Можно ли погрузиться в мир данных, самостоятельно освоив Data Science с нуля? Спойлер: да. В этом материале мы вместе с Факультетом Искусственного интеллекта GeekUniversity расскажем о навыках и дисциплинах, которые необходимо освоить на пути к карьере Data Scientist.
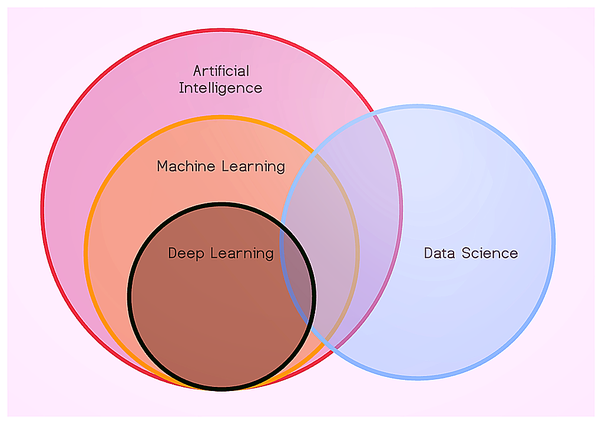
Чем отличаются Artificial Intelligence, Machine Learning, Deep Learning и Data Science?
Искусственный интеллект фокусируется на создании технологий, которые действуют и реагируют, как человеческий разум. В большинстве областей ИИ всё ещё не может полностью заменить человека.
Машинное обучение — техника, позволяющая смоделировать определённое поведение, основываясь на данных (например обучение нейронной сети, чтобы та могла отличать кошек от собак по фотографиям).
Глубокое обучение нейронных сетей — это создание многослойных нейронных сетей в областях, где требуется более продвинутый анализ, и традиционное машинное обучение с ним не справляется.
Наука о данных — сбор, визуализация и обработка данных, а также принятие решений на их основе.
Чем занимается Data Scientist?
В Data Science обучении стоит отталкиваться от задач, поставленных перед специалистом. При этом задачи Data Scientist могут отличаться в зависимости от сферы деятельности компании. Вот несколько примеров:
- обнаружение аномалий — например нестандартных действий с банковской картой, мошенничества;
- анализ и прогнозирование — показатели эффективности, качество рекламных кампаний;
- системы баллов и оценок — обработка больших объёмов данных для принятия решения, например, о выдаче кредита;
- базовое взаимодействие с клиентом — автоматические ответы в чатах, голосовые помощники, сортировка писем по папкам.
Но для любой из вышеперечисленных задач всегда нужно выполнять примерно одни и те же шаги:
- Сбор данных — поиск источников и способов получения информации, а также сам процесс сбора.
- Проверка — валидация, удаление аномалий.
- Анализ — изучение данных, построение предположений, выводов.
- Визуализация — приведение данных в вид, понятный для человека (графики и диаграммы).
- Результат — принятие решений на основе анализируемых данных, например об изменении маркетинговой стратегии или увеличении бюджета на какую-либо деятельность компании.
Что нужно знать?
Несмотря на то, что знать нужно довольно много, сейчас есть огромное число онлайн-курсов и книг, которые помогут получить нужные навыки гораздо быстрее.
Статистика, математика, линейная алгебра
Вам понадобится изучить фундаментальный курс по теории вероятностей, математический анализ, линейную алгебру и математическую статистику. Математические знания важны, чтобы уметь анализировать результаты применения алгоритмов обработки данных.
Книги по теме:
- «Практическая статистика для специалистов Data Science», П. Брюс, Э. Брюс — подойдёт тем, кто уже имеет начальные знания в статистике;
- «Наука о данных с нуля», Дж. Грас — книга для быстрого погружения в профессию, охватывающая большинство необходимых дисциплин;
- «Нейронные сети. Полный курс», С. Хайкин — материал, раскрывающий математическую составляющую нейросетей.
Машинное обучение
Машинное обучение позволяет научить компьютеры самостоятельно принимать решения, чтобы автоматизировать выполнение определённых задач. По этой причине МО применяется во многих областях, среди которых есть и наука о данных.
