Учим ИИ отвечать на сообщения
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-08-12 15:00
Теория информации, разработка чат-ботов, компьютерная лингвистика

Введение
Глубокое обучение применяется во многих задачах NLP вроде перевода, добавления титров к изображениям и систем поддержки диалога. В машинном переводе оно используется для преобразования считываемого при вводе языка в нужный на выходе. То же и с диалоговыми системами, где глубокое обучение используется для генерации ответа с учётом контекста. Иначе это называется генерацией естественного языка (NLG).
Модель делится на 2 части: энкодер и декодер. Энкодер считывает входной текст и возвращает представляющий вход вектор. Этот вектор передаётся декодеру, который генерирует соответствующий текст.
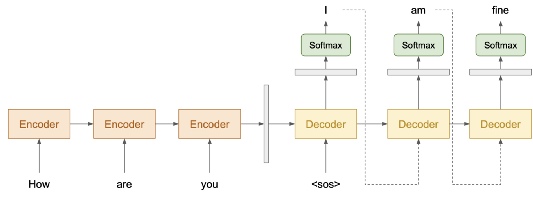
Генерация текста происходит, как правило, по одному токену. Без применения правильных техник сгенерированный ответ может быть очень обобщённым и скучным. Здесь мы познакомимся со стратегиями решения этой проблемы:
- Greedy Search (жадный поиск).
- Beam Search (лучевой поиск).
- Random Sampling (случайное сэмплирование).
- Temperature (температура).
- Top-K Sampling (сэмплирование K-верхних).
- Nucleus Sampling (ядерное сэмплирование).
Стратегии декодирования
На каждом шаге декодирования мы получаем вектор, содержащий промежуточную информацию между шагами, и применяем его к softmax-функции, преобразовывая вероятности появления каждого слова в массив.
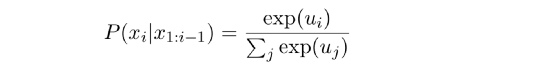
Жадный подход
Это самый простой подход. На каждом шаге просто выбирается наиболее вероятный токен.
Context: Try this cake. I baked it myself.
Optimal Response : This cake tastes great.
Generated Response: This is okay.
Однако, как мы видим, в примере выше при таком подходе может быть сформирован не самый оптимальный ответ. Так происходит из-за обучающих данных, которые зачастую используют примеры вроде That is […]. Поэтому если мы каждый раз генерируем наиболее вероятный токен, результатом может быть is вместо cake.
Лучевой поиск
Исчерпывающий поиск может решить предыдущую проблему, поскольку выполняется по всему пространству. Но он потребует существенных вычислительных ресурсов. Предположим, что у нас есть 10 000 словарей, тогда для генерации предложения длиной в 10 токенов число вариантов составляет 10??.
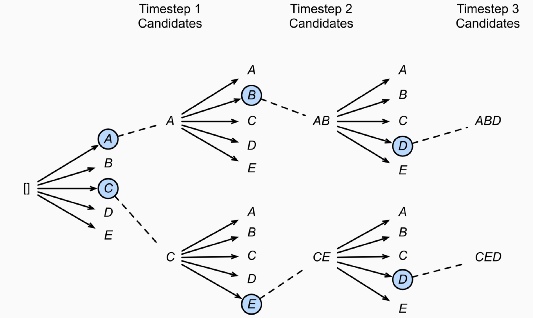
Лучевой поиск может справиться с этой проблемой. В каждом шаге он генерирует все возможные токены в список словаря. Затем он выбирает топ-B кандидатов, имеющих наивысшую вероятность. B-кандидаты переходят к следующей временной метке, затем процесс повторяется. В конце остаются только B-кандидаты. Пространство поиска составляет всего 10 000*B.
Context: Try this cake. I baked it myself.
Response A: That cake tastes great.
Response B: Thank you.
Иногда этот алгоритм выбирает даже более оптимальный ответ (Response B). В таком случае он отлично подходит по смыслу. Но представьте, что модель склонна к безопасному поведению и на большинство вариантов контекста генерирует I don’t know или Thank you. Такой бот уже нельзя считать хорошим.
Случайное сэмплирование
Как альтернативу можно рассматривать стохастический подход, позволяющий избегать обобщённости. При таком подходе мы можем сделать полезными сами вероятности каждого токена из softmax-функции, чтобы сгенерировать следующий токен.
Предположим, мы генерируем первый токен для контекста I love watching movies. На диаграмме ниже показана вероятность выбора того или иного первого слова.
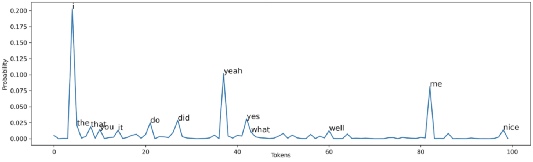
При использовании жадного подхода выбирается токен i. Тем не менее при случайном сэмплировании вероятность появления этого токена составляет около 0.2. В то же время любой токен, имеющий вероятность 0.0001, тоже может появиться. Просто это очень маловероятно.
