Введение в градиенты и автоматическую дифференциацию
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-10-08 09:40
Автоматическая дифференциация и градиенты
Автоматическое дифференцирование полезно для реализации алгоритмов машинного обучения, таких как обратное распространение, для обучения нейронных сетей.
В этом руководстве мы обсудим способы вычисления градиентов с помощью TensorFlow, особенно при активном выполнении.
Настроить
import numpy as np import matplotlib.pyplot as plt import tensorflow as tf Вычислительные градиенты
Чтобы различать автоматически, TensorFlow должен помнить, какие операции в каком порядке выполняются во время прямого прохода. Затем, во время обратного прохода , TensorFlow просматривает этот список операций в обратном порядке для вычисления градиентов.
Ленты с градиентом
TensorFlow предоставляет API tf.GradientTape для автоматического различения; то есть вычисление градиента вычисления относительно некоторых входных данных, обычно tf.Variable s. TensorFlow «записывает» соответствующие операции, выполняемые в контексте tf.GradientTape на «ленту». Затем TensorFlow использует эту ленту для вычисления градиентов «записанного» вычисления с использованием обратного дифференцирования .
Вот простой пример:
x = tf.Variable(3.0) with tf.GradientTape() as tape: y = x**2 После того, как вы записали некоторые операции, используйте GradientTape.gradient(target, sources) чтобы вычислить градиент некоторой цели (часто потери) относительно некоторого источника (часто переменных модели).
# dy = 2x * dx dy_dx = tape.gradient(y, x) dy_dx.numpy() 6.0
В приведенном выше примере используются скаляры, но tf.GradientTape так же легко работает с любым тензором:
w = tf.Variable(tf.random.normal((3, 2)), name='w') b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b') x = [[1., 2., 3.]] with tf.GradientTape(persistent=True) as tape: y = x @ w + b loss = tf.reduce_mean(y**2) Чтобы получить градиент y по обеим переменным, вы можете передать их в качестве источников в метод gradient . Лента гибкая в отношении того, как передаются источники, и принимает любую вложенную комбинацию списков или словарей и возвращает градиент, структурированный таким же образом (см. tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b]) Градиент по отношению к каждому источнику имеет форму источника:
print(w.shape) print(dl_dw.shape) (3, 2) (3, 2)
Вот снова расчет градиента, на этот раз передающий словарь переменных:
my_vars = { 'w': tf.Variable(tf.random.normal((3, 2)), name='w'), 'b': tf.Variable(tf.zeros(2, dtype=tf.float32), name='b') } grad = tape.gradient(loss, my_vars) grad['b'] Градиенты по модели
Обычно tf.Variables собирают в tf.Module или в один из его подклассов ( layers.Layer , keras.Model ) для keras.Model контрольных точек и экспорта .
В большинстве случаев вам нужно рассчитывать градиенты относительно обучаемых переменных модели. Поскольку все подклассы tf.Module объединяют свои переменные в свойстве Module.trainable_variables , вы можете вычислить эти градиенты в нескольких строках кода:
layer = tf.keras.layers.Dense(2, activation='relu') x = tf.constant([[1., 2., 3.]]) with tf.GradientTape() as tape: # Forward pass y = layer(x) loss = tf.reduce_mean(y**2) # Calculate gradients with respect to every trainable variable grad = tape.gradient(loss, layer.trainable_variables) for var, g in zip(layer.trainable_variables, grad): print(f'{var.name}, shape: {g.shape}') dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Контроль того, что смотрит лента
Поведение по умолчанию - записывать все операции после доступа к обучаемой tf.Variable . Причины этого:
- Ленте необходимо знать, какие операции записывать при прямом проходе, чтобы вычислить градиенты при обратном проходе.
- Лента содержит ссылки на промежуточные выходы, поэтому вы не хотите записывать ненужные операции.
- Наиболее распространенный вариант использования включает вычисление градиента потерь по всем обучаемым переменным модели.
