Что такое эмбеддинги и как они помогают машинам понимать тексты
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2020-03-28 11:29
Речь — одна из основных вещей, которые отличают нас от животных. Мы можем ее генерировать (то есть, говорить или писать) и понимать, и пытаемся научить этому компьютер. Самая сложная задача — сделать так, чтобы он понимал смысл текста. Начнем с того, что люди сами пока точно не знают, что вообще значит «понимать смысл», поэтому задачу немного упростили: давайте научим компьютер хорошо выполнять такие задачи с текстом, которые умеет выполнять человек. Например, определять жанр или тему текста, кратко его пересказывать, выделять основных персонажей, переводить на другой язык.
Допустим, нам нужно определить тему. Человек прочитает текст, увидит знакомые слова и разберется, как они связаны между собой. А что делать компьютеру? Наверное, ему тоже нужно разбить текст на предложения или слова, узнать их значения и найти связи. Можно найти или создать систему, в которой будет описано, что означают разные слова и как они могут быть связаны между собой. Но это очень ресурсозатратно и неэффективно. К счастью, компьютерные лингвисты изобрели другие методы.

Начнем по порядку. Компьютерам с текстами вообще непросто, потому что они не особо разбираются в буквах. Им больше нравится работать с цифрами, которые можно сравнивать между собой, складывать, вычитать и делать другие операции. Поэтому перед тем, как определять тему, для начала придется превратить каждый элемент текста в какое-то число.
Для этого нужно поделить текст на элементы, что тоже нетривиальная задача. Текст — штука многоуровневая, можно разбить его на предложения, слова, буквы или даже морфемы. Для разных задач хороши разные подходы, но когда мы пытаемся работать со смыслом, нам обычно интересны слова, потому что слово - мельчайшая единица речи, у которой есть значение. Слоги или буквы не всегда информативны: мы знаем, что означает слово кошечка, но сложно сказать, какое значение у слога ка или суффикса еч.
Хорошо, у нас есть слова и нужно их как-то закодировать в числа. Это называется векторизация - потому что в итоге текст превратится в вектор, то есть в большой (по количеству слов) ряд чисел.
Как было раньше?
Итак, нам хотелось бы, чтобы семантически (то есть, по смыслу) близкие слова были ближе друг к другу и в числовом виде. То есть, разница между близкими по смыслу словами должна быть минимальной. Но если мы будем просто нумеровать все слова, то как определить правильный порядок нумерации? Если слово мышь получит число 8, то под номером 7 или 9 должна быть крыса, мышонок или, может быть, хвост? Непонятно, как ранжировать слова по степени похожести.
Есть идея получше — заменить слово не одним числом, а целым вектором. Векторы можно представить в геометрическом пространстве, где у каждого слова-вектора может быть много соседей на одинаковом расстоянии. Такой вектор называется word embedding (увы, термин до сих пор нормально не перевели на русский, поэтому мы так и говорим — эмбеддинг).
Самый простой подход — это взять все слова, которые встречаются в тексте, и расставить их по алфавиту. Тогда можно превратить каждое слово в вектор по длине такого словаря. Он будет состоять из кучи нулей и одной единицы — на номере позиции, которую слово занимает в словаре. Представьте, что мы взяли маленький текст, в котором есть всего 7 разных слов. Одно из них — наша любимая мышь. Мы выстроили слова по алфавиту, и мышь оказалась на 3 месте. Тогда в виде вектора это слово будет выглядеть примерно так: [0, 0, 1, 0, 0, 0, 0]

Этот способ векторизации называется one-hot-encoding, и он позволяет машине производить над текстом разные операции — по сути, анализировать его. Можно, например, сложить векторы всех слов в предложении и получить вектор суммы. Он даст информацию о том, насколько часто в предложении встречаются разные слова. Векторы предложений уже можно сравнивать между собой.
При таком подходе никак не учитывается порядок слов, только их количество, поэтому он называется мешок слов. Люди придумали, как сделать его интереснее — вместо единицы в векторе слова можно записывать, насколько часто оно встречается в тексте. Или даже учесть, как часто оно употребляется и в других текстах тоже. Такой метод называется TF-IDF.
Можете разобраться в формуле, если интересно. А если не очень — скипайте с чистой совестью, это не повлияет на понимание дальнейшего текста :)
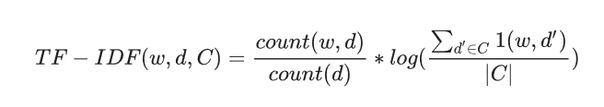
Выглядит страшно, но на деле очень просто. w — слово, d — текст, C — корпус текстов, т.е. все тексты, которые у нас есть. Первый множитель — это TF, частота слова w в конкретном тексте d, поделенная на общее число текстов в нашем корпусе C. Второй —IDF, то есть логарифм обратной частоты распространенности слова w в том же корпусе C.
