
Каждому специалисту по обработке и анализу данных, прежде чем запускать на своем наборе данных сложные алгоритмы машинного обучения, нужно исследовать и проанализировать его несколькими способами.
Начнем с определения бессерверных вычислений.
Бессерверные вычисления:
Согласно Википедии, бессерверные вычисления — стратегия организации платформенных облачных услуг, при которой облако автоматически и динамически управляет выделением вычислительных ресурсов в зависимости от пользовательской нагрузки.
Это означает, что мы, пользователи, имеем дело только с логикой. Нам не нужно беспокоиться о серверах, планировании ресурсов или масштабе операций технического обслуживания. Это не значит, что их нет, просто мы ими не занимаемся?
Что такое SQL?
Согласно Википедии, SQL — декларативный язык программирования, применяемый для создания, изменения и упорядочивания данных в реляционной базе данных.
Что такое бессерверный SQL?
Бессерверный SQL — это инструмент распределенных вычислений, который позволяет обрабатывать распределенные данные с помощью языка SQL без необходимости администрировать серверы баз данных. Если у нас есть данные, или даже "большие данные", в одном из наших озер или хранилищ, например AWS S3 или хранилище BLOB-объектов Azure, мы сможем выполнить запрос SQL на этих данных без необходимости создавать конвейер или импортировать данные в распределенные базы данных, например в Cassandra или MongoDB.
Это огромное преимущество, особенно если мы собираемся взаимодействовать с данными в автономных системах, не создавая конвейеры, или просто взглянуть на абсолютно новые данные, которые только что были добавлены в хранилище, прежде чем реплицировать или преобразовывать их, а затем сохранять в выделенную базу данных.