Например, следующее не может вычислить градиент, потому что tf.Tensor не «отслеживается» по умолчанию, а tf.Variable не обучается:
# A trainable variable x0 = tf.Variable(3.0, name='x0') # Not trainable x1 = tf.Variable(3.0, name='x1', trainable=False) # Not a Variable: A variable + tensor returns a tensor. x2 = tf.Variable(2.0, name='x2') + 1.0 # Not a variable x3 = tf.constant(3.0, name='x3') with tf.GradientTape() as tape: y = (x0**2) + (x1**2) + (x2**2) grad = tape.gradient(y, [x0, x1, x2, x3]) for g in grad: print(g) tf.Tensor(6.0, shape=(), dtype=float32) None None None
Вы можете перечислить переменные, за которыми следит лента, используя метод GradientTape.watched_variables :
[var.name for var in tape.watched_variables()] ['x0:0']
tf.GradientTape предоставляет перехватчики, которые дают пользователю контроль над тем, что смотрит, а что нет.
Чтобы записать градиенты относительно tf.Tensor , вам нужно вызвать GradientTape.watch(x) :
x = tf.constant(3.0) with tf.GradientTape() as tape: tape.watch(x) y = x**2 # dy = 2x * dx dy_dx = tape.gradient(y, x) print(dy_dx.numpy()) 6.0
И наоборот, чтобы отключить поведение по умолчанию при просмотре всех tf.Variables , установите watch_accessed_variables=False при создании ленты градиента. Этот расчет использует две переменные, но связывает градиент только для одной из переменных:
x0 = tf.Variable(0.0) x1 = tf.Variable(10.0) with tf.GradientTape(watch_accessed_variables=False) as tape: tape.watch(x1) y0 = tf.math.sin(x0) y1 = tf.nn.softplus(x1) y = y0 + y1 ys = tf.reduce_sum(y) Поскольку GradientTape.watch не был вызван на x0 , градиент не вычисляется относительно него:
# dy = 2x * dx grad = tape.gradient(ys, {'x0': x0, 'x1': x1}) print('dy/dx0:', grad['x0']) print('dy/dx1:', grad['x1'].numpy()) dy/dx0: None dy/dx1: 0.9999546
Промежуточные результаты
Вы также можете запросить градиенты вывода относительно промежуточных значений, вычисленных в контексте tf.GradientTape .
x = tf.constant(3.0) with tf.GradientTape() as tape: tape.watch(x) y = x * x z = y * y # Use the tape to compute the gradient of z with respect to the # intermediate value y. # dz_dx = 2 * y, where y = x ** 2 print(tape.gradient(z, y).numpy()) 18.0
По умолчанию ресурсы, удерживаемые GradientTape , освобождаются, как только вызывается метод GradientTape.gradient() . Чтобы вычислить несколько градиентов за одно вычисление, создайте ленту persistent градиента. Это позволяет многократно вызывать метод gradient() мере освобождения ресурсов при сборке мусора для объекта ленты. Например:
x = tf.constant([1, 3.0]) with tf.GradientTape(persistent=True) as tape: tape.watch(x) y = x * x z = y * y print(tape.gradient(z, x).numpy()) # 108.0 (4 * x**3 at x = 3) print(tape.gradient(y, x).numpy()) # 6.0 (2 * x) [ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape Примечания по производительности
Есть крошечные накладные расходы, связанные с выполнением операций внутри контекста градиентной ленты. Для наиболее энергичного выполнения это не будет заметной ценой, но вы все равно должны использовать ленточный контекст только в тех областях, где это необходимо.
Ленты с градиентом используют память для хранения промежуточных результатов, включая входные и выходные данные, для использования во время обратного прохода.
Для повышения эффективности некоторым операциям (например,
ReLU) не нужно сохранять свои промежуточные результаты, и они удаляются во время прямого прохода. Однако, если вы используете на своей лентеpersistent=True, ничего не сбрасывается, и ваше пиковое использование памяти будет выше.