Чтобы освоить Data Science с нуля, первым делом нужно изучить три основных раздела машинного обучения:
- Обучение с учителем (Supervised Learning) Позволяет спрогнозировать результат по заранее размеченным данным. Если нужно предсказать несколько значений (например отличить фотографии машин от самолётов и поездов), то это задача классификации, если одно (скажем, предположить цену квартиры в зависимости от её характеристик) — задача регрессии.
- Обучение без учителя (Unsupervised learning) Здесь входные данные не размечены, то есть ни результат, ни способ обработки данных не известны заранее. В пример можно привести поиск аномалий — необычных транзакций по кредитной карте, ошибочных показаний датчиков и тому подобное.
- Обучение с подкреплением (Reinforcement learning) Исходные данные тоже не размечены, но при каждом действии нейросеть получает стимул — положительный или отрицательный. По такому принципу ИИ учат играть в компьютерные игры, например в Dota 2 и Starcraft II.
Книги по теме
- «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» П. Флах — книга о методах построения моделей и алгоритмах МО.
- «Вероятностное программирование на Python: байесовский вывод и алгоритмы», К. Дэвидсон-Пайлон — рассказывает об алгоритмах обработки данных и развивает аналитические навыки.
- «Введение в машинное обучение с помощью Python», А. Мюллер, С. Гвидо — книга для оттачивания практических навыков машинного обучения.
Что нужно уметь?
Программировать на Python
Большим преимуществом будет знание основ программирования. Но это довольно обширная и сложная область, и чтобы немного упростить её изучение, можно сосредоточиться на одном языке. Python идеально подходит начинающим — у него относительно простой синтаксис, он многофункциональный и часто используется для обработки данных.
Книги по теме:
- «Python для сложных задач. Наука о данных и машинное обучение», Дж. Вандер Плас — руководство по статистическим и аналитическим методам обработки данных;
- «Python и анализ данных», Уэс Маккинни — пособие по применению Python в науке о данных;
- «Автоматизация рутинных задач с помощью Python», Эл Свейгарт — книга даёт хорошие практические основы для начинающих.
- «Изучаем Python», М. Лутц — учебник с практическим подходом, который подойдёт как новичкам, так и разработчикам с опытом.
После того, как вы изучите основы Python, можете ознакомиться с библиотеками для Дата Сайнс.
Основные библиотеки:
- Numpy (документация, руководство)
- Scipy (документация, руководство)
- Pandas (документация, руководство)
Визуализация:
- Matplotlib (документация, руководство)
- Seaborn (документация, руководство)
Машинное обучение и глубокое обучение:
- SciKit-Learn (документация, руководство)
- TensorFlow (документация, руководство)
- Theano (документация, руководство)
- Keras (документация, руководство)
Обработка естественного языка:
- NLTK (документация, руководство)
Веб-скрейпинг:
- BeautifulSoup 4 (документация, руководство)
Собирать данные
Data Mining — важный аналитический процесс, предназначенный для исследования данных. Он позволяет находить скрытые паттерны, чтобы получить ранее неизвестную полезную информацию, необходимую для принятия каких-либо решений. Сюда же входит визуализация данных — представление информации в понятном графическом виде.
Книги по теме:
- «Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP» В.В. Степаненко, И.И. Холод — описание методов обработки данных с примерами;
- «Data mining. Извлечение информации из Facebook, Twitter, LinkedIn, Instagram, GitHub», М. Рассел. М. Классен — книга, которая учит практическим приёмам анализа данных на примере популярных соцсетей.
Хорошая стратегия — получить базу по Data Science в онлайн-университете, а потом решать более сложные практические задачи на стажировке в компании.
Что дальше?
После того, как вы изучите основы и пройдёте всевозможные Data Science курсы, попробуйте свои силы в открытых проектах или соревнованиях, а затем начинайте искать работу.
Как вы уже поняли, изучение Data Science с нуля — это не только теория. Для практического опыта хорошо подойдёт Kaggle — веб-сайт, где постоянно проводятся соревнования по анализу данных, в которых принимают участие все желающие. Также есть много открытых наборов данных — можете анализировать их и публиковать свои результаты. Также изучайте на Kaggle работы других участников и учитесь на чужом опыте.
Чтобы подтвердить свою квалификацию, зарабатывайте баллы за участие в соревнованиях Kaggle и публикуйте свои проекты на GitHub. Главное — не прекращать обучение и получать удовольствие от того, что вы делаете.