Что внутри чат-бота?
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-10-03 16:46
Полную версию моего выступления на «Ночи научных историй» можно посмотреть в видеозаписи, а краткие тезисы я приведу в тексте ниже.

Возможности алгоритмов
В первую очередь, алгоритмы взаимодействия с человеком находят успешное применение в call-центрах. Работа оператора call-центра очень тяжелая и дорогостоящая. Более того, во многих ситуациях полностью решить проблему общения человека и компьютера практически невозможно. Одно дело, когда мы работаем с банком, у которого, как правило, несколько тысяч клиентов. Можно набрать штат сотрудников call-центра, который бы обслуживал этих клиентов и беседовал с ними. Но когда мы решаем более масштабные задачи (например, производим смартфоны или какую-то другую бытовую электронику), у нас клиентов не несколько тысяч, а несколько десятков миллионов по всему миру. И мы хотим понимать, какие проблемы с нашей продукцией есть у людей. Пользователи, как правило, делятся друг с другом информацией на форумах либо пишут в службу поддержки производителя смартфонов. Живые операторы не смогут справиться с работой по огромной клиентской базе, и здесь на помощь приходят алгоритмы, которые могут работать в многоканальном режиме, обслуживая огромное количество людей.
Для решения подобных задач, для построения алгоритмов диалоговых систем, которые могли бы взаимодействовать с человеком и извлекать смысл, важную информацию из произвольных сообщений, существует целое направление в области компьютерной лингвистики – анализ текстов на естественном языке. Робот должен уметь читать, понимать, слушать, говорить и так далее. Это направление – Natural Language Processing (анализ текста на естественном языке) – распадается на несколько частей.
Понимание текста (Natural Language Understanding, NLU).
Когда бот общается с человеком и человек что-то пишет боту, нужно понять, что написано, что хотел пользователь, о чем он упоминал в своей речи. Понимание намерений пользователя, так называемого интента – чего человек хочет: перевыпустить банковскую карту или заказать пиццу. И выделение именованных сущностей, то есть вещей, о которых конкретно говорит пользователь: если это пицца, то «Маргарита» или «Гавайская», если карта, то какая система – MasterCard, Мир и так далее.


Распознавание и синтез речи (Speech-to-Text and Text-to-Speech). Если чат-бот не просто переписывается с человеком, а говорит и слушает, нужно научить его понимать устную речь, звуковые колебания преобразовывать в текст, чтобы потом модулем понимания текста этот текст анализировать, и из текста-ответа генерировать, в свою очередь, звуковые колебания, которые потом услышит человек, абонент.
Виды чат-ботов
В чат-ботах можно выделить несколько ключевых архитектур.
Чат-бот, отвечающий на наиболее часто задаваемые вопросы (FAQ-чатбот) – самый простой вариант. Мы всегда можем сформулировать набор типовых вопросов, которые задают люди. Для сайта по доставке готовой еды, как правило, это вопросы: «сколько будет стоить доставка», «доставляете ли вы в Первомайский район», и пр. Можно их сгруппировать по нескольким классам, интентам, пользовательским намерениям. И для каждого интента подобрать типовые ответы.