Эмбединнговая революция
Векторизация на основе частотности слов неплохо работает, когда текстов относительно мало и словарь ограничен. Но с появлением этих ваших интернетов текстов стало намного больше, и словари тоже постоянно растут и меняются.
В 2013 году чешский аспирант Томаш Миколов предложил новый метод векторизации под названием word2vec, который перевернул мир обработки текстов и стал топовым по двум причинам: во-первых, он значительно упрощал и сокращал вычисления, а во-вторых — с ним наконец-то стала доступна семантика отдельных слов, и это оказалось очень интересно и эффективно.
Метод основан на идее дистрибутивной семантики: давайте будем считать, что слова, которые встречаются в похожих контекстах, семантически близки, то есть имеют похожие значения. Контекст в нашем случае — это несколько окружающих слов. Тогда можно превращать слова в вектора произвольной длины (обычно 200-300 чисел), и чем чаще слова встречаются в похожем контексте — тем ближе эти вектора будут в пространстве.
А ведь с векторами можно делать всяческие арифметические штуки. Скажем, слова друг из друга не вычтешь, а вот вектора — запросто.
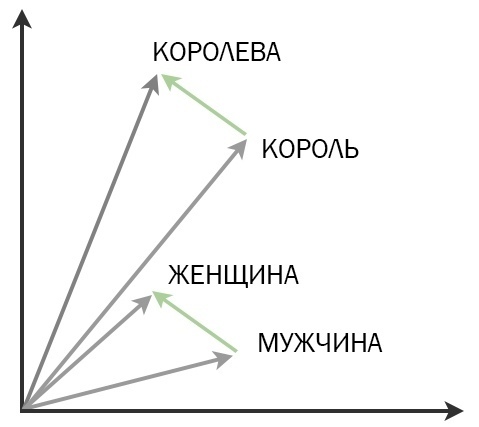
Классический пример, который всем надоел, но нам все равно нравится: король + женщина = королева.
Если к вектору король прибавить вектор женщина, можно получить вектор королева. Это ли не магия?
На самом деле все немного сложнее: во-первых, это сильно зависит от корпуса, на котором обучалась модель. Может быть, в каком-то другом корпусе слова король и королева по странным причинам употребляются в совсем разных контекстах. Или слова король там вообще нет — кстати, поэтому очень важно обучать word2vec на большом корпусе, чтобы модель встретила побольше хороших и разных контекстов.
Во-вторых, при каждом запуске модель инициализируется случайными числами, которые меняются во время обучения. Поэтому, например, обучить модели на разных корпусах и сравнить или объединить полученные вектора слов не выйдет. Строго говоря, сами вектора вообще не имеют смысла, они могут быть (и будут!) разными при каждом запуске обучения модели — гораздо важней отношения между ними.
Как это работает?
Главный технический вопрос: откуда берутся эти вектора? Для этого Миколов придумал обучать специальную нейросеть. Не будем вдаваться в детали ее архитектуры, лучше вспомним общий принцип работы машинного обучения. Готовьтесь, будет немного математично.
Итак, мы загружаем в нейросеть какие-то признаки — то есть, ряд неких параметров — отдельными наборами. Каждому набору соответствует метка. В нашем случае метка — это само слово, а набор параметров — его контекст. Модели нужно научиться предсказывать, какому слову соответствует тот или иной контекст. Кстати, слова в процессе обучения векторизованы с помощью нашего старого знакомого one-hot-encoding.
С набором параметров происходит несколько математических операций, в ходе которых мы получаем некоторые промежуточные наборы чисел. В результате этих операций нейросеть пытается предсказать слово для каждого контекста. Если предсказание неверное, то она немного поменяет числа, с которыми делает математические операции, и попытается еще раз — до тех пор, пока не научится угадывать. Когда это произойдет, наборы чисел в архитектуре сети перестанут меняться. Нам остается только вытащить один из этих наборов — он и будет вектором слова, которое нейросеть научилась угадывать.
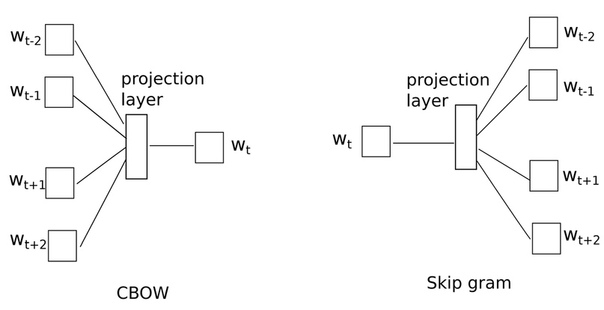
Такой алгоритм называется CBOW — continuous bag of words. Но на самом деле Миколов придумал не один, а два алгоритма. Второй — Skip gram — наоборот учится предсказывать контекст на основе слова. Об этом можно подробнее почитать в оригинальной статье с формулами и всем таким.
