Решение задачи Титаник на Kaggle для начинающих
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-06-23 21:22

Титаник — известная задача на Kaggle, ориентированная в большей мере на начинающих в машинном обучении. Датасет Титаник содержит данные пассажиров корабля. Цель задачи — построить модель, которая лучшим образом сможет предсказать, остался ли произвольный пассажир в живых или нет.
Перевод статьи A beginner’s guide to Kaggle’s Titanic problem, автор — Sumit Mukhija, ссылка на оригинал — в подвале статьи.
Я разработчик программного обеспечения, ставший энтузиастом в анализе данных. Недавно я начал постигать тонкости Data Science. Когда я начал изучать видеокурсы на таких сайтах, как Udemy, Coursera и т.д., из-за одной задачи у меня пропало желание решать ее и другие задачи, и я стал больше слушать и меньше делать. У меня не было практики, хотя я понимал большую часть теории.
В этот момент я наткнулся на Kaggle, сайт с набором задач в области Data Science и соревнованиями, проводимыми несколькими крупными технологическими компаниями, такими как Google. Во всем мире Kaggle известен своими интересными, сложными и очень захватывающими задачами. Одной из таких задач является датасет Титаник.
Подводя итог, можно сказать, что задача Титаник основана на потоплении «непотопляемого» корабля «Титаник» в начале 1912 года. Она дает вам информацию о пассажирах, такую как их возраст, пол, число братьев и сестер, порт посадки и выжили ли они или нет в катастрофе. Основываясь на этой информации, вы должны предсказать, сможет ли произвольный пассажир на Титанике пережить затопление.
Звучит легко, правда? Нет. Постановка задачи является лишь верхушкой айсберга.
Используемые библиотеки
- Pandas
- Seaborn
- Sklearn
- WordCloud
Начальный этап
На начальном этапе рассматривались признаки полного датасета. Здесь я не пытался производить действия над признаками, а просто наблюдал их значения.
1. Загрузка данных
Я сразу загрузил данные из train и test датасетов. Полученный датасет имел 1309 строк и 12 столбцов. Каждая строка представляла уникального пассажира Титаника, а в каждом столбце содержались количественные или категориальные признаки для каждого пассажира.
trd = pd.read_csv('train.csv') tsd = pd.read_csv('test.csv') td = pd.concat([trd, tsd], ignore_index=True, sort = False) 2. Пропущенные значения
В датасете было несколько столбцов, в которых отсутствовали значения. Признак «Cabin» имел 1014 пропущенных значений. Столбец «Embarked», который отображал пункт посадки пассажиров, имел всего 2 пропущенных значения. В признаке «Age» было 263 пропущенных значения, а в столбце «Fare» — одно.
td.isnull().sum() sns.heatmap(td.isnull(), cbar = False).set_title("Missing values heatmap") 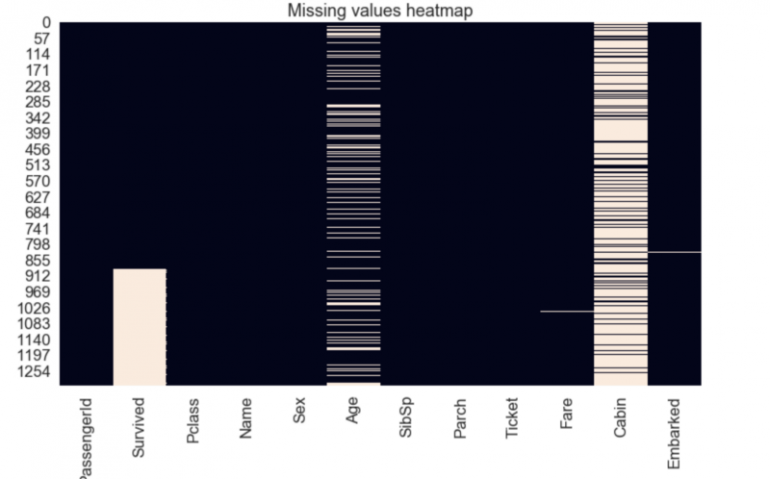
3. Категориальные признаки
Далее, чтобы определить категориальные признаки, я взглянул на количество уникальных значений в каждом столбце. Признаки «Sex» и «Survived» имели два возможных значения, а «Embarked» и «Pclass» имели три возможных значения.
td.nunique() PassengerId 1309 Survived 2 Pclass 3 Name 1307 Sex 2 Age 98 SibSp 7 Parch 8 Ticket 929 Fare 281 Cabin 186 Embarked 3 dtype: int64
Признаки
Получив лучшее представление о различных аспектах датасета, я начал исследовать признаки и роль, которую они сыграли в выживании или гибели путешественника.
