История одного пикселя. Или как обмануть нейронную сеть.
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-03-21 05:59

Давайте познакомимся с одной из атак на нейросети, которая приводит к ошибкам классификации при минимальных внешних воздействиях. Представьте на минуту, что нейросеть это вы. И в данный момент, попивая чашечку ароматного кофе, вы классифицируете изображения котиков с точностью более 90 процентов даже не подозревая, что "атака одного пикселя" превратила всех ваших "котеек" в грузовики.
А теперь поставим на паузу, отодвинем кофе в сторону и разберем как работают подобные атаки (one pixel attack).
Цель данной атаки заставить алгоритм (нейросеть) выдать некорректный ответ.
Ниже увидим это с несколькими различными моделями сверточных нейронных сетей. Используя один из методов многомерной математической оптимизации - дифференциальную эволюцию, найдем особенный пиксель, способный изменить изображение так, чтобы нейросеть стала неправильно классифицировать это изображение (несмотря на то, что ранее алгоритм "узнавал" это же изображение корректно и с высокой точностью).
Все подобные атаки можно разделить на два класса: WhiteBox и BlackBox. Разница между ними в том, что в первом случае нам все достоверно известно об алгоритме, модели с которой имеем дело. В случае с BlackBox все что нам нужно это входные данные (изображение) и выходные данные (вероятности отнесения к одному из классов). Атака одного пикселя (one pixel attack) относится к BlackBox .
В этой статье рассмотрим два варианта атаки одного пикселя: untargeted и targeted. В первом случае нам будет абсолютно все равно к какому классу отнесет нейронная сеть нашего котика, главное, чтобы не к классу котиков. Targeted атака применима когда мы хотим, чтобы наш котик непременно стал грузовиком и только грузовиком.
Но как же найти те самые пиксели, изменение которых приведет к изменению класса изображения? Как найти пиксель, поменяв который one pixel attack станет возможна и успешна? Давайте попробуем сформулировать эту проблему как задачу оптимизации, но только очень простыми словами: при untargeted attack мы должны минимизировать доверие к нужному классу, а при targeted - максимизировать доверие к целевому классу.
При проведении подобного рода атак трудно оптимизировать функцию с помощью градиента. Необходимо использовать алгоритм оптимизации, который не полагается на гладкость функции.
Для нашего эксперимента будем использовать датасет CIFAR-10, содержащий изображения реального мира, размером 32 х 32 пикселя, разбитых на 10 классов. А это означает, что у нас есть целочисленные дискретные значения от 0 до 31 и интенсивности цвета от 0 до 255, и функция ожидается не гладкая, а скорее зазубренная, как показано ниже:
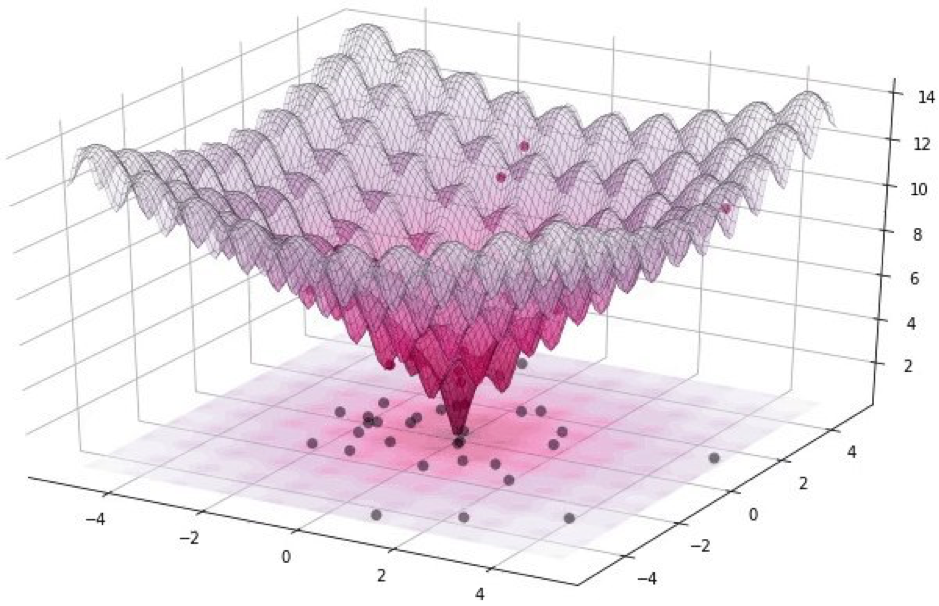
Визуализация алгоритма
Именно поэтому мы используем алгоритм дифференциальной эволюции.
Пришло время поделиться результатами исследования (проведенной атаки) и посмотреть как изменение лишь одного пикселя превратит лягушку в собаку, кота в лягушку, а автомобиль в самолет. А ведь чем больше точек изображения позволено изменять, тем выше вероятность успешной атаки на любое изображение.
Подпишись на рассылку новостей о AI
Только полезные материалы о машинном обучении и искусственном интеллекте. Мы уважительно относимся к нашим читателям и рассылаем письма не чаше 1 раза в неделю!
Это были примеры untargeted attack, а теперь проведем targeted attack и выберем к какому классу мы бы хотели, чтобы модель отнесла (классифицировала) изображение. Задача намного сложнее предыдущей, ведь мы заставим нейросеть классифицировать изображение корабля как автомобиля, а лошадь как кота.
Разобравшись с единичным случаями проведения атак, соберем статистику, используя архитектуру сверточных нейронных сетей ResNet, пройдясь по каждой модели, изменяя 1, 3 или 5 пикселей каждого изображения. В этой статье покажем итоговые выводы не утруждая читателя ознакомлением с каждой итерацией, поскольку это занимает немало времени и вычислительных ресурсов.
Для проверки возможности дискредитации сети был разработан алгоритм и измерено его влияние на качество прогноза решения по распознаванию образов.
В приведенной таблице видно, что используя нейронную сеть ResNet с точностью 0.9231, меняя несколько пикселей изображения, мы получили очень неплохой процент успешно атакованных изображений (attack_success_rate).
1)
Model - ResNet
Accuracy - 0.9231
Pixels - 1
Attack_success_rate - 0.144444
2)
Model - ResNet
Accuracy - 0.9231
Pixels - 3
Attack_success_rate - 0.211111
3)
Model - ResNet
Accuracy - 0.9231
Pixels - 5
Attack_success_rate - 0.222222
В своих экспериментах вы вольны использовать и другие архитектуры искусственных нейронных сетей, благо их в настоящее время великое множество.
Нейросети окутали современный мир незримыми нитями. Уже давно придуманы сервисы, где используя ИИ (искусственный интеллект), пользователи получают обработанные фото, стилистически похожие на работы кисти великих художников, а сегодня алгоритмы уже умеют сами рисовать картины, создавать музыкальные шедевры, писать книги и даже сценарии к фильмам.
Такие сферы, как компьютерное зрение, распознавание лиц, беспилотные автомобили, диагностика заболеваний - принимают важные решения и не имеют права на ошибку, а вмешательство в работу алгоритмов приведет к катастрофическим последствиям.
One pixel attack – один из способов спуфинг атак. Для проверки возможности дискредитации сети был разработан алгоритм и измерено его влияние на качество прогноза решения по распознаванию образов. Результат показал, что применяющиеся сверточные архитектуры нейросетей уязвимы перед специально обученным алгоритмом One pixel attack, который подменяет один пиксель, с целью дискредитации алгоритма распознавания.
Источник: data4.ru