Из интересного: готовые обученные вектора можно использовать в любых задачах, векторизуя тексты с их помощью. Давайте разберемся, как это применить к определению темы. Близкие друг к другу векторы, т.е. близкие по смыслу слова, можно сгруппировать в семантические кластеры. Посмотрим, какие группы слов есть в тексте — и поймем, о чем в нем говорится! Так что это хороший инструмент для тематического моделирования и красивых визуализаций. К примеру, так можно узнать темы популярных статей на pubmed:
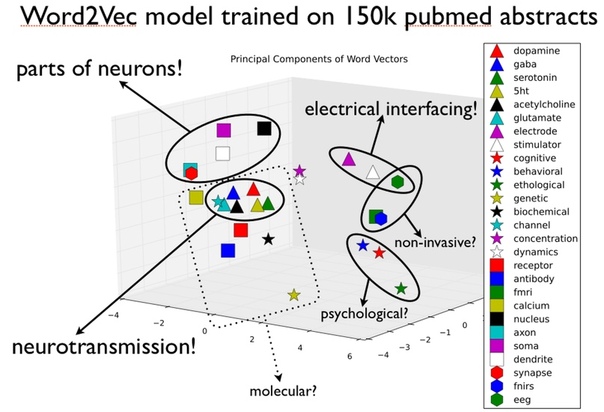
word2vec круче всех?
Если честно, то не совсем. Во-первых, у него есть куча модификаций, которые лучше подходят для решения отдельных задач. Можно обучить модель word2vec на тематическом корпусе и сделать отдельную модель для представления специфических научных терминов или не терминов вовсе. Например, биоинформатики собрали себе модели dna2vec и rna2vec, чтобы превращать в векторы отдельные последовательности генетического кода.
Иногда бывает полезней посмотреть на смысл целого предложения или абзаца, и для этого существуют алгоритмы doc2vec и seq2vec. А если можно превращать в векторы слова или предложения, почему бы не провернуть то же самое с n-граммами — последовательностями букв? На этой идее основана модель fasttext от компании Facebook (4). В ней каждое слово представлено как сумма векторов n-грамм, которые его составляют. Например, вектор слова яблоко будет равняться сумме векторов ябл, бло, лок и око.
А в 2018 года мир обработки текста вообще потрясло новое открытие — эмбеддинги, которые позволяют сопоставить одному слову несколько векторов — плюс-минус по количеству значений. Это круто, потому что решает проблему омонимии и многозначности: word2vec выдает один вектор для слова ручка, которое будет одинаково близко к словам дверь и писать. А новые модели, такие как BERT и ELMo, адаптируются под контекст конкретного предложения. Обязательно почитайте и об этих ребятах тоже.
Словарик
Векторизация — превращение текста в последовательность чисел или числовых векторов.
One-hot-encoding — способ векторизации или превращения категориальных данных в количественные. Каждый элемент превращается в вектор по длине словаря. Каждый вектор заполнен нулями, кроме одной позиции, которая соответствует порядковому номеру элемента в словаре.
TF-IDF — способ векторизации, при котором каждому слову в документе присваивается «вес», соответствующий его важности в документе. Вес каждого слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции.
Мешок слов (bag of words) — модель текстов на естественном языке, в которой каждый текст выглядит как неупорядоченный набор слов без сведений о связях между ними.
Эмбеддинг (word embedding) — сопоставление элемента речи (слова, предложения, etc.) числовому вектору.
Контекст — окружение слова в тексте.
Дистрибутивная семантика — область лингвистики, которая занимается вычислением степени семантической близости между лингвистическими единицами на основании их распределения (дистрибуции) в больших массивах лингвистических данных.
word2vec — нейросетевая модель для создания эмбеддингов на основе дистрибутивной семантики.
Continous bag of words (CBOW) — вариант архитектуры нейросети word2vec, который умеет предсказывать слова по окружающему контексту.
Skip-gram — вариант архитектуры нейросети word2vec, который умеет предсказывать контекст, окружающий слово.
Семантический кластер — группа слов, связанных между собой по смыслу.
Тематическое моделирование — модель коллекции текстовых документов, которая определяет, к каким темам относится каждый документ коллекции.
Источник: m.vk.com