Введение в Actor-Critic сети обучения с подкреплением.
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-04-05 07:28

В предыдущем посте в блоге мы погрузились в базовую реализацию глубокой Q-обучающей нейронной сети. Это была основанная на политике дуэль-сеть, которая использовалась для изучения игры thief-police-gold. Итак, я внезапно ввел здесь два термина: основанный на политике, дуэль-сеть .
Методы, основанные на политике, - это те, которые изучают распределение вероятности действий, которые необходимо предпринять в следующем состоянии, находясь в данном состоянии. Как можно было видеть, мы использовали слой softmax выходного размера= количество возможных действий, это было не что иное, как механизм обучения политике для сети, чтобы узнать, какое действие предпринять дальше в зависимости от вероятностей.
Переходим к следующему термину, дуэль-сеть . В предыдущем блоге мы использовали две нейронные сети, одна из которых использовалась и обновлялась в режиме онлайн, а другая обновлялась (не так часто) и использовалась для прогнозирования значений политики для new_state. Причина этого заключалась в том, чтобы иметь возможность поддерживать некоторую последовательность и не вызывать большой случайности в прогнозе политики для новых состояний, которые используются для обновления текущих значений политики.
Приходя в этот блог, я снова буду говорить о новом термине 😀 и это актер-критик Методы. Предыдущий агент может быть понят как акторная часть сетей акторов-критиков, поскольку он фокусируется на прогнозе политики. Чтобы понять критическую часть, нам нужно понять сети, основанные на ценностях. В отличие от сетей, основанных на политике, критик-сети предсказывают значение важности нахождения в состоянии (значение состояния) или для пары "действие-состояние" (значение q). На самом деле, обучение укреплению началось только с сетей, основанных на ценностях, и основанное на политике обучение было далее выведено с использованием уравнения ценностного уравнения.
Давайте на этот раз перейдем к математике 😊:
Основной целью алгоритма обучения с подкреплением является максимизация вознаграждения с учетом будущих действий и их вознаграждений. Математически это можно показать как :
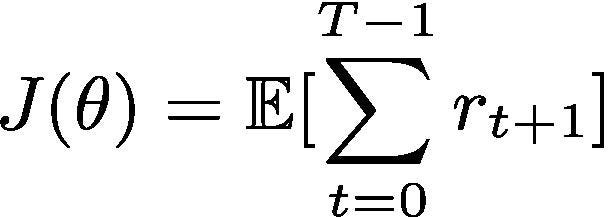
Теперь, когда мы говорили о функции политики ранее в этой статье, давайте рассмотрим математическое выражение градиентов функции затрат J(θ), необходимых для обновления функций политики. Мы называем их политическими градиентами. Очень хороший вывод получения градиентов приведен в этом блоге . Если вам интересно, вы можете прочитать его . Итак, конечное выражение для градиента выглядит следующим образом:
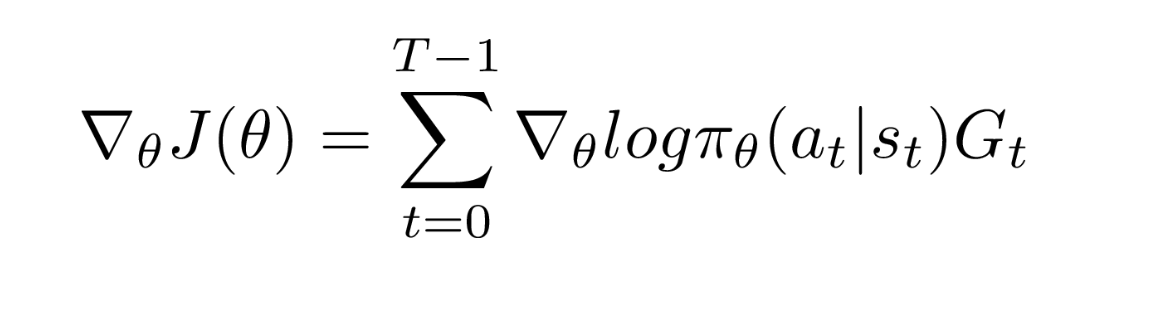
где G-сумма будущих дисконтированных вознаграждений:
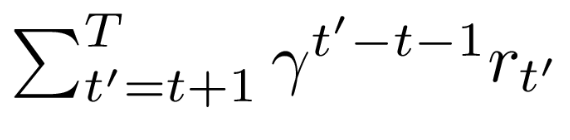
Итак, G-это не что иное, как Q-значение. Таким образом, теперь мы можем аппроксимировать как актора (softmax), так и критика (logits), используя единую нейронную сеть. Но дальнейшие исследования предложили небольшое улучшение выражения и вместо использования G используется функция преимущества, которая определяется следующим образом:
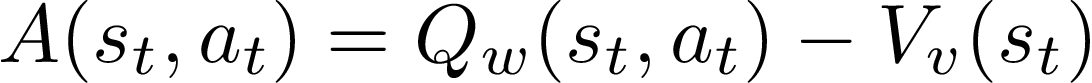
где V-функция значения состояния. Мы все еще можем использовать единую нейронную сеть для аппроксимации как критика, так и актора, благодаря оптимальному уравнению Беллмана, которое дает прямое отображение между значением Q и функциями состояния-значения. В результате мы можем непосредственно заменить G функцией преимущества, A в уравнении градиента политики.
Это приводит к тому, что алгоритм называется Advantage Actor-Critic(A2C), где есть только один агент, имеющий две сети, актер и критик, параметризованные одной нейронной сетью, веса которой обновляются с использованием значения Advantage и потери перекрестной энтропии. Мы также рассмотрим часть расчета потерь в этом блоге. Но перед этим я рассмотрю еще один известный алгоритм, предложенный DeepMind, который является расширенной версией A2C.
