коэффициенты корреляции между точностью декодирования и поведенческими характеристиками. Красные точки обозначают прожекторы, показывающие как значительную точность декодирования, так и корреляцию, в то время как синие и черные обозначают только те, которые показали значительную точность декодирования или корреляции. Незначительные прожекторы были окрашены в серый цвет. Наблюдаемые распределения точности декодирования и корреляций показаны соответственно в верхней и правой частях рисунка, сопровождаемые нулевыми распределениями, рассчитанными методом рандомизированного моделирования. Б, Расположение центров прожекторов, которые показали как значительную точность декодирования, так и значительную корреляцию с индивидуальными поведенческими характеристиками.
Кортикальные представления информации о подкатегориях
Затем мы исследовали, где мы могли бы декодировать подкатегорию исходного кода из мозговой активности программистов, чтобы исследовать более тонкие корковые представления. В нашем эксперименте испытуемые отвечали сортировкой, когда им были представлены фрагменты кода, реализующие один из трех различных алгоритмов сортировки: пузырьковый, вставочный и селекционный (Рис. 1аЭтот когнитивный процесс можно рассматривать как процесс обобщения, который включает различные, но сходные алгоритмы (подкатегорию) в более общий класс функциональности (категорию). Кроме того, некоторые психологи указывали, что эксперты специально демонстрируют высокие поведенческие характеристики в категориях подчиненного уровня, а также в категориях базового уровня (Tanaka and Taylor, 1991). Фактически, мы наблюдали, что способность дифференцировать классы подкатегорий существенно коррелирует с опытом программирования в конкурентном программировании (Рис. 2БЭто наблюдение подразумевает, что детальное различие функциональных возможностей исходного кода может быть представлено в паттернах мозговой активности программистов. Точность декодирования подкатегорий может быть коррелирована с опытом программирования, хотя они классифицировали только классы категорий, а не подкатегории данных фрагментов кода, и существование классов подкатегорий никогда не было обнаружено до конца эксперимента fMRI.
Мы использовали прожекторный анализ с той же настройкой, что и в предыдущем анализе, чтобы выявить пространственное распределение значительной точности декодирования подкатегорий и значимых корреляций с поведенческими характеристиками. На рис. 6 показаны центры прожекторов, которые показали значительно более высокую точность декодирования подкатегорий, чем случайность (9,72%; с поправкой на несбалансированные экземпляры), используя порог уровня вокселя p Линейная корреляция между точностью декодирования подкатегорий и индивидуальными поведенческими характеристиками была затем оценена с использованием пороговых значений уровня вокселя p < 0,001 некорригированный и кластерный уровень p < 0,05 FWE-скорректированный (рис. 7). В результате только кластер слева SMG и STG показал значимую корреляцию; пиковый коэффициент корреляции наблюдался в левом STG. Наконец, мы интегрировали результаты декодирования и корреляционного анализа подкатегории и подтвердили, что 120 прожекторных центров (равных 0,08%) слева SMG и STG сохранились как от статистических порогов точности декодирования, так и от корреляции с поведенческими характеристиками (рис. 8а, красные точки). Эти результаты позволяют предположить, что кортикальные представления тонких функциональных категорий на левом SMG и STG могут играть важную роль в достижении продвинутого уровня знаний программирования, хотя эти представления явно не требуются задачами.
