Stepik - «Введение в Data Science и машинное обучение»
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-04-20 11:35
Курс состоит из 4 глав. Каждая глава в своем составе имеет видео-лекции, интересные вопросы и задания, а также видео-интервью с секретным гостем, который работает в сфере Data Science.
1 глава - Введение
О чём этот курс?
Как решать практические примеры используя модели машинного обучения.
Пример: есть данные о поведении пользователей в игре. Предсказать какие пользователи останутся в игре, а какие уйдут.
Задачи курса: сформулировать задачу, построить модель, сделать прогноз.
Важной задачей этого курса будет не только разобраться с тем, как устроено дерево решений или какие команды на Python нужно выполнить, чтобы всё получилось. Но и сформировать более общее представление о том, как методы машинного обучения, да и в целом data-science интегрированы в реальные задачи, какие при этом процессы возникают, какие data-scientist бывают, и что еще обязательно нужно знать, чтобы успешно в этой области развиваться.
Рассмотрим основные термины и понятия на одном примере.
problem
Рассмотрим пример про применение машинного обучения в онлайн-играх. Допустим, у нас есть игра.
Пользователи скачивают нашу игру на мобильный телефон, создают эпического фэнтезийного персонажа и отправляются в путешествие по интересному миру со всякими драконами, гоблинами и т.д.
И вот одни пользователи молодцы: скачивают приложение, каждый день в него играют, покупают всякие мечи за деньги, имеют высокий рейтинг. А другие пользователи скачали приложение, пару раз поиграли, удалили его и больше никогда к нам не возвращались.
Возникает вопрос: а можно ли с этим что-то сделать? Можно ли как-то повлиять на это? Останется ли пользователь в нашем приложении или удалит и больше никогда не вернётся?
Это первая очень понятная стадия любой задачи, в которой машинное обучение используется. Умение видеть проблему, которую нужно решить - ключевая компетенция любого data-scientist. Без этого никакое машинное обучение в принципе и не нужно.
Как только мы сформулировали некоторую проблему на языке продуктовой задачи - как избежать того, что пользователи перестают пользоваться приложением, далее переводим её на язык машинного обучения - и понимаем, что это задача классификации или регрессии, и для ее решения мы будем использовать логистическую регрессию.
data engineering
Так вот, чтобы использовать логистическую регрессию, нам нужны данные. Без данных мы никакую регрессию не применим, и, если мы говорим про наш пример, понятное дело нужно логировать события пользователей внутри игры и где-то их хранить.
И это отдельная огромная область знаний, которая называется data engineering, отвечающая на вопросы:
как нам хранить данные? где их хранить? как обеспечить хранение миллиардов данных, которые могут происходить в нашем приложении?Это также очень важная компетенция любого data-scientist.
machine learning
Приблизительно после этого возникает время машинного обучения - когда мы сформулировали проблему, сохранили данные, теперь можно подумать о том, как нам обучить регрессию.
После того, как мы это сделали, нужно результат нашего машинного обучения как-то внедрить в продукт.
programming
Пофантазируем: мы подумали, что тем пользователям, которым мы предсказали высокую вероятность ухода, мы покажем рекламную плашку "купи новый меч". Для этого нам нужно изменить исходный код игры, реализовать логику машинного обучения, внедрить её в наш продукт и запрограммировать это всё.
Всё вместе это по-прежнему не отвечает на наш вопрос. Допустим, мы это сделали и пользователи, которые видят эту плашку, покупают мечи бесплатно. Здесь интуитивно понятно, что надо проверить, а работает ли наше решение.
analytics
Допустим, у нас есть 2 группы (экс и контрольная). Одним пользователям, которым мы предсказали высокую вероятность ухода, ничего не показывать. А другим показать плашку про бесплатный меч.
А потом, через определенное время, посмотреть результат - а правда ли, что для тех пользователей, которым мы предсказывали уход из игры и показали плашку с рекламой - ситуация стала лучше?
data science
Все предыдущие пункты вместе - называются data science. В идеальном мире, человек, занимающийся машинным обучением и data science, может сам взяться за все стадии этой задачи. На практике этим занимается команда людей с понятными пересекающимися ролями.
Когда мы слышим фразу "машинное обучение применили для того, чтобы что-нибудь сделать", на самом деле нужно понимать, что эта задача состоит из нескольких отдельных областей, в которых задействованы разные специалисты из data-science, и в данном курсе мы будем исследовать область обучения моделей.
Если применение машинного обучения разбивается на несколько подстадий, из которых мы будем больше фокусироваться на стадии именно обучения моделей (т.е. у нас есть некоторые данные, мы их скачали, считали с помощью библиотеки pandas и теперь хотим найти закономерности в этих данных, классифицировать наши наблюдения на две категории или решить задачу регрессии). Вот как в этом нам помогут различные методы машинного обучения? Именно об этом мы и будет разговаривать в большей части данного курса.
problem
Одна из самых творческих задач – это умение переформулировать задачу на язык машинного обучения. В примере, который мы рассматривали ранее, сама задача подсказывала возможные методы решения.
Как нам понять расстанется ли игрок с нами или продолжит пользоваться нашим приложением? Т.е. задача намекает на то, что возможно это задача классификации и возможно классом является тот факт, что человек играет или не играет. Это подсказывает нам как организовать подготовку данных, как разметить нашу выборку и какой метод машинного обучения использовать.