Алгоритм A3C
Дополнительный A, который добавляется в этом алгоритме, происходит от термина асинхронный . В этом методе существует глобальная сеть с общими параметрами, такими же, как predict_model в предыдущем блоге. Кроме того, существует несколько агентов, исследующих окружающую среду, а не только один агент. Все эти агенты учатся самостоятельно, так как каждый из них имеет свою собственную копию среды. Термин асинхронный приходит сюда, когда они изучают и обновляют глобальную сеть асинхронно-это означает, что каждый из них исследует окружающую среду параллельно, и в то время как один из них обновляет глобальную сеть, другие ждут и обновляют глобальную сеть, когда придет их очередь.
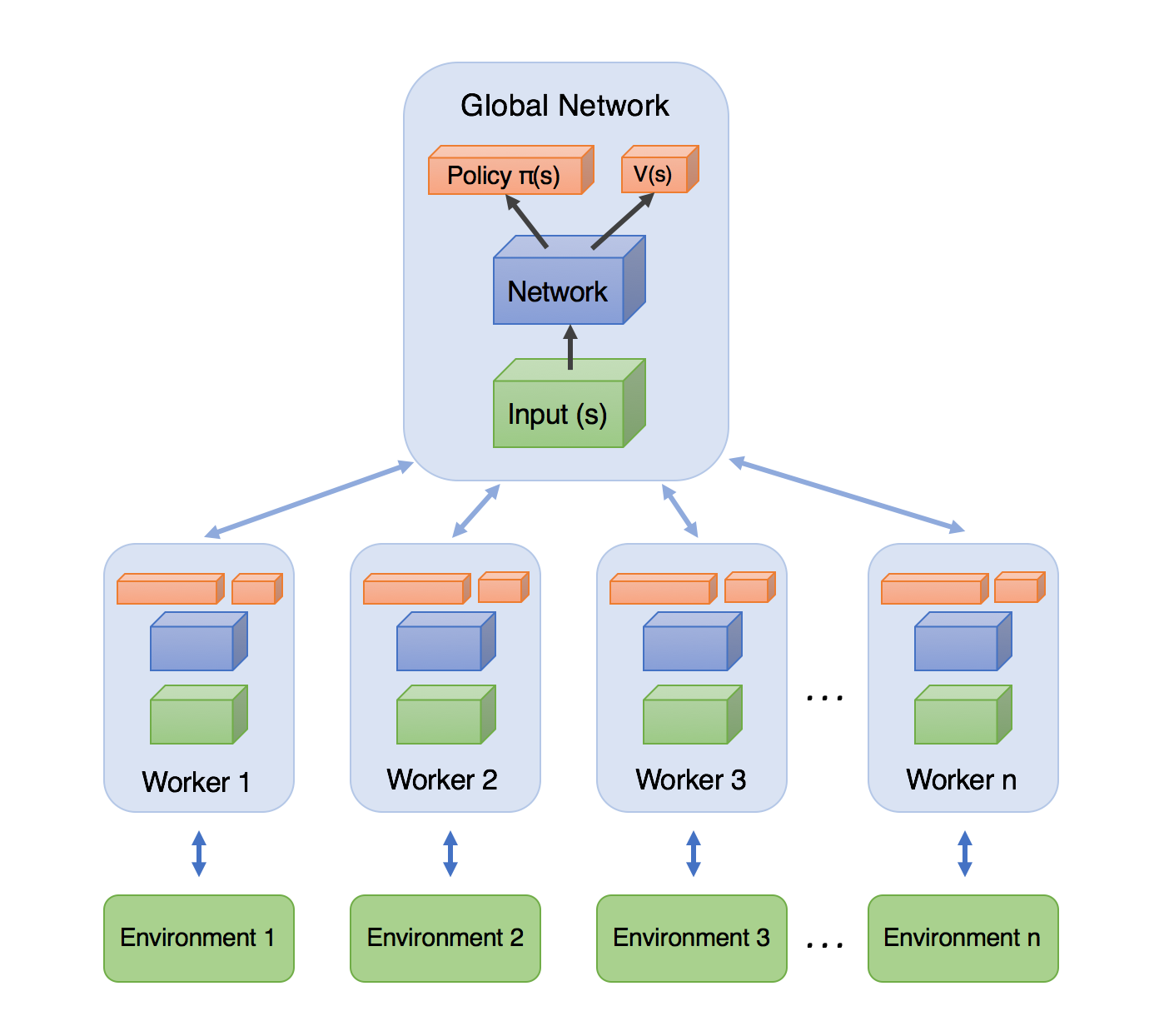
Результаты показывают, что, несмотря на размер и сложную природу A3C, A2C удается выполнить несколько ближе к нему, но все же A3C оказывается более последовательным из-за стратегии мультиагентной разведки.
Теперь давайте обсудим часть потерь:
1. Потеря критика: это будет вычисляться как среднее квадратическое значение потери, которое может быть показано следующим образом:
Closs = Σ (R-V)^2
где R-дисконтированная сумма будущих вознаграждений в траектории.
2. Потеря актора: это вычисляется сначала путем принятия категориально-перекрестной энтропии, принимая метку как действие, предпринятое случайным образом, и умножения этого значения со значением преимущества, (R-V) .
Я буду давать реализацию обсуждаемых алгоритмов в будущем блоге. Надеюсь, тебе это понравилось.
Источник: blogs.oracle.com