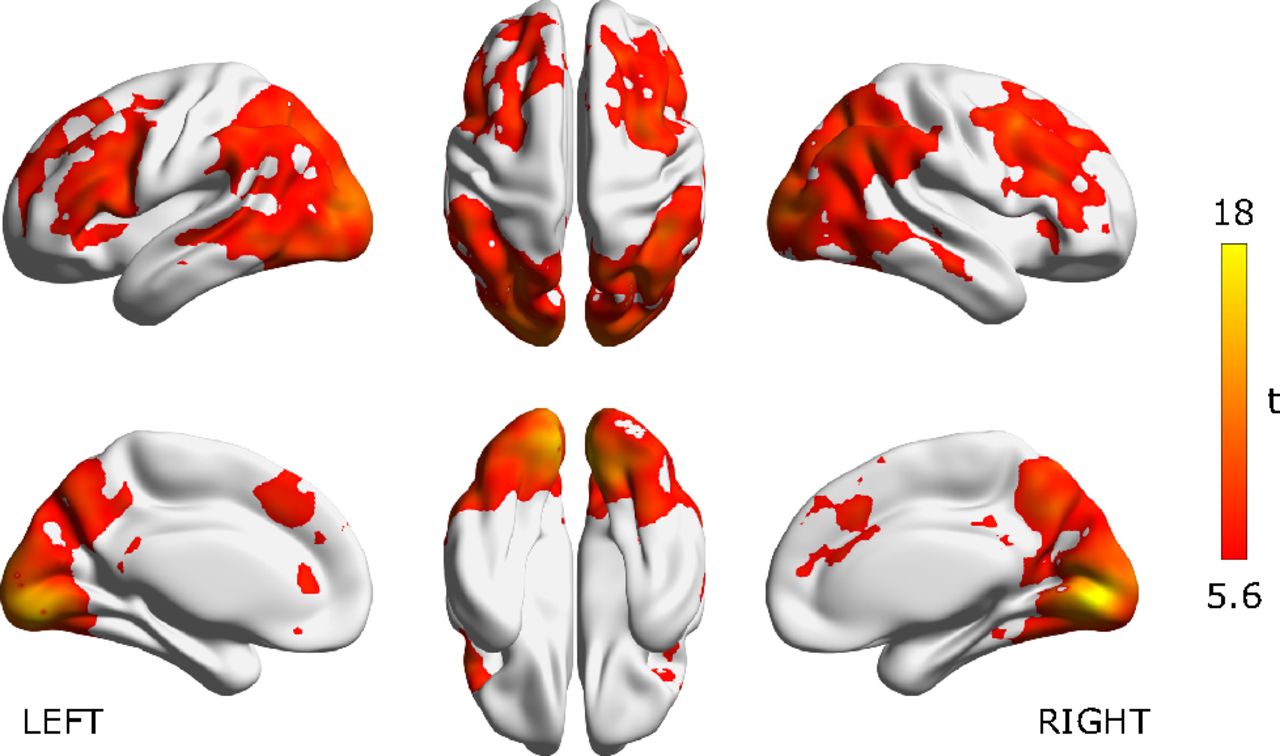
Рисунок 6.
Точность декодирования для подкатегории исходного кода. Местоположения прожекторов, демонстрирующие значительную точность декодирования подкатегорий, чем вероятность, оцененная по всем предметным данным (N = 30). Тепловые цветные воксели обозначают центры прожекторов со значительной точностью декодирования подкатегорий (уровень вокселя p Распределение точности декодирования пиковых подкатегорий воксельного уровня см. в расширенных данных рис. 6-1.

Рисунок 7.
Корреляционный анализ на основе прожектора между поведенческими характеристиками и точностью декодирования подкатегорий. А, расположение прожекторов, показывающих значительные корреляции. Значимость определялась порогом воксельного уровня Р < 0,001 и кластерного уровня Р B, Срезная визуализация значимых кластеров. C, Корреляция между поведенческими характеристиками и точностью декодирования. Каждая точка представляет собой отдельные данные субъекта. Только один кластер (экстент = 501 воксель) имел значимую корреляцию в этом анализе, и здесь были показаны три Пиковые корреляции в кластере. СТГ, верхняя височная извилина.

Рисунок 8.
Выявление прожекторных центров, которые показали как значительную точность декодирования подкатегорий, так и значительную корреляцию с индивидуальными поведенческими характеристиками. A, точечная диаграмма результатов прожектора; ось x показывает значения t, вычисленные из точности декодирования всех объектов в каждом месте расположения прожектора; y-ось указывает коэффициенты корреляции между точностью декодирования подкатегорий и поведенческими характеристиками. Красные точки обозначают прожекторы, показывающие как значительную точность декодирования, так и корреляцию, в то время как синие и черные обозначают только те, которые показали значительную точность декодирования или корреляции. Незначительные прожекторы были окрашены в серый цвет. Наблюдаемые распределения точности декодирования подкатегорий и корреляций показаны соответственно в верхней и правой частях рисунка, сопровождаемые нулевыми распределениями, рассчитанными методом рандомизированного моделирования. B, Расположение центров прожекторов, которые показали как значительную точность декодирования подкатегорий, так и значительную корреляцию с индивидуальными поведенческими характеристиками.