Как и со всеми облачными сервисами, необходимо понимать модель затрат. В бессерверной инфраструктуре мы платим за использование. То есть мы платим за объем обработанных данных.
Если выполнить запрос select * на наборе объемом 2 ТБ, мы заплатим за обработку 2 ТБ данных. Поэтому в зависимости от потребности компании или группы пул выделенных серверов может оказаться выгоднее.
Рассмотрим сценарий разведочного анализа данных с помощью бессерверного SQL
Возьмем известный набор данных нью-йоркского такси из открытых наборов данных и попробуем понять, как обстоят дела у таксопарков, в какое время дня люди вызывают такси и многое другое. Эта информация поможет нам исследовать данные.
Для бессерверного SQL я буду использовать рабочее пространство Azure Synapse. Вы можете использовать его, попробовать Big Query или присмотреться к другим инструментам.
Сначала посмотрим на данные — select top 100 вернет первые 100 строк из файла Parquet:
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet', FORMAT='PARQUET' ) AS [nyc] SELECT TOP 100 * FROM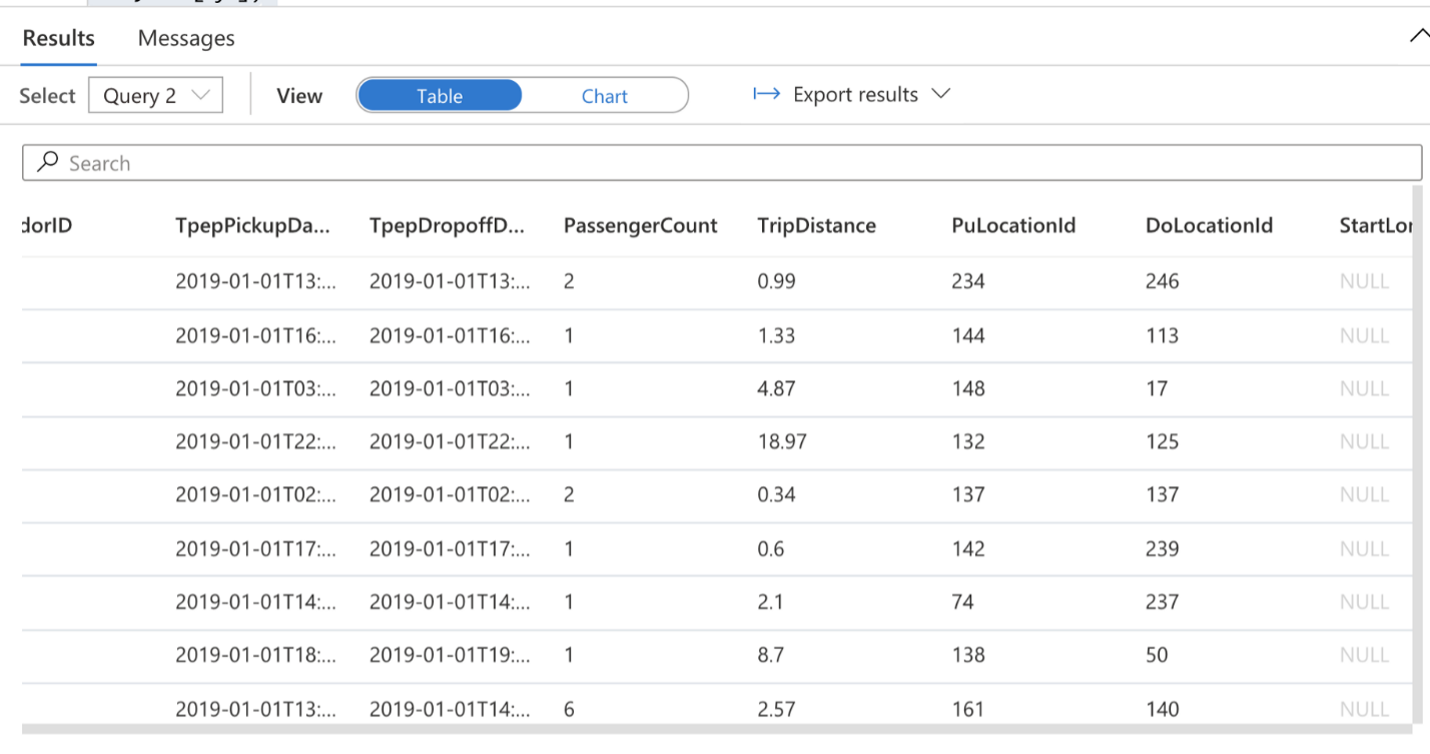
Это результаты операции select в таблице
Мы можем просматривать результат в формате таблицы или диаграммы. Диаграмма пока будет неинформативной, поскольку мы использовали простой запрос select.
Но мы уже можем начать знакомство с данными: столбцом категорий, метками и многим другим.
Посмотрим на ежегодное количество поездок в промежутке с 2014-го по 2019-й. Это даст нам общее представление о происходившем в эти годы:
