Разреженная глубокая Факторизационная машина для эффективного прогнозирования CTR
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-04-23 13:30
Yahoo Research, 2020
Keywords: CTR prediction, deep model acceleration, model compression, factorization machine, field importance, structural pruning
Статья Код
Какую задачу решают в статье?
Авторы статьи решают задачу предсказания вероятности клика.
Также в статье есть хороший обзор известных решений этой задачи. Перечислю значимые из них:
Factorization machine (FM) Учитывают линейные и квадратичные (между любыми двумя признаками) взаимодействия признаков. Для учета квадратичного взаимодействия строят эмбеддинги фич с помощью матричного разложения и используют скалярное произведение эмбеддингов как вес взаимодействия фич.
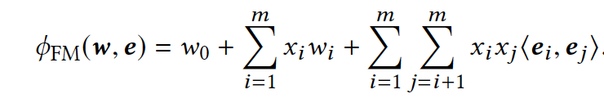
Field-aware Factorization Machine (FFM)Конспект про FFM, FFM в продакшенеВводят понятие группы признаков (field). Теперь каждый признак представлен в виде n векторов размерностью k — имеет разное представление в каждой другой группе признаков, что позволяет более точно учитывать взаимодействие между группами признаков. Это значительно повышает эффективность прогнозирования, но количество параметров также значительно увеличивается.
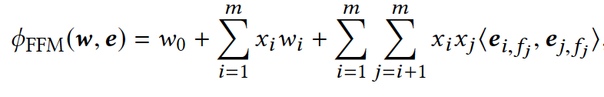
Field-weighted Factorization Machine (FwFM)Для оптимизации по памяти в FwFM введена матрица R (симметричная матрица размерности n) как взаимодействие различных групп признаков, поэтому более эффективно по памяти, предсказания также хороши как у FFM, но гораздо меньше параметров для обучения.
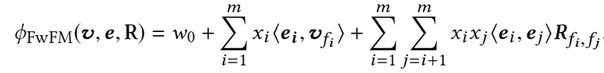
DNN с эмбеддингами сильнее учитывают нелинейное взаимодействие между признаками.
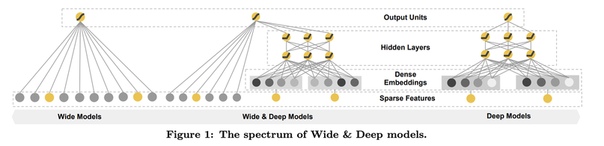
Wide & DeepПредложили обучить объединенную сеть, которая сочетает в себе линейную модель и глубокую модель, чтобы изучать взаимодействия признаков как низкого, так и высокого порядка. Тем не менее, пересечения признаков в линейной модели все еще требуют экспертной работы с ними и не могут быть легко адаптированы к новым наборам данных.
DeepFMDeepFM решил проблему сложной работы с пересечением признаков с помощью моделирования низкоуровнего взаимодействия через FM компонент вместо линейной модели.
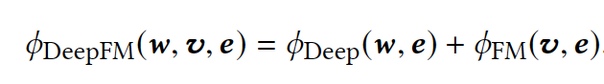
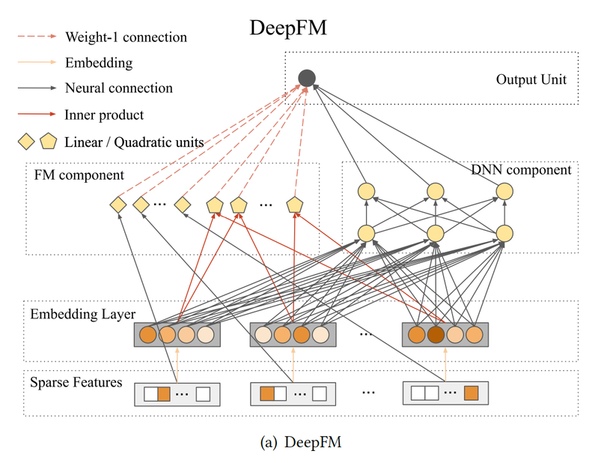
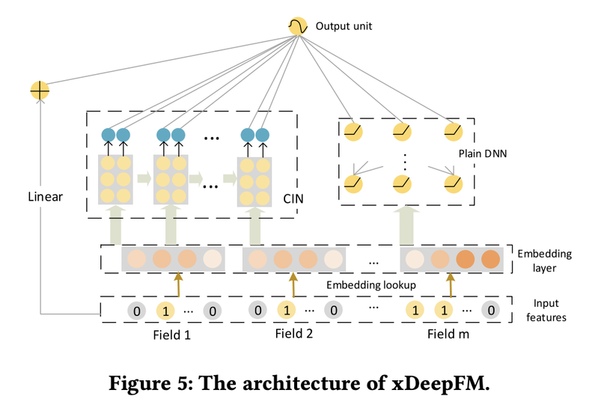
eXtreme Deep Factorization Machine (XDeepFM)XDeepFM предлагает включить сжатую сеть взаимодействий (CIN) для обучения высокоуровнего взаимодействия признаков. Основным недостатком является то, что CIN имеет большую вычислительную сложность, чем DNN, что приводит к дорогостоящим вычислениям в крупных рекламных системах.
Как решают?
Модель объединяет компонент FwFM и DNN в единую модель, которая эффективна для обучения взаимодействий признаков как низкого, так и высокого порядка. DeepFwFM позволяет значительно сократить время вывода при использовании такой комбинации, в то время как другие архитектуры могут потерпеть неудачу либо в глубоких ускорениях модели, либо в точных предсказаниях.
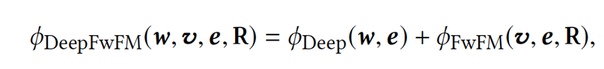
Модель похожа на DeepFM, но с заменой FM компонента на FwFM (оптимизированный по памяти).
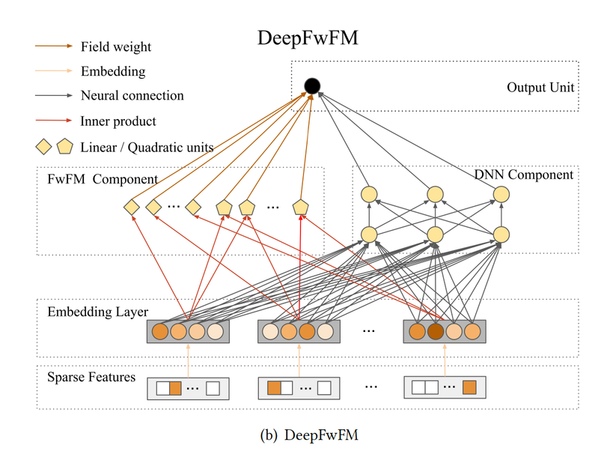
Pruning это итеративное удаление связей между нейронами, в простом случае тех, которые имеют наименьший вес, для сокращения размера модели.
Также авторы статьи используют structural pruning для ускорения расчета предсказания и оптимизации по памяти через уменьшение количества параметров. А именно они итеративно обрезают связи в DNN компоненте и в матрице R.
В результате качество сравнимое с state-of-the-art, но меньше ресурсов для обучения.
Преимущества подхода
- В 46 раз быстрее, чем state-of-the-art на датасете Criteo и в 27 раз быстрее на Avazu и оптимальнее по памяти без потери в качестве
- Первая работа про CTR prediction, которая использует structural pruning
Мое мнение
- Хороший обзор известных методов
- Сжимать модели без потери в качестве — круто
- Интересно, получилось ли у них использовать модель в продакшене
Источник: m.vk.com