
Филипп, в мире Kaggle более известный как Psi, стал кандидатом наук, получил диплом с отличием в области информатики в Техническом университете Граца, а также получил степень магистра в области разработки программного обеспечения и управления бизнесом. У Филиппа несколько достижений, в том числе многократные победы и высшие места на Kaggle, несколько научных наград, в том числе за лучшую работу на знаменитой Всемирной веб-конференции.
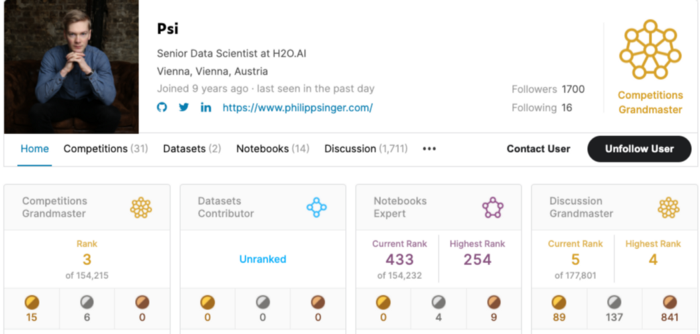
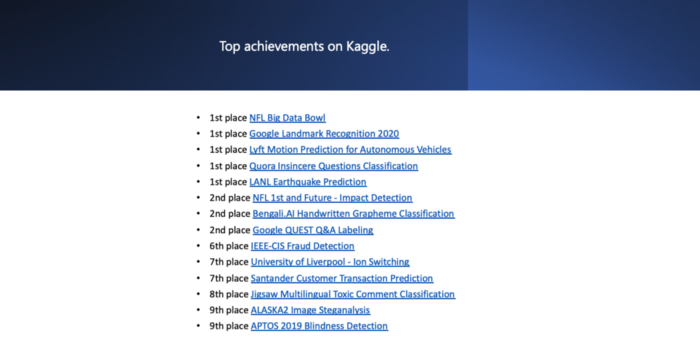
В настоящее время он занимает третье место в мире в рейтинге соревнований Kaggle. Это одновременно впечатляет и вдохновляет. Одно из самых заметных достижений Филиппа – победа на Втором ежегодном турнире по большим данным NFL вместе с другим дата-сайентистом H2O.ai Дмитрием Гордеевым. Более 2000 дата-сайентистов со всего мира соревновались на Kaggle, чтобы спрогнозировать результаты стремительной игры. Филипп Сингер и Дмитрий Гордеев получили главный приз – 50 000 долларов США за их подход к задаче.

У вас есть докторская степень в области компьютерных наук. Почему вы в качестве карьеры выбрали науку о данных, а не занимались научными исследованиями?
Филипп: Я получил степень доктора философии [кандидата наук] компьютерных наук в Техническом университете Граца в Австрии и был занят в исследованиях в Германии. За время своей научной карьеры я затронул множество разных тем в области науки о данных и опубликовал множество научных работ и статей на известных конференциях и в журналах. После я должен был стать профессором, это интриговало меня. Однако, хотя я люблю преподавать, я хотел углубиться в более прикладную работу, то есть хотел, чтобы моя работа имела большее влияние, чем то влияние, которое возможно в исследованиях. Это побудило меня заняться наукой о данных в качестве карьеры. Надо сказать, я до конца насладился докторской степенью и многому научился, но теперь я также рад быть в авангарде науки о данных и машинного обучения, играть по-настоящему важную роль в H2O.ai.
Как начался ваш путь на Kaggle, что поддерживало вас на пути к гроссмейстерству?
В последнее время вы уничтожили таблицу лидеров Kaggle, добились впечатляющих результатов, последний из которых – первое место на NFL и второе в Future – Impact Detection. Как вы подходите к решению таких проблем, как идёте так хорошо?
Филипп: Люди часто спрашивают меня, как выиграть соревнования Kaggle; я не думаю, что есть какой-то секретный соус, чтобы побеждать везде. Большой успех на Kaggle основывается на опыте, желании прикоснуться к чему-то новому, о чём, на первый взгляд, вы мало что знаете. Со временем я собрал особый универсальный набор инструментов, который содержит строительные блоки каждого соревнования, в котором я участвовал. Например, я понимаю, как правильно настроить кросс-валидацию, какие библиотеки задействовать в моделях, как правильно подбирать модели, отслеживать их производительность и т. п. Так что у меня освобождается больше времени, чтобы сосредоточиться на новых для меня и важных аспектах недавних соревнований. после каждого соревнования я всегда стараюсь улучшить свой рабочий процесс, чтобы повысить эффективность и способность конкурировать с соперниками.
Большой успех на Kaggle основывается на опыте, желании прикоснуться к чему-то новому, о чём, на первый взгляд, вы мало что знаете.
Как вы решаете, в каких соревнованиях участвовать?
Филипп: Я в основном пытаюсь решать новые типы задач или участвовать в соревнованиях, которые кажутся интересными в отношении данных или проблемы, которую нужно решить. Иногда я испытываю удачу в более стандартных соревнованиях, чтобы понимать состояние искусства Data Science, которое меняется каждую неделю.
Как вы обычно подходите к задаче на Kaggle? Есть ли какие-нибудь любимые ресурсы по ML (массовые открытые онлайн-курсы, блоги и т. д.), которыми вы хотите поделиться с сообществом?
Филипп: Я стараюсь прибегать к уже накопленному мной арсеналу методов, инструментов и опыта, а затем пытаюсь исследовать конкретную проблему. Это означает, что я изучаю предыдущие решения аналогичных проблем на Kaggle и читаю соответствующие статьи. Лучший способ изучить проблему – учиться на практике.
В каких конкретных областях вы работаете как дата-сайентист в H2O.ai?