SELECT YEAR(tpepPickupDateTime) AS current_year, COUNT(*) AS rides_per_year FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet', FORMAT='PARQUET' ) AS [nyc] WHERE nyc.filepath(1) >= '2014' AND nyc.filepath(1) <= '2019' GROUP BY YEAR(tpepPickupDateTime) ORDER BY 1 ASC; SELECTЗапрос
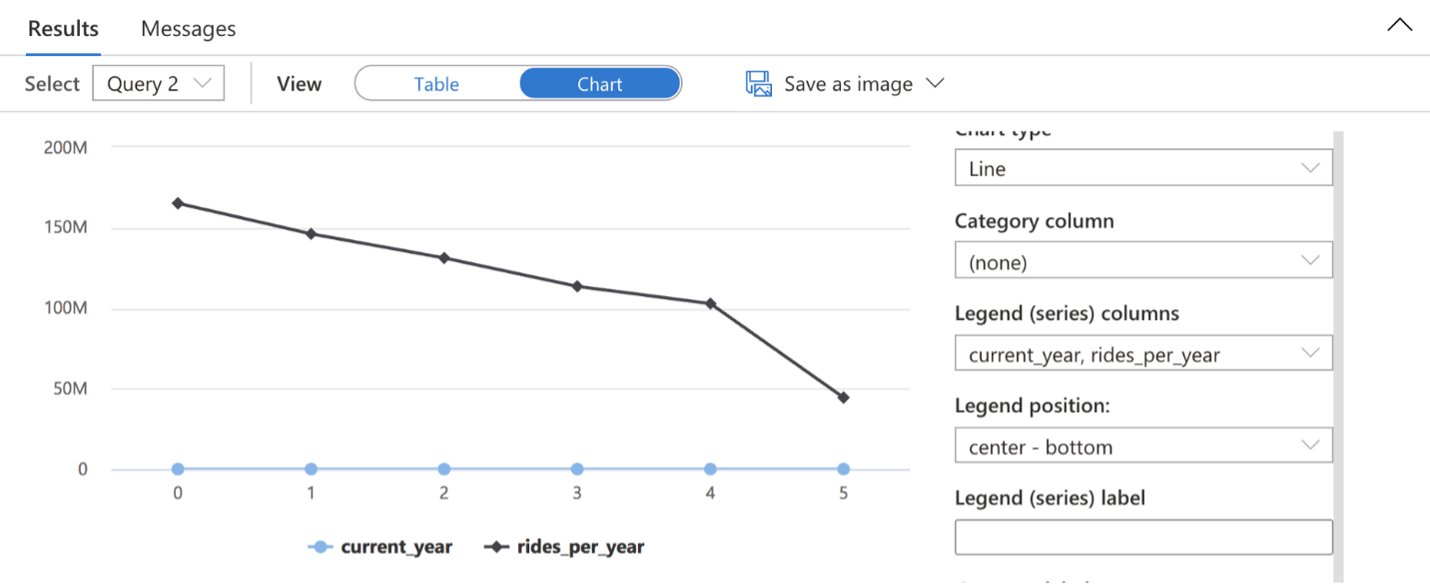
Итоговая диаграмма
Из диаграммы видно, что за эти годы пассажиры стали гораздо реже пользоваться нью-йоркским такси. Количество поездок упало со 165 миллионов в 2014 году до 44 миллионов в 2019 году.
Возможные причины: улучшение городского транспорта, например метро и автобусов, или появление новых сервисов заказа машин, таких как Uber и Lyft.
Теперь проанализируем один конкретный год:
SELECT CAST([tpepPickupDateTime] AS DATE) AS [current_day], COUNT(*) as rides_per_day FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet', FORMAT='PARQUET' ) AS [nyc] WHERE nyc.filepath(1) = '2016' GROUP BY CAST([tpepPickupDateTime] AS DATE) ORDER BY 1 ASCНа диаграмме по результатам нашего запроса мы видим падение количества поездок на выходных. Для этого я сменю представление диаграммы в соответствии с нашими потребностями:
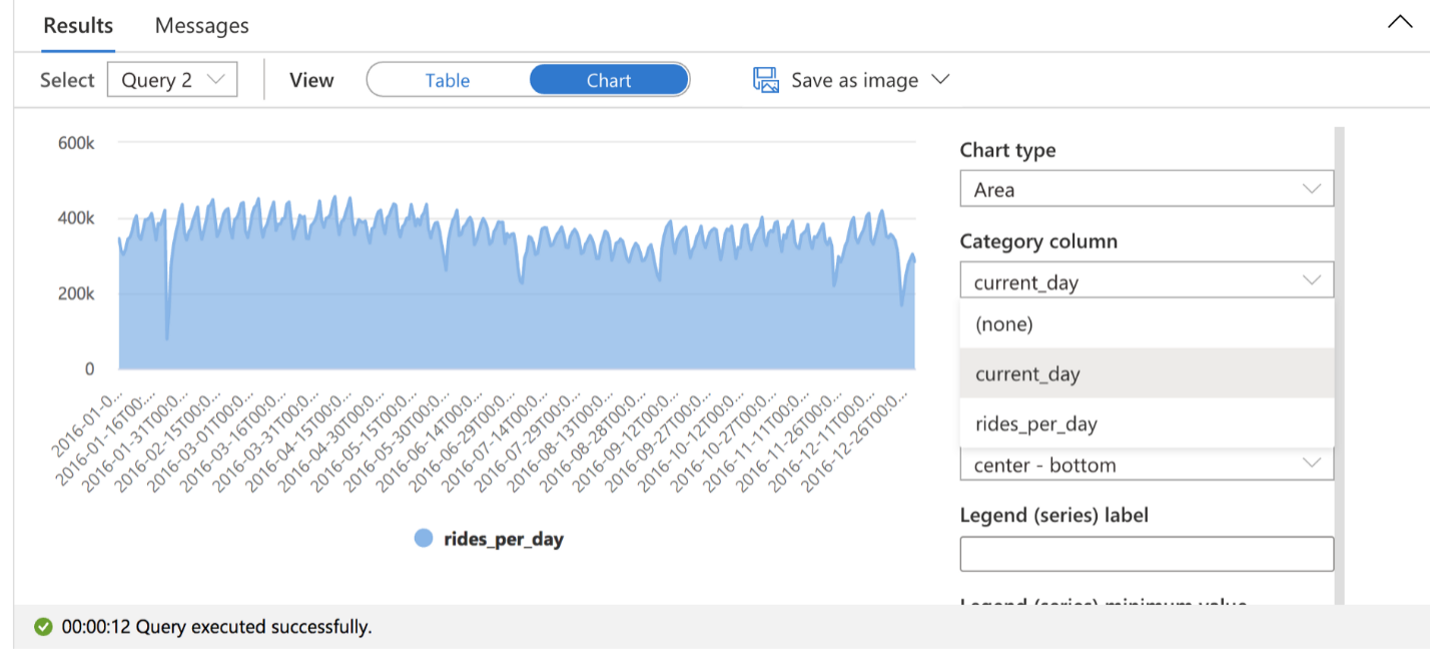
Возможно, это происходит из-за того, что люди реже вызывают такси на праздники. Поэтому мы объединим таблицу данных нью-йоркского такси с календарем праздников в США.
Все данные взяты из открытых наборов, поэтому вы тоже можете запрашивать их и работать с ними.