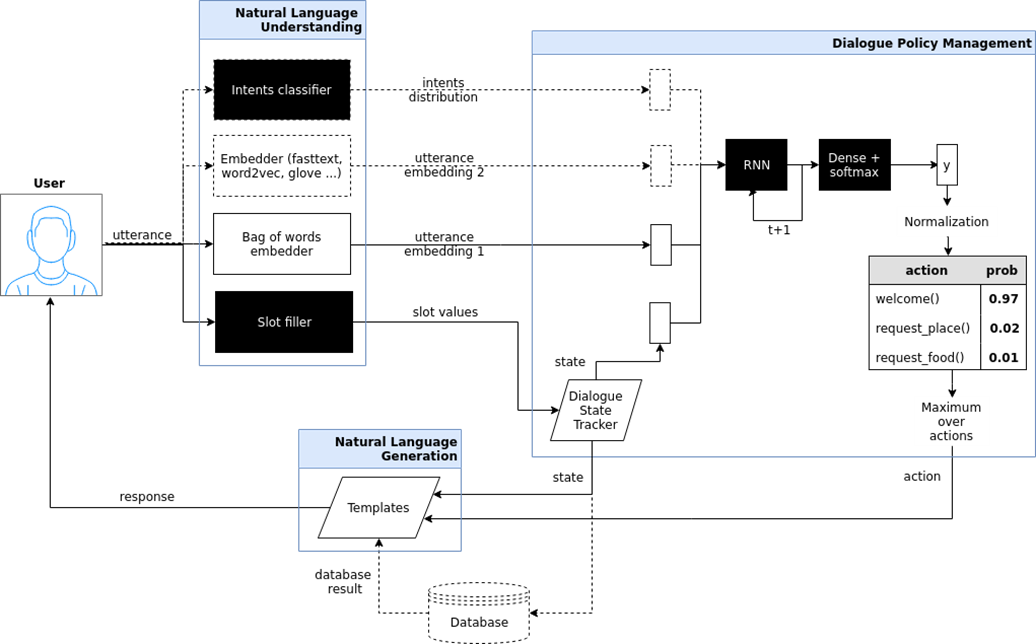
Целенаправленный чат-бот (goal oriented bot). Я здесь попытался показать архитектуру подобного чат-бота, который реализован в проекте iPavlov. iPavlov – это проект по созданию разговорного искусственного интеллекта. В частности, целенаправленный чат-бот помогает пользователю достичь какой-то цели (например, забронировать столик в ресторане или заказать пиццу, или что-то узнать о проблемах в банке). Речь идет не просто об ответе на вопрос (вопрос-ответ – без всякого контекста). У целенаправленного чат-бота есть модуль понимания текста, управления диалогом и модуль генерации ответов.
Виды машинного обучения
Распознавание интентов, выделение именованных сущностей, поиск в документах и поиск мест в документе, которые соответствуют семантике вопроса – все это без машинного обучения, без некого статистического анализа реализовать невозможно. Поэтому в основе современных чат-ботов лежит машинное обучение –методы задач, аппроксимации некой скрытой закономерности, которая есть в больших массивах данных и выявление этих закономерностей. Такой подход имеет смысл применять, когда закономерности, задачи есть, но простую формулу, формализм для описания этой закономерности придумать невозможно.
Существует несколько видов машинного обучения: с учителем (supervised learning), без учителя (unsupervised learning), с подкреплением (reinforcement learning). Нас интересует, прежде всего, задача обучения с учителем – когда есть входные изображения и указания (метки) учителя и классификация этих изображений. Либо входные речевые сигналы и их классификация. И мы учим нашего бота, наш алгоритм воспроизводить работу учителя.