Обсуждение
Мы показали, что функциональные категории исходного кода могут быть декодированы из мозговой активности программистов, измеренной с помощью фМРТ. Точность декодирования на двустороннем IFG Tri, левом IPL, левом SMG, левом MTG и IT, а также правом MFG была достоверно коррелирована с индивидуальными поведенческими характеристиками при выполнении задачи категоризации программы. Кроме того, точность декодирования подкатегории слева SMG и STG также сильно коррелировала с поведенческими характеристиками, в то время как представления подчиненного уровня не были непосредственно вызваны выполнением задач. Наши результаты выявили связь между выдающимися достижениями опытных программистов и предметно-специфическими корковыми репрезентациями в этих областях мозга, широко распределенных в лобной, теменной и височной коре.
Предыдущих МРТ исследований, посвященных программисты были направлены на то, характеризующий как программирование деятельности, таких как программа понимания и обнаружения ошибок, которые происходят в мозгу (Зигмунд и соавт., 2014, 2017; Флойд и соавт., 2017; Castelhano и соавт., 2019; Peitek и соавт., 2018a,б). В исключительных случаях исследовательское исследование сообщило, что полужирная сигнальная различимость между пониманием кода и текста отрицательно коррелировала с баллами GPA участников в университете (Floyd et al., 2017Однако связь между баллами GPA и опытом программирования была неоднозначной, и наблюдаемая корреляция была относительно небольшой (r = -0,44, p = 0,016, n = 29). Наша цель в настоящем исследовании была существенно иной: мы искали нейронные основы опыта программирования, которые способствуют выдающимся достижениям опытных программистов. Для достижения этой цели мы приняли объективно определенный эталон знаний в области программирования и набрали группу субъектов, охватывающих широкий спектр знаний в области программирования. Несмотря на разницу в целях исследования, подмножество областей мозга, указанных в этом исследовании, было аналогично тем, которые были определены в предыдущих исследованиях фМРТ программистов (Siegmund et al., 2014, 2017; Peitek et al., 2018aВ частности, это исследование связывало левые IFG, MTG, IPL и SMG с опытом программирования, в то время как предыдущие исследования связывали их с процессами понимания программ. Эта общность может предполагать, что и процессы понимания программы, и связанные с ними знания зависят от одного и того же набора областей мозга.
Потенциальные роли указанных областей мозга в нашем исследовании должны быть рассмотрены для ориентации будущих исследований на программную деятельность и опыт. Во-первых, левый IFG Tri и левый задний MTG часто участвуют в семантическом отборе/извлечении задач (D?monet et al., 1992; Thompson-Schill et al., 1997; Simmons et al., 2005; Price, 2012). Несколько исследований показали, что эти две области чувствительны к когнитивным требованиям для целенаправленного направления поиска семантических знаний (Rodd et al., 2005; Kuhl et al., 2007; Whitney et al., 2011Участие этих двух регионов в наших выводах может быть вызвано сходными требованиями, предъявляемыми к поиску функциональных категорий программ, и предполагает, что более высокий уровень знаний в области программирования связан со способностями целенаправленного поиска знаний. Во-вторых, многие нейробиологи показали, слева IPL и СМГ должны быть функционально связанных с нарушением чтения слов (Bookheimer и соавт., 1995; Philipose и соавт., 2007; Stoeckel и соавт., 2009) и эпизодической памяти извлечение (Вагнер с соавт., 2005; Vilberg и Ругг, 2008; О'Коннор и соавт., 2010Обе когнитивные функции потенциально связаны с задачей категоризации программы, используемой в нашем эксперименте. Визуальное чтение слов может быть естественным образом задействовано, поскольку исходный код состоит из многих англоязычных слов, и испытуемые могут активно вспоминать ранее приобретенные воспоминания, чтобы компенсировать недостаточные подсказки, потому что у них было всего 10 секунд, чтобы классифицировать данный фрагмент кода. Вовлеченность левого IPL и SMG в опыт программирования предполагает, что опытные программисты могут обладать различными стратегиями чтения и/или больше зависеть от поиска предметной памяти, чем новички. Кроме того, набор IFG и IPL часто обсуждался вместе как фронтально-теменная сеть, и они часто проявляют синхронную активность в широком спектре задач (Watson and Chatterjee, 2012; Ptak et al., 2017). Важно отметить, что недавнее исследование фМРТ программистов показало связь между пониманием программ и лобно-теменной сетью, которая была функционально связана с формальным логическим выводом (Liu et al., 2020). Наши результаты согласуются с этими выводами, подразумевая, что лобно-теменная сеть играет ключевую роль в процессах понимания программ экспертами.