1. Survived
Первый признак показывал, выжил ли пассажир или умер. Сравнение показало, что более 60% пассажиров умерли.
2. Pclass
Этот признак показывает класс, которым следовал пассажир. Пассажиры могли выбрать из трех отдельных классов, а именно: класс 1, класс 2 и класс 3. Третий класс имел наибольшее количество пассажиров, затем класс 2 и класс 1. Количество пассажиров в третьем классе было больше, чем количество пассажиров в первом и втором классе вместе взятых. Вероятность выживания пассажира класса 1 была выше, чем пассажира класса 2 и класса 3.
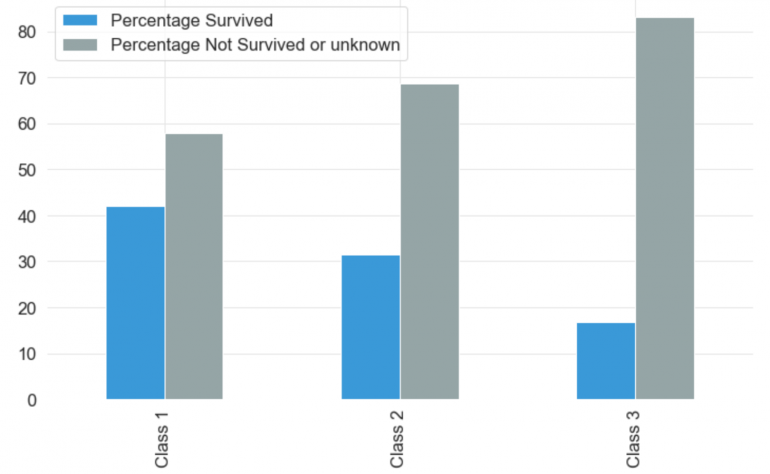
3. Sex
Примерно 65% пассажиров составляли мужчины, а остальные 35% — женщины. Тем не менее, процент выживших женщин был выше, чем число выживших мужчин. Более 80% мужчин умерли, в сравнении с примерно 70% женщинами.
4. Age
Самому молодому путешественнику на борту было около двух месяцев, а самому старшему — 80 лет. Средний возраст пассажиров на борту был чуть менее 30 лет. Большая часть детей в возрасте до 10 лет выжила. В любой другой возрастной группе число жертв было выше, чем число выживших. Более 140 человек в возрастной группе 20-30 лет погибли в сравнении с примерно 80 выжившими того же возраста.
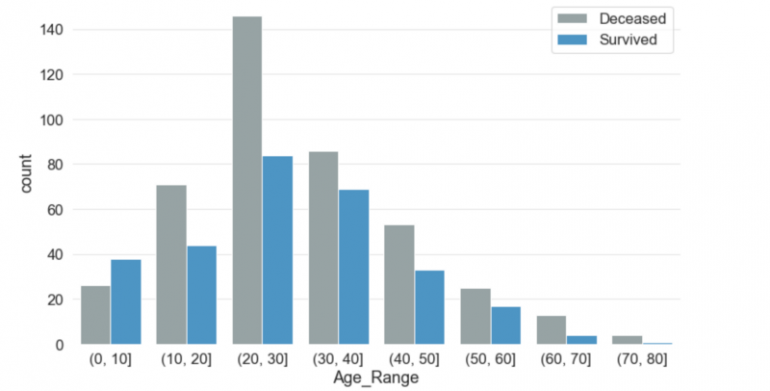
5. SibSp
SibSp — это число братьев, сестер или супругов на борту у человека. Максимум 8 братьев и сестер путешествовали вместе с одним из путешественников. Более 90% людей путешествовали в одиночку или с одним из своих братьев и сестер или супругом(ой). Шансы на выживание резко падали, если кто-то ездил с более чем двумя родными.