Градиенты нескалярных целей
По сути, градиент - это операция над скаляром.
x = tf.Variable(2.0) with tf.GradientTape(persistent=True) as tape: y0 = x**2 y1 = 1 / x print(tape.gradient(y0, x).numpy()) print(tape.gradient(y1, x).numpy()) 4.0 -0.25
Таким образом, если вы запросите градиент нескольких целей, результат для каждого источника будет:
- Градиент суммы целей или, что эквивалентно
- Сумма градиентов каждой цели.
x = tf.Variable(2.0) with tf.GradientTape() as tape: y0 = x**2 y1 = 1 / x print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy()) 3.75
Точно так же, если цель (цели) не скалярны, вычисляется градиент суммы:
x = tf.Variable(2.) with tf.GradientTape() as tape: y = x * [3., 4.] print(tape.gradient(y, x).numpy()) 7.0
Это упрощает использование градиента суммы совокупных потерь или градиента суммы поэлементного расчета потерь.
Если вам нужен отдельный градиент для каждого элемента, см. Якобианы .
В некоторых случаях якобиан можно пропустить. Для поэлементного вычисления градиент суммы дает производную каждого элемента по отношению к его входному элементу, поскольку каждый элемент независим:
x = tf.linspace(-10.0, 10.0, 200+1) with tf.GradientTape() as tape: tape.watch(x) y = tf.nn.sigmoid(x) dy_dx = tape.gradient(y, x) plt.plot(x, y, label='y') plt.plot(x, dy_dx, label='dy/dx') plt.legend() _ = plt.xlabel('x') 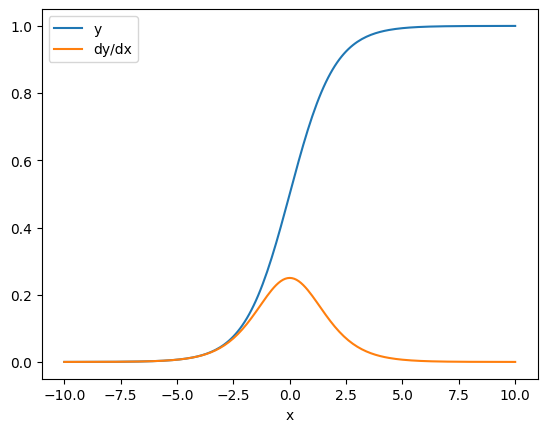
Поток управления
Поскольку ленты записывают операции по мере их выполнения, поток управления Python (например, с использованием if и while ) обрабатывается естественным образом.
Здесь разные переменные используются в каждой ветви if . Градиент подключается только к той переменной, которая была использована:
x = tf.constant(1.0) v0 = tf.Variable(2.0) v1 = tf.Variable(2.0) with tf.GradientTape(persistent=True) as tape: tape.watch(x) if x > 0.0: result = v0 else: result = v1**2 dv0, dv1 = tape.gradient(result, [v0, v1]) print(dv0) print(dv1) tf.Tensor(1.0, shape=(), dtype=float32) None
Просто помните, что сами управляющие операторы не дифференцируемы, поэтому они невидимы для оптимизаторов на основе градиентов.
В зависимости от значения x в приведенном выше примере лента либо записывает result = v0 либо result = v1**2 . Градиент по x всегда равен None .
dx = tape.gradient(result, x) print(dx) None
Получение градиента None
Когда цель не подключена к источнику, вы получите градиент None .
x = tf.Variable(2.) y = tf.Variable(3.) with tf.GradientTape() as tape: z = y * y print(tape.gradient(z, x)) None
Здесь z , очевидно, не связан с x , но есть несколько менее очевидных способов отсоединения градиента.
1. Заменил переменную на тензор.
В разделе «Контроль за тем, что смотрит лента» вы видели, что лента автоматически отслеживает tf.Variable но не tf.Tensor .
Одна из распространенных ошибок - непреднамеренная замена tf.Variable на tf.Tensor вместо использования Variable.assign для обновления tf.Variable . Вот пример:
x = tf.Variable(2.0) for epoch in range(2): with tf.GradientTape() as tape: y = x+1 print(type(x).__name__, ":", tape.gradient(y, x)) x = x + 1 # This should be `x.assign_add(1)` ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. Выполнял расчеты вне TensorFlow.