Другие новые находки в настоящем исследовании включали потенциальное вовлечение левой ИТ-группы, правой МФГ и правой МФГ три с опытом программирования. Важно отметить, что эти области не были определены предыдущими исследованиями, посвященными взаимосвязи между мозговой активностью и процессами понимания программ неопытными испытуемыми (Siegmund et al., 2014, 2017; Floyd et al., 2017; Peitek et al., 2018a), предполагая, что регионы могут быть более связаны с процессами понимания программ экспертами-программистами. Потому что левой он хорошо известен функцию на высоком уровне обработки визуальных данных, включая распознавание слов и категоричность объект представления (Chelazzi и соавт., 1993; Нобре и соавт., 1994; Kriegeskorte и соавт., 2008); наши результаты предполагают, что на высоком уровне зрительной коры, в опытные программисты могут быть доработаны по их опыт обучения реализовать быстрее программе понимания процесса. С другой стороны, наблюдаемая карта включает в себя левую IFG Tri, IPL и MTG/IT (Рис. 4а) может быть связана с семантической системой в мозге (Patterson et al., 2007; Binder et al., 2009). Наши результаты могут свидетельствовать о том, что мозг опытного программиста рекрутирует аналогичную языковую сеть как для обработки естественного языка, так и для понимания программы. В отличие от этого, первичная визуальная область показала значительную точность декодирования, но не коррелировала с опытом программирования. Первичная зрительная область в основном отражает примитивные визуальные признаки, такие как цвет, контраст, пространственная частота (Tong, 2003), в то время как вычисления в зрительной коре высокого уровня характеризуются как восходящими (то есть тем, как стимулы визуально представляются), так и нисходящими (как представление используется для когнитивной задачи) эффектами (Kay and Yeatman, 2017). Предыдущие исследования показали, что тонко настроенные представления в зрительной коре высокого уровня, а не в первичной зрительной области, могут быть связаны с визуальным опытом (Bilali? et al., 2016) и навыком чтения Kubota et al. (2019) В нашем эксперименте первичная зрительная область представляла собой большое количество визуальной информации независимо от уровня знаний программирования, поскольку всем испытуемым был представлен один и тот же набор фрагментов кода, вызывающих сходные визуальные паттерны на их сетчатке. Таким образом, информация в первичной визуальной области была достаточной для декодирования классов категорий и подкатегорий, но точность декодирования не обязательно должна была коррелировать с индивидуальными поведенческими характеристиками. Между тем, объем информации, представленной в зрительной коре высокого уровня, может быть модулирован индивидуальным опытом программирования. В соответствии с предыдущими экспертными исследованиями наши результаты предполагают, что опыт в понимании программ может быть в основном связан с визуальным восприятием высокого уровня.