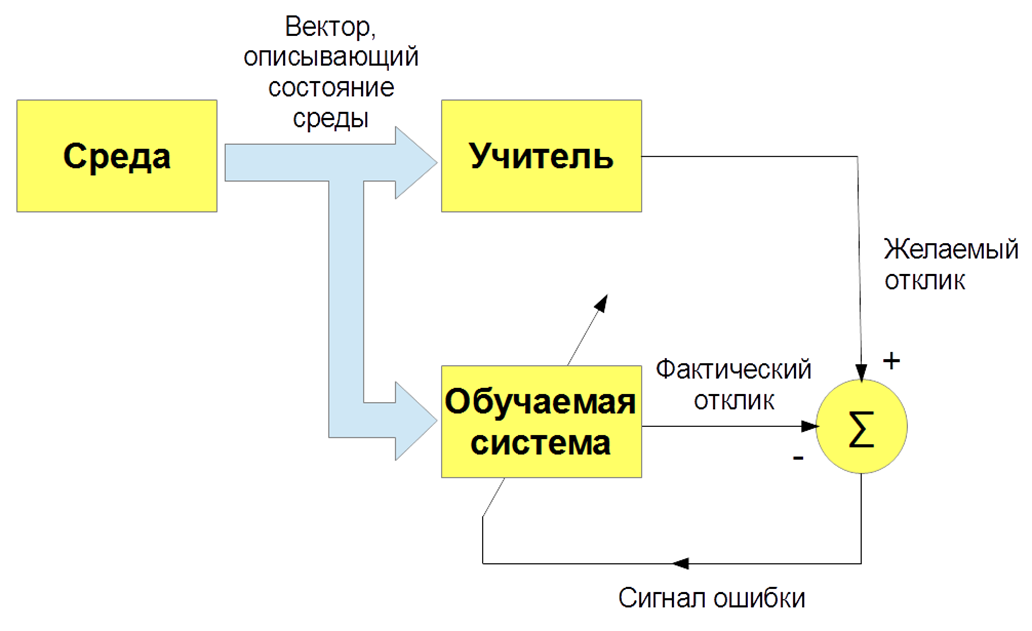
Наконец, как мы обучаем? Для того чтобы обучить бота понимать интенты, истинные намерения, нужно вручную разметить кучу текстов с помощью специальных программ. Чтобы научить бота понимать именованные сущности – имя человека, название фирмы, локация – тоже нужно размещать тексты. Соответственно, с одной стороны, алгоритм обучения с учителем наиболее эффективный, он позволяет создавать эффективную распознающую систему, но, с другой стороны, возникает проблема: нужны большие размеченные дата-сеты, а это делать дорого и долго. В процессе разметки дата-сетов могут быть ошибки, вызванные человеческим фактором.
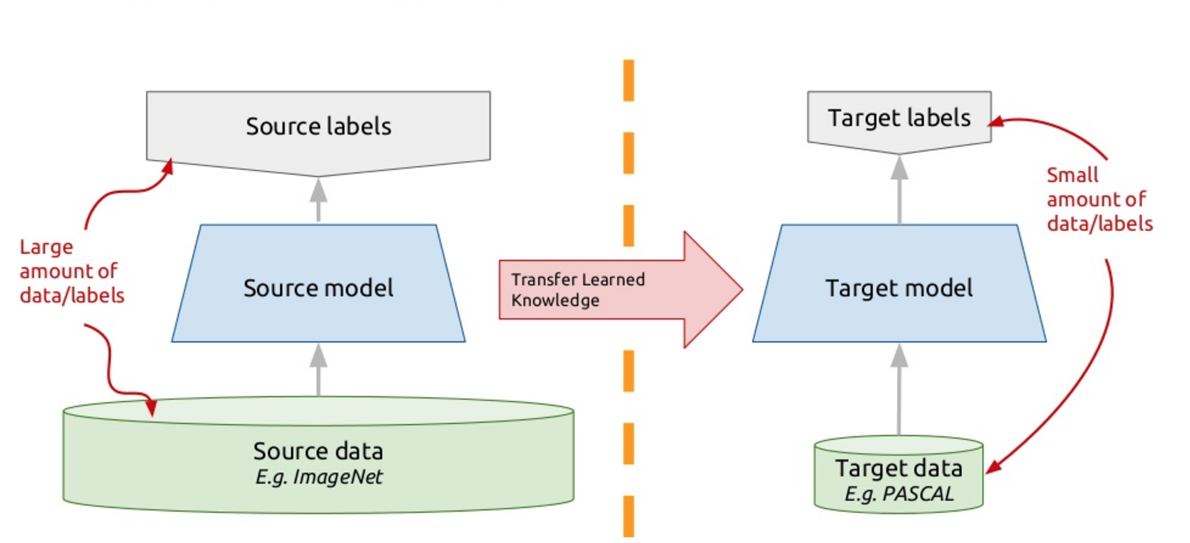
Для решения этой проблемы в современных чат-ботах применяют так называемый перенос обучения – transfer learning. Те, кто знают много иностранных языков, наверняка замечали такой нюанс, что очередной иностранный язык учить легче, чем первый. Собственно, когда вы изучаете какую-то новую задачу, то пытаетесь использовать для этого свой прошлый опыт. Так вот, transfer learning (перенос обучения) как раз основан на этом принципе: мы обучаем алгоритм решать одну задачу, для которой у нас есть большой дата-сет. А потом этот обученный алгоритм (то есть берем алгоритм не с нуля, а обученный решению другой задачи), дообучаем решать нашу задачу. Таким образом, мы получаем эффективное решение с использованием небольших различных данных.