Случайное сэмплирование с температурой
Само по себе случайное сэмплирование потенциально может сгенерировать совершенно произвольное слово. Температура повышает шансы появления наиболее вероятных токенов, снижая при этом шансы появления неподходящих. Обычно берётся диапазон 0 < temp ? 1. Заметьте, что при temp=1 никакого эффекта нет.
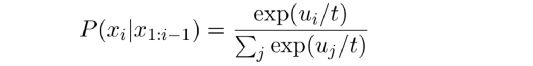
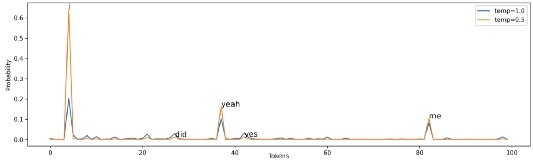
На Рис. 4 при temp=0.5 наиболее вероятные слова, такие как i, yeah, me имеют больше шансов на появление. В то же время это снижает шансы появления менее вероятных слов, хотя и не исключает их появление полностью.
Сэмплирование k-верхних
Этот вид сэмплирования используется для полного исключения появления маловероятных слов. Для генерации должны рассматриваться только токены с вероятностью k-верхних.
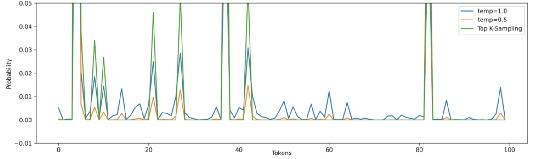
Индекс токена между 50 и 80 при применении случайного сэмплирования с температурой 0.5 или 1.0 имеет невысокую вероятность. При сэмплировании k-верхних (K=10) эти токены вообще не имеют шансов на появление. Обратите внимание, что мы можем просто совместить сэмплирование k-верхних с температурой, но вы наверняка уловили смысл, так что рассматривать это здесь мы не станем.
Такая техника сэмплирования принята во многих современных задачах генерации, поскольку её качество достаточно высоко. Она ограничена только тем, что число k-верхних слов должно определяться в самом начале. Предположим, что мы выбрали K=300. Однако в шаге декодирования модель знает, что должно быть 10 высоковероятных слов. Использование этой техники означает, что мы также рассмотрим и остальные 290 менее вероятных слов.
Ядерное сэмплирование
Этот вид сэмплирования схож с предыдущим. Вместо фокусирования на k-верхних словах ядерное сэмплирование сосредотачивается на мельчайших возможных выборках V-верхних слов таким образом, что сумма их вероятности ? p. Затем токены, не входящие в V^(p), устанавливаются как 0, а остальные повторно масштабируются, чтобы гарантировать, что они суммируются к 1.
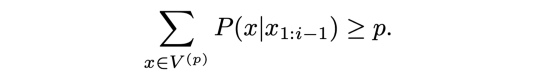
Логика такова, что если модель весьма уверена в некоторых токенах, то выборка потенциальных токенов будет мала, в противном случае токенов-кандидатов будет больше.
Модель уверена — несколько токенов имеют высокую вероятность, то есть суммы нескольких токенов достаточно, чтобы превысить p.
Модель не уверена — многие токены имеют невысокую вероятность, то есть сумма многих токенов не превышает p.
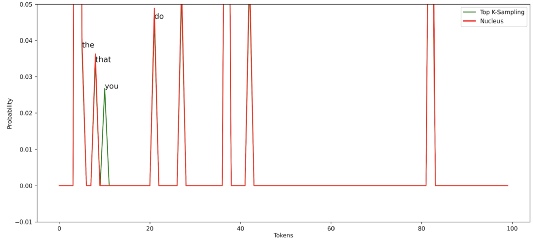
Сравнив ядерное сэмплирование (p=0.5) с сэмплированием K-верхних (K=10), мы видим, что ядерная модель не рассматривает в числе кандидатов токен you. Это говорит о том, что модель может адаптироваться к разным случаям и выбирать разное число токенов в отличие от сэмплирования K-верхних.
Краткий обзор
- Жадный поиск выбирает по одному наиболее вероятному токену за раз.
- Лучевой поиск выбирает наиболее вероятный ответ.
- Случайное сэмплирование выбирает случайно, но на основе степени вероятности.
- Температура уменьшает или увеличивает вероятности выбора.
- Сэмплирование K-верхних выбирает самые вероятные K-токены.
- Ядерное сэмплирование как будто динамически выбирает число из K.
В общем самыми популярными среди исследователей являются лучевой поиск, сэмплирование K-верхних и ядерное сэмплирование.
Заключение
Мы рассмотрели техники декодирования ответа. Их можно применять к разным задачам генерации, например, к добавлению субтитров к изображениям, машинному переводу и генерации историй. Хорошей модели с плохой техникой декодирования или плохой модели с хорошей техникой декодирования, конечно, недостаточно. Но хорошо подобранный баланс между этими составляющими уже может дать весьма интересный и полезный результат.
Читайте также:
- Худшие способы нанять хороших программистов
- 6 команд терминала для раздражающих задач
- P.S. Дорогой рефакторинг, нам нужно на время расстаться
Источник: m.vk.com