Филипп: Моя роль в H2O.ai очень многогранна. Я регулярно участвую в проектах, ориентированных на клиентов, и моя задача – опираясь на опыт, поддерживать проекты в области Data Science. Кроме того, будучи гроссмейстерами Kaggle, мы всегда стараемся использовать наш опыт и знания о последних достижениях, чтобы постоянно улучшать наши продукты и разрабатывать новые передовые прототипы и решения. Это означает, например, что мы предлагаем новые функции в Driverless AI, разрабатываем приложения ИИ в Wave , демонстрируя новые методы и весь конвейер решений Data Science.
Расскажите о лучшем из того, что вы узнали на Kaggle и применяете в работе на H2O.ai?
Филипп: На Kaggle вы узнаете, как создавать надёжные модели, которые хорошо обобщаются и не слишком подвержены переобучению. На Kaggle это важно, потому что вам нужно хорошо работать с невидимыми, закрытыми данными. Это означает, что вы многое узнаете о надёжной перекрёстной проверке и о других аспектах данных, таких как сдвиги в распределении функций, или некоторые других важных аспектах. Я могу хорошо приспособить эти знания в своей работе на H2O.ai, поскольку они также являются неотъемлемой частью наших продуктов. Опираясь на наш опыт и знания, мы хотим, чтобы ML наших клиентов было надёжным.
Область Data Science стремительно развивается. Как вам удается быть в курсе всех последних событий?
Филипп: Чтобы быть в курсе последних событий, я в основном использую Kaggle; это отличный фильтр новых методов, которые либо работают с практическими и прикладными проблемами, либо не работают. Обычно надёжные методы выживают, а ненадёжные методы, которые работают лишь от случая к случаю, отфильтровываются. В то же время я слежу за известными исследователями и практиками в Твиттере и на других платформах.
Есть ли какие-то конкретные области или проблемы, в которых вы хотели бы применить свой опыт в области машинного обучения?

Филипп: Я не держу в голове ничего конкретного; обычно я стараюсь удивляться интересным проблемам, которые возникают либо на работе, либо в Kaggle. Очень важно вникать в проблемы, которые на первый взгляд не кажутся вам интересными. Можно объективно взглянуть на проблему и, вероятно, обратиться к опыту, который вы приобрели решая другие проблемы, к тем данным, что у вас есть.
Несколько советов претендентам в Data Science и Kaggle, которые только начали или хотят начать свой путь в Data Science.
Филипп: Запачкайте руки, не бойтесь потерпеть неудачу и всегда стремитесь узнавать новое.
Путь Филиппа на Kaggle был весьма примечательным. Я уверен, что его путь, преданность делу и достижения станут источником вдохновения для тех, кто уже работает или пытается сделать карьеру в Data Science.