WITH taxi_rides AS ( SELECT CAST([tpepPickupDateTime] AS DATE) AS [current_day], COUNT(*) as rides_per_day FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet', FORMAT='PARQUET' ) AS [nyc] WHERE nyc.filepath(1) = '2016' GROUP BY CAST([tpepPickupDateTime] AS DATE) ), public_holidays AS ( SELECT holidayname as holiday, date FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet', FORMAT='PARQUET' ) AS [holidays] WHERE countryorregion = 'United States' AND YEAR(date) = 2016 ) SELECT * FROM taxi_rides t LEFT OUTER JOIN public_holidays p on t.current_day = p.date ORDER BY current_day ASC WITH taxi_rides ASЭтот запрос можно разделить на три запроса:
1. Define taxi_ride temp table
На этом шаге мы получаем данные из озера данных, выбираем, приводим информацию о датах, считаем поездки за 2016 год, а затем группируем поездки по дням.
taxi_rides AS ( SELECT CAST([tpepPickupDateTime] AS DATE) AS [current_day], COUNT(*) as rides_per_day FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet', FORMAT='PARQUET' ) AS [nyc] WHERE nyc.filepath(1) = '2016' GROUP BY CAST([tpepPickupDateTime] AS DATE) )2. Define public_holiday temp table:
На этом шаге мы получаем данные из озера, но уже из другой таблицы, а затем выбираем праздники в США за 2016 год.
public_holidays AS ( SELECT holidayname as holiday, date FROM OPENROWSET( BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet', FORMAT='PARQUET' ) AS [holidays] WHERE countryorregion = 'United States' AND YEAR(date) = 2016 )3. Объединяем:
Используем оператор with в начале запроса, а затем в третьем запросе обращаемся к обеим временным таблицам и объединяем их, используя столбец даты в качестве ключа.