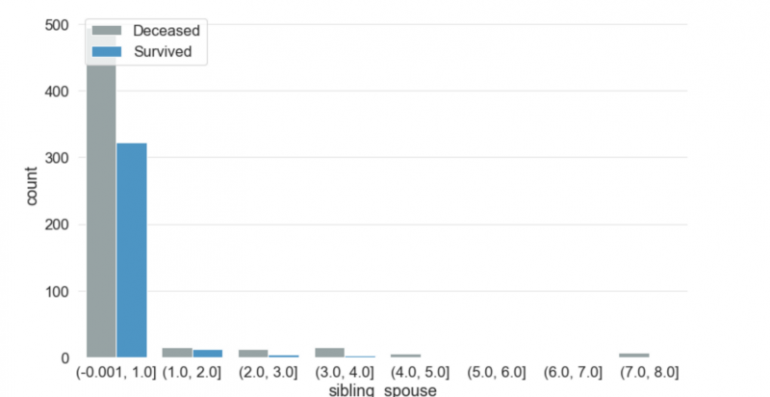
6. Parch
Подобно SibSp, этот признак содержал количество родителей или детей, с которыми путешествовал каждый пассажир. Максимум 9 родителей/детей путешествовали вместе с одним из пассажиров.
Для хранения суммарных значений «Parch» и «SibSp» я добавил столбец «Family».
td['Family'] = td.Parch + td.SibSp
Более того, шансы на выживание взлетели до небес, когда путешественник путешествовал один. Создал другой столбец Is_Alone и присвоил значение True, если значение в столбце «Family» было 0.
td['Is_Alone'] = td.Family == 0
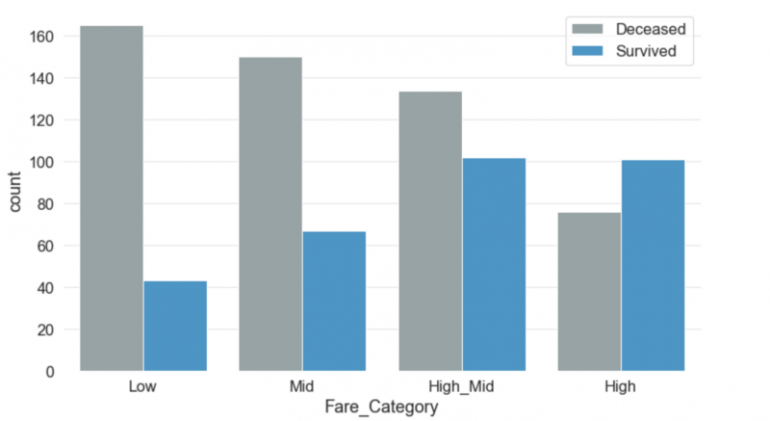
7. Fare
Разделив сумму тарифа на четыре категории, стало очевидно, что существует тесная связь между стоимостью тарифа и выживанием. Чем больше заплатит пассажир, тем выше будут его шансы на выживание.
Я добавил новые категории тарифов в новый столбец Fare_Category.
td['Fare_Category'] = pd.cut(td['Fare'], bins=[0,7.90,14.45,31.28,120], labels=['Low','Mid', 'High_Mid','High'])
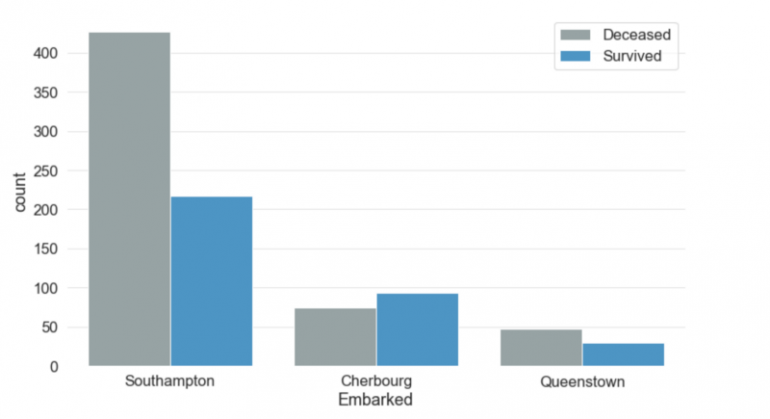
8. Embarked
Этот столбец хранит информацию о порте посадки пассажира. Есть три возможных значения для Embarked -? Саутгемптон, Шербург и Куинстаун. Более 70% людей сели в Саутгемптон. Чуть менее 20% сели на борт из Шербура, а остальные — из Квинстауна. Люди, которые сели в порте Шербург, имели более высокие шансы на выживание, чем люди, которые сели в портах Саутгемптон или Квинстаун.
Стоит отметить, что мы не использовали столбец «Ticket».
Заполнение пропущенных данных
Существует множество процессов заполнения пропусков, которые можно использовать. Я использовал некоторые из них.