Однако, это далеко не всегда так. Как научить компьютер играть в шахматы? Эта задача в своём первозданном виде никак не помогает нам понять какой метод машинного обучения и как использовать; какие данные нам нужны и вообще, с чего начинать.
Или как научить программу общаться с другим человеком так, как будто она другой настоящий человек.
Что думает сама программа по этому поводу?
- Алиса, как ты работаешь?
- Сделать меня довольно просто: возьмите подающую надежду нейросеть, научите её распознавать человеческую речь и отвечать на вопросы. Чувство юмора и сарказм - по вкусу.
- Понятно, спасибо.
Даже Алиса говорит о том, что без нейронных сетей здесь не обошлось. Но чувствуется разрыв между исходной задачей и её реализацией.
Какие данные нужно собрать? Как их подготовить? Как переформулировать задачу на понятный для машинного обучения язык?
И мы попробуем с этим поработать.
data preparation
Следующая стадия в обучении любой модели – подготовка данных. Это огромная, очень важная тема, связанная с чисткой данных с feature engineering (извлечение из данных тех показателей, которые мы хотим использовать для обучения модели). Например, в случае линейной регрессии, скажем, это извлечение из данных зависимых переменных для того, чтобы предсказать некоторую независимую. Это зачастую не так просто, как кажется, и это очень важная часть машинного обучения.
Рассмотрим пример: данные поведения игроков из воображаемой игры могли бы быть сохранены в таком виде:
Где мы для каждого игрока пишем время, событие и какой-то идентификатор, чтобы понять - события какого игрока мы наблюдаем.
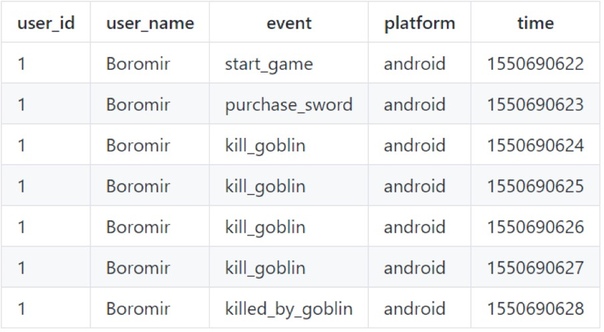
Понятное дело, что данные в таком виде хранятся, мы их так записываем, они так хранятся в csv-файле, который дал нам data-engineer и сказал: «Вот применяй модель машинного обучения». Однако, данные не позволяют нам ничего сделать.
Нужно их переструктурировать, переформировать, извлечь из них нужные признаки, разметить нашу выборку и т.д. Зачастую это важный процесс, позволяющий нам понять, что пользователь ушёл или не ушёл, и как вообще это определить? Игрок не заходил месяц, или два? Мы подумаем какие фичи (признаки объекта, которые мы хотим использовать для обучения нашей модели) можно придумать – сколько гоблинов убил пользователь или сколько игр сыграл, ни разу не проиграв.
Всё это преобразует наш исходный dataframe в новый, где в качестве колонок будут признаки объекта, которые мы хотим использовать для обучения нашей модели, а в какой-то ещё колонке (часто её называют y) будет некоторый класс – например 1 или 0, в том смысле ушёл человек из игры или нет. Позже обсудим это подробнее.
machine learning
После того, как мы взяли сырые данные и как-то их переформулировали, переструктурировали, агрегировали и подготовили их, чтобы можно было применить машинное обучение наступает этап применения машинного обучения.
В большинстве случаев это код, написанный на Python или другом языке программирования, который использует разные методы машинного обучения (например, регрессию, нейросеть, дерево решений) и обучает нашу модель. Мы ещё подробнее разберем, что значит обучить модель.
validation
После того, как мы применили модель машинного обучения – скажем, сформировали регрессию, подобрали коэффициенты и сможем теперь предсказывать наш класс – 0 или 1, происходит очень важный этап – валидация модели (мы хотим убедиться, что наша модель может выше случайного предсказывать нашу исходную переменную, она действительно работает и как в этом можно убедиться, какие могут быть проблемы с тем, когда это не так).
В методах машинного обучения это отдельная важная стадия: как именно убедиться в том, что наша модель может переносить полученные знания с одних данных на некоторые другие данные, которые она раньше не видела.
Вывод:
Всё вместе – это машинное обучение.
В данном курсе большой акцент будет на обучение модели на готовых данных, в меньшей степени на извлечение и обработку данных.
Столкнувшись на практике с реальным проектом, вы поймете, что на самом деле никаких данных нет. Их нужно сначала откуда-то собрать, придумать, сконструировать набор признаков, по которым вы будете обучаться. В курсе же в основном будет говориться о том, как модели работают и как они обучаются.
Машинное обучение всегда интегрировано в более сложную структуру data science и всегда нужно помнить о стадиях, которые лежат до и после.
Ссылки на эти уроки:
https://stepik.org/lesson/85279/step/1?unit=61804
https://stepik.org/lesson/216064/step/1?unit=188926
Автор: Зульфара Шаймухаметова
Главный редактор: Диляра Ахметзакирова
Источник: m.vk.com