Enhanced Meta-Learning for Cross-lingual Named Entity Recognition with Minimal Resources
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-08-13 11:03
Автор конспекта: Владимир Агеев
Microsoft Research, Accepted to AAAI-20
Ссылка на статью
tags: nlp, ner, deep_learning, bert
Какую задачу решают в статье?
Одна из распространённых задач над текстовыми документами — Named Entity Recognition (NER). Например, это может быть задача разметки названий лекарств или заболеваний в медицинских документах.
Другими словами, NER-система, получив на вход последовательность токенов {x_i}, должна вернуть последовательность меток {y_i} (person, org, location, etc.).
Такая разметка может быть ценна как сама по себе, так и использоваться в качестве входных признаков для другой модели.

Проблема, с которой можно столкнуться при решении подобной задачи для документов на разных языках — отсутствие размеченных данных на языках, отличных от использованных для обучения.
Одним из подходов к решению может быть перевод фраз на исходный язык и перенос разметки с помощью поиска ближайших соседей в общем векторном пространстве (статья), но такой перевод может оказаться довольно шумным.
С появлением multilingual BERT появилась возможность делать zero-shot transfer на другие языки. В этой статье авторы предлагают несложный мета-алгоритм для файнтюнинга multilingual BERT, который дает значительный прирост в метриках без использования размеченных данных на других языках.
Как решают?
Base Model
В качестве базовой модели используется multilingual BERT (Base).
Каждый пример — последовательность токенов фиксированной длины.
В качестве функции потерь — кросс-энтропия:
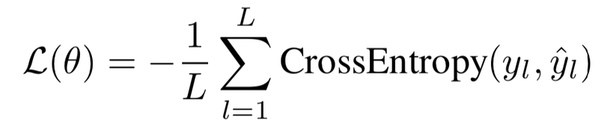
Здесь L — длина последовательности, y_l — one hot encoding вектор ground-truth метки для токена, hat{y}_l — распределение над метками, предсказанное моделью.
В статье под тренировочной выборкой понимают тексты на английском языке, под тестовой — тексты на пяти других языках.
Meta-training
Идея мета-алгоритма заключается в том, чтобы симулировать inference этап, который описан чуть ниже и сделать модель “чувствительнее” к задаче.
Для этого запускается следующая процедура:
- Из каждого примера в тренировочной выборке выбирается несколько его ближайших соседей в смысле косинусной меры
- Формируются псевдо-задачи: соседи — тренировочный сет, текущий пример — тест. Так выбираются тренировочные примеры, которые по своей структуре близки к тестовому
- На каждом сформированном тренировочном сете происходит обновление параметров модели градиентным спуском — минимизируется лосс выше. Затем вычисляется градиент функции потерь на тестовом примере. Это необходимо, чтобы сделать мета-апдейт параметров модели, то есть учесть ее поведение на всех псевдо-задачах и минимизировать сумму потерь на всех примерах
Meta-training

Идея мета-алгоритма заключается в том, чтобы симулировать inference этап, который описан чуть ниже и сделать модель “чувствительнее” к задаче .
Для этого запускается следующая процедура:
- Из каждого примера в тренировочной выборке выбирается несколько его ближайших соседей в смысле косинусной меры
- Формируются псевдо-задачи: соседи — тренировочный сет, текущий пример — тест. Так выбираются тренировочные примеры, которые по своей структуре близки к тестовому
- На каждом сформированном тренировочном сете происходит обновление параметров модели градиентным спуском — минимизируется лосс выше. Затем вычисляется градиент функции потерь на тестовом примере. Это необходимо, чтобы сделать мета-апдейт параметров модели, то есть учесть ее поведение на всех псевдо-задачах и минимизировать сумму потерь на всех примерах
Masking
В отличие от обычных слов, репрезентации именованных сущностей из разных языков могут оказаться далеко друг от друга в пространстве эмбеддингов, так как в целом встречаются в текстах намного реже.
Чтобы уменьшить зависимость модели от представлений именованных сущностей, авторы предлагают на каждой эпохе случайным образом заменять токены именованных сущностей на [MASK].
Max Loss
В функции потерь выше все токены в последовательности учитываются равномерно. При этом на каких-то токенах модель может ошибаться сильнее чем на других. Авторы предлагают дополнительно добавить штраф за максимальную кросс-энтропию в последовательности, чтобы заставить модель лучше обучаться на подобных примерах:
Adaptation / Inference
При переходе к тестовым данным — текстам, на языках, отличных от использованных в мета-обучении, в статье предлагается следующее:
- Аналогично формированию псевдо-задач выше, для каждого тестового примера на новом языке находится несколько похожих примеров на исходном языке из тренировочной выборки
- На найденных примерах производится обновление параметров — один шаг градиентного спуска без использования Masking и Max Loss
- Наконец, с помощью полученной модели строится предсказание для тестового примера
Adaptation / Inference
При переходе к тестовым данным — текстам, на языках, отличных от использованных в мета-обучении, в статье предлагается следующее:
- Аналогично формированию псевдо-задач выше, для каждого тестового примера на новом языке находится несколько похожих примеров на исходном языке из тренировочной выборки
- На найденных примерах производится обновление параметров — один шаг градиентного спуска без использования Masking и Max Loss
- Наконец, с помощью полученной модели строится предсказание для тестового примера
Что в результате
Авторы утверждают, что данный мета-алгоритм позволяет добиться state-of-the-art результатов даже в случае перехода от задачи без разметки к задаче c Low Resources, то есть когда небольшой набор размеченных примеров все-таки доступен.
В статье приведены результаты Ablation Study, которые позволяют получить представление о том, какой вклад в перформанс модели вносит каждая из механик:

Мое мнение
- Выглядит как хороший способ еще чуть-чуть повысить качество модели в случае, когда размеченных данных на новых языках очень мало, что на практике в NER действительно встречается часто
- Было бы интересно попробовать подобный мета-алгоритм на других задачах с текстом и с другими вариациями BERT'а
Существуют более поздние статьи авторов на ту же тему: раз, два.
Источник: m.vk.com