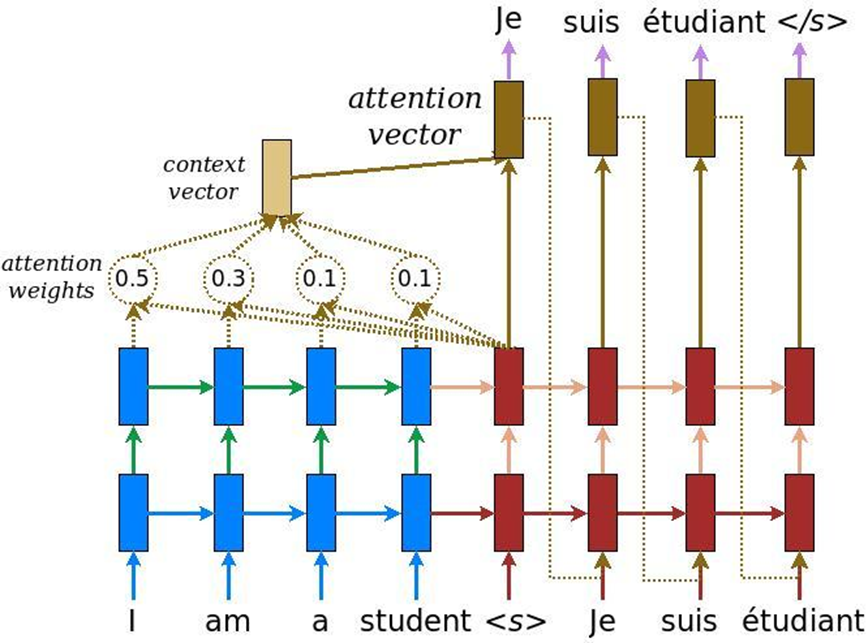
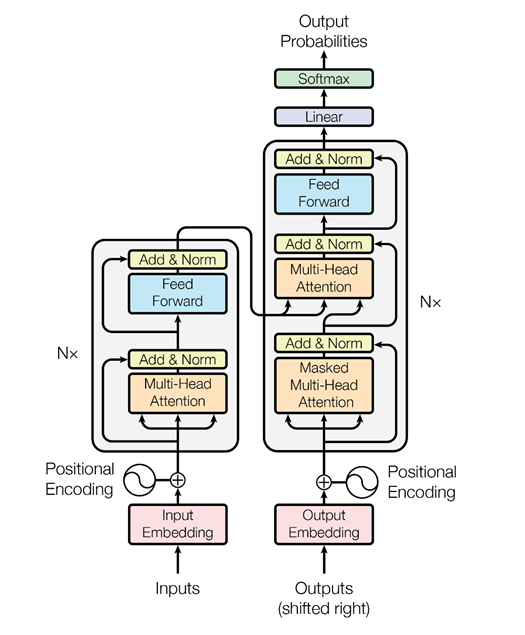
В анализе текстов есть еще одна особенность: когда решается задача машинного перевода, один и тот же смысл одним количеством слов на английском может быть передан и другим количеством слов на русском. Соответственно, идет не линейное сопоставление, и нам необходим механизм, который бы акцентировал внимание на тех или иных кусочках текста, чтобы адекватно их перевести на другой язык. Изначально внимание было придумано для машинного перевода – задача преобразования одного текста в другой с обычными рекуррентными нейронными системами. В это мы добавляем специальный слой внимания, который в каждый момент времени оценивает, какое слово нам сейчас важно.
Источник: habr.com