1. Embarked
Поскольку у «Embarked» было только два пропущенных значения и наибольшее количество пассажиров отправлялось из Саутгемптона, вероятность посадки в Саутгемптоне выше. Итак, мы заполняем недостающие значения Саутгемптоном. Однако вместо того, чтобы вручную вводить Саутгемптон, мы найдем моду столбца Embarked и подставим в него отсутствующие значения.
Мода — наиболее часто встречающийся элемент в выборке.
td.Embarked.fillna(td.Embarked.mode()[0], inplace = True)
2. Cabin
В колонке «Cabin» было много пропущенных данных. Я решил определить все отсутствующие данные в отдельный класс. Я назвал его NA и заполнил все пропущенные значения этим значением.
td.Cabin = td.Cabin.fillna('NA') 3. Age
Возраст был самым непростым столбцом для заполнения. Возраст имел 263 пропущенных значения. Я сперва классифицировал людей на основе их имени. Разделение строк простого Python было достаточно, чтобы извлечь префикс для обращений (например, Mr, Miss, Mrs) из каждого имени. Было 18 разных названий.
td['Salutation'] = td.Name.apply(lambda name: name.split(',')[1].split('.')[0].strip()) Затем я сгруппировал эти названия по Sex и PClass.
grp = td.groupby(['Sex', 'Pclass'])
Медиана группы затем была подставлена ??в пропущенные строки.
grp.Age.apply(lambda x: x.fillna(x.median())) td.Age.fillna(td.Age.median, inplace = True)
Кодирование категориальных признаков
Поскольку текстовые данные плохо сочетаются с алгоритмами машинного обучения, мне нужно было преобразовать нечисловые данные в числовые. Я использовал LabelEncoder для кодирования столбца «Sex». LabelEncoder будет заменять «мужские» значения одним числом, а «женские» значения — другим числом.
td['Sex'] = LabelEncoder().fit_transform(td['Sex'])
Для других категориальных данных я использовал функцию Pandas get_dummies, которая добавляет столбцы, соответствующие всем уникальным значениям столбца. Таким образом, если бы было три возможных значения столбца — Q, C и S, метод get_dummies создал бы три различных столбца и назначил бы значения 0 или 1 в зависимости от соответствия значения этому столбцу.
pd.get_dummies(td.Embarked, prefix="Emb", drop_first = True)
Удаление колонок
Я отбросил столбцы, которые мне не нужны для прогнозирования, и столбцы, которые я кодировал функцией get_dummies.
td.drop(['Pclass', 'Fare','Cabin', 'Fare_Category','Name','Salutation', 'Deck', 'Ticket','Embarked', 'Age_Range', 'SibSp', 'Parch', 'Age'], axis=1, inplace=True)
Прогнозирование
Это был случай задачи классификации, и я попытался сделать предсказания с помощью двух алгоритмов — Случайный лес и Гауссовский Наивный Байесовский классификатор.
Я был удивлен результатами. Наивный классификатор работал плохо, а Случайный лес, напротив, делал предсказания с точностью более 80%.