Правые MFG и IFG Tri функционально связаны с стимулируемым контролем внимания (Corbetta et al., 2008; Japee et al., 2015). Участие этих двух регионов предполагает, что программисты с высоким уровнем знаний в области программирования могут использовать различные стратегии внимания, чем менее квалифицированные. Кроме того, дополнительные вовлечения областей правого полушария у экспертов являются общими для всех экспертных исследований. Например, шахматные эксперты (Bilali? et al., 2011) и эксперты по счетам (Tanaka et al., 2002; Hanakawa et al., 2003) показали дополнительную вовлеченность области правого полушария при выполнении их предметно-специфических задач. Некоторые исследования фМРТ также предполагают, что такие сдвиги активации от левого к правому полушарию могут быть связаны с изменениями когнитивной стратегии экспертов (Bilali? et al., 2011; Tanaka et al., 2012). Изменения когнитивной стратегии неоднократно наблюдались в сравнениях между опытными и начинающими программистами: основной характеристикой является переход от восходящего (или текстуального) к нисходящему (или целеполагаемому) пониманию программы, которое становится возможным благодаря знаниям экспертов в конкретной предметной области (Koenemann and Robertson, 1991; Fix et al., 1993; Von Mayrhauser and Vans, 1995). Участие правых MFG и IFG Tri, наблюдаемых в этом исследовании, может быть связано с такими когнитивными стратегическими различиями между программистами в задаче категоризации программ. С другой стороны, активация в префронтальной и теменной областях, включая двустороннюю IFG/MFG и левую IPL, была связана со степенью когнитивных потребностей (Harvey et al., 2005Хотя в нашем исследовании не было прямого показателя когнитивных потребностей по категориям, разница в поведенческих характеристиках для каждой категории может быть ключом к оценке степени когнитивных потребностей по категориям. Мы использовали одностороннюю ANOVA для проверки разницы в средних поведенческих характеристиках между категориями, но никаких существенных различий не было обнаружено ни для одной группировки (см. расширенные данные рис. 2-1Хотя эти результаты не дают прямого указания на когнитивные требования по всем категориям, у нас нет никаких положительных доказательств того, что степень когнитивных требований оказала значительное влияние на наблюдаемую точность декодирования.
Расширенные Данные Рис. 2-1
Поведенческие характеристики каждой категории в эксперименте фМРТ. Числа с 3 (математика) в последних столбцах означают среднее ± SD. Однофакторный дисперсионный анализ не выявил значительных различий в поведенческих выступлений между категориями для любого группировки (эксперт, Ф(3,36) = 1.38, Р = 0.27; среднего, Ф(3,36) = 2.99, Р = 0.06; новичок, Ф(3,36) = 2.81, Р = 0.07; всех, Ф(3,116) = 2.02, Р = 0.12). Загрузите рисунок 2-1, XLSX-файл.
Расширенные Данные Рис. 3-1
Боковые графики точности декодирования пиковой категории воксельного уровня на нескольких областях мозга. Каждая точка представляет собой точность декодирования отдельного субъекта. Пунктирная линия указывает на точность уровня вероятности (25%). SMG, супрамаргинальная извилина; IPL, нижняя теменная долька; MTG, средняя височная извилина; IT, нижняя височная извилина; IFG Tri, нижняя лобная извилина pars triangularis. Загрузите рисунок 3-1, EPS-файл.
Расширенные Данные Рис. 6-1
Боковые графики точности декодирования пиковой подкатегории воксельного уровня на нескольких областях мозга. Каждая точка представляет собой точность декодирования отдельного субъекта. Пунктирная линия указывает на точность уровня вероятности (9,72%). SMG, супрамаргинальная извилина; IPL, нижняя теменная долька; MTG, средняя височная извилина; IT, нижняя височная извилина; IFG Tri, нижняя лобная извилина pars triangularis. Пользовательский программный код. Пользовательский код MATLAB, используемый для анализа декодирования в данной статье. Загрузите рисунок 6-1, EPS-файл.