SELECT * FROM taxi_rides t LEFT OUTER JOIN public_holidays p on t.current_day = p.date ORDER BY current_day ASCВыполнив запрос на бессерверной платформе SQL, мы получим диаграмму, в которой сможем настраивать столбцы, чтобы лучше исследовать и понимать данные:
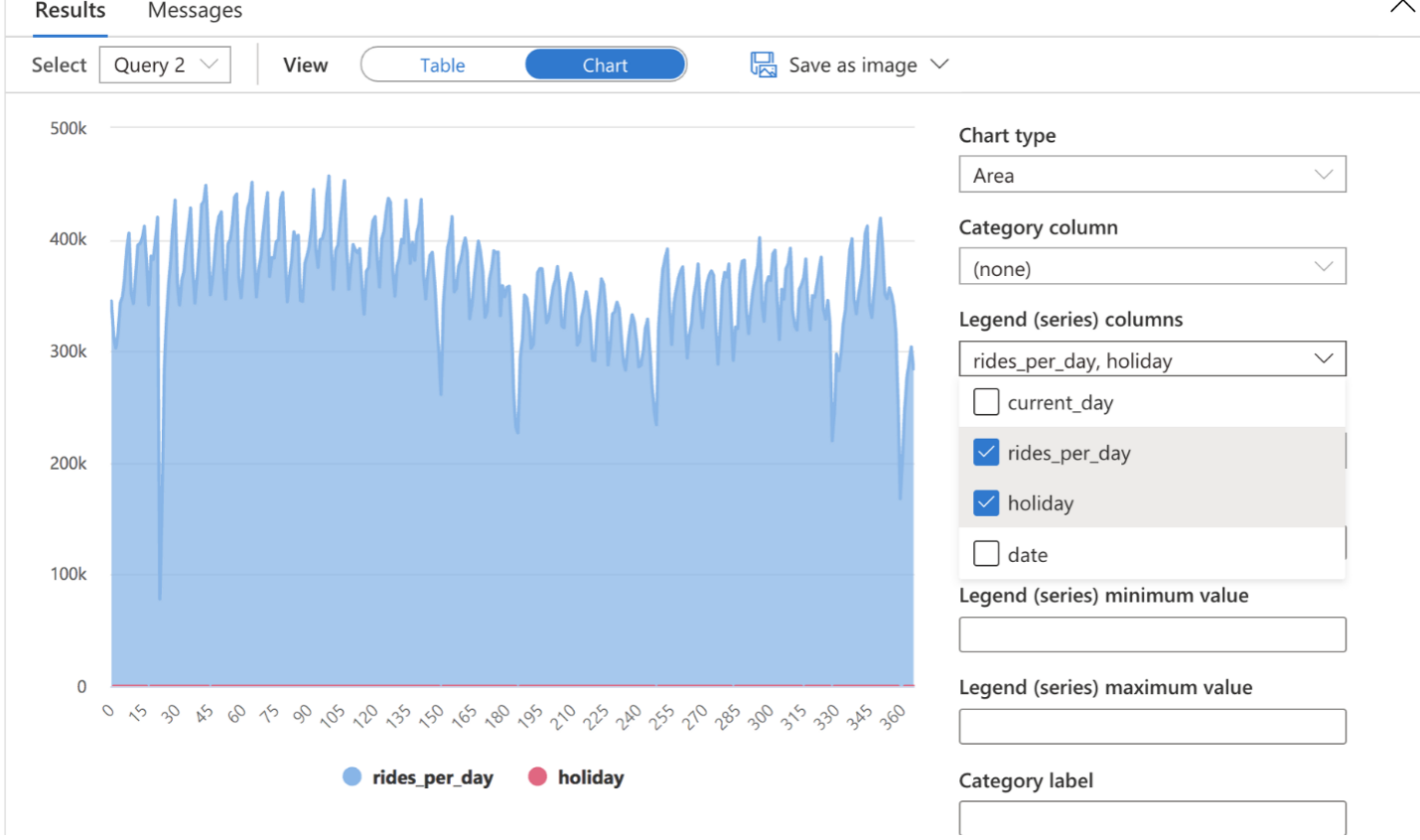
Любые данные, которые находятся в озере данных — открытом или корпоративном, — можно удобно исследовать с помощью бессерверного SQL.
Впоследствии мы сможем сохранить созданное представление данных и поделиться им с коллегами или загрузить образ, нажав кнопку Загрузить как образ.
Кнопка "Сохранить как образ"
Хотите узнать больше?
Приглашаю вас на полностью бесплатный мастер-класс, который я проведу 7 декабря вместе с Саймоном Уитли. Мы покажем шаг за шагом, как извлечь больше выводов из данных нью-йоркского такси:
Мы проанализируем:
-
расстояние поездок;
-
чеки с разбивкой по позициям;
-
типы тарифов;
-
способы оплаты;
-
количество пассажиров (со слов водителей).
Все, что вам нужно, — зарегистрироваться по этой ссылке.
Примечания
-
Бессерверный SQL не создан для аналитики в реальном времени и рабочих нагрузок, требующих ответа в пределах миллисекунд.
-
В бессерверном SQL оплата взимается за использование.
Спасибо, что дочитали. Будем рады вашим вопросам, комментариям и отзывам на @adipolak.-