# Data to be predicted X_to_be_predicted = td[td.Survived.isnull()] X_to_be_predicted = X_to_be_predicted.drop(['Survived'], axis = 1) # X_to_be_predicted[X_to_be_predicted.Age.isnull()] # X_to_be_predicted.dropna(inplace = True) # 417 x 27 #Training data train_data = td train_data = train_data.dropna() feature_train = train_data['Survived'] label_train = train_data.drop(['Survived'], axis = 1) ##Gaussian clf = GaussianNB() x_train, x_test, y_train, y_test = train_test_split(label_train, feature_train, test_size=0.2) clf.fit(x_train, np.ravel(y_train)) print("NB Accuracy: "+repr(round(clf.score(x_test, y_test) * 100, 2)) + "%") result_rf=cross_val_score(clf,x_train,y_train,cv=10,scoring='accuracy') print('The cross validated score for Random forest is:',round(result_rf.mean()*100,2)) y_pred = cross_val_predict(clf,x_train,y_train,cv=10) sns.heatmap(confusion_matrix(y_train,y_pred),annot=True,fmt='3.0f',cmap="summer") plt.title('Confusion_matrix for NB', y=1.05, size=15) 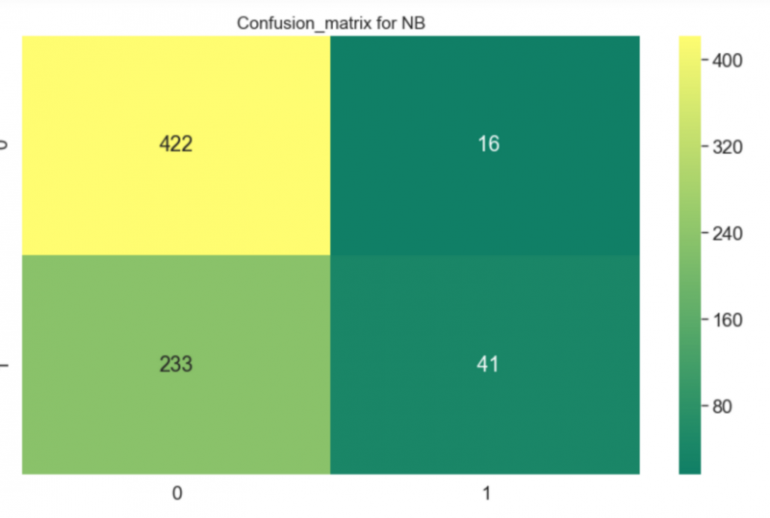
##Random forest clf = RandomForestClassifier(criterion='entropy', n_estimators=700, min_samples_split=10, min_samples_leaf=1, max_features='auto', oob_score=True, random_state=1, n_jobs=-1) x_train, x_test, y_train, y_test = train_test_split(label_train, feature_train, test_size=0.2) clf.fit(x_train, np.ravel(y_train)) print("RF Accuracy: "+repr(round(clf.score(x_test, y_test) * 100, 2)) + "%") result_rf=cross_val_score(clf,x_train,y_train,cv=10,scoring='accuracy') print('The cross validated score for Random forest is:',round(result_rf.mean()*100,2)) y_pred = cross_val_predict(clf,x_train,y_train,cv=10) sns.heatmap(confusion_matrix(y_train,y_pred),annot=True,fmt='3.0f',cmap="summer") plt.title('Confusion_matrix for RF', y=1.05, size=15) 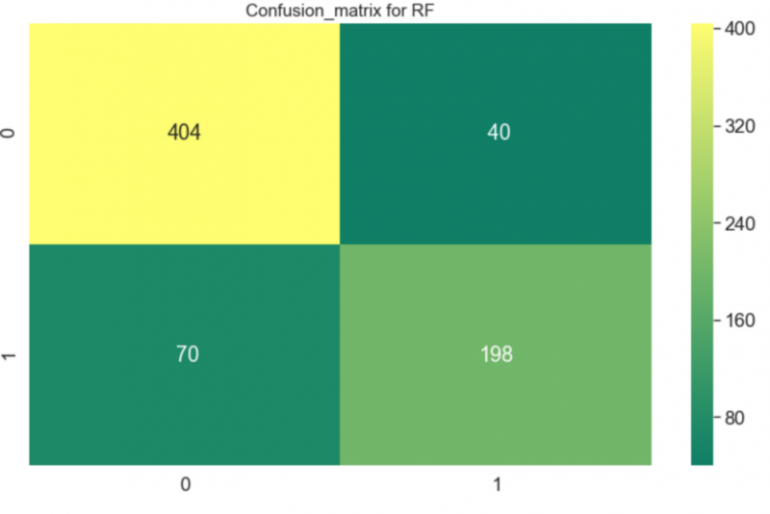
RF Accuracy: 78.77% The cross validated score for Random forest is: 84.56
Наконец, я создал файл для хранения предсказанных результатов.
result = clf.predict(X_to_be_predicted) submission = pd.DataFrame({'PassengerId':X_to_be_predicted.PassengerId,'Survived':result}) submission.Survived = submission.Survived.astype(int) print(submission.shape) filename = 'Titanic Predictions.csv' submission.to_csv(filename,index=False) print('Saved file: ' + filename) Строка кода ниже особенно важна, поскольку Kaggle неверно оценил бы прогнозы, если значение Survived не относится к типу данных int.
submission.Survived = submission.Survived.astype(int)

С полной реализацией Jupyter Notebook можно ознакомиться на моем GitHub или Kaggle. Решение позволило попасть мне в топ 8% участников. Это было нелегко, и мне потребовалось более 20 попыток попасть туда. Я бы сказал, что важно быть аналитическом, пробовать то, что покажется интересным, использовать интуицию и пробовать все, каким бы нелепым это ни казалось.
Источник: neurohive.io