Наши результаты связывали опыт программирования с точностью декодирования не только категории, но и подкатегории, хотя категоризация подчиненного уровня явно не требовалась для выполнения задачи. Мы наблюдали, что индивидуальные поведенческие характеристики достоверно коррелировали с точностью декодирования подкатегорий на левом СТГ и СМГ. Эти две области функционально связаны с прелексической и фонологической обработкой в понимании естественного языка (D?monet et al., 1992; Moore and Price, 1999; Burton et al., 2001Интересно, что мы также обнаружили значимую корреляцию между поведенческими характеристиками и точностью декодирования категорий во временных областях (левая MTG и IT), связанных с большей семантической обработкой (Rodd et al., 2005; Whitney et al., 2011; Price, 2012). Если бы эти функциональные интерпретации могли быть адаптированы к процессам понимания программы, то было бы интуитивно понятно, что подчиненные конкретные понятия (т. е. подкатегория) исходного кода обрабатываются в левом STG/SMG, а более семантически абстрактные понятия (т. е. категория) представлены в левом MTG/IT. В дальнейшем, Мкртычян и др. (2019) связали STG, MTG и IFG с обработкой абстрактных понятий в своем обзоре эффектов конкретности, подразумевая, что представления в этих трех регионах могут отражать относительные различия в абстрактности между категорией и подкатегорией в нашем исследовании. Эти интерпретации могут предложить гипотезу о том, что мозг опытного программиста имеет иерархическую систему семантической обработки для получения ментальных представлений исходного кода для нескольких уровней абстракции.
Наша структура декодирования, специализированная для функциональной категории исходного кода, может быть расширена за счет последних достижений подходов декодирования/кодирования в сочетании с распределенными векторами признаков (Diedrichsen and Kriegeskorte, 2017). Несколько исследователей продемонстрировали фреймворки для декодирования произвольных объектов с использованием набора вычислительных визуальных признаков, представляющих категории целевых объектов (Horikawa and Kamitani, 2017), а также для декодирования перцептивных переживаний, вызванных естественными фильмами, с использованием распределенных представлений на основе слов (Nishida and Nishimoto, 2018Другие исследования также использовали распределенные представления на основе слов для систематического отображения семантической избирательности в коре головного мозга (Huth et al., 2016; Pereira et al., 2018). Между тем исследователи в области анализа программ предложили распределенные представления исходного кода на основе абстрактного синтаксического дерева (AST; Alon et al., 2019a; Zhang et al., 2019). Alon et al. (2019b), например, представили непрерывные распределенные векторы, представляющие функциональность исходного кода с использованием нейронной сети AST и path-attention. Сочетание современных подходов к декодированию/кодированию и распределенных представлений исходного кода может позволить нам построить вычислительную модель понимания программы, которая связывает семантические особенности исходного кода с перцептивным опытом программистов.
Ограничения исследования
Результаты, полученные в ходе настоящего исследования, были ограничены конкретным типом экспертных знаний по программированию, оцениваемых с помощью экспертной справки и лабораторного задания, использованного в эксперименте. В частности, мы изучили способность семантически классифицировать исходный код, который коррелирует с опытом программирования, чтобы выиграть высокие баллы в конкурентных соревнованиях по программированию. Возможно, существует качественный разрыв между опытом в области конкурентного программирования и практической/промышленной разработкой программного обеспечения. Например, способность писать эффективные программы на языке SQL может быть явным показателем другого типа опыта программирования, но это исследование не охватывало такой тип опыта программирования. Задача категоризации программ, использованная в этом исследовании, в первую очередь оценивала умение быстро и точно распознавать алгоритмы, что было одним из аспектов широкого спектра когнитивных навыков, составляющих опыт программирования. Мы считали, что оцениваемый навык связан с пониманием программы, а также связан с навыками рефакторинга и отладки кода, поскольку эти процессы требуют глубокого понимания алгоритмов или того, как работает код, в то время как его отношение к написанию кода в данном исследовании не оценивается. Таким образом, наши результаты не должны предполагать связь между нейронными коррелятами, выявленными здесь, и другими типами опыта программирования, которые не могут быть исследованы в этом эксперименте. Однако это также факт, что мы не можем исследовать нейронные основы программирования экспертизы без четкого определения показателя экспертизы и лабораторной задачи, которые хорошо вписываются в общие ограничения экспериментов фМРТ. Чтобы смягчить потенциально неизбежные последствия, вызванные этим ограничением, мы приняли объективно определенный эталон знаний в области программирования, который непосредственно отражает фактические результаты программистов, и набрали группу субъектов, охватывающих широкий спектр знаний в области программирования. Это исследование может стать основой для будущих исследований, направленных на изучение нейронных основ навыков программирования и связанных с ними способностей.
