Open Images V6: Google AI обновили самый крупный датасет для компьютерного зрения
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-03-03 12:00
Google AI опубликовали шестую версию датасета Open Images, — Open Images V6. В Open Images добавили разметку взаимосвязей объектов на изображении, человеческих действий и лейблы изображений. Помимо этого, в шестой версии датасета есть локализованные нарративы для 500 тысяч изображений. Локализованный нарратив — это мультимодальная разметка изображения, которая состоит из синхронизированных голоса, текста и движения компьютерной мыши по изображению. Чтобы облегчить сравнение с предыдущими работами, исследователи опубликовали локализованные нарративы для датасета COCO.
Open Images — это самый крупный размеченный датасет с изображениями, который активно используется для задач компьютерного зрения. Данные состоят из 9 миллионов изображений, 36 миллионов размеченных лейблов изображений, 15.8 миллионов границ объектов, 2.8 миллионов разметок instance сегментации и 391 тысяч размеченных отношений между объектами. Параллельно с датасетом существуют открытые контесты (Open Images Challenges) для задач:
- распознавание объектов;
- instance сегментация;
- распознавание связей между объектами
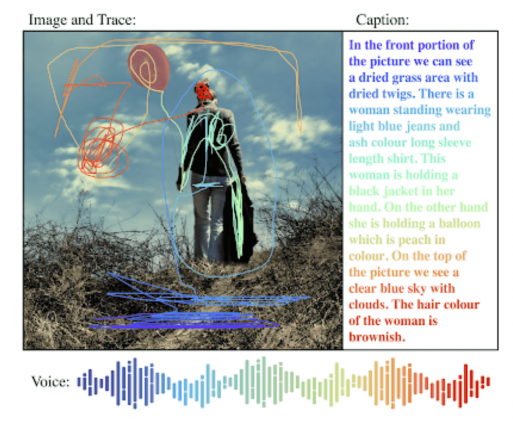
Локализованные нарративы
Локализованные нарративы генерируются аннотаторами, которые предоставляют аудиозапись описания изображения и одновременно двигают мышью по частям изображения, которые описывают в момент речи. Разметчики вручную транскрибируют аудиозапись описания. Транскрипт описания соотносится с автоматически сгенерированным текстом описания. В итоге текст, аудиозапись и движения мыши полностью синхронизированы.
Визуальные связи, действия людей и лейблы изображений
Помимо локализованных нарративов, в датасете расширили типы разметки визуальных связей. В Open Images также добавили 2.5 миллионов разметок человеческих действий. Кроме этого, дополнительно разметили 23.5 миллиона лейблов изображений.
Источник: neurohive.io