Лента не может записать путь градиента, если вычисление выходит из TensorFlow. Например:
x = tf.Variable([[1.0, 2.0], [3.0, 4.0]], dtype=tf.float32) with tf.GradientTape() as tape: x2 = x**2 # This step is calculated with NumPy y = np.mean(x2, axis=0) # Like most ops, reduce_mean will cast the NumPy array to a constant tensor # using `tf.convert_to_tensor`. y = tf.reduce_mean(y, axis=0) print(tape.gradient(y, x)) None
3. Перенести градиенты через целое число или строку.
Целые числа и строки не дифференцируются. Если путь вычисления использует эти типы данных, градиент не будет.
Никто не ожидает, что строки будут дифференцируемыми, но легко случайно создать константу или переменную int если вы не укажете dtype .
# The x0 variable has an `int` dtype. x = tf.Variable([[2, 2], [2, 2]]) with tf.GradientTape() as tape: # The path to x1 is blocked by the `int` dtype here. y = tf.cast(x, tf.float32) y = tf.reduce_sum(x) print(tape.gradient(y, x)) WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow не выполняет автоматическое преобразование типов между типами, поэтому на практике вы часто будете получать ошибку типа вместо отсутствующего градиента.
4. Получение градиентов через объект с сохранением состояния.
Состояние останавливает градиенты. Когда вы читаете из объекта с состоянием, лента может видеть только текущее состояние, а не историю, которая к нему ведет.
tf.Tensor неизменен. Вы не можете изменить тензор после его создания. У него есть значение , но нет состояния . Все операции, которые обсуждались до сих пор, также не имеют состояния: вывод tf.matmul зависит только от его входных данных.
tf.Variable имеет внутреннее состояние, свое значение. Когда вы используете переменную, считывается состояние. Вычисление градиента относительно переменной является нормальным явлением, но состояние переменной блокирует вычисления градиента от дальнейшего возврата. Например:
x0 = tf.Variable(3.0) x1 = tf.Variable(0.0) with tf.GradientTape() as tape: # Update x1 = x1 + x0. x1.assign_add(x0) # The tape starts recording from x1. y = x1**2 # y = (x1 + x0)**2 # This doesn't work. print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x2) None
Аналогичным образом итераторы tf.data.Dataset и tf.queue сохраняют состояние и останавливают все градиенты на тензорах, которые проходят через них.
Градиент не зарегистрирован
Некоторые tf.Operation зарегистрированы как tf.Operation и возвращают None . У других градиент не зарегистрирован .
На странице tf.raw_ops показано, какие низкоуровневые операции имеют зарегистрированные градиенты.
Если вы попытаетесь принять градиент через операцию с плавающей запятой, для которой не зарегистрирован градиент, лента выдаст ошибку вместо того, чтобы молча вернуть None . Таким образом вы узнаете, что что-то пошло не так.
Например, функция tf.image.adjust_contrast обертывает raw_ops.AdjustContrastv2, который может иметь градиент, но градиент не реализован:
image = tf.Variable([[[0.5, 0.0, 0.0]]]) delta = tf.Variable(0.1) with tf.GradientTape() as tape: new_image = tf.image.adjust_contrast(image, delta) try: print(tape.gradient(new_image, [image, delta])) assert False # This should not happen. except LookupError as e: print(f'{type(e).__name__}: {e}') LookupError: gradient registry has no entry for: AdjustContrastv2
Если вам нужно различать эту операцию, вам нужно либо реализовать градиент и зарегистрировать его (используя tf.RegisterGradient ), либо повторно реализовать функцию, используя другие операции.
Нули вместо None
В некоторых случаях было бы удобно получить 0 вместо None для несвязанных градиентов. Вы можете решить, что возвращать, когда у вас есть несвязанные градиенты, используя аргумент unconnected_gradients :
x = tf.Variable([2., 2.]) y = tf.Variable(3.) with tf.GradientTape() as tape: z = y**2 print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO)) tf.Tensor([0. 0.], shape=(2,), dtype=float32)
Источник: www.tensorflow.org