Наш эксперимент, который был разработан, чтобы соответствовать общим ограничениям измерения фМРТ, может включать в себя несколько оговорок к внешней валидности. Во-первых, мы использовали относительно небольшие фрагменты кода с 30 строками максимум из-за ограничения размера экрана МРТ. Поведенческие характеристики исходного кода на системном уровне в исследовании не оценивались. Таким образом, обобщение наших результатов на экспертизу в области системного понимания программ не было гарантировано. Во-вторых, в этом исследовании в качестве экспериментальных стимулов использовались только фрагменты кода Java. Результаты, полученные в ходе экспериментов, могут быть искажены выбранным языком программирования, например, Python имеет более естественный синтаксис, чем Java, и может вызвать большую активацию в связанных с языком областях мозга. В то время как недавнее исследование фМРТ изучало мозговую деятельность, вызванную кодом, написанным на двух языках программирования (Python и ScratchJr; Ivanova et al., 2020), до сих пор неясно, может ли выбор конкретного языка программирования изменить паттерн мозговой активности эксперта. Ожидается, что в будущей работе будет рассмотрена взаимосвязь между опытом программирования и типами языков программирования (например, процедурные и функциональные языки).
Еще одной потенциальной проблемой настоящего исследования является несправедливый гендерный баланс в исследуемой популяции. В то время как 95 программистов заполнили нашу анкету для регистрации в качестве кандидатов-испытуемых, была найдена только одна женщина-кандидат среднего уровня и ноль женщин-экспертов (см. Материалы и методы, предметы). Исходя из этой ситуации, мы признали неизбежную гендерную предвзятость в нашей целевой популяции. Чтобы должным образом охватить широкий спектр программной экспертизы, мы были вынуждены отказаться от поддержания гендерного баланса на каждом уровне экспертизы. Однако в нескольких исследованиях фМРТ сообщалось о возможных гендерных различиях в поведении, когнитивных функциях и данных нейровизуализации (David et al., 2018; Huang et al., 2020Результаты, полученные в ходе этого исследования, могут быть предвзятыми из-за гендерного дисбаланса исследуемой популяции. Будущая работа должна исследовать, будут ли обнаружены поведенческие и когнитивные различия между программистами-мужчинами и женщинами. Кроме того, хотя размер нашей выборки был определен в соответствии с предыдущими экспертными исследованиями, десять субъектов для каждого уровня экспертизы не были большой популяцией и были недостаточны для того, чтобы показать статистически значимые результаты между различными классами экспертизы. Поэтому упоминать о сравнении между новичком-середняком или средним специалистом следует с большой осторожностью. Более крупные образцы были бы желательны в будущих репродуктивных или последующих исследованиях.
Наши результаты показывают связь между опытом программирования и корковыми представлениями исходного кода программы в мозге программиста. Мы продемонстрировали, что функциональные категории исходного кода могут быть декодированы из мозговой активности программиста, и точность декодирования в семи областях лобной, теменной и височной коры была значительно коррелирована с индивидуальными поведенческими характеристиками. Полученные результаты дополнительно предполагают, что кортикальные представления тонких функциональных категорий (подкатегорий) на левом SMG и STG могут быть связаны с опытом программирования продвинутого уровня. Хотя исследования на нейронной основе опыта программирования все еще находятся в зачаточном состоянии, мы считаем, что наше исследование расширяет существующую литературу по человеческому опыту в области программирования, демонстрируя, что программисты верхнего уровня имеют специфические для предметной области корковые представления.
Подтверждения
Благодарности: мы благодарим Такао Накагаву и Хидетаке Увано за полезные комментарии по первоначальному проекту исследования.
Сноски
-
Авторы не декларируют никаких конкурирующих финансовых интересов.
-
Эта работа была поддержана грантом JSP KAKENHI с номерами JP15H05311, JP16H05857, JP16H06569, JP17H01797, JP18K18108, JP18K18141, JP18J22957 и грантом JST ERATO с номером JPMJER1801.
Это статья открытого доступа , распространяемая на условиях международной лицензии Creative Commons Attribution 4.0, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии, что оригинальная работа должным образом атрибутирована.
Источник: school.irinakoval.ru